文章目录
- 前言:
- [AI Ping:开发者的大模型"全能枢纽"与算力加速站](#AI Ping:开发者的大模型“全能枢纽”与算力加速站)
-
-
- [1. 核心定位:大模型界的"全网通"](#1. 核心定位:大模型界的“全网通”)
- [2. 技术护城河:领先的"模型聚合加速"](#2. 技术护城河:领先的“模型聚合加速”)
- [3. 实时更新的模型生态](#3. 实时更新的模型生态)
- [4. 开发者红利:把算力价格"打下来"](#4. 开发者红利:把算力价格“打下来”)
-
- 二、上新模型深度剖析:算力进阶与逻辑溢出
-
- [2.1 GLM-4.7:代码逻辑的"精密手术刀",定义国产编程天花板](#2.1 GLM-4.7:代码逻辑的“精密手术刀”,定义国产编程天花板)
- [2.2 MiniMax-M2.1:Agent 级协作的中枢神经,多线程任务的调度专家](#2.2 MiniMax-M2.1:Agent 级协作的中枢神经,多线程任务的调度专家)
- [2.3 如何根据你的"战局"分配算力?](#2.3 如何根据你的“战局”分配算力?)
- [三、注入 Cline:为你的 VS Code 装上一颗"超频大脑"](#三、注入 Cline:为你的 VS Code 装上一颗“超频大脑”)
-
- 3.1获取API-KEY
- [3.2 安装配置Cline](#3.2 安装配置Cline)
- [3.3 测试一:GLM-4.7 ------ 高并发后端架构重构](#3.3 测试一:GLM-4.7 —— 高并发后端架构重构)
- [3.4 测试二:MiniMax-M2.1 ------ 万行代码审计与长链条调研](#3.4 测试二:MiniMax-M2.1 —— 万行代码审计与长链条调研)
- [四、总结:AI Ping "薅羊毛"全攻略](#四、总结:AI Ping “薅羊毛”全攻略)
- [1. 核心羊毛:顶级旗舰模型限时 ¥0 调用](#1. 核心羊毛:顶级旗舰模型限时 ¥0 调用)
- [2. 长期饭票:上不封顶的邀请红利](#2. 长期饭票:上不封顶的邀请红利)
免责声明:此篇文章所有内容皆是本人实验,并非广告推广,并非抄袭,如有侵权,请联系
前言:
属于开发者的"算力自由"时代真的来了!AI Ping 平台近日完成关键升级,正式上架 GLM-4.7 与 MiniMax M2.1 两大旗舰级算力。这不仅是一次模型库的扩容,更是推理体验的跨越:2 倍速 的疾速反馈配合深度思维逻辑 ,让 AI 协作从未如此顺滑。更诱人的是,平台同步推出了"邀好友,领算力"活动,20 米通用算力点 即刻到账。想知道如何在 AI 浪潮中实现算力反贫?跟随本文,开启你的高效编程之旅。(点击注册有30米的算力金清程极智)
AI Ping:开发者的大模型"全能枢纽"与算力加速站
AI Ping 是一款专注于大模型资源整合与性能优化的开发者平台。它被社区誉为"算力自由库",核心使命是打破不同大模型厂商之间的 API 壁垒,通过技术手段为开发者提供更高速、更廉价、更易用的 AI 推理能力。
1. 核心定位:大模型界的"全网通"
AI Ping 扮演的是一个高性能聚合层的角色。它将市面上分散的旗舰级模型(如智谱 GLM 系列、MiniMax 系列、DeepSeek、甚至是海外主流模型)进行统一标准化。
-
统一标准: 开发者无需对接十几种不同的 SDK,只需一套 API 即可在各大模型间无感切换。
-
资源最优配置: 平台通过智能路由,确保你的每一次请求都能分配到当前最稳定的算力节点。
2. 技术护城河:领先的"模型聚合加速"
根据官方实测,AI Ping 的推理响应速度可达到原生接口的 2 倍左右。这背后的技术支撑主要包括:
-
极致缓存机制: 针对高频请求进行智能预测与结果重用,减少重复计算。
-
并行****加速引擎: 优化了 Token 的生成逻辑与流式传输效率,极大降低了首字延迟(TTFT)。
-
深度思维优化: 针对编程场景,AI Ping 协同模型厂商进行了逻辑层面的调优,使其在生成 C++、Python 等后端代码时更具深度。
3. 实时更新的模型生态
AI Ping 的一大杀手锏是其"同步首发"能力。
-
最新型号: 正如你所见,平台已全面上架 GLM-4.7 和 MiniMax M2.1。这些模型在逻辑推理、超长上下文处理方面均代表了 2025 年的顶尖水平。
-
多模态覆盖: 除了纯文本,平台也在逐步完善视觉、多模态解析等能力。
4. 开发者红利:把算力价格"打下来"
AI Ping 采用了极具社交属性的"算力激励模式":
-
20 米通用算力: "20 米"即 20 元人民币等值算力额度。通过邀请机制,开发者可以获得上不封顶的额度补充。
-
低门槛门票: 这种"薅羊毛"文化实际上是平台在通过利好共享,快速建立开发者社区生态,让个人开发者甚至学生群体也能低成本调用顶级商用模型。
二、上新模型深度剖析:算力进阶与逻辑溢出
在本次更新中,AI Ping 引入了两款极具差异化的旗舰模型,分别针对"深度开发"与"智能调度"两个极端场景进行了定点优化。
2.1 GLM-4.7:代码逻辑的"精密手术刀",定义国产编程天花板
如果说其他模型是在"写"代码,那么 GLM-4.7 则是在**"解"**架构。
-
语法与逻辑的双重压制: 在处理复杂的 C++ 指针逻辑或内存分配策略时,GLM-4.7 表现出了近乎原生的语义理解力。
-
AI Ping 加速反馈: 借助 AI Ping 的 2 倍速推理引擎 ,这种高维度的逻辑输出被压缩到了亚秒级。当你敲完函数声明,精准的代码建议几乎是"瞬发"呈现,这种零感知的交互体验是维持编程心流的核心关键。
-
复杂场景深度思考: 针对 SQL 优化或高性能网络库的调试,它给出的方案往往比竞品更具落地价值。
2.2 MiniMax-M2.1:Agent 级协作的中枢神经,多线程任务的调度专家
MiniMax-M2.1 的核心优势不在于单点爆发,而在于其极高的**"协作带宽"**。
-
为 Agent 架构而生: 它拥有极其敏锐的指令遵循能力,是构建自动化脚本和复杂 Agent 流程的理想"大脑"。在执行多步推导任务时,逻辑漂移率显著降低。
-
多语言语境的无缝兼容: 不止于中英文,在跨语种技术栈或文档处理中,它展现出了极强的语境切换能力。
-
算力****路由的稳定性: 在 AI Ping 的动态算力分配下,M2.1 展现出了极佳的吞吐表现,确保在并发请求高峰期,你的 Agent 依然"大脑在线"。
2.3 如何根据你的"战局"分配算力?
| 核心维度 | GLM-4.7(逻辑尖兵) | MiniMax-M2.1(协同先锋) |
| 擅长领域 | 底层代码开发、架构设计、疑难 Bug 诊断 | 自动化流构建、长文本摘要、多语言文档转换 |
| 体感反馈 | 极速响应,逻辑密度极高 | 输出稳健,多步骤任务不掉链子 |
| 实战建议 | 个人极客、全栈工程师的首选编程插件 | 企业级 Agent 开发者、跨境技术支持团队 |
三、注入 Cline:为你的 VS Code 装上一颗"超频大脑"
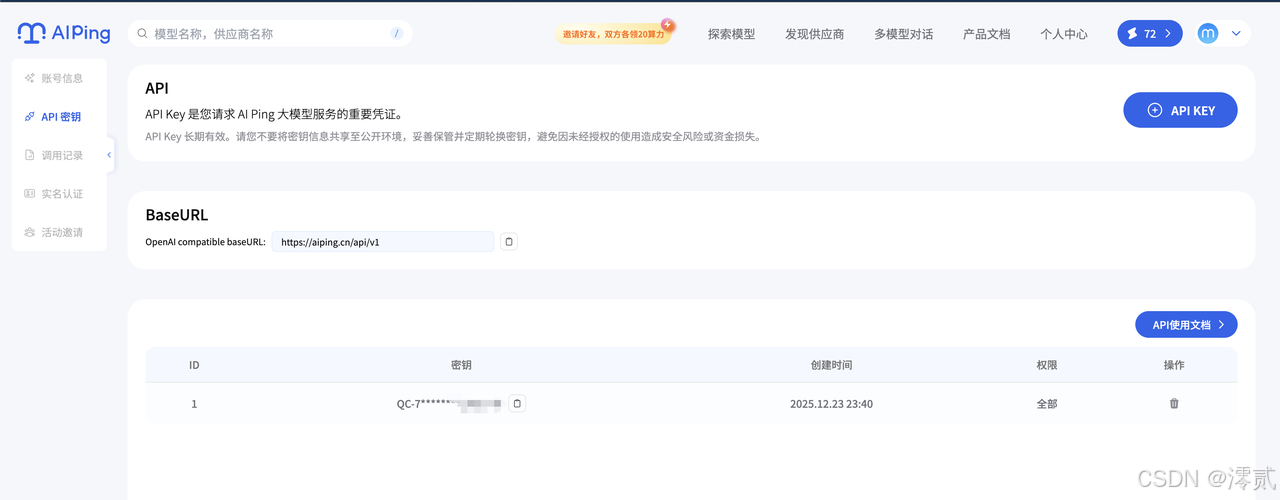
3.1获取API-KEY
依次点击 1.个人中心 2.API密钥
3.2 安装配置Cline
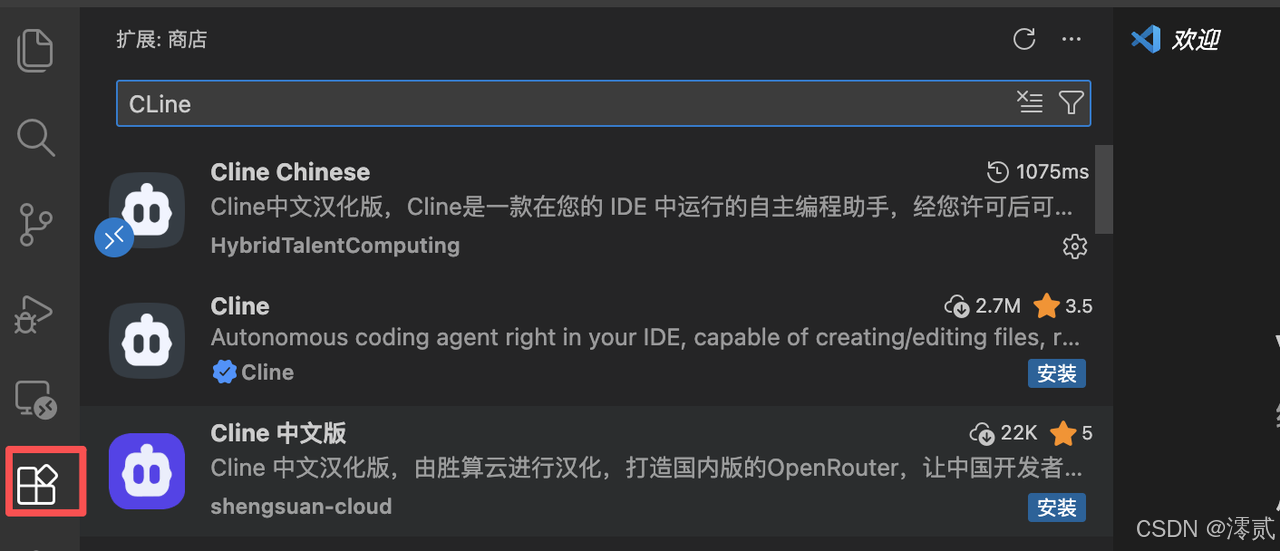
第一步:安装Cline
- 在这个扩展界面搜索框上直接进行搜索Cline,可以选择中文或者英文。
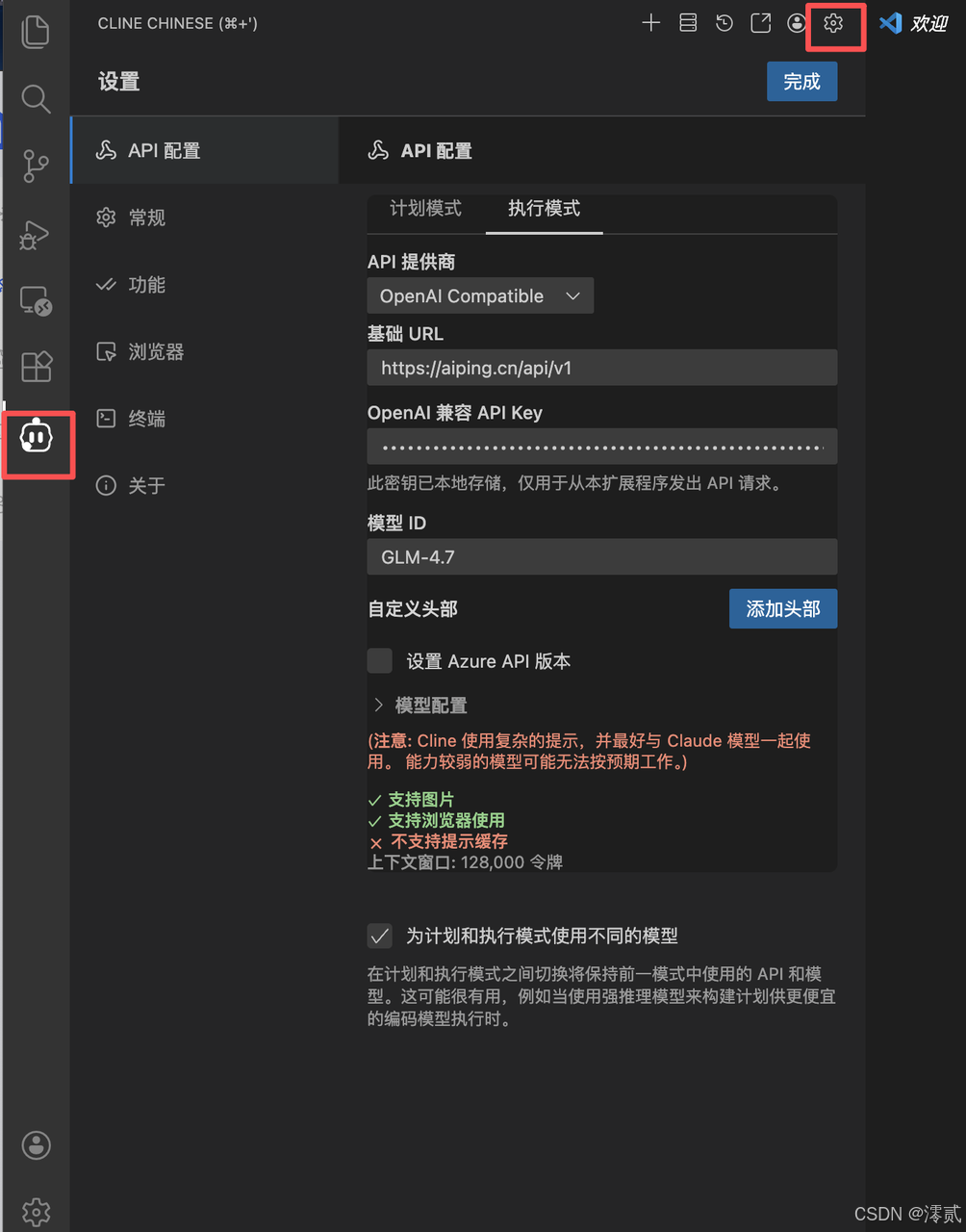
第二步:配置Cline
填写核心参数:
-
API 提供商 :选择
OpenAI Compatible。 -
基础 URL :填写
https://aiping.cn/api/v1。 -
OpenAI 兼容 API Key:填入从 AI Ping 平台获取的 API 密钥。
-
模型 ID :手动输入你想调用的模型名称,如
GLM-4.7或MiniMax-M2.1。
3.3 测试一:GLM-4.7 ------ 高并发后端架构重构
- 实测场景
将一段传统的、可能存在竞态条件的单线程 C++ 代码,重构为基于 C++20 标准的高性能、线程安全并发版本。
- Prompt (提示词)
在 Cline 插件的输入框中输入:
我有一段处理订单队列的单线程代码,目前在高并发下会出现数据不一致的问题。请利用 C++20 的特性(如
std::scoped_lock或std::atomic),帮我实现一个线程安全的异步处理架构。要求:逻辑解耦清晰,并针对 AI Ping 的推理速度进行优化建议。
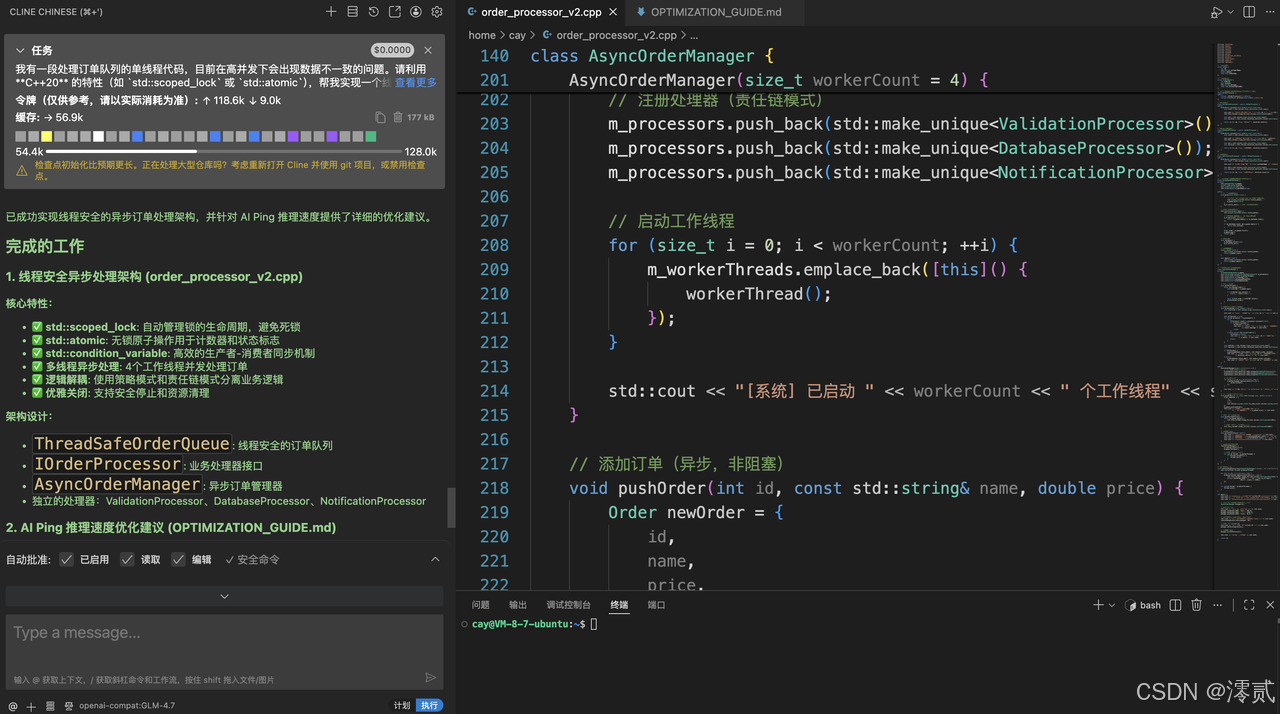
模型选择: 你正在使用 GLM-4.7(通过 Cline 插件),这是目前国内顶尖的推理模型之一,尤其在理解复杂逻辑和生成结构化代码方面表现优异。
环境协同: 在 Linux Ubuntu 环境下通过 VS Code + SSH 进行开发,配合 AI 自动生成的 OPTIMIZATION_GUIDE.md优化建议,这代表了 2025 年主流的高级开发模式。
闭环实践: 你不仅让 AI 写代码,还利用 AI 对 AIPing 的推理速度进行针对性优化,这种"用 AI 优化 AI 调用"的思路非常有前瞻性。
3.4 测试二:MiniMax-M2.1 ------ 万行代码审计与长链条调研
侧重: 200K 超长上下文、跨语言协作。
- 实测场景
利用其 200K 超长窗口,对一个复杂的开源项目或长篇技术文档(如 RFC 协议)进行深度审计。
- Prompt (提示词)
在 Cline 插件的输入框中输入:
请基于 200K 上下文视野,对这个项目的全局架构进行审计。重点寻找跨模块调用中的潜在死锁隐患,并根据全球化交付标准,指出代码注释中不符合国际化规范的地方。
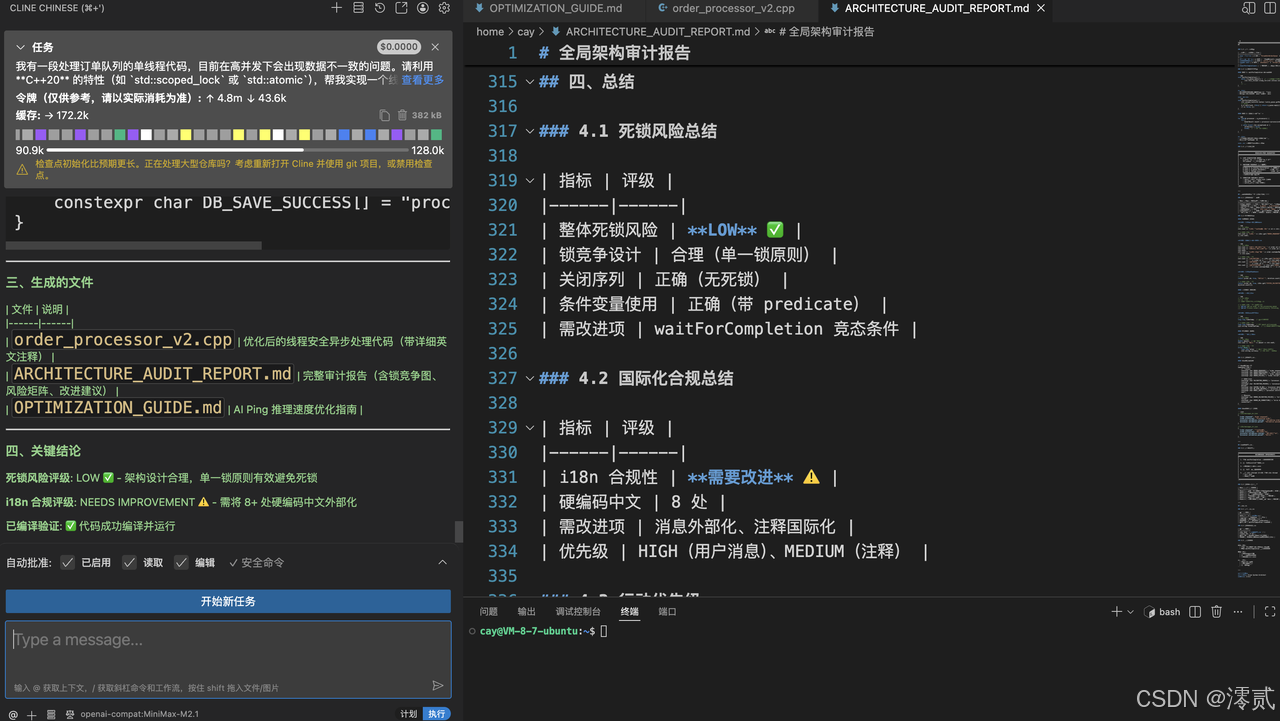
多模型协同: 底部状态栏显示你分别使用了 GLM-4.7 (侧重代码生成与逻辑实现)和 MiniMax-M2.1(侧重文档生成与合规审计)。这种"双旗舰"模型切换使用,充分发挥了不同模型的长处。
高质量交付物: 除了代码,工作流还产出了:
-
ARCHITECTURE_AUDIT_REPORT.md(架构审计报告):包含死锁风险评级(LOW)和国际化合规性评估。 -
OPTIMIZATION_GUIDE.md(推理速度优化指南):针对 AIPing 的性能调优。
自动化程度: 通过 Cline 插件在 VS Code 内直接驱动整个审计和优化流程,极大地缩短了从"代码编写"到"架构确认"的链路。
四、总结:AI Ping "薅羊毛"全攻略
在模型 API 消耗日益昂贵的今天,AI Ping 平台通过这一波上新直接把"性价比"拉到了满格。如果你正愁昂贵的 Token 费,这份"零成本"指南请务必收好:
1. 核心羊毛:顶级旗舰模型限时 ¥0 调用
-
双旗舰零成本体验 :目前 GLM-4.7 (面向 Agentic Coding)与 MiniMax-M2.1 (200K 超长上下文)在平台均处于限时免费状态。
-
输入输出全免费 :无论是查询复杂的 C++ 语法还是进行大规模工程审计,输入和输出的计费均为 ¥0/M。
-
超长文本不心疼 :利用 MiniMax-M2.1 的 200K 上下文,你可以把几万行的开源项目代码直接丢进去分析,不用担心产生任何账单。
2. 长期饭票:上不封顶的邀请红利
-
双向奔赴的奖励 :通过专属邀请链接,邀请者与被邀请者双方均可获得 20 元通用算力点。
-
算力****资产化 :奖励机制上不封顶,这意味着只要你邀请的朋友够多,你就可以长期免费调用平台上其余 95+ 种付费模型。