深度学习作为人工智能领域最引人注目的技术突破,其学习路径与传统机器学习之间的关系一直是学术界和工业界热议的话题。本文将从架构师的视角,系统分析深度学习与机器学习之间的知识依赖关系,探讨学习深度学习是否必须首先掌握机器学习的核心理论。通过技术演进的历史脉络分析、关键问题剖析以及实际案例与代码示例,本文将提供一条清晰的知识发展路径,帮助读者构建系统化的深度学习知识体系。

深度学习的本质定位:机器学习的高级范式
深度学习在AI体系中的位置
深度学习并非独立于机器学习之外的全新领域,而是机器学习的一个重要分支和发展阶段。从概念层级上看,人工智能包含机器学习,而机器学习又包含深度学习。这种包含关系决定了深度学习的学习必然建立在机器学习的基础理论之上。
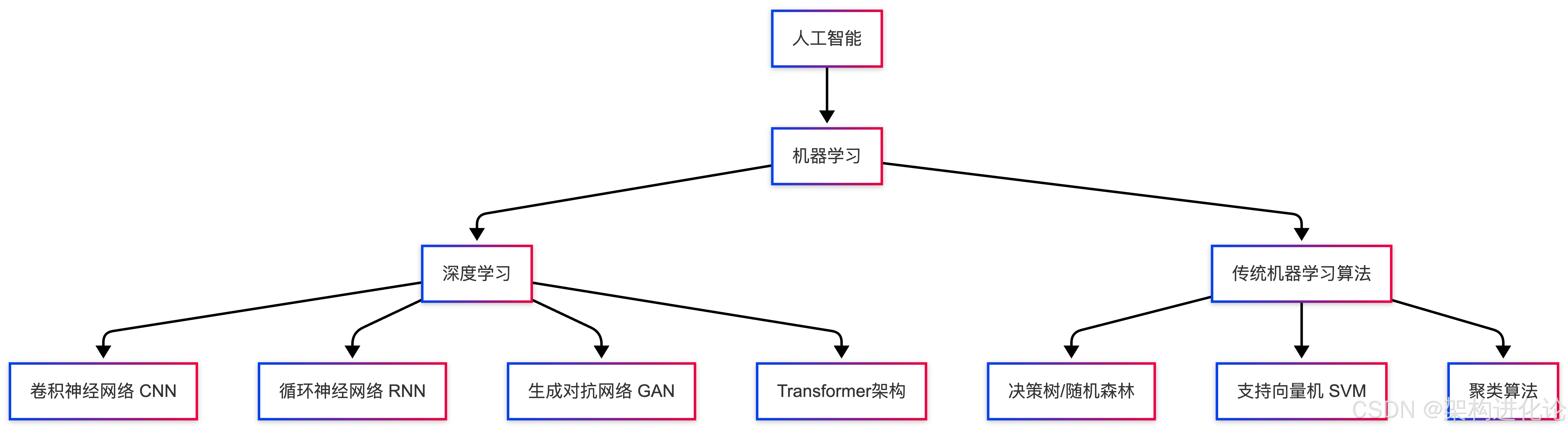
深度学习的核心特征
深度学习通过多层次的非线性变换,实现了对数据的高层次抽象表示学习。与传统机器学习相比,深度学习具有以下核心特征:
-
端到端学习:直接从原始数据学习目标输出,减少特征工程依赖
-
层次化表示:通过多个隐藏层逐级提取特征
-
自动特征提取:模型自动学习数据的有效表示,而非人工设计特征
-
大数据依赖:通常需要大量数据才能发挥优势
-
计算密集:依赖强大的计算资源(特别是GPU)
为什么学习深度学习需要机器学习基础
理论基础共享
深度学习建立在机器学习的理论框架之上,共享以下核心概念:
-
损失函数与优化:深度学习同样需要定义目标函数并使用梯度下降等优化方法
-
过拟合与正则化 :深度神经网络同样面临过拟合问题,需要dropout、权重衰减等正则化技术(扩展阅读:正则化技术演进:从理论基石到创新设计)
-
评估指标:准确率、精确率、召回率、F1分数等评估指标在深度学习中同样适用
-
偏差-方差权衡:这一机器学习核心理论在深度学习中仍然至关重要
数学基础要求
深度学习所需的数学知识与机器学习高度重叠:
-
线性代数:矩阵运算、特征值分解等
-
微积分:梯度计算、链式法则等
-
概率统计:概率分布、最大似然估计等
-
优化理论:凸优化、随机梯度下降等
实践技能迁移
机器学习的实践技能为深度学习提供坚实基础:
-
数据预处理:数据清洗、归一化、标准化等技能
-
模型评估:交叉验证、超参数调优等方法
-
问题拆解:将实际问题转化为机器学习问题的思维框架
技术演进:从传统机器学习到深度学习的必然路径
前深度学习时代的技术局限
在深度学习兴起之前,传统机器学习方法在处理复杂模式识别任务时面临诸多挑战:
-
特征工程瓶颈:模型性能高度依赖人工设计的特征
-
表示能力有限:浅层模型难以捕捉数据中的复杂非线性关系
-
泛化能力不足:对于高维、复杂数据,传统方法容易过拟合
-
手工特征的主观性:特征设计依赖领域专家知识,难以标准化
深度学习的突破性进展
深度学习的兴起解决了传统机器学习的多个核心问题:
python
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
# 传统机器学习方法:手工特征提取 + 分类器
class TraditionalImageClassifier:
def extract_features(self, images):
"""手工提取图像特征(如HOG、SIFT等)"""
# 传统方法需要复杂的特征工程
features = []
for img in images:
# 简化的特征提取示例:颜色直方图 + 边缘特征
color_hist = self.extract_color_histogram(img)
edge_features = self.extract_edge_features(img)
combined_features = np.concatenate([color_hist, edge_features])
features.append(combined_features)
return np.array(features)
def train_classifier(self, features, labels):
"""训练传统分类器(如SVM)"""
from sklearn.svm import SVC
classifier = SVC(kernel='rbf')
classifier.fit(features, labels)
return classifier
# 深度学习方法:端到端学习
def build_cnn_model(input_shape, num_classes):
"""构建卷积神经网络,自动学习特征"""
model = models.Sequential([
# 第一卷积层:自动提取低级特征(边缘、纹理等)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape),
layers.MaxPooling2D((2, 2)),
# 第二卷积层:提取中级特征(形状部件等)
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 第三卷积层:提取高级特征(对象部件等)
layers.Conv2D(64, (3, 3), activation='relu'),
# 展平层
layers.Flatten(),
# 全连接层:组合特征进行分类
layers.Dense(64, activation='relu'),
layers.Dense(num_classes, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# 对比两种方法的差异
"""
传统机器学习流程:
1. 手工设计特征提取器
2. 提取所有图像的特征
3. 训练分类器
4. 对新图像:先提取特征,再分类
深度学习流程:
1. 构建端到端网络
2. 输入原始图像
3. 网络自动学习特征并分类
4. 对新图像:直接输入网络得到结果
"""关键技术突破时间线
案例:从传统方法到深度学习的演进
案例:手写数字识别
传统机器学习方法(如SVM):
-
人工设计特征:提取图像的HOG(方向梯度直方图)特征
-
将每个图像转换为固定长度的特征向量
-
使用SVM等分类器进行训练
-
准确率通常在95-98%之间
深度学习方法(CNN):
-
输入原始像素图像
-
卷积层自动学习边缘、角点等特征
-
深层网络组合低级特征形成数字形状
-
准确率可达99.5%以上
代码示例对比
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, metrics
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
import tensorflow as tf
from tensorflow.keras.datasets import mnist
# 加载MNIST数据集
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 数据预处理
X_train = X_train.reshape(-1, 28*28) / 255.0
X_test = X_test.reshape(-1, 28*28) / 255.0
# 方法1:传统机器学习(SVM + PCA降维)
def traditional_ml_pipeline(X_train, y_train, X_test, y_test):
"""传统机器学习流程"""
print("=== 传统机器学习方法(SVM) ===")
# PCA降维:保留主要特征,减少计算复杂度
pca = PCA(n_components=100)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 训练SVM分类器
svm_classifier = svm.SVC(kernel='rbf', gamma='scale')
svm_classifier.fit(X_train_pca, y_train)
# 预测和评估
y_pred = svm_classifier.predict(X_test_pca)
accuracy = metrics.accuracy_score(y_test, y_pred)
print(f"PCA保留维度: 100")
print(f"SVM准确率: {accuracy:.4f}")
print(f"分类报告:\n{metrics.classification_report(y_test, y_pred)}")
return svm_classifier, accuracy
# 方法2:深度学习方法(简单神经网络)
def deep_learning_pipeline(X_train, y_train, X_test, y_test):
"""深度学习流程"""
print("\n=== 深度学习方法(神经网络) ===")
# 重塑数据为适合CNN的格式
X_train_cnn = X_train.reshape(-1, 28, 28, 1)
X_test_cnn = X_test.reshape(-1, 28, 28, 1)
# 构建简单的CNN模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5), # 正则化防止过拟合
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(X_train_cnn, y_train,
epochs=10,
batch_size=64,
validation_split=0.2,
verbose=1)
# 评估模型
test_loss, test_acc = model.evaluate(X_test_cnn, y_test, verbose=0)
print(f"测试准确率: {test_acc:.4f}")
# 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.title('模型准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.title('模型损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.tight_layout()
plt.show()
return model, test_acc
# 比较两种方法
print("手写数字识别:传统机器学习 vs 深度学习")
print("=" * 50)
# 使用部分数据加快演示
sample_size = 10000
X_train_sample = X_train[:sample_size]
y_train_sample = y_train[:sample_size]
X_test_sample = X_test[:2000]
y_test_sample = y_test[:2000]
# 执行两种方法
svm_model, svm_acc = traditional_ml_pipeline(
X_train_sample, y_train_sample,
X_test_sample, y_test_sample
)
dl_model, dl_acc = deep_learning_pipeline(
X_train_sample, y_train_sample,
X_test_sample, y_test_sample
)
# 结果对比
print("\n=== 方法对比总结 ===")
print(f"SVM准确率: {svm_acc:.4f}")
print(f"深度学习准确率: {dl_acc:.4f}")
print(f"性能提升: {(dl_acc - svm_acc)*100:.2f}%")
# 分析差异原因
print("\n=== 关键差异分析 ===")
print("1. 特征处理:")
print(" - SVM: 需要PCA降维,可能丢失重要特征")
print(" - CNN: 自动学习分层特征,保留空间信息")
print("\n2. 模型复杂度:")
print(" - SVM: 相对简单,决策边界由支持向量决定")
print(" - CNN: 高度非线性,通过多层变换学习复杂模式")
print("\n3. 数据需求:")
print(" - SVM: 在小样本上表现良好")
print(" - CNN: 需要更多数据,但能学习更复杂的特征")深度学习架构的演进与创新设计
核心架构组件演进

现代深度学习架构设计原则
-
模块化设计:将网络分解为可重用的组件
-
残差连接:解决深度网络梯度消失问题
-
注意力机制:动态聚焦重要信息
-
归一化技术:稳定训练过程
-
正则化策略:防止过拟合
创新架构示例:ResNet与Transformer融合设计
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResidualBlock(nn.Module):
"""残差块:解决深度网络训练难题"""
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(
in_channels, out_channels,
kernel_size=3, stride=stride, padding=1, bias=False
)
self.bn1 = nn.BatchNorm2d(out_channels)
# 第二个卷积层
self.conv2 = nn.Conv2d(
out_channels, out_channels,
kernel_size=3, stride=1, padding=1, bias=False
)
self.bn2 = nn.BatchNorm2d(out_channels)
# 快捷连接(shortcut)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
# 残差连接:F(x) + x
residual = self.shortcut(x)
# 主路径
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# 添加残差连接
out += residual
out = F.relu(out)
return out
class MultiHeadAttention(nn.Module):
"""多头注意力机制:Transformer核心组件"""
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
assert embed_dim % num_heads == 0
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# 查询、键、值的线性变换
self.q_linear = nn.Linear(embed_dim, embed_dim)
self.k_linear = nn.Linear(embed_dim, embed_dim)
self.v_linear = nn.Linear(embed_dim, embed_dim)
# 输出线性变换
self.out_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 线性变换并分头
Q = self.q_linear(query).view(
batch_size, -1, self.num_heads, self.head_dim
).transpose(1, 2)
K = self.k_linear(key).view(
batch_size, -1, self.num_heads, self.head_dim
).transpose(1, 2)
V = self.v_linear(value).view(
batch_size, -1, self.num_heads, self.head_dim
).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / \
torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 注意力输出
attention_output = torch.matmul(attention_weights, V)
# 合并多头
attention_output = attention_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.embed_dim
)
# 输出线性变换
output = self.out_linear(attention_output)
return output, attention_weights
class HybridResNetTransformer(nn.Module):
"""混合架构:ResNet特征提取 + Transformer序列建模"""
def __init__(self, num_classes=10):
super(HybridResNetTransformer, self).__init__()
# ResNet特征提取部分
self.resnet_blocks = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
ResidualBlock(64, 64),
ResidualBlock(64, 64),
ResidualBlock(64, 128, stride=2),
ResidualBlock(128, 128),
ResidualBlock(128, 256, stride=2),
ResidualBlock(256, 256),
)
# 自适应池化
self.adaptive_pool = nn.AdaptiveAvgPool2d((1, 1))
# Transformer编码器部分
encoder_layer = nn.TransformerEncoderLayer(
d_model=256, nhead=8, dim_feedforward=1024,
dropout=0.1, activation='relu', batch_first=True
)
self.transformer_encoder = nn.TransformerEncoder(
encoder_layer, num_layers=6
)
# 分类头
self.classifier = nn.Sequential(
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128, num_classes)
)
def forward(self, x):
# ResNet提取空间特征
spatial_features = self.resnet_blocks(x)
# 池化减少空间维度
pooled_features = self.adaptive_pool(spatial_features)
batch_size = pooled_features.size(0)
features_flat = pooled_features.view(batch_size, 1, -1)
# Transformer建模序列关系
# 添加位置编码(简化版本)
seq_length = features_flat.size(1)
position = torch.arange(seq_length).unsqueeze(0).unsqueeze(-1).float()
div_term = torch.exp(torch.arange(0, 256, 2).float() *
-(torch.log(torch.tensor(10000.0)) / 256))
position_encoding = torch.zeros(seq_length, 256)
position_encoding[:, 0::2] = torch.sin(position * div_term)
position_encoding[:, 1::2] = torch.cos(position * div_term)
position_encoding = position_encoding.unsqueeze(0).to(x.device)
features_with_pos = features_flat + position_encoding
# Transformer编码
transformer_output = self.transformer_encoder(features_with_pos)
# 全局平均池化
global_features = transformer_output.mean(dim=1)
# 分类
output = self.classifier(global_features)
return output
# 模型使用示例
def demonstrate_hybrid_model():
"""演示混合模型的使用"""
# 创建模型实例
model = HybridResNetTransformer(num_classes=10)
# 模拟输入数据(batch_size=4, 1通道, 28x28图像)
dummy_input = torch.randn(4, 1, 28, 28)
# 前向传播
output = model(dummy_input)
print("混合模型架构演示")
print("=" * 50)
print(f"输入形状: {dummy_input.shape}")
print(f"输出形状: {output.shape}")
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
# 计算复杂度分析
print("\n=== 架构优势分析 ===")
print("1. ResNet部分:")
print(" - 提取空间层次特征")
print(" - 残差连接解决梯度消失")
print(" - 适合图像局部模式")
print("\n2. Transformer部分:")
print(" - 建模全局依赖关系")
print(" - 多头注意力捕捉复杂关系")
print(" - 适合序列和长期依赖")
print("\n3. 混合优势:")
print(" - 结合局部和全局信息")
print(" - 更强的表示能力")
print(" - 更好的泛化性能")
return model, output
# 执行演示
model, output = demonstrate_hybrid_model()
学习路径设计:从机器学习到深度学习的渐进路线
分阶段学习路线图

实践项目路线
-
基础项目:线性回归、逻辑回归实现
-
中级项目:手写数字识别、情感分析
-
高级项目:图像分割、机器翻译
-
创新项目:GAN生成艺术、强化学习游戏AI
学习资源建议
python
class LearningPathRecommender:
"""个性化学习路径推荐系统"""
def __init__(self, learner_level, target_domain):
"""
初始化推荐器
参数:
learner_level: 学习水平 ('beginner', 'intermediate', 'advanced')
target_domain: 目标领域 ('cv', 'nlp', 'rl', 'general')
"""
self.learner_level = learner_level
self.target_domain = target_domain
# 定义学习资源
self.resources = {
'math_foundation': {
'books': ['线性代数及其应用', '概率论与数理统计', '凸优化'],
'courses': ['MIT 18.06 线性代数', 'Stanford CS229 概率']
},
'ml_foundation': {
'books': ['Pattern Recognition and Machine Learning',
'机器学习-周志华'],
'courses': ['Coursera 机器学习-吴恩达', 'fast.ai 实践课程']
},
'dl_foundation': {
'books': ['Deep Learning', '神经网络与深度学习'],
'courses': ['CS231n 卷积神经网络', 'CS224n 自然语言处理']
},
'advanced_dl': {
'books': ['动手学深度学习', '生成对抗网络'],
'courses': ['深度学习专项课程', '强化学习专项']
}
}
# 定义项目建议
self.projects = {
'beginner': [
'MNIST手写数字分类',
'波士顿房价预测',
'鸢尾花分类'
],
'intermediate': [
'CIFAR-10图像分类',
'IMDb电影评论情感分析',
'手写数学公式识别'
],
'advanced': [
'图像风格迁移',
'文本生成',
'AlphaGo简化版'
]
}
def recommend_path(self):
"""推荐学习路径"""
print(f"=== {self.learner_level.upper()}级别学习路径推荐 ===")
print(f"目标领域: {self.target_domain.upper()}")
print("=" * 40)
# 基础阶段
print("\n1. 基础阶段 (1-2个月):")
print(" - 数学基础复习")
print(f" 推荐书籍: {', '.join(self.resources['math_foundation']['books'][:2])}")
print(f" 推荐课程: {self.resources['math_foundation']['courses'][0]}")
# 机器学习阶段
print("\n2. 机器学习阶段 (2-3个月):")
print(" - 掌握核心算法")
print(f" 推荐书籍: {self.resources['ml_foundation']['books'][0]}")
print(f" 推荐课程: {self.resources['ml_foundation']['courses'][0]}")
print(f" 实践项目: {', '.join(self.projects['beginner'][:2])}")
# 深度学习阶段
print("\n3. 深度学习阶段 (3-4个月):")
print(" - 神经网络与深度学习")
print(f" 推荐书籍: {self.resources['dl_foundation']['books'][0]}")
if self.target_domain == 'cv':
print(f" 推荐课程: {self.resources['dl_foundation']['courses'][0]}")
print(f" 实践项目: {self.projects['intermediate'][0]}")
elif self.target_domain == 'nlp':
print(f" 推荐课程: {self.resources['dl_foundation']['courses'][1]}")
print(f" 实践项目: {self.projects['intermediate'][1]}")
# 高级阶段
if self.learner_level in ['intermediate', 'advanced']:
print("\n4. 高级阶段 (4-6个月):")
print(" - 专业领域深入")
print(f" 推荐书籍: {self.resources['advanced_dl']['books'][0]}")
print(f" 实践项目: {', '.join(self.projects['advanced'][:2])}")
if self.target_domain == 'cv':
print(" - 计算机视觉专题:")
print(" 目标检测、图像分割、人脸识别")
elif self.target_domain == 'nlp':
print(" - 自然语言处理专题:")
print(" 机器翻译、文本生成、问答系统")
print("\n" + "=" * 40)
print("提示: 实践优先,理论学习与实践项目交替进行")
def estimate_timeline(self):
"""估算学习时间线"""
timelines = {
'beginner': {
'foundation': '1-2个月',
'ml': '2-3个月',
'dl_basics': '3-4个月',
'total': '6-9个月'
},
'intermediate': {
'foundation': '1个月',
'ml': '1-2个月',
'dl_basics': '2-3个月',
'advanced': '3-4个月',
'total': '7-10个月'
},
'advanced': {
'foundation': '2周',
'ml': '1个月',
'dl_basics': '1-2个月',
'advanced': '2-3个月',
'total': '4-6个月'
}
}
timeline = timelines.get(self.learner_level, timelines['beginner'])
print(f"\n=== 学习时间估算 ({self.learner_level}) ===")
for stage, duration in timeline.items():
print(f"{stage.replace('_', ' ').title()}: {duration}")
return timeline
# 使用示例
print("深度学习学习路径规划系统")
print("=" * 50)
# 为不同水平的学习者推荐路径
for level in ['beginner', 'intermediate', 'advanced']:
recommender = LearningPathRecommender(level, 'cv')
recommender.recommend_path()
recommender.estimate_timeline()
print("\n" + "=" * 50 + "\n")行业应用与未来趋势
深度学习在各行业的应用
-
医疗健康:医学影像分析、药物发现、疾病预测
-
金融服务:欺诈检测、风险评估、算法交易
-
自动驾驶:环境感知、路径规划、决策控制
-
智能制造:质量控制、预测维护、供应链优化
-
内容创作:文本生成、图像合成、视频制作
技术发展趋势
-
模型大型化:参数规模持续增长,能力边界扩展
-
多模态融合:文本、图像、语音等多模态统一建模
-
可解释性增强 :从黑盒模型向可解释AI发展(扩展阅读:可解释AI(XAI):构建透明可信人工智能的架构设计与实践)
-
绿色AI:关注能耗效率,发展可持续AI
-
边缘AI:模型轻量化,部署到边缘设备
创新研究方向
python
class ResearchTrendsAnalyzer:
"""深度学习研究趋势分析"""
def __init__(self):
self.trends = {
'foundational_models': {
'description': '基础模型,一次预训练多次使用',
'examples': ['GPT系列', 'BERT', 'CLIP'],
'impact': '高',
'maturity': '中等'
},
'multimodal_learning': {
'description': '多模态数据联合学习',
'examples': ['DALL-E', 'VisualBERT', 'SpeechBERT'],
'impact': '高',
'maturity': '早期'
},
'efficient_ai': {
'description': '高效率、低能耗AI',
'examples': ['知识蒸馏', '模型剪枝', '量化'],
'impact': '中等',
'maturity': '中等'
},
'neuro_symbolic_ai': {
'description': '神经符号AI,结合深度学习与符号推理',
'examples': ['神经网络+知识图谱', '符号引导学习'],
'impact': '高',
'maturity': '早期'
},
'federated_learning': {
'description': '联邦学习,保护隐私的分布式学习',
'examples': ['横向联邦学习', '纵向联邦学习'],
'impact': '中等',
'maturity': '早期'
}
}
def analyze_trends(self):
"""分析研究趋势"""
print("深度学习研究趋势分析")
print("=" * 60)
for trend, info in self.trends.items():
trend_name = trend.replace('_', ' ').title()
print(f"\n{trend_name}:")
print(f" 描述: {info['description']}")
print(f" 代表工作: {', '.join(info['examples'][:3])}")
print(f" 影响力: {info['impact']}")
print(f" 成熟度: {info['maturity']}")
# 推荐研究方向
if info['maturity'] == '早期':
print(" 推荐: 适合创新研究,有机会产生突破")
elif info['maturity'] == '中等':
print(" 推荐: 适合工程优化和商业应用")
print("\n" + "=" * 60)
print("未来5年关键发展方向:")
print("1. 基础模型的规模化与专业化")
print("2. 多模态统一表示学习")
print("3. AI可解释性与可信性")
print("4. 资源受限环境下的高效AI")
print("5. AI与人类协作的交互范式")
def recommend_research_topics(self, experience_level):
"""推荐研究课题"""
topics_by_level = {
'beginner': [
'深度学习模型在特定任务的优化',
'已有架构在新领域的应用',
'数据增强技术的改进'
],
'intermediate': [
'新型注意力机制设计',
'多任务学习框架',
'领域自适应方法'
],
'advanced': [
'新型神经网络架构探索',
'自监督学习范式创新',
'AI与神经科学交叉研究'
]
}
print(f"\n=== {experience_level.upper()}级别研究课题推荐 ===")
for i, topic in enumerate(topics_by_level[experience_level], 1):
print(f"{i}. {topic}")
# 分析研究趋势
analyzer = ResearchTrendsAnalyzer()
analyzer.analyze_trends()
# 为不同经验水平推荐研究课题
for level in ['beginner', 'intermediate', 'advanced']:
analyzer.recommend_research_topics(level)
print()从机器学习到深度学习的知识演进
深度学习并非孤立的技术领域,而是机器学习发展到一定阶段的必然产物。学习深度学习确实需要机器学习的基础,但这种需要并非简单的先后顺序,而是一种知识体系的自然延伸和深化。
核心观点总结
-
知识连续性:深度学习建立在机器学习的理论基础之上,共享核心概念和数学工具
-
思维模式演进:从特征工程到表示学习,思维模式发生了根本转变
-
技术互补性:深度学习与传统机器学习并非替代关系,而是各有适用场景
-
学习效率:具备机器学习基础能更高效地理解深度学习原理和优化方法
实践建议
对于想要深入学习深度学习的从业者,建议采取以下路径:
-
打好基础:掌握机器学习核心理论和数学基础
-
实践驱动:通过项目实践理解算法原理和应用场景
-
渐进深入:从简单网络开始,逐步深入复杂架构
-
关注前沿:持续跟踪最新研究进展和技术趋势
-
跨界思考:结合领域知识,解决实际应用问题
未来展望
随着深度学习技术的不断成熟和发展,未来的AI系统将更加智能、高效和可靠。从机器学习到深度学习的学习路径将变得更加清晰和系统化,但核心的学习原则不会改变:坚实的理论基础、持续的实践探索和开放的创新思维。
深度学习的学习之旅是充满挑战但也极其值得的过程。无论你是初学者还是有经验的从业者,理解从机器学习到深度学习的知识演进路径,都将帮助你在这个快速发展的领域中建立稳固的知识体系,为未来的创新和应用打下坚实基础。