
苹果公司为我提供了这台Mac Studio集群,用于测试macOS 26.2的新功能------基于雷电接口的RDMA技术。最便捷的测试方式是使用开源私有AI集群工具Exo 1.0。通过RDMA技术,这些Mac可以像共享一个巨型内存池般协同工作,从而显著提升大型AI模型等任务的运行效率。
我测试的这个内存总量达1.5TB的Mac集群,其成本略低于4万美元。说实话,我个人实在找不出花这笔钱的正当理由------这些Mac Studio是苹果借给我测试的。同时要感谢DeskPi公司寄来了装载该集群的四立柱迷你机架。
记忆中上一次听到苹果与高性能计算(HPC)相关的趣闻,还要追溯到二十世纪初他们还在生产Xserve服务器的年代。
他们曾拥有名为Xgrid的专有集群解决方案...最终却黯然退场。几所大学搭建过这类集群,但始终未能真正流行,如今Xserver已成为遥远记忆。
不知是机缘巧合还是苹果的长期布局,M3 Ultra版Mac Studio在本地AI模型运行方面找到了完美平衡点。随着RDMA技术支持将内存访问延迟从300微秒降至50微秒以内,集群现在能显著提升性能,尤其是运行大型模型时。
这些设备在创意应用和小规模科学计算领域同样表现出色,同时保持低于250瓦的功耗和近乎无声的运行状态。
底部两台Mac配备512GB统一内存和32个CPU核心,单台售价11,699美元。上方两台内存减半的机型则为8,099美元每台。
价格确实不菲。
但随着英伟达推出DGX Spark系统,AMD发布AI Max+ 395方案(两者最大内存仅128GB,相当于四分之一容量),我决定对这个集群进行全面测试。
迷你Mac机架
就在这些Mac电脑到货的前一天,DeskPi适时地送来了一款名为TL1的新型四柱迷你机架。

今年早些时候我启动了MINI RACK项目,其核心理念是让你既能享受机架式设备的优势,又能将其以适合桌面摆放或角落收纳的紧凑尺寸呈现。
目前除了这款3D打印外壳外,我还没发现其他能将Mac Studio装入10英寸机架的解决方案,所以暂时只是把它们放在10英寸机架托盘上。
任何非Pro版Mac上架时最麻烦的就是电源键。Mac Studio的电源键位于背部左侧的弧形表面上,这意味着机架解决方案必须设计特殊的触发方式。
这种开放式迷你机架设计让我可以伸手按到电源键,但操作时还得扶着Mac Studio机身,防止它从前面滑落!
好在Studio前置接口可以直接连接键盘和显示器:

对于电源方面,我很高兴苹果采用了内置电源设计。太多"小型"PC之所以体积小,仅仅是因为它们把电源塞进了机箱外部的巨大砖块里。但这款产品并非如此,不过你必须处理苹果的非C13电源线(这意味着更难找到长度完美的线缆来减少需要管理的线束)。

DGX Spark在网络性能上优于苹果设备。它配备了大型矩形QSFP端口(如上图所示),这种插头既稳固耐用又便于插拔。
Mac Studio配备10Gbps以太网接口,但其高速网络功能(实际吞吐量约50-60Gbps)依赖雷电接口实现。即便使用每条售价70美元的高端苹果线缆,在多场景环境中这种复杂的插接系统也难以长期稳定工作。
现有ThunderLok-A技术通过微型螺丝固定线缆,但我不可能对借测的Mac Studio进行钻孔攻丝来验证其可行性。
另外据我所知,目前尚无雷电5交换机问世,这意味着无法将多台Mac接入中央交换机------必须实现所有设备间的点对点直连,导致线缆管理更加混乱。现阶段最多支持四台Mac交叉互联,但现有Mac Studio可能突破此限制(苹果宣称所有五个TB5端口均支持RDMA)。
更核心的问题是:真的需要组建完整Mac Studio集群吗?单台性能已堪比四台顶配DGX Spark或AI Max+ 395系统,而集群管理本身就会带来诸多挑战。
M3 Ultra Mac Studio - Benchmark Tests
为辅助决策,我进行了一系列基准测试,并将所有结果(比本篇博文提及的更全面)发布至我的sbc-reviews项目。
现将M3 Ultra Mac Studio与以下设备进行对比:
- 搭载GB10的戴尔Pro Max(类似英伟达DGX Spark,但散热更优)
- Framework桌面主板(配备AMD AI Max+ 395芯片)
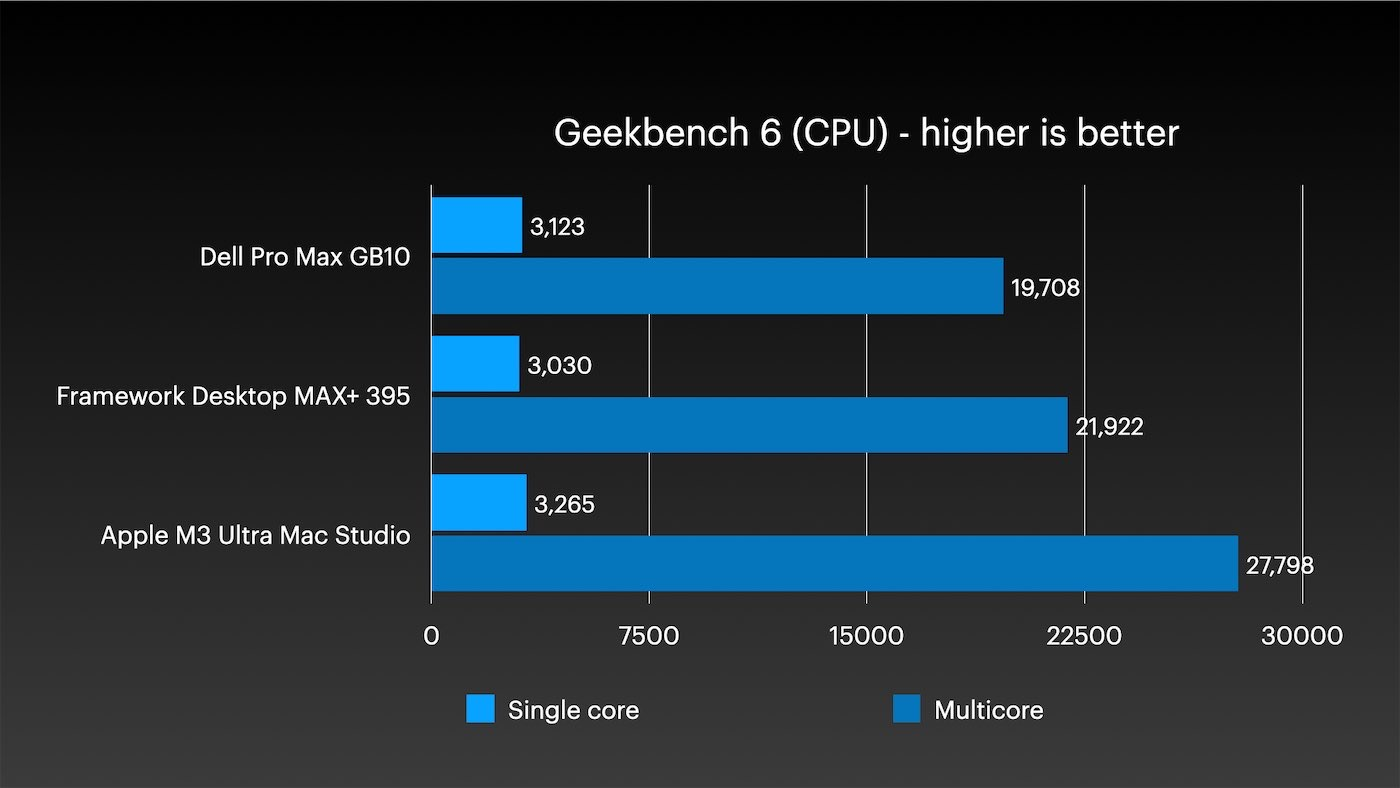
首先来看Geekbench测试。搭载两代前CPU核心的M3 Ultra芯片,在单核与多核性能表现上均超越另外两款竞品(在更适合多核CPU测试的Geekbench 5中优势更为明显)。
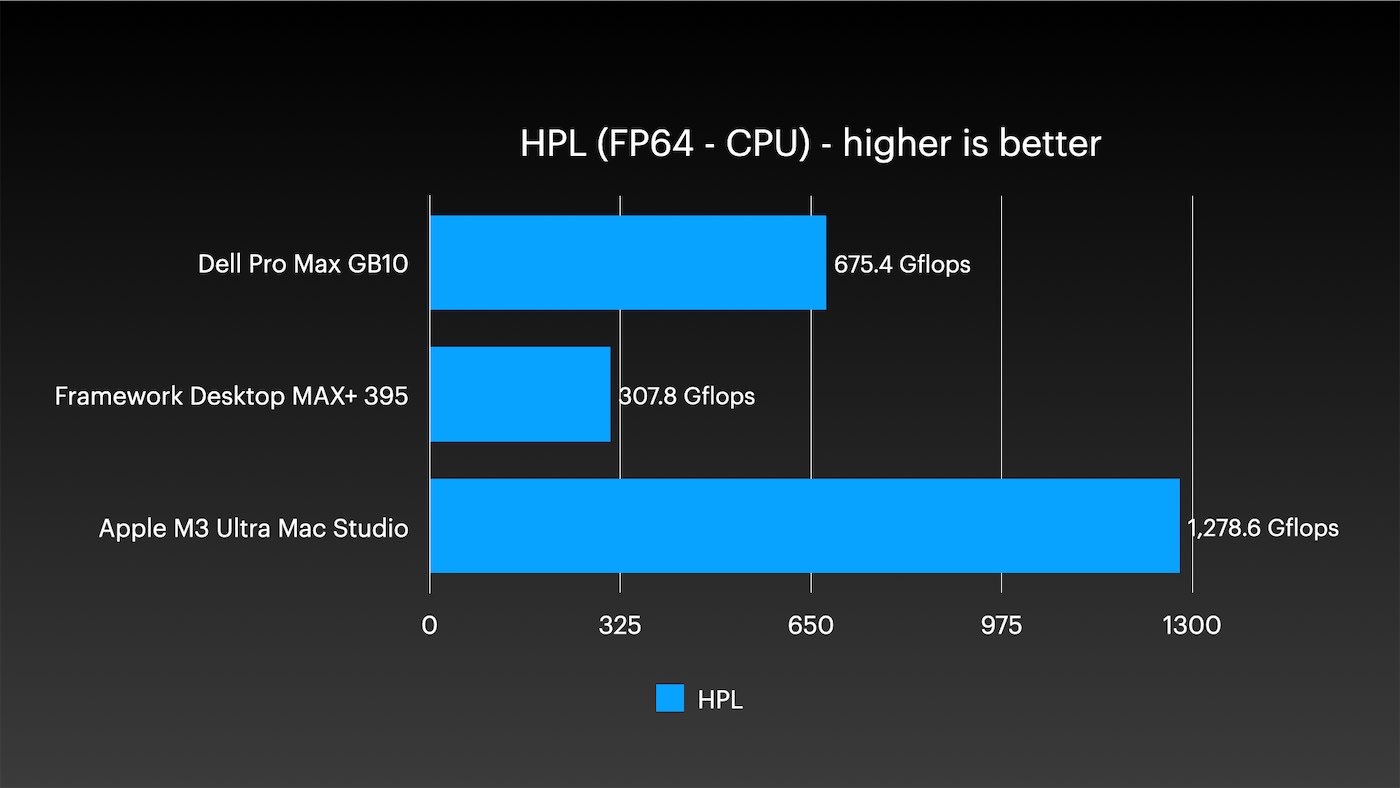
切换到双精度FP64测试,我的经典TOP500 HPL基准测试中,M3 Ultra是首款突破1 Tflop FP64性能的小型台式机。其性能几乎是英伟达GB10的两倍,而AMD的AI Max芯片则被远远甩在后面。
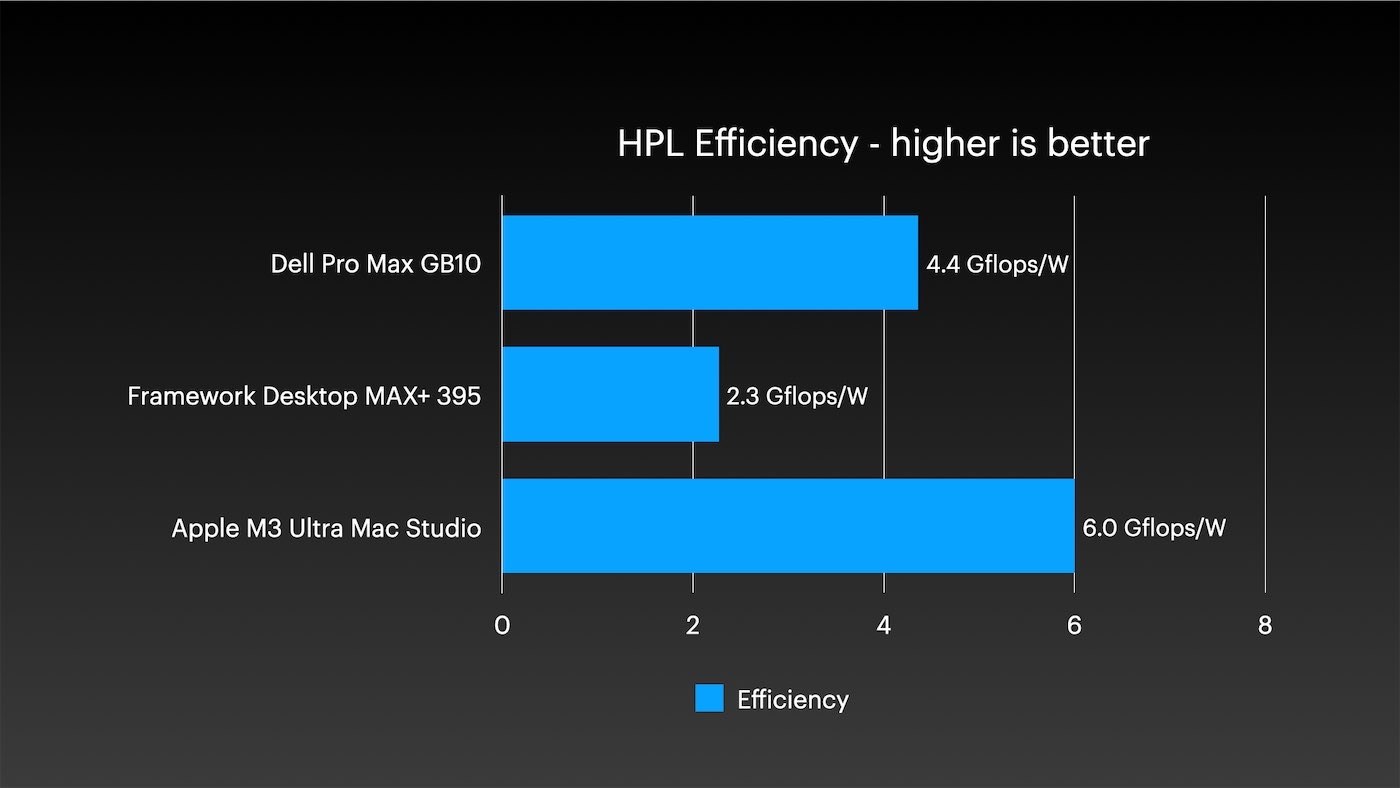
CPU 的效率也非常出色,不过自 A 系列芯片以来,苹果的所有芯片一直如此。与此相关的是,这里的闲置功耗不到 10 瓦。
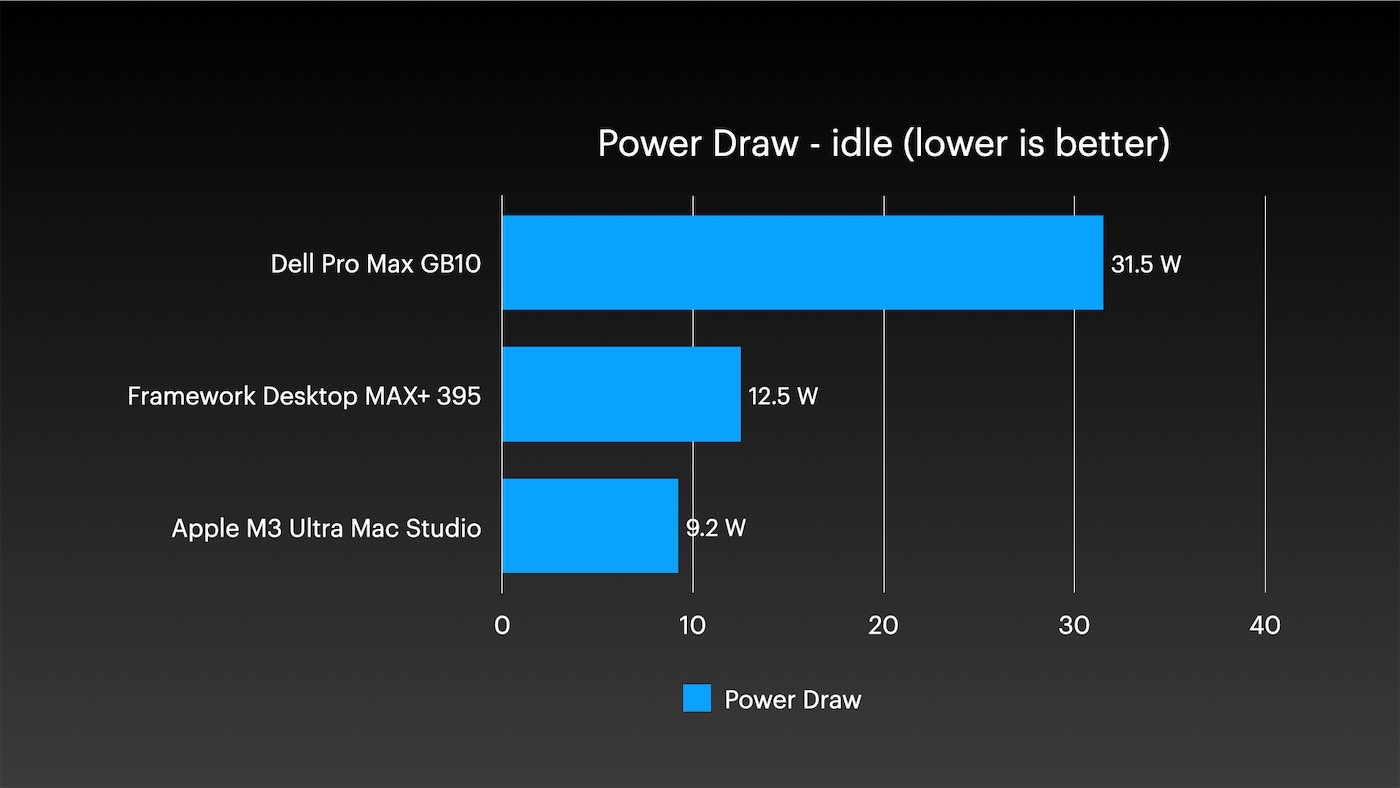
我是说,我见过单板计算机待机功耗超过10瓦,更不用说能被称为个人超级计算机的设备了。
在AI推理方面,M3 Ultra表现突出,无论是小型还是大型模型:
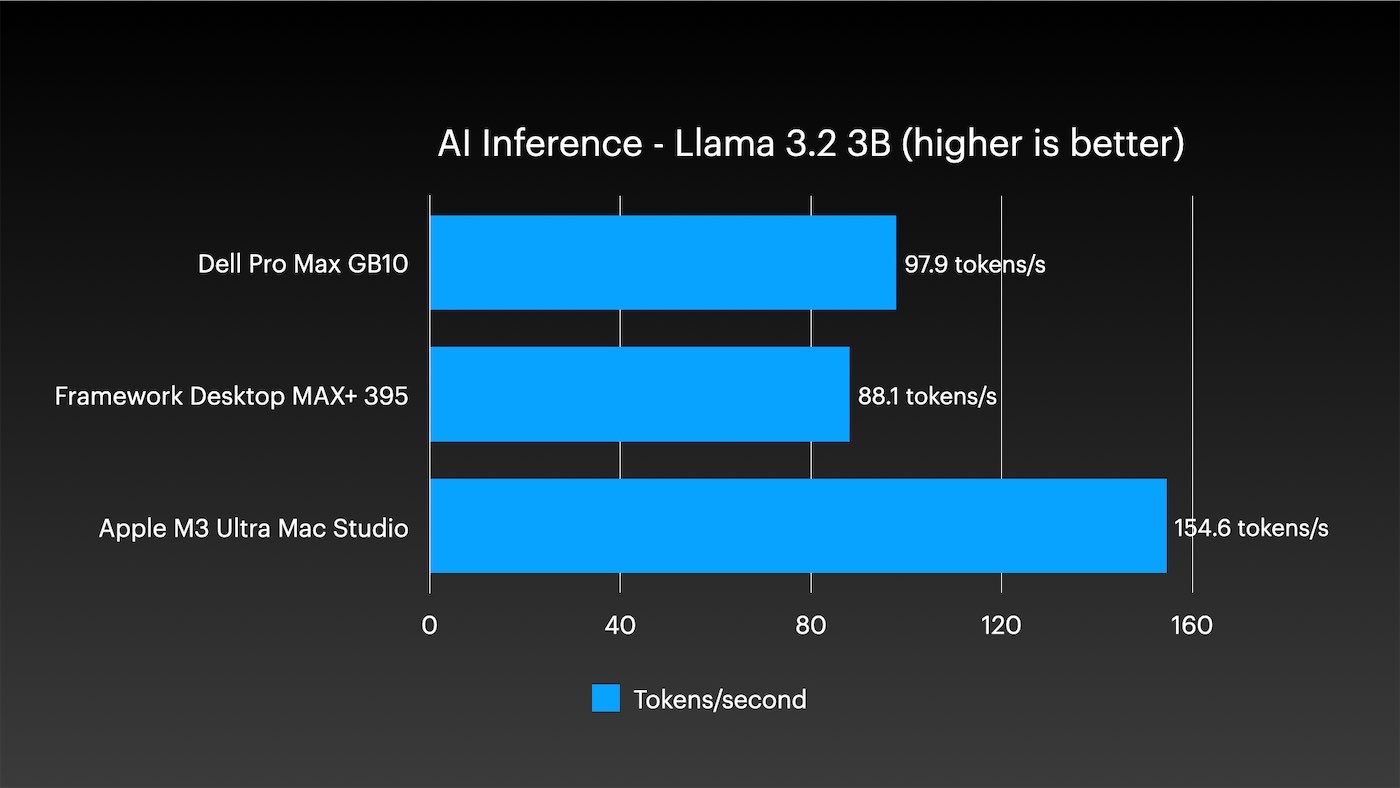
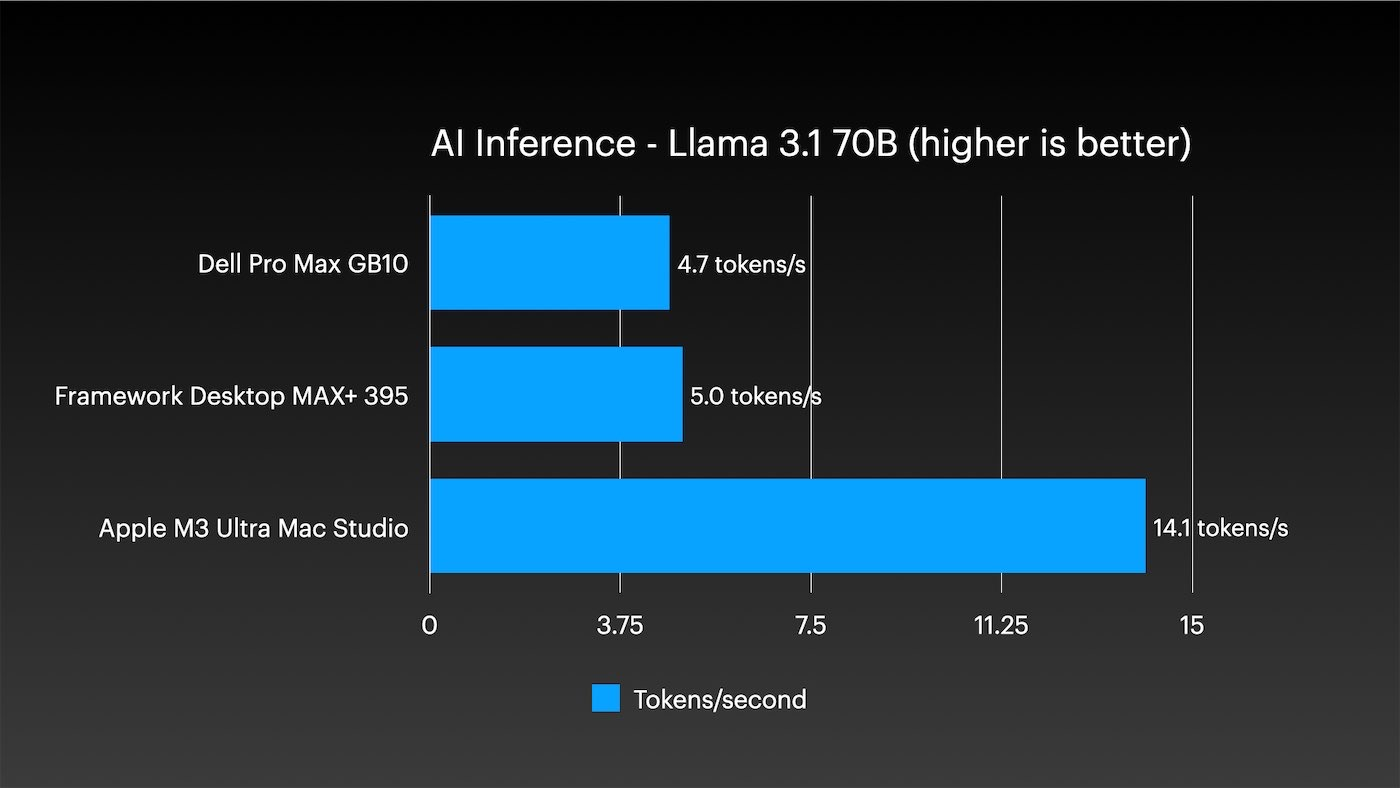
当然,真正庞大的模型(如DeepSeek R1或Kimi K2 Thinking)甚至无法在其他两个系统的单个节点上运行。
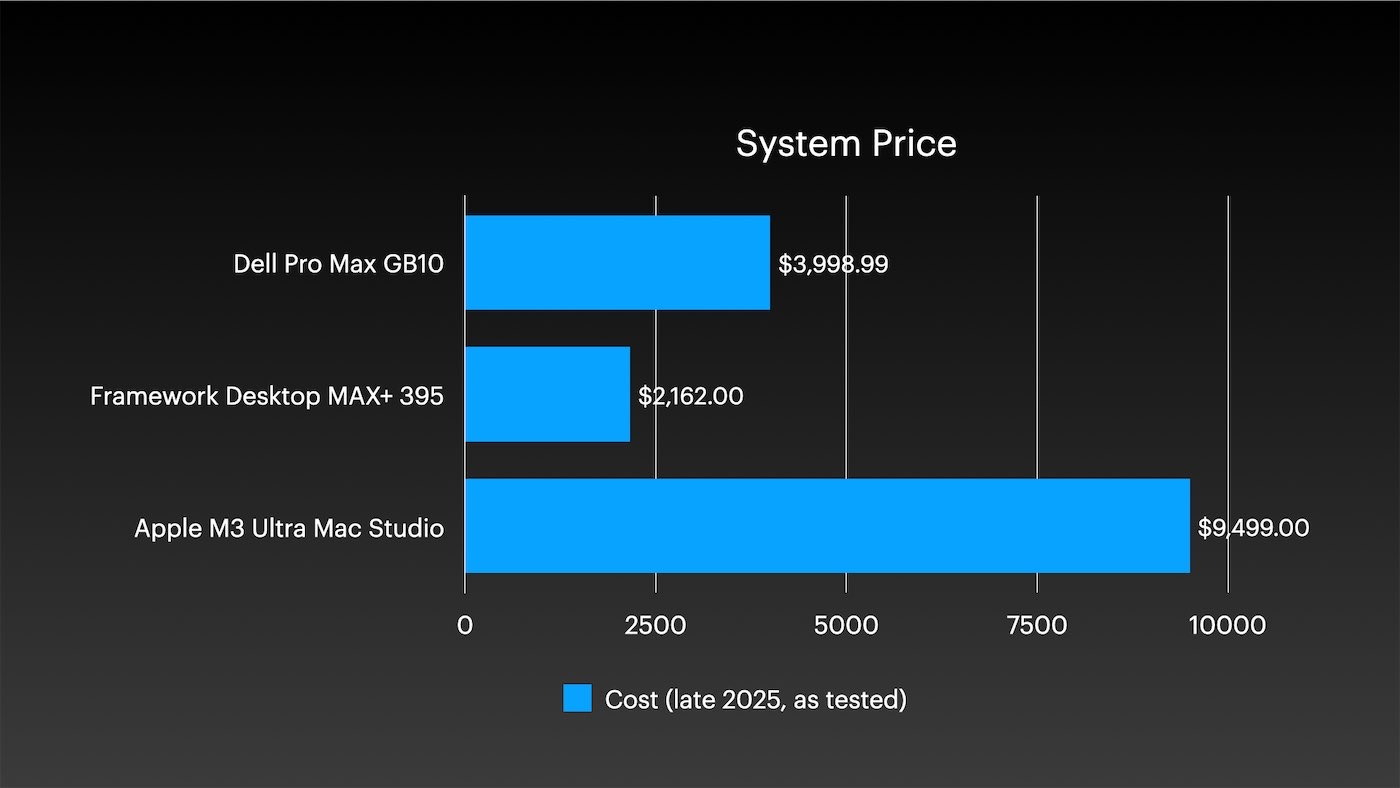
但这是一套价值1万美元的系统。付出更多时,自然期待更多。
不过想想看:一台M3 Ultra版Mac Studio的性能就超过我整个Framework台式机集群,而功耗仅为其一半。我还将其与两台Dell Pro Max GB10系统组成的小型双节点集群进行了对比,结果单台M3 Ultra在性能和能效上依然领先,且内存翻倍。
迷你机堆,极致Mac
但拥有四台Mac电脑,如何实现集群和远程管理?
对我来说最大的障碍是macOS系统本身。我在Mac上实现了所有能自动化的操作。我维护着最受欢迎的Mac管理Ansible脚本库,可以权威地说:管理Linux集群反而更简单。
每个集群都有难点,但在没有MDM等额外工具的情况下管理Mac集群会面临诸多小挑战。比如:你知道无法通过SSH运行系统升级(比如升级到26.2版)吗?必须通过图形界面点击按钮才能完成。
我没有远程给每台Mac连接KVM切换器,而是使用macOS内置的屏幕共享功能连接到每台Mac,通过图形界面完成特定操作。
HPL与Llama.cpp测试
完成所有设置后,我通过2.5千兆以太网测试了HPL,并通过以太网和雷电5接口测试了llama.cpp。
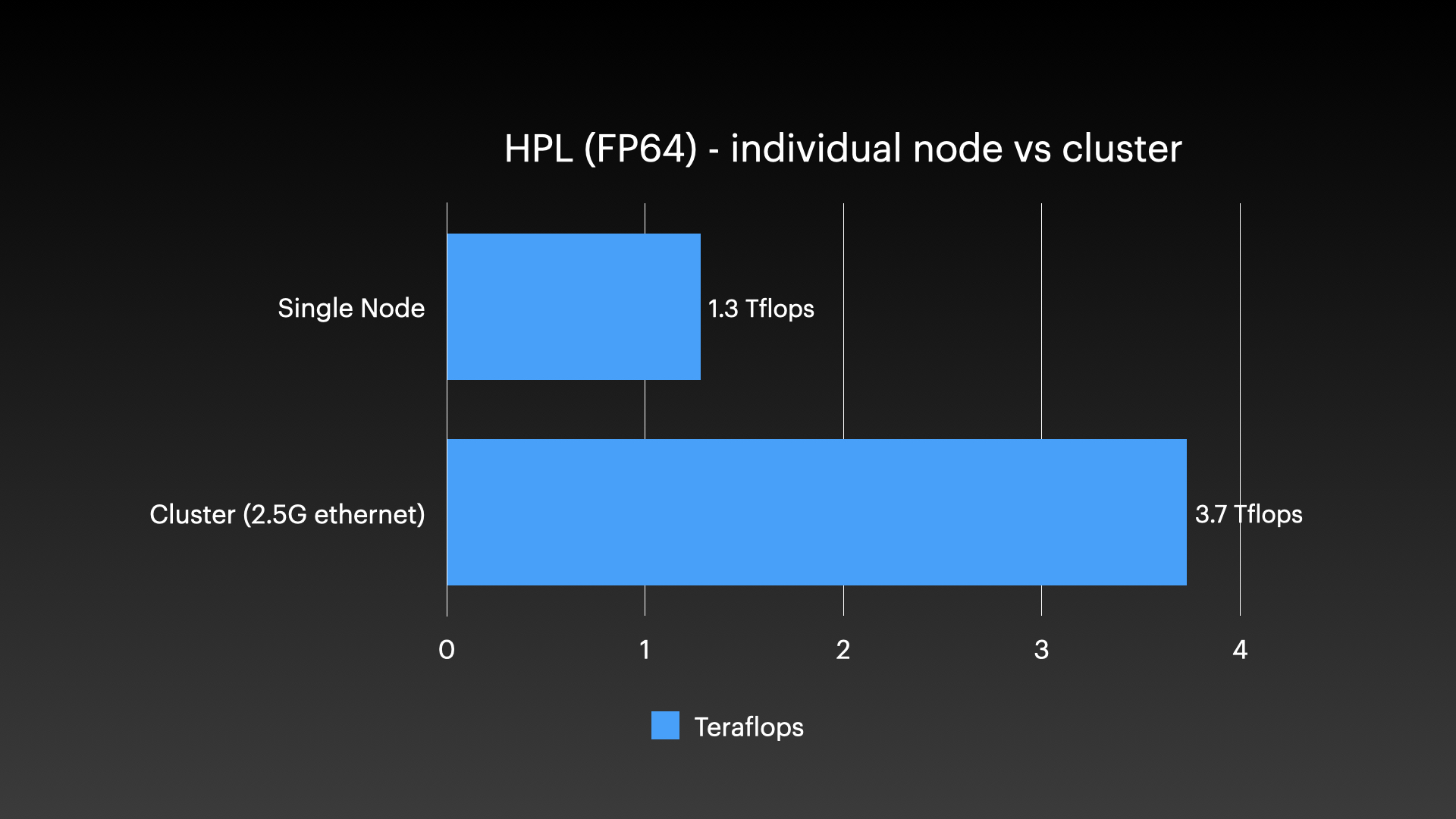
对于HPL基准测试,单个M3 Ultra芯片实现了1.3万亿次浮点运算。当四个芯片协同工作时,总性能达到3.7万亿次,加速比略低于3倍。但需要注意,顶部两台工作站的内存容量只有底部两台的一半,因此3倍左右的加速比基本符合预期。
我尝试通过雷电接口运行HPL测试(未启用RDMA,仅使用TCP协议),但配置成集群的两台Mac运行约一分钟后都会崩溃并重启。我研究了使用Apple的MLX封装器来运行mpirun,但没能在本文发布前完成配置。
接下来我测试了通过2.5千兆以太网与雷电5接口运行llama.cpp人工智能模型的性能对比:
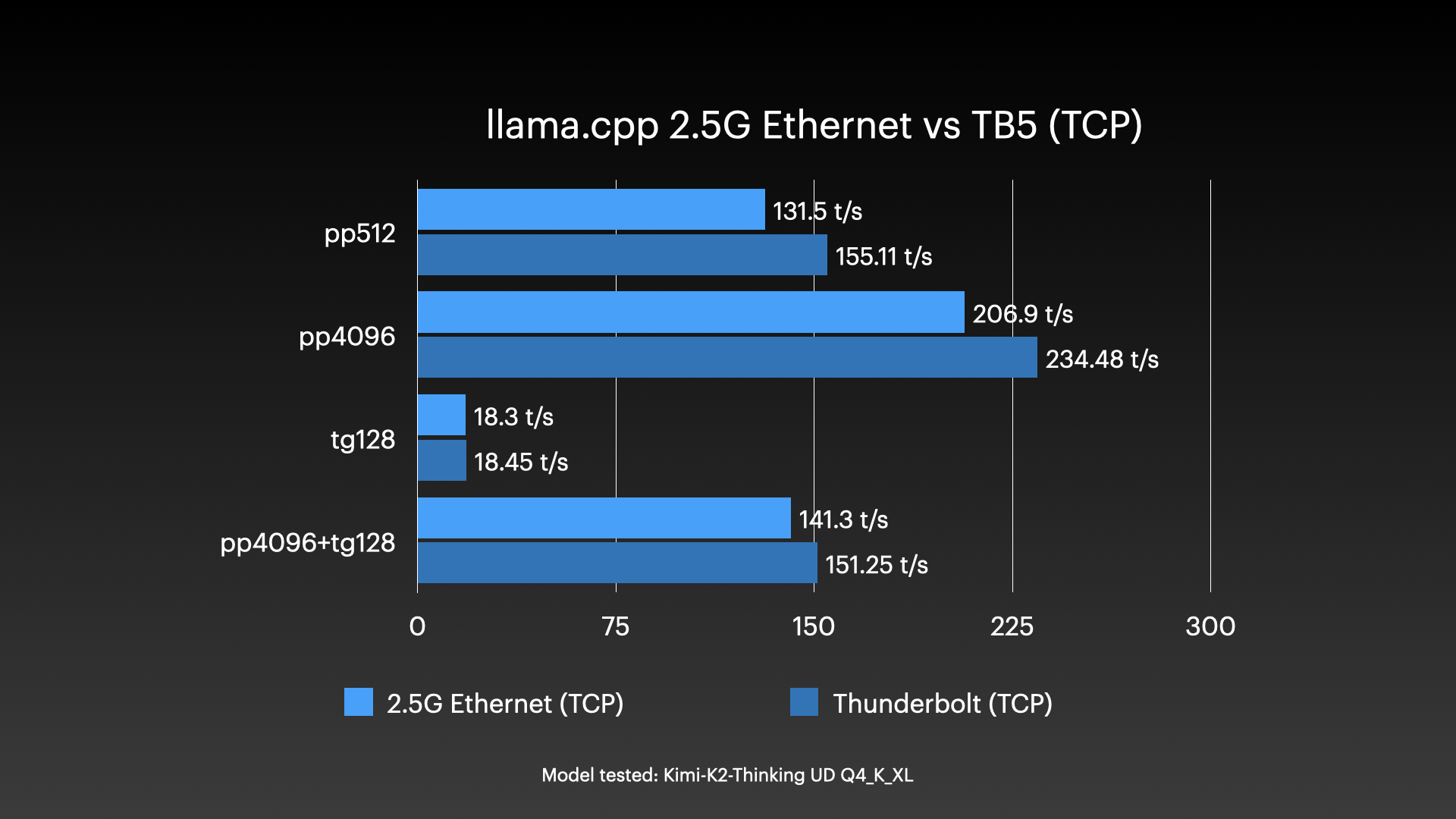
雷雳在延迟方面绝对胜出,即使您没有使用RDMA技术。
我的所有llama.cpp集群测试结果都列在这里------为了简洁起见,我进行了许多未包含在这篇博客文章中的测试。
启用RDMA
Exo 1.0今天正式发布(至少据我所知),其主打功能就是为配备雷雳5接口的Mac电脑提供集群RDMA支持。
启用RDMA
Exo 1.0版本于今日发布(至少据我所知),其主打功能是为配备Thunderbolt 5的Mac设备集群提供RDMA支持。
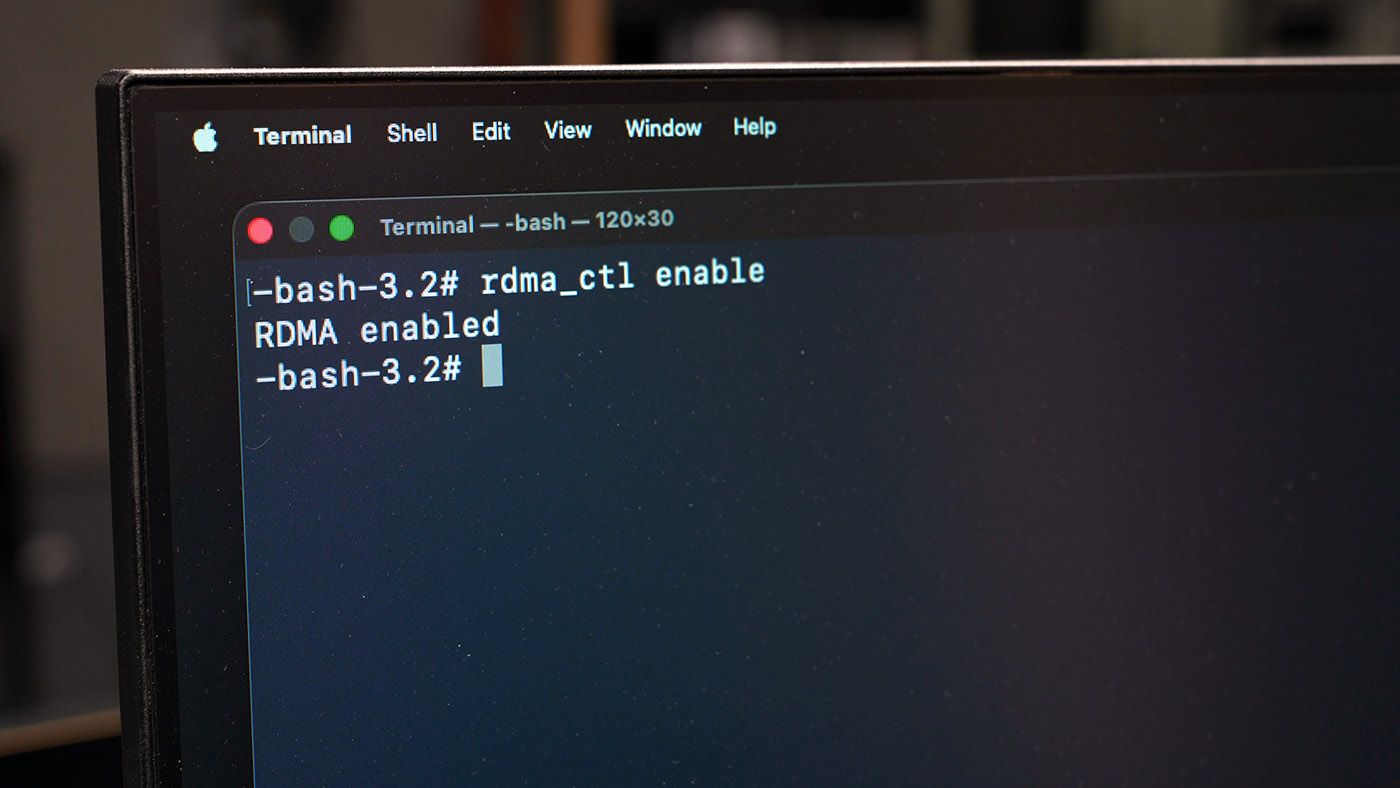
要启用RDMA功能,您需要进入恢复模式并执行以下命令:
- 关闭Mac Studio
- 长按电源键10秒(将出现启动菜单)
- 选择"选项",进入界面后从"实用工具"菜单打开终端
- 输入
rdma_ctl enable并按回车 - 重启Mac Studio
完成设置后,我运行了多个大型模型,包括超过600GB的Kimi K2 Thinking模型------这个体积已经超出了单台Mac的运行能力。
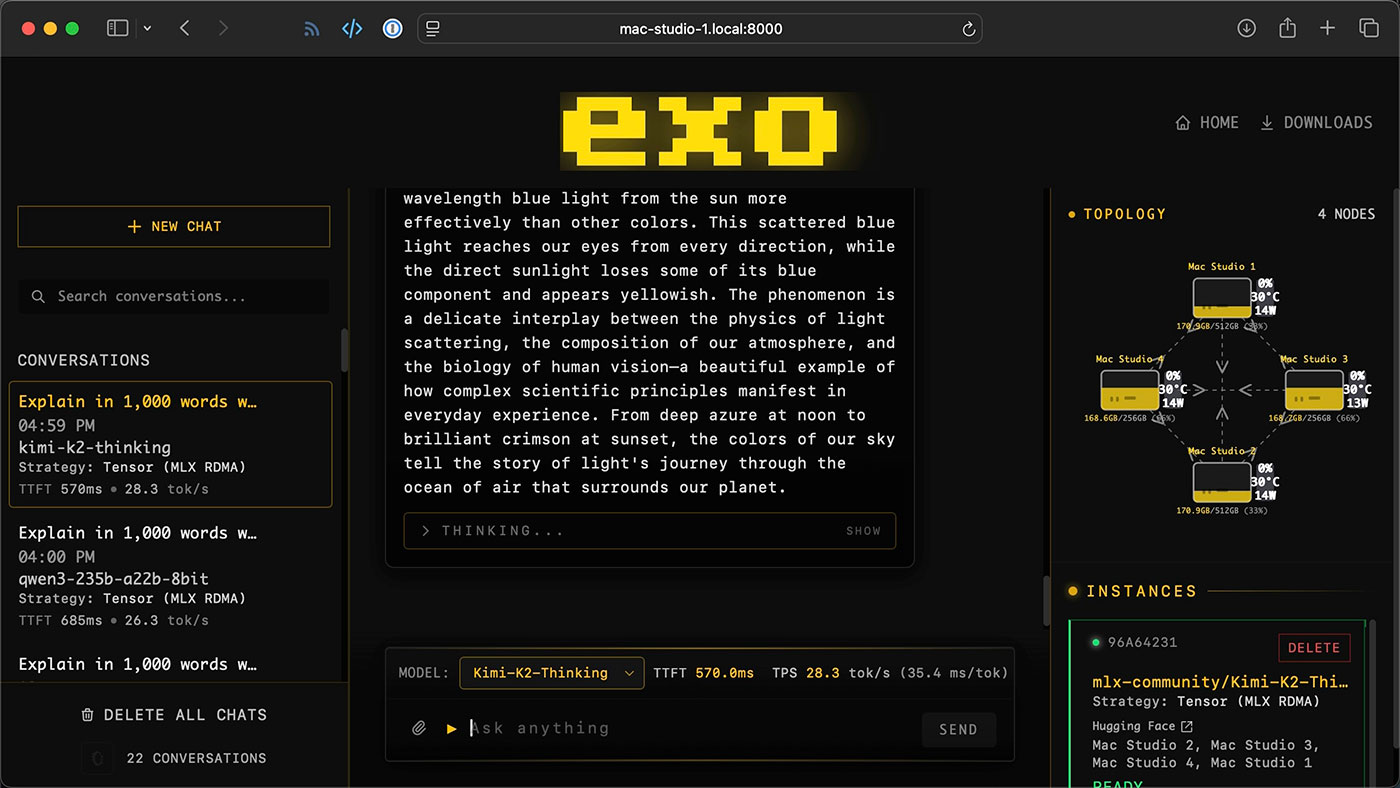
我可以在多台Mac上使用llama.cpp和Exo运行此类模型,但目前为止只有后者支持RDMA(远程直接内存访问)。llama.cpp目前采用RPC方法将模型各层分布到不同节点,虽然具有扩展性但效率低下,随着节点增加性能会下降。
这份Qwen3 235B的基准测试结果清楚地展现了这一点:
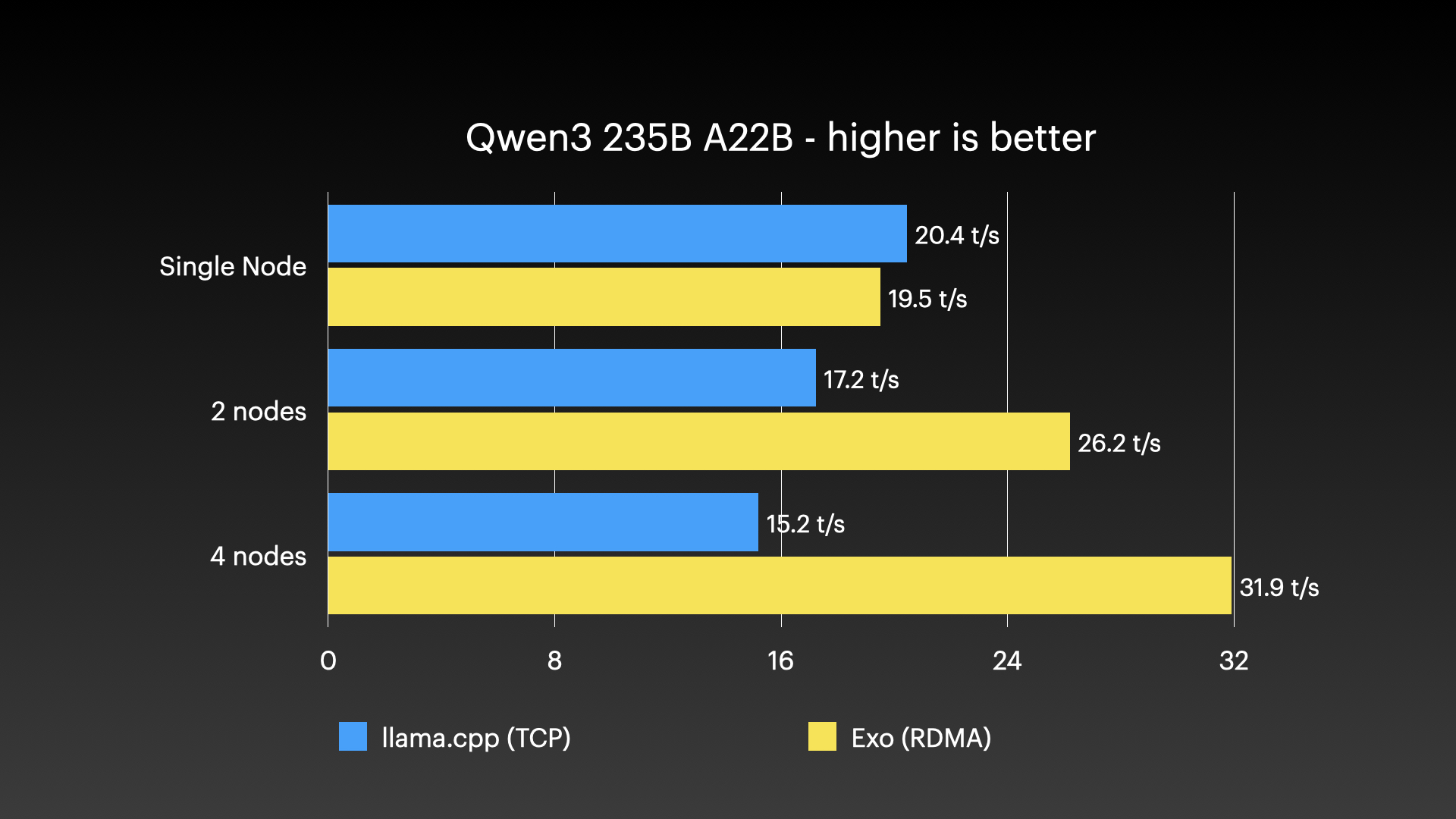
随着节点增加,Exo的处理速度会加快,在完整集群上达到每秒32个令牌。这种速度对氛围编程绰绰有余------如果你好这口的话,但我不感兴趣。
于是我转而测试拥有6710亿参数的DeepSeek V3.1模型:
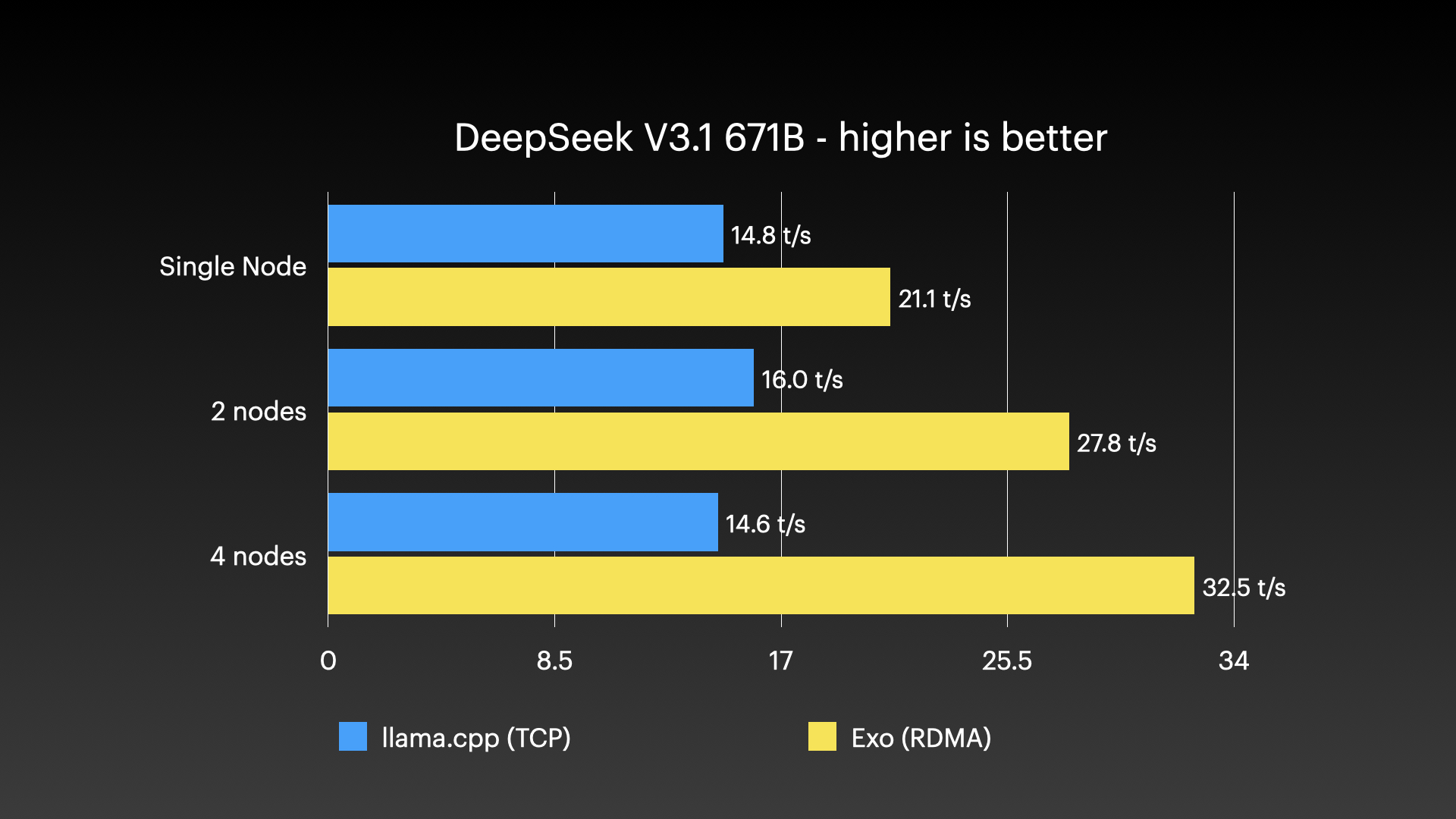
看到llama.cpp获得了一些速度提升,我有点惊讶。也许在两个节点上运行时的网络开销并没有那么糟糕?我不太确定。
让我们转向我个人在任何设备上运行过的最大模型------Kimi K2 Thinking:
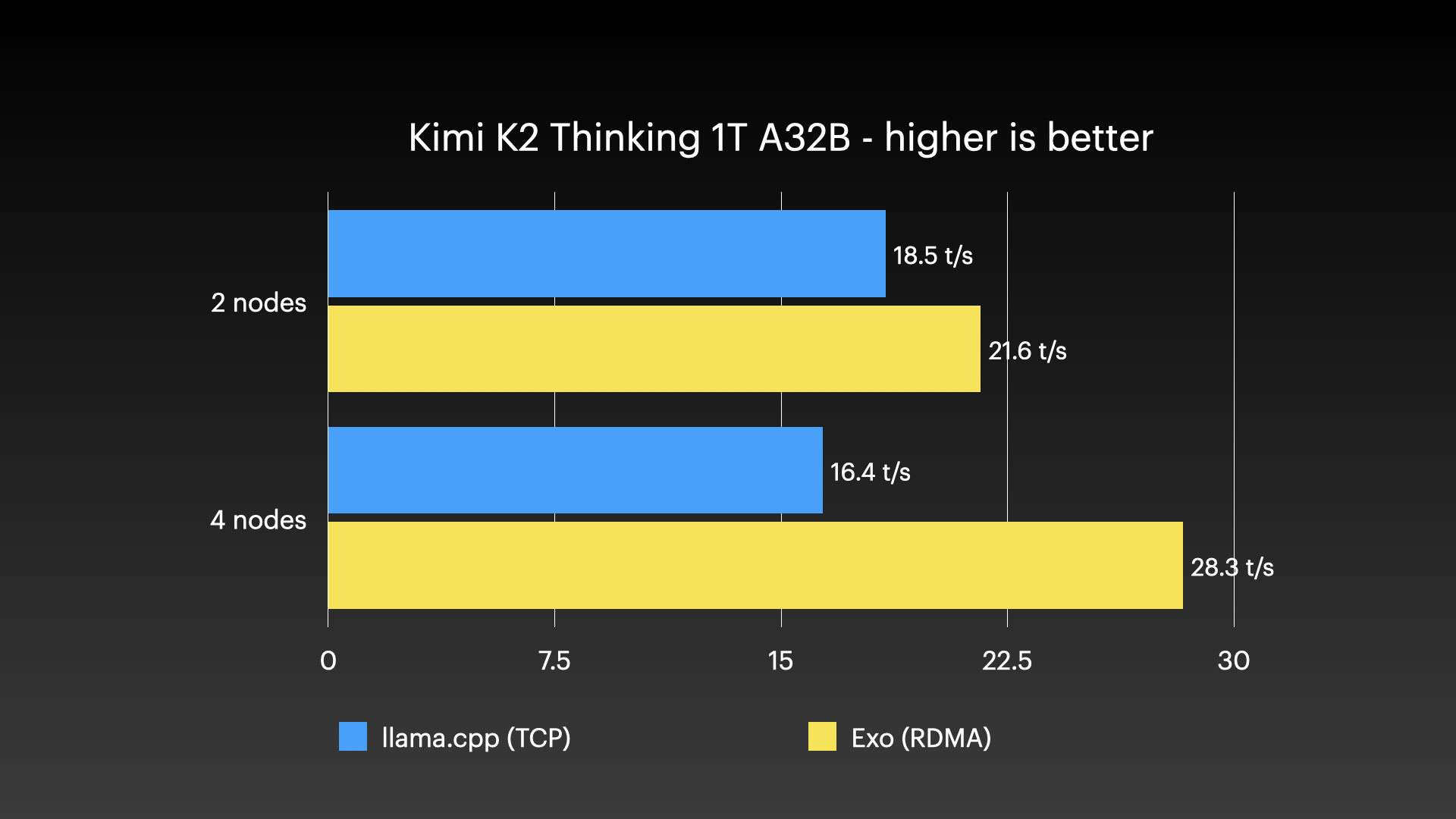
这是一个具有1万亿参数的模型,不过在任何特定时刻只有320亿参数处于"活跃"状态------这就是A32B中"A"的含义。
但我们仍能获得每秒约30个token的处理速度。
在使用这些大型模型的过程中,我确实看到了人工智能的某些用途,特别是当它处于我的本地控制之下时。但要让我完全信任它的输出结果还为时过早------我对待它就像对待维基百科一样。或许可以作为思考的起点,但永远不要让AI取代你批判性思考的能力!
不过这篇文章讨论的重点不是AI的价值,而是关于Mac Studio集群、RDMA和Exo技术。
它们的表现很出色...当它们正常运行的时候。
稳定性问题
首先声明:我在测试时使用的是预发布软件。许多bug在测试过程中得到了解决。
但很明显,基于雷电接口的RDMA技术还很新。当它正常工作时表现卓越。当出现问题时...这么说吧,我很庆幸自己配置了Ansible,可以快速关闭并重启整个集群。
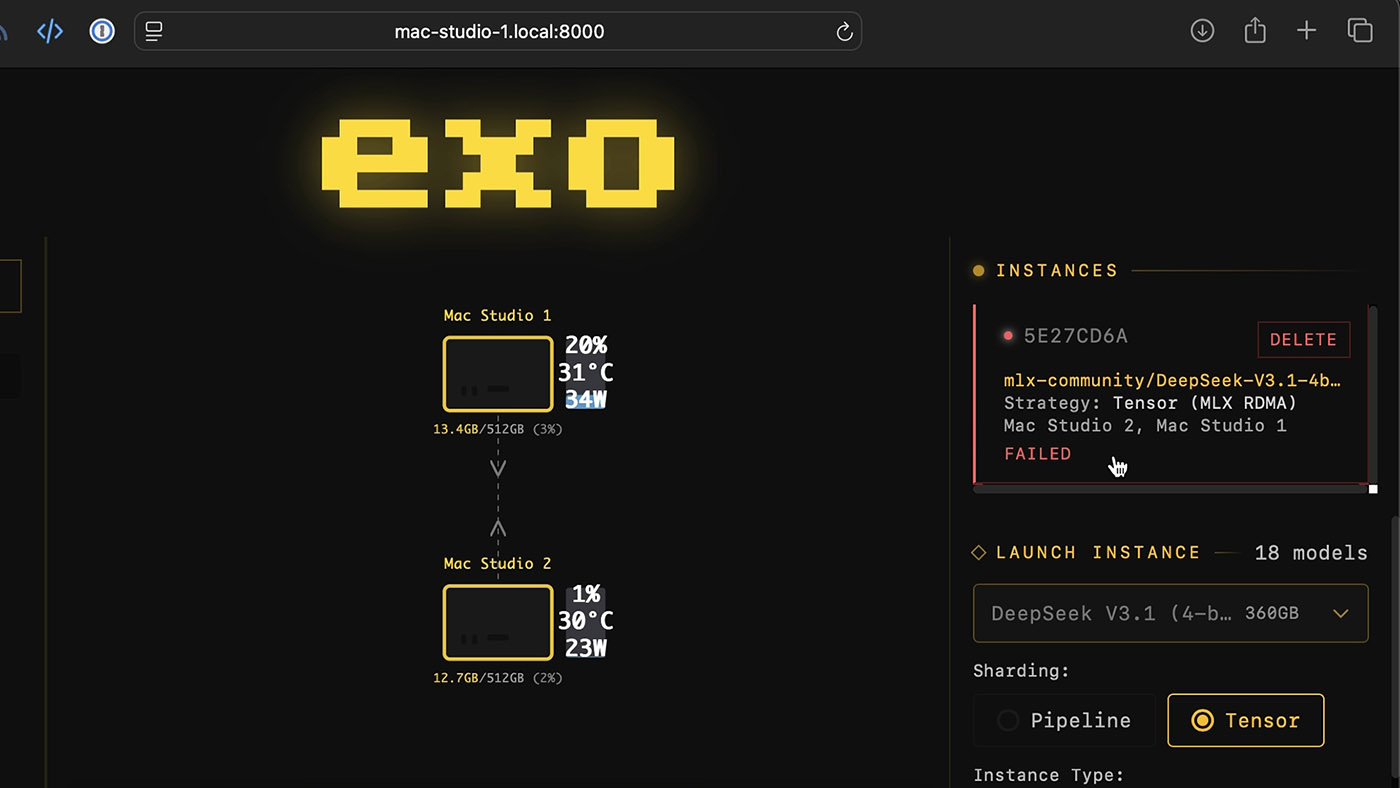
我也提到过在雷电接口上运行HPL时出现的崩溃问题。即便最终能解决,截至2025年末,我也只见过最多4台Mac通过RDMA组网的集群。不过苹果声称所有五个雷电5接口都支持RDMA,或许能连接更多Mac?
除此之外,我对Exo团队仍存有根本性的信任问题,因为开发者曾失联过一段时间。虽然他们恪守开源初心,在Apache 2.0协议下发布了Exo 1.0,但我希望他们不必躲起来秘密开发------这大概是与苹果密切合作的副作用。当然这是他们的权利,但作为一个可能过分公开开发的程序员,我反感任何开源项目周围笼罩的保密氛围。
我很好奇他们接下来的动向。团队暗示过在Mac Studio集群前部署DGX Spark来加速提示词处理...说不定还会重新支持树莓派?谁知道呢。
待解疑问/探索方向
但仍有诸多疑问萦绕:
- M5 Ultra在哪里?如果苹果发布这款芯片,机器学习性能将大幅提升
- 苹果会复活Mac Pro吗?这样就能获得全部PCIe带宽实现更快的集群,不再受制于雷电接口
- Mac能支持SMB Direct吗?让网络文件共享如同直连本地,这对视频剪辑等延迟敏感的高带宽应用将意义重大
最后,其他软件呢?Llama.cpp等应用若获得RDMA支持也将迎来速度飞跃
结语
与多数AI硬件不同,我其实不反感苹果对此的造势。当AI泡沫破裂时,Mac Studio仍是强大静音的工作站(我桌上就摆着M4 Max!)。但苹果乐园并非处处彩虹:管理Mac集群本就令人头疼,雷电5接口更限制了性能发挥。QSFP本是更好的选择,不过对"只想买台电脑"的用户就太超前了。
或许可以这样补偿:用QSFP替换背面的网口和一两个雷电接口?这样我们就能用网络交换机,一次性集群超过四台设备了...