在MySQL查询优化中,排序(ORDER BY)和分组(GROUP BY)是高频操作,其性能直接影响业务系统的响应速度。本文将结合实操案例,详解MySQL排序机制、Filesort内存/磁盘判定逻辑、排序与分组的优化方案,帮助开发者避开性能陷阱。
一、测试环境准备
先创建测试表并插入数据。以下SQL语句可直接执行:
sql
-- 切换数据库(若martin库不存在,需先执行CREATE DATABASE martin;)
use martin;
-- 删除已存在的表(避免冲突)
drop table if exists t1;
-- 创建测试表t1
CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT,
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
`c` int DEFAULT NULL,
`d` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`), -- 主键索引
KEY `idx_a_b` (`a`,`b`), -- 联合索引(a在前,b在后)
KEY `idx_c` (`c`) -- 单列索引
) ENGINE=InnoDB CHARSET=utf8mb4 ;
-- 创建批量插入数据的存储过程
drop procedure if exists insert_t1;
delimiter ;;
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=10000)do -- 插入10000条数据
insert into t1(a,b,c) values(i,i,i);
set i=i+1;
end while;
end;;
delimiter ;
-- 调用存储过程插入数据
call insert_t1();
-- 模拟部分数据更新(制造数据差异性)
update t1 set a=1000 where id >9000;二、MySQL的两种排序方式
MySQL针对ORDER BY操作,主要采用两种排序策略,核心区别在于是否利用索引。
1. 有序索引直接返回有序数据
当排序字段存在索引时,MySQL可直接通过索引的有序性返回结果,无需额外排序操作,性能最优。
案例验证
以c字段(有idx_c索引)为例,执行排序查询并分析执行计划:
sql
explain select id,c from t1 order by c;执行计划分析

type列显示index,表示使用索引扫描;Extra列无Using filesort,说明未触发额外排序,直接利用索引有序性。
2. 通过Filesort进行排序
当排序字段无索引 时,MySQL需先读取数据到内存/磁盘,再进行排序,此过程称为Filesort,性能较差。
案例验证
以d字段(无索引)为例,执行排序查询并分析执行计划:
sql
explain select id,d from t1 order by d;执行计划分析

type列显示ALL,表示全表扫描;Extra列出现Using filesort,说明触发了Filesort排序。
三、Filesort:在内存还是磁盘中执行?
很多开发者误以为Filesort一定在磁盘中执行,实则不然------其执行位置由排序数据大小 与sort_buffer_size配置共同决定。
1. 核心判定逻辑
- 若排序数据总大小 ≤
sort_buffer_size:内存排序(效率高); - 若排序数据总大小 >
sort_buffer_size:磁盘排序(需临时文件,效率低)。
2. 查看sort_buffer_size配置
sql
show global variables like "sort_buffer_size";查询结果
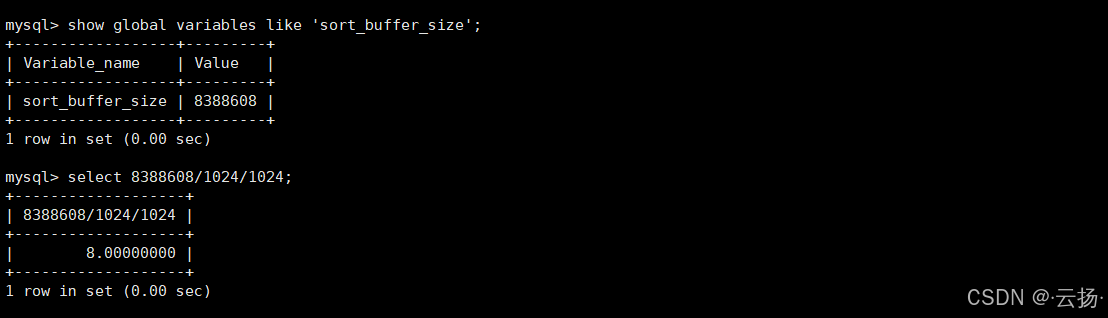
- 默认值通常为262144字节(256KB),可根据业务需求调整,但需避免过大导致服务器Swap。
3. 实操验证:内存排序 vs 磁盘排序
通过optimizer_trace工具可追踪Filesort的执行细节。
(1)内存排序案例
- 开启trace追踪:
sql
set session optimizer_trace="enabled=on",end_markers_in_json=on;- 执行排序查询(
d字段无索引):
sql
select id,d from t1 order by d;- 查看trace结果:
sql
SELECT * FROM information_schema.OPTIMIZER_TRACE\G结果分析
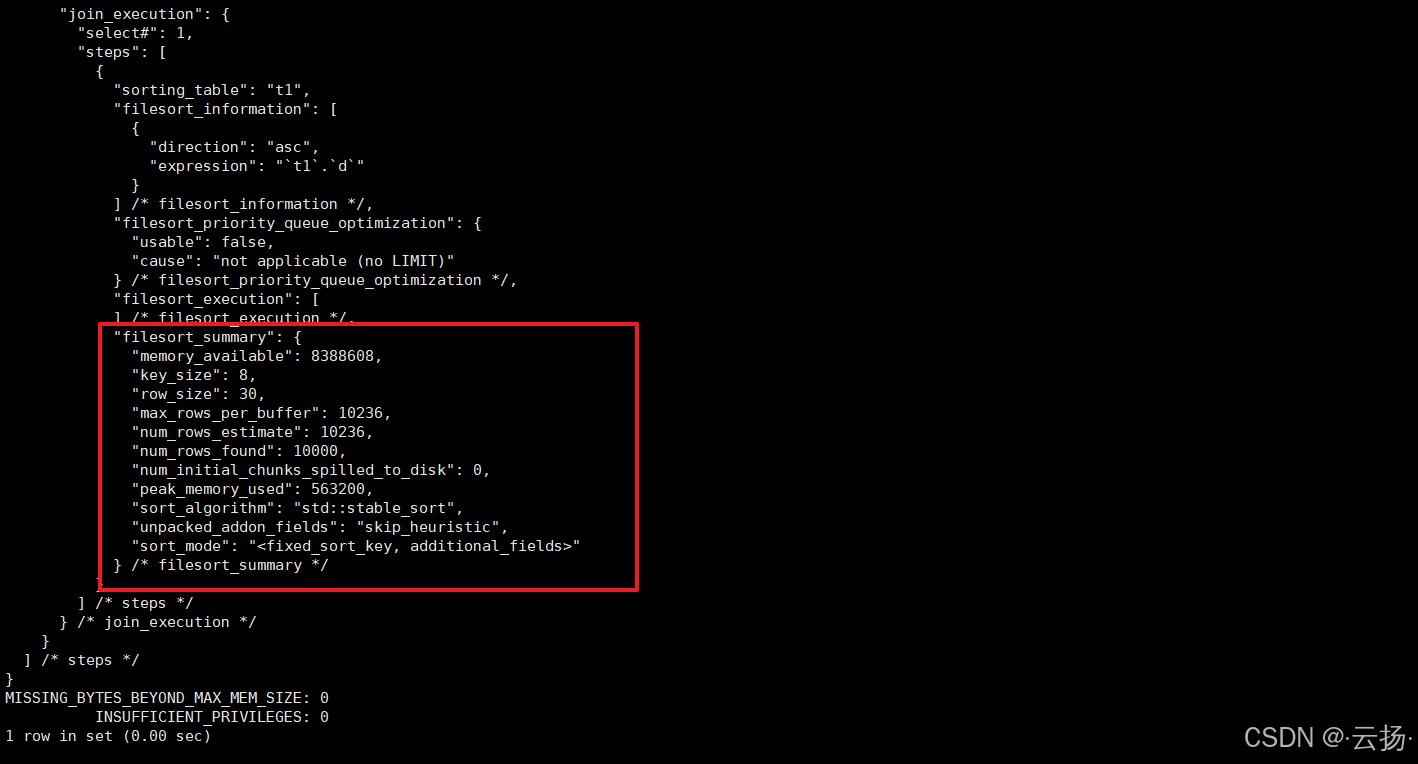
- 若
num_initial_chunks_spilled_to_disk为0,表示排序在内存中完成,未使用磁盘临时文件。 - 若
num_initial_chunks_spilled_to_disk> 0:表示内存不足,部分数据需写入磁盘临时文件,属于 "磁盘排序"。
(2)磁盘排序案例
- 缩小
sort_buffer_size(强制触发磁盘排序):
sql
set sort_buffer_size=32768; -- 设置为32KB- 重复上述排序查询与trace查看:
sql
select id,d from t1 order by d;
SELECT * FROM information_schema.OPTIMIZER_TRACE\G结果分析
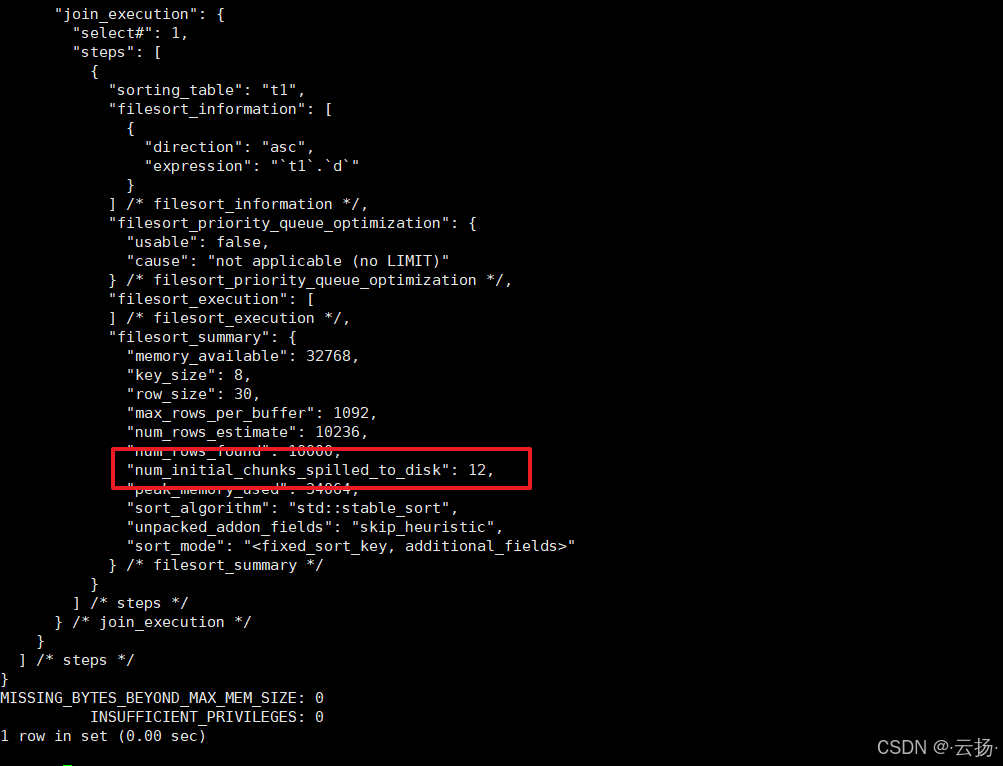
num_initial_chunks_spilled_to_disk的值为12,说明排序过程使用了磁盘临时文件。
四、排序字段字节数参考
计算排序数据总大小时,需了解不同字段类型的字节占用,避免误判sort_buffer_size是否足够。
| 字段类型 | 字节占用 | 说明 |
|---|---|---|
| INT | 4 | 整数类型 |
| BIGINT | 8 | 长整数类型 |
| DECIMAL(M,D) | M+2 | 高精度小数,M为总位数 |
| DATETIME | 8 | 日期时间类型(如本文d字段) |
| TIMESTAMP | 4 | 时间戳类型(需注意时区) |
| CHAR(M) | M | 定长字符串 |
| VARCHAR(M) | M | 变长字符串(实际按内容算) |
五、ORDER BY性能优化实践
优化ORDER BY的核心思路是:尽量利用索引排序,避免Filesort;若无法避免,则优化Filesort效率。
1. 排序字段添加索引
这是最直接的优化方式------为ORDER BY后的字段创建索引,直接跳过Filesort。
案例对比
-
无索引(
d字段):explain select d,id from t1 order by d;结果:
Using filesort

-
有索引(
c字段):explain select c,id from t1 order by c;结果:无
Using filesort

2. 多字段排序:联合索引匹配顺序
多字段排序(如order by a,b)需创建联合索引 ,且索引中字段顺序需与排序顺序完全一致。
案例验证
-
无匹配联合索引(排序
a,c,索引为idx_a_b):sqlexplain select id,a,c from t1 order by a,c;结果:
Using filesort

-
有匹配联合索引(排序
a,b,索引为idx_a_b):sqlexplain select id,a,b from t1 order by a,b;结果:无
Using filesort

3. 先等值查询再排序:联合索引覆盖条件+排序
对于where 条件 + order by的语句(如where a=1000 order by d),可创建"条件字段+排序字段"的联合索引,同时覆盖查询条件与排序需求。
案例对比
-
无联合索引:
sqlexplain select id,a,d from t1 where a=1000 order by d;结果:
Using filesort

-
有联合索引(
idx_a_b覆盖a=1000和order by b):sqlexplain select id,a,b from t1 where a=1000 order by b;结果:无
Using filesort

4. 去掉不必要的返回字段
若查询select *,MySQL需回表获取所有字段,可能放弃使用索引(成本高于全表扫描)。应只返回必要字段,利用索引覆盖优化。
案例对比
-
select *(全字段):sqlexplain select * from t1 order by a,b;结果:
Using filesort

-
select id,a,b(必要字段,索引覆盖):sqlexplain select id,a,b from t1 order by a,b;结果:无
Using filesort

5. 合理调整参数
sort_buffer_size:适当调大(如1MB),尽量让Filesort在内存中执行,但避免超过物理内存导致Swap;max_length_for_sort_data:MySQL 8.0.20前用于控制Filesort算法(行排序/字段排序),8.0.20后已弃用,无需调整。
查看max_length_for_sort_data:
sql
show global variables like 'max_length_for_sort_data';
六、无法利用索引排序的典型场景
即使创建了索引,以下场景也无法利用索引排序,需特别注意。
1. 范围查询后排序
若where子句中对索引字段使用范围查询(如a>9000),后续order by将无法利用该索引。
案例验证
sql
explain select id,a,b from t1 where a>9000 order by b;结果分析

where a>9000为范围查询,破坏了索引idx_a_b的有序性,后续order by b触发Using filesort。
2. 正序与倒序混合使用
联合索引字段排序时,若同时使用asc(正序)和desc(倒序),索引有序性失效。
案例验证
sql
explain select id,a,b from t1 order by a asc,b desc;结果分析

a asc与b desc混合排序,无法利用idx_a_b索引,触发Using filesort。
七、GROUP BY与索引的关系
GROUP BY的性能瓶颈在于是否创建临时表,而索引是关键影响因素。
1. Group by字段无索引
- 执行逻辑:全表扫描 → 创建临时表 → 临时表中分组(确保同组数据连续) → 聚合计算;
- 执行计划特征:
Extra列出现Using temporary(临时表)和Using filesort(排序分组)。
2. Group by字段有索引
- 执行逻辑:利用索引有序性,同组数据天然连续 → 直接分组聚合,无需临时表;
- 执行计划特征:无
Using temporary和Using filesort,性能显著提升。
注意 :需确保所有GROUP BY字段属于同一索引。
八、GROUP BY优化技巧
- 合理使用索引 :为
GROUP BY字段创建索引(或联合索引),避免临时表; - 避免不必要的列 :
SELECT和GROUP BY中只保留必要字段,减少数据处理量; - 提前过滤数据 :用
WHERE子句(如where a>100)减少分组前的数据量,降低分组成本。
结语
MySQL的排序与分组优化,核心是**"索引优先,避免Filesort和临时表"**。实际开发中,需结合业务场景设计合理的索引(单列/联合),调整关键参数(如sort_buffer_size),并通过explain和optimizer_trace工具验证优化效果。本文案例均基于实操可复现,建议开发者动手实践,加深对MySQL执行逻辑的理解,从而写出更高性能的SQL。