前言
Redis 作为一个高性能的键值对数据库,凭借其纳秒级的响应速度和丰富的数据结构,成为了现代分布式系统的标配。然而,"快"并不是 Redis 的全部。在实际生产环境中,我们更关注数据的安全性(持久化 )、内存的高效利用(内存淘汰 )以及极端场景下的稳定性(延迟优化)。
一、持久化机制:RDB 与 AOF 的权衡
Redis 是内存数据库,如果服务器断电,内存数据将瞬间丢失。为了保障数据安全,Redis 提供了 RDB(快照)和 AOF(追加文件)两种持久化方式。
1. RDB (Redis Database) - 快照
RDB 是 Redis 默认的持久化方式。它会在指定的时间间隔内,将内存中的数据集快照写入磁盘。
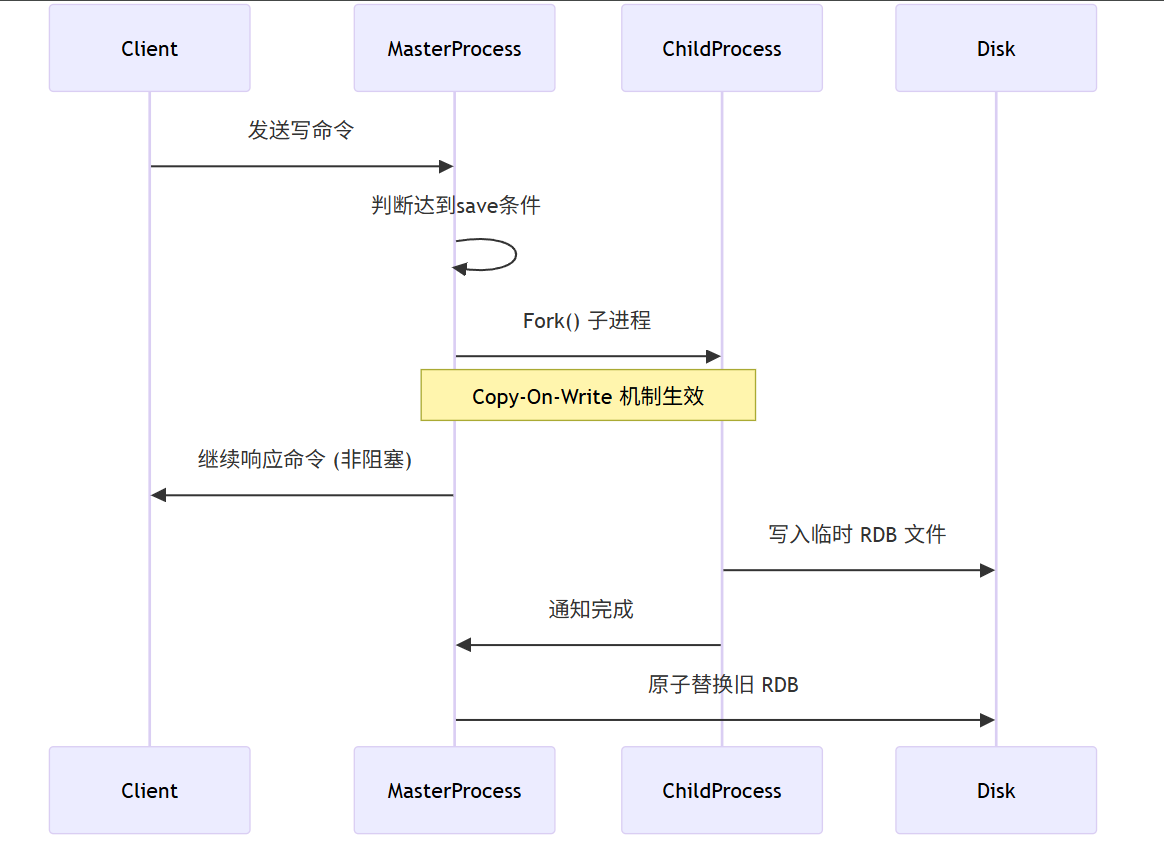
核心原理:Fork 与 COW (Copy-On-Write)
当执行 bgsave 时,Redis 主进程会 fork 出一个子进程。
-
父进程:继续处理客户端请求。
-
子进程:负责将内存数据写入临时文件,写完后替换旧文件。
-
COW 机制:Linux 的写时复制机制保证了父子进程共享内存页,只有当父进程修改数据时,才会复制该页面的副本。这使得快照过程极快且节省内存。
2. AOF (Append Only File) - 日志
AOF 以日志的形式记录服务器处理的每一个写、删除操作。
核心原理:重写 (Rewrite)
随着时间推移,AOF 文件会越来越大。Redis 提供了 bgrewriteaof 命令,创建一个新的 AOF 文件,只包含恢复当前数据集所需的最小命令集合。
3. 手动触发与配置检查
在 Java 中,我们通常使用 Jedis 或 Lettuce 客户端。以下代码展示了如何通过 Java 触发持久化以及监控上次保存时间。
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
public class RedisPersistenceDemo {
public static void main(String[] args) {
try (JedisPool pool = new JedisPool("localhost", 6379);
Jedis jedis = pool.getResource()) {
// 1. 写入一些数据
jedis.set("user:1001", "Alice");
// 2. 手动触发 RDB 异步保存 (通常由配置文件自动处理,但运维工具有时需要)
System.out.println("Triggering Background Save...");
String response = jedis.bgsave();
System.out.println("Response: " + response);
// 3. 获取上次持久化时间
Long lastSaveTime = jedis.lastsave();
System.out.println("Last successful save time (Unix timestamp): " + lastSaveTime);
// 4. 动态修改 AOF 配置 (不推荐生产环境动态改,应走配置文件)
// 开启 AOF
// jedis.configSet("appendonly", "yes");
}
}
}最佳实践: 推荐使用 混合持久化 (Redis 4.0+)。RDB 作为全量备份,AOF 作为增量备份,重启加载时既快又安全。
二、内存淘汰机制:有限空间的生存法则
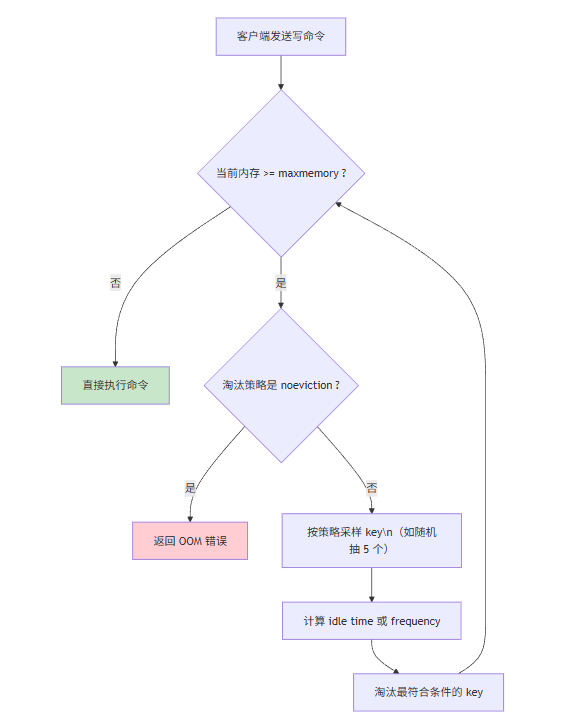
当 Redis 内存使用达到 maxmemory 限制时,Redis 需要决定删除哪些数据。这就是内存淘汰策略。
1. 淘汰策略详解
Redis 提供了 8 种策略(LRU = 最近最少使用,LFU = 最不经常使用):
|----------------|---------------------------|---------------|
| 策略 | 描述 | 适用场景 |
| noeviction | 默认。内存满直接报错。 | 数据极重要,宁可报错不可丢 |
| allkeys-lru | 在所有 key 中移除最近最少使用的。 | 最常用,缓存场景 |
| volatile-lru | 在设置了过期时间的 key 中移除最近最少使用的。 | 只想淘汰临时数据 |
| allkeys-random | 在所有 key 中随机移除。 | key 访问概率相等时 |
| volatile-ttl | 移除即将过期的 key。 | 让越快过期的数据越早死 |
| allkeys-lfu | (4.0+) 移除所有 key 中访问频率最低的。 | 热点数据明显的场景 |
2. 近似 LRU 原理
Redis 并没有维护一个严格的链表来记录所有 key 的 LRU,因为这太耗内存了。
Redis 采用随机采样的方式:随机取出 N 个 key(配置 maxmemory-samples),淘汰其中空闲时间最长的一个。
3. Java优雅处理 OOM
在 Java 客户端中,我们需要捕获内存溢出异常,并做降级处理。
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.exceptions.JedisDataException;
public class MemoryEvictionDemo {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
try {
// 模拟大量写入
for (int i = 0; i < 100000; i++) {
jedis.set("key:" + i, "large_value_" + i);
}
} catch (JedisDataException e) {
if (e.getMessage().contains("OOM")) {
System.err.println("CRITICAL: Redis memory is full!");
// 降级策略:
// 1. 记录日志
// 2. 尝试删除一些非核心缓存
// 3. 或者暂时不再写入 Redis,直接走数据库或本地缓存
fallbackToDB();
} else {
e.printStackTrace();
}
}
}
private static void fallbackToDB() {
System.out.println("Switching to DB mode...");
}
}三、延迟优化:追求极致性能
Redis 是单线程模型(指处理命令的主线程),任何阻塞操作都会导致所有请求延迟。
1. 延迟源头分析
-
Big Keys(大键):读取或删除一个几 MB 的 Hash/Set,主线程会卡死。
-
Slow Log(慢查询):KEYS *, SORT 等 O(N) 命令。
-
网络往返(RTT):大量的小命令,网络耗时远超执行耗时。
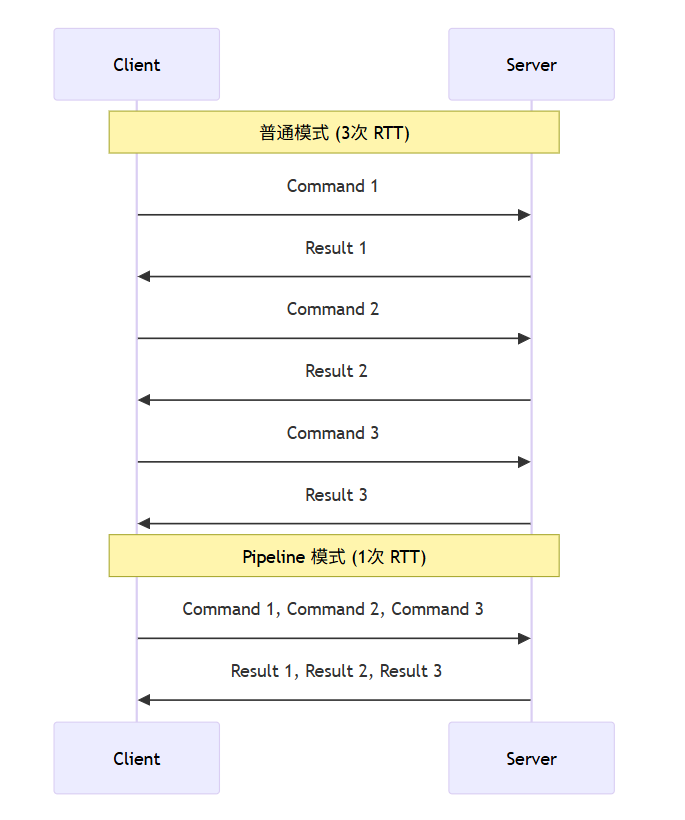
2. 优化方案:Pipeline (管道)
Pipeline 允许客户端一次发送多个命令,服务端一次性处理并返回结果,大大减少了 RTT。
3. 优化方案:异步删除 (Lazy Free)
Redis 4.0 引入了 UNLINK 命令,它是 DEL 的异步版本。主线程只将 key 从元数据中摘除,真正的内存释放由后台线程完成。
4. Java :Pipeline 与 大 Key 拆分
Pipeline 批量写入示例:
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import java.util.List;
public class LatencyOptimizationDemo {
public void batchInsert() {
try (Jedis jedis = new Jedis("localhost", 6379)) {
Pipeline p = jedis.pipelined();
long start = System.currentTimeMillis();
// 批量发送 1000 条命令
for (int i = 0; i < 1000; i++) {
p.set("batch:" + i, String.valueOf(i));
}
// 同步获取结果
List<Object> results = p.syncAndReturnAll();
long end = System.currentTimeMillis();
System.out.println("Pipeline executed in: " + (end - start) + "ms");
}
}
// 解决 Big Key 问题:拆分存储
// 假设我们要存一个包含 100万元素的 List
public void splitBigList(String originalKey, List<String> hugeData) {
try (Jedis jedis = new Jedis("localhost", 6379)) {
int batchSize = 1000;
// 将 key 拆分为 list:0, list:1, list:2 ...
for (int i = 0; i < hugeData.size(); i++) {
String subKey = originalKey + ":" + (i / batchSize);
jedis.rpush(subKey, hugeData.get(i));
}
}
}
}总结
深入理解 Redis 的内部机制
-
持久化 :生产环境建议开启 RDB + AOF 混合模式,兼顾恢复速度与数据完整性。
-
内存淘汰:根据业务属性选择策略,缓存场景用 allkeys-lru,并监控内存碎片率。
-
延迟优化:杜绝 Big Key,善用 Pipeline 批量操作,对于耗时删除使用 UNLINK 代替 DEL。