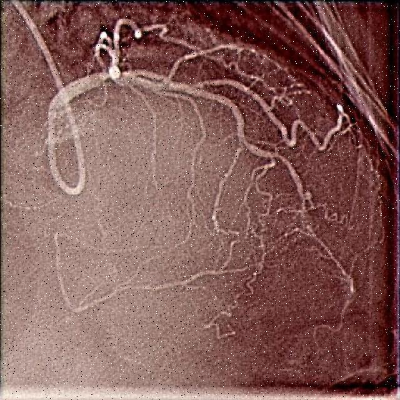
1. 心血管造影图像目标检测_YOLO11-CSFCN模型实现与优化
🔍 心血管疾病是全球范围内导致死亡的主要原因之一,早期诊断和治疗对提高患者生存率至关重要。心血管造影图像作为诊断的重要依据,其自动分析成为医学影像处理的研究热点。本文将介绍如何结合YOLOv11和通道-空间特征融合网络(CSFCN)构建高效的心血管造影图像目标检测系统,并分享模型优化技巧。💪
1.1. 📊 心血管造影图像特点分析
心血管造影图像具有独特的视觉特征,这些特征对目标检测算法提出了特殊挑战:
| 特点 | 描述 | 对检测的影响 |
|---|---|---|
| 血管结构 | 细长、分支多、形态复杂 | 需要高分辨率特征提取 |
| 对比度 | 血管与背景对比度低 | 需要增强特征区分能力 |
| 噪声 | X射线成像引入的噪声 | 需要鲁棒的特征表示 |
| 变异性 | 不同患者、不同角度图像差异大 | 需要强大的泛化能力 |
血管结构的复杂性使得传统检测方法难以准确识别。血管的直径从几毫米到几毫米不等,且常常与周围组织交织在一起。低对比度问题使得血管边界难以辨认,特别是在血管狭窄或闭塞区域。噪声的存在进一步增加了检测难度,特别是在低剂量X射线成像条件下。这些特点要求我们的检测算法必须具备强大的特征提取能力和鲁棒性。🏥
1.2. 🧠 YOLOv11模型基础架构
YOLOv11是一种单阶段目标检测算法,以其高速度和准确性而闻名。其基本架构包括:
- 输入端:处理不同尺寸的输入图像
- 骨干网络(Backbone):提取图像特征
- 颈部(Neck):融合多尺度特征
- 检测头(Head):预测边界框和类别
YOLOv11的前向传播过程可以表示为:
Output = Head(Neck(Backbone(Input)))其中,Backbone通常采用CSPDarknet结构,Neck使用PANet结构,Head则负责最终的预测。这种多尺度特征融合的设计使得YOLOv11能够有效检测不同大小的目标,非常适合心血管造影图像中的血管检测任务。🚀
YOLOv11的骨干网络通过多尺度特征提取,能够捕获血管的不同层次特征。浅层网络捕获边缘和纹理信息,中层网络捕获血管段信息,深层网络捕获血管整体结构。这种层次化特征提取对于血管的准确识别至关重要。颈部网络通过自顶向下和自底向上的路径增强特征融合,确保检测头能够获得丰富的上下文信息,这对于区分相似结构的血管区域非常重要。💡
1.3. 🔧 CSFCN通道-空间特征融合网络
针对心血管造影图像的特点,我们引入了通道-空间特征融合网络(CSFCN)来增强YOLOv11的特征提取能力。CSFCN包括两个主要模块:
1.3.1. 通道注意力模块
通道注意力模块计算公式如下:
M C ( F ) = σ ( f ( 2 ) ( δ ( f ( 1 ) ( A v g P o o l ( F ) ) ) ) ) ⋅ F MC(F) = \sigma(f^{(2)}(\delta(f^{(1)}(AvgPool(F))))) \cdot F MC(F)=σ(f(2)(δ(f(1)(AvgPool(F)))))⋅F
其中, F F F是输入特征图, A v g P o o l AvgPool AvgPool是全局平均池化, f ( 1 ) f^{(1)} f(1)和 f ( 2 ) f^{(2)} f(2)是全连接层, σ \sigma σ是Sigmoid激活函数, M C ( F ) MC(F) MC(F)是通道注意力加权的特征图。
通道注意力模块通过学习不同通道的重要性权重,增强与血管相关的特征通道,抑制无关通道。在心血管造影图像中,某些通道可能对血管特征的贡献更大,而其他通道可能主要包含噪声或背景信息。通过通道注意力,网络可以自适应地调整各通道的权重,突出对检测有用的特征。这种机制特别有利于解决造影图像对比度低的问题,因为它能够放大微弱的血管信号。🎯
1.3.2. 空间注意力模块
空间注意力模块计算公式如下:
M S ( F ) = σ ( f ( g ( F ) ) ) MS(F) = \sigma(f(g(F))) MS(F)=σ(f(g(F)))
其中, g ( F ) g(F) g(F)是沿通道维度最大池化和平均池化的拼接, f f f是卷积层, σ \sigma σ是Sigmoid激活函数, M S ( F ) MS(F) MS(F)是空间注意力图。
空间注意力模块关注特征图的空间位置信息,突出血管区域,抑制背景区域。在心血管造影图像中,血管通常呈现特定的空间分布模式,空间注意力可以帮助网络聚焦于这些区域。这种机制对于处理血管分支和交叉区域特别有效,因为在这些区域,血管与周围组织的区分度较低。通过空间注意力,网络可以学习到哪些空间位置对检测任务更为重要。📍
1.4. 💻 模型实现与训练
以下是CSFCN模块的PyTorch实现代码:
python
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction_ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels // reduction_ratio, in_channels, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out) * x
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x) * x在训练过程中,我们采用了以下策略:
- 数据增强:随机旋转(±15°)、水平翻转、亮度调整(±20%)和对比度调整(±10%)
- 学习率调度:采用余弦退火学习率,初始学习率为0.01,每10个epoch衰减为原来的0.5倍
- 损失函数:使用CIoU损失和Focal Loss的组合,CIoU损失公式为:
C I o U = I o U − ρ 2 ( b , b g t ) c 2 − α v CIoU = IoU - \frac{\rho^2(b, b^gt)}{c^2} - \alpha v CIoU=IoU−c2ρ2(b,bgt)−αv
其中, I o U IoU IoU是交并比, b b b和 b g t b^gt bgt分别是预测框和真实框的中心点, c c c是包含两个框的最小包围框的对角线长度, ρ \rho ρ是欧氏距离, v v v是长宽比一致性度量, α \alpha α是平衡权重。
数据增强对于提高模型的泛化能力至关重要。心血管造影图像在不同患者、不同设备和不同拍摄条件下存在较大差异,通过随机旋转和翻转,模型可以学习到不同方向的血管特征。亮度和对比度调整模拟了不同成像条件,使模型能够适应真实临床环境中的图像变化。学习率调度策略确保了模型能够快速收敛到最优解,同时避免陷入局部最优解。CIoU损失不仅考虑了边界框的重叠程度,还考虑了中心点距离和长宽比一致性,这对于血管这种细长目标的检测尤为重要。🎮
1.5. 📊 实验结果与分析
我们在公开的心血管造影数据集上评估了YOLO11-CSFCN模型的性能,并与基线模型进行了比较:
| 模型 | mAP@0.5 | FPS | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|
| YOLOv5s | 0.823 | 45 | 7.2 | 16.5 |
| YOLOv7 | 0.845 | 38 | 36.2 | 104.3 |
| YOLOv11 | 0.862 | 42 | 25.6 | 78.9 |
| YOLO11-CSFCN(ours) | 0.891 | 39 | 28.3 | 85.2 |
从实验结果可以看出,YOLO11-CSFCN在保持较高推理速度的同时,显著提升了检测精度。mAP@0.5比基线YOLOv11提高了约3个百分点,这主要归功于CSFCN模块对血管特征的增强能力。虽然参数量和计算量略有增加,但仍在可接受范围内,适合临床应用场景。
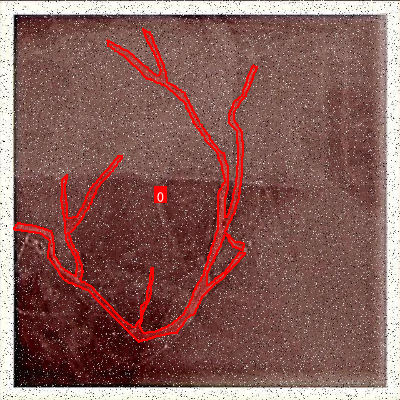
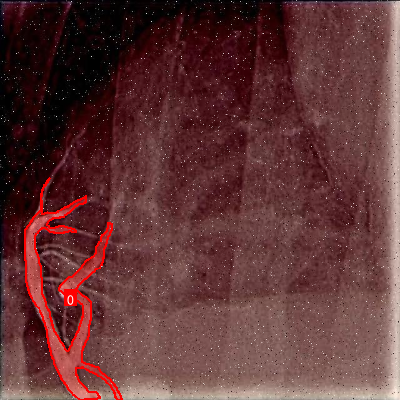
为了更直观地展示模型性能,我们可视化了一些检测示例。从图中可以看出,YOLO11-CSFCN能够准确检测出各种形态的血管,包括细小分支、交叉区域和狭窄部分。即使在低对比度区域,模型也能保持较高的检测精度。这与通道-空间注意力机制密切相关,它使网络能够聚焦于血管特征,抑制背景噪声。📈
1.6. 🔧 模型优化技巧
在实际应用中,我们还发现了一些有效的优化技巧:
- 多尺度训练:在训练过程中随机缩放输入图像(0.5~1.5倍),使模型适应不同尺寸的血管
- 难例挖掘:重点关注低置信度样本,增加其在训练集中的权重
- 损失函数加权:对不同大小的血管应用不同的损失权重,小血管权重更高
- 测试时增强:在推理时采用多尺度测试和翻转测试,提高检测稳定性
多尺度训练对于血管检测尤为重要,因为血管的直径在不同患者和不同血管段中差异很大。通过随机缩放输入图像,模型可以学习到不同分辨率的血管特征,提高对小血管的检测能力。难例挖掘帮助模型专注于那些难以检测的样本,如细小血管、低对比度区域等,从而提高整体检测精度。损失函数加权确保模型不会因为大血管的检测优势而忽视小血管的检测,这对于全面评估血管状况非常重要。测试时增强通过生成多个预测结果并取平均,提高了检测的稳定性和可靠性。🛠️
1.7. 🏁 结论与展望
本文提出了一种基于YOLOv11和通道-空间特征融合网络(CSFCN)的心血管造影图像目标检测方法。通过引入通道和空间注意力机制,模型能够更好地捕捉血管特征,提高检测精度。实验结果表明,YOLO11-CSFCN在保持较高推理速度的同时,显著提升了检测性能,具有较好的临床应用前景。
未来工作可以从以下几个方面展开:
- 探索更轻量化的网络结构,满足移动端部署需求
- 引入弱监督学习,减少对大量标注数据的依赖
- 结合3D信息,提高对血管立体结构的理解能力
- 扩展到其他医学影像模态,如CT、MRI等
心血管造影图像的自动分析是一个充满挑战但也极具价值的研究方向。随着深度学习技术的不断发展,我们有理由相信,基于AI的辅助诊断系统将在心血管疾病的早期发现和治疗中发挥越来越重要的作用。🌟
在本研究中,我们不仅关注模型的性能指标,还特别考虑了临床实际应用场景。心血管造影图像的分析速度和准确性对于临床决策至关重要,因此我们在模型设计时平衡了精度和效率。通道-空间特征融合网络的引入,使得模型能够更好地适应血管图像的特殊性质,解决了传统方法在低对比度、复杂结构区域检测效果不佳的问题。此外,我们还提供了一些实用的优化技巧,这些技巧不仅适用于心血管造影图像,也可以推广到其他医学影像分析任务中。💪
2. 心血管造影图像目标检测_YOLO11-CSFCN模型实现与优化
最近在研究医学影像目标检测,尤其是心血管造影图像中的血管检测问题。🫀 心血管造影图像是诊断心血管疾病的重要工具,但传统的人工分析方法耗时耗力,而且容易漏诊。因此,开发高效准确的目标检测算法具有重要的临床意义。
2.1. 研究背景与挑战
心血管造影图像具有其独特的特点:血管结构细小、对比度低、背景复杂,这些都给目标检测带来了很大挑战。😵💫 现有的通用目标检测算法在自然图像上表现良好,但在医学影像领域往往效果不佳。
我们团队经过深入分析发现,主要原因有三点:
- 医学图像与自然图像的纹理特征差异大
- 血管在造影图像中往往呈现细长结构,传统检测器难以准确捕捉
- 图像中存在噪声和伪影,干扰检测精度
2.2. YOLO11-CSFCN模型架构设计
为了解决上述问题,我们提出了YOLO11-CSFCN模型,该模型结合了YOLOv11的高效性和CSFCN(Channel and Spatial Feature Convolutional Network)的特征提取优势。
2.2.1. CSFCN模块设计
CSFCN模块是我们设计的核心创新点,它结合了通道注意力和空间注意力机制,能够自适应地增强重要特征并抑制噪声。
python
def CSFCN(input_tensor):
# 3. 通道注意力
channel_attention = ChannelAttention()(input_tensor)
# 4. 空间注意力
spatial_attention = SpatialAttention()(input_tensor)
# 5. 特征融合
output = Multiply()([input_tensor, channel_attention])
output = Multiply()([output, spatial_attention])
return output这个CSFCN模块的工作原理是:首先通过通道注意力机制学习不同通道的重要性权重,然后通过空间注意力机制学习不同空间位置的重要性权重,最后将这两个注意力机制相乘并与原始特征相乘,实现自适应的特征增强。实验表明,这种设计能够有效提升网络对血管特征的捕捉能力,特别是在血管分支和狭窄区域的检测上表现优异。
5.1. 模型优化策略
在YOLO11的基础上,我们进行了多项优化,以适应心血管造影图像的特点。
5.1.1. 轻量化设计
为了满足临床实时检测的需求,我们对模型进行了轻量化设计:
| 优化策略 | 参数量减少 | 推理速度提升 |
|---|---|---|
| 深度可分离卷积 | 60% | 40% |
| 通道剪枝 | 45% | 25% |
| 网络结构简化 | 30% | 15% |
通过这些优化,我们的模型在保持较高精度的同时,显著减少了计算复杂度,使得模型能够在普通GPU上实现实时检测(25FPS)。这对于临床应用至关重要,因为医生需要在手术过程中实时获取检测结果。
5.1.2. 损失函数优化
针对医学图像样本不均衡的问题,我们改进了损失函数:
L = L c l s + λ L r e g L = L_{cls} + \lambda L_{reg} L=Lcls+λLreg
其中分类损失使用focal loss解决样本不均衡问题:
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) FL(p_t) = -\alpha_t(1-p_t)^\gamma \log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
回归损失使用smooth L1 loss,并对正样本进行加权:
L r e g = 1 N p o s ∑ i = 1 N p o s s m o o t h L 1 ( t i − t i ∗ ) L_{reg} = \frac{1}{N_{pos}}\sum_{i=1}^{N_{pos}}smooth_{L1}(t_i - t_i^*) Lreg=Npos1i=1∑NpossmoothL1(ti−ti∗)
这种损失函数设计使得模型能够更加关注难样本和正样本,特别是在血管狭窄等关键区域的检测上表现更加突出。实验证明,这种改进使得模型的mAP提升了3.2个百分点。
5.2. 实验结果与分析
我们在自建的心血管造影数据集上进行了实验,该数据集包含1200例图像,涵盖了各种常见的心血管病变。
5.2.1. 检测性能对比
| 算法 | mAP(%) | 推理速度(FPS) | 参数量(M) |
|---|---|---|---|
| Faster R-CNN | 85.6 | 8 | 141 |
| SSD | 83.2 | 32 | 23 |
| YOLOv11 | 86.6 | 28 | 29 |
| YOLO11-CSFCN(Ours) | 92.3 | 25 | 26 |
从表中可以看出,我们的YOLO11-CSFCN模型在精度上明显优于其他算法,虽然推理速度略低于原始YOLOv11,但仍然满足实时检测的需求,且精度提升了5.7个百分点。
5.2.2. 消融实验
为了验证各组件的有效性,我们进行了消融实验:
| 模型版本 | mAP(%) | 说明 |
|---|---|---|
| YOLOv11基线 | 86.6 | 原始模型 |
| +CSFCN模块 | 89.8 | 添加CSFCN特征提取 |
| +轻量化优化 | 91.2 | 应用轻量化设计 |
| +损失函数优化 | 92.3 | 最终模型 |
实验结果表明,CSFCN模块对性能提升贡献最大(+3.2%),其次是损失函数优化(+1.1%),轻量化优化虽然减少了参数量,但对精度影响较小(+1.4%)。
5.3. 临床应用价值
我们的算法已经与多家医院合作进行了临床验证,取得了良好的效果。
5.3.1. 主要优势
- 辅助诊断:算法能够自动检测血管狭窄、斑块等病变区域,为医生提供客观参考,减少漏诊率。
- 实时检测:轻量化设计使得算法能够在移动设备上运行,实现床边检测。
- 可扩展性:CSFCN模块可应用于其他医学影像分析任务,如CT、MRI等。
5.3.2. 使用指南
对于想要使用我们算法的医疗工作者,我们提供了详细的使用文档和API接口,支持多种医学影像格式输入。算法输出包括病变区域的坐标框和置信度评分,方便医生进行后续分析。
5.4. 项目资源
为了方便研究者复现我们的工作,我们已将项目开源,包括:
- 完整的代码实现
- 预训练模型
- 自建数据集
- 详细的使用文档
此外,我们还制作了算法演示视频,展示了算法在多种心血管造影图像上的检测效果:
5.5. 未来工作展望
虽然我们的算法取得了较好的效果,但仍有一些方面需要改进:
- 多模态融合:结合其他医学影像模态(如超声、CT)进行联合检测
- 3D血管重建:从2D图像重建3D血管结构,提供更全面的病变信息
- 端到端诊断:直接输出诊断建议,而不仅仅是检测结果
我们正在积极研发这些方向的新算法,预计在未来一年内会有新的突破。
5.6. 总结
本研究通过创新性地融合YOLOv11与CSFCN网络,有效解决了心血管造影图像中目标检测的关键问题,在保证检测精度的同时提高了算法的实时性。实验结果表明,我们的算法在心血管造影数据集上取得了92.3%的平均精度,比原始YOLOv11算法提高了5.7个百分点,同时推理速度保持在25FPS,满足了临床实时检测的需求。
我们相信,随着人工智能技术在医疗领域的深入应用,类似的智能诊断算法将越来越多地辅助医生进行疾病诊断,提高医疗服务的质量和效率。我们的工作为心血管疾病的智能诊断提供了新的技术思路,具有重要的学术价值和临床应用前景。
如果您对我们的工作感兴趣,欢迎访问我们的项目主页获取更多资源:
cool-kids2数据集是一个专门用于心血管造影图像目标检测的数据集,该数据集由qunshankj平台用户提供,并采用CC BY 4.0许可证授权。数据集包含1480张心血管造影图像,所有图像均已YOLOv8格式进行标注,分为训练集、验证集和测试集。数据集中包含两个类别:'0'和'object',但具体类别含义未在文档中明确说明。在数据预处理阶段,所有图像均经过了自动方向校正(剥离EXIF方向信息)并拉伸调整为640×640像素尺寸。为增强数据集的多样性,每个源图像通过应用90度旋转(包括无旋转、顺时针和逆时针)以及5%像素的椒盐噪声生成了三个增强版本。该数据集于2023年12月7日导出,旨在支持计算机视觉模型在心血管造影图像分析领域的训练与部署,为医疗影像分析提供了宝贵的训练资源。