Transformer为什么使用多个注意力头?
单头注意力如同用单一滤镜观察数据,难以同时捕捉语法、语义、指代等异构特征。
多头机制通过子空间投影分解 ,实现了并行化特征专家的效果,在几乎不增加计算量的前提下显著提升模型容量
在 Transformer 中,Multi-Head Attention(多头注意力机制) 是对 Self-Attention(自注意力机制)的拓展与增强,是模型理解复杂语言结构的关键技术之一。今天我们系统地讲清楚 为什么使用 Multi-Head Attention、它的计算方式和背后的原理。
想象你正在开发一个Java微服务系统,那我们可以把这种思维应用过来解释多头注意力机制:
- 单头注意力 = 1个全栈工程师包揽前端+后端+DB+运维 →超负荷且深度不足
- 多头注意力 = 前端组(React专家)+ 后端组(Spring Cloud专家)+ DBA组 →各司其职,架构更健壮
一、单头注意力机制的致命缺陷?
1️⃣ 表达力瓶颈(核心问题)
- 单头场景 :想象你是一个只能戴一种颜色滤镜的摄影师。无论拍什么场景,滤镜都是固定的(比如只能增强红色)。单头注意力就像这个单一滤镜------所有输入信息只能通过同一组注意力权重进行交互。
- 多头场景:换成拥有8个不同滤镜(红/蓝/绿/偏振/UV等)的相机。每个滤镜捕捉不同特征(颜色对比度/纹理/反光),最后合成一张信息丰富的照片。
- 技术本质 :每个头的投影矩阵 W i Q W_i^Q WiQ**, W i K W_i^K WiK , ** W i V W_i^V WiV不同 ,相当于学习 h h h种不同的"信息关注模式"。
单头注意力公式:
Attention(Q, K, V) = softmax(Q·K\^T / √d_k) · V
多头注意力 ( h h h个头):
h e a d i = A t t e n t i o n ( Q ⋅ W i Q , K ⋅ W i K , V ⋅ W i V ) head_i = Attention(Q·W_i^Q, K·W_i^K, V·W_i^V) headi=Attention(Q⋅WiQ,K⋅WiK,V⋅WiV)
M u l t i H e a d = C o n c a t ( h e a d 1 , . . . , h e a d h ) ⋅ W O MultiHead = Concat(head_1, ..., head_h) · W^O MultiHead=Concat(head1,...,headh)⋅WO
2️⃣ 混合信号干扰
- 单头问题:当句子同时包含语法结构(主谓宾)、语义关系(同义词/反义词)、指代关系(代词指向)时,单头注意力被迫将所有信息压缩到同一组权重中,导致特征混淆。
- 多头优势 :不同头可自主分工:
- 头1 :专注捕捉局部语法依赖(如动词与宾语的关联)
- 头2 :识别长距离指代(如"它"指代前文的哪个名词)
- 头3 :提取情感语义(如"优秀"与"卓越"的相似性)
3️⃣ 优化难度
- 单头困境:要求单个注意力层同时学习多种复杂关系,梯度更新方向易冲突(类似多任务学习的跷跷板效应)。
- 多头策略 :通过低维子空间分解 (将 d m o d e l d_model dmodel拆分为 h h h个 d k d_k dk维度)降低学习难度,各头可独立收敛到不同解。
二、为什么要使用Multi-Head Attention
总结起来,相比于使用单头,使用多头注意力机制有如下好处:
- 捕捉不同子空间的信息:在自然语言处理任务中,文本数据是高维的。一个句子可以包含多种语义信息,如语法结构、语义关系、情感倾向等。多头注意力机制可以将输入数据分割成多个不同的子空间,每个注意力头可以学习到输入数据在不同子空间中的特征。
- 模型容量和灵活性增加:与单一注意力机制相比,它能够同时处理多种不同的特征组合。
- 提高模型的泛化能力:由于多头注意力机制能够从不同角度学习数据特征,它有助于模型在面对新的、未见过的数据时更好地泛化。
从算法层面来说,并行使用多个注意力层,有助于捕捉输入序列中单词之间的不同交互。每个注意力头产生的隐藏状态的维度除以注意力头的数量,然后与其他隐藏状态连接起来。最终的隐藏状态通过线性层组合成最终的隐藏状态。机制如下图所示:
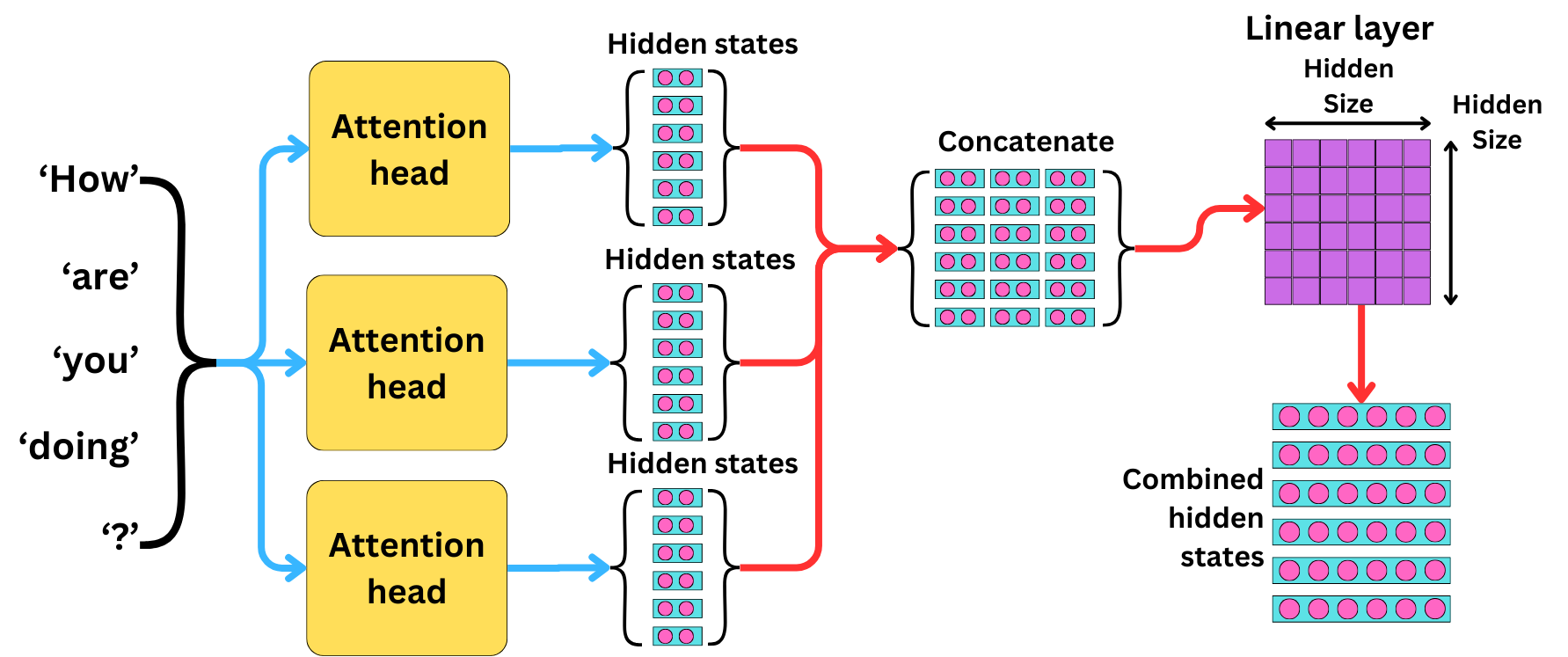
为了降低隐藏状态的维数,我们只需要改变内部矩阵的形状:
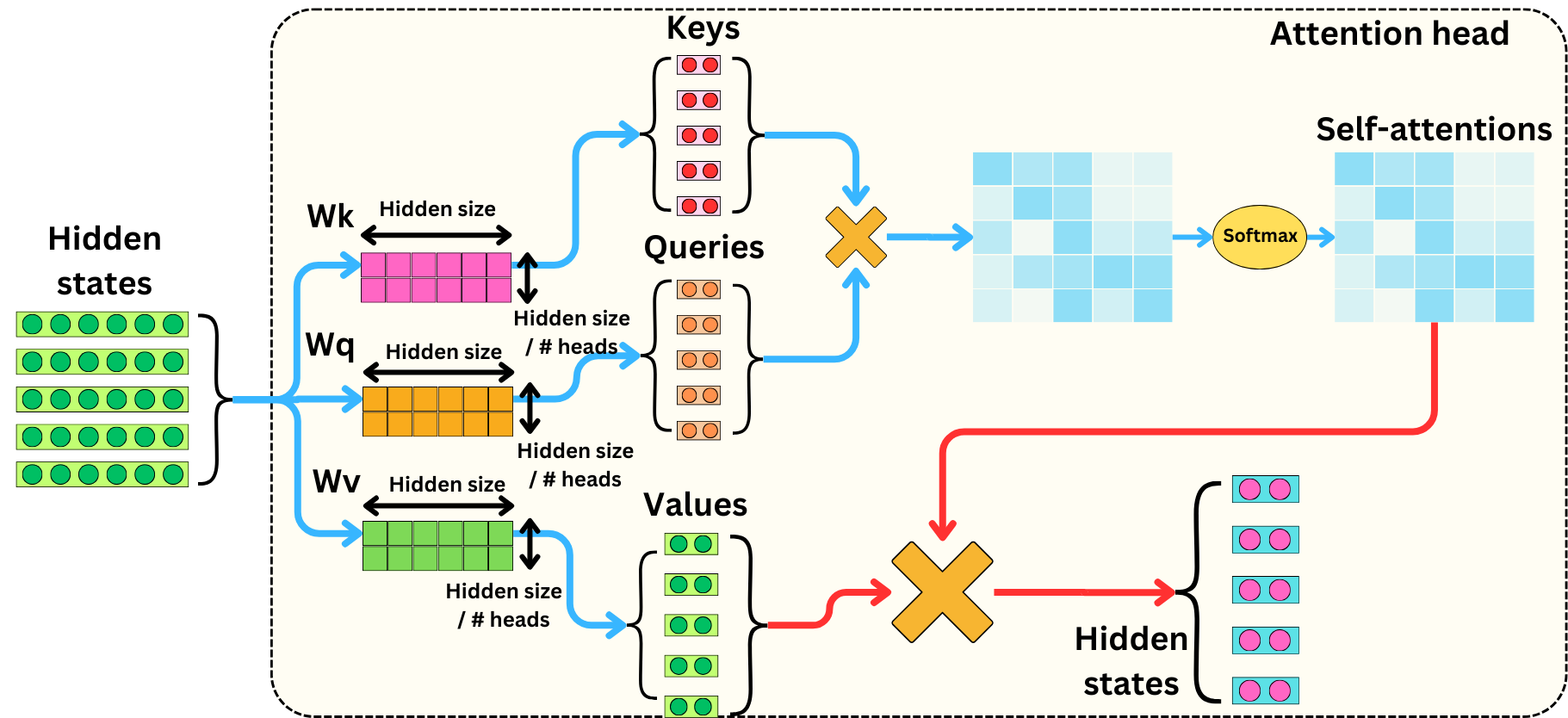
多头注意力的工程价值?
在原始Transformer论文(Attention is All You Need)中,8头比单头在WMT2014英德翻译任务上提升超过2 BLEU值,接近当时SOTA。
具体价值可见下表:
| 特性 | 单头注意力 | 多头注意力 |
|---|---|---|
| 表征多样性 | ❌ 单一模式 | ✅ 多视角特征提取 |
| 长距离依赖建模 | ⚠️ 易被局部主导 | ✅ 分工捕捉不同距离关系 |
| 模型鲁棒性 | ❌ 权重扰动影响全局 | ✅ 头间冗余提升容错性 |
| 并行计算效率 | = 同等计算量 | = 头间天然可并行化 |
多头注意力机制代码(Python版):
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, num_heads=8):
super().__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
B, T, C = x.size()
# 线性映射
Q = self.q_linear(x).view(B, T, self.num_heads, self.d_k).transpose(1, 2)
K = self.k_linear(x).view(B, T, self.num_heads, self.d_k).transpose(1, 2)
V = self.v_linear(x).view(B, T, self.num_heads, self.d_k).transpose(1, 2)
# Attention 权重
scores = Q @ K.transpose(-2, -1) / self.d_k ** 0.5
weights = torch.softmax(scores, dim=-1)
attn_output = weights @ V # shape: (B, num_heads, T, d_k)
# 合并 heads
out = attn_output.transpose(1, 2).contiguous().view(B, T, C)
return self.out_proj(out)多头注意力机制代码(Java版):
// 多头投影
public MultiHeadTensor splitHeads(Tensor x, int numHeads) {
int batchSize = x.shape()[0];
int seqLen = x.shape()[1];
int dModel = x.shape()[2];
int dHead = dModel / numHeads;
return x.reshape(batchSize, seqLen, numHeads, dHead)
.transpose(2, 1); // [Batch, Heads, SeqLen, dHead]
}参考文献
Transformer_transformer每一个注意力头对应一个特征吗-CSDN博客
【Transformer】Transformer:采用Multi-head Attention的原因和计算规则_transformer为什么要多头-CSDN博客
https://newsletter.theaiedge.io/p/the-multi-head-attention-mechanism