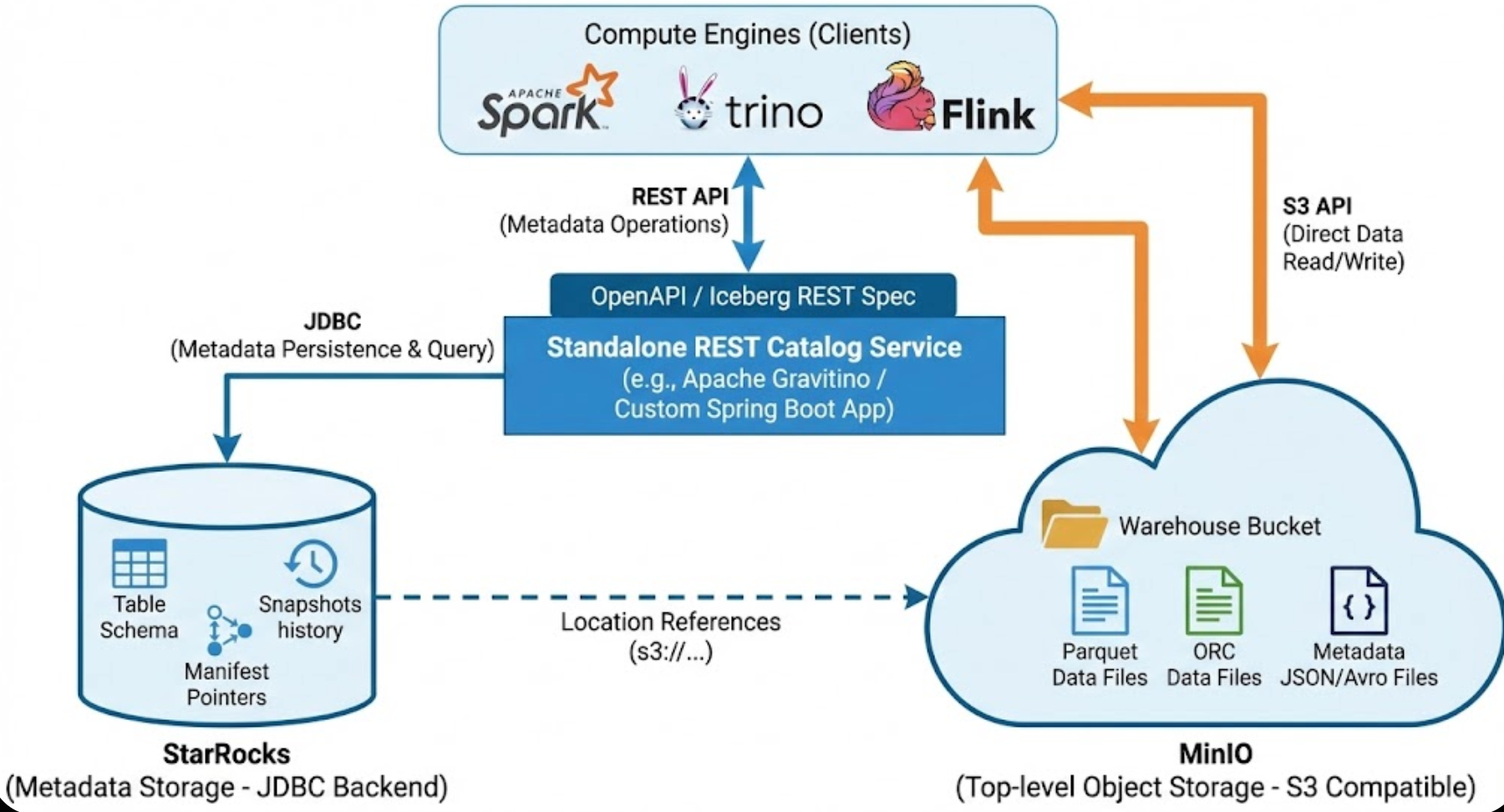
Apache Iceberg 是一个开源的表格式,用于大规模数据湖,提供 ACID 事务、模式演化、时间旅行等功能。REST Catalog 是 Iceberg 的一个关键组件,它通过 RESTful API 暴露目录操作(如表创建、更新、查询),允许不同引擎(如 Spark、Trino)统一访问元数据。 在本介绍中,我们重点讨论将 REST Catalog 作为独立服务部署,使用 StarRocks 管理 Iceberg 元数据,以及 MinIO 作为顶层对象存储的架构。这种 setup 适用于构建高性能、分布式的数据湖house,支持多引擎协作和高效元数据检索。
1. 架构概述
- REST Catalog 作为独立服务 :REST Catalog 不存储数据本身,而是作为一个接口层,连接后端元数据存储(如数据库)和底层对象存储(如 MinIO)。它可以部署为独立的 HTTP 服务,支持 OpenAPI 规范,便于客户端集成。
- StarRocks 管理 Iceberg 元数据 :StarRocks 是一个高性能 OLAP 数据库,支持作为 Iceberg 的 JDBC Catalog 后端存储元数据(如表模式、快照、分区)。这利用 StarRocks 的并行处理和缓存机制加速元数据检索。 StarRocks 还支持 Iceberg 的时间旅行、分支和标签管理。
- MinIO 作为顶层存储:MinIO 是一个 S3 兼容的对象存储系统,用于存储 Iceberg 表的实际数据文件(Parquet、ORC 等)。它提供高性能、可扩展的存储,支持多租户和版本控制,与 Iceberg 的数据湖集成无缝。
这种组合的优势包括:跨引擎互操作性(通过 REST)、高效元数据管理(StarRocks 的 OLAP 能力)和成本有效的存储(MinIO 的开源性)。
2. 如何搭建 REST Catalog 作为独立服务
REST Catalog 可以基于Apache Gravitino或自定义实现部署为独立服务。 以下是使用 Docker 和 Gravitino 的典型搭建步骤(假设您有基本的 Docker 和 Java 环境):
- 准备环境 :
- 安装 Docker 和 Docker Compose。
- 下载 Gravitino(Iceberg REST server 支持版),从 Apache 官网或 GitHub 获取最新版本(v1.0.0+)。
- 配置 catalog-config-provider 以支持 JDBC 后端(指向 StarRocks)。
- 部署 MinIO 作为对象存储 :
-
使用 Docker 运行 MinIO:
docker run -d -p 9000:9000 -p 9001:9001 --name minio \ -e "MINIO_ROOT_USER=admin" -e "MINIO_ROOT_PASSWORD=admin123" \ minio/minio server /data --console-address ":9001" -
创建桶(bucket)用于 Iceberg 数据,例如 iceberg-data。
-
配置 S3 访问:MinIO 的 endpoint 为 http://localhost:9000,access key 和 secret key 如上。
-
- 设置 StarRocks 作为元数据管理 :
-
部署 StarRocks(使用 Docker 或官方安装包)。例如 Docker 方式:
docker run -d -p 9030:9030 -p 8040:8040 --name starrocks starrocks/allin1-ubuntu:latest -
在 StarRocks 中创建数据库和表用于 Iceberg 元数据(Iceberg JDBC Catalog 需要一个兼容 MySQL 的数据库)。StarRocks 兼容 MySQL 协议,可作为 JDBC 后端。
-
配置 Iceberg JDBC Catalog:在 Gravitino 配置中设置 catalog-backend=jdbc,并指定 StarRocks 的 JDBC URL(如 jdbc:mysql://localhost:9030/iceberg_db?user=root&password=...)。
-
StarRocks 支持 Iceberg 元数据表查询(如 snapshots、manifests),启用时间旅行等功能。
-
- 部署 REST Catalog 服务 :
-
使用 Gravitino 启动 REST server:
-
编辑 conf/gravitino.conf 配置后端:
gravitino.server.port=8090 catalog.iceberg.type=iceberg catalog.iceberg.uri=http://localhost:8090 # 自引用或外部 catalog.iceberg.catalog-backend=jdbc catalog.iceberg.jdbc.uri=jdbc:mysql://starrocks-host:9030/iceberg_db catalog.iceberg.warehouse=s3://iceberg-data/ # 指向 MinIO bucket catalog.iceberg.s3.endpoint=http://minio-host:9000 catalog.iceberg.s3.access-key=admin catalog.iceberg.s3.secret-key=admin123 -
运行:
./bin/gravitino.sh start
-
-
或者,使用 Datastrato 或自定义 Java 实现:从 GitHub clone Iceberg 项目,构建 REST module,并用 Spring Boot 或类似框架部署为服务。
-
测试:使用 curl 发送 REST 请求,例如 curl -X GET http://localhost:8090/v1/namespaces 检查命名空间。
-
- 集成与测试 :
- 在 Spark 或其他引擎中配置 catalog 类型为 rest,URI 指向您的 REST 服务(如 spark.sql.catalog.my_catalog.uri=http://localhost:8090)。
- 创建 Iceberg 表:数据文件存储在 MinIO,元数据在 StarRocks。
- 在 StarRocks 中创建 external catalog 指向 Iceberg REST,以查询数据:CREATE EXTERNAL CATALOG iceberg_catalog PROPERTIES ("type"="iceberg", "iceberg.catalog.type"="rest", "uri"="http://localhost:8090");。
3. REST Catalog访问 Iceberg 表示例
3.1 通用 REST Catalog
在 Flink SQL 客户端中执行以下语句:
-- 创建 REST Catalog
CREATE CATALOG rest_catalog WITH (
'type' = 'iceberg',
'catalog-impl' = 'org.apache.iceberg.rest.RESTCatalog',
'uri' = 'http://localhost:8090', -- 您的 REST 服务 URI
'warehouse' = 's3://iceberg-data/', -- MinIO bucket
's3.endpoint' = 'http://minio-host:9000',
's3.access-key-id' = 'admin',
's3.secret-access-key' = 'admin123',
's3.path-style-access' = 'true'
);
-- 切换到该 Catalog
USE CATALOG rest_catalog;
-- 创建一个 Iceberg 表(假设命名空间为 default)
CREATE TABLE IF NOT EXISTS default.sample_table (
id BIGINT,
name STRING,
age INT
) WITH (
'format-version' = '2' -- Iceberg V2 格式,支持删除等
);
-- 插入数据
INSERT INTO default.sample_table VALUES (1, 'Alice', 30), (2, 'Bob', 25);
-- 查询数据
SELECT * FROM default.sample_table;
-- 时间旅行查询(Iceberg 特性,查询特定快照)
SELECT * FROM default.sample_table VERSION AS OF 1234567890; -- 替换为实际快照 ID3.2 Gravitino 作为 REST Catalog
sql
-- 创建 Gravitino Catalog(它内部使用 REST)
CREATE CATALOG gravitino_catalog WITH (
'type' = 'gravitino',
'uri' = 'http://localhost:8090', -- Gravitino 服务 URI
'catalog' = 'iceberg_catalog' -- Gravitino 中的 Iceberg Catalog 名称
);
-- 切换 Catalog
USE CATALOG gravitino_catalog;
-- 创建 Iceberg 表(元数据存储在 StarRocks/PostgreSQL)
CREATE TABLE sample_table (
id BIGINT,
data STRING
) WITH (
'write.format.default' = 'parquet' -- 数据格式
);
-- 插入和查询同上
INSERT INTO sample_table VALUES (1, 'Test Data');
SELECT * FROM sample_table;4. 注意事项
- 安全性:配置 JWT 或 OAuth 以保护 REST API,尤其在生产环境中。
- 性能优化:利用 StarRocks 的缓存加速元数据加载,MinIO 的多节点部署提升存储吞吐。
- 扩展:对于生产级,可用 Kubernetes 部署所有组件,支持多租户。