在机器人操纵领域,视觉 - 语言 - 动作(VLA)模型凭借大规模预训练数据的语义与视觉先验,实现了跨任务泛化,但长期受限于 2D-centric 的反应式决策范式,难以应对需要精准 3D 空间推理、长时程物理一致性的复杂任务。
香港中文大学(深圳)、湖南大学、理想汽车等联合团队提出的 GeoPredict 框架,以 "预测性运动学 + 3D 高斯几何" 为双核心,通过 "轨迹级运动预测 - 3D 高斯场景建模 - 训练时监督推理时轻量化" 的创新架构,首次将未来感知的几何先验注入连续动作 VLA 模型,彻底突破了传统方法的空间推理瓶颈。
论文题目:GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
GeoPredict --- Project Page (jingjingqian75.:https://jingjingqian75.github.io/GeoPredict-Page/
核心亮点:轨迹级 3D 关键点预测、轨迹引导的 3D 高斯几何细化、训练 - 推理解耦设计、跨模拟 / 真实场景鲁棒性
问题根源:传统 VLA 模型的三大核心短板
GeoPredict 的技术突破源于对现有 VLA 模型本质缺陷的精准定位,三大核心挑战构成其创新起点:
空间建模缺失
现有模型局限于 2D 图像空间进行反应式决策,缺乏对物体姿态、间隙、末端执行器运动的显式 3D 几何建模,在需要精准定位的任务中可靠性不足。
长时程预测不足
反应式策略仅依赖瞬时观测,无法捕捉运动惯性与场景动态演化,难以应对长时程操纵任务中的物理一致性要求。
推理效率矛盾
引入复杂 3D 预测模块的方法往往导致推理时计算开销激增,无法满足实时机器人控制的部署需求。
方案设计:GeoPredict 的双预测模块技术架构
针对上述挑战,GeoPredict 构建了 "运动学预测 - 几何建模 - 注意力融合" 的三层技术体系,在不增加推理负担的前提下,为 VLA 模型注入未来感知的几何先验:
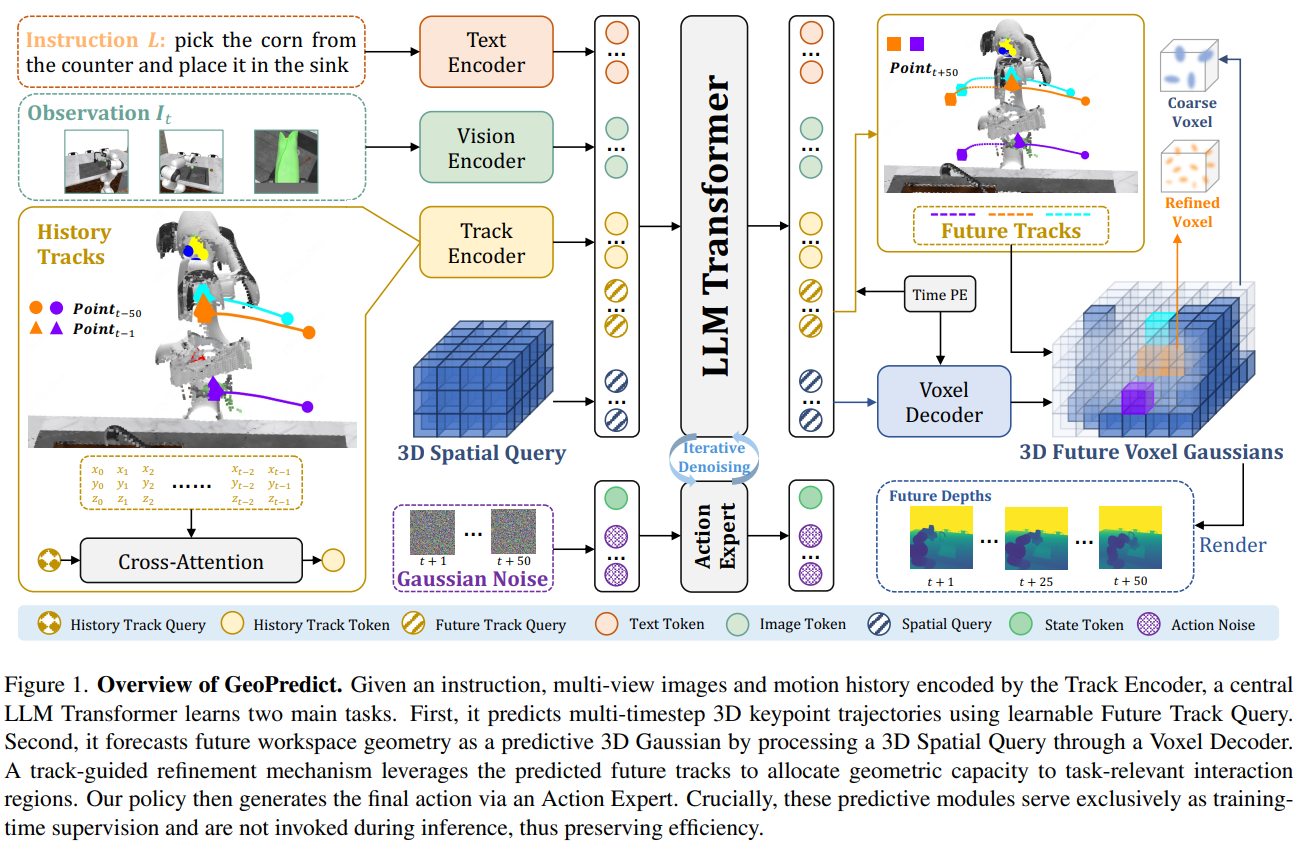
第一层:轨迹级运动学预测模块 ------ 捕捉机器人运动的未来惯性
该模块通过编码运动历史、预测多步轨迹,为政策提供显式的运动学先验,同时引导后续几何建模的资源分配:
- 轨迹编码器(Track Encoder):追踪机器人关节与末端执行器的 K 个 3D 关键点,将其历史运动轨迹通过交叉注意力压缩为紧凑的历史轨迹token,编码运动惯性、关节限制等动态规律;
- 未来轨迹查询(Future Track Query) :引入可学习的未来轨迹查询向量,结合语言指令、当前观测与历史token,通过 MLP 解码生成 H 步(默认 50 步)的 3D 关键点轨迹预测,采用均方误差损失( L t r a c k L_{track} Ltrack)监督轨迹精度;
- 双重作用:既正则化 Transformer 的内部动态,又为 3D 几何模块提供 "哪里需要高精度建模" 的空间指引。
第二层:预测性 3D 高斯几何模块 ------ 预见场景的动态演化
基于 3D 高斯 splatting(3DGS)的高效表征能力,构建未来场景几何预测模块,实现对工作空间动态的精准建模:
- 3D 空间查询(3D Spatial Query):将机器人工作空间离散为体素网格,通过 3D 正弦位置编码注入空间结构信息,生成初始空间查询token序列;
- 体素解码器(Voxel Decoder) :结合时间位置编码,将空间token解码为密集体素特征,映射为包含位置、不透明度、协方差的 3D 高斯基元,形成初始场景表征( G i n i t G^{init} Ginit);
- 轨迹引导细化(Track-guided Refinement) :利用运动学模块预测的未来关键点轨迹,生成二进制细化掩码,对轨迹途经的体素分配更多高斯基元( N G ′ N_G' NG′ > N G N_G NG),形成高分辨率交互区域表征( G r e f i n e G^{refine} Grefine),最终融合为完整场景模型( G t o t a l G^{total} Gtotal);
- 深度渲染监督 :通过可微分阿尔法合成从 3D 高斯模型渲染未来深度图,采用掩码 L1 损失( L d e p t h L_{depth} Ldepth)监督几何精度,仅关注工作空间内的有效区域。
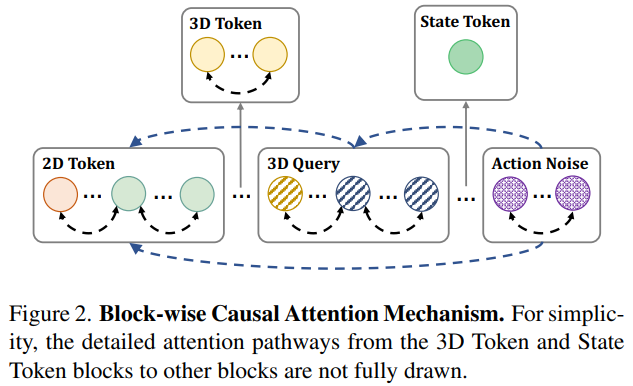
第三层:块级因果注意力 ------ 实现多模态信息的层级融合
设计块级因果注意力机制,将不同类型token按 "感知 - 预测 - 控制" 层级组织,确保信息流动的合理性与高效性:
-
token分组:将文本 / 图像token(2D Token)、历史轨迹token(3D Token)、未来查询token(3D Query)、本体感受token(State Token)、动作噪声token(Action Noise)划分为五个有序块;
-
注意力规则:块内双向注意力支持充分交互,块间严格因果注意力(仅后续块可关注前置块),构建 "2D 感知→3D 历史→3D 预测→动作生成" 的逻辑链路;
-
训练 - 推理解耦:运动学预测与 3D 高斯几何模块仅在训练时提供监督信号,推理时仅需轻量级查询token,保持与基础 VLA 模型一致的高效性。
验证逻辑:从模拟到真实的四级性能验证
GeoPredict 通过 "模拟基准测试 - 组件消融分析 - 定性效果可视化 - 真实场景落地" 的完整验证体系,充分证明其技术有效性:
跨数据集基准测试:刷新 SOTA 性能
在两大权威机器人操纵基准上,GeoPredict 显著超越现有方法:
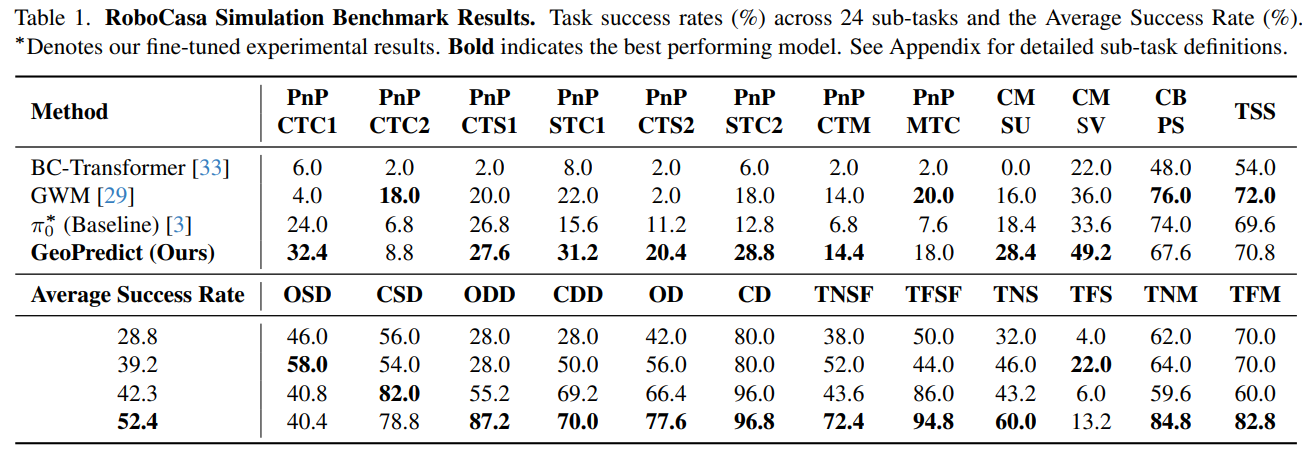
- RoboCasa Human-50 :在 24 个复杂日常任务的少样本设置(每任务 50 条人类演示)中,平均成功率达 52.4%,较基础模型 π 0 \pi_0 π0提升 10.1%,大幅超越 BC-Transformer(28.8%)、GWM(39.2%)等基线;
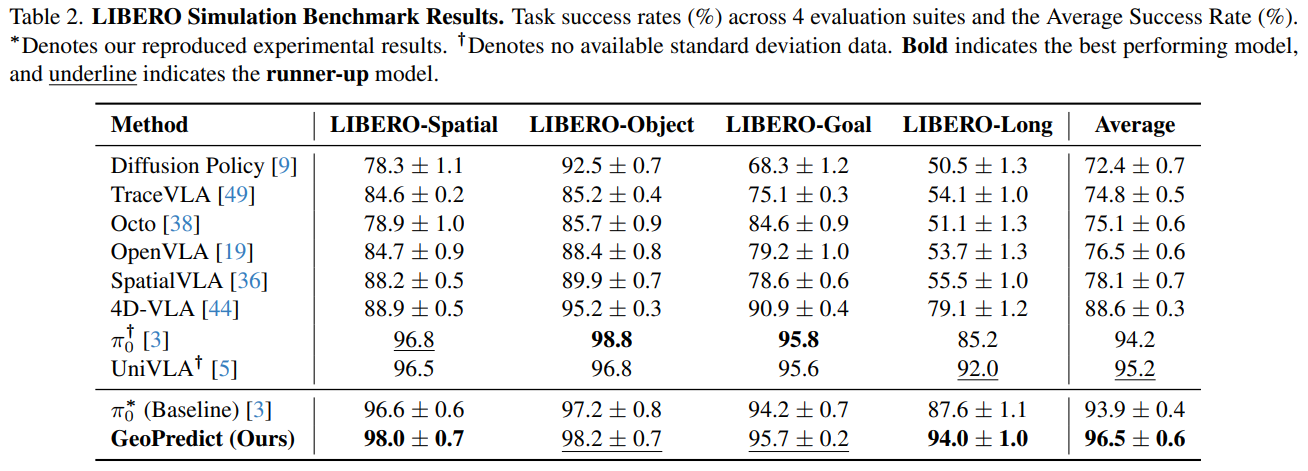
- LIBERO 四大套件:在空间推理、物体交互、目标达成、长时任务中均表现最优,平均成功率 96.5%,超越 UniVLA(95.2%)、4D-VLA(88.6%)等当前 SOTA 方法,尤其在长时任务(LIBERO-Long)中提升 6.4%,凸显长时程预测优势。
组件消融分析:验证核心设计价值
通过逐步构建模型,量化各组件的贡献:
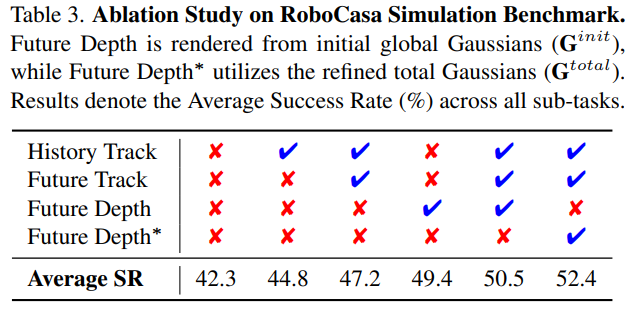
- 运动学模块:仅添加轨迹编码器提升 2.5%,结合未来轨迹查询进一步提升至 47.2%,验证运动惯性建模的重要性;
- 几何模块:基础 3D 高斯建模(无细化)提升至 49.4%,结合轨迹引导细化后达 52.4%,证明针对性几何资源分配的有效性;
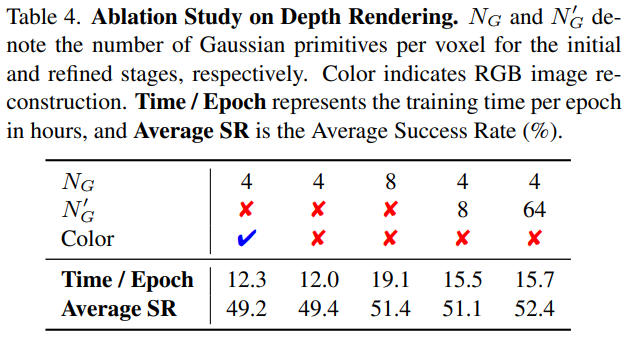
- 效率对比 :轨迹引导细化( N G N_G NG=4, N G ′ N_G' NG′=64)较全局高分辨率建模( N G N_G NG=8)训练效率提升 20%,且性能更优(52.4% vs 51.4%)。
定性效果可视化:几何预测的精准性
未来深度渲染结果显示,GeoPredict 的 3D 高斯模型能精准捕捉场景动态:
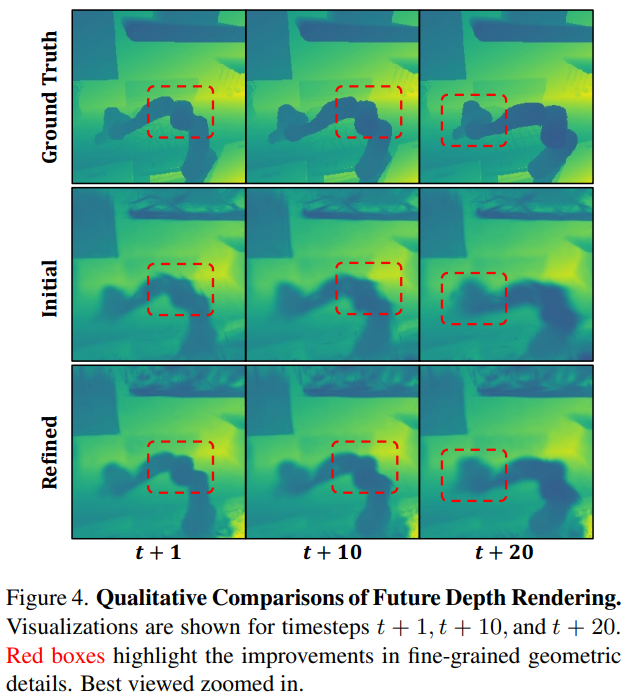
- 初始高斯模型( G i n i t G^{init} Ginit)仅能呈现粗糙场景布局,而轨迹引导的细化模型( G t o t a l G^{total} Gtotal)在机器人运动路径上提供锐利的几何细节,尤其在关节与物体交互区域;
- 随时间步(t+1→t+20)演进,预测深度图与真实场景的一致性持续保持,验证长时程几何预测的稳定性。
真实场景验证:突破 2D 模型的泛化瓶颈
在三大真实世界任务中,GeoPredict 展现出卓越的 3D 推理泛化能力:
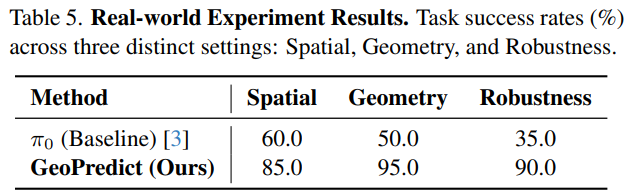
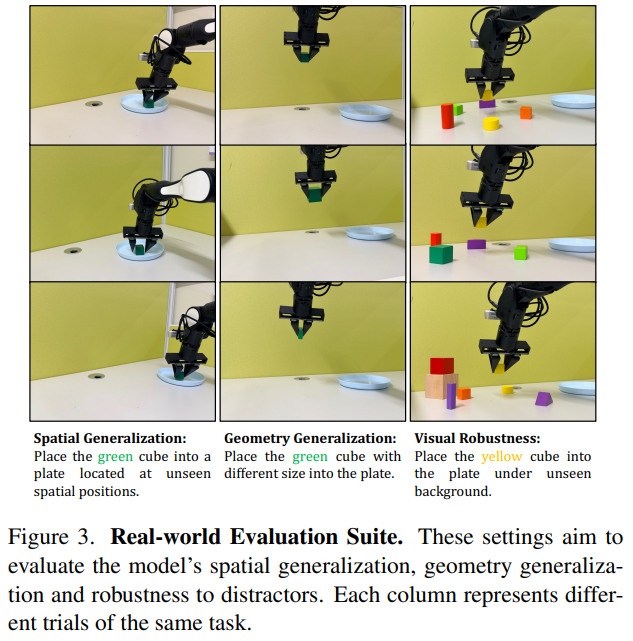
- 空间泛化任务:将绿色立方体放入未见过的目标位置,成功率达 85.0%(基线 60.0%);
- 几何泛化任务:应对训练中未出现的物体尺寸与形状(含长方体的三种稳定姿态),成功率 95.0%(基线 50.0%),凸显 3D 几何理解优势;
- 视觉鲁棒性任务:在背景存在陌生干扰物的场景中,成功率 90.0%(基线 35.0%),证明几何先验对视觉噪声的抵抗能力。
局限与未来方向
GeoPredict 作为几何感知 VLA 模型的开创性工作,仍存在可拓展空间:
- 几何表征维度:当前聚焦深度几何建模,未融合物体材质、物理属性等信息,未来可引入多属性高斯表征;
- 预测 horizon 平衡:更长的预测步长可能提升长时任务性能,但需解决累积误差问题,可探索自适应 horizon 机制;
- 实时性优化:虽推理时不启用 3D 解码,但轨迹预测与注意力计算仍有精简空间,可结合模型压缩技术进一步提升部署效率;
- 多机器人适配:当前针对单臂机器人设计,未来可扩展至多臂协作场景,构建多主体运动学与几何预测框架。
总结:GeoPredict 的范式价值与行业影响
GeoPredict 的核心贡献不仅在于提出了双预测模块架构,更在于建立了 "3D 先验注入 - 训练推理解耦" 的新范式:通过轨迹级运动学预测捕捉动态惯性,通过 3D 高斯几何建模预见场景演化,通过训练时监督机制在不牺牲效率的前提下提升模型几何推理能力。其在 RoboCasa、LIBERO 基准及真实场景的优异表现,证明了预测性几何先验对 VLA 模型的关键增益,为机器人操纵从 "反应式" 走向 "预判式" 提供了完整技术路径,加速了通用自主机器人在复杂真实环境中的落地进程。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?