TL;DR
- 场景:用 scikit-learn 快速落地 KNN 分类,理解 fit/predict/score、kneighbors 与选 K。
- 结论:单次划分下"最优 K"不稳定;用交叉验证 + 标准化 Pipeline 才能工程化定 K。
- 产出:两套案例代码骨架 + 邻居检索方法 + 选 K 的可复现实践清单与错误速查。

scikit-learn 算法库实现
scikit-learn(简称 sklearn)自 2007 年由 David Cournapeau 发起以来,已经成为 Python 生态系统中最重要的机器学习库之一。作为 NumPy 和 SciPy 生态系统的重要组成部分,sklearn 为数据科学家和机器学习工程师提供了强大而高效的工具集。
在功能架构上,scikit-learn 主要支持四大核心机器学习算法领域:
- 分类算法:包括逻辑回归(LogisticRegression)、支持向量机(SVC)、随机森林(RandomForestClassifier)等,适用于客户流失预测、垃圾邮件识别等场景
- 回归算法:如线性回归(LinearRegression)、岭回归(Ridge)等,可用于房价预测、销量预估等任务
- 降维技术:主成分分析(PCA)、t-SNE 等算法,帮助处理高维数据可视化
- 聚类算法:K均值(KMeans)、DBSCAN 等,适用于用户分群、异常检测等应用
此外,scikit-learn 还提供三大关键功能模块:
- 特征提取:包括文本特征向量化(CountVectorizer)、TF-IDF 转换等
- 数据预处理:标准化(StandardScaler)、归一化(MinMaxScaler)、缺失值处理等
- 模型评估:交叉验证(cross_val_score)、多种评估指标(accuracy_score, f1_score 等)
在实际工程应用中,直接使用 Python 原生代码从头实现机器学习算法存在诸多挑战:
- 开发周期长,需要处理大量底层数学运算和优化问题
- 难以保证代码的健壮性和计算效率
- 缺乏统一的接口设计,不利于团队协作和模型维护
相比之下,使用 scikit-learn 的标准工作流程更加高效可靠:
- 数据采集后,首先进行探索性分析(EDA)
- 根据数据特征(如线性/非线性、数据规模、特征维度等)选择合适的算法
- 通过 sklearn 统一的 API 接口(fit/predict/transform)调用算法
- 使用网格搜索(GridSearchCV)或随机搜索(RandomizedSearchCV)优化超参数
- 通过交叉验证评估模型性能,最终实现算法效率与效果的平衡
例如,在电商推荐系统开发中,可以:
- 使用 sklearn 的 KNN 算法实现协同过滤
- 通过 Pipeline 将特征标准化、降维和分类器组合
- 利用 classification_report 输出精确率、召回率等指标
正是这种模块化设计、统一接口和丰富的算法实现,使 scikit-learn 成为机器学习实践中的首选工具包,大大降低了算法应用的门槛,提高了开发效率。
设计原则
一致性 所有对象共享一个简单一致的界面(接口)
- 估算器:fit()方法,基于数据估算参数的任意对象,使用的参数是一个数据集(对应 X,有监督算法还需要一个Y),引导估算过程的任意其他参数成为超参数,必须被设置为实例变量。
- 转换器:transform()方法,使用估算器转换数据集,转换过程依赖于学习参数,可以使用便捷方式:fit_transform(),相当于先 fit()再 transform(),有时优化过速度更快。
- 预测器:predict()方法,使用估算器预测新数据,返回包含预测结果的数据,还有 score()方法:用于度量给定测试集的预测效果的好坏(连续 y 使用 R 方,分类 y 使用准确率 accuracy)
监控
检查所有参数,所有估算器的超参数可以通过公共实例变量访问,所有估算器的学习参数都可以通过有下划线后缀的公共实例变量访问。
防止类扩散
对象型固定,数据集被表示为 Numpy 数组或 Scipy 稀疏矩阵,超惨是普通的 Python字符或数字。
合成
现有的构建尽可能重用,可以轻松创建一个流水线 Pipline。
合成默认值
大多参数提供合理默认值,可以轻松搭建一个基本的工作系统。
案例1:红酒
python
from sklearn.neighbors import KNeighborsClassifier
# 0 代表 "黑皮诺",1 代表 "赤霞珠"
clf = KNeighborsClassifier(n_neighbors = 3)
clf = clf.fit(wine_data.iloc[:,0:2], wine_data.iloc[:,-1])
result = clf.predict([[12.8,4.1]]) # 返回预测的标签
print(f"result: {result}")
# 对模型进行一个评估,接口score返回预测的准确率
score = clf.score([[12.8,4.1]],[0])
print(f"score: {score}")
print(clf.predict_proba([[12.8,4.1]]))执行结果如下图是: 
案例2:乳腺癌
python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
#读取数据集
data = load_breast_cancer()
#DateFrame格式显示
X = data.data
y = data.target
name = ['平均半径','平均纹理','平均周长','平均面积',
'平均光滑度','平均紧凑度','平均凹度',
'平均凹点','平均对称','平均分形维数',
'半径误差','纹理误差','周长误差','面积误差',
'平滑度误差','紧凑度误差','凹度误差',
'凹点误差','对称误差',
'分形维数误差','最差半径','最差纹理',
'最差的边界','最差的区域','最差的平滑度',
'最差的紧凑性','最差的凹陷','最差的凹点',
'最差的对称性','最差的分形维数','患病否']
data=np.concatenate((X,y.reshape(-1,1)),axis=1)
table=pd.DataFrame(data=data,columns=name)
table.head()
# 划分训练集和测试集 #30%数据作为训练集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=420)
# 建立模型&评估模型
clf = KNeighborsClassifier(n_neighbors=4)
# 建立分类器
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score执行结果如下图所示: 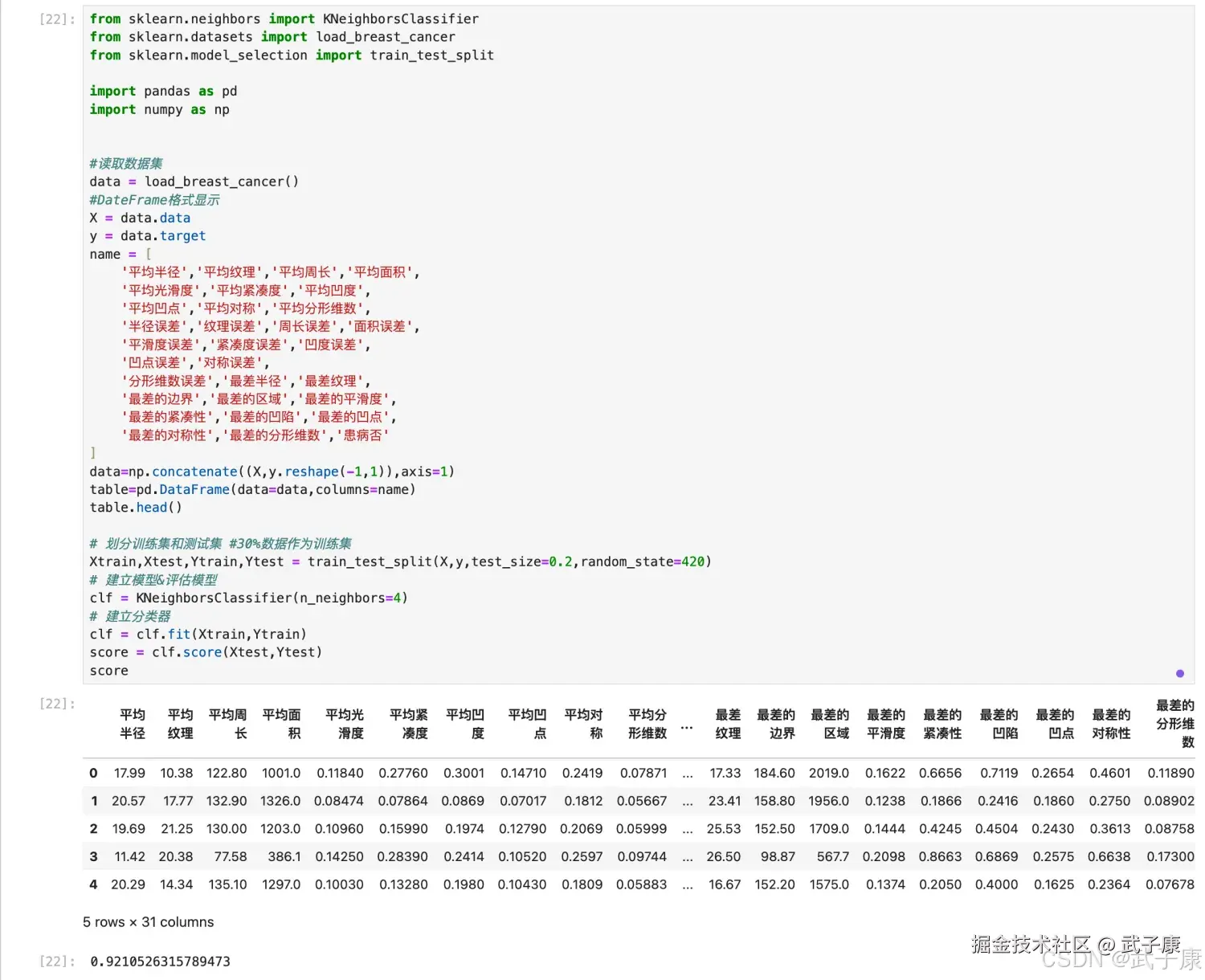 如何用上面分类器拟合结果找出离 Xtest 中第 20 行和第 30 行最近的 4 个"点"?
如何用上面分类器拟合结果找出离 Xtest 中第 20 行和第 30 行最近的 4 个"点"?
python
# 查找点的K邻居。返回每个点的邻居的与之的距离和索引值。
clf.kneighbors(Xtest[[20,30],:],return_distance=True)查询结果如下图所示: 
选择最优K值
KNN 中的一个超参数,所谓"超参数",就是需要人为输入,算法不能通过直接计算得出这个参数,KNN 中的 K 代表的是距离需要分类的测试点 X 最近的 K 个样本,如果不输入这个值,那么算法中重要部分"选出 K 个最近邻"就无法实现。 从 KNN 的原理中可见,是否能够确认合适的 K 值对算法有极大的影响。
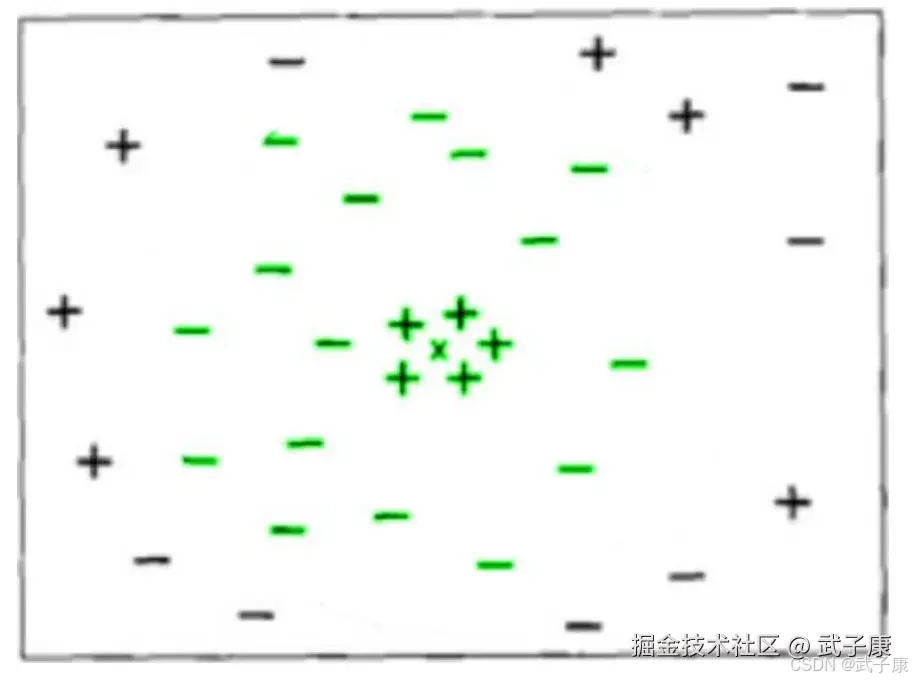 如果选择的 K值较小,就相当于较小的领域中的训练实例进行预测,这时候只有与输入实例较近的训练实例才会对预测结果起作用,但缺点是预测结果会对近邻的实例点非常敏感,如果近邻的实例点恰好是噪声,预测就会出错。 相反的,如果选择的 K 值较大,就相当于较大的领域中的训练实例进行预测,这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。因此,超参数 K 的选定是 KNN 的头号问题。
如果选择的 K值较小,就相当于较小的领域中的训练实例进行预测,这时候只有与输入实例较近的训练实例才会对预测结果起作用,但缺点是预测结果会对近邻的实例点非常敏感,如果近邻的实例点恰好是噪声,预测就会出错。 相反的,如果选择的 K 值较大,就相当于较大的领域中的训练实例进行预测,这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。因此,超参数 K 的选定是 KNN 的头号问题。
学习曲线
我们怎么样选择一个最佳的 K 值?在这里要使用机器学习中的神器:参数学习曲线,参数学习曲线是一条以不同的参数取值为横坐标,不同参数取值下的模型结果为纵坐标的曲线,我们往往选择模型表现最佳点的参数取值作为这个参数的取值。
python
# 更换不同的n_neighbors参数的取值,观察结果的变化
clf = KNeighborsClassifier(n_neighbors=7)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score查看结果如下:  绘制学习曲线:
绘制学习曲线:
python
score = []
krange = range(1,20)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i)
clf = clf.fit(Xtrain,Ytrain)
score.append(clf.score(Xtest,Ytest))
plt.plot(krange,score)
plt.show()执行结果如下: 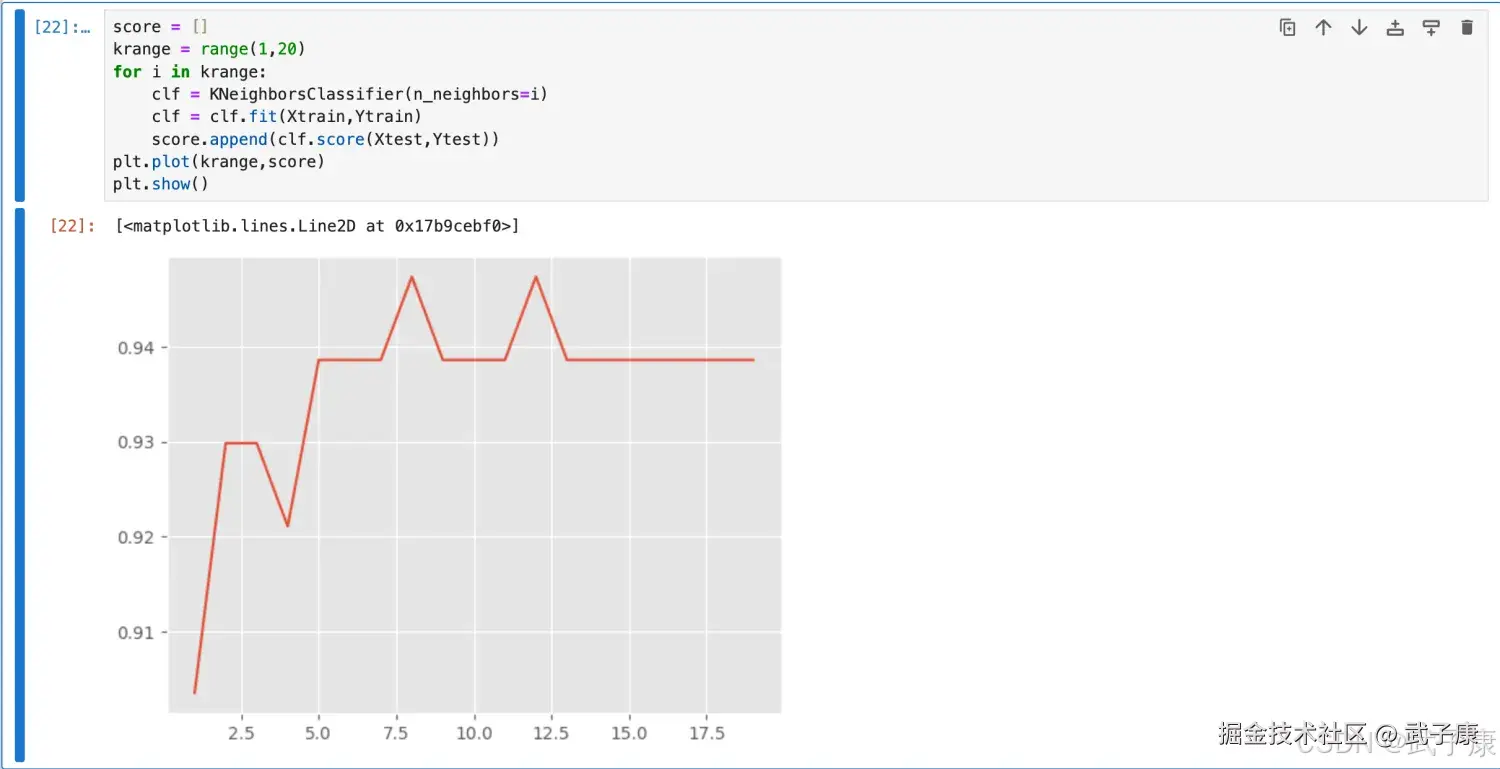 图像如下所示:
图像如下所示:
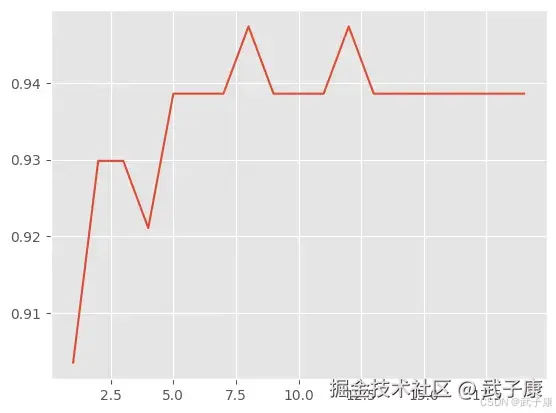 那么上图中 K 为多少的时候分值最高呢?
那么上图中 K 为多少的时候分值最高呢?
shell
score.index(max(score))+1执行结果如下所示:  但是这个时候也会有问题,如果随机划分的数据集变化的话,得分最高的K 值也会发生变化。
但是这个时候也会有问题,如果随机划分的数据集变化的话,得分最高的K 值也会发生变化。
python
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=421)
score = []
krange = range(1,20)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i)
clf = clf.fit(Xtrain,Ytrain)
score.append(clf.score(Xtest,Ytest))
plt.plot(krange,score)
plt.show()执行结果如下所示:  输出的图片的是: !K近邻学习训练](i-blog.csdnimg.cn/direct/2a00...) 此时的K 为多少分值最高?
输出的图片的是: !K近邻学习训练](i-blog.csdnimg.cn/direct/2a00...) 此时的K 为多少分值最高?
python
score.index(max(score))+1执行结果如下所示:  此时就无法确定最佳的 K 值了,就无法进行下面的建模工作,怎么办?
此时就无法确定最佳的 K 值了,就无法进行下面的建模工作,怎么办?
错误速查
| 症状 | 根因定位 | 修复 | 学习曲线 |
|---|---|---|---|
代码直接报 IndentationError |
for 循环体未缩进 |
补齐循环体缩进;确保 clf = ... fit append 在循环内 |
运行到 for i in krange: 处即失败 |
NameError: name 'wine_data' is not defined |
红酒案例未给出数据读取/变量定义 | 在正文前补充数据加载与 DataFrame 构造;或改用 sklearn 内置数据集/CSV 读取示例 |
指向 wine_data.iloc... |
NameError: name 'plt' is not defined |
绘图未导入 matplotlib |
增加 import matplotlib.pyplot as plt |
指向 plt.plot(...) |
score 看起来"很高/很低",但不可信 |
单样本或极小样本调用 score,统计意义不足 |
用独立测试集(Xtest/Ytest)评估;至少上百样本或交叉验证均值 |
clf.score([[12.8,4.1]],[0]) 这类写法 |
"最佳 K"随 random_state 改变 |
单次切分导致方差大;数据量/类别分布使结果敏感 | 用 StratifiedKFold + GridSearchCV;报告均值±方差/置信区间,不报单点峰值 |
对比 random_state=420 与 421 的峰值 K 不同 |
| KNN 效果异常、K 很大/很小才好 | 特征未标准化导致距离被量纲主导 | 用 Pipeline(StandardScaler(), KNN);必要时尝试不同距离度量(metric) |
检查特征量纲(如面积/周长量级远大于分形维数) |
kneighbors 结果看不懂或索引对不上原表 |
Xtest 是 ndarray,索引返回的是训练集索引(相对 Xtrain) |
明确 kneighbors(Xtest[[20,30]], ...) 返回的是 Xtrain 的邻居索引;用这些索引回查 Xtrain/Ytrain |
输出为 (distances, indices),indices 指向训练集样本 |
| 文字注释与代码不一致 | 注释写"30%数据作为训练集",但 test_size=0.2 实际是 20% 测试集 |
以代码为准;统一注释口径(训练/测试比例)避免读者误解 | train_test_split(... test_size=0.2 ...) |
KNeighborsClassifier 速度慢/内存高 |
大样本下 KNN 预测为近邻检索,复杂度高 | 降维(PCA)、近似近邻(外部库)、减少特征/样本;或换模型(线性/树模型) |
预测耗时随样本数线性/近线性上升 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-207 RabbitMQ Direct 交换器路由:RoutingKey 精确匹配、队列多绑定与日志分流实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解