最近阿里开源的文生图小模型Z-image-Turbo强的可怕,参数量只有6B,内存占用仅仅20多G,很适合在个人电脑上做本地部署。
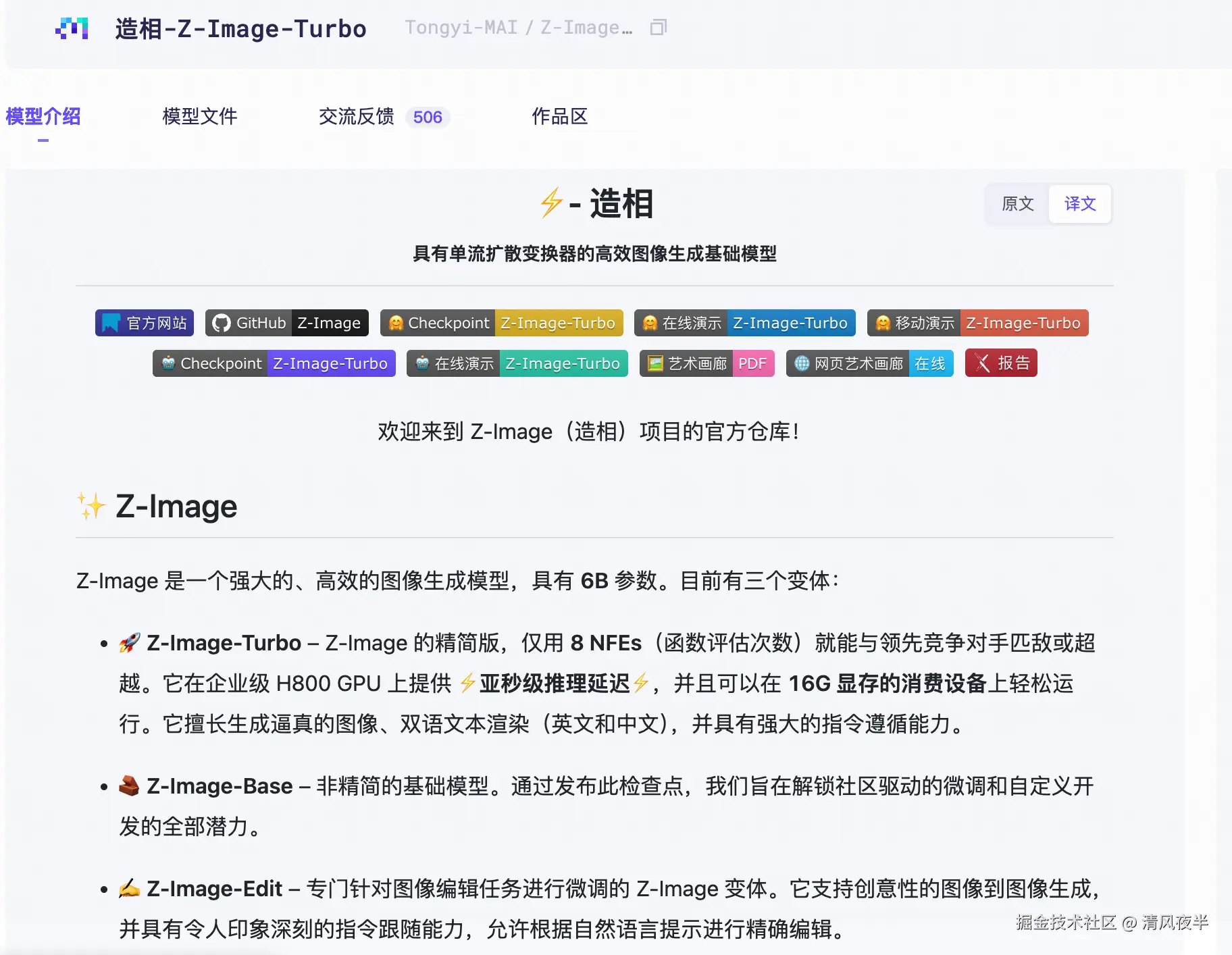

不过很多人说自己的笔记本没显卡跑不动,想用Z-image-Turbo GGUF量化版,但是又必须搭配ComfyUI,学习起来又比较麻烦。
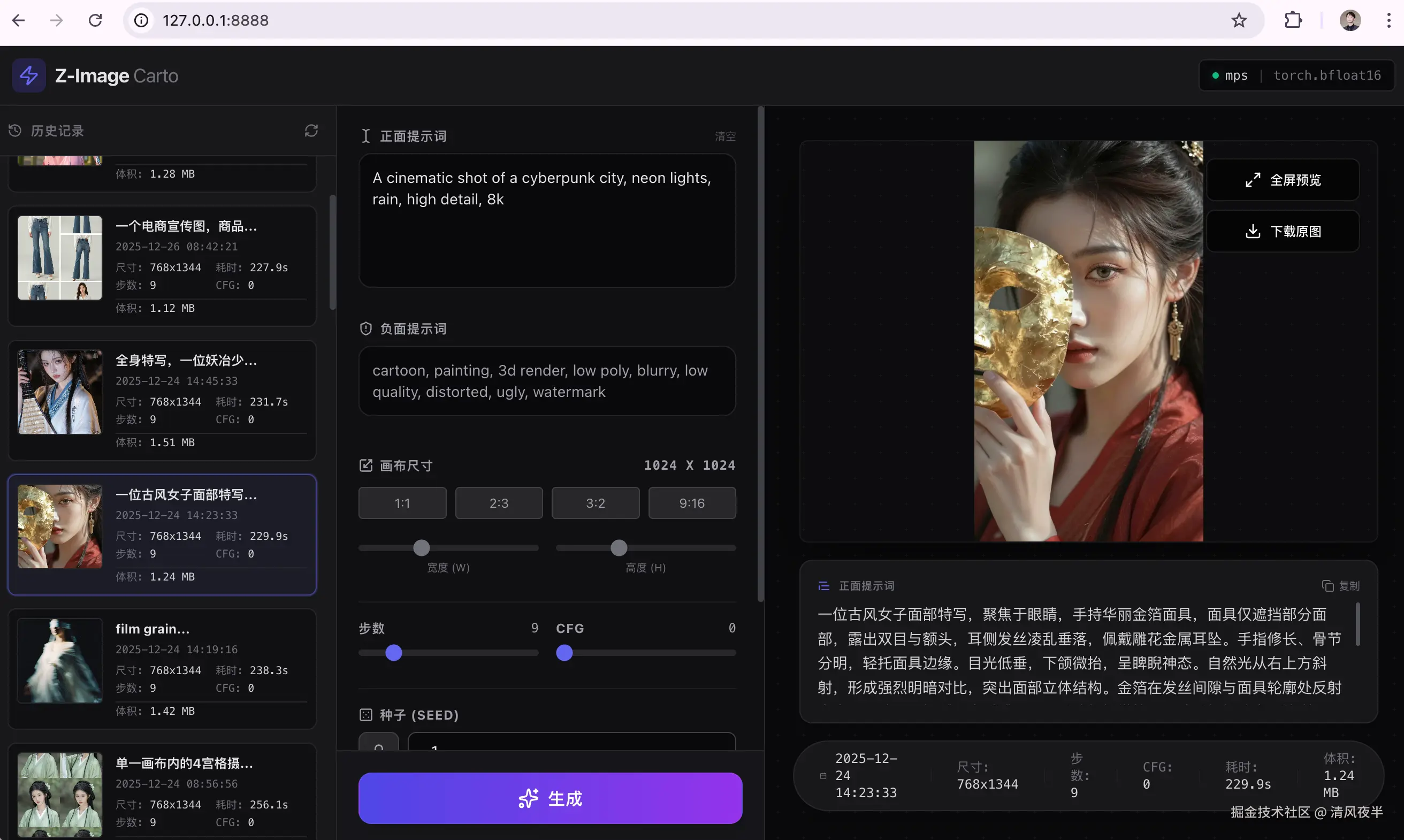
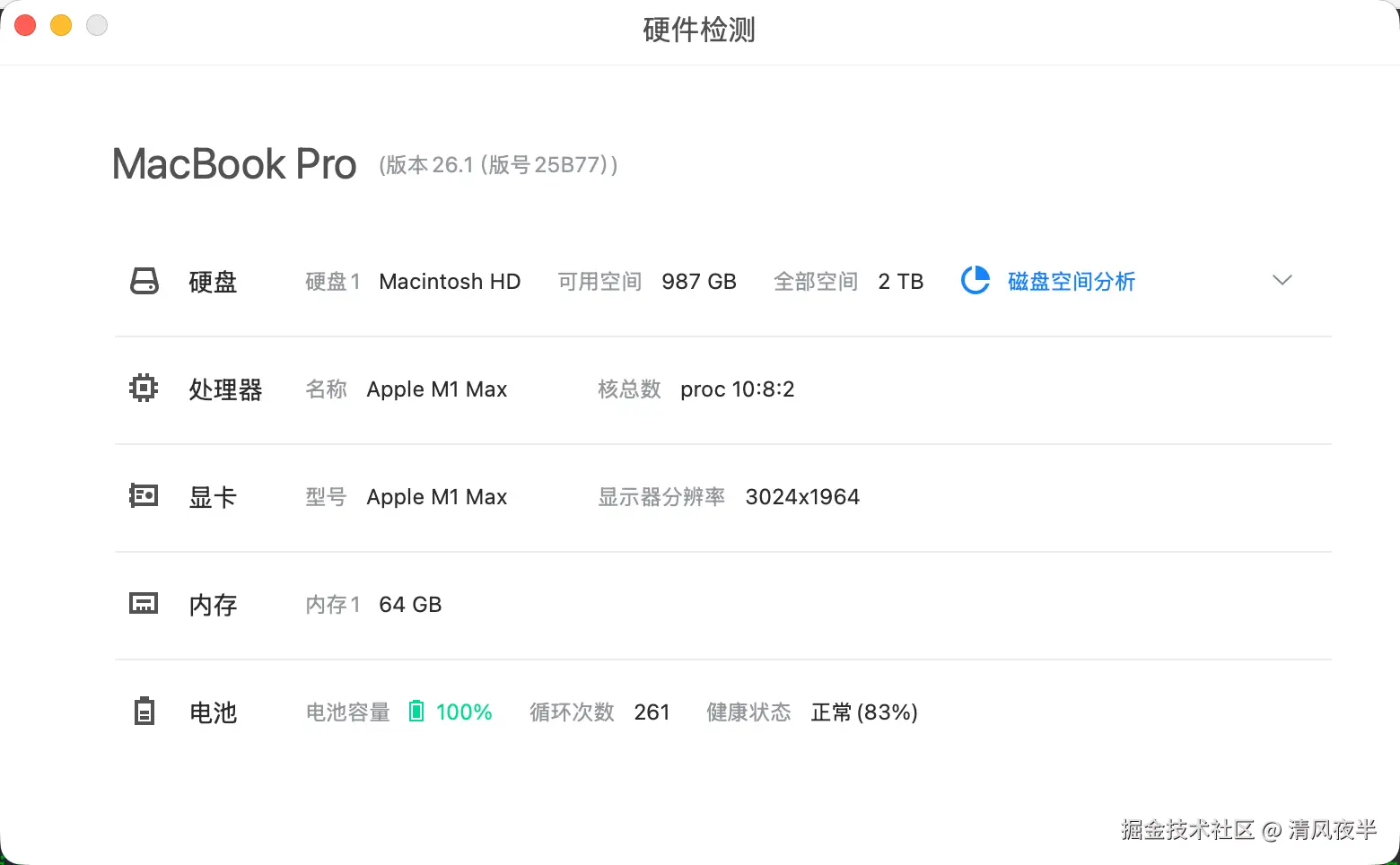
于是最近我研究了一下优化办法,可以在没有独显的电脑上使用,并且能保证图片生成质量,毕竟我也只有一台Mac笔记本。我的电脑配置是M1 Max 64G+2T,按照Z-image-Turbo的文档来看,本地跑这个模型处处有余,事实上确实如此,以生成1024x1024分辨率的图片为例,最终内存占用稳定在32G左右,如果你的内存是32G的,那也够用了。
生成效果
至于生成效果,我觉得还不错,有些图片甚至能以假乱真,先给大家看看我的作品(多图预警):










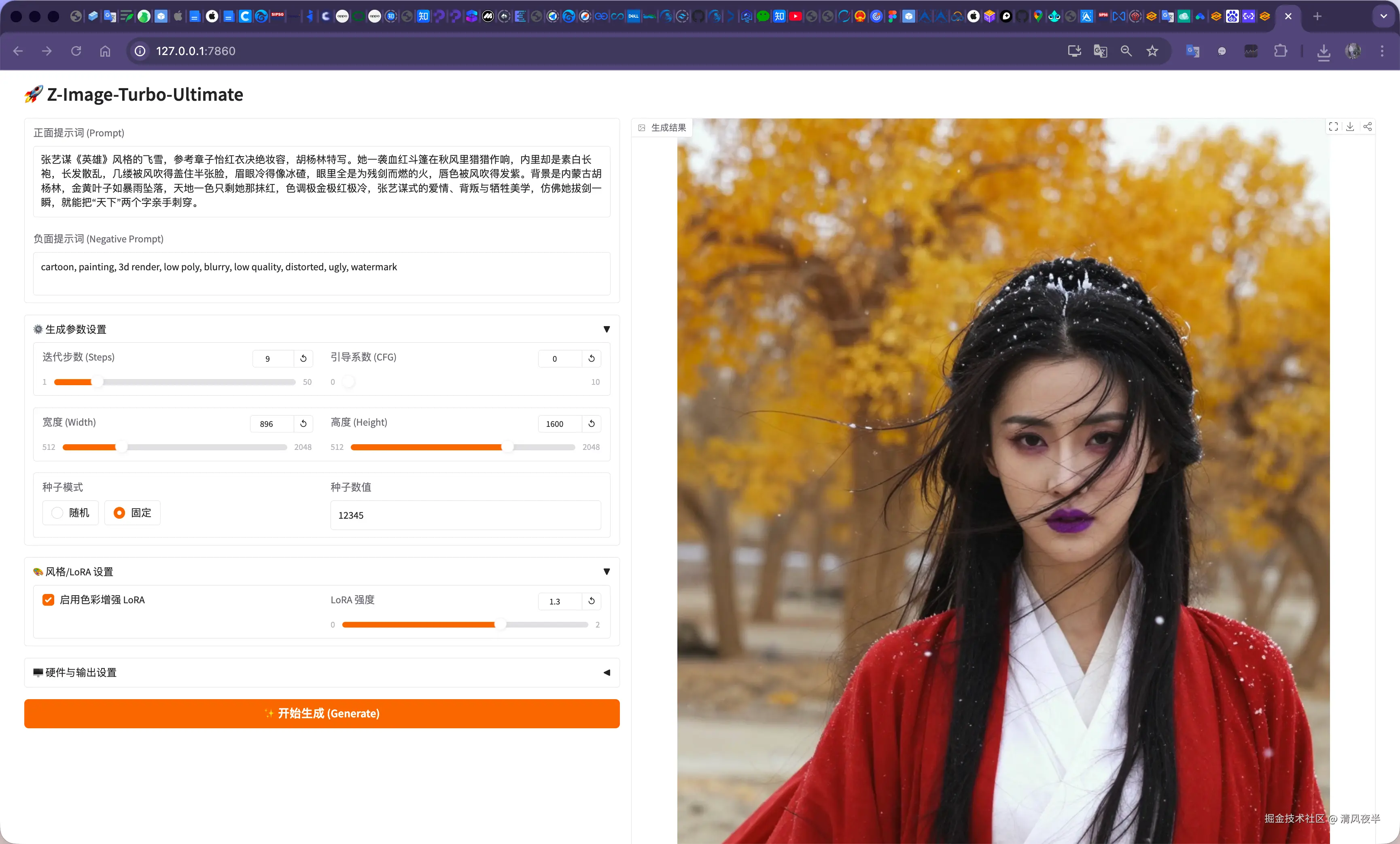
基本各种场景都尝试了一遍,考虑到只是一个6B的小模型,效果可谓是很惊艳,甚至有图片质量不输一些付费的AI平台。本地调试成功后,为了方便测试,用Vue替换了Gradio做了一个WebUI,并且把调节参数都开放了出来,这样打开浏览器就可以更加精准的控制生成效果,目前支持调节如下参数:
- 正面提示词
- 负面提示词
- 迭代步数
- 引导系数(CFG)
- 图片尺寸
- 种子模式
- LoRA色彩、强度
- 硬件自动检测(cuda、mps、cpu)
- 图片输出格式(webp、png、jpeg)
- 历史记录

踩坑记录
其实在本地部署的过程中也踩了不少坑,这里列出来让大家避雷:
- 内存占用异常,导致程序崩溃
- 画质模糊,成像效果差
- 色彩失真,图片毫无质感
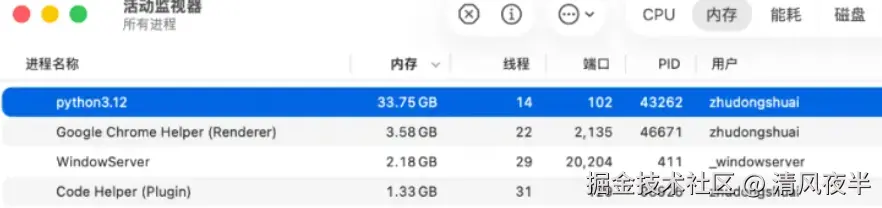
关于内存占用异常问题,由于没独显不能用cuda模式,模型默认用cpu来跑,生成一张512x512的图片就爆内存,内存占用达到了59G,直接给进程杀掉了。
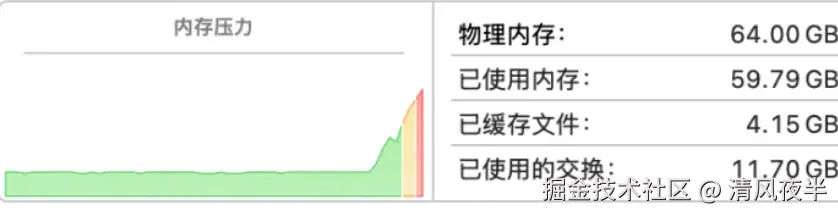
好在苹果最新的M系列芯片采用内存和显存共用的模式,推出了mps用于GPU加速(Metal Performance Shaders,类似于英伟达的cuda),于是针对M系列的芯片,我将torch的推理模式改成了mps。
python
if torch.cuda.is_available():
return"cuda"
elif torch.backends.mps.is_available():
return"mps"
else:
return"cpu"这下解决了爆内存的问题,但是内存占用还是很高,电脑又卡又发烫,生成图片的时候基本不能干其他事。 原因是Z-Image-Turbo 默认推荐使用 FP16 半精度进行推理,这在 Nvdia 显卡(cuda)上表现比较好,但在 Mac M 系列芯片(mps)上,FP16 极易爆内存,为了保证可用性,不得不使用FP32 全精度,但又会导致显存占用翻倍且推理缓慢。
最终经过优化,我切换到了 M 芯片原生支持的 bfloat16 精度,它拥有与 FP32 相同的动态范围(彻底解决溢出/黑屏问题),同时保持了 16 位的轻量体积,这一改进使显存占用相比 FP32 减少了一半,推理速度提升了约 2 倍。
python
if device == "cuda":
# NVIDIA 显卡: FP16 性能最佳且显存占用低
return torch.float16
elif device == "mps":
# Apple Silicon: 必须使用 Bfloat16
# 原因1: 避免 FP16 的溢出(黑屏)问题
# 原因2: 相比 FP32 节省一半显存,速度翻倍
return torch.bfloat16
else:
# CPU: 兜底使用 FP32,兼容性最好
return torch.float32我做了一下测试,以我的M1 Max 64G内存为例:
- 生成一张1024x1024的图片,大约180秒,内存稳定占用约33G
- 生成一张512x512的图片, 大约30秒,内存稳定占用约29G
即使解决了内存占用异常问题,但现在生成的图片质量和官方宣传的还是没法比,虽然分辨率是达到了要求,不过整体比较模糊,锐度缺失,而且色彩和光照都不对,基本没法看。

后来查了资料,其实这里要用到2个东西:VAE(Variational Autoencoder) 和 LoRA(Low-Rank Adaptation)
关于VAE 和 LoRA 的介绍由于篇幅较长这里不做解释,可以简单理解为:
VAE :是滤镜/修图师
LoRA :是风格包/皮肤
- VAE用来解决画面模糊问题,用来提升清晰度和锐度
python
def_apply_optimizations(self):
"""根据硬件类型应用显存和画质优化"""
# [通用] VAE 精度修复: 强制 FP32 以解决模糊问题
if hasattr(self.pipe, "vae"):
self.pipe.vae.to(dtype=torch.float32)
self.pipe.vae.config.force_upcast = True
print("👁️ [Optim] VAE 已切换至 FP32 (画质锐化)")- LoRA用来做色彩增强,提升彩饱和度和光影质感。
python
defupdate_lora(self, enable, scale):
"""更新 LoRA 状态 (启用/禁用/调整强度)"""
# 情况A: 从无到有 -> 直接加载
if enable andnot self.current_lora_applied:
self.lora_merger.load_lora_weights(config.LORA_PATH, scale)
self.current_lora_applied = True
return"LoRA 已启用"
#...最终便是开始看到的效果,无论是从内存占用、生成速度、生成质量上都有了明显的提升,清晰度和质感和实拍照片没区别。
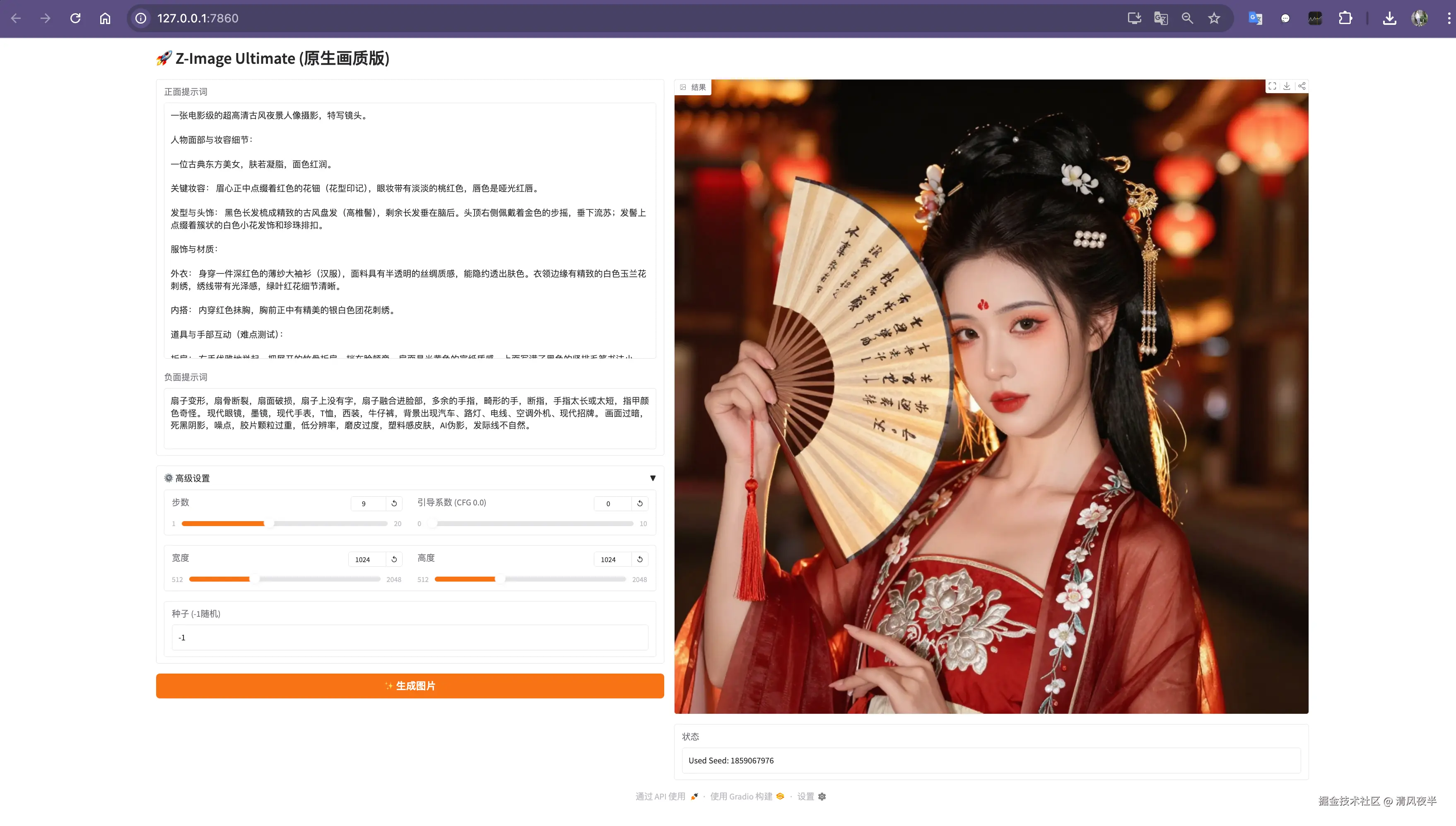
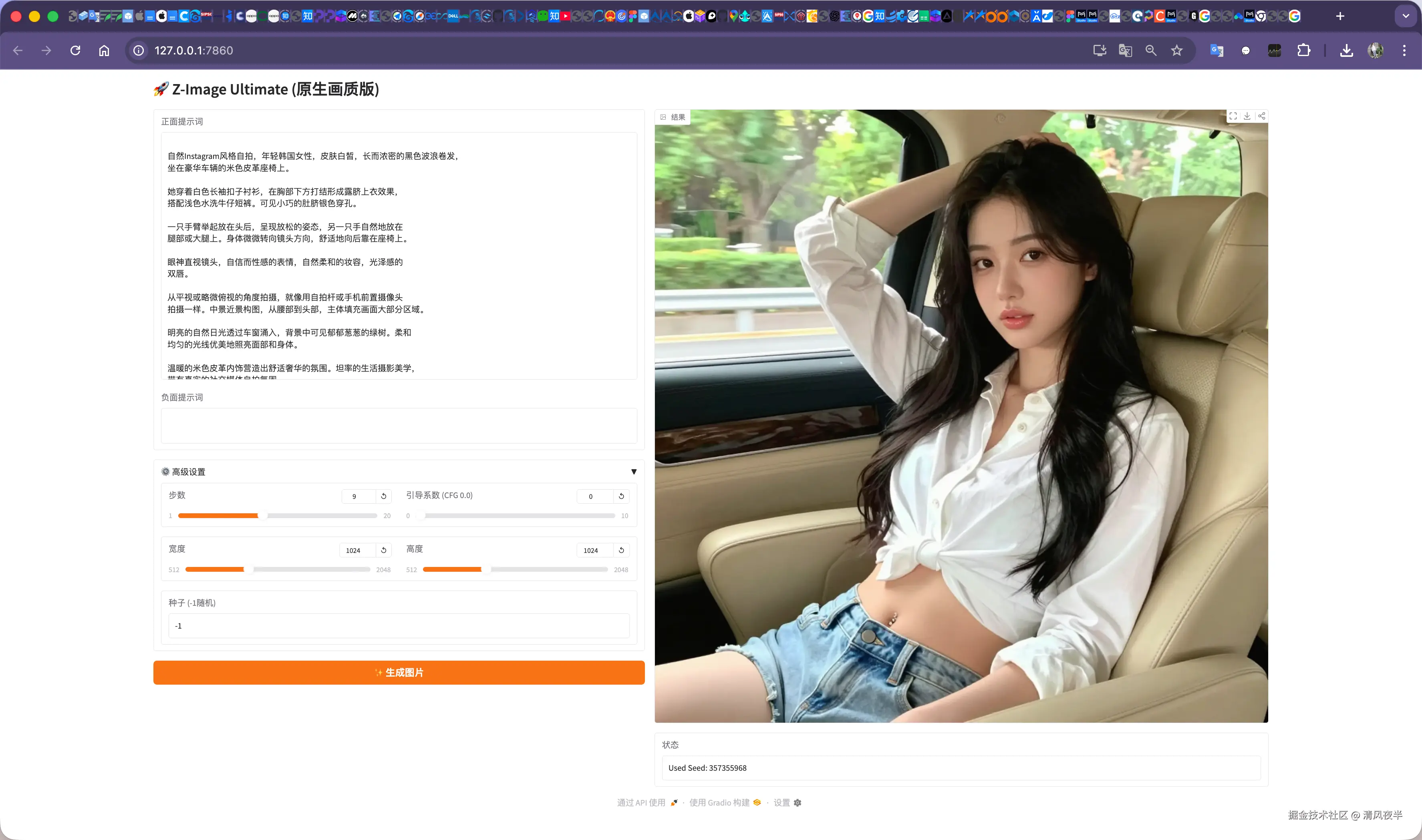

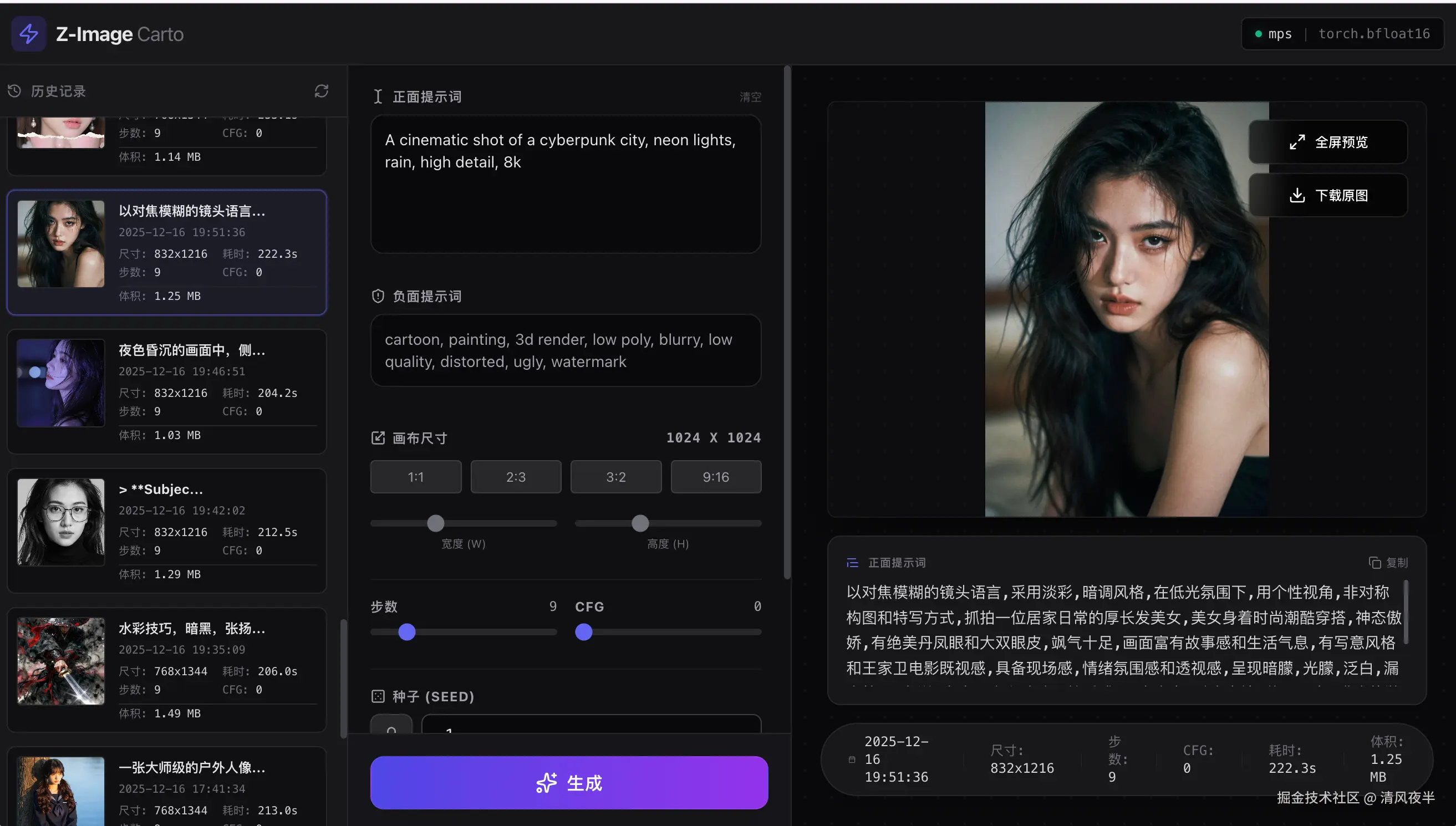
测试过程中为了方便,就默认用了Gradio做UI,实在是太丑了,后面索性把项目重构了基于(FastAPI 后端 + Vue 3 前端 + SQLite 数据库),另外换成了tailwind.css,颜值提升了一个档次
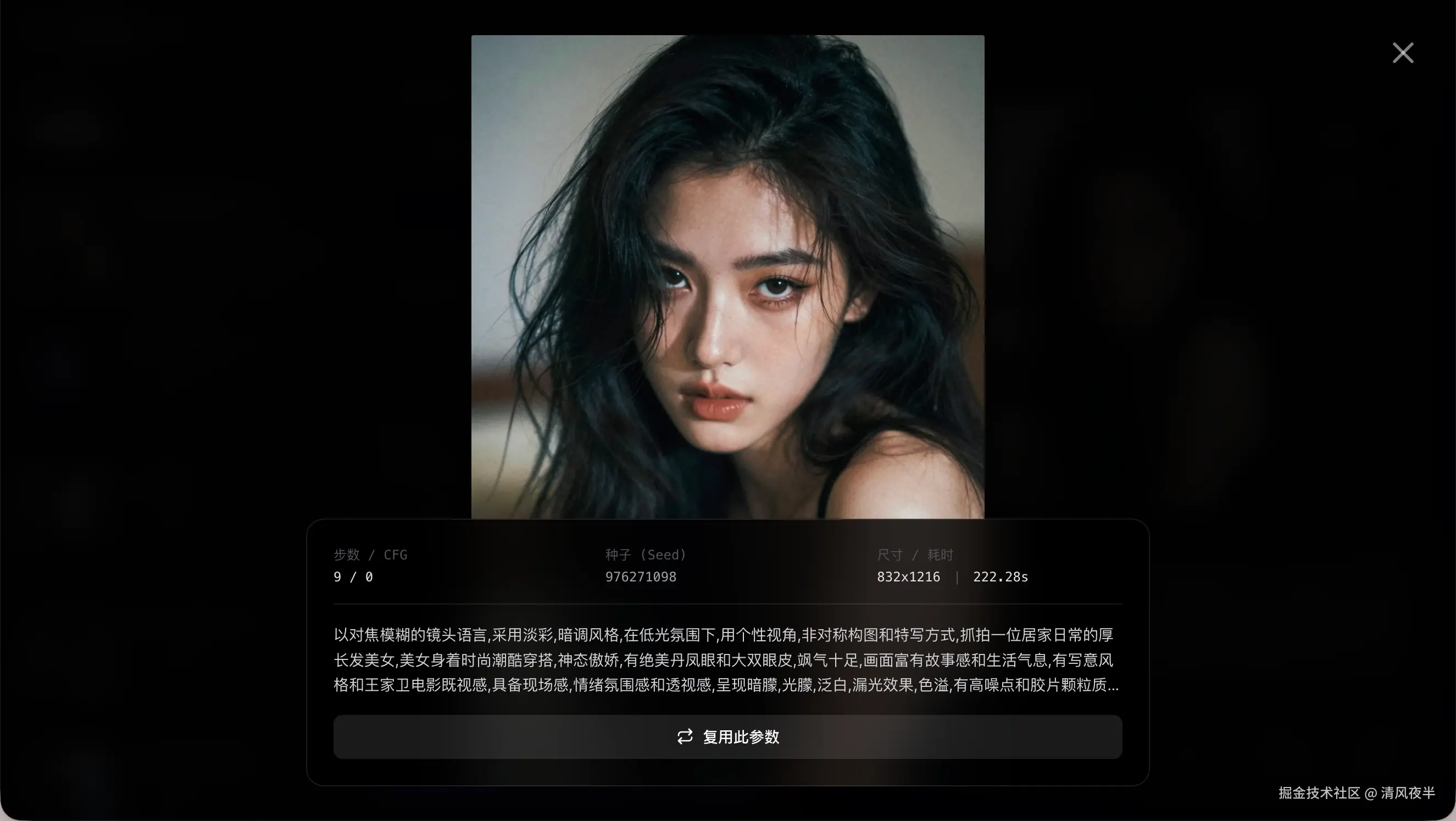
如何在本地部署?
以Mac电脑为例
1.获取本项目源代码
2.环境准备
- 芯片:Apple M1 / M2 / M3 系列(Pro/Max/Ultra 体验更佳)
- 内存:至少 16GB(推荐 32GB 以上)
- 硬盘:预留 60GB 以上空间
- Python环境:建议 Python 3.10 或 3.11 (暂不支持 3.13)
3.安装依赖
推荐使用 requirements.txt 一键安装所有依赖:
shell
pip install -r requirements.txt或者手动安装:
shell
pip install torch torchvision torchaudio
pip install gradio transformers accelerate protobuf sentencepiece safetensors huggingface_hub
# 安装 Diffusers (开发版)
pip install git+https://github.com/huggingface/diffusers.git
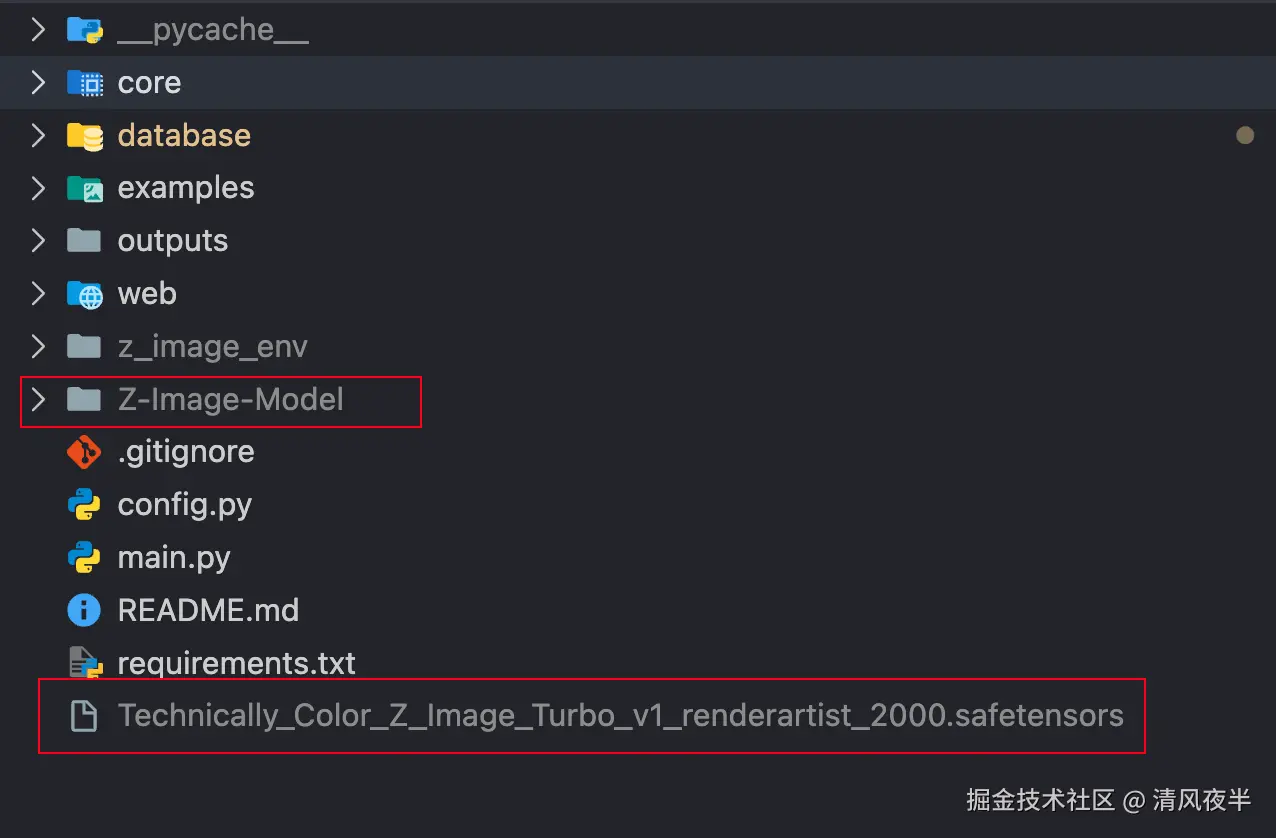
pip install fastapi uvicorn python-multipart aiofiles websockets4.模型准备 请确保项目根目录下有以下文件/文件夹:
5.运行在项目根目录下运行:
shell
python amin.py等待终端显示 👉 请访问: http://127.0.0.1:8888 后在浏览器打开即可。