一、卷积神经网络(CNN)概述
卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理具有网格结构数据(如图像、语音)的深度学习模型。与传统的全连接神经网络相比,CNN通过引入卷积操作、池化操作等核心机制,有效降低了模型的参数数量,解决了全连接网络在处理高维度图像数据时易出现的过拟合和计算量过大问题,因此在计算机视觉领域(如图像分类、目标检测、图像分割等)得到了广泛应用。
CNN的核心优势源于其对图像局部特征的提取能力和参数共享机制:
-
局部感受野:卷积核仅对输入图像的局部区域进行卷积运算,能够精准捕捉图像的边缘、纹理等局部特征,再通过深层网络逐步组合成更复杂的全局特征。
-
参数共享:同一卷积核在整个输入图像上重复使用,大幅减少了模型需要学习的参数数量,提升了训练效率,同时增强了模型的泛化能力。
-
池化操作:对卷积后的特征图进行下采样,保留关键特征的同时降低特征图的维度,进一步减少计算量,抑制过拟合。
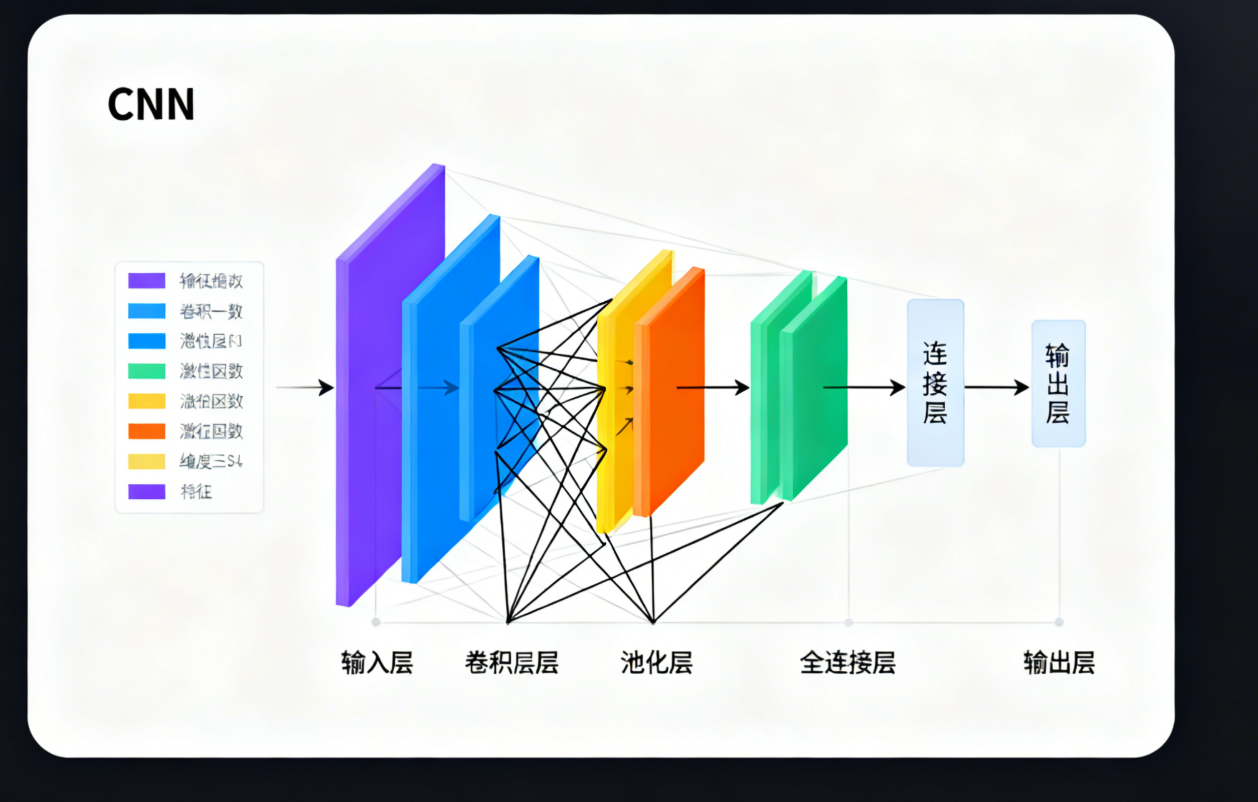
二、CNN的核心结构
一个典型的CNN模型由输入层、卷积层(Conv Layer)、激活函数、池化层(Pooling Layer)、全连接层(FC Layer)和输出层组成,各层协同完成特征提取与分类任务:
-
输入层:接收原始图像数据,通常为三维张量(高度×宽度×通道数),例如RGB彩色图像的通道数为3,灰度图像的通道数为1。
-
卷积层:核心特征提取层,通过多个卷积核对输入图像进行卷积运算,生成特征图(Feature Map)。卷积运算的本质是通过滑动窗口计算局部区域的加权和,权重即卷积核的参数,由模型训练学习得到。
-
激活函数:引入非线性因素,解决线性模型无法拟合复杂数据分布的问题。CNN中常用的激活函数为ReLU(Rectified Linear Unit),其表达式为f(x) = max(0, x),能够有效缓解梯度消失问题,加速训练。
-
池化层:位于卷积层之后,对特征图进行下采样。常用的池化方式有最大池化(Max Pooling)和平均池化(Average Pooling),其中最大池化应用最广泛,即取滑动窗口内的最大值作为输出,能够保留特征的最强响应。
-
全连接层:将池化层输出的高维特征图展平为一维向量,通过全连接操作将特征映射到样本标签空间,为分类任务做准备。
-
输出层:根据任务类型输出结果,图像分类任务中通常使用Softmax激活函数,输出每个类别的概率分布,概率最大的类别即为模型的预测结果。
三、基于CNN的图像分类实践(Python代码实现)
本节将基于TensorFlow/Keras框架,实现一个简单的CNN模型,用于MNIST手写数字数据集的分类任务。MNIST数据集包含60000张训练图像和10000张测试图像,每张图像为28×28的灰度图,共10个类别(0-9)。
3.1 环境准备
首先安装并导入所需的库:
# 安装依赖(若未安装) # pip install tensorflow matplotlib numpy # 导入库 import tensorflow as tf from tensorflow.keras import layers, models import matplotlib.pyplot as plt import numpy as np3.2 数据加载与预处理
加载MNIST数据集,并对数据进行归一化和维度调整:
# 加载MNIST数据集 (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() # 数据预处理:归一化(将像素值从[0,255]映射到[0,1])、调整维度(添加通道数维度) x_train = x_train.reshape((60000, 28, 28, 1)).astype('float32') / 255.0 x_test = x_test.reshape((10000, 28, 28, 1)).astype('float32') / 255.0 # 标签独热编码(适应分类任务的输出格式) y_train = tf.keras.utils.to_categorical(y_train, 10) y_test = tf.keras.utils.to_categorical(y_test, 10) # 查看数据形状 print(f"训练集图像形状:{x_train.shape}") # (60000, 28, 28, 1) print(f"训练集标签形状:{y_train.shape}") # (60000, 10) print(f"测试集图像形状:{x_test.shape}") # (10000, 28, 28, 1) print(f"测试集标签形状:{y_test.shape}") # (10000, 10)3.3 构建CNN模型
构建包含2个卷积块(卷积层+ReLU+池化层)和2个全连接层的CNN模型:
def build_cnn_model(): # 初始化序贯模型 model = models.Sequential() # 第一个卷积块:16个3×3卷积核,步长1,填充方式为same(输出维度与输入一致) model.add(layers.Conv2D(16, (3, 3), activation='relu', input_shape=(28, 28, 1), padding='same')) # 最大池化:2×2池化窗口,步长2 model.add(layers.MaxPooling2D((2, 2), strides=2)) # 第二个卷积块:32个3×3卷积核 model.add(layers.Conv2D(32, (3, 3), activation='relu', padding='same')) model.add(layers.MaxPooling2D((2, 2), strides=2)) # 展平层:将特征图转换为一维向量 model.add(layers.Flatten()) # 全连接层:128个神经元,ReLU激活 model.add(layers.Dense(128, activation='relu')) # 输出层:10个神经元(对应10个类别),Softmax激活 model.add(layers.Dense(10, activation='softmax')) return model # 创建模型实例 cnn_model = build_cnn_model() # 查看模型结构 cnn_model.summary()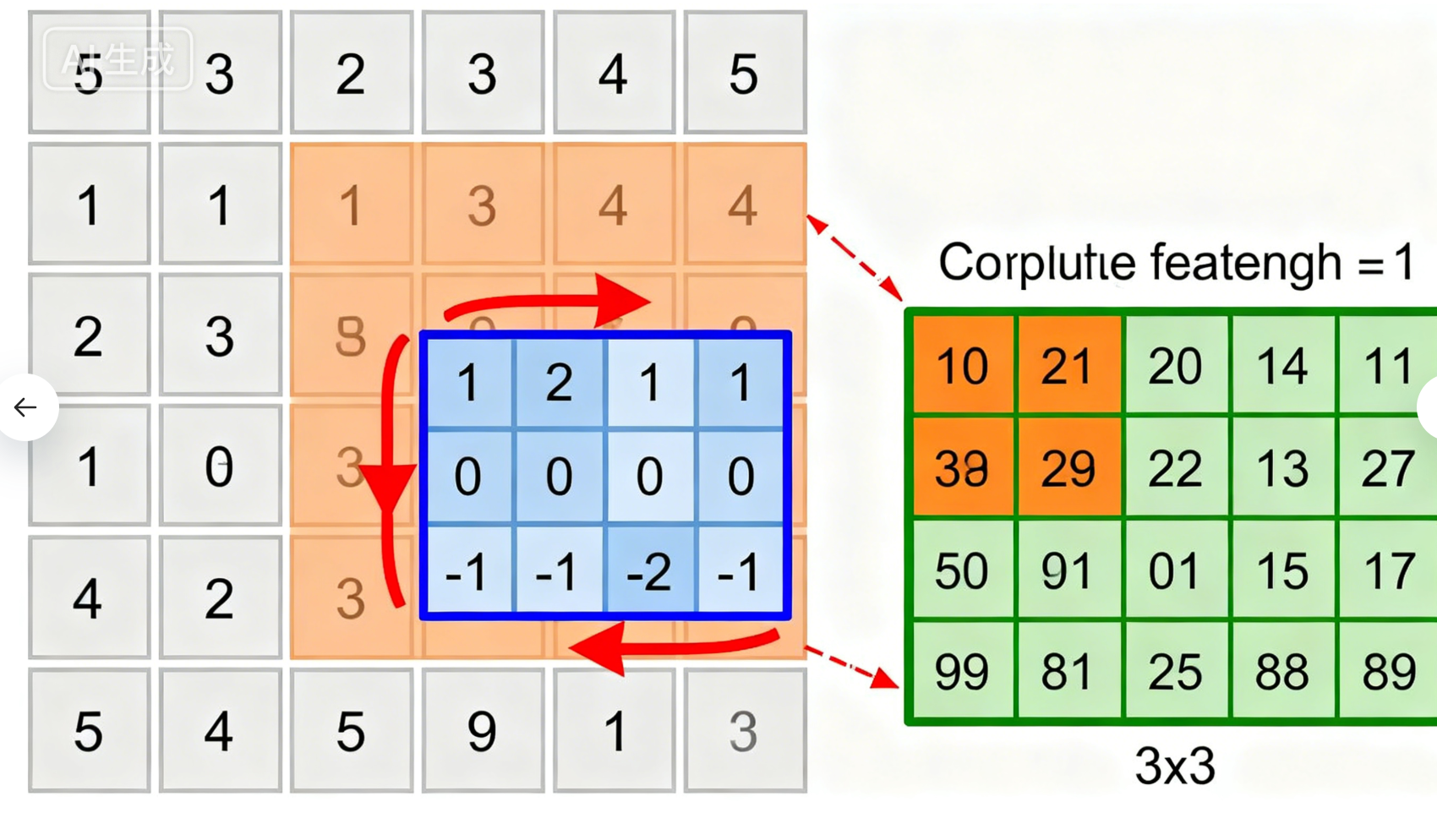
模型结构输出说明:第一个卷积层输入为28×28×1,使用16个3×3卷积核,输出特征图维度为28×28×16;经过2×2最大池化后,维度变为14×14×16。第二个卷积层输出14×14×32,池化后变为7×7×32。展平层将7×7×32的特征图转换为1568维的向量,最终通过全连接层映射到10个类别的概率分布。
3.4 模型编译与训练
配置优化器、损失函数和评估指标,然后对模型进行训练:
# 编译模型:Adam优化器,交叉熵损失函数(多分类任务),评估指标为准确率 cnn_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # 训练模型:批量大小32,训练5个epoch,使用10%的训练集作为验证集 history = cnn_model.fit(x_train, y_train, batch_size=32, epochs=5, validation_split=0.1) # 在测试集上评估模型性能 test_loss, test_acc = cnn_model.evaluate(x_test, y_test, verbose=2) print(f"\n测试集准确率:{test_acc:.4f}") print(f"测试集损失:{test_loss:.4f}")
训练过程中,模型会通过反向传播不断调整卷积核和全连接层的参数,最小化损失函数。通常训练5个epoch后,测试集准确率可达到98%以上,证明模型具有良好的分类能力。
3.5 训练结果可视化
绘制训练过程中的准确率和损失变化曲线,直观观察模型的训练效果:
def plot_training_history(history): # 提取训练数据 acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(len(acc)) # 创建画布 plt.figure(figsize=(12, 4)) # 绘制准确率曲线 plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='训练准确率') plt.plot(epochs_range, val_acc, label='验证准确率') plt.xlabel('Epoch') plt.ylabel('准确率') plt.legend(loc='lower right') plt.title('训练与验证准确率') # 绘制损失曲线 plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='训练损失') plt.plot(epochs_range, val_loss, label='验证损失') plt.xlabel('Epoch') plt.ylabel('损失') plt.legend(loc='upper right') plt.title('训练与验证损失') # 显示图像 plt.tight_layout() plt.show() # 调用函数绘制训练历史 plot_training_history(history)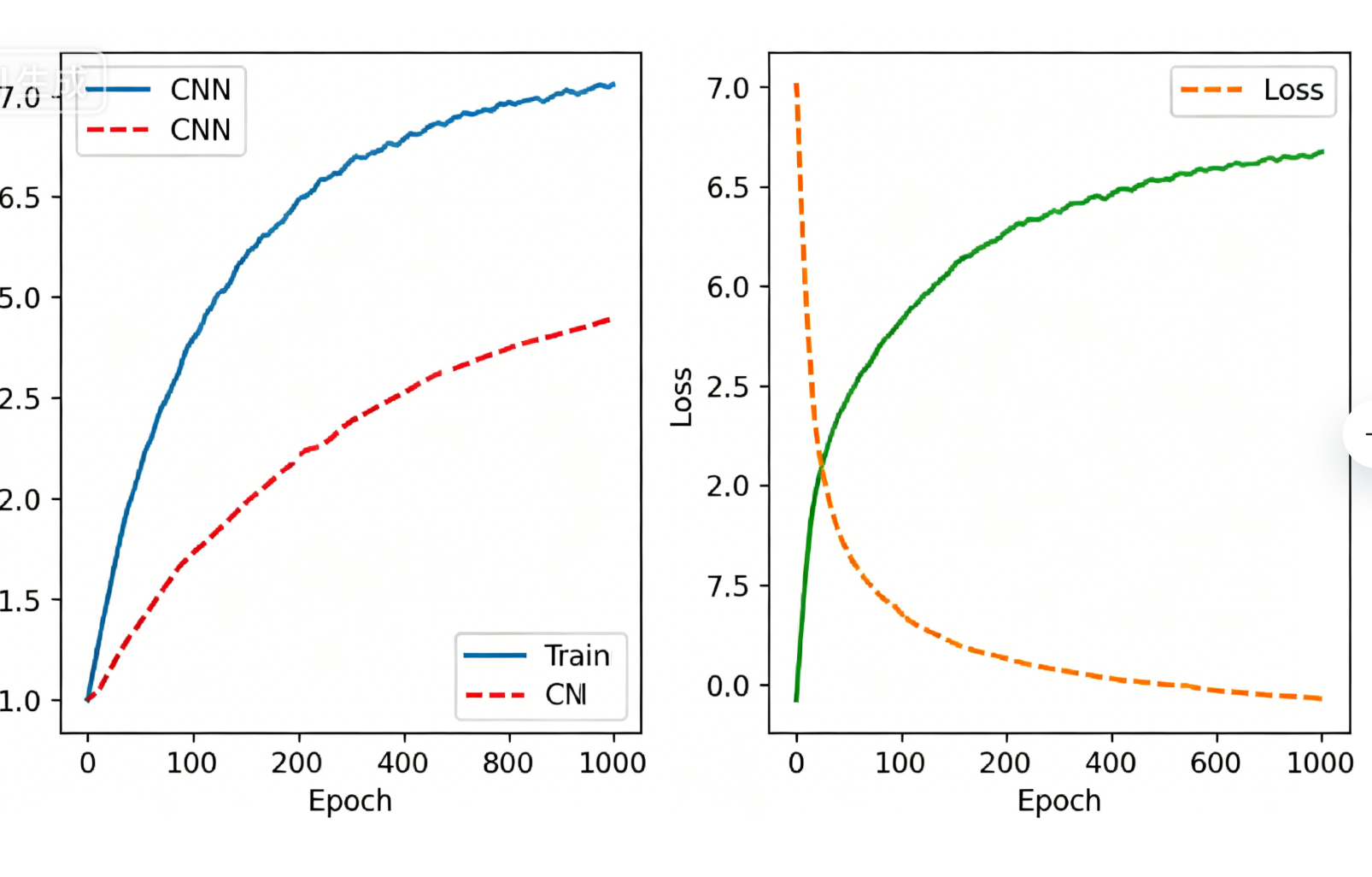
通过可视化曲线可以观察到:随着epoch的增加,训练准确率逐渐上升,训练损失逐渐下降;若验证准确率和训练准确率差距不大,说明模型未出现明显过拟合;若验证准确率下降而训练准确率继续上升,则可能存在过拟合,需要通过增加数据量、添加Dropout层等方式进行优化。
3.6 模型预测示例
使用训练好的模型对测试集中的图像进行预测,并展示预测结果:
# 随机选取5张测试图像进行预测 np.random.seed(42) random_indices = np.random.choice(len(x_test), 5, replace=False) test_images = x_test[random_indices] test_labels = y_test[random_indices] # 模型预测 predictions = cnn_model.predict(test_images) # 获取预测类别(概率最大的索引) predicted_classes = np.argmax(predictions, axis=1) # 获取真实类别 true_classes = np.argmax(test_labels, axis=1) # 展示预测结果 plt.figure(figsize=(15, 3)) for i in range(5): plt.subplot(1, 5, i+1) # 显示图像(去除通道维度) plt.imshow(test_images[i].reshape(28, 28), cmap='gray') plt.axis('off') # 标注预测结果和真实结果 plt.title(f'预测:{predicted_classes[i]}\n真实:{true_classes[i]}') plt.show()四、CNN的优化与拓展
上述实现的是基础CNN模型,在实际应用中,为了进一步提升模型性能,可采用以下优化策略和拓展方向:
-
增加网络深度:通过堆叠更多的卷积层,提升模型对复杂特征的提取能力,例如经典的VGGNet、ResNet等深度CNN模型。
-
添加Dropout层:在全连接层或卷积层后添加Dropout层,随机丢弃部分神经元,抑制过拟合。例如在展平层后添加
layers.Dropout(0.5),表示随机丢弃50%的神经元。 -
数据增强:通过对训练图像进行旋转、平移、缩放、翻转等变换,增加训练数据的多样性,提升模型的泛化能力。Keras中可通过
tf.keras.preprocessing.image.ImageDataGenerator实现数据增强。 -
使用批归一化(Batch Normalization):在卷积层或全连接层后添加批归一化层,加速模型训练,缓解梯度消失问题,提升模型稳定性。例如
layers.BatchNormalization()。 -
优化超参数:调整卷积核数量、大小、步长、池化方式、学习率、批量大小等超参数,找到最优的模型配置。
五、总结
卷积神经网络通过卷积、池化等核心操作,高效解决了图像等高维度数据的特征提取问题,是计算机视觉领域的核心技术之一。本文从CNN的基本原理和核心结构出发,结合MNIST手写数字分类任务,实现了一个完整的CNN模型,包括数据预处理、模型构建、训练、评估和预测等环节。通过实验可以发现,基础CNN模型即可在简单图像分类任务中取得优异的性能,而通过增加网络深度、数据增强、批归一化等优化策略,可进一步提升模型在复杂任务中的表现。
随着深度学习技术的发展,CNN不断涌现出新的结构和算法,例如残差网络(ResNet)解决了深度网络的梯度消失问题,卷积注意力机制(CBAM)增强了模型对关键特征的关注,这些进阶技术进一步推动了CNN在更广泛领域的应用。