openGauss 作为一款企业级开源数据库,其强大的内核能力主要体现在智能优化器、多模存储引擎以及海量数据分区管理上。深入掌握这些高级特性及完整语法,是进行数据库架构设计与性能调优的基石。

思维导图
一、智能查询优化器
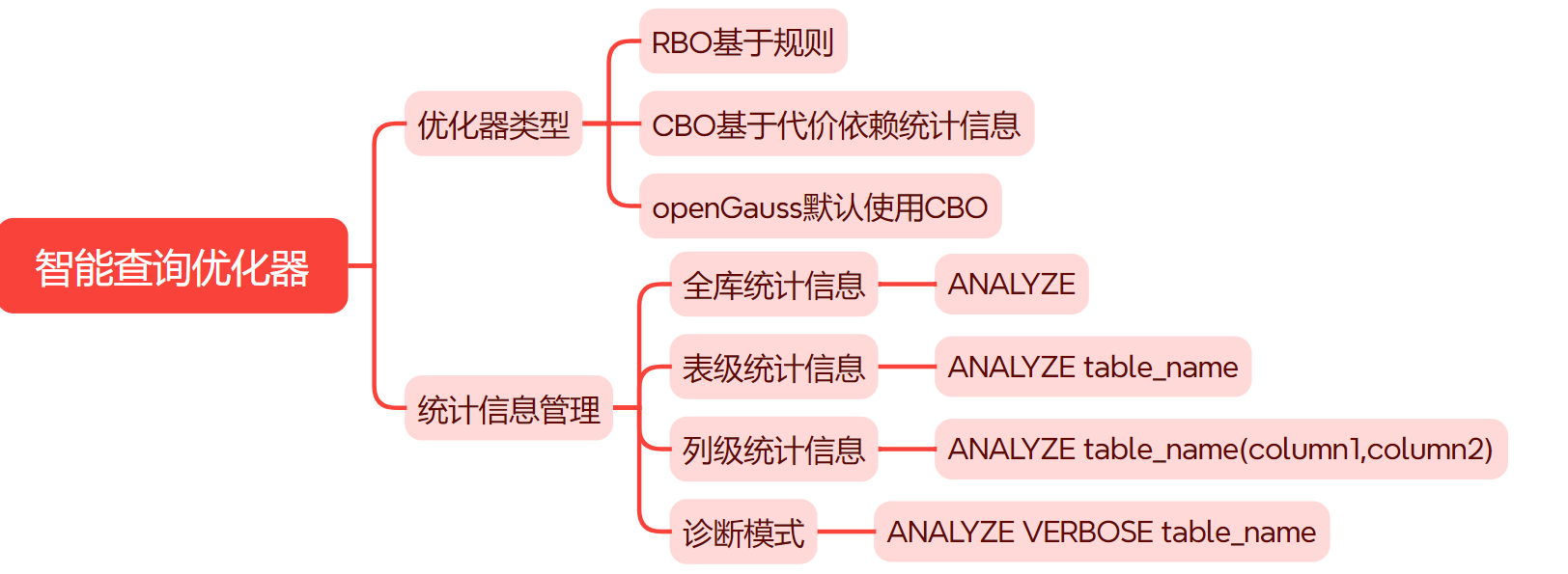
优化器 是数据库的大脑,负责将 SQL 语句转换为最高效的执行计划。
1. 核心机制对比
RBO :基于固定规则。例如有索引就用索引。它不考虑表中有多少数据,逻辑简单但僵化,适用于简单查询或元数据查询。
CBO :基于代价估算。它是 openGauss 的主力优化器。它通过计算 CPU、内存、I/O 等资源的消耗,选择代价最小的路径。CBO 严重依赖统计信息的准确性。
2. 统计信息管理
为了让 CBO 聪明地工作,必须定期收集统计信息。
sql
-- 1. 收集全库统计信息 (通常由自动维护任务执行)
ANALYZE;
-- 2. 收集指定表的统计信息 (标准用法)
ANALYZE customer;
-- 3. 收集指定表特定列的统计信息
ANALYZE customer (age, city);
-- 4. 打印详细进度信息 (用于诊断)
ANALYZE VERBOSE customer;二、多模表存储引擎
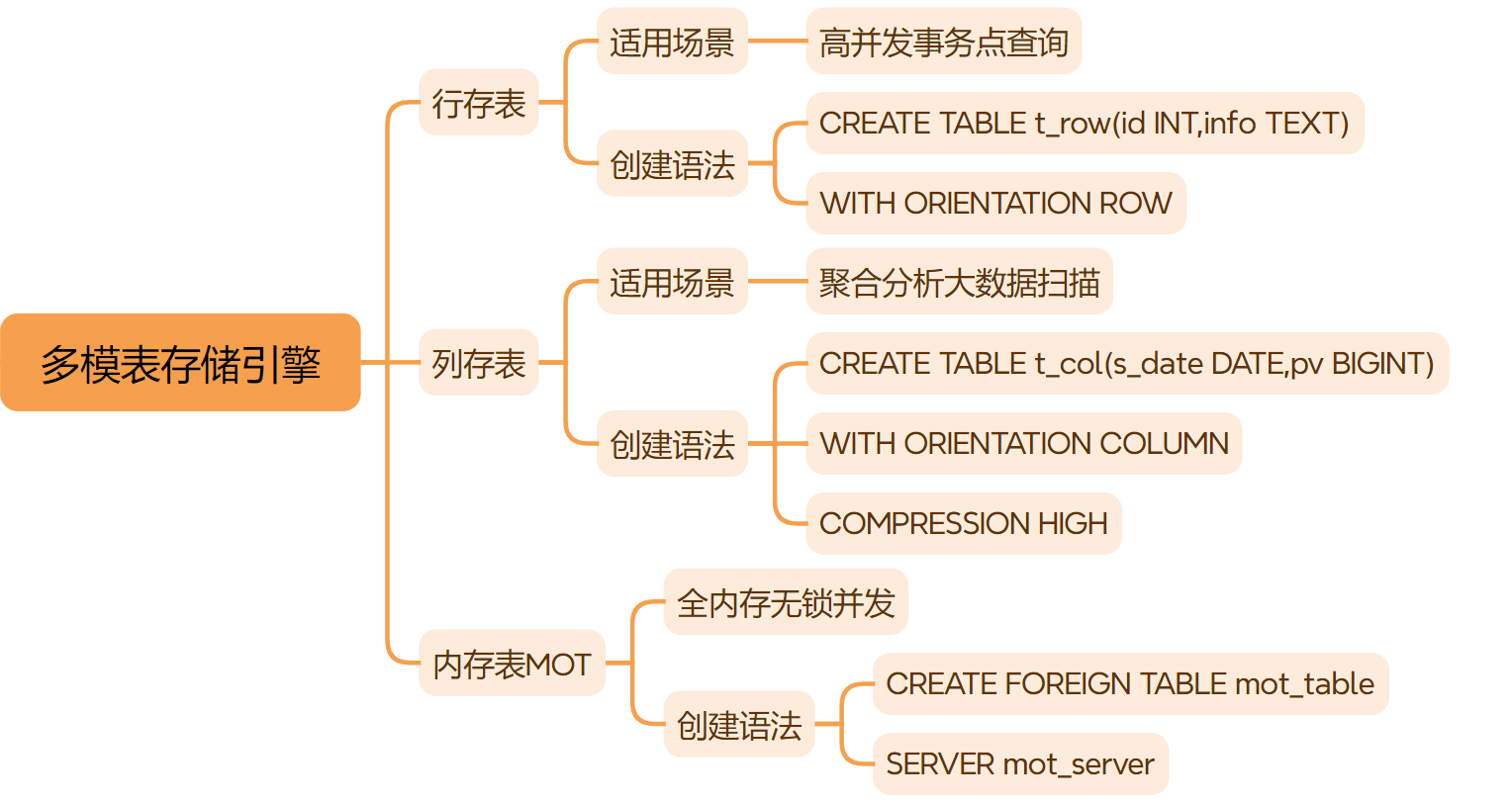
openGauss 支持在一个数据库中混合使用多种存储模式,以适配不同的业务负载。
1. 行存表:OLTP 首选
数据按行连续存储,适合点查询和高频事务
完整创建语法
sql
CREATE TABLE table_name (
column_name data_type,
...
)
WITH (
ORIENTATION = ROW, -- 显式指定为行存
COMPRESSION = NO, -- 行存通常不压缩或轻量压缩
FILLFACTOR = 80 -- 预留空间参数,优化 UPDATE 性能
)
TABLESPACE tablespace_name; -- 指定存储表空间2. 列存表:OLAP 利器
数据按列连续存储,适合统计分析和海量数据
完整创建语法
sql
CREATE TABLE table_name (
column_name data_type,
...
)
WITH (
ORIENTATION = COLUMN, -- 显式指定为列存
COMPRESSION = HIGH, -- 设置压缩级别 (LOW/MIDDLE/HIGH)
MAX_BATCHROW = 60000, -- 单个 CU (压缩单元) 的最大行数
PARTIAL_CLUSTER_ROWS = 600000 -- 局部聚簇行数,优化顺序扫描
);3. 内存表:极致低延迟
MOT数据全内存驻留,无锁并发。
完整创建语法
MOT 表通过外表 机制实现。
sql
-- 1. 创建 MOT 专用表 (通常只需指定 FOREIGN 表,部分版本支持直接 CREATE FOREIGN TABLE)
CREATE FOREIGN TABLE mot_table (
id INT NOT NULL,
data CHAR(20)
)
SERVER mot_server; -- 指定使用内置的 MOT 服务引擎三、分区表:海量数据治理
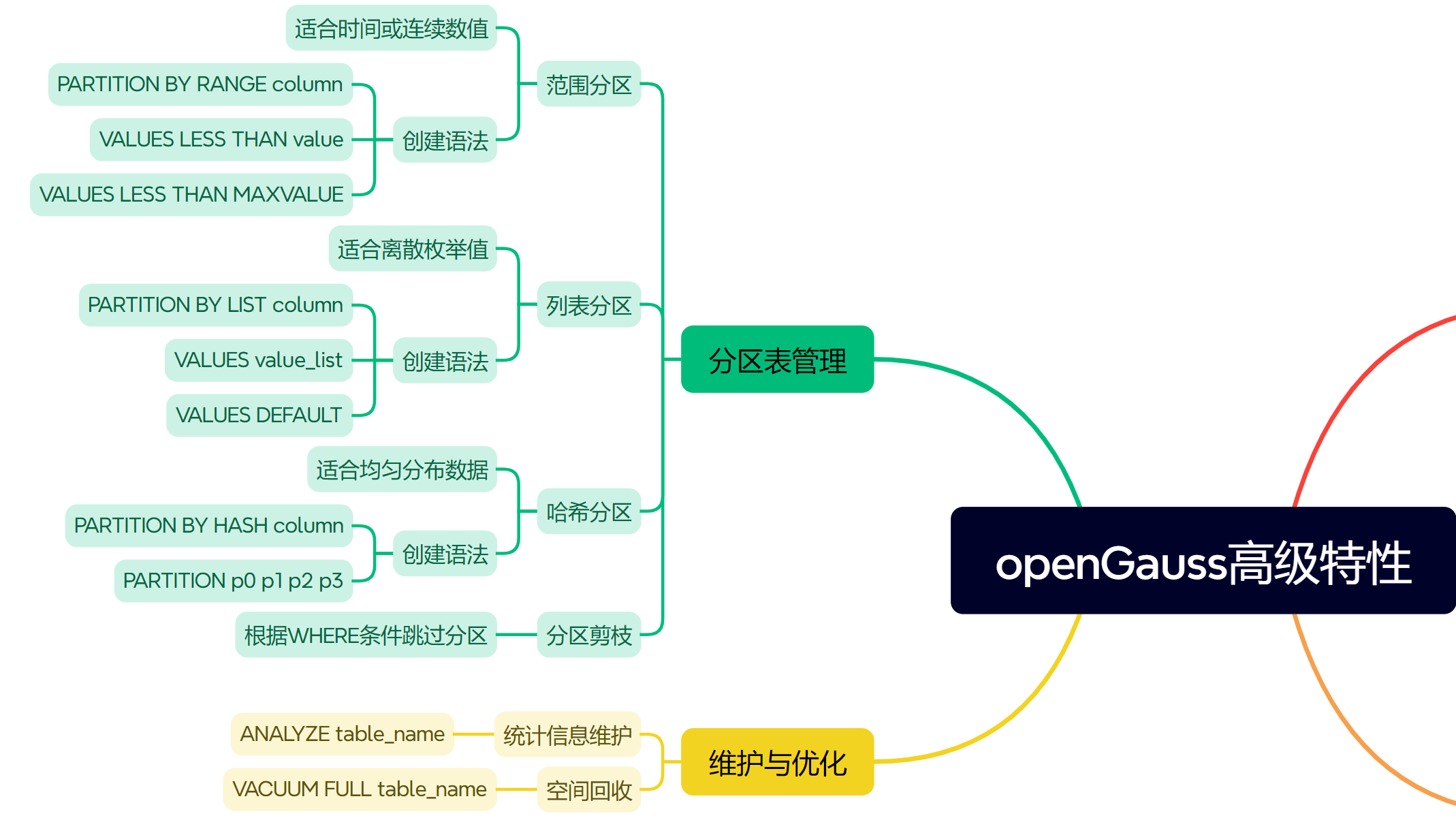
分区表将大表物理拆分为小文件,大幅提升查询和维护效率。
1. 范围分区
最常用的策略,按数值范围或时间周期划分。
完整语法示例
sql
CREATE TABLE sales_range (
sale_id INT,
sale_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (sale_date) (
-- 定义明确的范围分区
PARTITION p_q1_2023 VALUES LESS THAN ('2023-04-01'),
PARTITION p_q2_2023 VALUES LESS THAN ('2023-07-01'),
-- 定义表空间,实现冷热分离
PARTITION p_q3_2023 VALUES LESS THAN ('2023-10-01') TABLESPACE ts_ssd,
-- 兜底分区,存放超出上述范围的数据
PARTITION p_max VALUES LESS THAN (MAXVALUE) TABLESPACE ts_hdd );2. 列表分区
按离散枚举值划分,适合地域、类别等字段。
完整语法示例
sql
CREATE TABLE users_list (
user_id INT,
region VARCHAR(20)
)
PARTITION BY LIST (region) (
-- 单个值分区
PARTITION p_beijing VALUES ('Beijing'),
PARTITION p_shanghai VALUES ('Shanghai'),
-- 多个值合并分区
PARTITION p_south VALUES ('Guangzhou', 'Shenzhen'),
-- 默认分区 (可选)
PARTITION p_other VALUES (DEFAULT)
);3. 哈希分区
按哈希值打散,用于数据均匀分布,避免热点。
完整语法示例
sql
CREATE TABLE orders_hash (
order_id UUID,
customer_id INT
)
PARTITION BY HASH (customer_id) (
-- 只需指定分区数量,系统自动计算哈希边界
PARTITION p0,
PARTITION p1,
PARTITION p2,
PARTITION p3
);四、练习
1.openGauss 默认使用的优化器是哪一种?它主要依据什么来生成执行计划?
-
当一张表的数据发生大量变更(如插入了 50% 的新数据)后,为了防止 SQL 执行变慢,管理员应该立即执行什么命令?
-
编写 SQL 语句,创建一个名为
t_row_basic的行存表,包含id(INT) 和info(TEXT) 两列,并显式指定其存储方向参数。 -
编写 SQL 语句,创建一个名为
t_col_analytics的列存表,包含s_date(DATE) 和pv(BIGINT) 两列,并将其压缩级别设置为HIGH。 -
某业务系统需要每天进行大量的单行
INSERT操作,且主要是按主键 ID 进行单点查询,应选择行存还是列存? -
某数据仓库需要存储海量历史日志,且查询模式通常是扫描几百万行数据但只读取其中的两三列进行
SUM计算,对应选择行存还是列存? -
MOT 表的数据和索引主要存储在哪里?这为它带来了什么显著的性能优势?
-
如果要按"省份"(如 'Beijing', 'Shanghai')这类离散值对用户表进行分区,应该使用哪种分区策略?
-
编写 SQL 语句,创建一个名为
t_log_range的范围分区表。按log_id(INT) 列分区:p_small存储小于 1000 的数据,p_medium存储小于 2000 的数据,p_max存储剩余所有数据。 -
在存储同样的数据量时,通常哪种存储模式占用的磁盘空间更少?
-
简述列存表在执行
SELECT count(col_A) FROM table这类只涉及单列的聚合查询时,比行存表快的主要原因。 -
简述 RBO (基于规则的优化器) 相比于 CBO 的主要缺点是什么?
-
在
CREATE TABLE的WITH子句中,用于指定表存储方向(行或列)的参数名称是什么? -
使用分区表时,数据库可以通过分析查询条件(WHERE)直接跳过不符合条件的分区文件,这一特性被称为什么?
-
对于列存表,频繁的
UPDATE和DELETE操作会导致磁盘空间膨胀且无法自动回收,通常需要手动执行什么命令来彻底重组表并回收空间?
五、解析
1. CBO,主要依据统计信息计算出的代价。
解析: RBO 依据固定规则,CBO 依据数据统计信息,openGauss 核心是 CBO。
2.
sql
ANALYZE table_name;解析 : 数据大量变更会导致旧的统计信息失真,误导优化器生成错误的执行计划。
ANALYZE命令用于重新收集统计信息。
3.
sql
CREATE TABLE t_row_basic (id INT, info TEXT) WITH (ORIENTATION = ROW);解析 : 行存表的关键参数是
ORIENTATION = ROW。
4.
sql
CREATE TABLE t_col_analytics (s_date DATE, pv BIGINT) WITH (ORIENTATION = COLUMN, COMPRESSION = HIGH);解析 : 列存表使用
ORIENTATION = COLUMN,并通过COMPRESSION参数控制压缩等级。
5. 行存表
解析: OLTP 场景(高频插入、事务处理、点查询)是行存表的绝对强项。
6. 列存表
解析: OLAP 场景(聚合分析、海量扫描、只读取特定列)是列存表的设计初衷,能大幅减少 I/O。
7. 存储在内存中。优势:实现了极低的事务延迟和极高的吞吐量,消除了磁盘 I/O 瓶颈。
解析: MOT 全称 Memory-Optimized Table,是全内存引擎,非缓存机制。
8. 列表分区
解析: 省份是有限的、离散的枚举值,适合 List 分区;连续的数值或时间适合 Range 分区。
9.
sql
CREATE TABLE t_log_range (log_id INT) PARTITION BY RANGE (log_id) (
PARTITION p_small VALUES LESS THAN (1000),
PARTITION p_medium VALUES LESS THAN (2000),
PARTITION p_max VALUES LESS THAN (MAXVALUE)
);解析 : Range 分区需要定义上界,
MAXVALUE用于捕获所有超出前面定义范围的数据。
10. 列存表
解析: 列存表中同一列的数据类型相同,重复度高,利用 RLE (运行长度编码) 等算法能获得极高的压缩比(通常 10 倍以上)。
11. I/O 裁剪或只读取需要的列。列存表只需要物理读取 col_A 这一列的数据块,而行存表必须将包含所有列的整行数据读入内存,产生了大量无效 I/O。
解析: 读取的数据量越少,查询速度越快。
12. RBO 忽略数据的实际分布情况,仅依靠硬编码规则,在数据分布不均时如数据倾斜容易生成次优的执行计划。
解析: 例如索引列全是同一个值,RBO 仍可能强制走索引,导致随机 I/O 激增,性能不如全表扫描。
13. ORIENTATION
解析 : 语法为
WITH (ORIENTATION = ROW | COLUMN)。
14. 分区剪枝
解析: 这是分区表性能提升的核心原理,系统只扫描包含目标数据的分区,跳过无关分区。
15. VACUUM FULL table_name;
解析 : 列存表的删除通常是逻辑标记删除,物理空间不会立即释放。
VACUUM FULL会重写整个表文件,彻底回收空间。

日期:2025年12月25日
专栏:openGauss