TL;DR
- 场景:小样本、低维特征的监督分类,用"相似样本投票"快速出结果
- 结论:KNN核心是距离度量+K个邻居投票;特征尺度决定距离可信度,K影响偏差/方差
- 产出:一套可复现实验(葡萄酒二分类)、距离计算/排序/投票流程、KNN函数封装

监督学习算法
KNN/K近邻算法
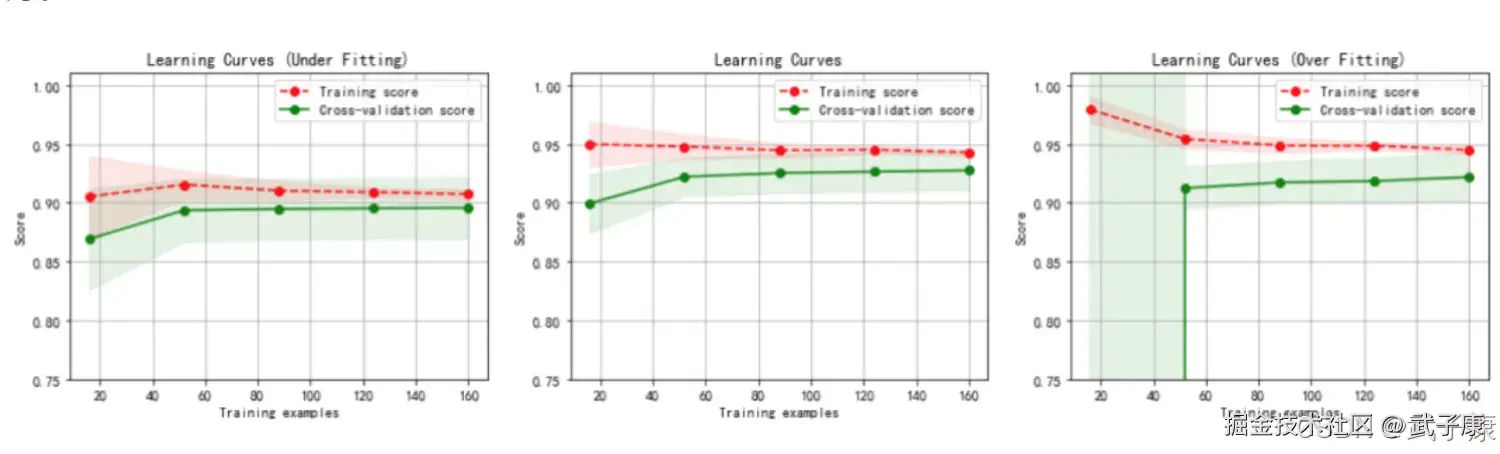
K近邻算法(K-Nearest Neighbors, KNN)的核心思想是基于样本间的距离度量来判断相似性。具体来说,它通过计算待分类样本与训练集中各个样本之间的特征空间距离(常用的距离度量包括欧式距离、曼哈顿距离或余弦相似度等),如果两个样本在特征空间中的距离足够接近,就认为它们具有较高的相似度,很可能属于同一类别。
在实际应用中,仅依靠单个最近邻样本进行分类容易受到噪声和异常值的影响,导致分类结果不稳定。因此KNN算法会选取距离最近的K个样本(即K个最近邻),这些近邻样本构成了待分类样本的局部邻域。算法会统计这些近邻样本的类别标签分布情况(标签代表样本所属的真实类别,如"猫"、"狗"等分类结果),然后采用投票机制:将K个近邻中出现次数最多的类别作为待分类样本的预测结果。
举例来说,在图像分类任务中,假设K=5,待分类图片的5个最近邻中包含3张"猫"和2张"狗"的图片,那么算法就会将该图片分类为"猫"。这种基于局部邻域投票的机制使得KNN算法对噪声数据具有较好的鲁棒性,同时K值的选择(通常通过交叉验证确定)会直接影响算法的分类性能。
实现过程
假设 X_test 待标记的数据样本,X_train 为已标记的数据集。
- 遍历已标记数据集中的所有样本,计算每个样本与待标记的点的距离,并把距离保存在 Distance 数组中。
- 对 Distance 数组进行排序,取距离最近的 K 个点,记为X_knn。
- 在 X_knn 中统计每个类别的个数,即 class0 在 X_knn 中有几个样本,class1 在 X_knn中有几个样本
- 待标记样本的类别,就是在 K_knn 中样本个数最多的那类别。
距离的确定
该算法的【距离】在二维坐标轴就表示两点之间的距离,计算距离的公式有很多。我们常说的欧拉公式,即"欧氏距离",回忆一下,一个平面直角坐标系上,如何计算两点之间的距离?一个立体直角坐标系上,又如何计算两点之间的距离?
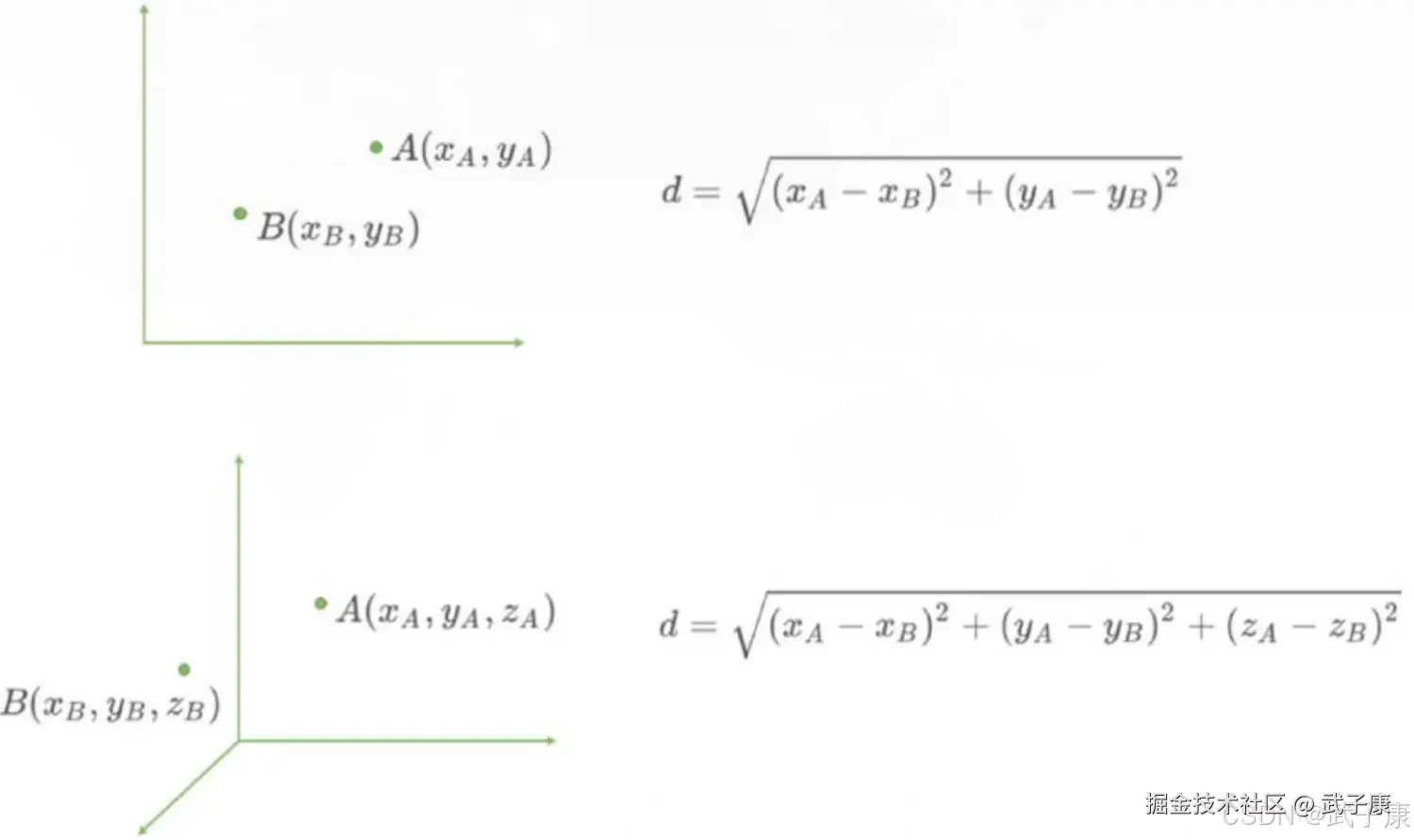
当特征数量有很多个形式多维空间时,再用上述的写法就不方便了,我们换一个写法,用 X 加下角标的方式表示特征维度,则在 N 维空间中,有两个点 A 和B,它们坐标分别为:
 而在机器学习中,坐标轴上的 x1、x2、x3等,正是我们样本上的N 个特征。
而在机器学习中,坐标轴上的 x1、x2、x3等,正是我们样本上的N 个特征。
算法优点
算法参数k(通常称为k近邻算法中的k值)是一个关键的超参数,它决定了在预测时要考虑多少个最近的邻居样本。具体来说:
-
k值的作用机制:
- 当k=1时,模型仅考虑最近的一个样本点,这会使决策边界变得非常复杂
- 随着k值增大,模型会考虑更多邻居的投票结果,使得决策边界趋于平滑
-
k值与模型偏差的关系:
- 较大的k值(如k=15)会使模型偏差增大,因为决策会基于更多样本的平均值
- 这会使模型对个别噪声数据点(如标注错误的样本)的敏感度降低
- 极端情况下,当k接近训练集大小时,模型会简单地预测多数类
-
k值与模型方差的关系:
- 较小的k值(如k=1或3)会使模型方差增大
- 模型容易捕捉到训练数据中的随机波动和噪声
- 在图像分类任务中,过小的k值可能导致模型对像素级别的变化过于敏感
-
参数选择的实践经验:
- 通常从k=5开始尝试,这是经验法则
- 对于特征维度较高的数据(如文本数据),可能需要更大的k值
- 可以通过交叉验证来寻找最优k值,常用方法是绘制k值与准确率的曲线图
- 在sklearn中,可以使用GridSearchCV进行k值调优
-
不同场景下的k值选择:
- 对于噪声较多的数据集(如传感器数据),建议使用较大的k值(7-15)
- 对于清晰可分的数据(如MNIST手写数字),较小的k值(3-5)可能更合适
- 当类别分布不平衡时,k值不宜过小,否则容易受到少数类样本的影响
-
与其他参数的协同作用:
- k值选择还需考虑距离度量方式(欧式距离、曼哈顿距离等)
- 在特征缩放后,k值的效果可能会发生变化
- 加权kNN中,k值的影响会相对减弱
算法变种
变种 1
默认情况下,在计算距离时,权重都是相同的,但实际上可以针对不同的领居指定不同的距离权重,比如距离越近权重越高。 可以通过指定算法的 weights 参数来实现。
变种2
使用一定半径内的点取代距离最近的 k 个点
- 在 scikit-learn 中,RadiusNeighborsClassifier 实现了这种算法的变种
- 当数据采样不均匀时,该算法变种可以获得更好的性能
代码实现
导入相关包
python
# 全部行都能输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
plt.style.use('ggplot')
# plt.figure(figsize=(2,3),dpi=720)执行结果如下: 
构建已经分类好的原始数据集
首先随机设置十个样本表示十杯酒,这里去了部分样本点。 为了方便验证,使用 Python 的字典 dict 构建数据集,然后再将其转换为DataFrame 格式。
python
rowdata = {
'颜色深度': [14.13,13.2,13.16,14.27,13.24,12.07,12.43,11.79,12.37,12.04],
'酒精浓度': [5.64,4.28,5.68,4.80,4.22,2.76,3.94,3.1,2.12,2.6],
'品种': [0,0,0,0,0,1,1,1,1,1]
}
# 0 代表 "黑皮诺",1 代表 "赤霞珠"
wine_data = pd.DataFrame(rowdata)执行结果如下图所示: 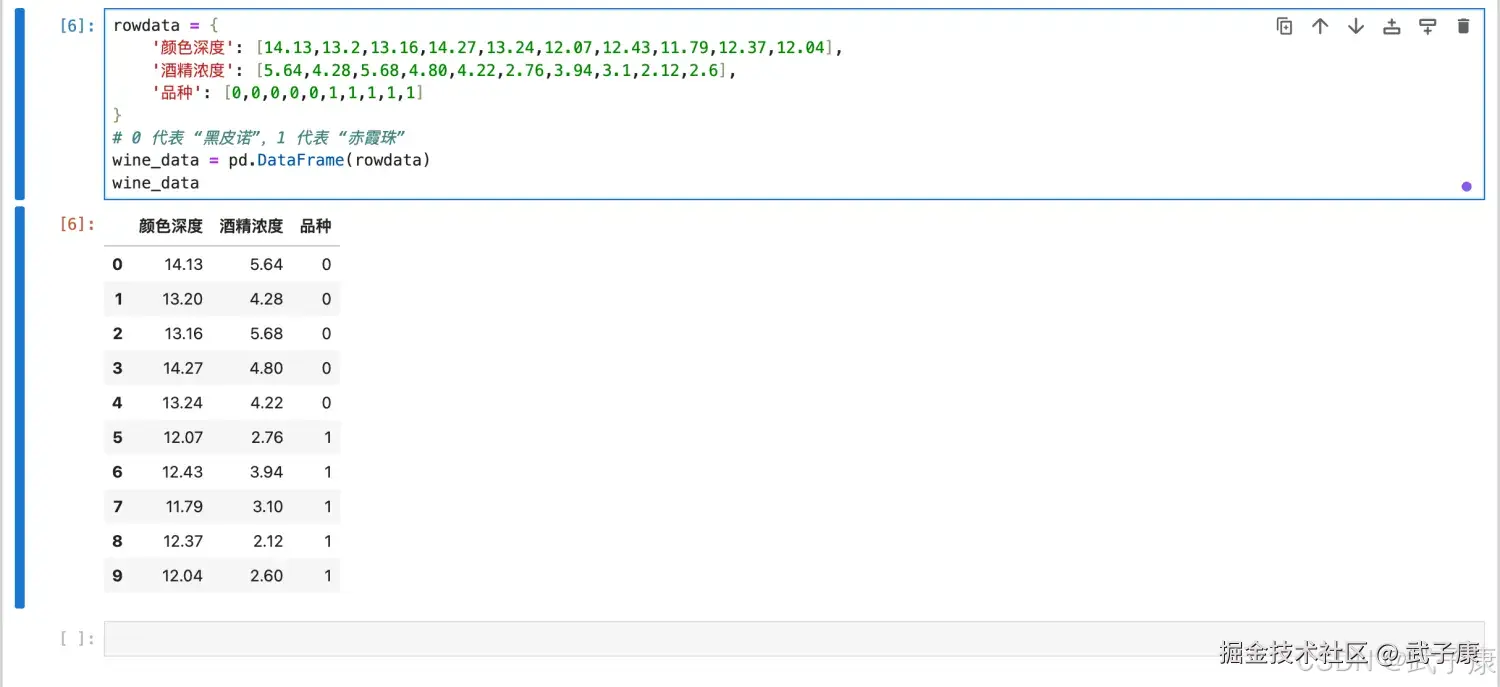 编写代码进行处理:
编写代码进行处理:
python
X = np.array(wine_data.iloc[:,0:2]) #我们把特征(酒的属性)放在X
y = np.array(wine_data.iloc[:,-1]) #把标签(酒的类别)放在Y
#探索数据,假如我们给出新数据[12.03,4.1] ,你能猜出这杯红酒是什么类别么?
new_data = np.array([12.03,4.1])
plt.scatter(X[y==1,0], X[y==1,1], color='red', label='赤霞珠') #画出标签y为1
的、关于"赤霞珠"的散点
plt.scatter(X[y==0,0], X[y==0,1], color='purple', label='黑皮诺') #画出标签y为0
的、关于"黑皮诺"的散点
plt.scatter(new_data[0],new_data[1], color='yellow') # 新数据点
new_data
plt.xlabel('酒精浓度')
plt.ylabel('颜色深度')
plt.legend(loc='lower right')
plt.savefig('葡萄酒样本.png')执行结果如下如下所示: 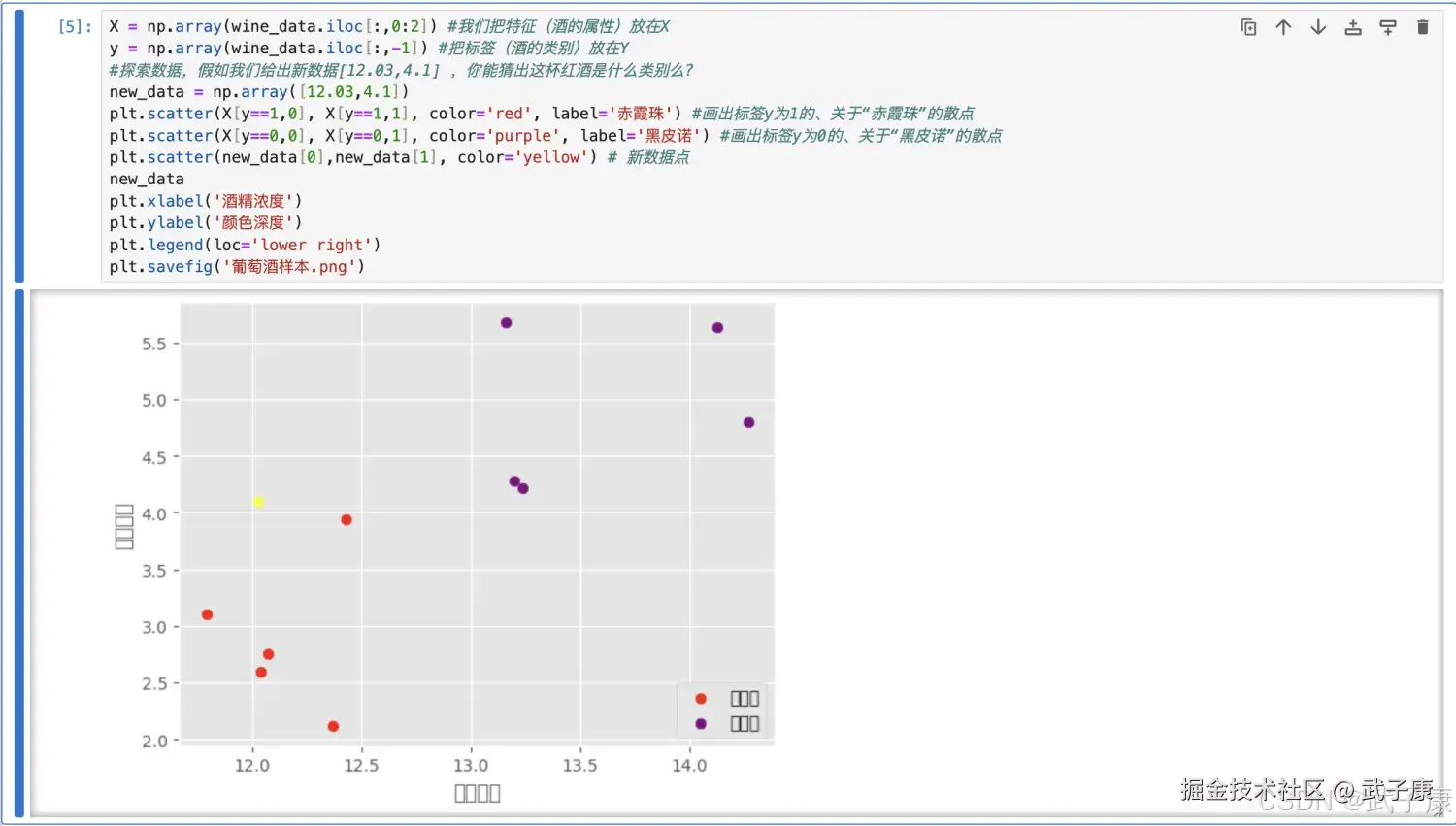
计算已知类别数据集中的点与当前之间的距离
我们使用欧式距离公式,计算新数据点 new_data 与现存的 X 数据集每一个点的距离:
python
from math import sqrt
distance = [sqrt(np.sum((x-new_data)**2)) for x in X ]
distance执行结果如下:
shell
[2.6041505332833594,
1.1837651794169315,
1.9424983912477256,
2.3468276459936295,
1.2159358535712326,
1.3405968819895113,
0.4308131845707605,
1.0283968105745949,
2.0089798406156287,
1.500033332962971]运行结果如下所示: 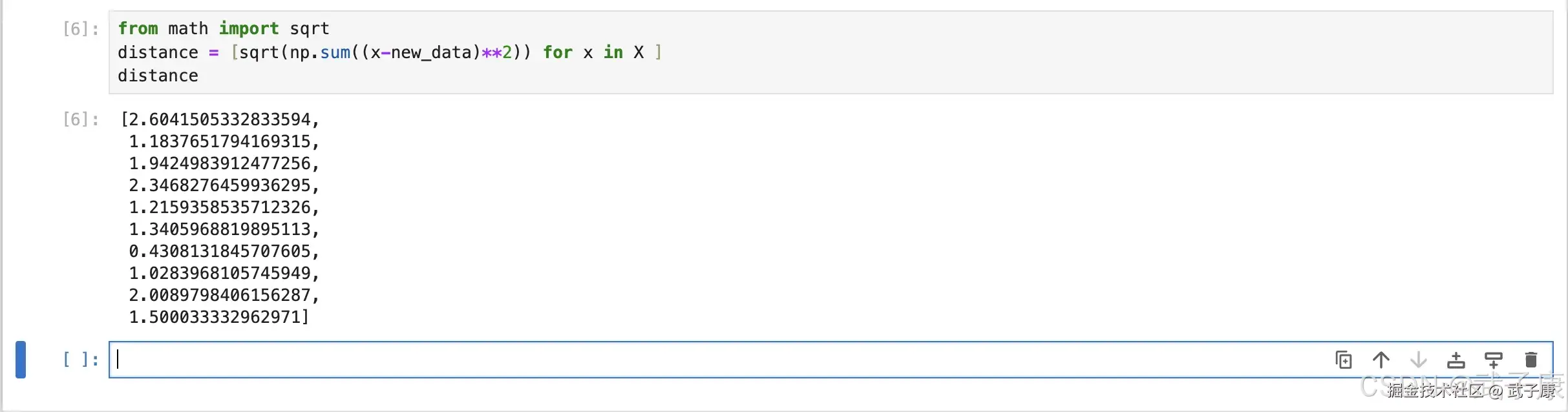
将距离升序排列 选取距离最小的 K 个点
python
sort_dist = np.argsort(distance)
sort_dist执行结果如下所示:  所以,6、7、1 为最近的3个"数据点"的索引值,那么这些索引值对应的原数据的标签是什么?
所以,6、7、1 为最近的3个"数据点"的索引值,那么这些索引值对应的原数据的标签是什么?
python
k = 3
topK = [y[i] for i in sort_dist[:k]]
topK执行结果如下所示: 
确定前k个点所在类别的计数
python
pd.Series(topK).value_counts().index[0]执行结果如下所示:

封装函数
将数据的过程封装成一个函数:
python
def KNN(new_data,dataSet,k):
'''
函数功能:KNN分类器
参数说明:
new_data: 需要预测分类的数据集
dataSet: 已知分类标签的数据集
k: k-近邻算法参数,选择距离最小的k个点
return:
result: 分类结果
'''
from math import sqrt
from collections import Counter
import numpy as np
import pandas as pd
result = []
distance = [sqrt(np.sum((x-new_data)**2)) for x in
np.array(dataSet.iloc[:,0:2])]
sort_dist = np.argsort(distance)
topK = [dataSet.iloc[:,-1][i] for i in sort_dist[:k]]
result.append(pd.Series(topK).value_counts().index[0])
return result测试函数的运行结果:
python
new_data=np.array([12.03,4.1])
k = 3
KNN(new_data,wine_data,k)执行结果如下所示: 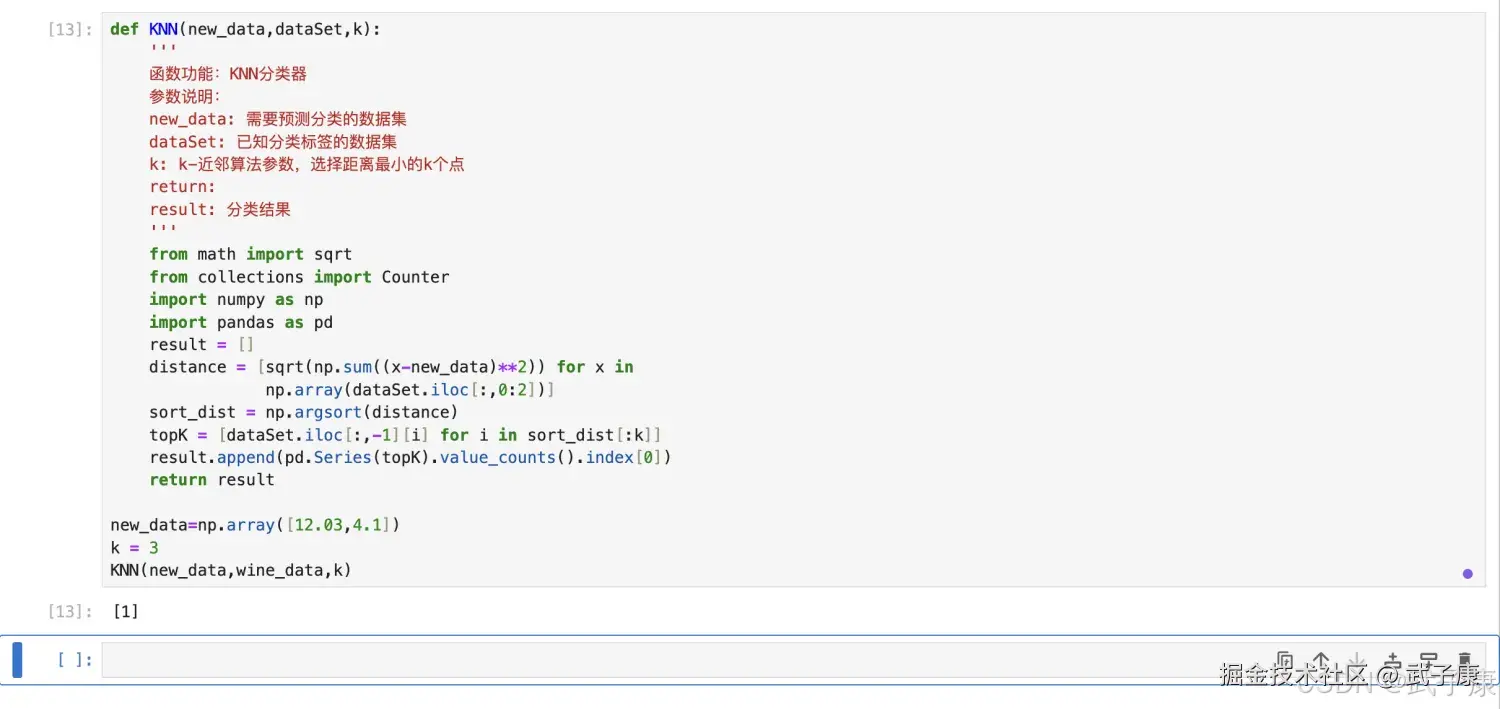
错误速查
| 症状 | 根因 | 定位方法 | 修复方案 |
|---|---|---|---|
| 中文/负号乱码 | 字体未安装或字体名不匹配;axes.unicode_minus未生效 |
查看控制台字体 fallback 警告;图中中文变方块 | 安装/指定可用中文字体(如 SimHei/微软雅黑);保留 plt.rcParams['axes.unicode_minus']=False |
| 散点图坐标轴含义对不上 | X列顺序与 xlabel/ylabel语义不一致 |
对照 wine_data.iloc[:,0:2] 的列顺序与 plt.xlabel/plt.ylabel |
统一"X的第0/1列"与坐标轴标签;或交换 plt.scatter(..., X[...,0], X[...,1]) 的轴含义 |
| 代码运行直接报 SyntaxError | 注释被断行,形成裸文本(如"的、关于...") | 报错行通常在 plt.scatter(... label=...) 附近 |
把断行文字改为 # 注释或移到同一行注释里 |
| Simhei 不生效/报找不到字体 | 字体名大小写或字体不存在;Linux常见无该字体 | matplotlib 日志 findfont/Font family |
改为系统存在字体名;或用字体文件路径加载 |
| 保存图片为空白或缺元素 | savefig 与绘制/显示顺序不当,或画布被清空 |
检查是否在 plt.show() 后保存;是否多次创建 figure |
先绘制完再 plt.savefig(...);必要时显式 plt.figure() 管理画布 |
| KNN 结果不稳定/偏某一类 | K过小/过大;类别不平衡;距离被尺度主导 | 观察不同 K 的预测变化;看特征量纲差异 | 做特征缩放;用交叉验证选 K;必要时改用加权KNN |
| 高维数据效果明显变差 | 距离集中现象(维度灾难),欧氏距离区分度下降 | 维度升高后近邻距离差距变小 | 降维/特征选择;换距离度量;或改用更适合高维的模型 |
| 半径近邻找不到邻居/报空集 | 半径设置不合理、采样不均匀 | 输出邻居数量或检查半径覆盖范围 | 调整 radius;设置回退策略(无邻居时用默认类/扩大半径) |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解