自然语言处理(NLP)指的是利用自然语言(如英语)与智能系统交流的人工智能方法。
当你需要一个智能系统(如机器人)按照你的指令行动,或者想听到基于对话的临床专家系统做出决策等时,自然语言处理是必不可少的。
NLP领域涉及让计算机用人类使用的自然语言来执行有用的任务。NLP系统的输入和输出可以是−
- 演讲
- 书面文本
NLP的组成部分
在本节中,我们将了解NLP的不同组成部分。NLP有两个组成部分。组件如下描述 −
自然语言理解(NLU)
它包含以下任务 −
-
将自然语言中的输入映射为有用的表示。
-
分析语言的不同方面。
自然语言生成(NLG)
它是通过某种内部表征以自然语言形式产生有意义的短语和句子的过程。它涉及 −
-
文本规划------这包括从知识库中检索相关内容。
-
句子规划------这包括选择所需词语、形成有意义的短语、设定句子的语气。
-
文本实现 - 这是将句子计划映射到句子结构中。
NLU中的困难
自然语言的形式和结构非常丰富;然而,它是模棱两可的。可能存在不同程度的歧义------
词汇歧义
它是在一个非常原始的水平,如字的水平。例如,将单词board视为名词或动词?
语法级歧义
一个句子可以用不同的方法分析。例如,他举起了戴着红帽子的甲虫。−他是用帽子举起甲虫还是举起了一只戴着红色帽子的甲虫?
指称歧义
指使用代词的事物。例如,丽玛去高丽,她说,我累了。-到底是谁累了?
NLP术语
现在让我们看看NLP术语中的几个重要术语。
-
音系学------它是对声音系统组织的研究。
-
形态学 − 这是一门研究从原始有意义单位构造词汇的学科。
-
模态 − 它是语言中的一个原始意义单位。
-
句法 − 它指的是排列单词以构成句子。它还涉及确定词语在句子和短语中的结构性作用。
-
语义学------它关注词语的含义以及如何将词语组合成有意义的短语和句子。
-
语用学------它涉及在不同情境下使用和理解句子,以及句子的解释如何受到影响。
-
话语------它处理的是紧接前一句如何影响下一句的解释。
-
世界知识------它包括关于世界的一般知识。
NLP中的步骤
本节展示了NLP中不同的步骤。
词汇分析
它涉及识别和分析词汇的结构。语言词汇表指的是语言中词汇和短语的集合。词汇分析是将整个文本段落划分为段落、句子和单词。
句法分析(句法分析)
它涉及对句子中词语语法的分析,并以显示词语之间关系的方式排列词语。句子如"The school goes to boy"被英语句法分析器拒绝。
语义分析
它从文本中提取确切的含义或词典意义。文本会被检查是否有意义。它通过映射任务域中的语法结构和对象来实现。语义分析器忽略了诸如"hot ice-cream"这样的句子。
话语整合
任何句子的意义取决于其前一句的含义。此外,它也引发了紧接句子的含义。
务用分析
在此过程中,人们会重新解释所说的话,以理解其实际含义。它涉及推导出那些需要现实世界知识的语言方面。
NLTK 软件包
在本章中,我们将学习如何开始使用自然语言工具包。
前提条件
如果我们想构建自然语言处理应用,那么上下文的变化会让它变得最困难。上下文因素会影响机器理解特定句子的方式。因此,我们需要通过机器学习方法开发自然语言应用,使机器也能像人类理解语境一样理解上下文。
为了构建此类应用,我们将使用名为NLTK(自然语言工具包)的Python包。
导入NLTK
我们需要先安装NLTK才能使用。它可以通过以下命令安装 −
pip install nltk要构建 NLTK 的 conda 包,请使用以下命令 −
conda install -c anaconda nltk安装完 NLTK 包后,我们需要通过 Python 命令提示符导入它。我们可以通过在 Python 命令提示符上写以下命令来导入它 −
>>> import nltk下载NLTKs数据
导入NLTK后,我们需要下载所需的数据。这可以通过Python命令提示符上的以下命令完成 −
>>> nltk.download()安装其他必要软件包
为了使用 NLTK 构建自然语言处理应用,我们需要安装必要的软件包。这些包如下 −
基因模拟
它是一个强大的语义建模库,适用于许多应用。我们可以通过执行以下命令安装它 −
pip install gensim图案
它主要用来让 gensim 包正常工作。我们可以通过执行以下命令安装它
pip install pattern词汇化、词干化和词汇化的概念
在本节中,我们将了解什么是词汇化、词干和词汇化。
分词化
它可以被定义为将给定文本,即字符序列,拆分为称为标记的更小单元的过程。标记可以是单词、数字或标点符号。这也被称为词分段。以下是分词化的一个简单示例 −
输入 − 芒果、香蕉、菠萝和苹果都是水果。
输出−

打破给定文本的过程可以通过确定词界来完成。单词的结尾和新单词的开头称为单词边界。书写系统和词语的排版结构会影响边界。
在 Python NLTK 模块中,我们有不同的分词化包,可以根据需求将文本划分为多个分区。部分封装如下 −
sent_tokenize套餐
顾名思义,这个软件包会将输入文本划分为句子。我们可以借助以下 Python 代码导入该包 −
rom nltk.tokenize import sent_tokenizeword_tokenize包
该软件包将输入文本划分为单词。我们可以借助以下 Python 代码导入该包 −
python
from nltk.tokenize import word_tokenizeWordPunctTokenizer 包
该软件包将输入文本与标点符号分成单词。我们可以借助以下 Python 代码导入该包 −
python
from nltk.tokenize import WordPuncttokenizer词干
在处理单词时,我们会遇到许多因语法原因产生的变体。这里的变体概念意味着我们必须处理同一个词的不同形式,比如民主、民主 和民主化。机器必须明白这些不同的词有相同的基础形式。这样,在分析文本时提取词语的基础形态会很有用。
我们可以通过遏制来实现这一点。因此,我们可以说词干提取是一种通过截断词尾来提取词语基础形式的启发式过程。
在 Python NLTK 模块中,我们有与词干提取相关的不同包。这些包可以用来获取单词的基础形式。这些软件包使用算法。部分封装如下 −
PorterStemmer 套件
这个 Python 软件包使用 Porters 算法提取基表。我们可以借助以下 Python 代码导入该包 −
python
from nltk.stem.porter import PorterStemmer例如,如果我们将词写 作为词干输入,则词干处理后得到词写。
LancasterStemmer 软件包
这个 Python 包将使用 Lancasters 算法提取基础表单。我们可以借助以下 Python 代码导入该包 −
python
from nltk.stem.lancaster import LancasterStemmer例如,如果我们将词写 作为词干输入,则词干处理后得到词写。
SnowballStemmer 包
这个 Python 软件包将使用 snowballs 算法提取基础表单。我们可以借助以下 Python 代码导入该包 −
python
from nltk.stem.snowball import SnowballStemmer例如,如果我们将词写 作为词干输入,则词干处理后得到词写。
这些算法的严格度各不相同。如果比较这三种干性,波特式的干性最不严格,兰开斯特最为严格。Snowball Stemmer 在速度和严谨度方面都很好用。
词汇化
我们也可以通过词形化提取词的基础形式。它基本上通过词汇和词形学分析来完成这项任务,通常只针对词尾去除屈折。这种词的基础形式称为引理。
词干化和词汇化的主要区别在于词汇和词形分析的使用。另一个区别是,词干化通常合并与派生相关的词,而词汇化通常只合并词元的不同屈折形式。例如,如果我们提供单词 saw 作为输入词,词干化可能会返回单词 s,但词汇化则会根据词符的使用是动词还是名词,尝试返回单词 see 或 see。
在 Python NLTK 模块中,我们有以下与词汇化过程相关的包,可以用来获得单词 − 的基础形式
WordNetLemmatizer 包
该 Python 包会根据词语作为名词还是动词来提取其基础形式。我们可以借助以下 Python 代码导入该包 −
python
from nltk.stem import WordNetLemmatizer分块:将数据划分为块
它是自然语言处理中重要的过程之一。分块的主要工作是识别词性和短语,比如名词短语。我们已经研究过代币化的过程,即代币的创建。分块基本上就是给这些代币做标签。换句话说,分块会显示句子的结构。
在接下来的部分,我们将了解不同类型的分块。
分块类型
分块有两种类型。类型如下 −
大块块
在这个分块过程中,物体、事物等会变得更通用,语言也变得更加抽象。同意的可能性更大。在这个过程中,我们会拉远距离。例如,如果我们把汽车的用途分成一个问题?我们可能会得到答案,传送。
分块
在这种分块的过程中,物体、事物等逐渐变得更具体,语言也更加深入。更深层的结构则通过切块分析。在这个过程中,我们会放大镜头。例如,如果我们把问题分成"具体说说一辆车?我们会获得关于这辆车的小信息。
示例
在这个例子中,我们将进行名词-短语分块,这是一种分块类别,通过使用 Python 中的 NLTK 模块 − 来找到句子中的名词短语 chunks
在 Python 中按照以下步骤实现名词短语分块 −
步骤1 − 在此步骤中,我们需要定义分块的语法。它将包括我们需要遵守的规则。
步骤2 − 在这一步中,我们需要创建一个块解析器。它会解析语法并给出输出。
步骤3 − 在最后一步,输出以树状形式生成。
我们导入所需的NLTK包如下 −
python
import nltk现在,我们需要定义句子。这里,DT表示行列词,VBP表示动词,JJ表示形容词,IN表示介词,NN表示名词。
python
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]现在,我们需要讲语法。这里,我们将以正则表达式的形式给出语法。
python
grammar = "NP:{<DT>?<JJ>*<NN>}"我们需要定义一个解析器来解析语法。
python
parser_chunking = nltk.RegexpParser(grammar)解析器解析句子的方式如下 −
python
parser_chunking.parse(sentence)接下来,我们需要获取输出。输出通过称为output_chunk的简单变量生成。
python
Output_chunk = parser_chunking.parse(sentence)执行以下代码后,我们可以将输出绘制成树形。
python
output.draw()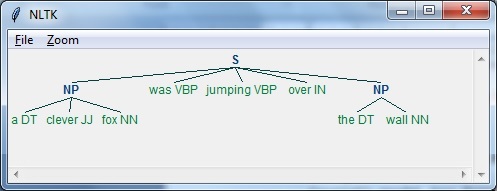
词袋(BoW)模型
词袋(Bag of Word,简称BoW)是一种自然语言处理模型,基本上用于从文本中提取特征,以便文本能够用于建模,例如机器学习算法。
现在问题是,为什么我们需要从文本中提取特征?这是因为机器学习算法无法处理原始数据,它们需要数值数据才能提取有意义的信息。将文本数据转换为数值数据称为特征提取或特征编码。
工作原理
这是一种非常简单的文本特征提取方法。假设我们有一个文本文档,想将其转换为数值数据,或者想提取特征,那么首先,这个模型会从文档中的所有单词中提取一个词汇表。然后通过使用文档术语矩阵,构建模型。因此,BoW仅将文档呈现为一袋文字。关于文档中单词顺序或结构的任何信息都被剔除。
文档术语矩阵的概念
BoW 算法通过使用文档术语矩阵构建模型。顾名思义,文档术语矩阵是文档中出现的各种字数矩阵。借助该矩阵,文本文档可以表示为多个词语的加权组合。通过设定阈值并选择更有意义的词语,我们可以构建文档中所有词语的直方图,作为特征向量。以下是一个例子,帮助理解文档术语矩阵的概念 −
示例
假设我们有以下两句话 −
-
Sentence1 − 我们使用了词袋模型。
-
Sentence2 − 词袋模型用于提取特征。
现在,通过考虑这两句话,我们得到以下13个不同的词------
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
现在,我们需要为每句子构建直方图,方法是利用每句子的字数 −
Sentence1 − 1,1,1,1,1,1,1,1,0,0,0,0
Sentence2 − 0,0,0,1,1,1,1,1,1,1,1,1,1
这样,我们就得到了被提取出来的特征向量。每个特征矢量是13维的,因为我们有13个不同的词。
统计学概念
统计的概念称为术语频率-逆文档频率(tf-idf)。文档中的每一个字都很重要。统计数据帮助我们理解每一个字的重要性。
项频率(tf)
它是衡量每个单词在文档中出现频率的指标。它可以通过将每个单词的数量除以给定文档中的总字数来得到。
逆文档频率(idf)
它是衡量该词在给定文档集中中的唯一性。为了计算idf并制定独特特征向量,我们需要降低常见词(如 the)的权重,并权重稀有词。
在NLTK中构建单词袋模型
在本节中,我们将通过使用 CountVectorizer 从这些句子创建向量来定义字符串集合。
我们引入所需的包 −
python
from sklearn.feature_extraction.text import CountVectorizer现在定义句子集合。
python
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)上述程序生成如下所示的输出。它表明上述两句中有13个不同的词------
python
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}这些是可用于机器学习的特征向量(文本转数字形式)。
解决问题
在本节中,我们将解决一些相关问题。
类别预测
在一组文档中,不仅词语本身,词的类别也很重要;某个词语属于哪类文本。例如,我们希望预测某句话是否属于电子邮件、新闻、体育、计算机等类别。在下面的例子中,我们将使用 tf-idf 来构建一个特征向量,以找到文档类别。我们将使用sklearn的20个新闻组数据集的数据。
我们需要导入所需的包 −
python
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer定义类别映射。我们使用了五个不同的类别,分别是 Religion, Autos, Sports, Electronics and Space.。
python
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}创建训练集 −
python
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)构建计数向量器并提取项计数 −
python
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)tf-idf 变换器的创建方式如下 −
python
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)现在,定义测试数据 −
python
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]上述数据将帮助我们训练一个多项式朴素贝叶斯分类器 −
python
classifier = MultinomialNB().fit(train_tfidf, training_data.target)使用计数向量器 − 对输入数据进行变换
python
input_tc = vectorizer_count.transform(input_data)现在,我们将使用tfidf变换器−
python
input_tfidf = tfidf.transform(input_tc)我们将预测输出类别 −
python
predictions = classifier.predict(input_tfidf)输出生成如下 −
python
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])类别预测器生成以下输出 −
python
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: Electronics性别识别器
在这个问题陈述中,分类器会被训练通过提供名称来确定性别(男性或女性)。我们需要用启发式方法构造特征向量并训练分类器。我们将使用scikit-learn软件包中的标记数据。以下是构建性别查找器的 Python 代码 −
让我们导入所需的包 −
python
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import names现在我们需要从输入词中提取最后的N个字母。这些字母将作为特征------
python
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':使用NLTK中可用的标记名称(男性和女性)创建训练数据 −
python
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)现在,测试数据将按以下方式生成 −
python
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']用以下代码定义用于训练和测试的样本数量
python
train_sample = int(0.8 * len(data))现在,我们需要遍历不同长度,以便比较精度------
python
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)分类器的准确性可计算为−
python
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')现在,我们可以预测输出 −
python
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))上述程序将生成以下输出−
python
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female在上述输出中,我们可以看到最大结尾字母数的准确率为2,且随着结尾字母数量增加,准确率下降。
主题建模:识别文本数据中的模式
我们知道文档通常会按主题分组。有时我们需要识别文本中与特定主题相关的模式。这种做法称为主题建模。换句话说,我们可以说主题建模是一种揭示给定文档中抽象主题或隐藏结构的技术。
我们可以在以下情景中使用主题建模技术------
文本分类
借助主题建模,分类可以得到改进,因为它将相似的词汇归为一组,而不是单独使用每个词作为特征。
推荐系统
借助主题建模,我们可以通过使用相似度度量构建推荐系统。
主题建模算法
主题建模可以通过算法实现。算法如下 −
潜在狄利克雷分配(LDA)
该算法是主题建模中最受欢迎的。它使用概率图形模型实现主题建模。我们需要导入 Python 中的 gensim 包以使用 LDA 字数。
潜在语义分析(LDA)或潜在语义索引(LSI)
该算法基于线性代数。基本上,它在文档术语矩阵上使用了SVD(奇异值分解)的概念。
非负矩阵分解(NMF)
它同样基于线性代数。
上述所有主题建模算法的参数都以主题数 为参数,文档**-词矩阵** 作为输入,输出为WTM(词主题矩阵) 和TDM(主题文档矩阵)。