【进阶教程】Windows本地部署GPT-SoVITS并联动Dify复刻"芙宁娜"语音助手
本教程将指导你如何在Windows电脑上本地部署GPT-SoVITS语音生成服务,并通过Dify的工作流(Workflow)调用它,实现一个能够用"芙宁娜"口吻和声音回复的AI助手。
一、 前置准备
-
安装Dify :
需要本地安装好Dify(建议使用Docker部署)。如果未安装,请参考上一篇教程:【Windows笔记本大模型"傻瓜式"教程】使用Dify工具来完成对Windows笔记本大模型Qwen2.5-3B-Instruct知识库集成和Agent流程制作。
-
准备软件与模型 :
GPT-SoVITS在Windows上推荐使用整合包,省去配置Python环境的麻烦。我们需要下载程序本体 和芙宁娜的语音模型。
二、 安装启动 GPT-SoVITS
1. 解压与脚本制作
将下载好的 GPT-SoVITS 压缩包解压到一个纯英文路径 下(例如 D:\AI\GPT-SoVITS)。
在文件夹根目录下,新建一个文本文档,重命名为 go-api.bat,右键点击编辑,粘贴以下代码:
batch
@echo off
echo 正在启动 GPT-SoVITS API (V2版本)...
REM 尝试调用 runtime 里的 python 运行 api_v2.py
REM 如果你的整合包 python 路径不同,请修改 runtime\python.exe
if exist "api_v2.py" (
.\runtime\python.exe api_v2.py
) else (
echo 根目录下没找到 api_v2.py,尝试在 GPT_SoVITS 子目录寻找...
.\runtime\python.exe GPT_SoVITS\api_v2.py
)
pause2. 启动服务
双击运行制作好的 go-api.bat。等待黑色窗口滚动日志,直到出现以下内容,代表API启动成功:
text
INFO: Started server process [41100]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:9880 (Press CTRL+C to quit)注意:请保持这个黑色窗口开启,不要关闭。
3. 模型文件处理(⚠️关键避坑)
解压下载好的"芙宁娜"模型包,你会看到三个关键文件。为了防止API因为中文特殊符号报错,强烈建议对参考音频重命名:
- GPT模型 :
芙宁娜_ZH-e10.ckpt- 建议放入路径:
GPT-SoVITS根目录\GPT_weights_v2\
- 建议放入路径:
- SoVITS模型 :
芙宁娜_ZH_e10_s950_l32.pth- 建议放入路径:
GPT-SoVITS根目录\SoVITS_weights_v2\
- 建议放入路径:
- 参考音频 :原文件名很长(
【默认】根据故事走向...),请将其重命名为1.wav。- 建议放入路径:
D:\1.wav(路径越简单越好)
- 建议放入路径:
记录下这三个文件的绝对路径,稍后在Dify中要用到。
三、 Dify 的配置
1. 开始节点
在Workflow中添加【开始】节点。
- 配置:确保有一个输入变量(通常默认为
sys.query),为了容纳更多内容,建议将最大长度限制调大(如2000)。
2. 问题分类器(可选)
- 说明:如果你是在现有的Agent中集成该功能,需要使用分类器来判断用户意图。如果是新建的专用Workflow,此步骤可跳过。
- 配置 :增加一个分类,关键词/意图描述填写:
用户需要使用芙宁娜的声音来生成一段语音。
3. LLM 节点(角色扮演)
添加一个LLM节点,用于将用户的普通话术改写为"芙宁娜"的风格。
-
模型:选择你部署好的 Qwen2.5 或其他大模型。
-
System 提示词 :
text你现在是《原神》中的"芙宁娜"。 请将用户的输入内容改写成芙宁娜的口吻进行回复。 人设要求: 1. 称呼用户为"旅行者"。 2. 语气端庄、优雅、温柔,带有一点点大小姐的矜持。 3. 这是一个语音生成的中间步骤,请不要输出表情符号(如(微笑)),只输出纯文本内容,方便后续TTS朗读。 4. 如果用户输入的内容不适合直接改写,就以芙宁娜的身份通过语音回应他。 -
User 提示词 :选择变量
{``{#start.query#}}(即用户在开始节点的输入)。
4. HTTP 请求节点(核心步骤)
添加一个 HTTP 请求节点,用于调用本地的 TTS 服务。
- 请求方法 :
GET - API 地址 :
http://host.docker.internal:9880/tts解释:host.docker.internal是Docker容器内部访问宿主机Windows的专用地址。 - 参数 (Params) :
请在"Params"部分添加以下 7个 Key-Value 键值对(请务必替换为你电脑上的实际路径):
| Key (键) | Value (值) | 说明 |
|---|---|---|
text |
{``{#llm.text#}} |
这里选LLM节点的输出变量,不要写死。 |
text_lang |
zh |
要合成的语言(中文)。 |
ref_audio_path |
D:\1.wav |
刚才重命名后的参考音频路径。 |
prompt_lang |
zh |
参考音频的语言。 |
prompt_text |
根据故事走向,前往特定情景吗?听起来挺新颖。所以信封里写了什么? |
必须与参考音频的内容一字不差。 |
gpt_model_path |
D:\AI\GPT-SoVITS\GPT_weights_v2\芙宁娜_ZH-e10.ckpt |
芙宁娜GPT模型的绝对路径。 |
sovits_model_path |
D:\AI\GPT-SoVITS\SoVITS_weights_v2\芙宁娜_ZH_e10_s950_l32.pth |
芙宁娜SoVITS模型的绝对路径。 |
参数小贴士:
ref_audio_path:这是"药引子",告诉AI用什么声线说话。prompt_text:这是告诉AI"药引子"里说了什么内容,用于校准。
5. 输出节点
- 配置 :在"回复变量"中,选择 HTTP 请求节点 的输出
body或files。 - 注意:如果是 Dify 的 Workflow 模式,返回的是文件流;如果是 Chatflow 模式,Dify 会自动解析为音频播放器。
四、 测试
- 点击右上角的 "预览" 或 "运行"。
- 输入测试内容 :
你好,我亲爱的旅行者,谢谢你来看我,为了感谢你,我绝对给你分享我最喜欢的草莓小蛋糕,怎么样? - 结果验证 :
- LLM 节点会先把它改写得更有"芙宁娜味儿"。
- HTTP 节点会处理几秒钟。
- 最后返回一个可以播放的音频文件。
点击播放,享受芙宁娜大人的亲自问候吧!
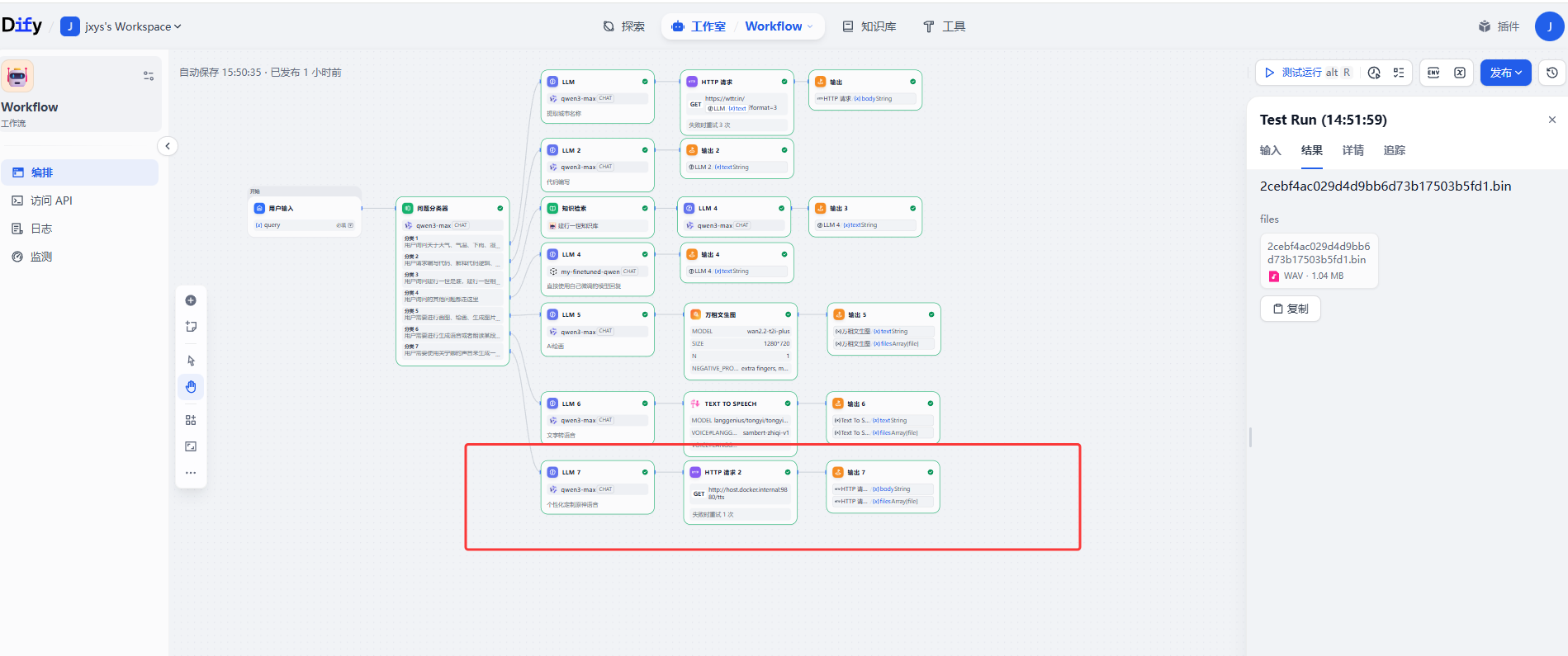
以下是整个简单dome的工程,红框位置是本次使用的节点