检索链的种类
检索链是实现检索增强生成(RAG)的核心组件,其核心逻辑是:先从知识库中检索与用户相关的上下文,再将问题和上下文传入大模型生成答案。其主要分类如下:
| 链名称 | 核心特点 |
|---|---|
| RetrievalQA | 基础检索问答链,最通用 |
| RetrievalQAWithSourcesChain | 专门优化「来源追溯」 |
| ConversationalRetrievalChain | 融合对话记忆 |
| RetrievalQAWithChainOptions | 自定义链配置(进阶) |
以电商平台商品推荐为例(下面自己手搓的代码,盗用请标注来源)
用到的函数
python
from langchain_community.document_loaders import (
TextLoader,
PyPDFLoader,
UnstructuredMarkdownLoader,
WebBaseLoader
)
from langchain_classic.schema import Document
from langchain_community.vectorstores import FAISS
from langchain_classic.chains import RetrievalQA
from langchain_classic.prompts import PromptTemplate
from langchain_community.embeddings import DashScopeEmbeddings步骤一:我用到的商品文件
下图是我的商品pdf:
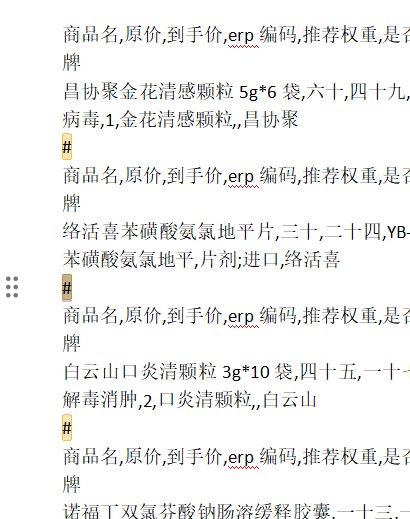
步骤二:pdf转进行分块,我们这里按照自定义字符串进行分割,即#
python
def print_document_splits(splits, num_to_display=5):
print(f"\n📋 文档分割详情(共 {len(splits)} 个片段):\n" + "="*60)
for i, doc in enumerate(splits[:num_to_display]):
print(f"\n➡️ 片段 {i+1}:")
print(f" 来源: {doc.metadata.get('source', '未知')}")
print(f" 页码: {doc.metadata.get('page', '未知')}")
print(f" 字符数: {len(doc.page_content)}")
content_preview = doc.page_content[:200] + "..." if len(doc.page_content) > 200 else doc.page_content
print(f" 内容预览: {content_preview}")
if len(splits) > num_to_display:
print(f"\n... 还有 {len(splits) - num_to_display} 个片段未显示")
embeddings = DashScopeEmbeddings(
model="text-embedding-v3",
dashscope_api_key="sk-8009265c5eddxxxxx9cb9ef3"
)
loader = PyPDFLoader("/wwwxxxx量商品推荐_20251224135554.pdf")
documents = loader.load()
# 按 # 分割,这里是关键
full_text = "\n".join([doc.page_content for doc in documents])
chunks = full_text.split("#")步骤三:创建向量数据库:
python
vectorstore = FAISS.from_documents(documents=splits, embedding=embeddings)
vectorstore.save_local("./save_knowledgeDB")结果展示------生成好的知识库:
如果创建成功后,下次就不用再创建向量数据库了,直接导入加载即可,加载代码如下:
python
vectorstore = FAISS.load_local(
folder_path="./save_knowledgeDB", # 你的保存路径
embeddings=embeddings, # 需要用相同的embedding模型
allow_dangerous_deserialization=True
)步骤四:创造检索器
由于工作内容检索复杂,我打算采用混合检索器的方式,那么混合检索器主要分为2种,分别为:简单检索器和加权融和检索器。混合检索器混合的两种方法通常是向量检索和BM25混合,下面我将主要介绍这两种方法:
方法一:简单融合检索器实现
python
def Simple_hunhe_search(query, k):
print("🟢 简单混合检索------执行向量检索...")
vector_document = vector_retriever.invoke(query)
print("🟢 简单混合检索------执行BM25检索...")
bm25_document = BM25_retriever.invoke(query)
all_docs, seen__content = [], set()
for _ in vector_document:
content = _.page_content[:100] # 取文档前100字符作为唯一标识,防止相同文档重复统计
if content not in seen__content:
all_docs.append((_, 0.6))
seen__content.add(content)
for _ in bm25_document:
content = _.page_content[:100]
if content not in seen__content:
seen__content.add(content)
all_docs.append((_,0.4))
all_docs.sort(key=lambda x:x[1], reverse=True)
result = [c for c,_ in all_docs[:k]]
print("🟢 简单混合检索完成!...")
return result方法一:加权融合检索器实现
python
def Weight_hunhe_search(query, vector_weight=0.7, bm25_weight=0.3, k=5):
print(f"⚖️ 加权融合检索 (向量:{vector_weight}/BM25:{bm25_weight})")
vector_document = vector_retriever.invoke(query)
bm25_document = BM25_retriever.invoke(query)
score_docs = {}
for i, _ in enumerate(vector_document):
score = (1 - i/len(vector_document)) * vector_weight if vector_document else 0
content = _.page_content[:150]
if content not in score_docs:
score_docs[content] = {"doc":_, "score":score}
else:
score_docs[content]["score"] += score
for i, _ in enumerate(bm25_document):
score = (1-i/len(bm25_document)) * bm25_weight if bm25_document else 0
content = _.page_content[:150]
if content not in score_docs:
score_docs[content] = {"doc":_, "score":score}
else:
score_docs[content]["score"] += score
result = sorted(score_docs.values(), key=lambda x:x['score'],reverse=True)
result = [items['doc'] for items in result[:k]]
return result步骤五:写好提示词,连接chain,搭建工作流。
我们的目的是:先提取用户想买的商品,该商品放入检索器检索并输出可能的商品,再让一个基础LLMChain完成商品推荐逻辑
python
## 先提取用户的商品名称:
from langchain_classic.chains import LLMChain
extract_product_name = LLMChain(llm=llm, prompt=PromptTemplate.from_template("你是一个专业提取用户需求的助手,能够提取用户{input}里面想要的商品名称。例如:我想买花露水 -> 花露水,直接输出最终商品名称即可,严禁多于废话"),
output_key="product_name", verbose=False)
introduct_products = LLMChain(llm=llm, prompt=PromptTemplate.from_template("请结合用户需求,和在知识库中检索出来的商品列表,挑选最符合的商品推荐给用户,输出格式为:" \
"为您推荐xx个商品,第一款为xxx,第二款为xxx。现在用户需求为{input},商品列表为{product_list}"),
output_key="answer", verbose=False)
user_issues = [
"我想买大米",
"给我推荐食用油",
"有没有口罩"
]
for i, issue in enumerate(user_issues, 1):
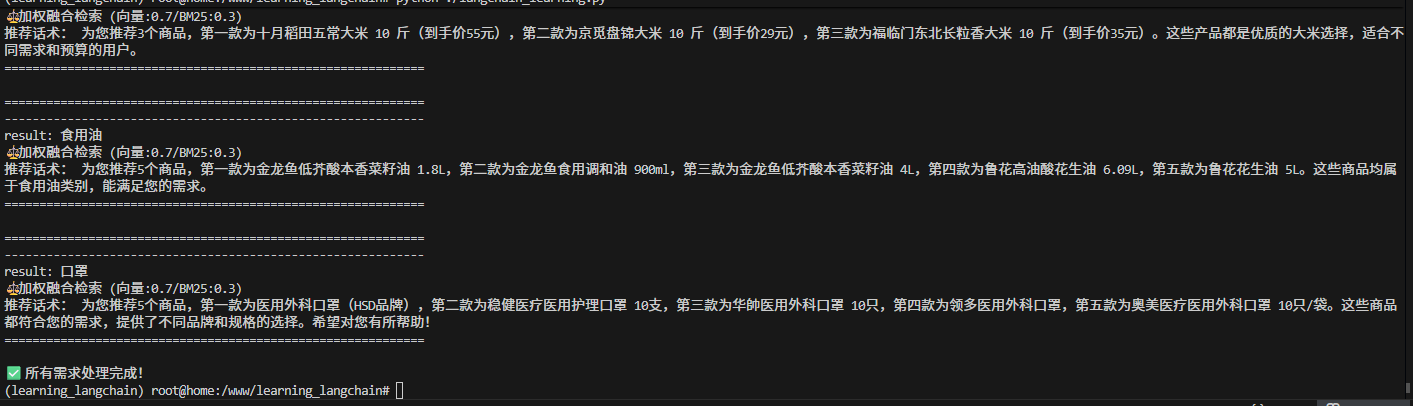
print(f"\n{'='*60}")
print(f"{'-'*60}")
result = extract_product_name.invoke({"input":f"{issue}"})
print("result:",result['product_name'])
products_list = Weight_hunhe_search(result['product_name'], vector_weight=0.7, bm25_weight=0.3, k=10)
res = introduct_products.invoke({"input":f"{issue}", "product_list":f'{products_list}'})
print("推荐话术:", res['answer'])
print(f"{'='*60}")
print("\n✅ 所有需求处理完成!")效果展示