LangChain 实战:让 LLM 拥有记忆与结构化输出能力
在稀土掘金社区,大家都在热烈讨论大模型应用落地。其中两个最常见、最棘手的痛点就是:
- LLM 没有记忆:每次调用都像第一次见面,问"你叫什么名字",它永远回答"我是AI助手"......
- LLM 输出不听话:让你返回 JSON,它偏要加解释、前言后语、甚至格式错得离谱。
今天,我们就用 LangChain.js彻底解决这两个问题。通过真实代码 + 底层原理剖析,手把手带你实现:
- 有状态的多轮对话(带记忆)
- 强制结构化 JSON 输出(带运行时校验)
一、为什么 LLM 天生"失忆"?
先来一个最简单的实验:
js
const res1 = await model.invoke('我叫彭于晏,一个演员');
console.log(res1.content); // 助手愉快回应
const res2 = await model.invoke('我叫什么名字');
console.log(res2.content); // "我不知道你叫什么名字......"为什么会这样?
因为所有主流 LLM API(OpenAI、DeepSeek、Claude 等)都是无状态的,就像普通的 HTTP 请求一样:
- 你发一个请求 → 模型处理 → 返回响应
- 下一次请求 → 模型完全不记得上一次发生了什么
这就像你去饭店点菜,每次都要重新自我介绍:"你好,我是彭于晏,今天想吃麻辣烫"......服务员永远一脸茫然。
传统解决方案:手动维护消息历史
最原始的做法是自己维护一个 messages 数组:
js
let messages = [
{ role: "user", content: "我叫彭于晏,一个演员" },
{ role: "assistant", content: "好的,彭于晏先生!" },
{ role: "user", content: "我叫什么名字?" }
];
await model.invoke(messages); // 这次就能答对了这确实能工作,但问题很快暴露:
- 对话越长,messages 越长 → Token 消耗雪球式增长
- 每次都要手动拼接历史,代码丑陋且容易出错
- 多用户场景?需要为每个用户维护一个消息列表,复杂度爆炸
这时候,LangChain 登场了。
二、LangChain 如何优雅实现"记忆"?
先看完整代码

javascript
import { ChatDeepSeek } from "@langchain/deepseek";
import { ChatPromptTemplate } from "@langchain/core/prompts";
//带上历史记录的可运行对象
import { RunnableWithMessageHistory } from "@langchain/core/runnables";
import 'dotenv/config';
//存在内存之中
import { InMemoryChatMessageHistory } from "@langchain/core/chat_history";
const model = new ChatDeepSeek({
model:'deepseek-chat',
temperature:0
});
//chat 模式 数组
const prompt = ChatPromptTemplate.fromMessages([
['system',"你是一个有记忆的助手"],
['placeholder',"{history}"],
['human',"{input}"]
] )
const runnable = prompt
.pipe((input)=>{// debug 节点
console.log('>>>最终传给模型的信息(prompt 内存)');
console.log(input);
return input
})
.pipe(model);
//对话历史实例
const messageHistory = new InMemoryChatMessageHistory();
const chain = new RunnableWithMessageHistory({
runnable,
getMessageHistory:async ()=> messageHistory,
inputMessagesKey:'input' ,
historyMessagesKey:'history'
})
const res1 = await chain.invoke({
input:'我叫彭于晏,一个演员',
},
{
configurable:{
sessionId:'makefriend'
}
}
)
console.log(res1.content);
const res2 = await chain.invoke({
input:'我叫什么名字',
},
{
configurable:{
sessionId:'makefriend'
}
}
)
console.log(res2.content);
带记忆的链
JavaScript
dart
const chain = new RunnableWithMessageHistory({
runnable, // ①
getMessageHistory: async () => messageHistory, // ②
inputMessagesKey: 'input', // ③
historyMessagesKey: 'history' // ④
})这四个参数就是整个记忆机制的命脉,缺一个都不行。下面我详细解释每个参数的作用、为什么需要它、底层到底是怎么工作的。
① runnable: 你的"核心处理链"是什么?
作用:这是你要"加记忆"的那条原始链,也就是不带记忆时的完整处理流程。
在代码中:
JavaScript
ini
const runnable = prompt
.pipe(debug节点)
.pipe(model);它本质上是一个 Runnable 对象,负责把输入 → 处理 → 输出(即:把 {input, history} 格式化成消息列表 → 传给模型 → 返回回复)。
为什么需要它? RunnableWithMessageHistory 本身不负责业务逻辑,它只是一个"包装器"(wrapper)。它要包装的对象就是这个 runnable------它会自动在每次调用前,后对 runnable 的输入和输出做增强(注入历史 + 保存新消息)。
底层逻辑: 当你调用 chain.invoke(...) 时,实际上是 RunnableWithMessageHistory 先接管请求,改造输入后再调用 runnable.invoke(...),最后再处理输出。
② getMessageHistory: 如何获取/存储当前会话的历史?
作用:一个异步函数,每次调用时根据会话 ID 返回对应的聊天历史对象。
JavaScript
vbnet
getMessageHistory: async () => messageHistory这里用了同一个 InMemoryChatMessageHistory() 实例,相当于所有 sessionId 共用一个历史。
真实项目中应该怎么写?
JavaScript
csharp
// 推荐:用 Map 存储多个会话的历史
const store = new Map<string, InMemoryChatMessageHistory>();
const chain = new RunnableWithMessageHistory({
// ...
getMessageHistory: async (sessionId: string) => {
if (!store.has(sessionId)) {
store.set(sessionId, new InMemoryChatMessageHistory());
}
return store.get(sessionId)!;
},
})为什么是 async? 因为生产环境你可能要从 Redis、MongoDB、MySQL 等外部存储读取历史,必须是异步操作。
每次 invoke 时发生了什么?
- 你传了 configurable: { sessionId: 'makefriend' }
- LangChain 自动从 getMessageHistory('makefriend') 拿到历史对象
- 取出里面的所有历史消息(AIMessage / HumanMessage 列表)
③ inputMessagesKey: 'input'
作用 :告诉 LangChain,"你每次 invoke 传进来的对象里,哪一个 key 是当前用户的新输入"。
你调用时是这样写的:
JavaScript
css
chain.invoke({
input: '我叫彭于晏,一个演员'
}, { configurable: { sessionId: 'makefriend' } })所以这里必须写 'input'。
它干了三件事:
- 注入到 Prompt:把这个值填充到 prompt 里的 {input} 占位符(对应 'human', "{input}")
- 转为 HumanMessage:内部会把 input 的值包装成一条 HumanMessage
- 保存到历史:调用结束后,这条 HumanMessage + 模型的回复(AIMessage)会被自动添加到 messageHistory 中
如果写错会怎样? 比如你写成 inputMessagesKey: 'question',但 invoke 时传的是 { input: '...' } → 报错:找不到当前输入消息。
④ historyMessagesKey: 'history'
作用:告诉 LangChain,"我要把历史消息列表注入到 runnable 的输入对象里,用哪个 key 名?"
它和 prompt 模板里的 'placeholder', "{history}" 必须完全对应。 我们一步步看 LangChain 是怎么把输入变成最终发给模型的消息列表的。
底层执行流程是这样的:
每次 chain.invoke 时,LangChain 会构造一个新输入对象:
JavaScript
css
{
input: "用户当前说的话", // 来自 inputMessagesKey
history: [ // 来自 getMessageHistory 取出的历史
HumanMessage("我叫彭于晏,一个演员"),
AIMessage("好的,记住了!"),
// ... 更多历史
]
}然后把这个对象传给你的 runnable(也就是 prompt → model)。
你的 prompt 正好有:
JavaScript
less
['placeholder', "{history}"], // 会把整个历史消息列表塞进去
['human', "{input}"]所以模型看到的完整消息列表就是:
text
css
System: 你是一个有记忆的助手
... 所有历史消息(从 {history} 注入)
Human: 我叫什么名字(从 {input} 注入)完美闭环!
如果 key 不匹配会怎样? 比如你写 historyMessagesKey: 'chatHistory',但 prompt 用的是 {history} → 历史根本不会注入,模型还是失忆。
完整执行时序图
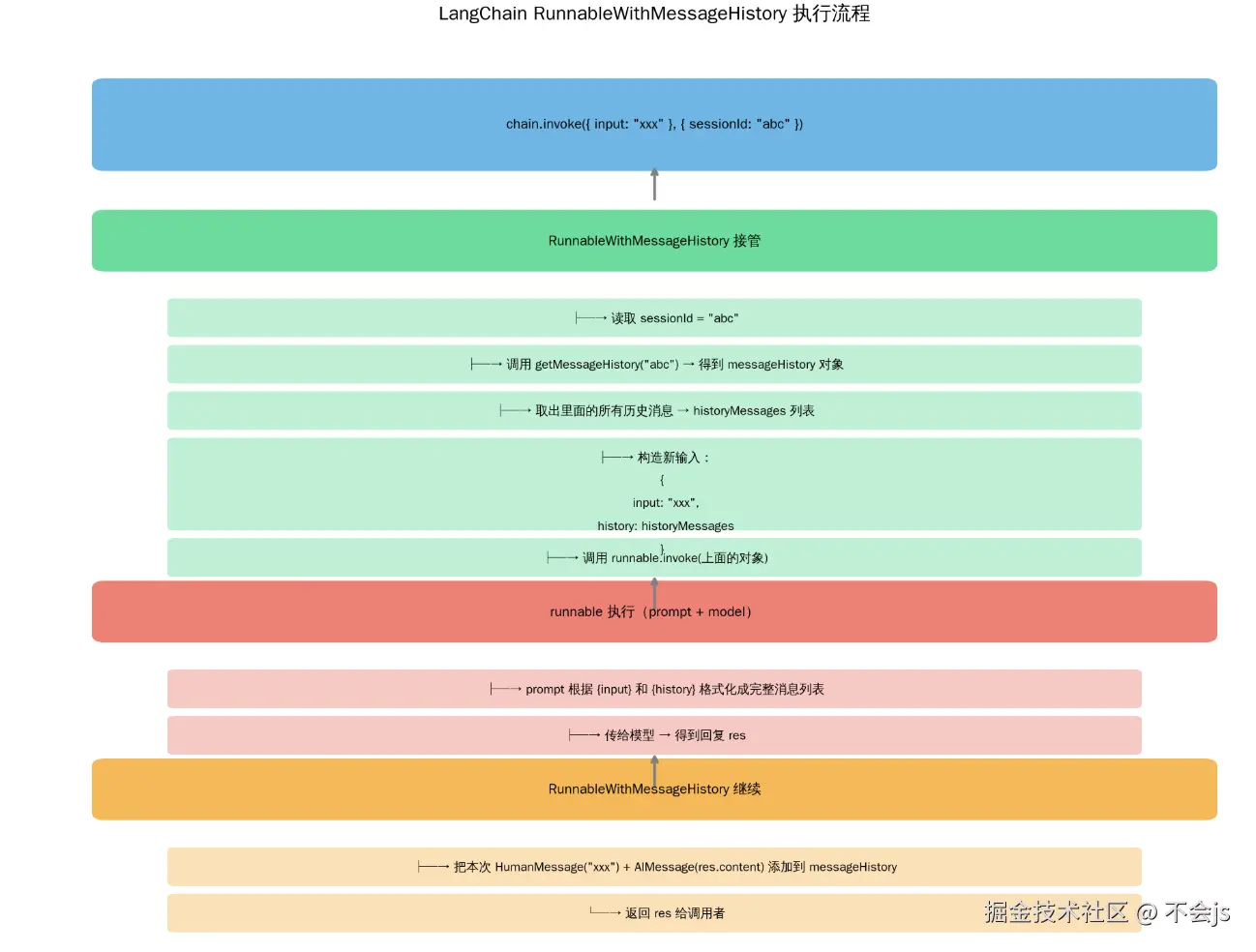 这就是为什么第二次问"我叫什么名字"时,模型能答对------历史已经被正确注入并保存了。
这就是为什么第二次问"我叫什么名字"时,模型能答对------历史已经被正确注入并保存了。
易错点大汇总(必看!)
- sessionId 没传或传错 → 每次都是新历史,永远失忆
- inputMessagesKey / historyMessagesKey 和 prompt 不匹配 → 历史不注入或当前输入丢失
- getMessageHistory 没根据 sessionId 分隔存储 → 多用户串历史(演示代码的坑)
- 用了 InMemoryChatMessageHistory 但没考虑服务重启 → 重启后记忆全丢(生产必须换持久化存储)
- prompt 没用 MessagesPlaceholder(即 placeholder) → 历史不会正确展开成多条消息
我们来深入了解一下placeholder
情况1:正确使用 MessagesPlaceholder(placeholder)
输入对象:
JavaScript
css
{
input: "我叫什么名字",
history: [
HumanMessage("我叫彭于晏,一个演员"),
AIMessage("好的,记住了!你好彭于晏!")
]
}经过 ChatPromptTemplate 处理后,最终发给模型的消息数组是:
JavaScript
arduino
[
{ role: "system", content: "你是一个有记忆的助手" },
{ role: "human", content: "我叫彭于晏,一个演员" }, // 来自 history 展开
{ role: "assistant", content: "好的,记住了!你好彭于晏!" }, // 来自 history 展开
{ role: "human", content: "我叫什么名字" } // 来自 {input}
]注意:历史消息被一条一条展开,每一轮的 role 都完整保留!
模型看到的是一个完整的多轮对话上下文,自然就能"记住"你叫彭于晏。
情况2:错误地用普通字符串替换 {history}
同样的输入对象:
JavaScript
css
{
input: "我叫什么名字",
history: [ ... 两条消息对象 ... ]
}但因为你用了普通字符串模板,LangChain 在填充 {history} 时,会调用 .toString() 或直接序列化这个消息数组。
结果可能是:
text
css
历史对话:[{"type":"human","content":"我叫彭于晏,一个演员"},{"type":"assistant","content":"好的,记住了!你好彭于晏!"}]最终发给模型的消息数组变成:
JavaScript
go
[
{ role: "system", content: "你是一个有记忆的助手" },
{ role: "human", content: "历史对话:[{"type":"human",...}]" }, // 一大坨 JSON 字符串!
{ role: "human", content: "我叫什么名字" }
]这时候模型看到的上下文是:
text
css
系统:你是一个有记忆的助手
用户:历史对话:[{"type":"human","content":"我叫彭于晏,一个演员"}, ... ]
用户:我叫什么名字模型根本不知道这坨 JSON 字符串是上一轮对话!它只会觉得你在说一段奇怪的代码,或者直接忽略。
结果:完全失忆。
总结:这四个参数的"灵魂配合"
| 参数 | 对应位置 | 作用本质 |
|---|---|---|
| runnable | 你的核心链 | 被包装的对象 |
| getMessageHistory | 外部存储 / Map | 读写历史的地方 |
| inputMessagesKey | invoke 时传的 key + prompt | 当前用户输入的标识与注入点 |
| historyMessagesKey | prompt 中的 placeholder | 历史消息列表的注入点 |
它们就像四个齿轮,缺一不可,咬合得天衣无缝,才实现了"有状态的 LLM 调用"。
三、为什么 LLM 输出 JSON 这么不靠谱?
另一个经典场景:你想让模型返回结构化数据。
最 naive 的写法:
js
prompt = "请用 JSON 格式返回前端概念信息,包含 name、core、useCase、difficulty 字段。话题:Promise"结果往往是:
json
好的,以下是 Promise 的信息:
{
"name": "Promise",
"core": "...",
// ... 可能缺字段、多字段、键名写错
}
如果你有其他问题欢迎继续提问!问题出在:
- 模型是"生成型"的,不是"服从型"的
- 它更倾向于"自然对话",而不是严格遵守格式
- 即使提示写得再严,也偶尔会"叛变"
传统解决方案:正则 + 手动解析
js
const jsonStr = response.match(/\{.*\}/s)[0];
JSON.parse(jsonStr); // 祈祷别出错风险极高,一出错整个链崩。
四、LangChain + Zod:强制结构化输出的终极方案
来看最佳实践:
js
const FrontendConceptSchema = z.object({
name: z.string().describe("概念名称"),
core: z.string().describe("核心要点"),
useCase: z.array(z.string()).describe("常见使用场景"),
difficulty: z.enum(['简单','中等','复杂']).describe("学习难度")
});
const jsonParser = new JsonOutputParser(FrontendConceptSchema);Zod 是什么?为什么这么强?
Zod 是一个 TypeScript 第一的运行时类型校验库。
你用代码定义数据契约:
ts
type FrontendConcept = z.infer<typeof FrontendConceptSchema>;
// 自动推导为:
interface FrontendConcept {
name: string;
core: string;
useCase: string[];
difficulty: '简单' | '中等' | '复杂';
}完整链路是怎么工作的?
js
const chain = prompt.pipe(model).pipe(jsonParser);执行流程:
prompt中插入jsonParser.getFormatInstructions()- 自动生成一段精确的 JSON 格式说明,注入到
{format_instructions}
- 自动生成一段精确的 JSON 格式说明,注入到
- 模型看到严格指令,更大概率输出正确 JSON
- 模型输出文本 → 进入
JsonOutputParser - 解析器做两件事:
JSON.parse()转对象schema.parse()用 Zod 严格校验
- 任意一项失败 → 抛错(你可以 catch 重试)
实际生成的 format_instructions(自动!)
text
The output should be a valid JSON formatted according to the following schema:
{
"name": "string",
"core": "string",
"useCase": ["string"],
"difficulty": "enum(['简单', '中等', '复杂'])"
}
Only return the JSON object, no additional text.为什么这比手动写 prompt 强 100 倍?
| 项目 | 手动写 prompt | Zod + JsonOutputParser |
|---|---|---|
| 格式说明一致性 | 容易写错、漏改 | 自动生成,永远正确 |
| 修改字段成本 | 要改多处 prompt | 只改一处 Schema |
| 运行时安全 | 无校验,祈祷模型听话 | 严格 parse,错就报错 |
| TypeScript 支持 | res 是 any | 自动推导精确类型,IDE 提示完美 |
| 复杂结构支持 | 嵌套、联合类型很难描述 | 原生支持 transform、refine 等 |
| 可复用性 | 每个链都要复制 prompt | Schema 定义一次,全局复用 |
真实案例 :你后来想加 relatedConcepts: string[] 字段
→ 只需改一行 Zod,其他全部自动同步!
永远记得:Zod Schema 的 key 名必须和提示中要求的完全一致!
五、从早期 JS 模块化看现代工程化演进
早期前端的尴尬:
html
<script src="./a.js"></script>
<script>
const p = new Person('张三',18);
p.sayName();
</script>- 全局污染严重
- 依赖顺序必须手动控制
- 没有作用域隔离
这才有了:
- CommonJS(Node.js)
- AMD/CMD(RequireJS)
- 最终 ES6 Modules(
import/export)
LangChain 的设计哲学也是如此:
- 早期:手动拼接 messages、手动解析 JSON
- 现在:模块化、可组合、类型安全、自动管理
这正是现代 AI 工程化的方向。
总结:两个核心能力,缺一不可
| 能力 | 解决方案 | 核心类/工具 | 推荐程度 |
|---|---|---|---|
| 多轮对话记忆 | RunnableWithMessageHistory | InMemoryChatMessageHistory / Redis | ⭐⭐⭐⭐⭐ |
| 结构化输出 | JsonOutputParser + Zod | z.object() + getFormatInstructions() | ⭐⭐⭐⭐⭐ |
掌握了这两招,你的 LLM 应用就从"玩具"升级为"生产级工具":
- 聊天机器人能记住用户
- 数据提取接口稳定可靠
- 前端直接对接类型安全的响应
- 维护成本大幅降低
最后送上一句心得:
大模型很强大,但"强大"不等于"可靠"。
真正的工程能力,是在不可靠的生成模型之上,构建一层可靠的、类型安全的、可维护的系统。
这才是 LangChain 存在的意义。