目录
1一致性hash算法和固定hash算法和字符串hash解析区别?
1运维篇-课程介绍

2日志-错误日志

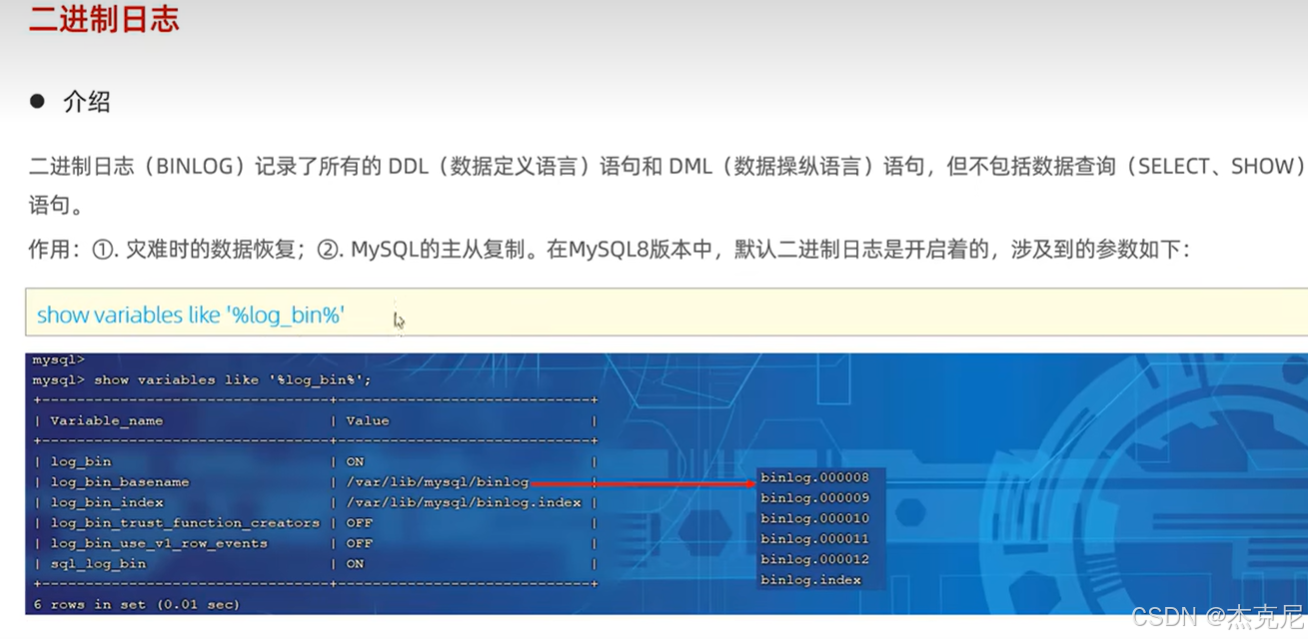
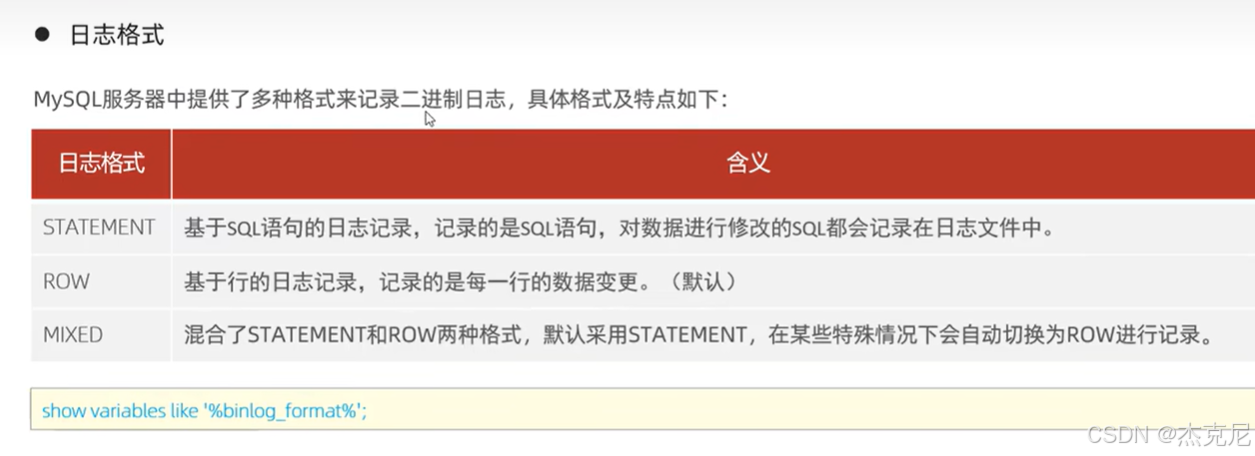
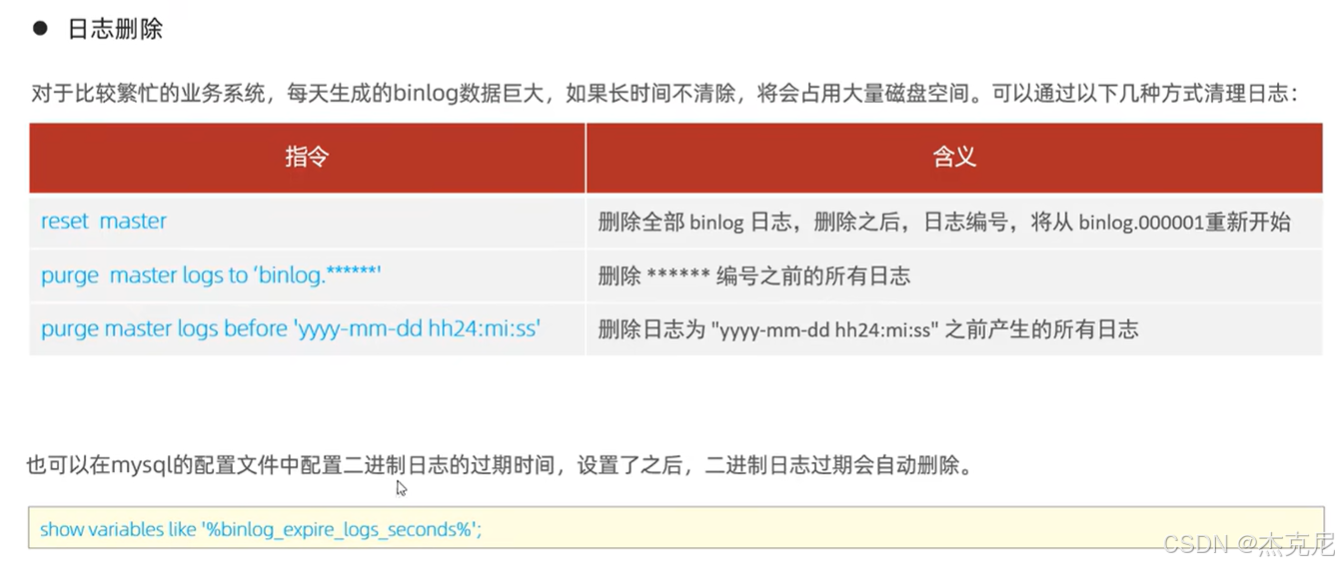
3二进制日志
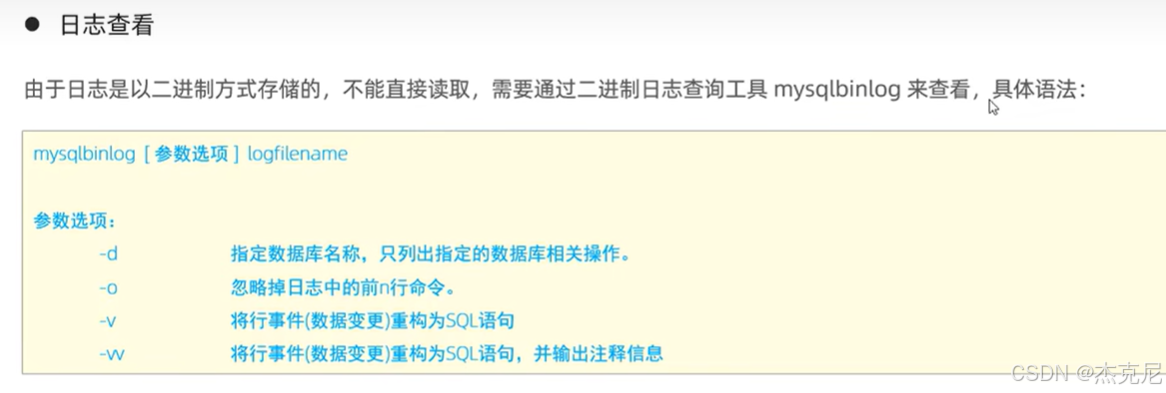
4查询日志
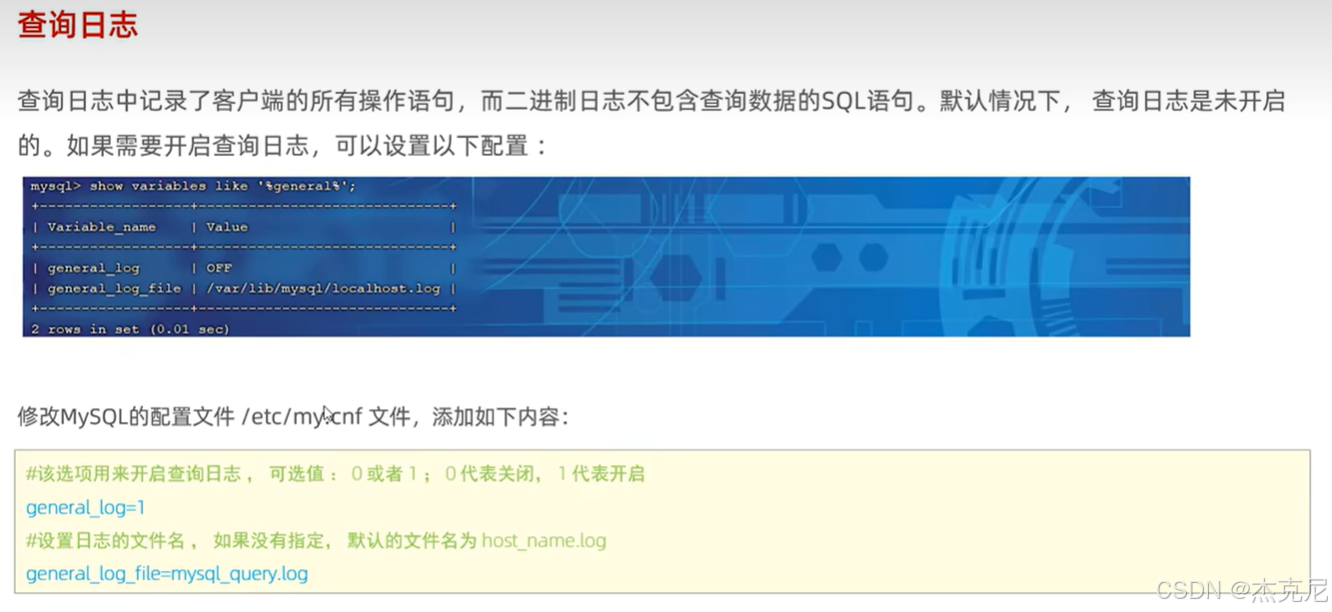
5慢查询日志

问题:
各日志的作用?
错误日志->定位错误
二进制日志->数据恢复
查询日志->所有客户端操作语句(默认没有开启)
慢查询日志->记录执行效率比较低的SQL语句(从而可以精确优化)
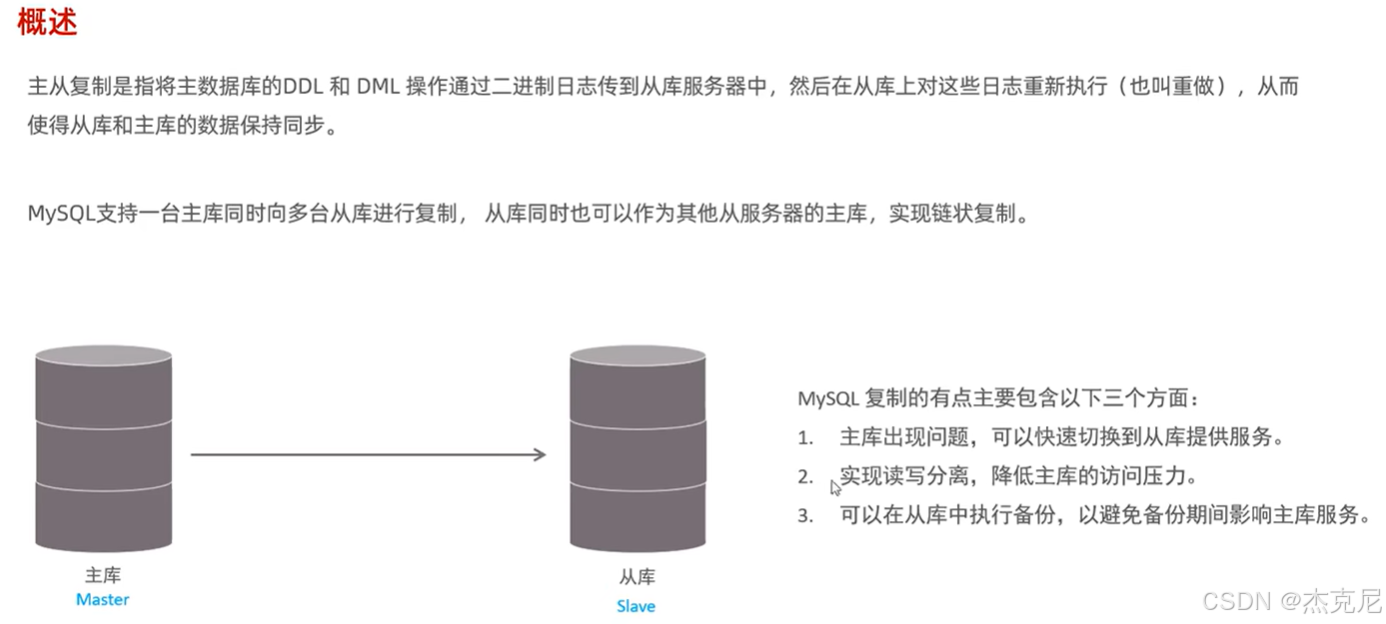
6主从复制-概述

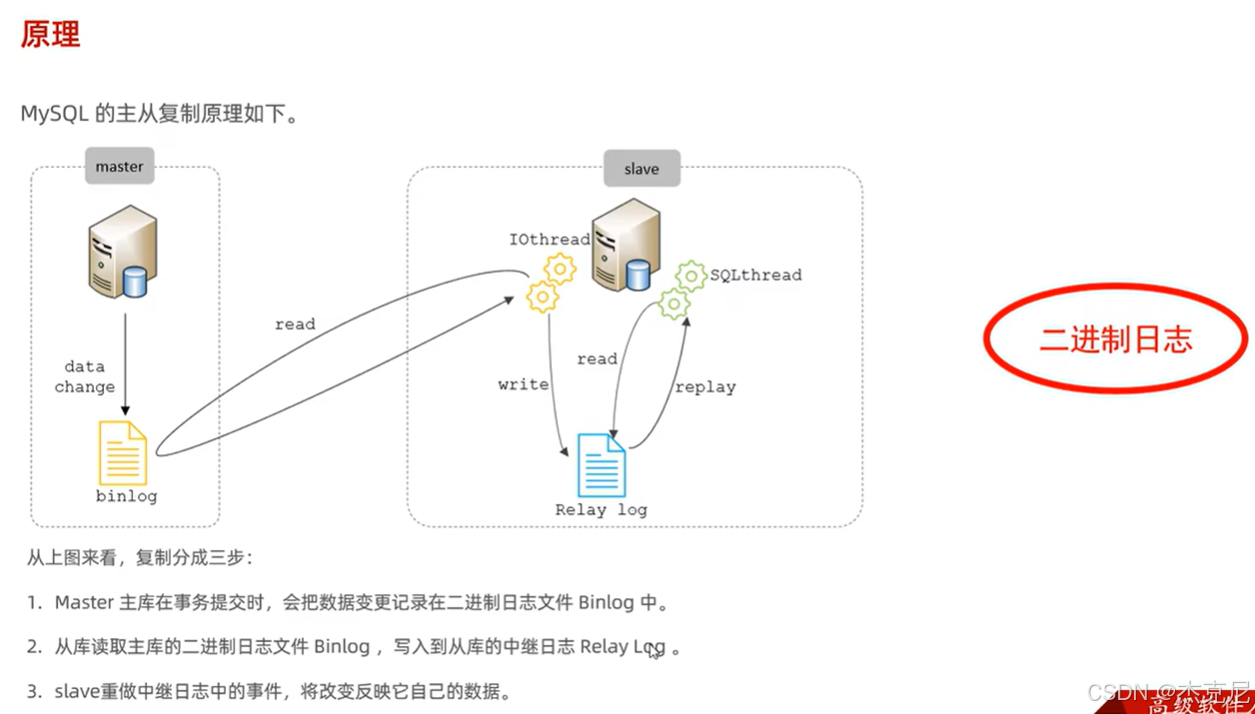
7主从复制-原理
问题:
这主从复制原理第三步是什么意思?

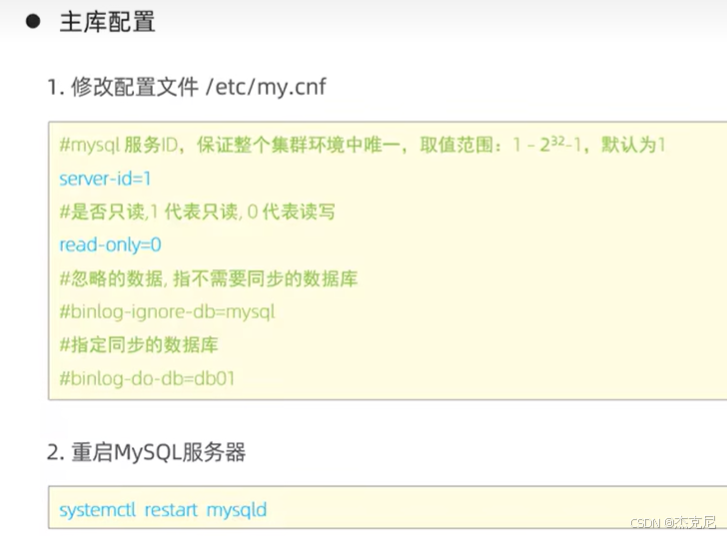
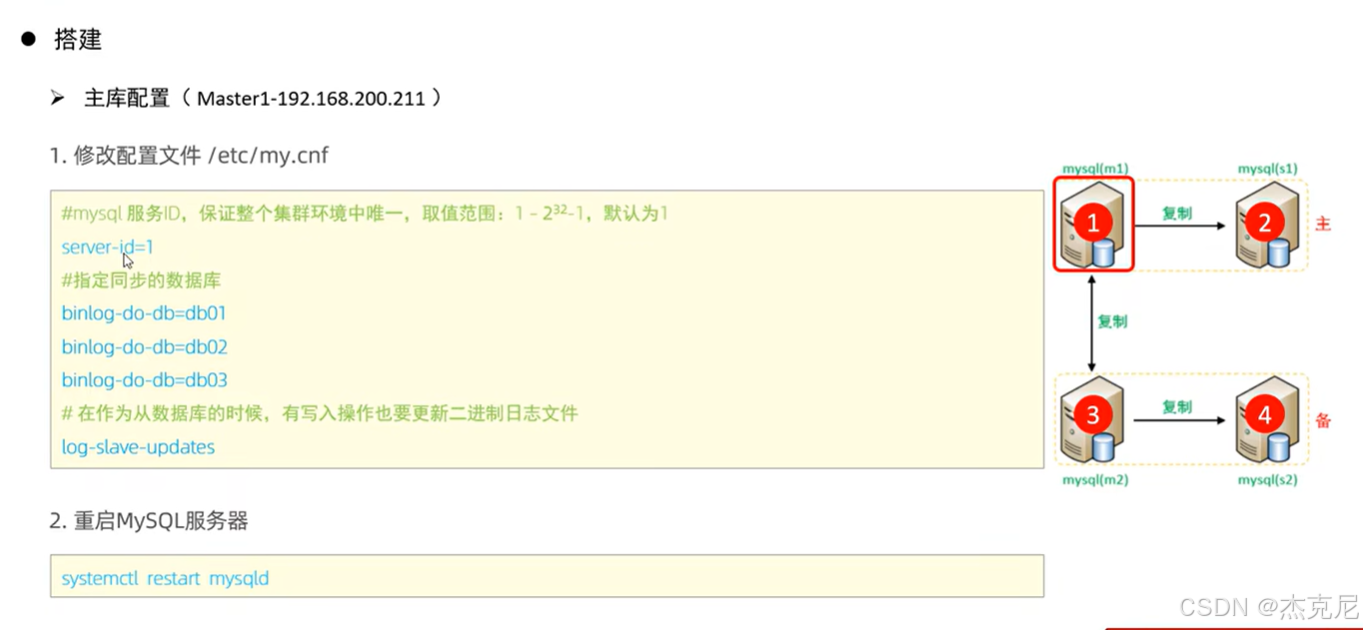
8主从复制-主库配置

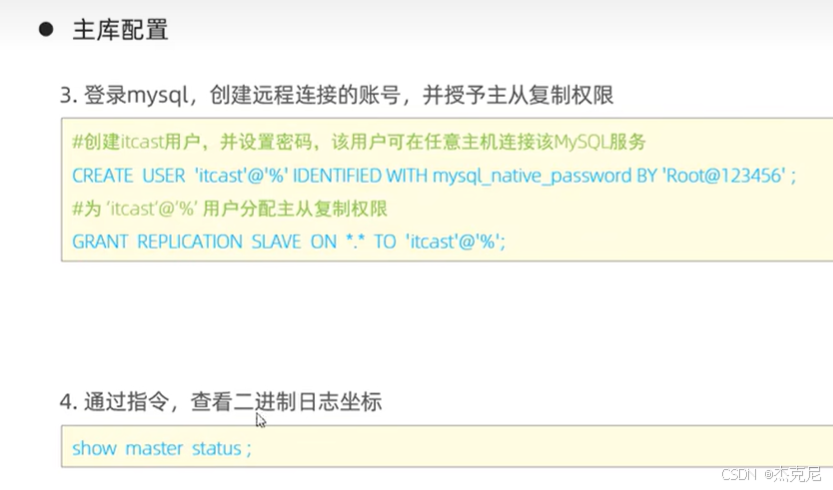

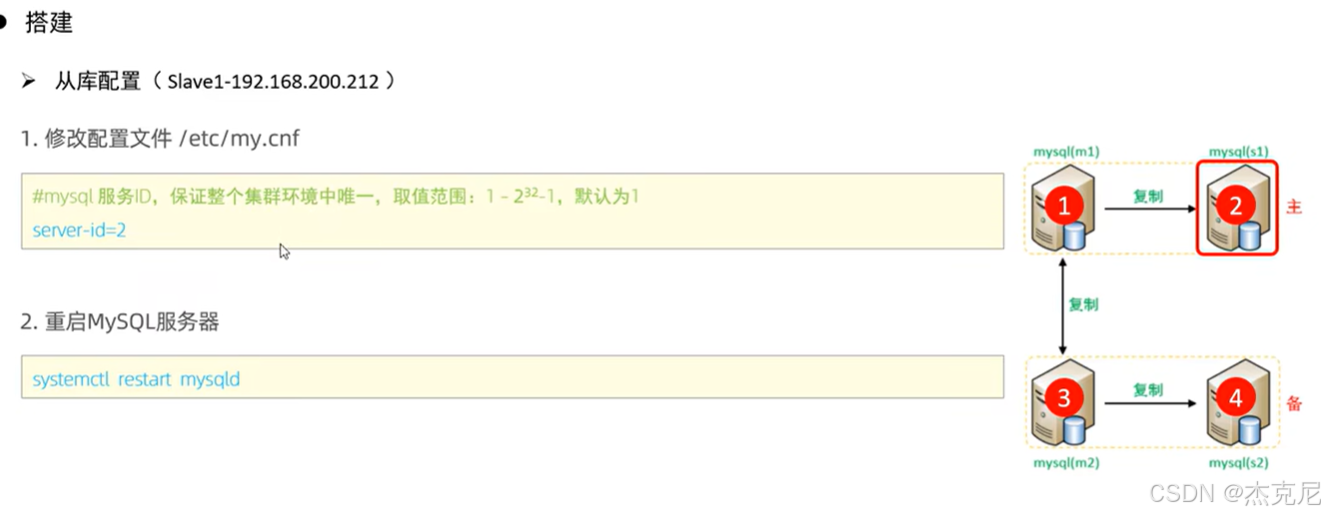
9主从复制-从库配置
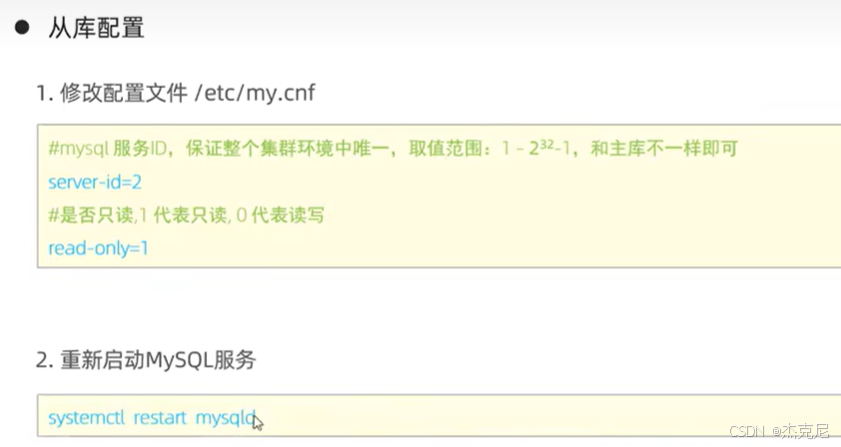
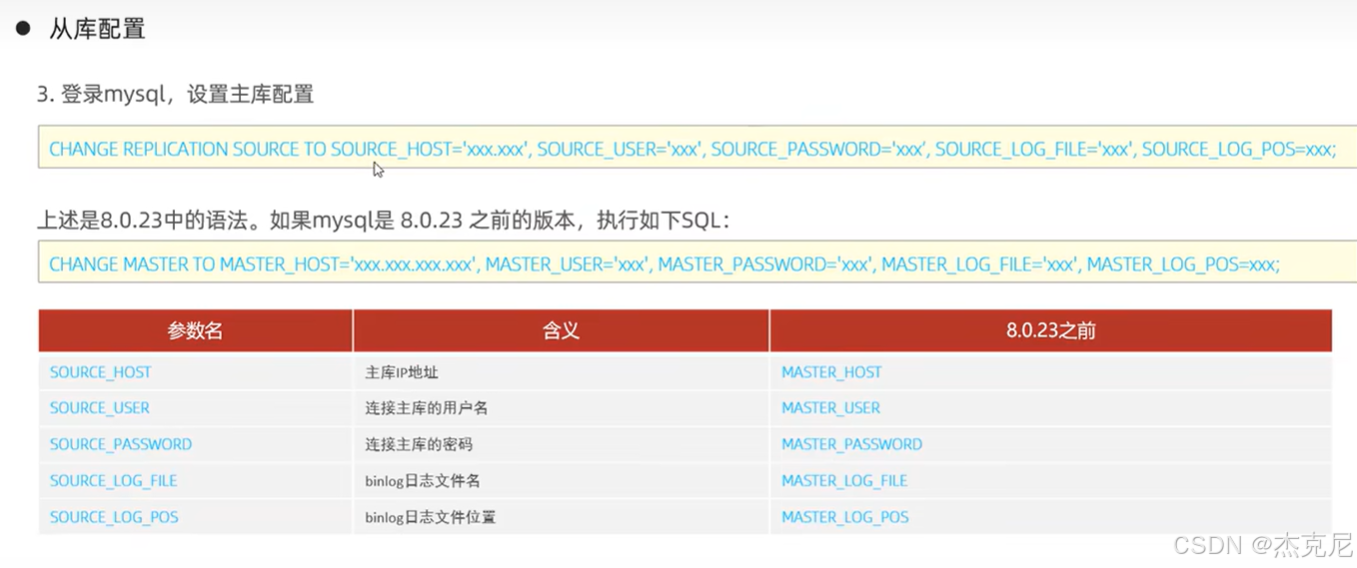
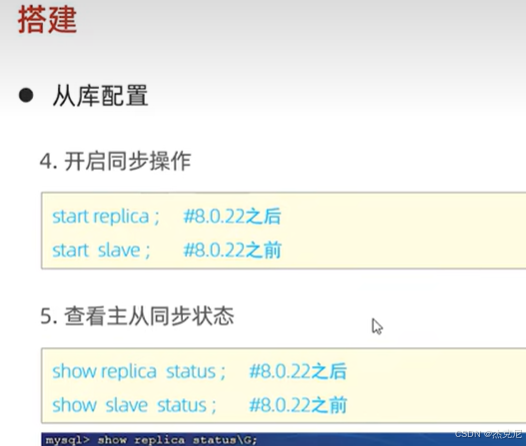
问题:
从库配置中的只读是什么意思?
他这个只读不影响主从之间的读写

10主从复制-测试


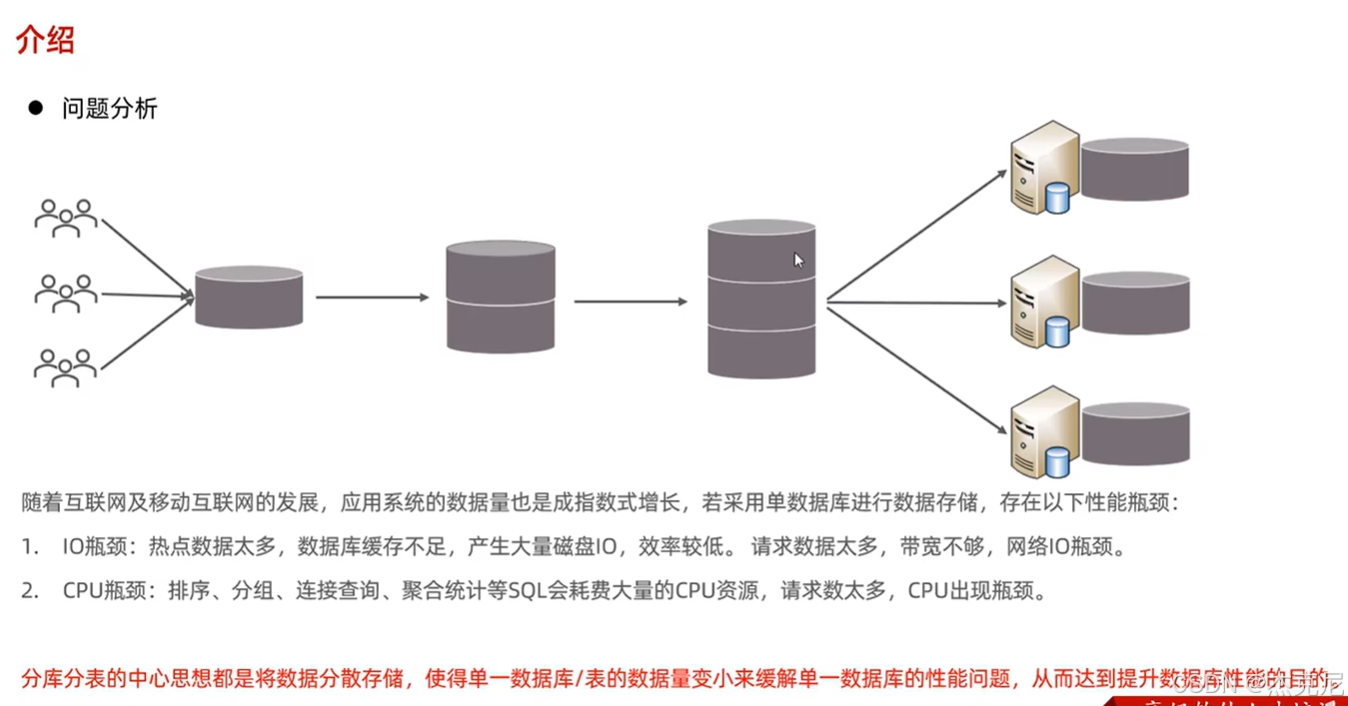
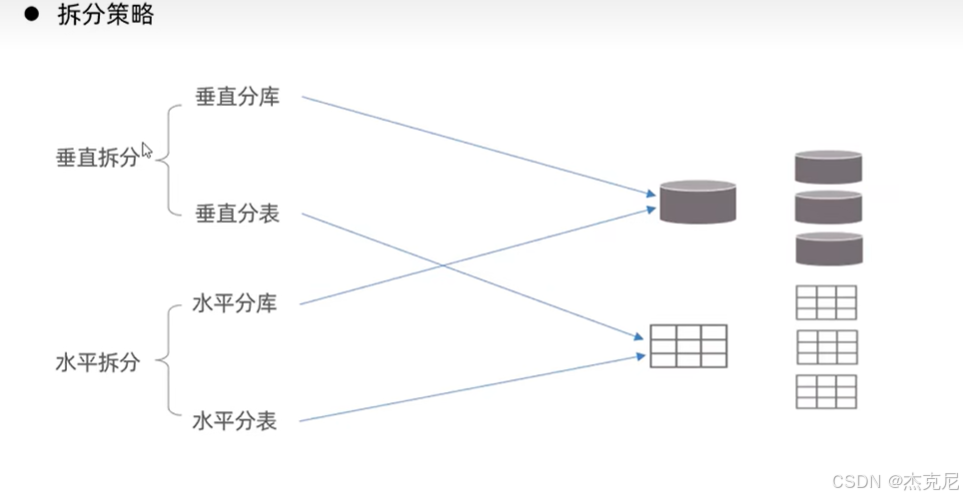
11分库分表-介绍

12介绍-拆分方式
问题:
1垂直分库和垂直分表的区别?

2那水平分库和水平分表呢?

13MyCat概述-安装

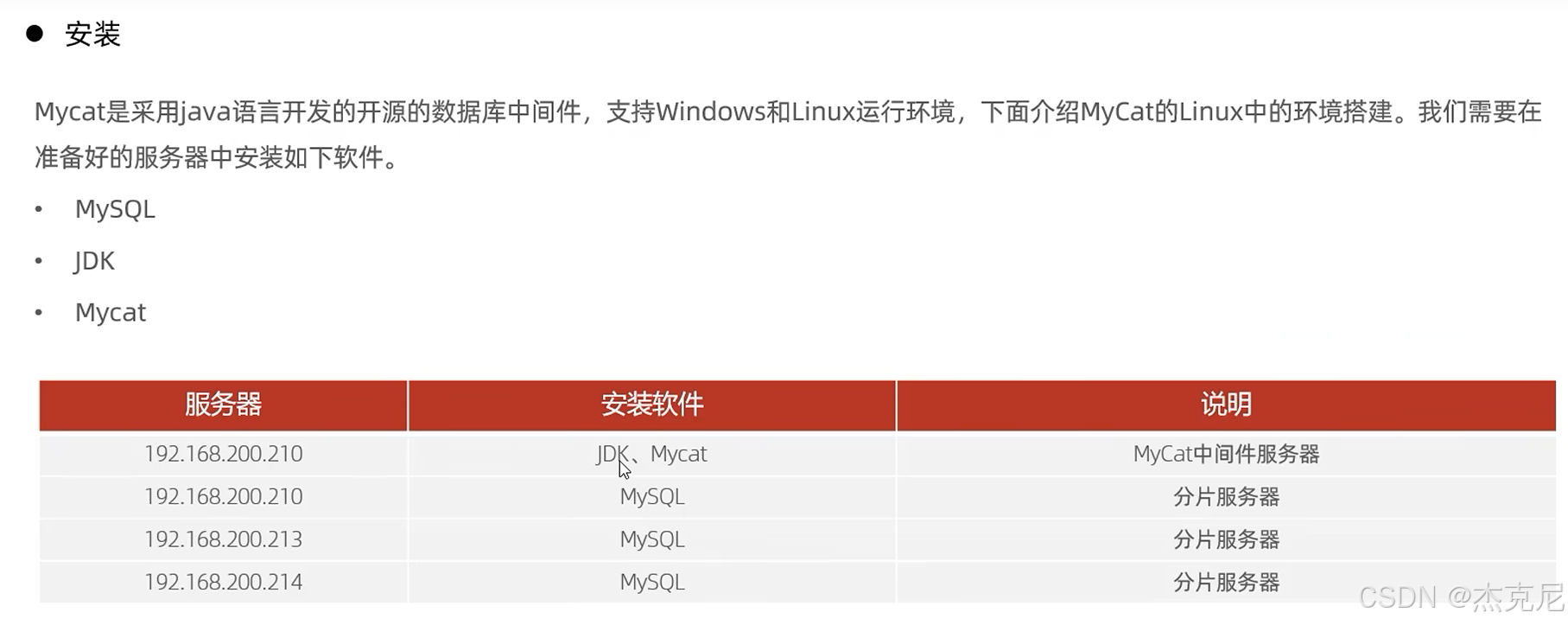

13. 运维-分库分表-MyCat概述-安装_哔哩哔哩_bilibili
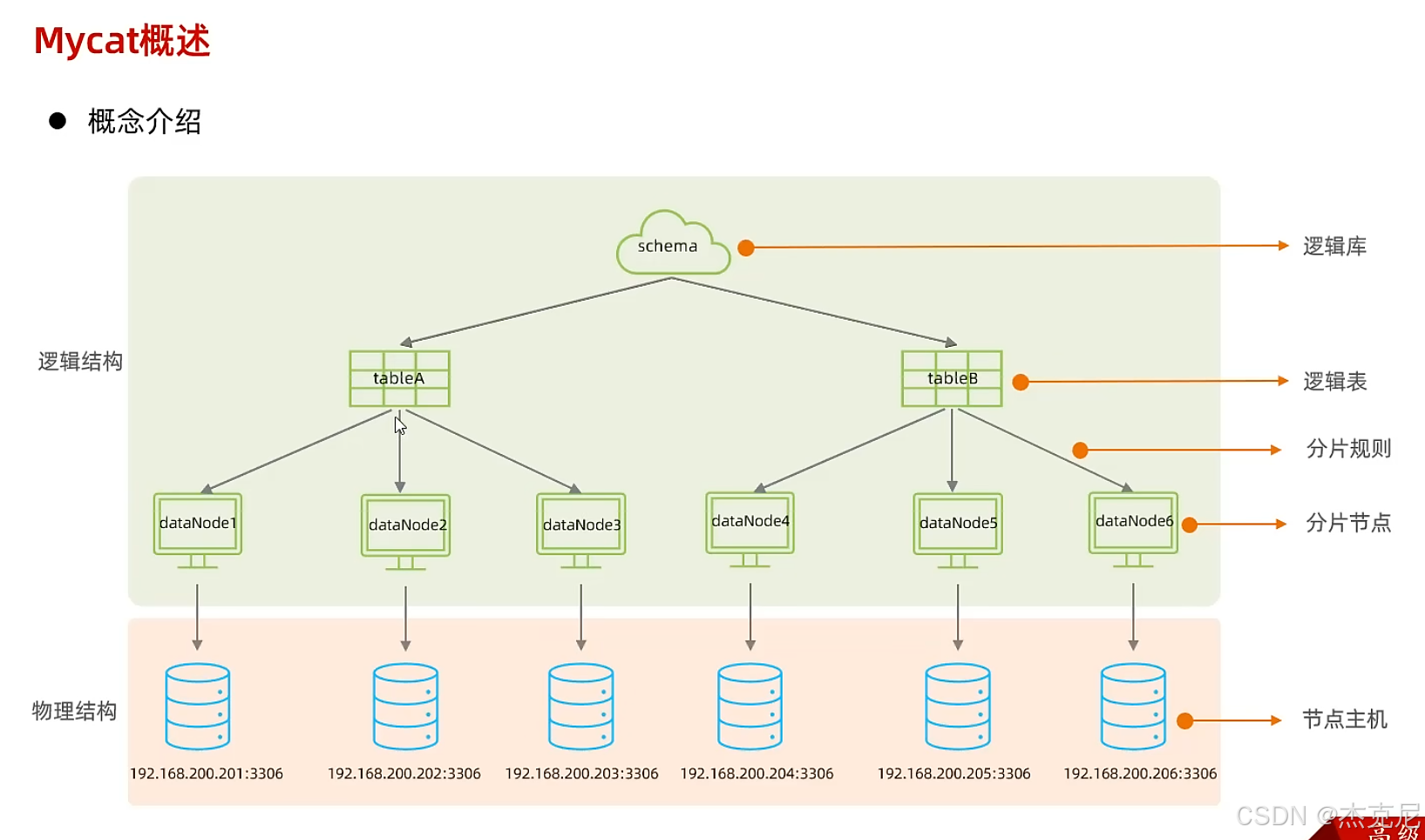
14MyCat概述-核心概念
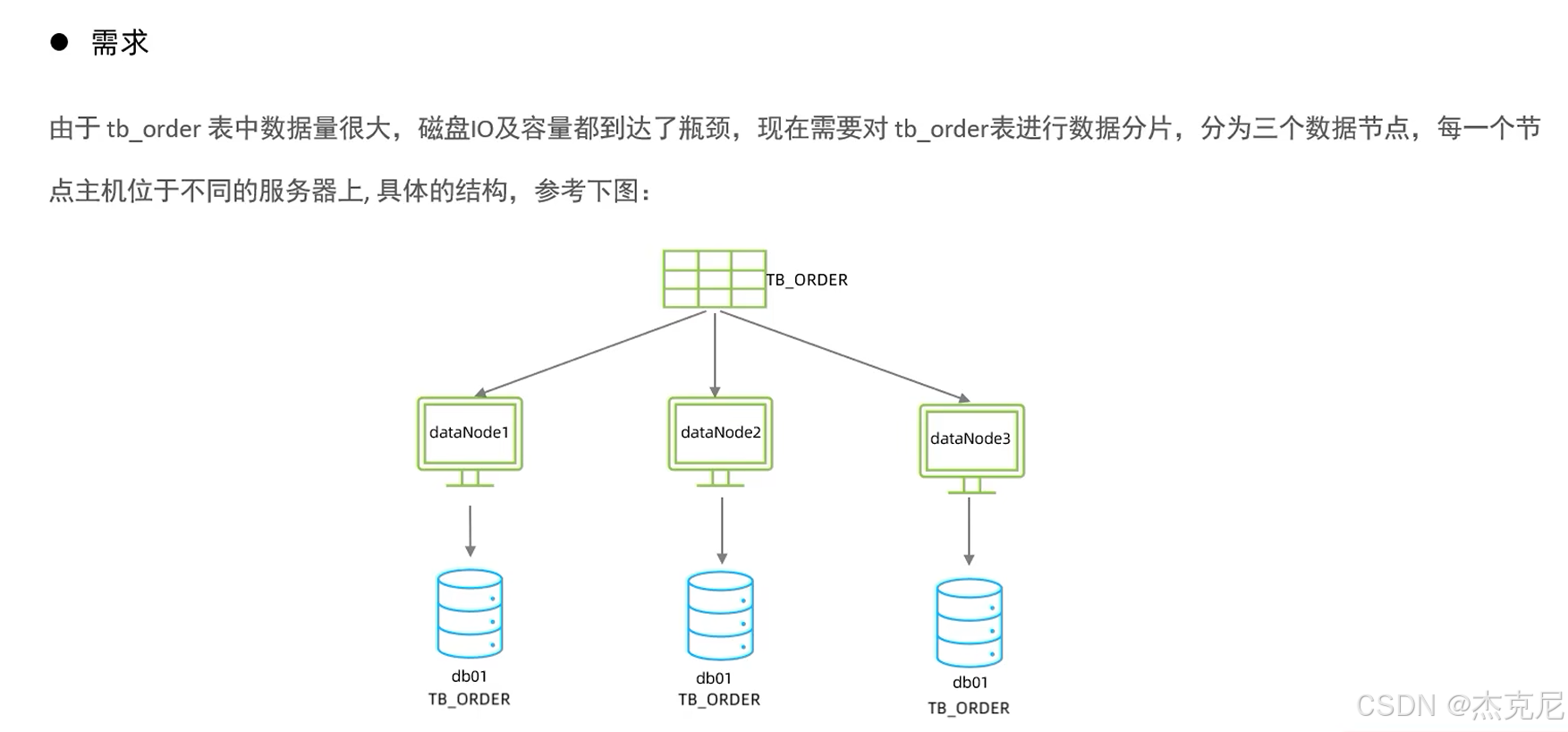
15MyCat入门
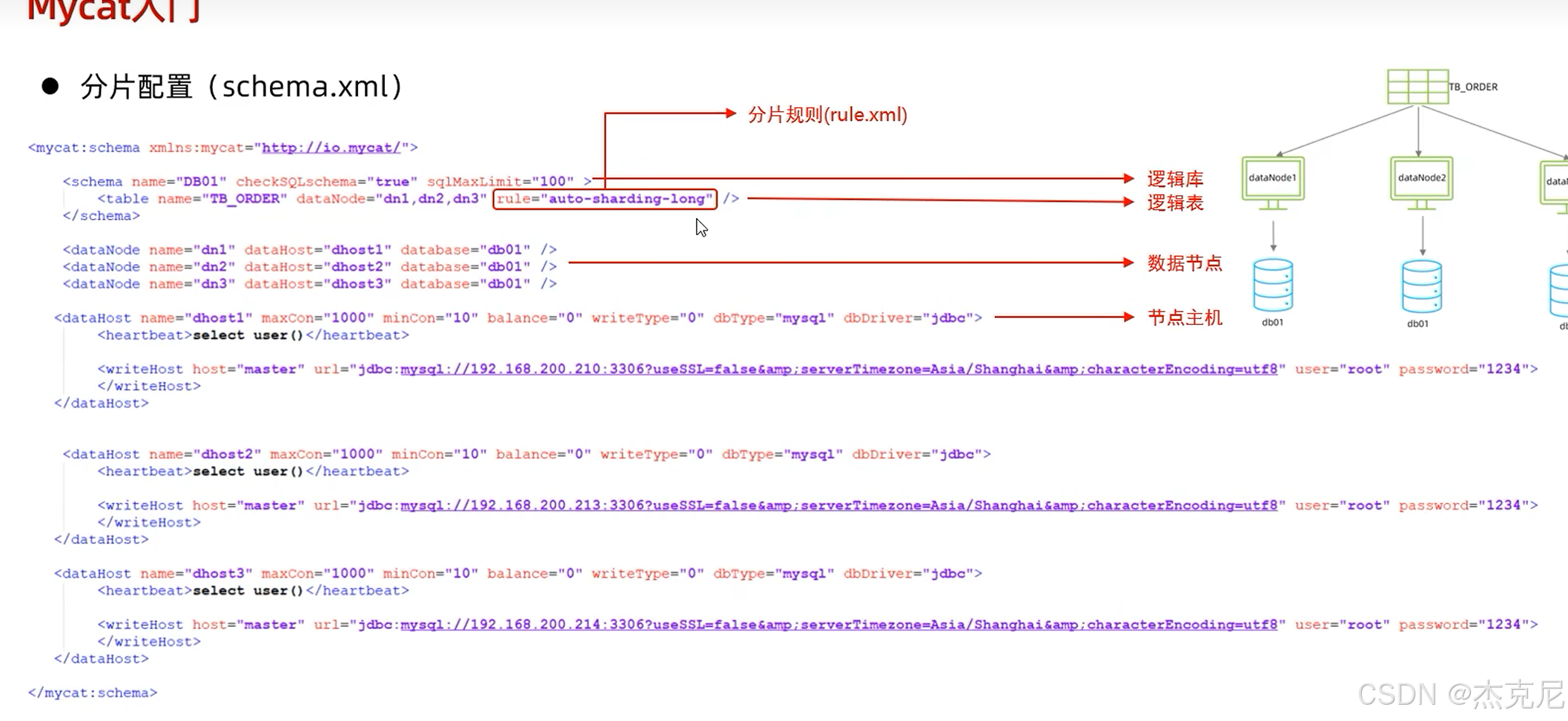
问题:
这些.xml放在哪里?
Mycat其实就是中间件

16MyCat入门-测试

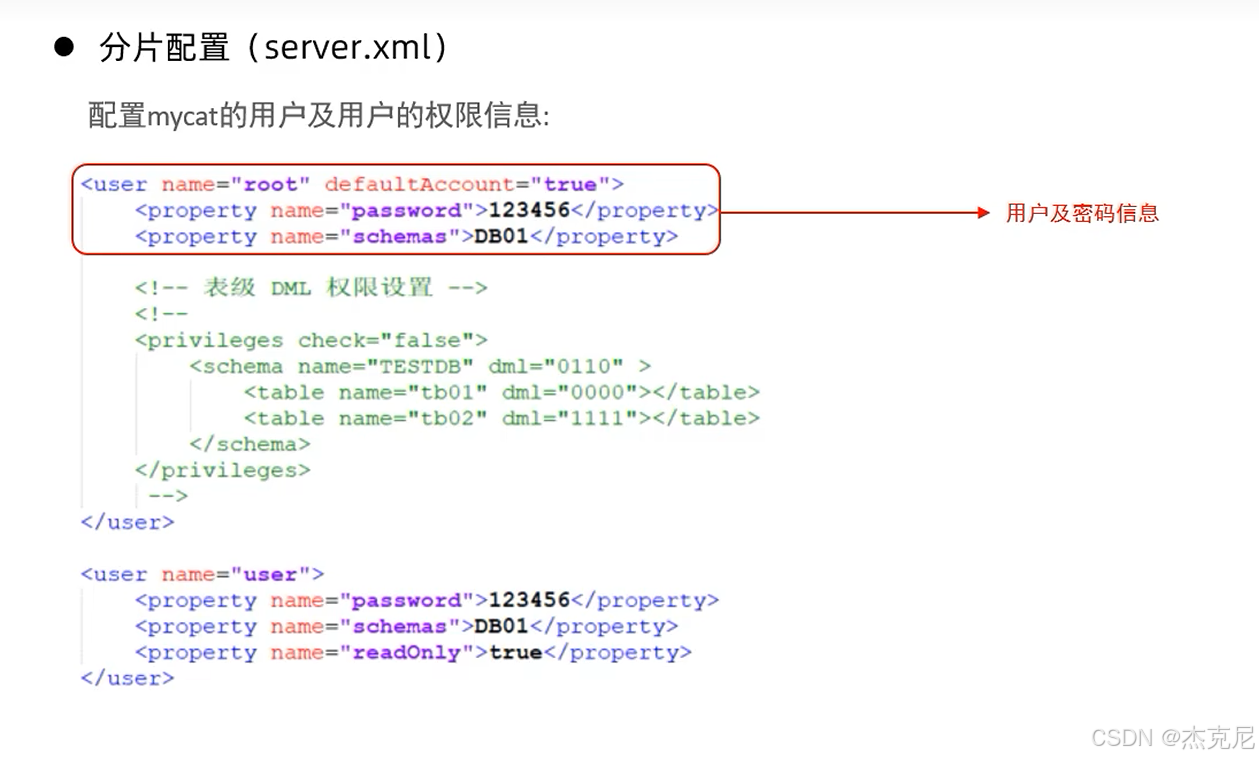
17MyCat配置1




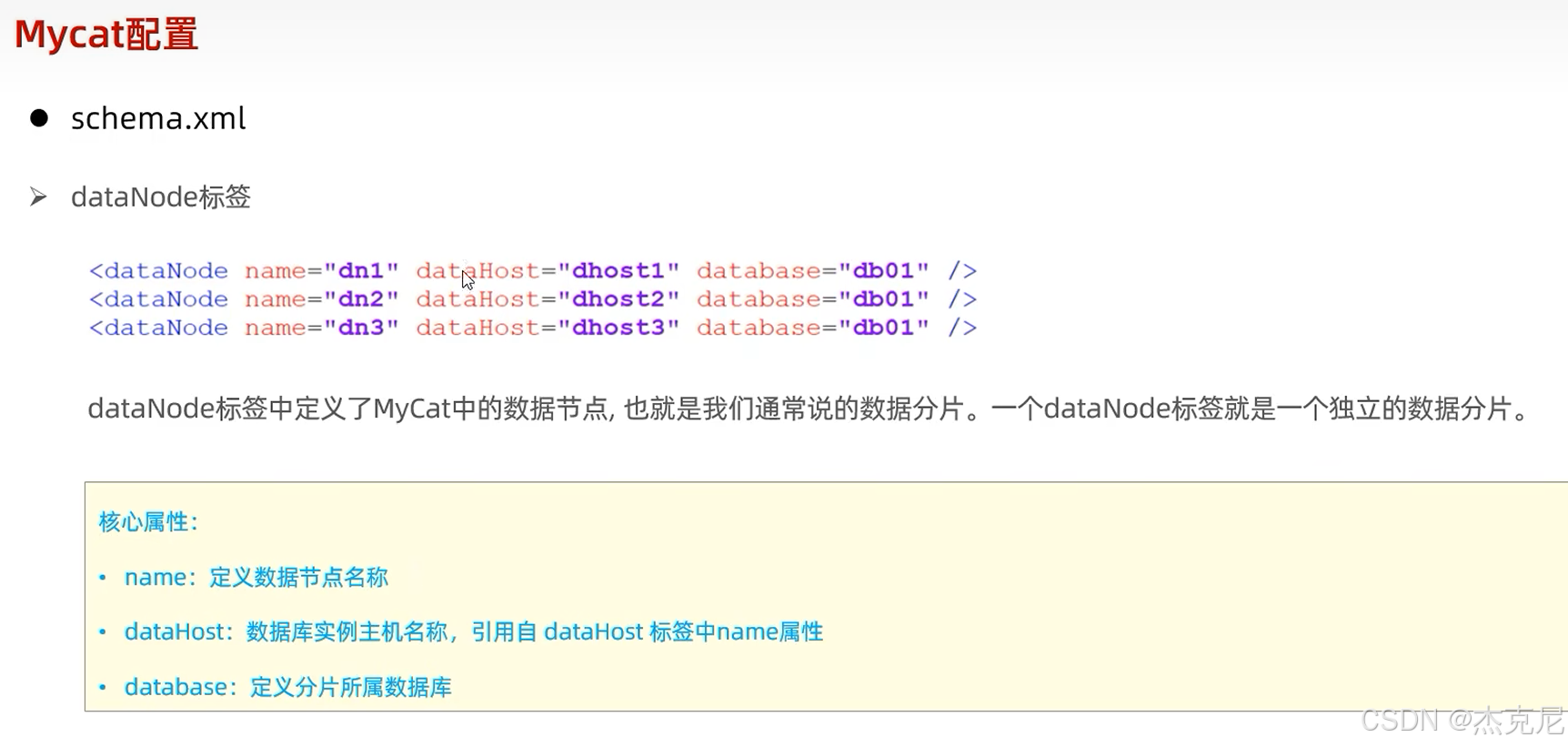


问题:
1没有记住?
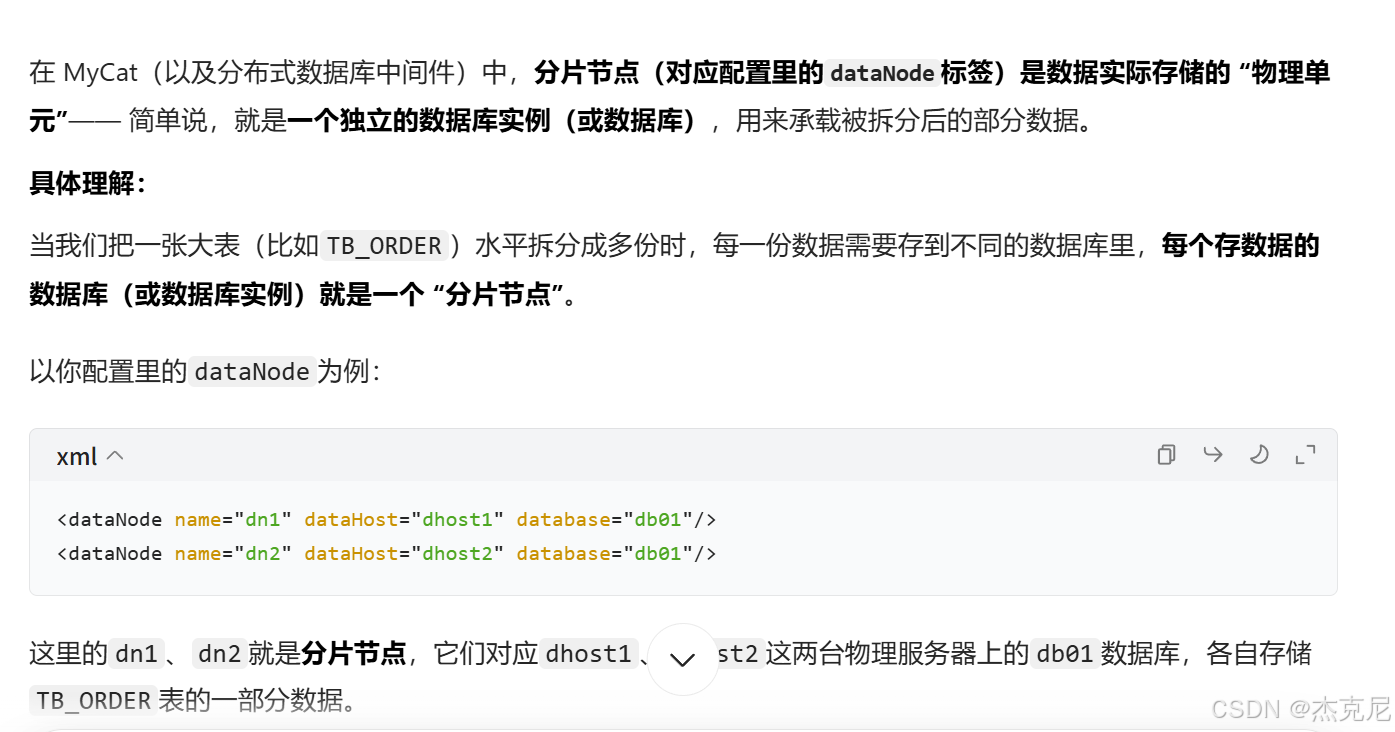
2什么是分片节点?
18MyCat配置2


问题:
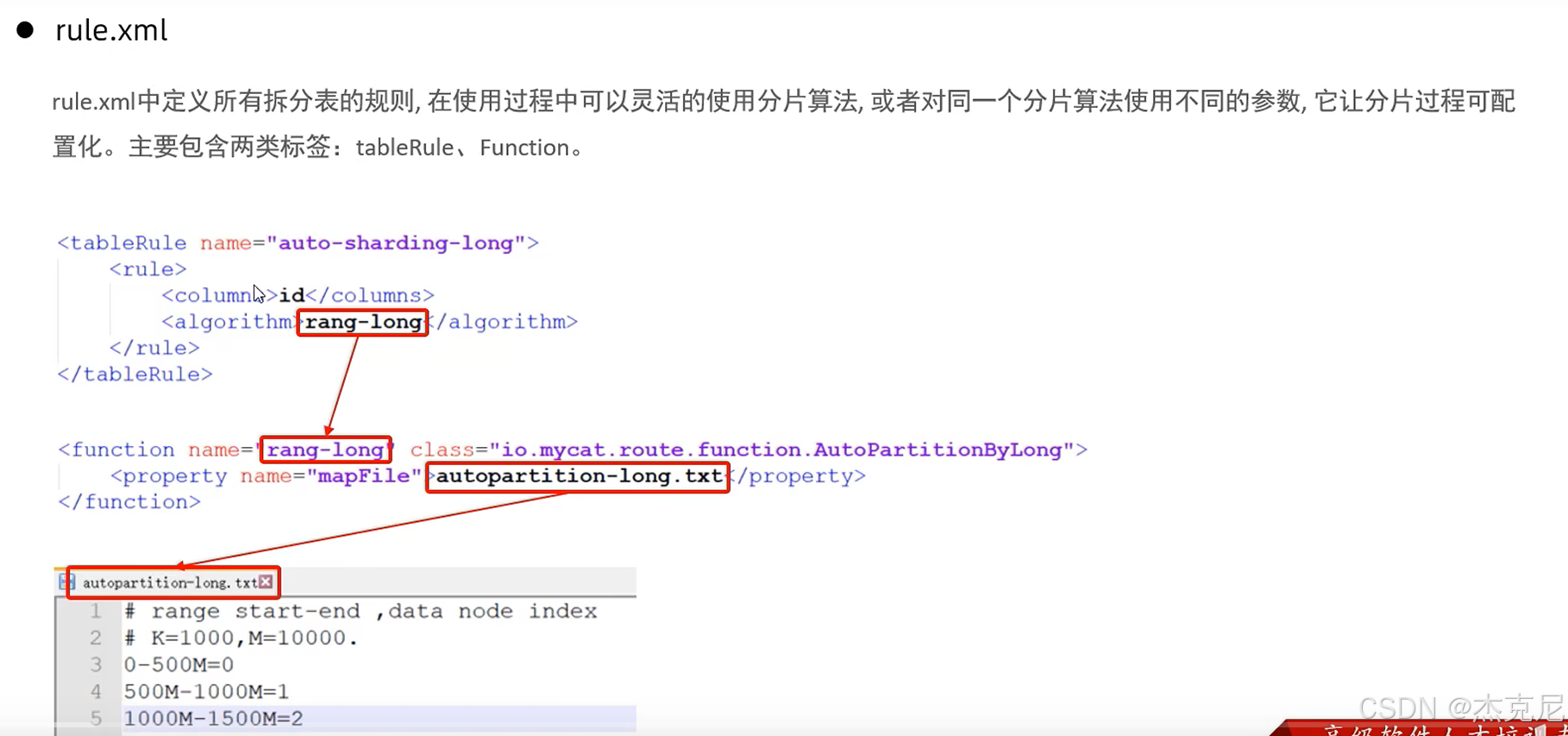
1什么是分片算法?

垂直分库不需要rule
19MyCat分片-垂直分库
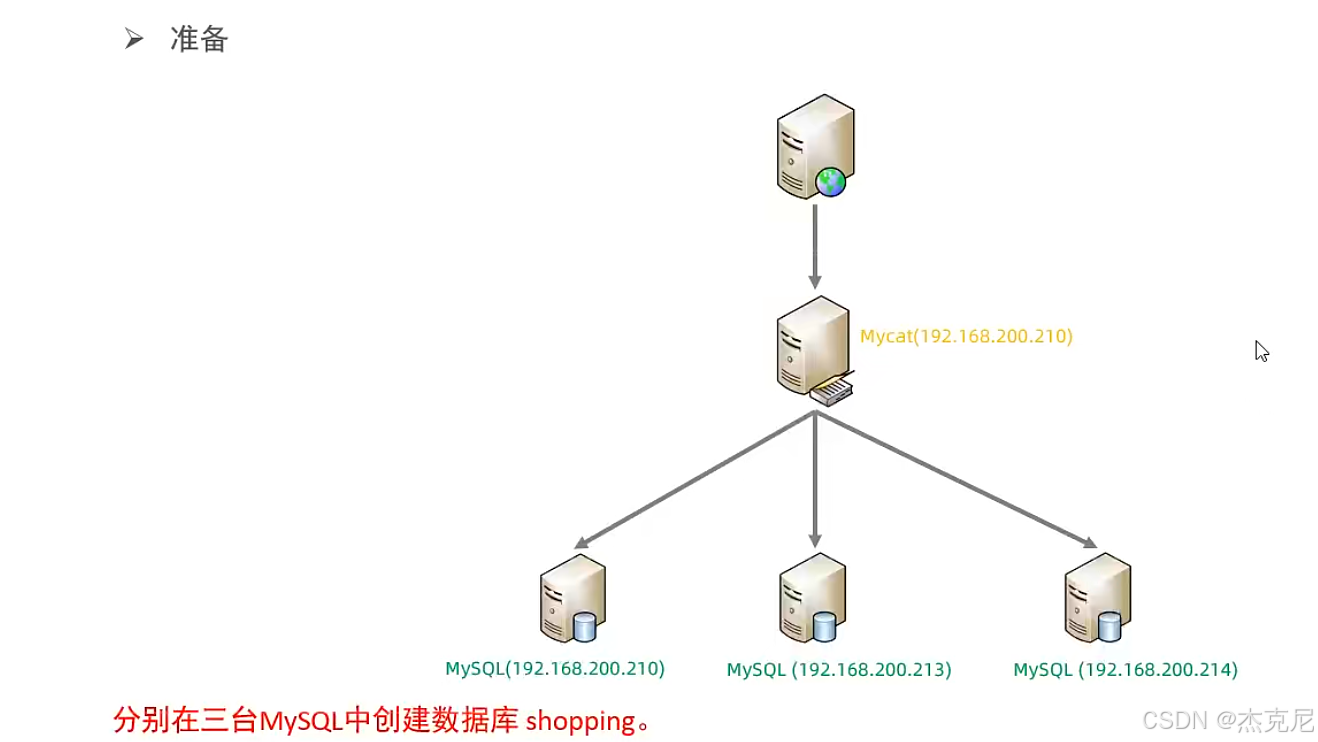

20垂直分库-测试
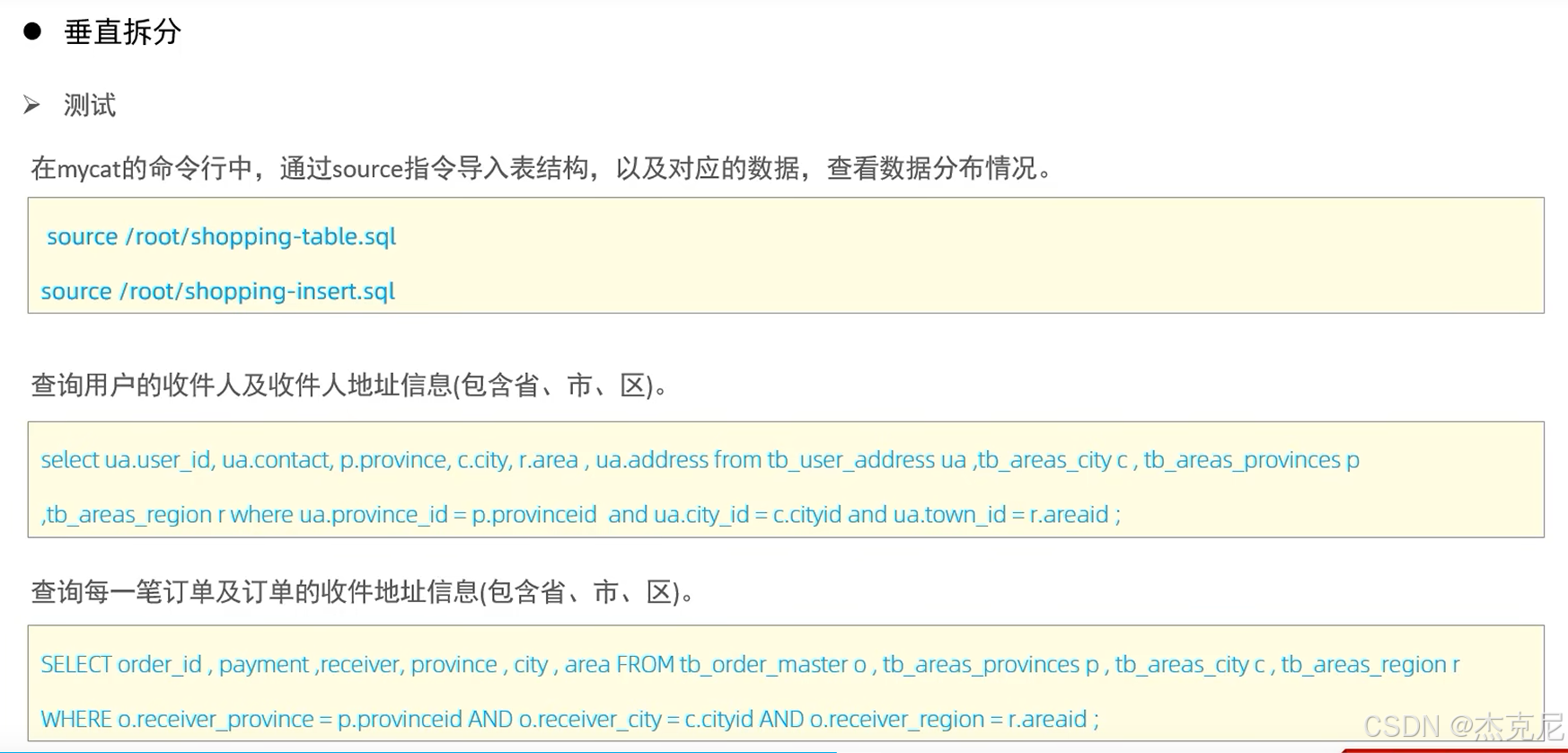

问题:
如何设置全局表?
设置<table>标签里面的type="global"
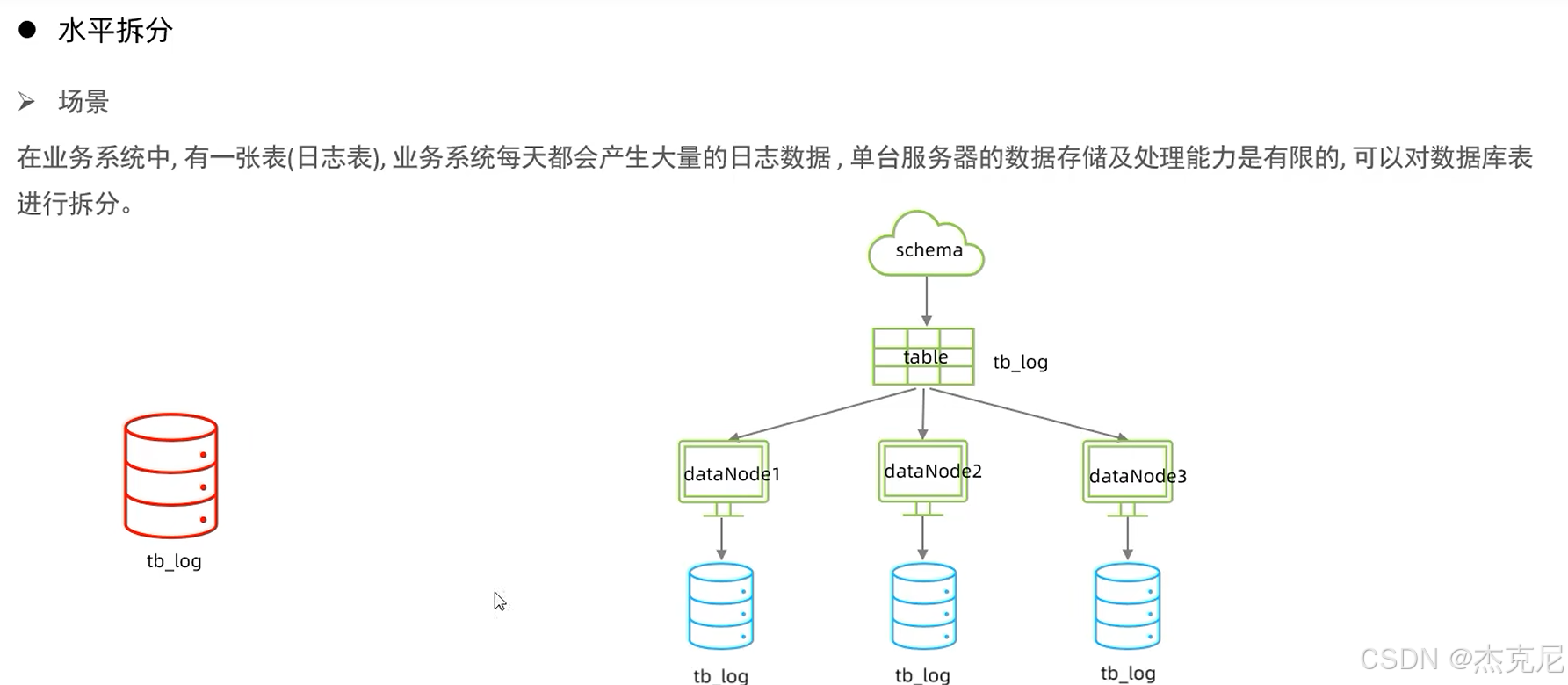
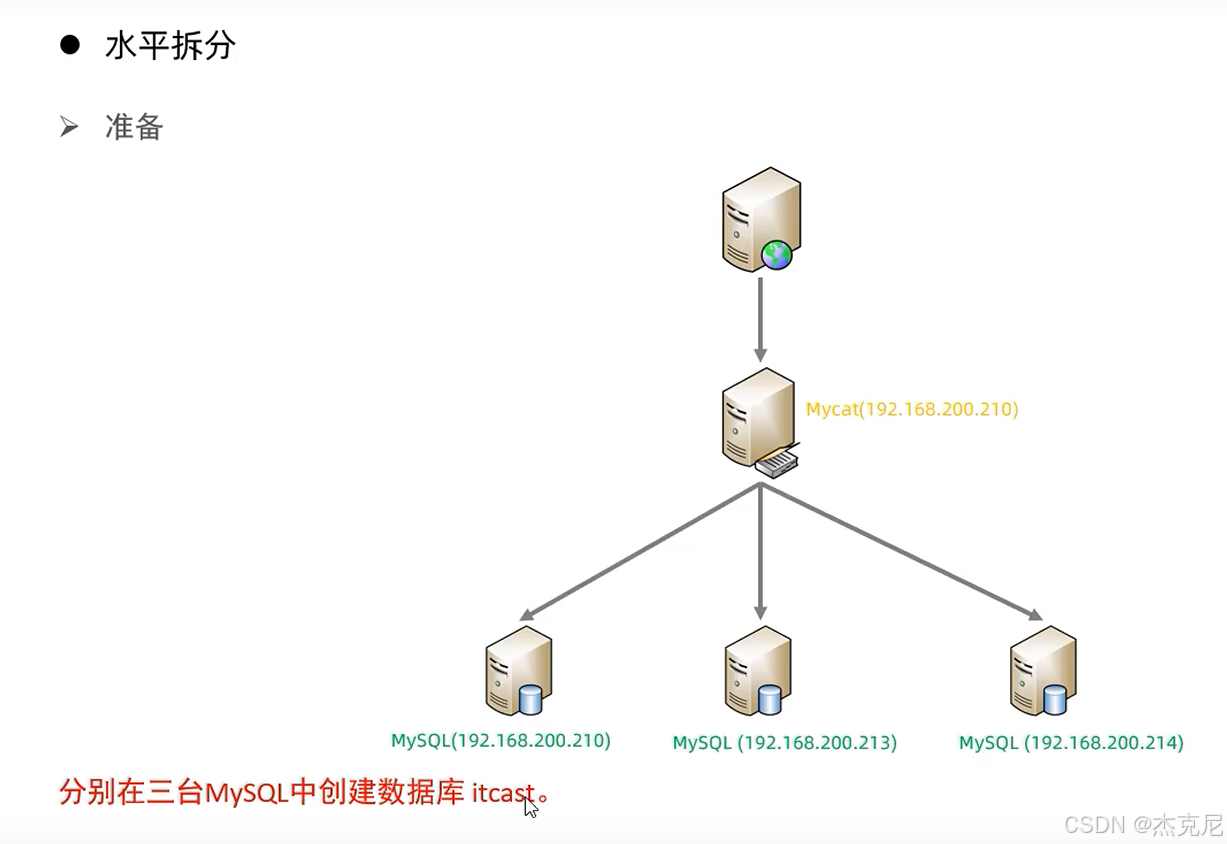
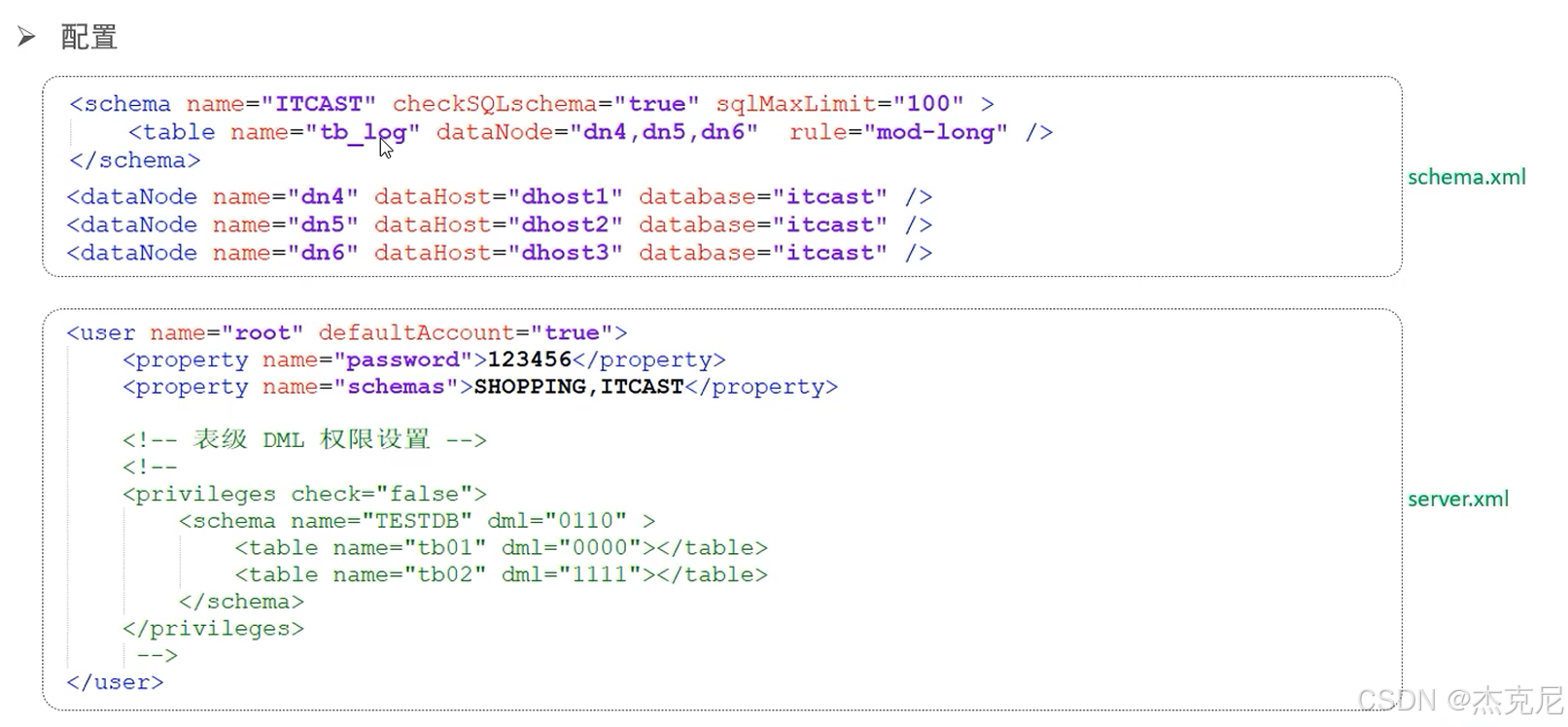
21MyCat分片-水平分表
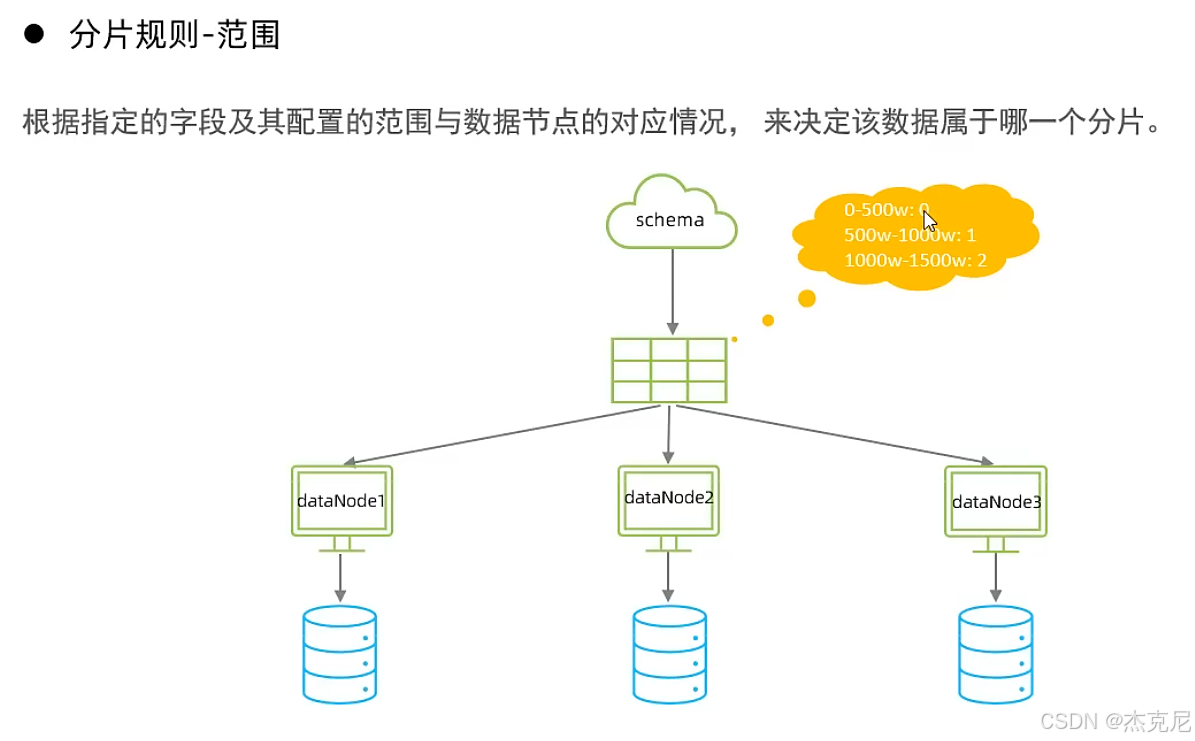
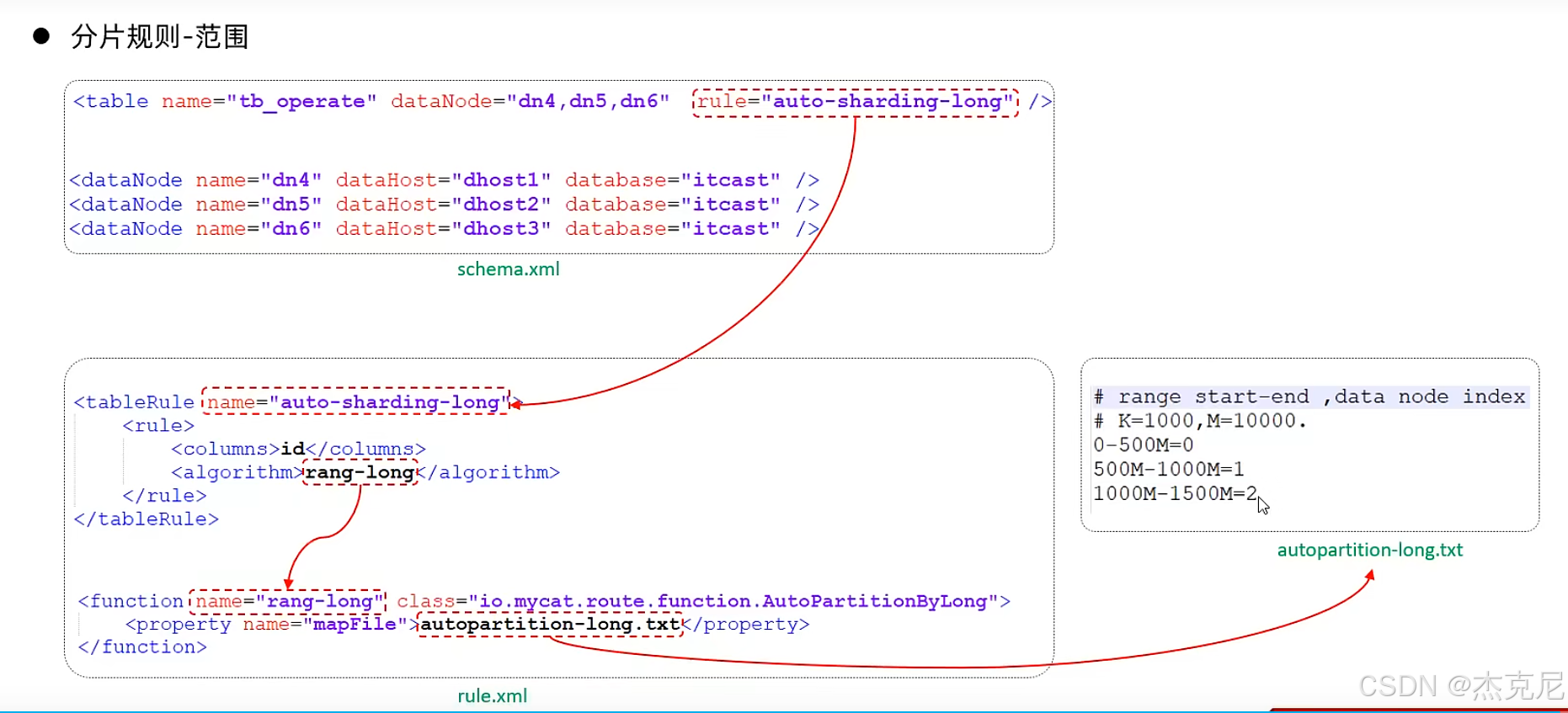
22分片规则-范围分片
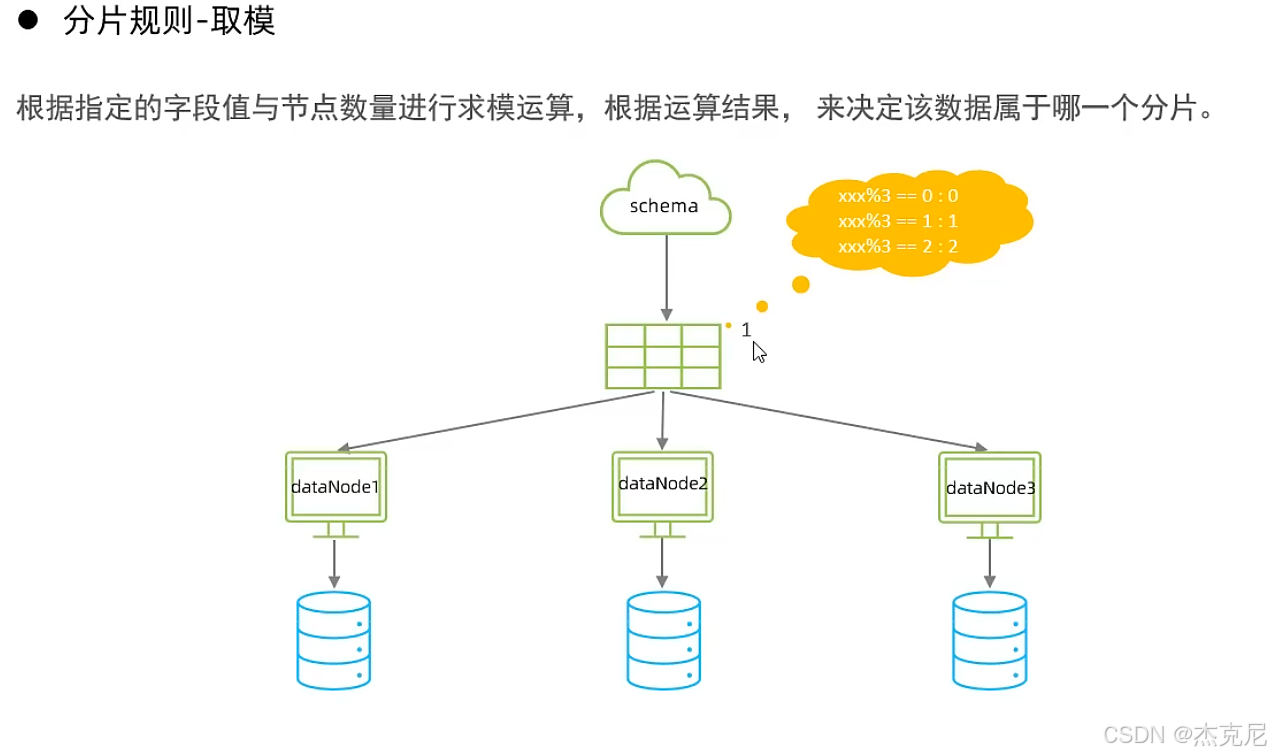
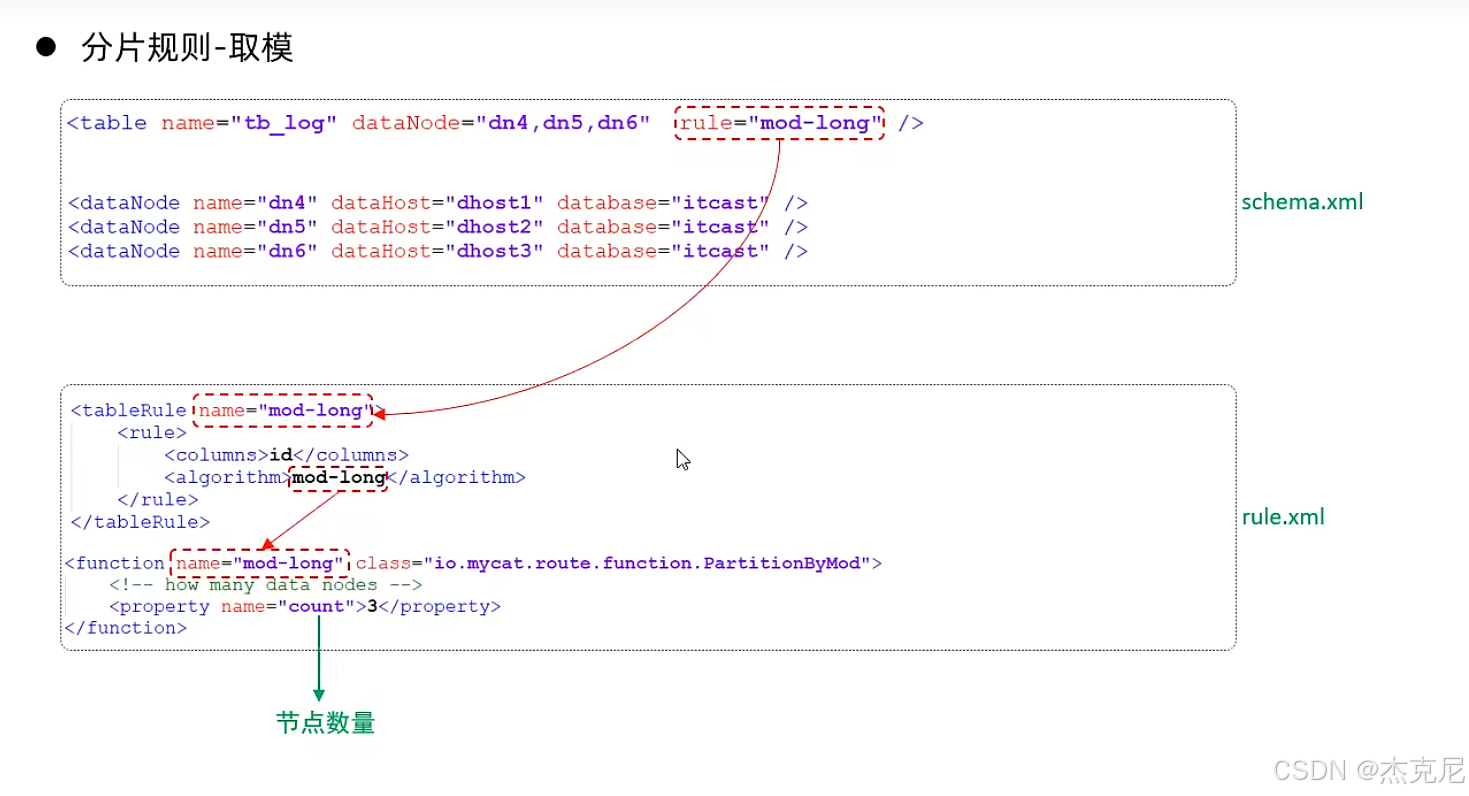
23分片规则-取模分片
问题:
1上面两种名字及原理?
2上面两种算法都是针对数值的,那字符串数据呢?
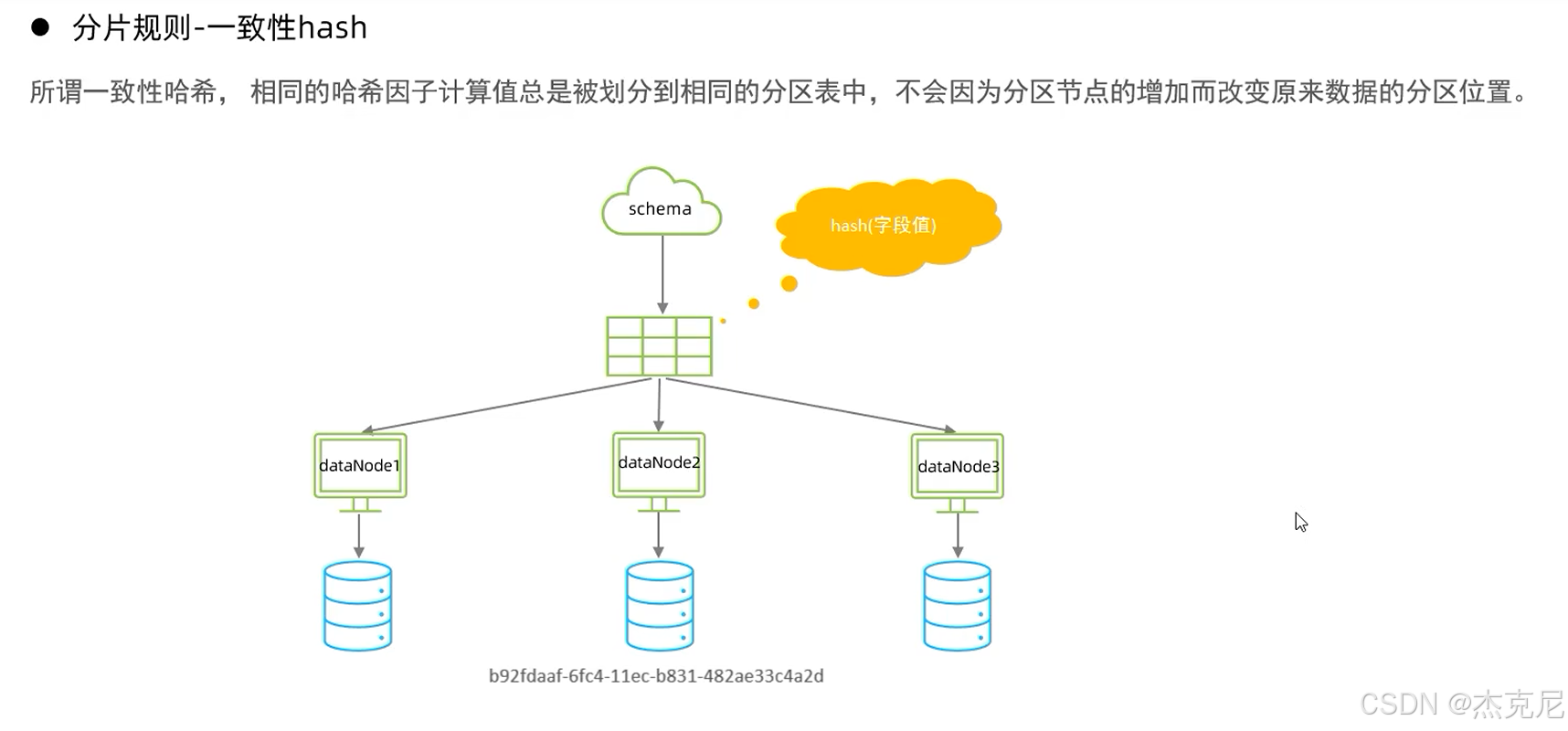
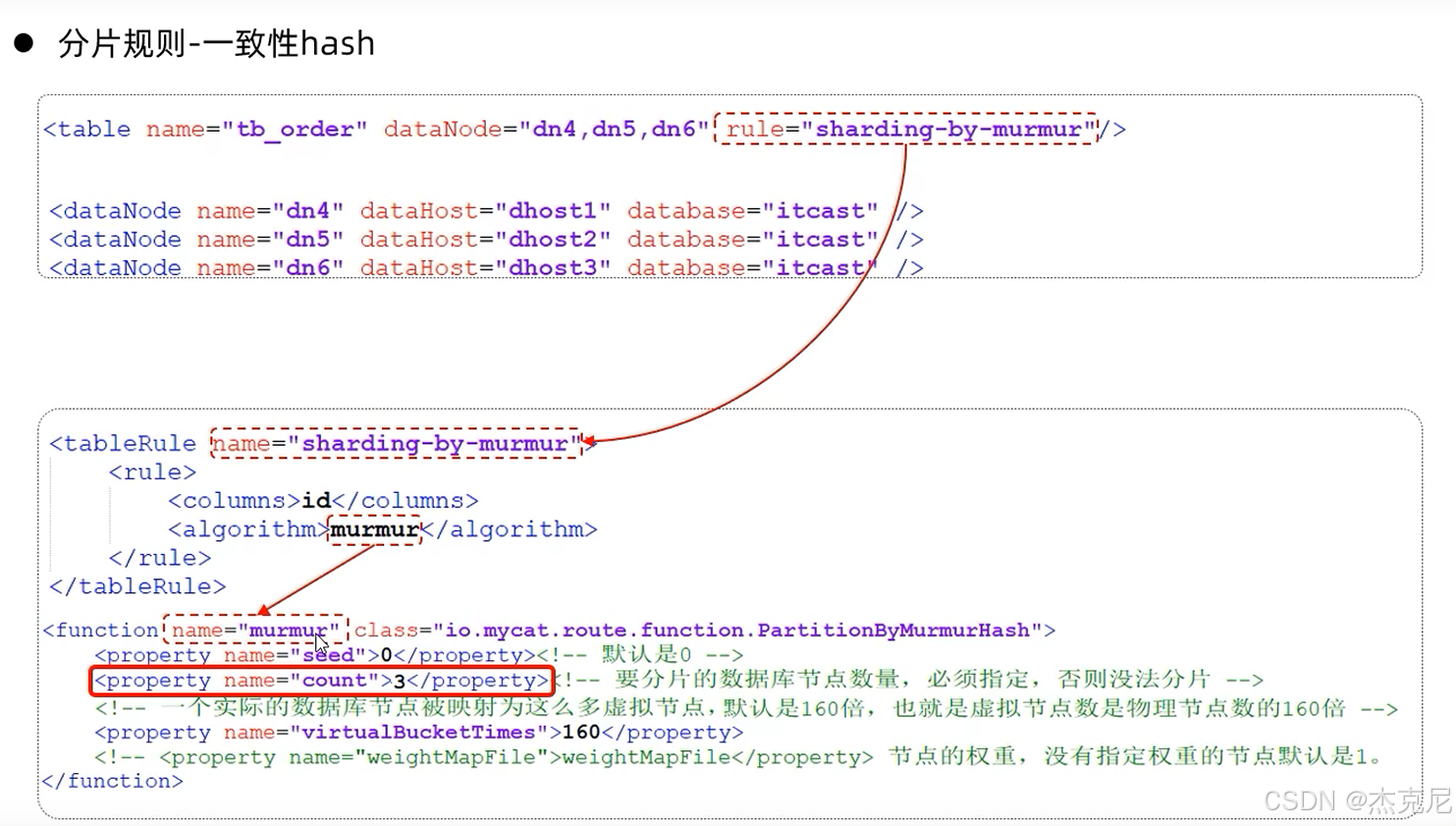
24一致性hash算法
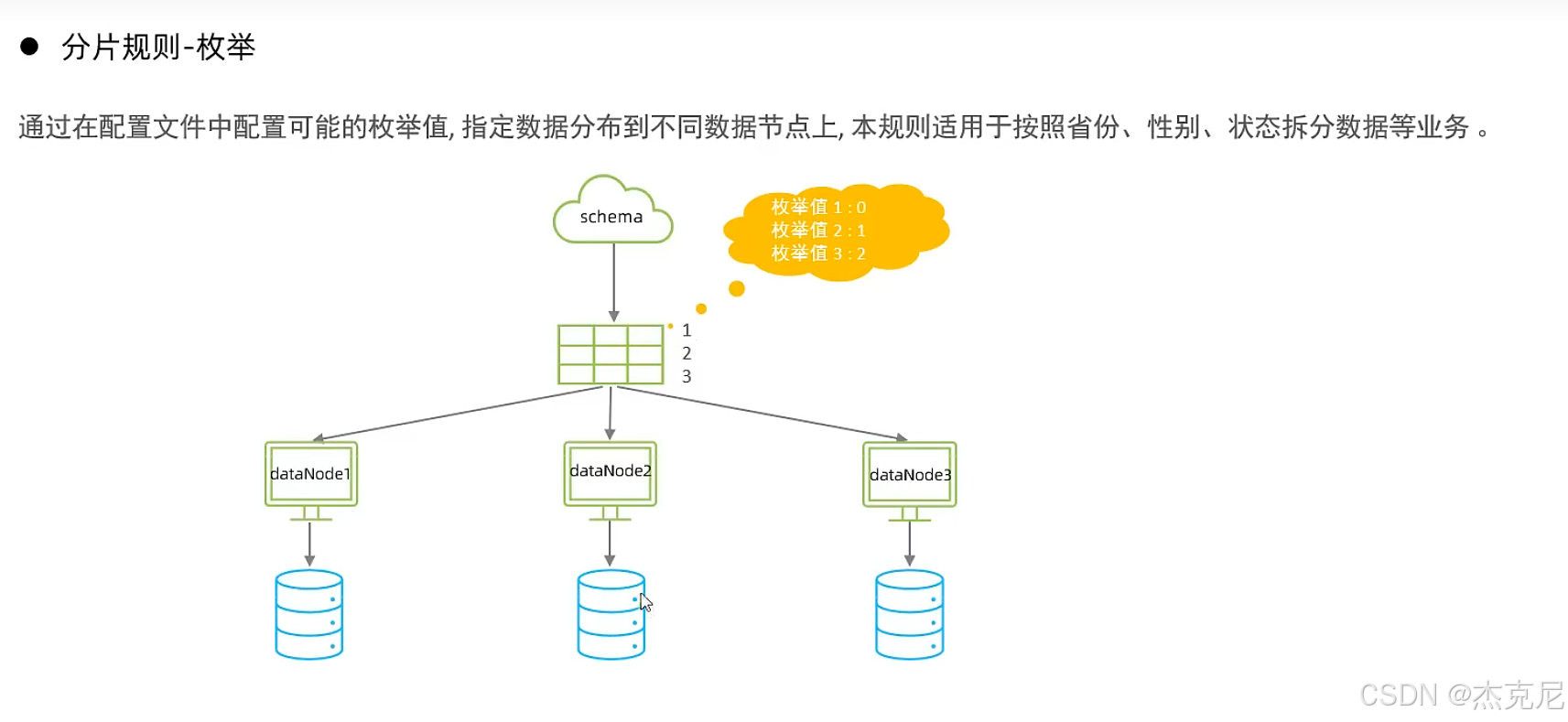
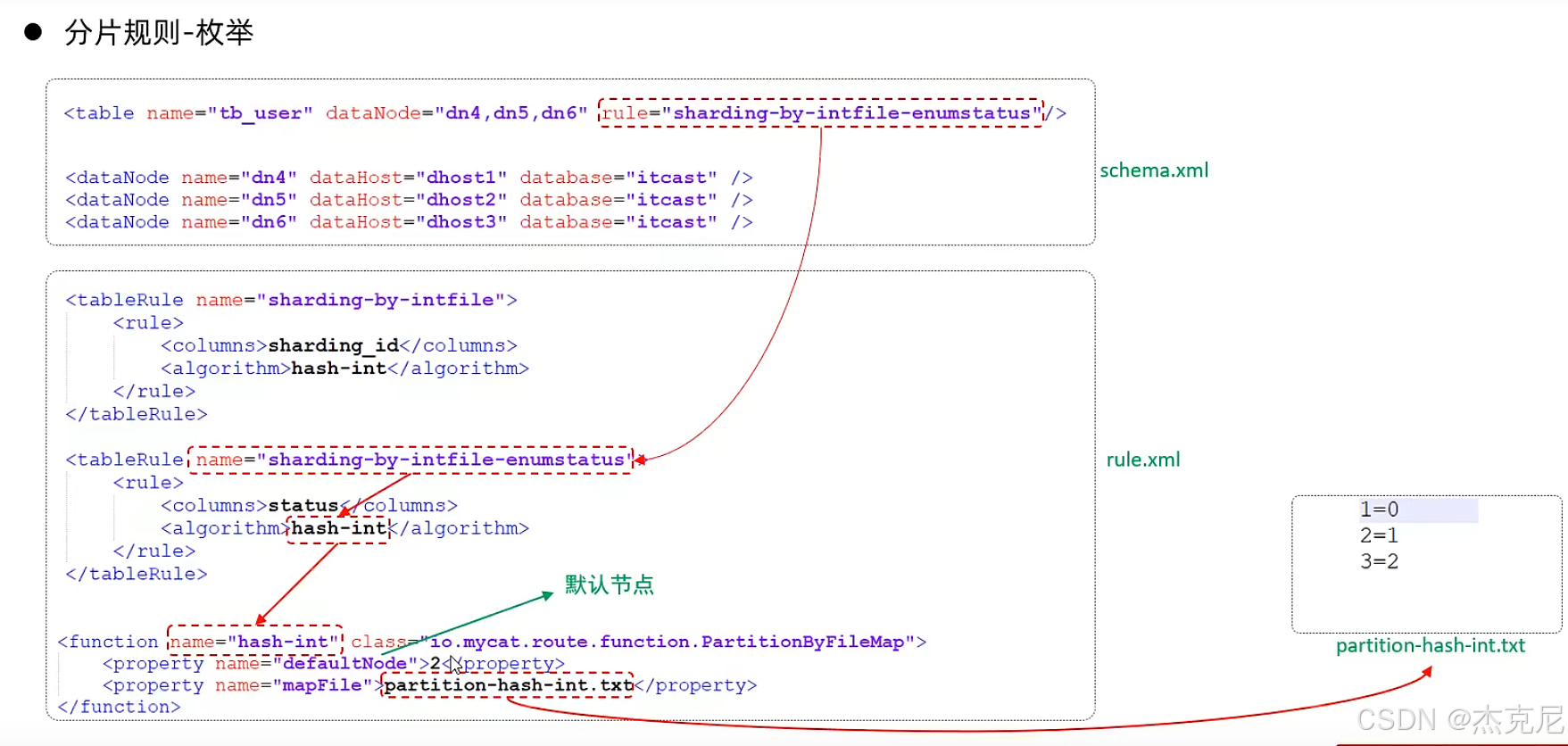
25枚举分片
问题:
枚举分片和一致性hash算法有什么区别?

26应用指定算法
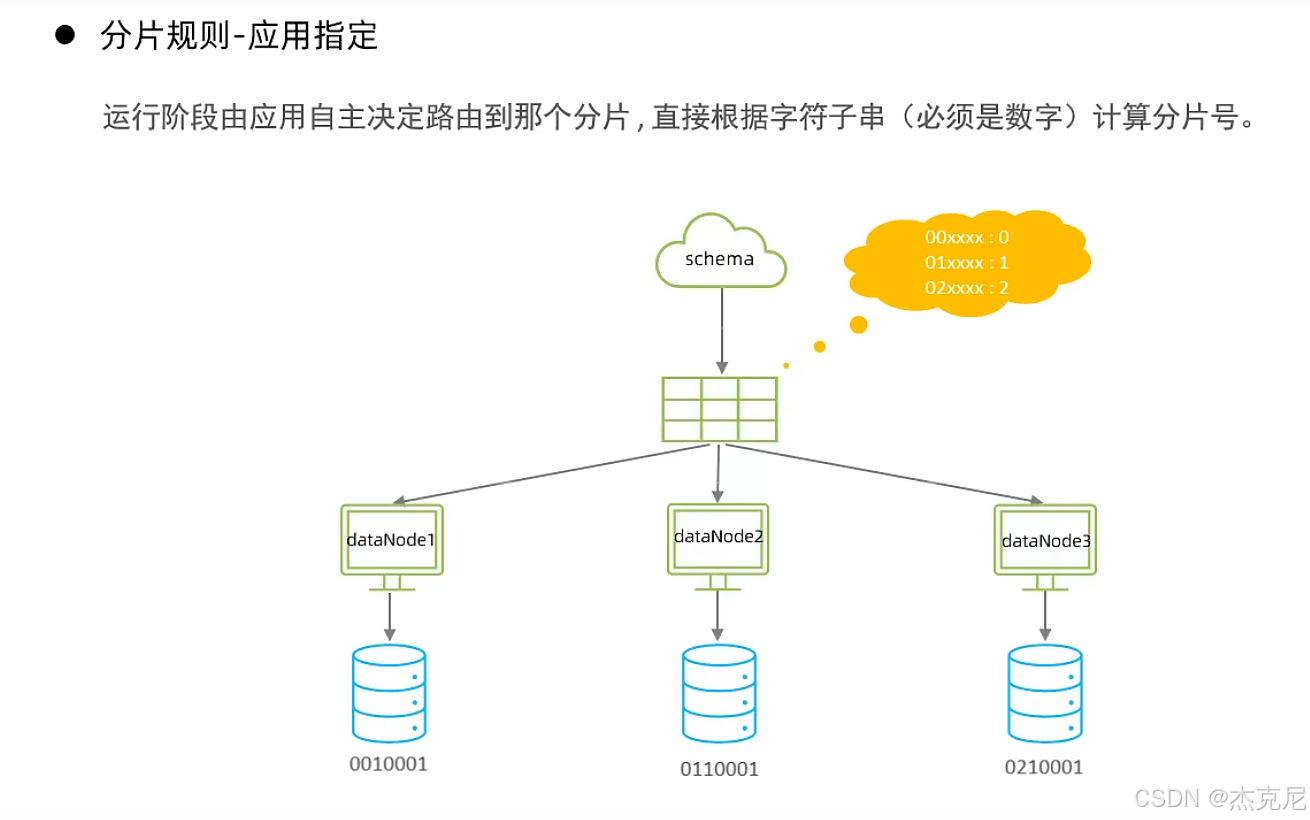
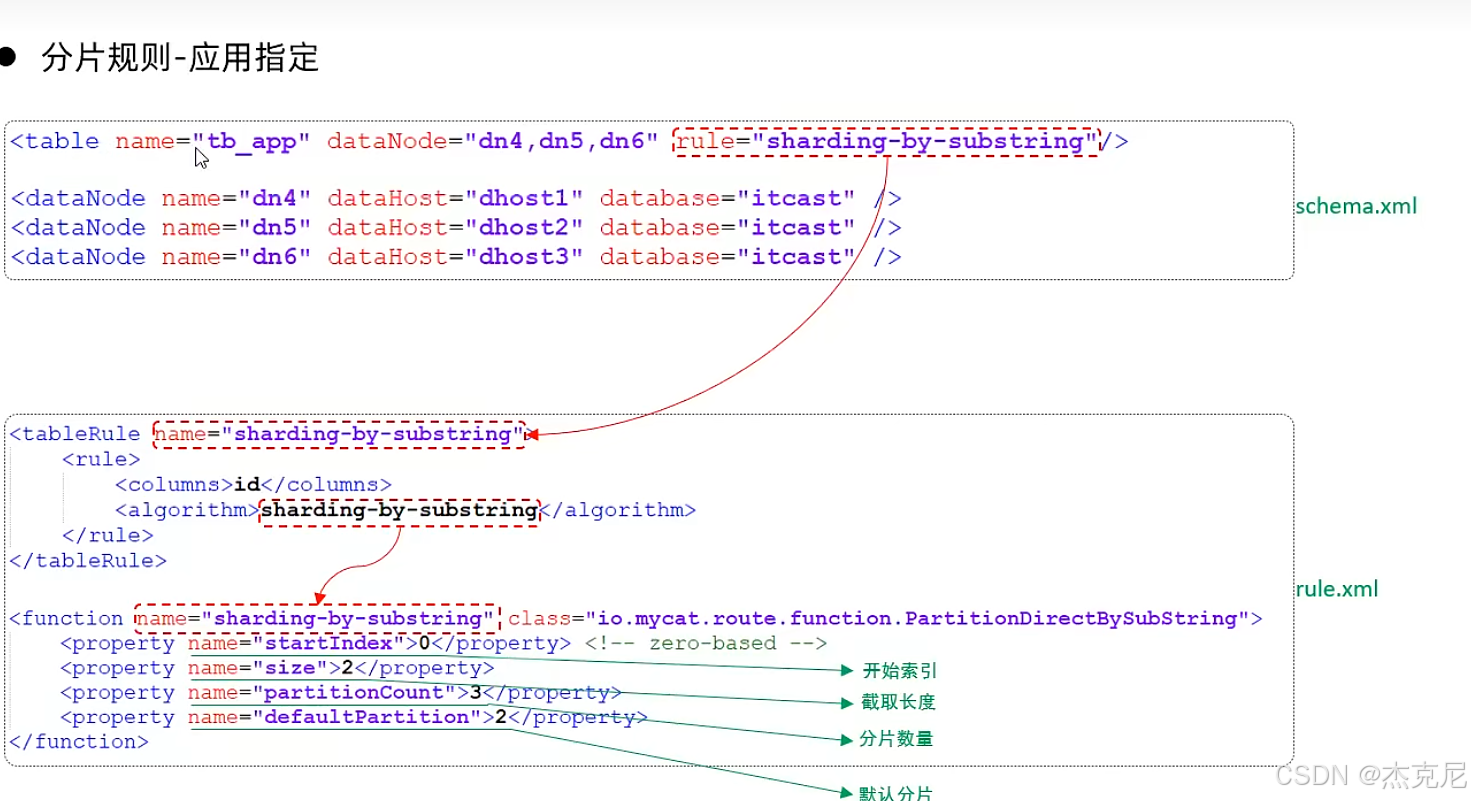
27固定hash算法
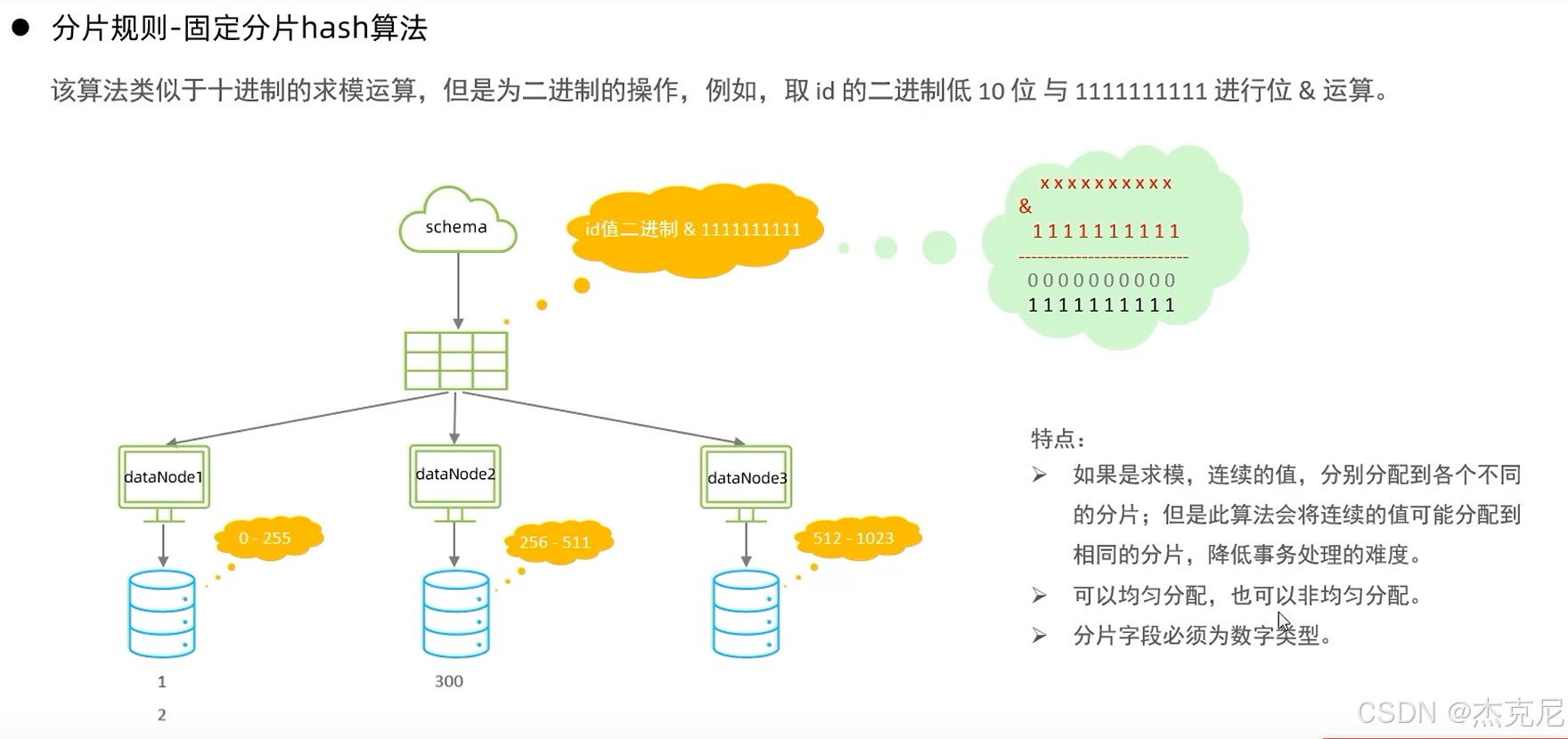
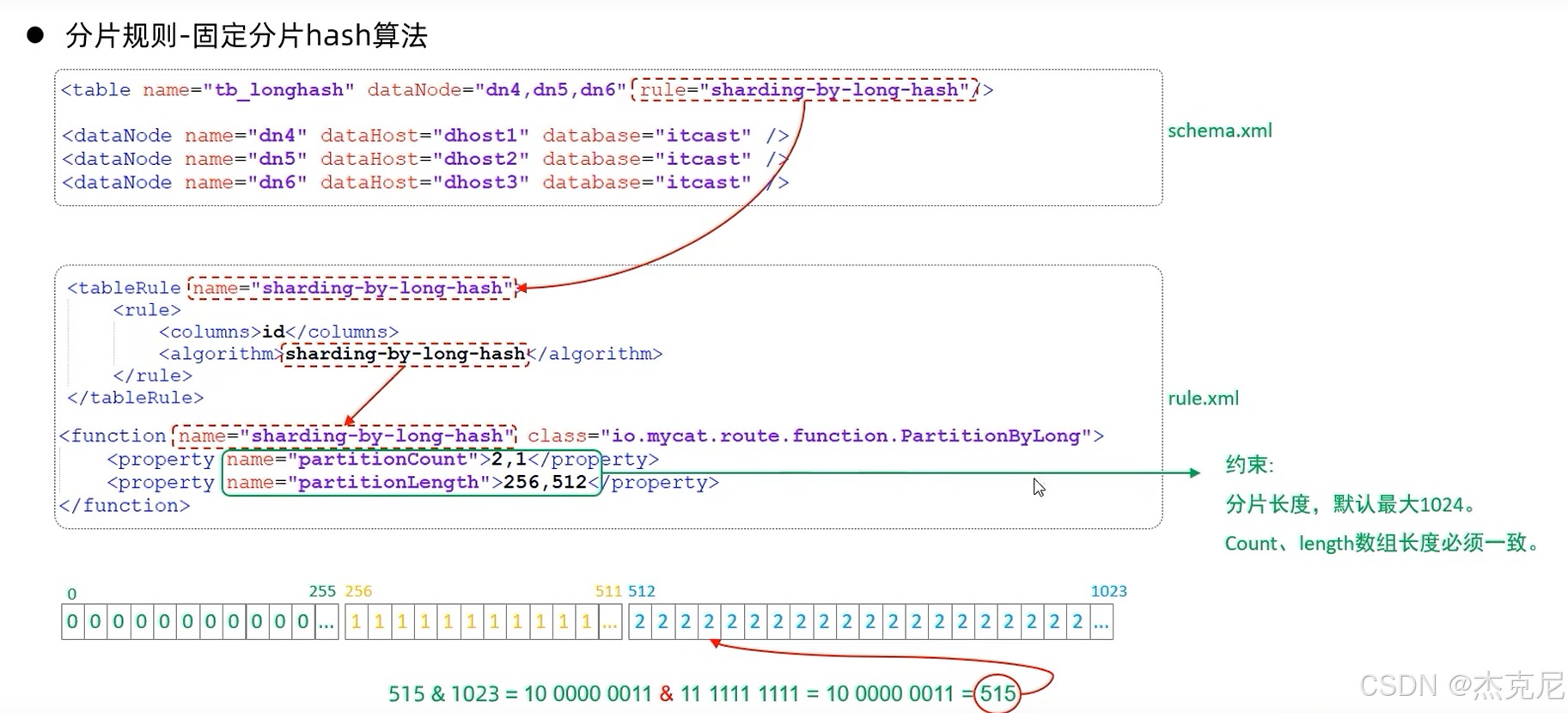
28字符串hash解析
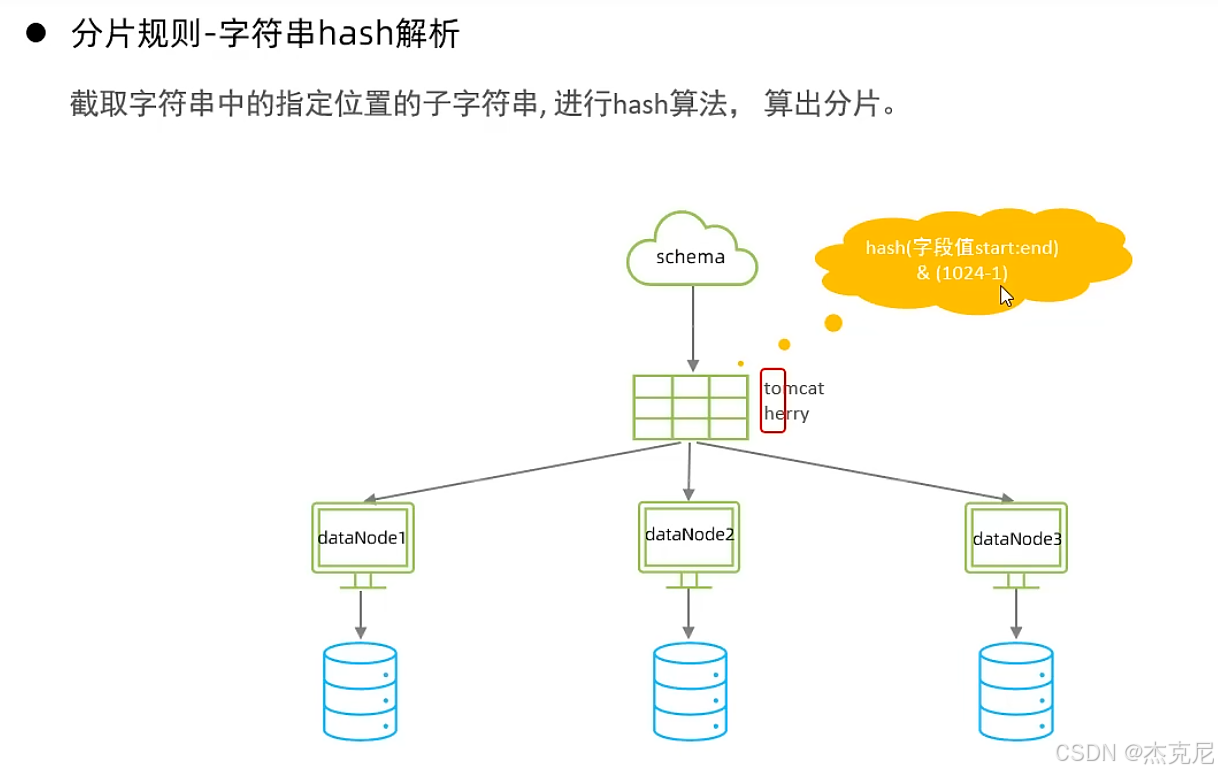
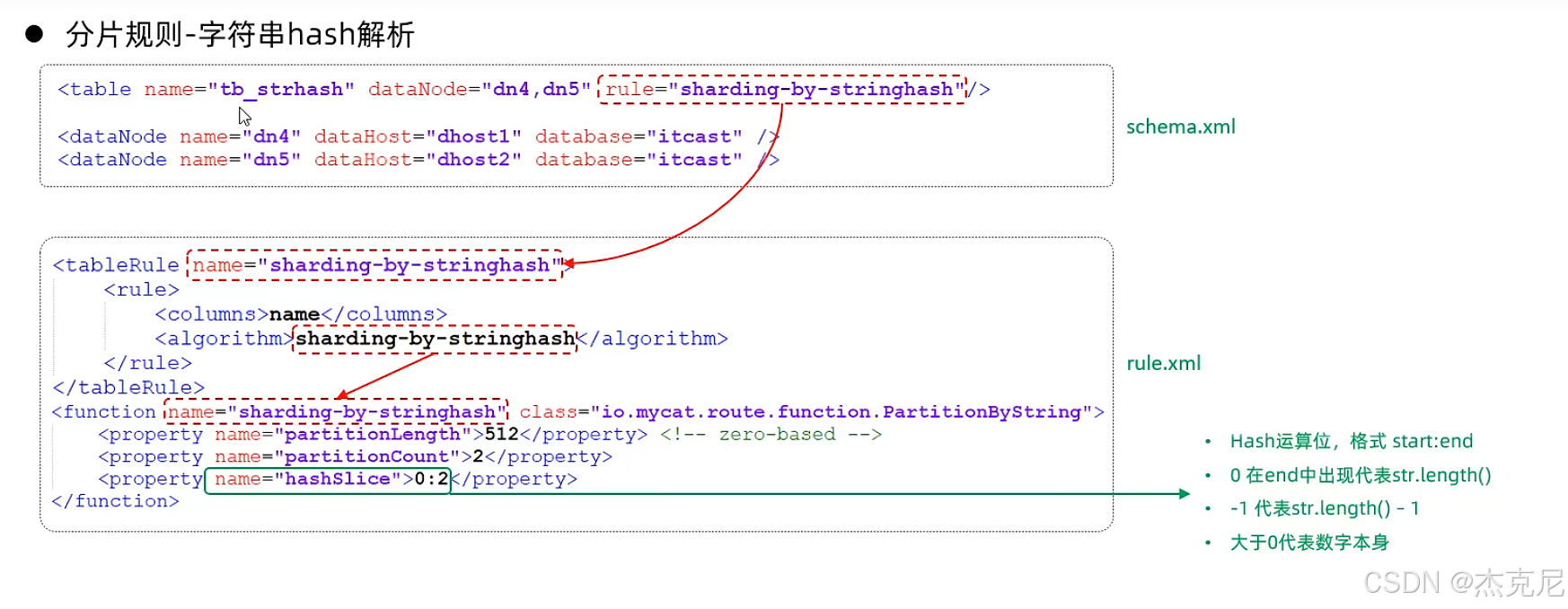
问题
1一致性hash算法和固定hash算法和字符串hash解析区别?



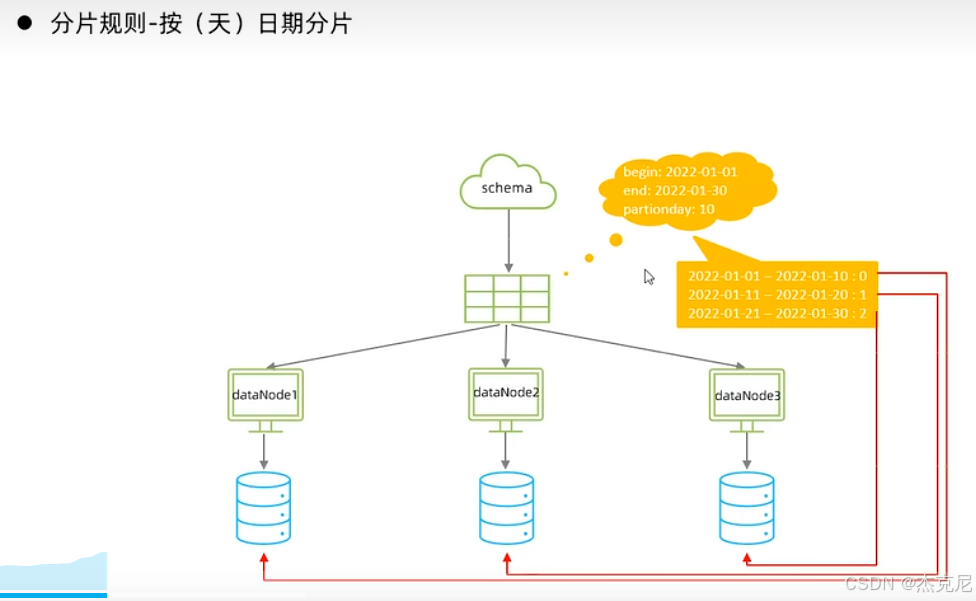
29按天分片

30按自然月分片
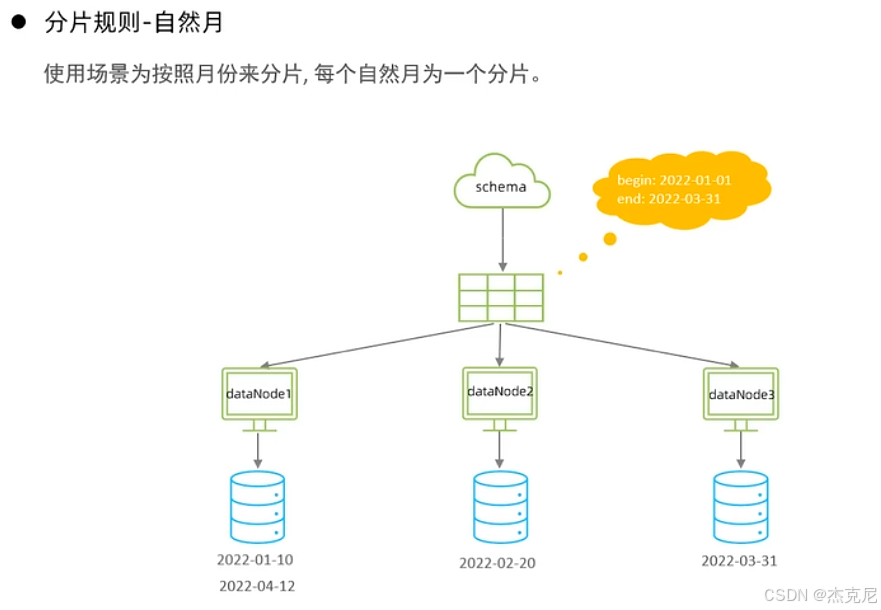
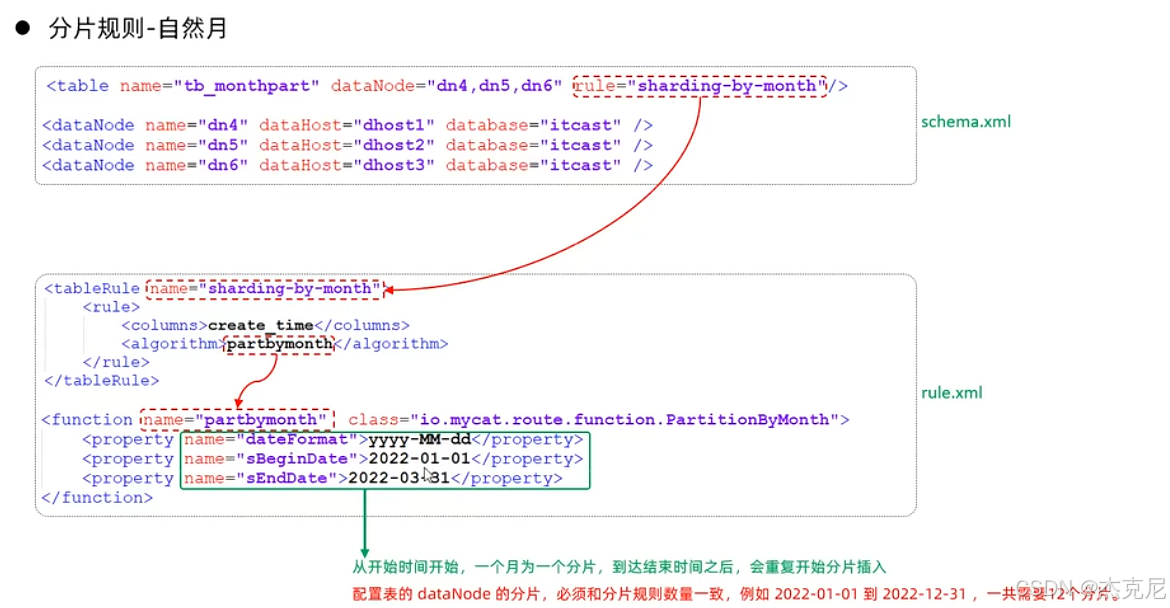
问题:
上图的数量一致是什么意思?

31Mycat管理与监控-原理
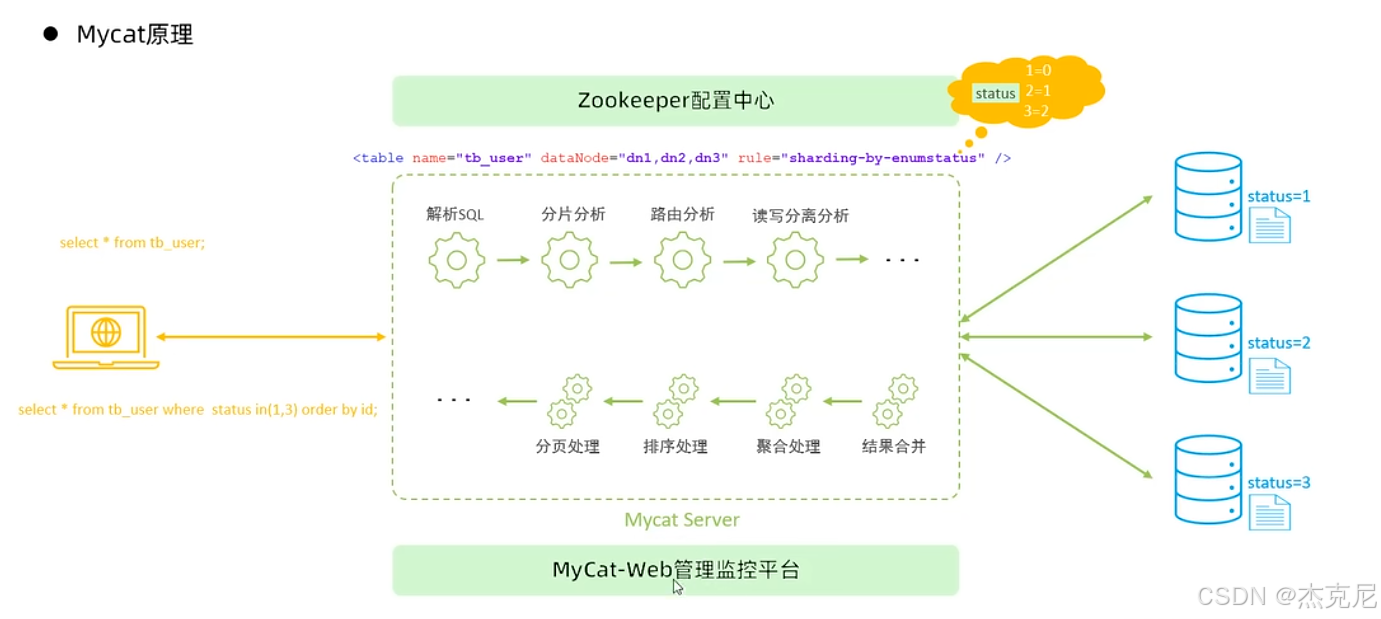
问题:
分片分析是什么意思?

32Mycat管理工具

33Mycat监控1


关键:
需要安装zookeeper
33. 运维-分库分表-MyCat监控1_哔哩哔哩_bilibili
34Mycat监控2
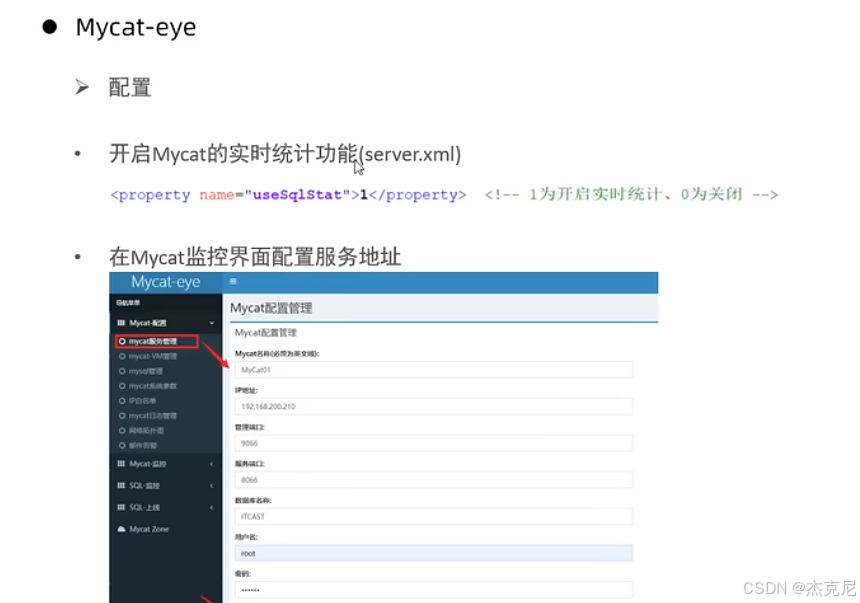
35分库分表总结
36读写分离-介绍

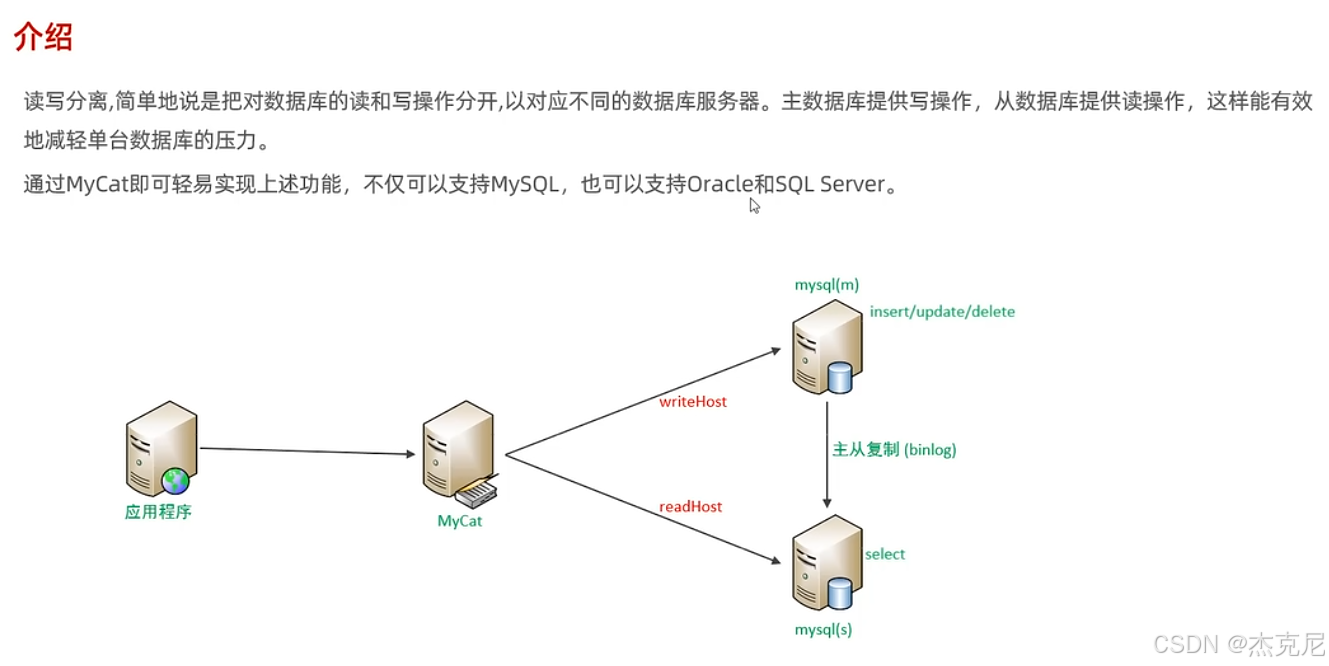
问题:
主从复制的原理?
基于mysql的二进制文件binlog实现的
37一主一从准备
38一主一从分离
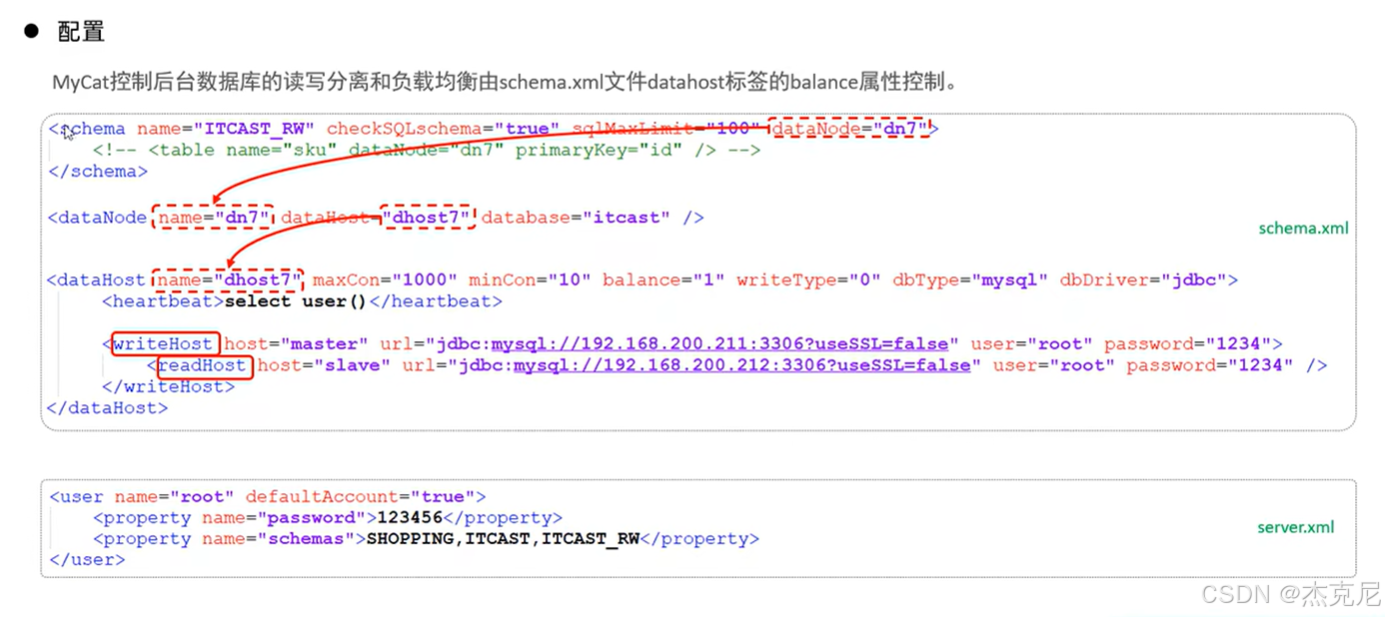
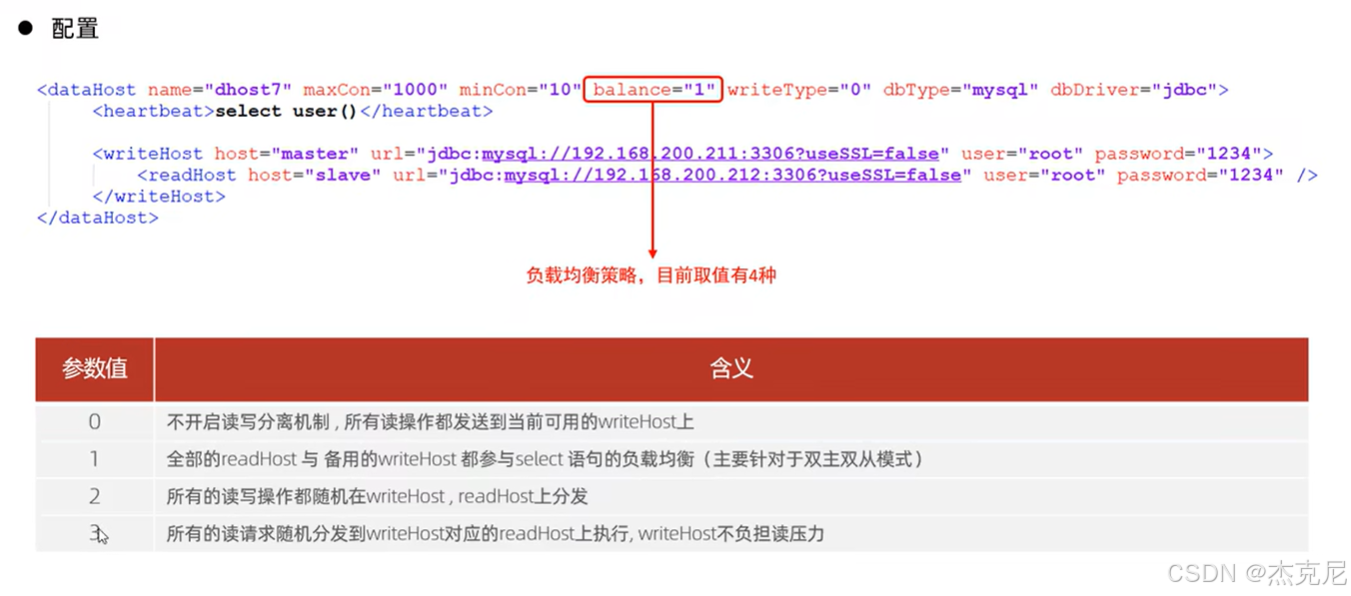
关键:
想要实现读写分离需要将负载均衡的值(balance)设置为1或者3
39双主从介绍
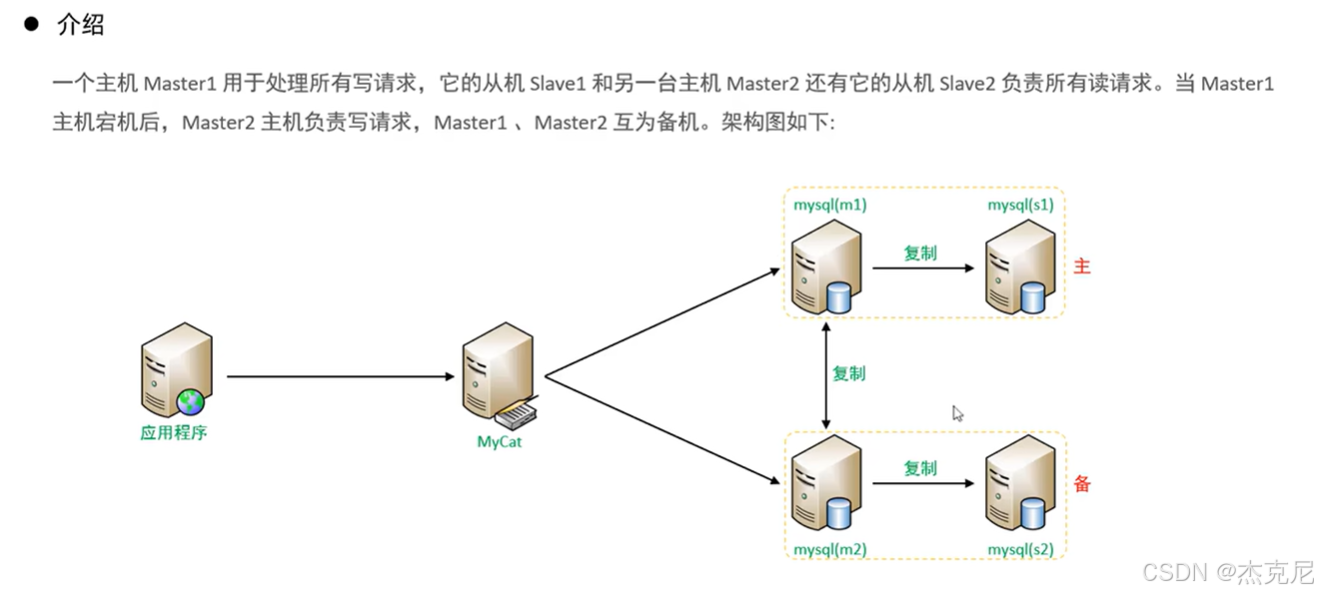
问题:
双主双从比一主一从好在哪里?

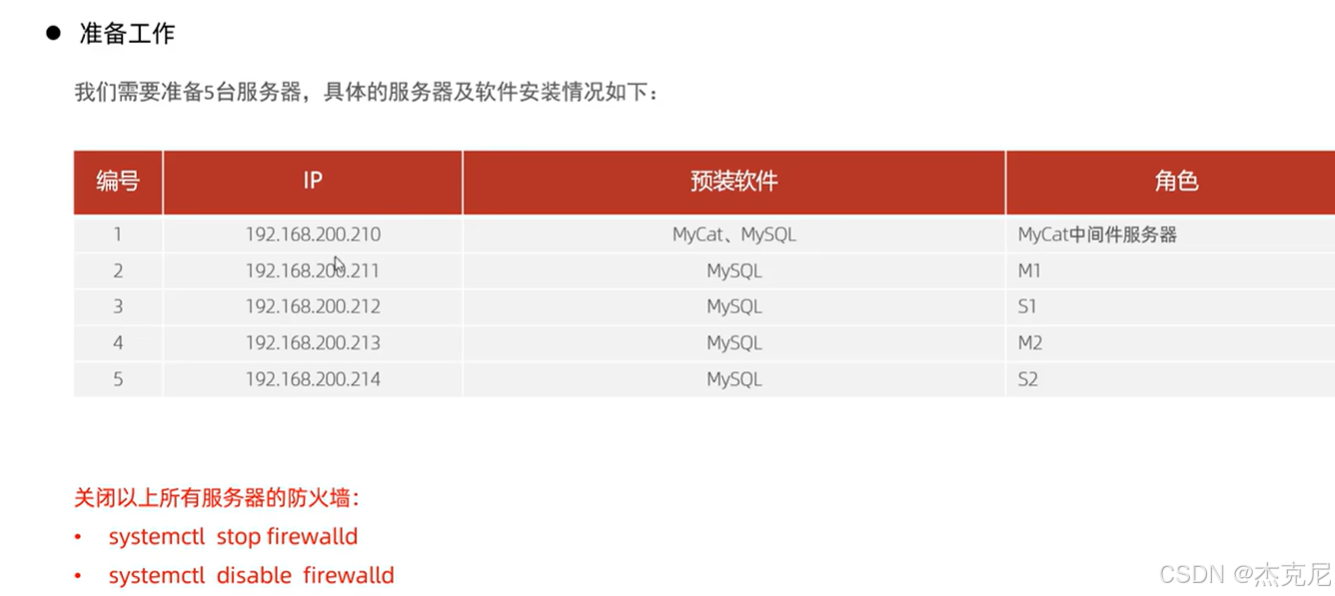
40双主从搭建
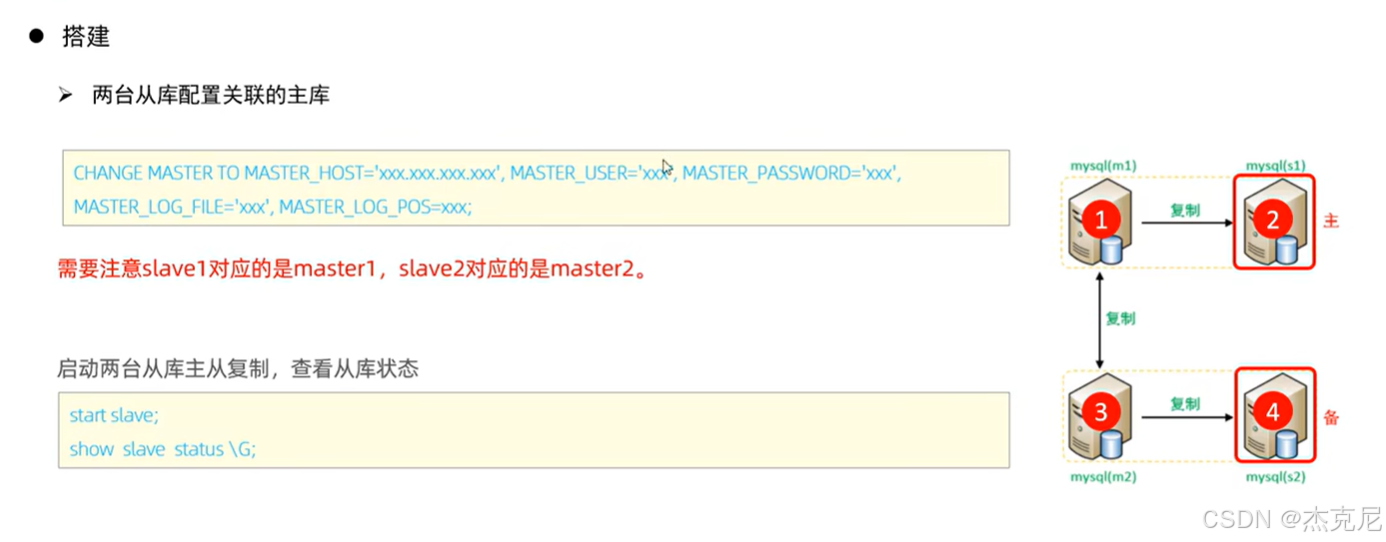
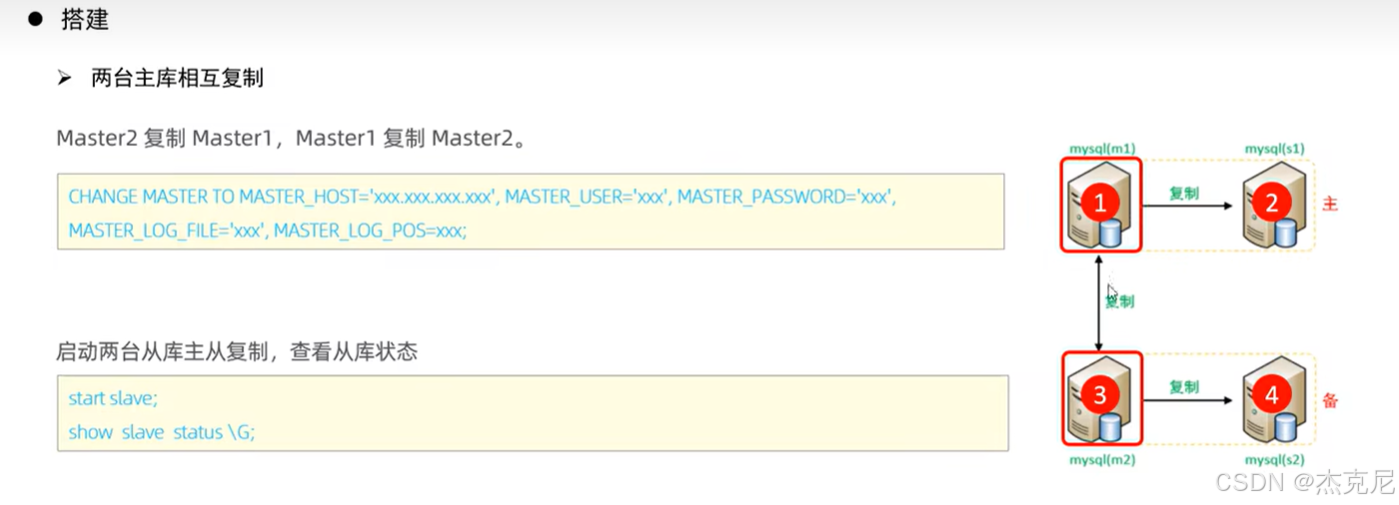
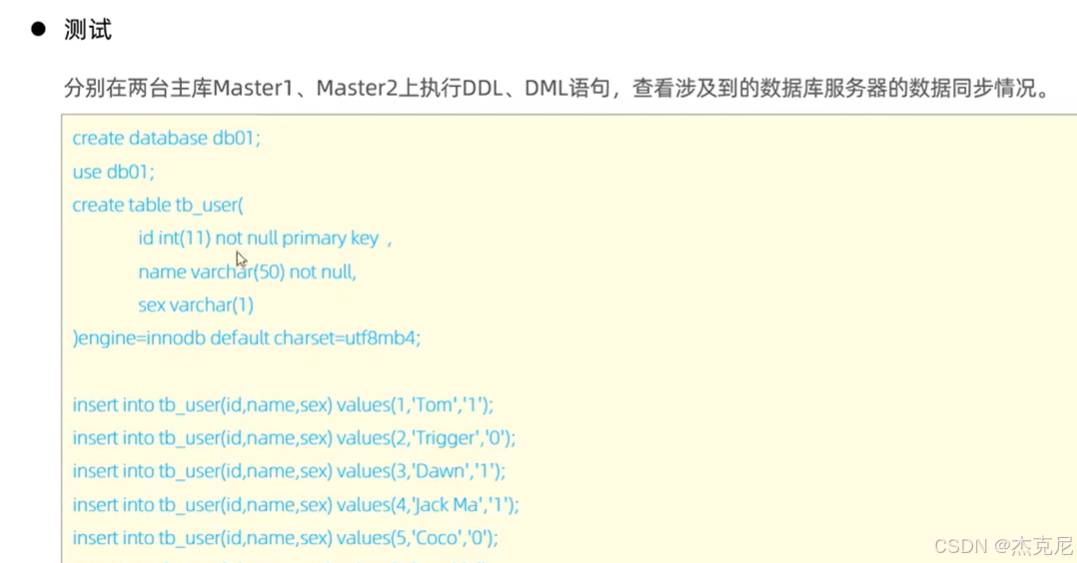
问题:
两台主库相互复制是干什么的?

41双主从读写分离
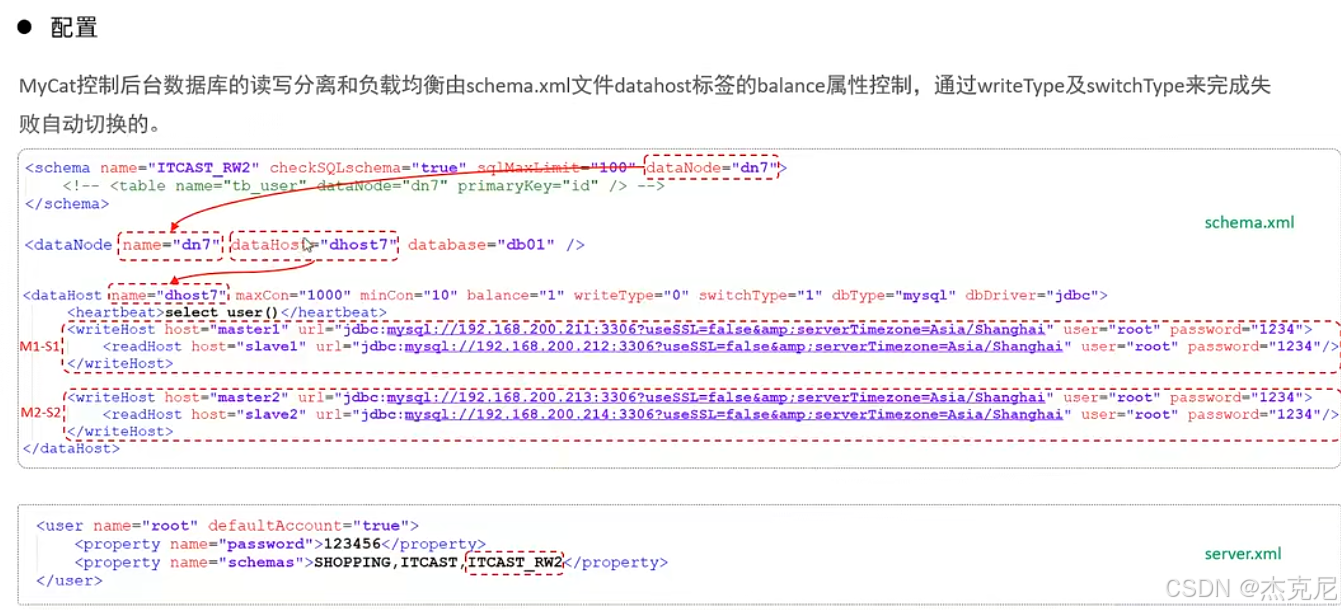
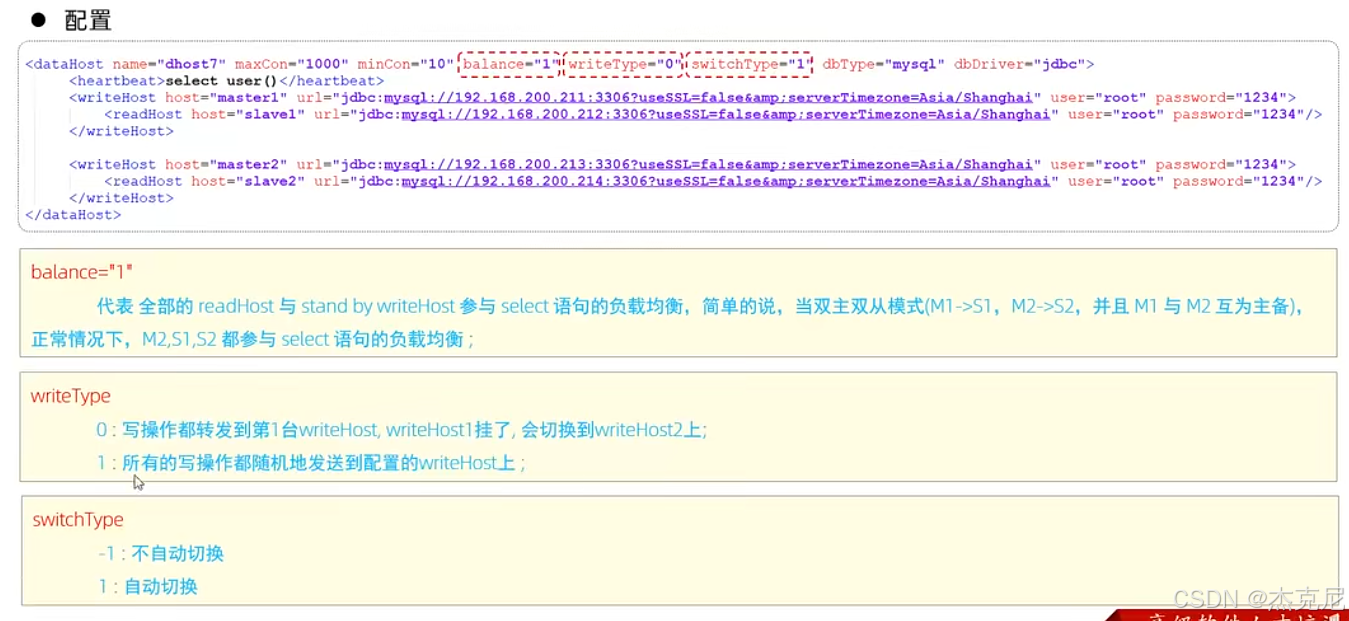
问题:
这个自动切换是什么意思?
就是当writeHost1挂掉之后,会不会自动切换到writeHost2
42读写分离总结

43运维篇总结

【MySQL 运维 + MyCat 分片】从入门到上手:新手也能看懂的核心知识点总结
大家好,最近在学 MySQL 运维和 MyCat 分片的内容,整理了一份 "人话版" 笔记 ------ 把复杂的技术概念拆成大白话,从日志、主从复制到 MyCat 分库分表,全是新手最容易卡壳的点。
一、MySQL 运维篇:先搞懂 "日志"------ 数据库的 "黑匣子"
学 MySQL 运维,第一步得先搞懂日志:它是数据库的 "操作记录",出问题了全靠它查原因。
- 错误日志:数据库的 "故障报警本"
作用:记录 MySQL 启动、关闭、运行过程中出现的错误(比如启动失败、连接异常)。
新手场景:如果 MySQL 突然连不上,先去看错误日志 ------ 比如日志里写 "端口 3306 被占用",那就是端口冲突了;写 "权限不足",就是账号密码错了。
- 二进制日志(binlog):数据库的 "操作录像机"
作用:记录所有对数据库的 "写操作"(增删改),是主从复制、数据恢复的核心。
通俗理解:你在数据库里执行insert加了条数据,binlog 就会记下来 "几点几分,哪个用户,往哪个表插了什么数据";要是数据库崩了,能通过 binlog 把数据恢复到崩溃前的状态。
新手注意:binlog 默认是关闭的,要手动开启(配置文件里加log_bin=mysql-bin),否则主从复制用不了。
- 查询日志:数据库的 "访问记录表"
作用:记录所有发送到 MySQL 的 SQL 语句(不管执行成功还是失败)。
适用场景:想知道 "谁在什么时间执行了什么 SQL",就看查询日志;但它会占很多磁盘空间,生产环境别开(测试环境可以临时开)。
- 慢查询日志:数据库的 "性能体检报告"
作用:记录 "执行时间超过指定阈值" 的 SQL(默认是 1 秒),是优化 SQL 性能的关键。
新手场景:如果网站突然变卡,先查慢查询日志 ------ 比如里面有个select * from user where age>20执行了 5 秒,那就是这条 SQL 没加索引,得优化。
二、主从复制:让数据库 "分身",解决 "读写卡" 问题
主从复制是 MySQL 高可用的基础 ------ 简单说就是 "让一个数据库(主库)的数据,自动同步到其他数据库(从库)"。
- 主从复制的核心作用
读写分离:主库负责 "写操作"(增删改),从库负责 "读操作"(查数据),解决单库 "读写冲突" 的问题;
数据备份:从库是主库的备份,主库崩了能从从库恢复;
负载均衡:多个从库可以分摊读请求,比如电商网站的 "商品列表查询" 全走从库,主库只处理下单。
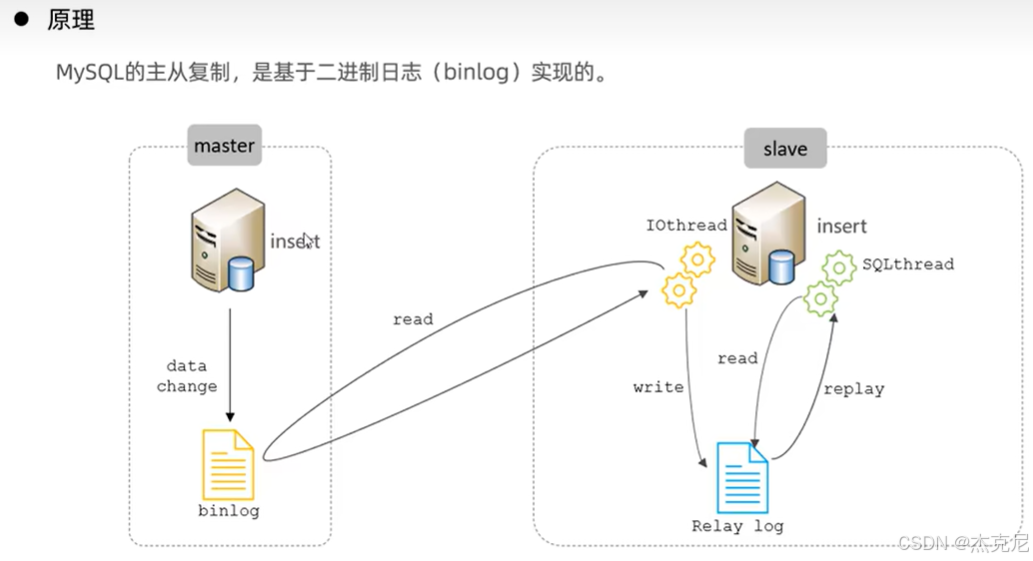
- 主从复制的原理(新手版三步拆解)
很多教程把主从复制讲得很复杂,其实核心就 3 步:
第一步:主库写 binlog
主库执行写操作后,会把操作记录到自己的 binlog 里;
第二步:从库 "读" 主库的 binlog
从库启动一个 "IO 线程",去主库那里把 binlog 复制到自己的 "中继日志(relay log)" 里;
第三步:从库 "执行" 中继日志
从库再启动一个 "SQL 线程",把中继日志里的操作在自己身上执行一遍 ------ 这样从库的数据就和主库同步了。
- 主从复制的配置(新手必看细节)
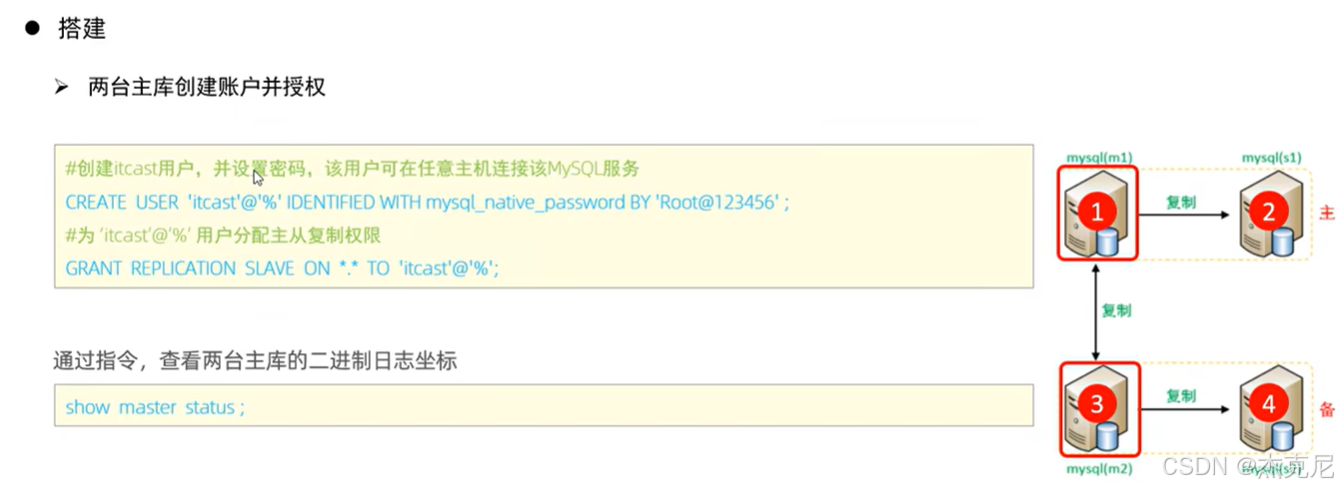
(1)主库配置:打开 "数据同步开关"
开启 binlog(配置文件加log_bin=mysql-bin);
给从库创建一个 "同步账号"(比如账号repl,密码123456,权限是REPLICATION SLAVE);
重启主库,记录主库的 binlog 文件名和位置(用show master status;查看)。
(2)从库配置:"绑定" 主库,开启同步
配置文件里加read_only=1(从库只读):这是为了防止从库被误写,保证从库数据和主库一致;
执行CHANGE MASTER TO命令,把主库的 IP、同步账号、binlog 文件名 / 位置填进去;
启动从库同步(start slave;),用show slave status\G;查看状态 ------ 如果Slave_IO_Running和Slave_SQL_Running都是Yes,就成功了。
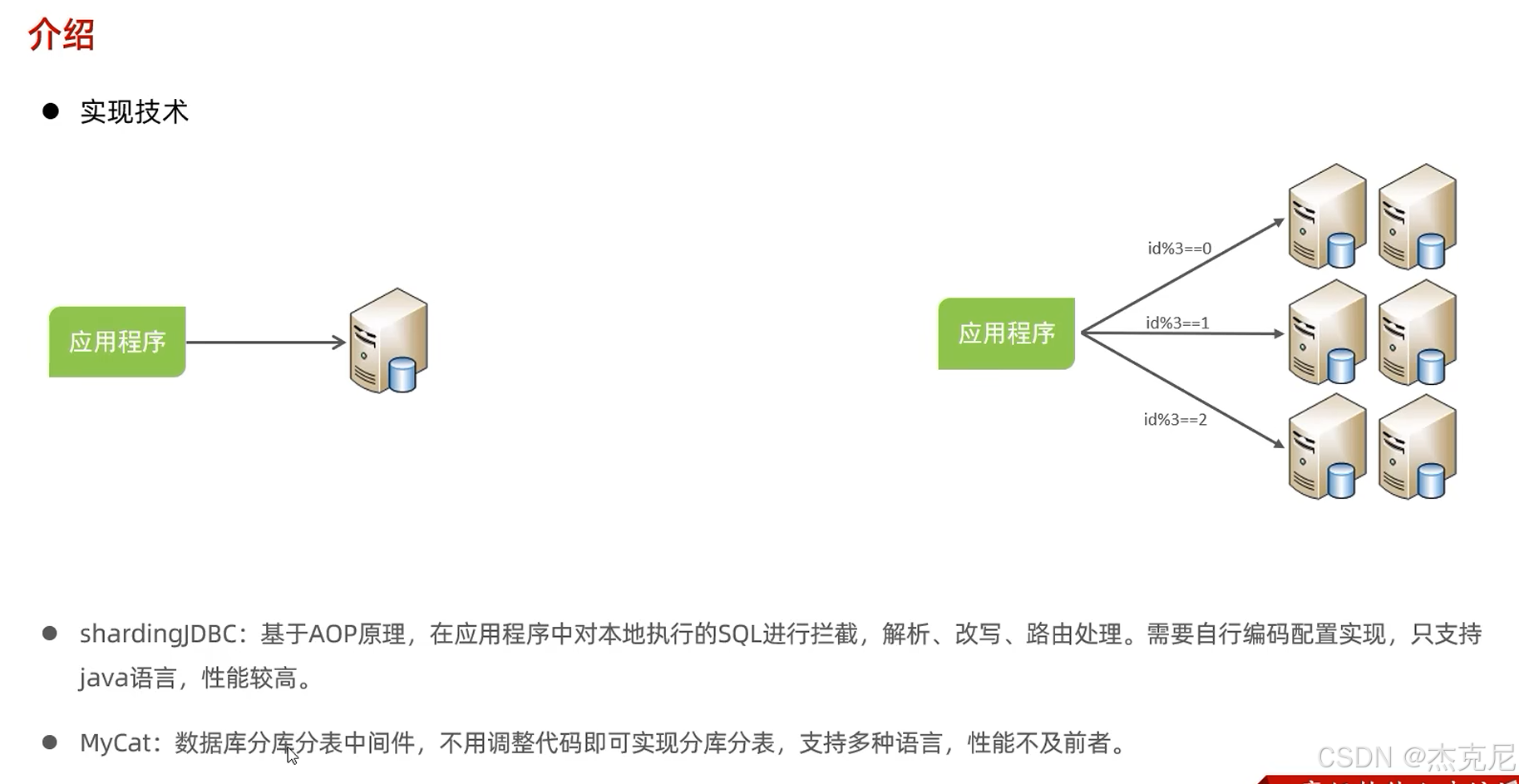
三、MyCat:让 MySQL "变大"------ 分库分表的 "中间件工具"
当数据量超过 1000 万,单库单表会越来越卡,这时候就得用 MyCat 做分库分表------ 把一个大表拆成多个小表,分散到不同数据库里。
- MyCat 的核心概念(先搞懂这几个词)
xml 配置文件:MyCat 的 "规则手册",都放在 MyCat 的conf目录下:
schema.xml:定义数据库、表的结构;
rule.xml:定义分库分表的规则;
server.xml:定义用户、权限;
分片节点(dataNode):就是 "拆分后的数据存储位置"------ 比如把user表拆成 2 个分片,每个分片对应一个dataNode(可以理解为 "一个分片 = 一个小数据库");
分片算法:决定 "数据该分到哪个分片" 的规则 ------ 比如按用户 ID 取模(ID 是偶数分到分片 1,奇数分到分片 2)、按时间分片(1 月的数据分到分片 1,2 月分到分片 2)。
- 分库分表的两种方式
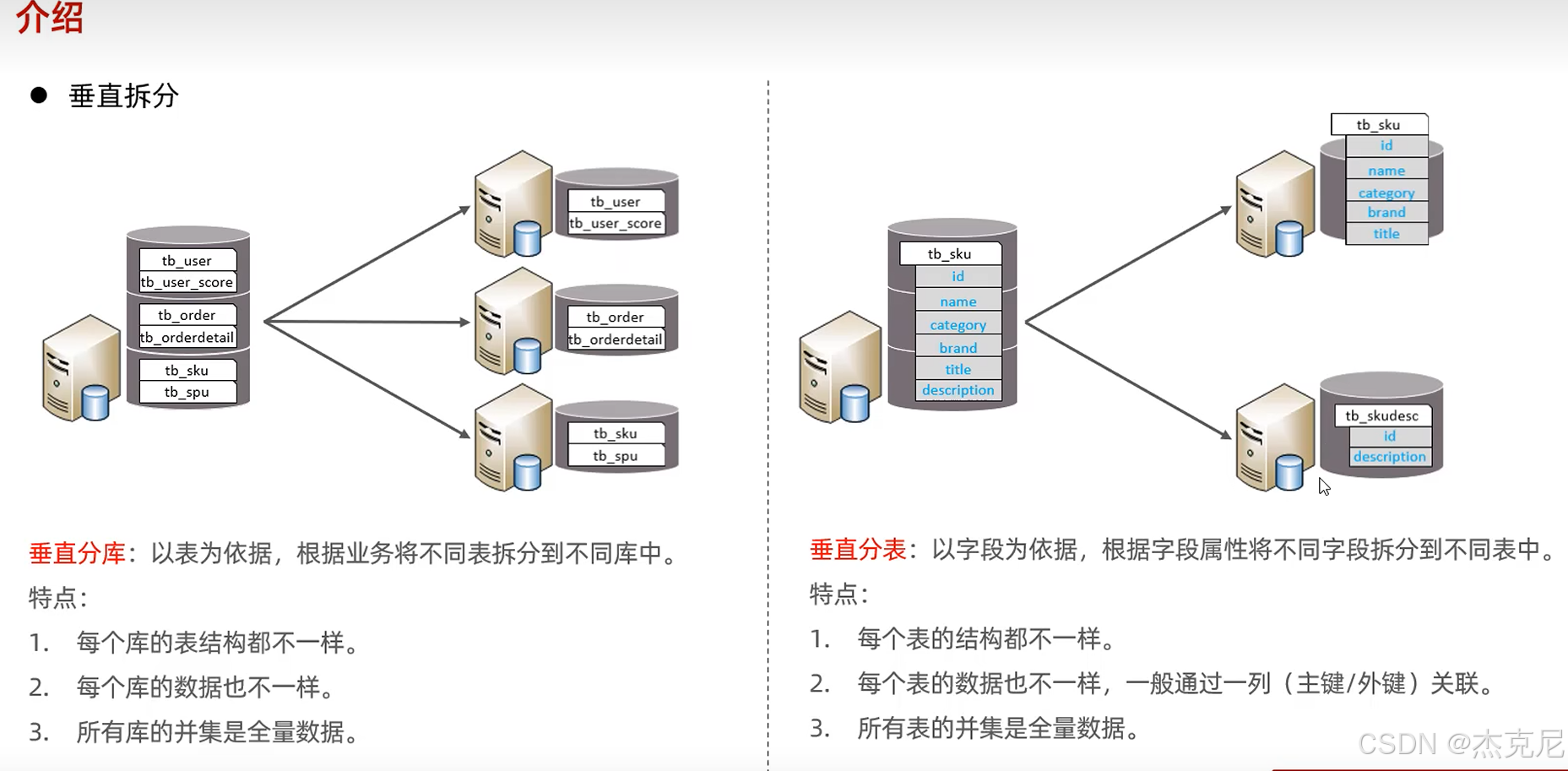
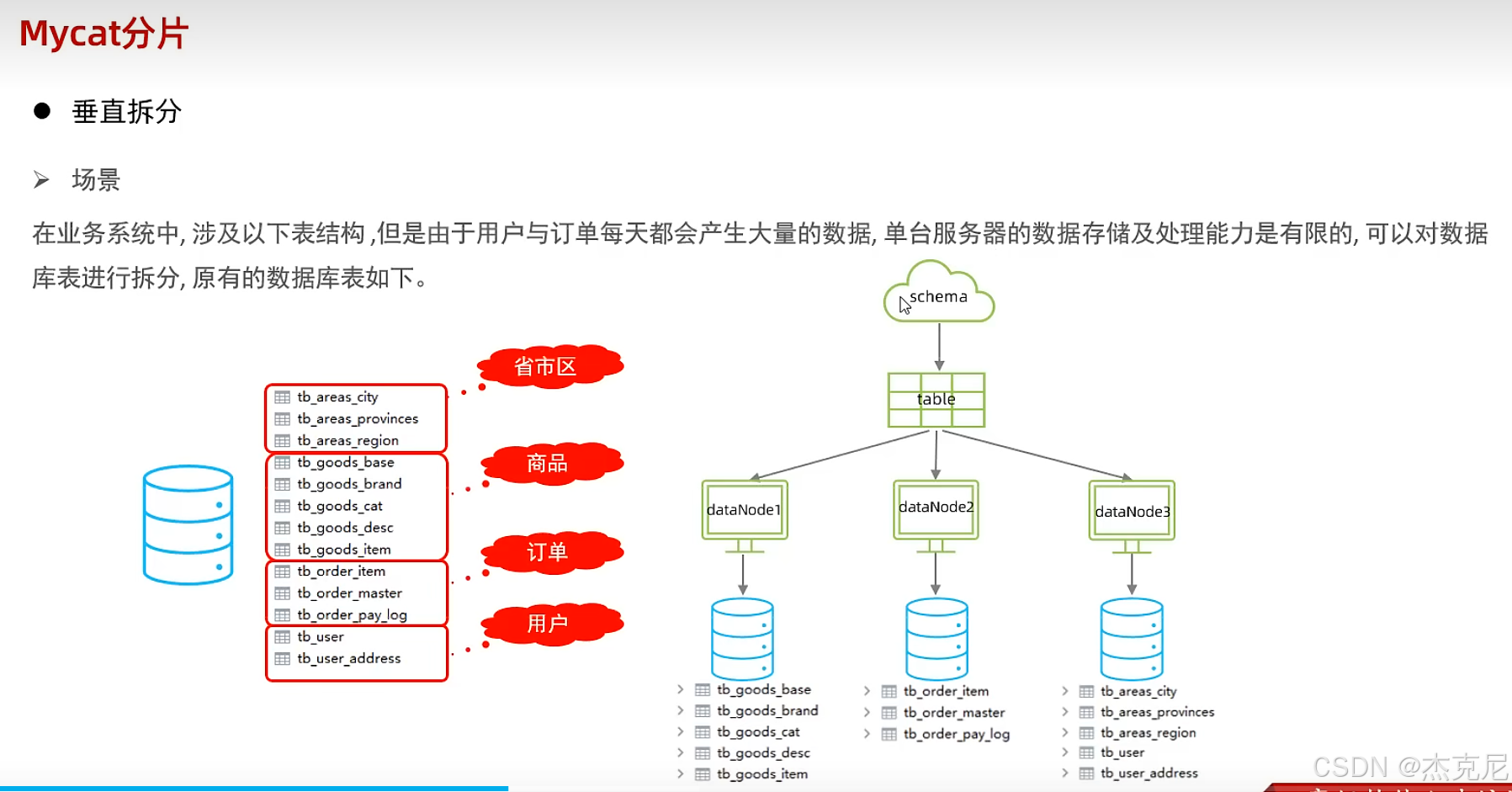
(1)垂直分库:按 "业务模块" 拆
把不同业务的表放到不同数据库里 ------ 比如电商系统,把 "用户表" 放一个库,"订单表" 放另一个库,"商品表" 放第三个库。
作用:解决 "单库压力大" 的问题,比如订单表数据多,不会影响用户表的查询。
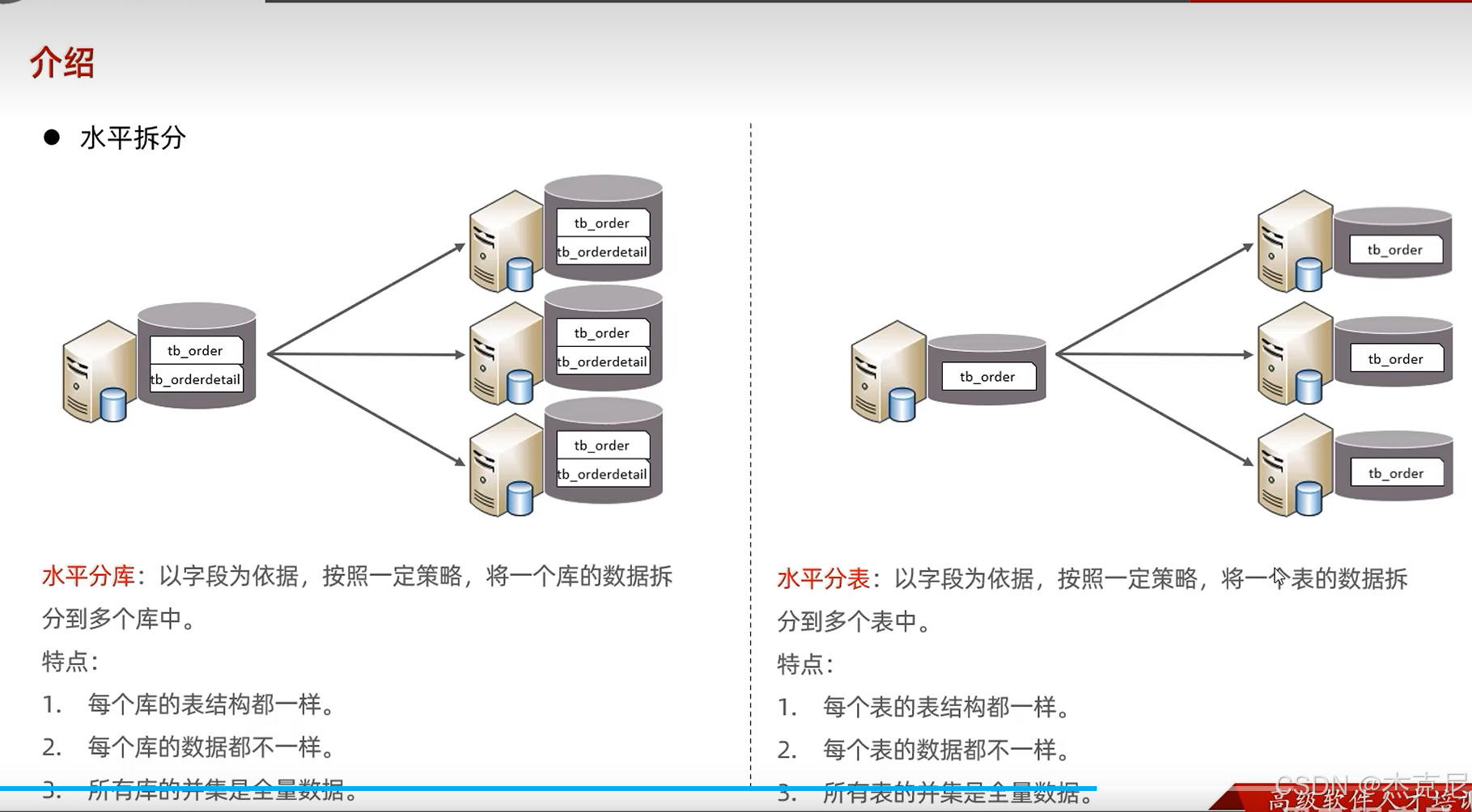
(2)水平分表:把 "大表拆成小表"
把一个大表拆成多个结构一样的小表 ------ 比如把 1 亿条数据的user表,按 ID 取模拆成 10 个小表(user_1到user_10),每个表存 1000 万条数据。
作用:解决 "单表数据太多" 的问题,比如查user表时,不用扫 1 亿条,只扫 1000 万条。
- 常见的分片算法(新手必知 3 种)
(1)范围分片:按 "数值区间" 分
比如把 ID 在 1-100 万的分到分片 1,101 万 - 200 万的分到分片 2;
适用场景:数据按顺序增长(比如 ID 自增),但要注意 "后期分片会越来越大"(比如分片 1 存满 100 万后,新数据全部分到分片 2)。
(2)取模分片:按 "余数" 分
比如 ID 对 2 取模,余数 0 分到分片 1,余数 1 分到分片 2;
适用场景:数据分布均匀,不会出现某个分片数据特别多的情况,但扩容时要迁移数据(比如从 2 个分片扩到 3 个,所有数据的分片规则都变了)。
(3)枚举分片:按 "固定值" 分
比如按status字段分:status=1分到分片 1,status=2分到分片 2;
适用场景:字段值是固定枚举(比如状态、地区),但字段值不能太多(否则要建很多分片)。
- 特殊分片场景:字符串、时间怎么分?
字符串分片:把字符串转成哈希值,再用 "取模分片"------ 比如用户昵称转成哈希值,对分片数取模;
时间分片:按天 / 月 / 年分 ------ 比如把 2025-01-01 的订单分到分片 1,2025-01-02 的分到分片 2,适合 "按时间查询" 的场景(比如查某天的订单)。
- MyCat 的 "全局表":解决 "跨分片查公共数据" 的问题
比如 "地区表"(存全国省份、城市),每个分片都需要用 ------ 如果每个分片都存一份,改数据要改多个分片,很麻烦。
全局表:就是在所有分片都存一份的表,MyCat 会自动同步所有分片的全局表数据 ------ 改一次数据,所有分片都更新,适合存 "不常改的公共数据"。
四、双主双从:比 "一主一从" 更稳的高可用架构
一主一从的问题是 "主库崩了业务就停",双主双从就是 "两个主库互备",解决单点故障问题。
- 双主双从的核心:两台主库 "相互复制"
主库 1 和主库 2 互相同步数据(主 1 的 binlog 同步到主 2,主 2 的 binlog 同步到主 1);
平时用主 1 承接写请求,主 2 是备用;主 1 崩了,直接切到主 2,业务无感知;
两个从库分别同步主 1 和主 2 的数据,分摊读请求。
- 双主双从的 "自动切换":不用手动改配置
MyCat 支持 "主库自动切换"------ 当主 1 宕机,MyCat 会自动把写请求转到主 2,从库也会自动切换到同步主 2 的数据,全程不用人工操作,这就是 "高可用" 的核心。
五、MyCat 监控:得知道 "分片有没有出问题"
MyCat 的监控需要依赖 ZooKeeper(分布式协调工具),作用是:
看每个分片的 "运行状态"(有没有崩);
看 SQL 的 "执行情况"(有没有慢 SQL);
看数据的 "同步情况"(分片数据有没有不一致)。
最后:新手学习的 "避坑提醒"
日志别乱开:查询日志和慢查询日志,生产环境尽量别开(占磁盘),出问题再临时开;
主从复制先看状态:show slave status\G;里的两个Yes是关键,不是Yes就重新配置;
分片算法别瞎选:按业务场景选 ------ID 自增用范围,均匀分布用取模,固定值用枚举;
双主双从别忘互复制:两台主库一定要互相同步,否则主库崩了数据会丢。