无论是语言模型还是推荐大模型,基于强化学习的偏好对齐已成为其训练流程中不可或缺的关键环节。
本文将系统梳理强化学习在大模型中的实践路径:首先阐明其核心机制与主流算法,继而聚焦语言模型与推荐大模型的典型应用场景,深入解析强化学习如何落地于具体模型的优化过程。
一、强化学习核心思路
强化学习的核心任务在于:为智能体训练一个神经网络,该网络接收当前状态作为输入,输出对下一步动作的预测,以最大化整体期望回报。
以AlphaGo为例,其将棋盘的视觉或网格化表征输入神经网络,输出下一步落子位置的决策,从而提升胜率;当智能体为语言模型时,则将当前问题或对话上下文作为输入,生成能最大程度契合人类偏好与意图的响应。
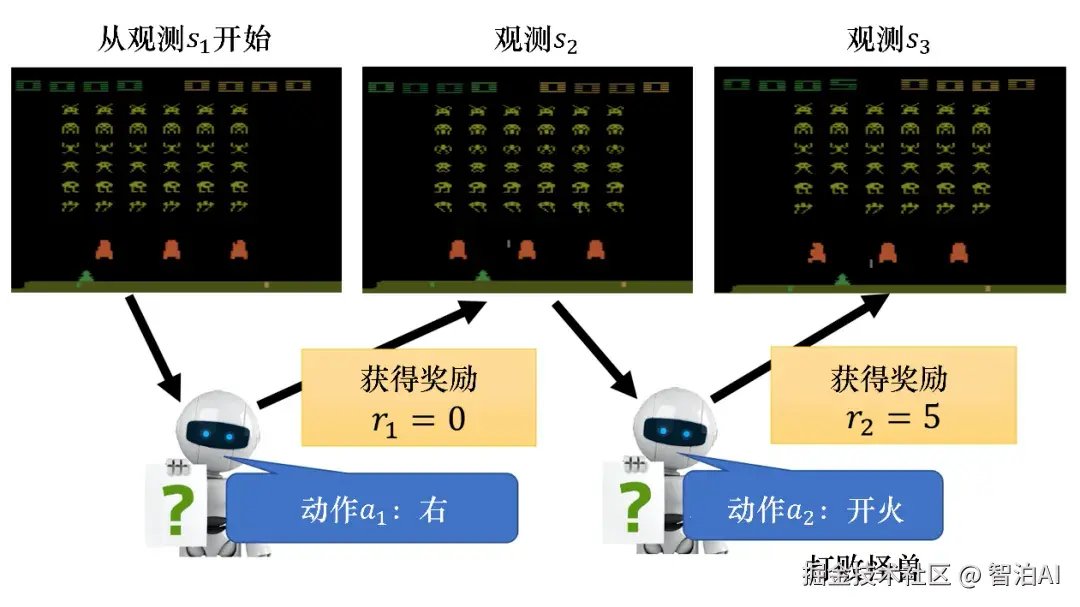
为什么上述优化问题无法用普通的有监督学习进行优化?主要源于两个根本性限制。
其一是样本收集机制的差异:在游戏等序列决策场景中,智能体的每一步动作都会改变环境状态,进而影响后续行为与奖励信号的生成;
因此,样本的产生必须依赖一个初始智能体与环境的持续交互,而模型的更新又反过来影响后续样本的分布------样本生成与模型训练形成闭环,这与有监督学习中静态、独立采样的数据集有本质区别。
其二是奖励函数的优化特性:奖励设计通常具有多层次性,既包含单步即时奖励,也涵盖长期累积奖励,且这些奖励往往由规则引擎或复杂模型动态计算得出,不具备可微性;
因此,无法像有监督学习那样通过标签与预测值的直接梯度反传进行端到端优化。
二、强化学习基础算法


其核心思路是利用重要性采样,根据新老参数的分布差异对老参数智能体收集的样本进行加权使得该样本在新参数上也能训练。
同时考虑到两个分布差异太大会导致重要性采样误差较大,使用KL散度约束新老参数产出的行为分布不能相差太多,也可以使用clip的方法对两个分布的差异进行clip。
三、大模型中的强化学习应用
在阐明强化学习的基本原理之后,接下来我们将聚焦于其在大语言模型中的具体实践。
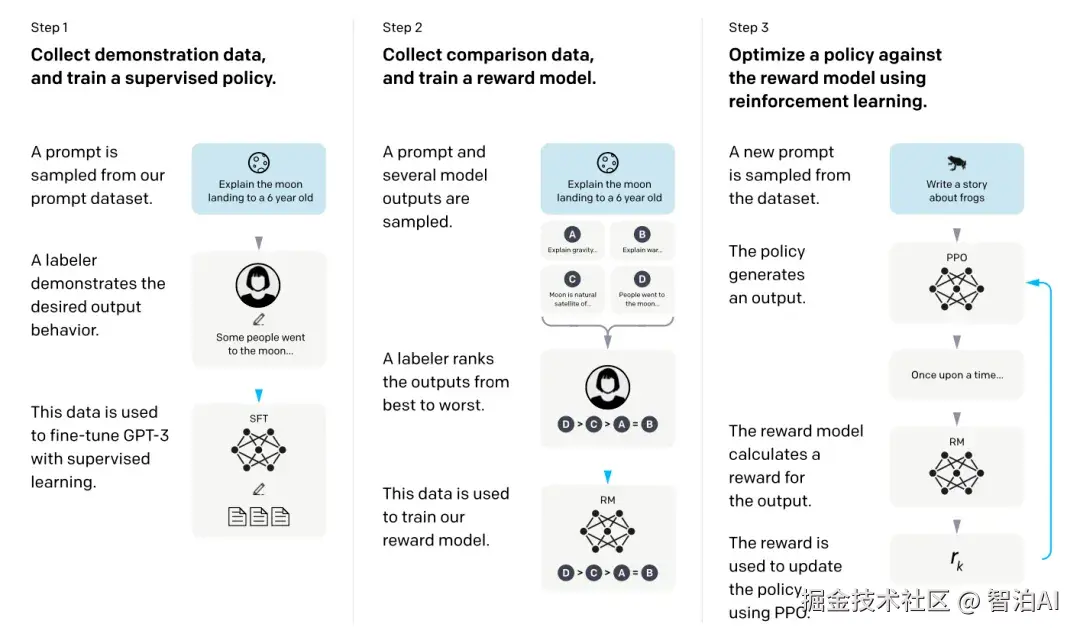
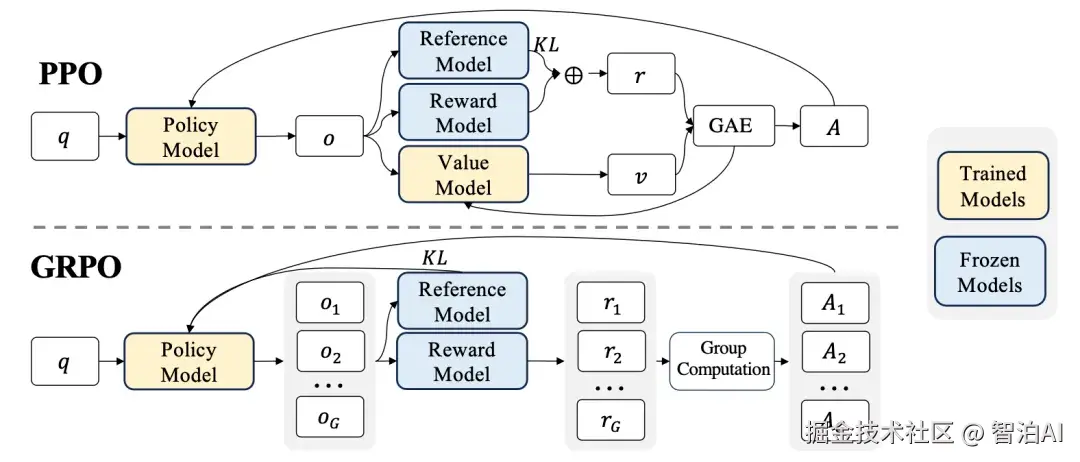
首个将强化学习引入大模型训练的开创性工作是 Training language models to follow instructions with human feedback(2022),该研究采用 PPO 算法实现模型输出与人类意图的对齐,从而催生了 InstructGPT。
在此框架中,智能体即为大语言模型自身;环境由输入的 prompt(如问题或指令)构成,其目标是引导模型生成响应;
而动作则对应模型在每个时间步所生成的文本片段,每一个文本token的输出均视为序列决策过程中的一个独立行动。
Reward 的评估依赖于一个独立训练的奖励模型:针对同一 prompt,系统会采样多个模型输出,由人工标注者对这些输出进行排序与偏好标注,进而利用这些带顺序的反馈数据训练出一个能量化评估"prompt+回答"组合质量的奖励函数。
该奖励模型输出的分数,即作为强化学习过程中的信号反馈。这一机制实现了将人类主观的表达偏好直接嵌入模型优化目标,而此类非可微的偏好信号,唯有通过强化学习框架才能有效整合。
Value function 则采用与主模型完全一致的架构,其作用是预测在生成每个 token 时,后续序列最终所能获得的累积奖励预期。
整体的损失函数表示如下,其中第一项是PPO损失,文中将PPO的KL散度约束改成了per-token的,即预训练模型和偏好对齐后的模型每个token的分布不能差异太大。同时也引入了前序非强化学习的预训练loss进行混合训练。
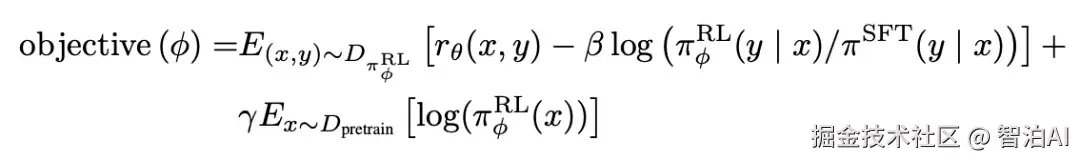
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models(2024)引入了一种更高效的GRPO算法,用以替代传统的PPO方法。
在PPO框架中,为评估每个生成token的未来期望回报,需依赖一个value function作为基准(baseline),该函数通常与策略网络(即大模型本身)共享结构,参数规模庞大,显著推高了计算开销。
GRPO的创新之处在于彻底摒弃了这一value function,转而利用同一问题下多条采样输出的奖励信号,通过计算其均值与方差对当前样本的奖励进行归一化处理,从而实现对baseline功能的等效替代。
二者的核心差异在于:PPO依赖模型自身对奖励期望的预测值作为基准,而GRPO则完全基于采样结果经由奖励模型评分后所得的统计量来构建基准。
DAPO: An Open-Source LLM Reinforcement Learning System at Scale(2025)针对PPO与GRPO在大规模语言模型训练中的瓶颈,提出了四项关键改进:
PPO的Clip约束优化:传统PPO通过重要性采样引入的Clip机制,其上限设定与KL散度类似,旨在控制策略更新时行为分布的偏移。
然而,该机制过度抑制了低概率token的探索,同时难以有效约束高概率token的过度扩张。
为此,DAPO放宽了Clip的上限阈值,以增强探索自由度并平衡策略更新的稳定性。
GRPO采样策略调整:在训练后期,大量采样样本的奖励值趋于一致且精确,导致梯度信号冗余、训练效率下降。
DAPO通过增加采样总数,并主动剔除奖励完全一致的重复样本,显著提升了有效梯度的多样性与更新效率。
损失计算粒度重构:原方法在sample维度对token损失取平均,致使长序列中单个token的优劣表现被整体平滑掩盖。
DAPO改用token级损失计算,使每个生成token的预测误差独立贡献梯度,从而更精准地引导模型优化。
超长样本加权降权:由于token级损失对截断样本更敏感,过长序列被截断后引入的训练不稳定性加剧。
DAPO依据样本超出最大长度的比例动态调整其loss权重:超出比例越高,权重越低,从而在保留长文本信息的同时缓解训练震荡。
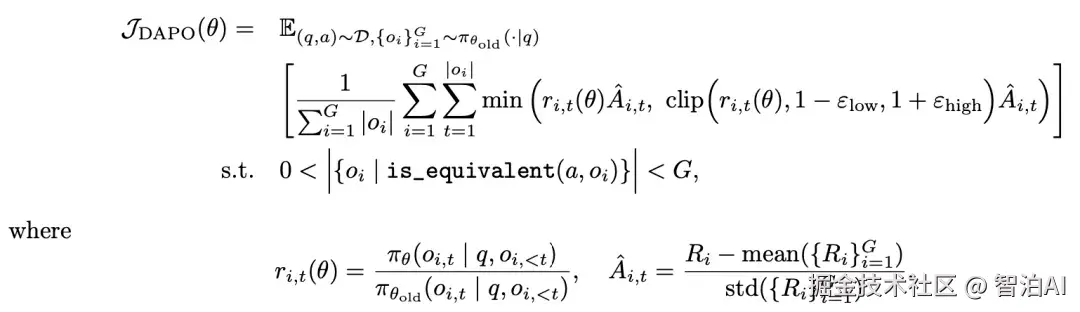
除了上述标准强化学习方法外,有的模型也利用其他方法模拟强化学习的偏好对齐能力。
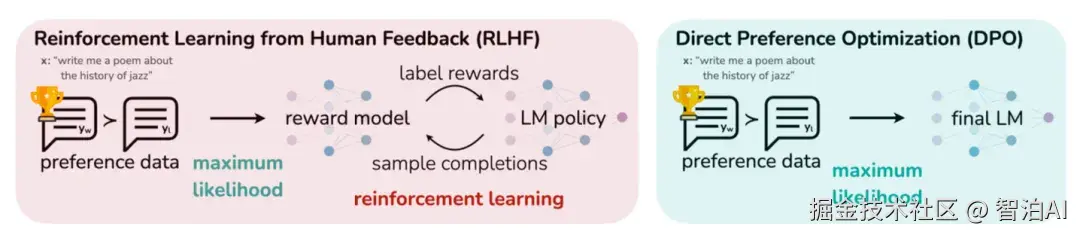
例如Direct Preference Optimization: Your Language Model is Secretly a Reward Model(2024)论文中提出的DPO方法。
基于人工标注的最好的样本和最差的样本构建pair-wise样本,让模型预测好样本概率大于差样本,绕过了强化学习,Qwen模型中也使用该方法进行偏好对齐。
四、推荐大模型中的强化学习应用
在推荐大模型的框架中,强化学习方法的运用基本继承自语言大模型的主流范式,其关键区别体现在 reward 的定义方式上:在推荐系统中,通常依据用户日志行为(如播放时长、点击率等)来衡量用户对推荐内容的偏好程度。
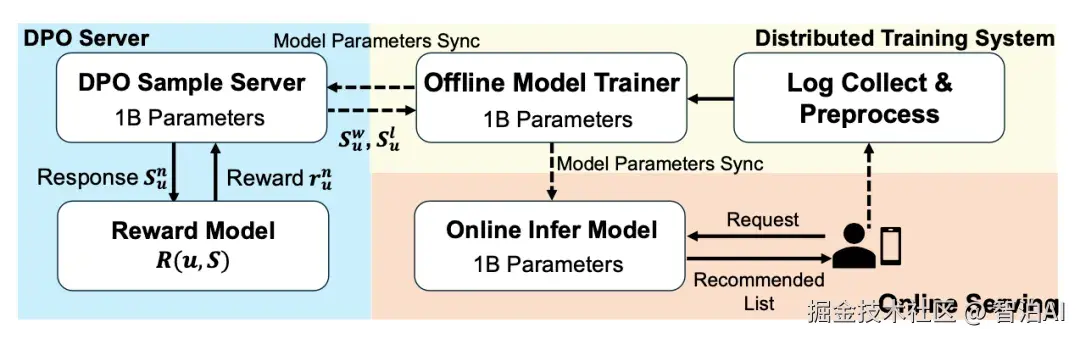
在 Onerec 的第一版实现中,reward model 的训练方式借鉴了精排模型的结构,将多个核心目标(如有效播放、点击率等)统一建模为 reward 信号。
针对单个用户的一次 session 请求,系统通过 beam search 生成若干候选推荐序列,随后利用精排模型为每个序列计算综合 reward 分数,并从中选取 reward 值最高与最低的两个样本构成正负配对,最终基于 DPO 损失函数完成模型优化。
在 Onerec V2 中,同样引入了强化学习以实现推荐大模型的偏好对齐。其 reward 设计更为简洁,完全依赖人工设定 reward 值:
将用户观看的视频按市场维度分组,若某视频的观看时长位于该分组内该用户历史观看时长的前 25% 区间,则 reward 设为 1;
若用户对视频执行了显式负反馈操作,则 reward 置为 0。这一机制将 PPO 算法中 value function 与 baseline 的比较功能,直接嵌入至人工 reward 的构建环节。
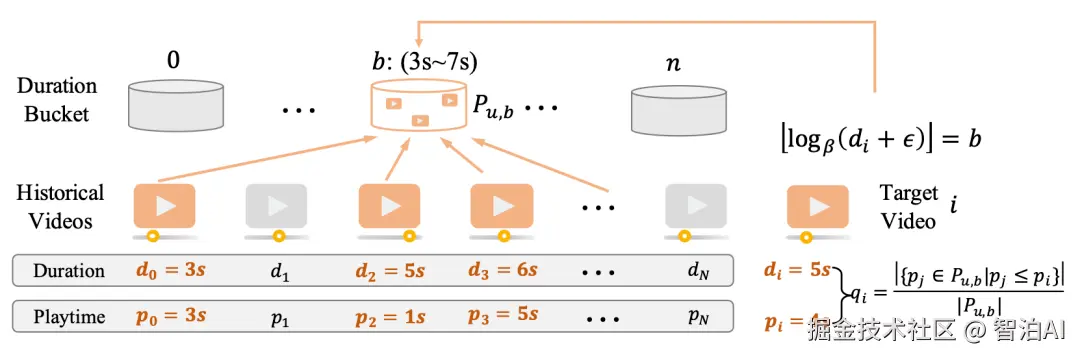

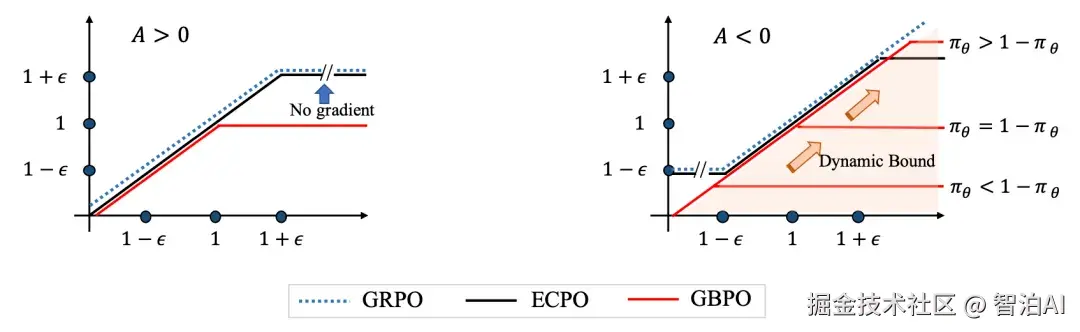
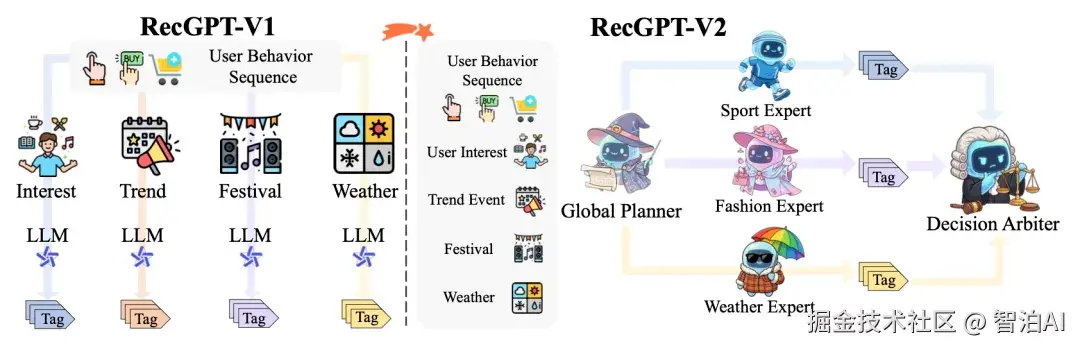
在RecGPTV2中,也采用了强化学习的方法对RecGPTV1进行偏好对齐。RecGPTV2采用GRPO进行优化,主要差异是在reward的设计上。
在每个Expert的训练上,reward综合考虑了item tag预测的准确率、基于用户偏好对训练的奖励模型的打分、生成结果的多样性(每个tag映射成表征计算两两cosine距离的均值)等。
可以看到在推荐大模型领域,reward的设计会更加复杂,需要综合考虑用户偏好、多样性、负反馈等各种信息。