
💎【行业认证·权威头衔】
✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家
✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主
✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】
🎖 连续三年蝉联"华为云十佳博主"(2022-2024)
🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】
覆盖全栈技术矩阵:
◾ 编程语言:.NET/Java/Python/Go/Node...
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
文章目录
- 🚀前言
- [🚀一、知识库的理论基础 RAG](#🚀一、知识库的理论基础 RAG)
-
- [🔎1.RAG 的基本概念](#🔎1.RAG 的基本概念)
- [🔎2.RAG 的核心架构](#🔎2.RAG 的核心架构)
- [🔎3.RAG 的核心优势](#🔎3.RAG 的核心优势)
🚀前言
通用大模型虽然功能强大,但它可能会产生"幻觉",其回答问题的准确性无法达到100%。在对模型生成文本的准确性要求较高的应用场景中,例如企业智能客服、高精尖科学技术服务等,往往需要通过知识库来集成私有知识数据,从而丰富大模型的知识范围并提高其回复的准确性。本章将讲解基于大模型的企业知识库的相关知识,并介绍扣子知识库及其在打造汽车行业智能客服方面的实战案例。
🚀一、知识库的理论基础 RAG
🔎1.RAG 的基本概念
RAG(检索增强生成) 是一种将信息检索与文本生成相结合的技术。其核心目的是为了向通用大模型补充外部的、专有的知识,从而生成更准确、更相关且信息更丰富的回答。
简单来说,RAG的工作模式是 "先检索,后生成" 。当用户提出问题时,系统首先从一个大型知识库(如企业内部文档)中查找相关信息,然后将这些检索到的信息作为上下文,与原始问题一并提交给大模型进行处理。这使得大模型的回答能够"有据可依",有效弥补了其自身在特定领域知识上的不足,减少了产生"幻觉"(编造信息)或给出无关答案的可能性。
🔎2.RAG 的核心架构
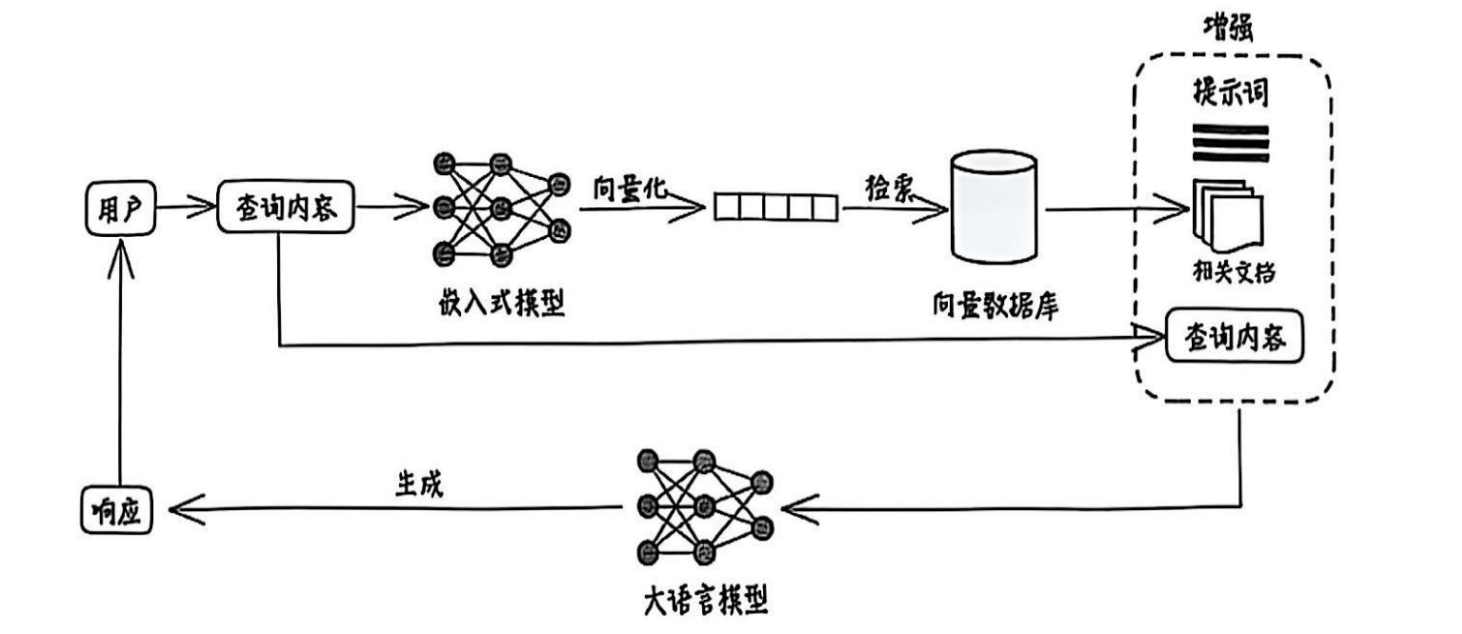
一个典型的RAG流程包含三个核心步骤:检索、增强、生成,其基本架构如图所示。
-
检索(Retrieval)
根据用户的查询内容,从外部知识库中获取相关信息。技术上,这通常通过向量化检索实现:
- 首先,将用户的查询文本通过嵌入模型转换为一个数值向量(即语义表示)。
- 然后,在一个预先构建好的向量数据库中,通过相似度计算(如余弦相似度),快速找出与查询向量最匹配的前K个文本片段。
-
增强(Augmentation)
将上一步检索到的相关文本片段(知识)与用户的原始查询,一同整合到一个预设的提示词模板中。这个模板会指导大模型如何利用这些补充信息。
-
生成(Generation)
将经过"增强"后的、包含上下文信息的完整提示词,输入给大型语言模型。最终,由大模型综合原始问题和提供的参考资料,生成最终的、准确的答案。
整个RAG系统的应用可以分为两个主要阶段:知识库构建 和知识库应用。
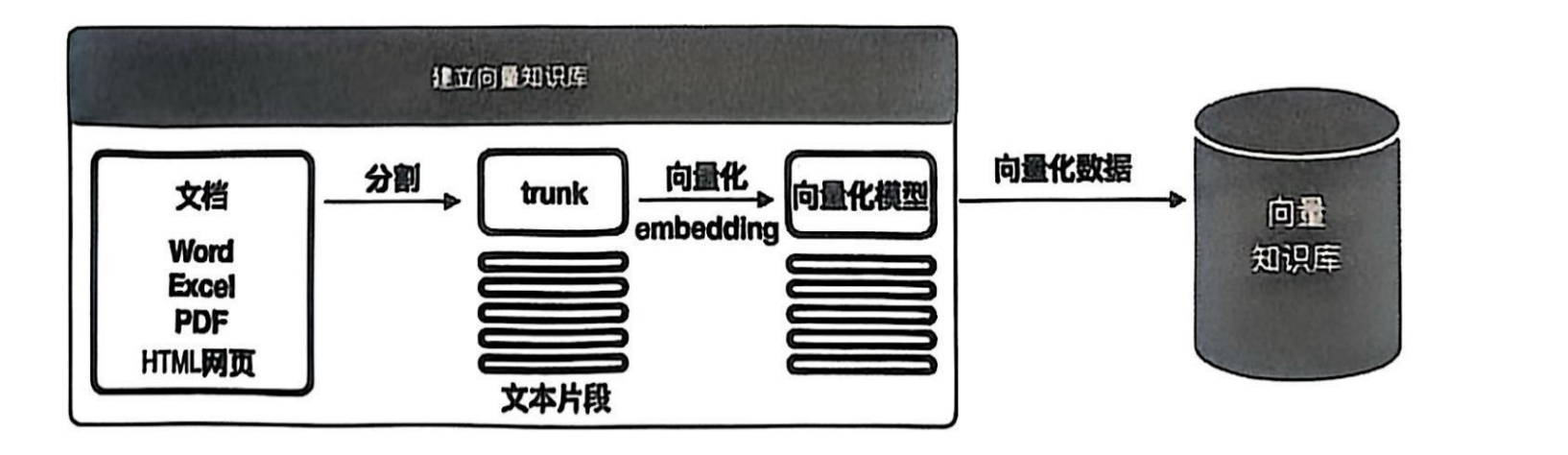
阶段一:知识库的构建(索引创建)
这是将原始资料处理成可供高效检索的知识库的过程,步骤如图所示:
- 数据收集与准备:从企业内部的各种渠道(如文档、数据库、系统)收集原始数据,格式可能包括Word、PDF、TXT、Excel等。
- 文档分割与预处理:对长文档进行清洗、标准化,并将其分割成大小合适的文本块,以便后续处理和精准检索。
- 向量化:使用嵌入模型将每个文本块转换为高维向量。这种向量表示能够捕捉文本的深层语义信息。
- 索引创建 :将所有文本向量存入向量数据库,并构建高效的索引结构(如使用近似最近邻算法),以实现后续的快速相似性搜索。
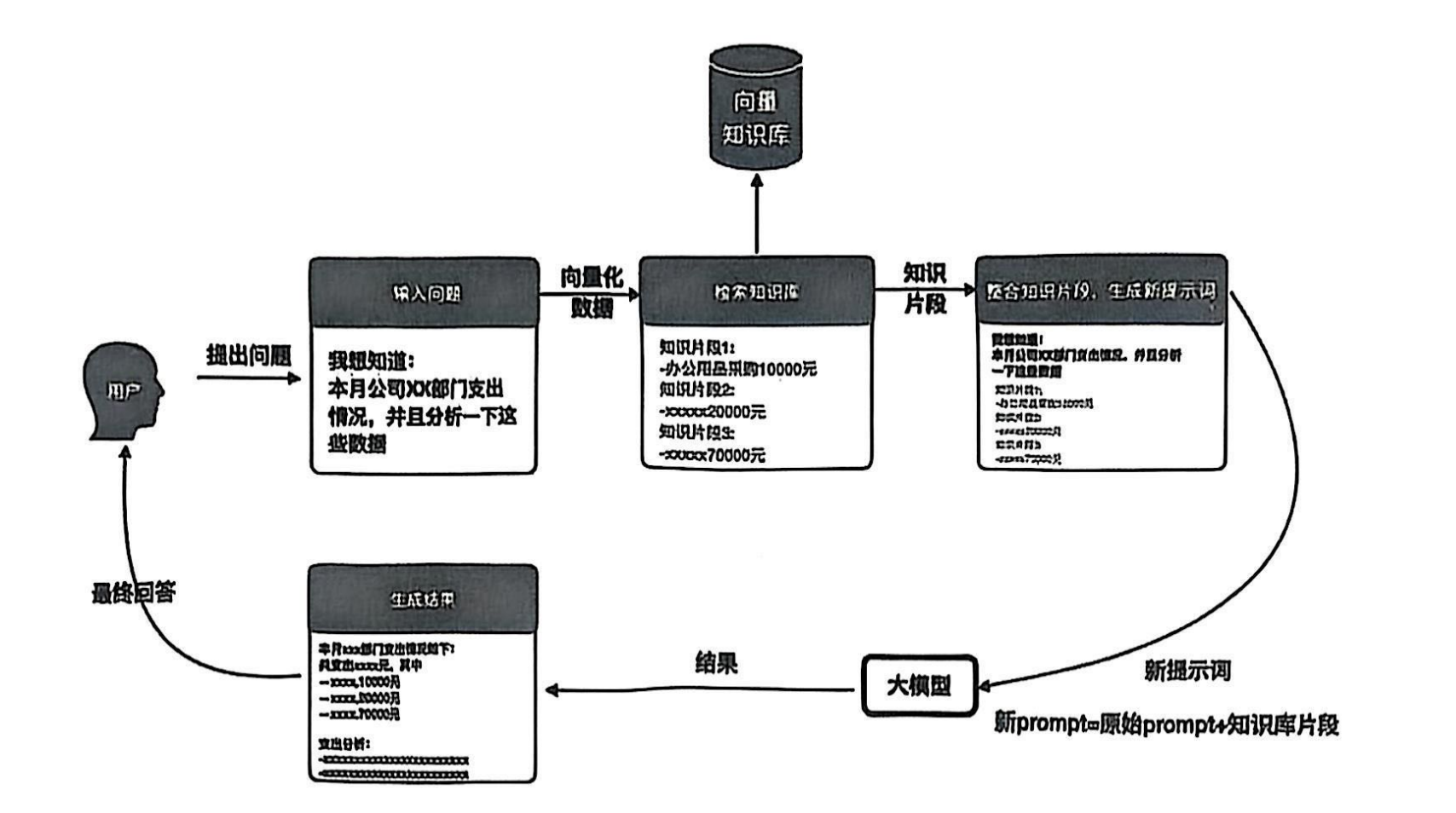
阶段二:知识库的应用(问答推理)
这是用户实际使用知识库进行问答的阶段,流程如图所示:
用户输入问题 → 系统从知识库中检索关联信息 → 将问题和检索信息结合成提示词 → 大模型生成答案 → 返回结果给用户。
🔎3.RAG 的核心优势
对于企业应用而言,RAG架构在准确性、时效性和安全性方面提供了关键优势:
- 提升准确性,减少幻觉:通过让大模型在生成答案时参考检索到的具体文档片段,RAG能确保答案有据可查,极大降低了生成错误或虚构信息的可能性,使输出更加可靠。
- 保证时效性,易于更新:RAG模型的知识更新非常灵活。企业只需更新向量数据库中的文档内容,无需重新训练或微调成本高昂的大模型,即可让系统基于最新信息进行回答,这对于政策、产品信息频繁变动的场景至关重要。
- 保障安全性,实现数据私有:企业可以在本地或私有环境中部署RAG系统,将敏感数据和知识库完全掌控在自己手中。查询时,只有相关的、非原始的文本片段会被发送给大模型(可以是公有云API或本地部署的模型),避免了将核心原始数据直接暴露给外部服务的风险,完美契合了企业对数据安全和隐私保护的严格要求。