前言
上篇文章 LangGraph1.0速通指南(三)------ LangGraph1.0 自动邮件处理智能体实战阅读完成后,大家就系统掌握了 LangGraph 1.0 中"点"、"边"、"图"、"记忆"与"人在回路"等核心功能,并通过一个完整的自动邮件处理智能体,学习了使用 LangGraph 开发智能体的基本方法。
然而,要想高效构建一个可靠、可扩展的智能体,仅仅熟悉语法和基础功能是不够的。笔者在《LangGraph 1.0 速通指南(一)------ LangGraph 1.0 核心概念、点、边》中曾将 LangGraph 比作"智能体开发的编程语言"。既然是一种语言,自然存在一系列经过实践检验、可复用的优秀构造模式------这正是智能体开发的设计模式。
从本文开始,笔者将开启 LangGraph 设计模式系列的分享,系统介绍如何运用这些模式来构建更清晰、健壮且易于维护的智能体工作流。本系列将涵盖常见的工作流模式与多智能体架构模式,预计通过五篇文章展开。相关内容均列于笔者的专栏《深入浅出LangChain&LangGraph AI Agent 智能体开发》,同时也要说明该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 34 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
一、LangGraph设计模式
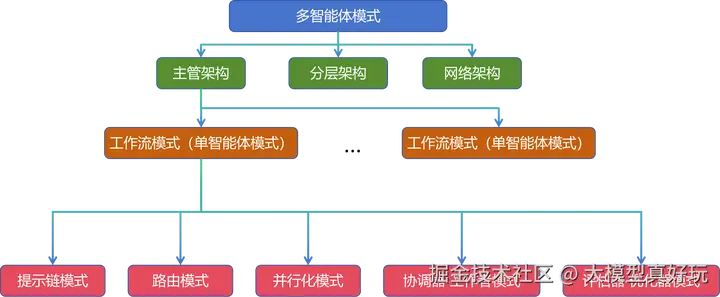
1.1 LangGraph设计模式总览
随着大模型智能体能力的不断增强,其需要处理的任务也日趋复杂。如同城市建设需要规划蓝图、软件开发离不开架构设计一样,构建强大且稳健的人工智能体系统,同样需要精心设计的架构模式作为支撑。
从本期开始,笔者将系统介绍在 LangGraph 框架下构建各类智能体系统的关键架构模式。这些模式将涵盖从基础的工作流编排,到更高级的多智能体协同设计,为大家开发智能体提供一套可复用、可扩展的方法论。
添加图片注释,不超过 140 字(可选)
1.2 LangGraph工作流模式
笔者首先介绍 LangGraph 的工作流模式 ,它常被称为单智能体模式。需要明确的是,"单智能体"并非指仅使用一个大模型,而是指系统目标单一,且所有决策由一个统一的智能体核心来完成。一个基础的单智能体通常由以下部分构成:大模型(如 DeepSeek、Qwen3)作为"大脑",可调用各种工具,具备记忆存储与检索能力,并通过系统提示词来响应用户输入。
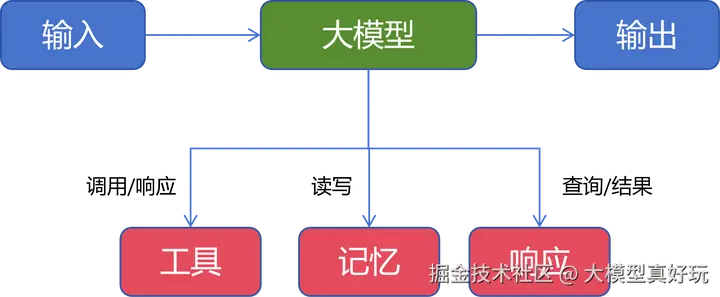
而 LangGraph 的工作流模式,正是在此基础上,通过引入规划与多步调用机制等,来更高效、更可靠地完成复杂用户任务。常见的工作流模式包括提示链模式、路由模式、并行化模式、协调器-工作者模式、评估器-优化器模式 等。本期笔者先从几个相对基础的模式开始分享:提示链模式、路由模式和并行化模式。
二、提示链模式
2.1 提示链模式定义
提示链模式是最基础的工作流模式之一,其核心思想是将复杂任务分解为一系列更简单、相互关联的步骤。在该模式中,大模型被多次顺序调用,且前一次调用的输出常作为后续调用的输入,从而形成一个多阶段、串行处理的工作流。
为了确保流程的质量和方向,提示链模式在步骤之间通常会引入程序化的检查点,称为 "门控"(Gate) 。门控作为质量审查节点,能够校验上一步的输出是否满足特定条件,从而决定流程是继续向前、转向特定分支还是提前结束。
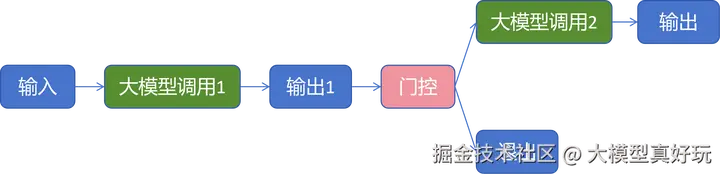
提示链模式的核心优势在于:
- 分解复杂度:将庞杂任务拆分为更小、更易管理的子任务,降低单次处理的认知负荷。
- 提升准确性与可控性:通过多步骤的精细化和中间检查,能够获得比单次大模型调用更可靠、更符合预期的输出。
该模式特别适用于那些能够被清晰划分为顺序子任务的场景。例如,要生成一个小众语言的营销文案,可以将其拆解为:第一步由大模型生成高质量的英文/中文原稿,第二步再由大模型将其翻译为目标语言。在第一步之后,还可以加入门控检查,确保原稿的调性、长度或关键信息点符合要求,从而更好地控制最终结果的质量。
2.2 提示链模式代码示例
单纯的概念描述不够直观,接下来笔者通过一个具体的代码实例来理解。本例将模拟一个多步骤生成优质笑话的流程:首先生成简短笑话,然后根据检查结果决定是否增强趣味性,最后进行润色转折。
-
引入相关依赖: 在项目文件夹下新建.env文件,填入你的DEEPSEEK_API_KEY。
pythonfrom typing import TypedDict from langchain_deepseek import ChatDeepSeek from langgraph.graph import END, START, StateGraph from dotenv import load_dotenv #0. 配置模型 load_dotenv() llm = ChatDeepSeek( model="deepseek-chat", ) -
定义状态: 这是一个三阶段流程,因此状态需要记录初始主题、各阶段生成的笑话。
python# 1. 定义图状态 class State(TypedDict): topic: str joke: str improved_joke: str final_joke: str -
定义节点函数: 包括三个大模型调用节点和一个门控检查节点。
python# 2. 定义节点函数 def generate_joke(state: State): ''' 第一个大模型调用,根据主题生成初始笑话 ''' topic = state['topic'] msg = llm.invoke(f'写一个关于{topic}的简短笑话') return { 'joke': msg.content } def check_punchline(state: State): ''' 模拟门控函数------笑话中是否包含?或! ''' joke = state['joke'] if '?' in joke or '?' in joke: return "Fail" # 未能通过门控检查, 需要继续增强 return "Pass" def improve_joke(state: State): ''' 第二个大模型调用,通过添加文字游戏改进笑话 ''' joke = state['joke'] msg = llm.invoke(f'通过添加文字游戏使笑话更有趣,当前笑话是: {joke}') return { 'improved_joke': msg.content } def polish_joke(state: State): ''' 第三个大模型调用,最终润色笑话,添加令人惊讶的转折 ''' improved_joke = state['improved_joke'] msg = llm.invoke(f'为这个笑话添加一个令人惊讶的转折: {improved_joke}') return { 'final_joke': msg.content } -
定义边并构建图: 通过条件边来实现门控逻辑。
python#2. 定义边和图 workflow = StateGraph(State) workflow.add_node('generate_joke', generate_joke) workflow.add_node('improve_joke', improve_joke) workflow.add_node('polish_joke', polish_joke) workflow.add_edge(START, 'generate_joke') workflow.add_conditional_edges('generate_joke', check_punchline, { 'Fail': 'improve_joke', 'Pass': END }) workflow.add_edge('improve_joke', 'polish_joke') workflow.add_edge('polish_joke', END) chain = workflow.compile() -
测试运行: 当生成的简短笑话包含'?'时,无法通过门控检查,流程会进入增强和润色环节。虽然笔者一直觉得大模型生成的笑话不好笑,但从最终表现形式上看,笑话已经从简短的一小段扩充到丰富的内容,这正是提示链模式通过顺序分解任务来提升输出效果的体现。
python#3. 测试运行 state = chain.invoke({'topic': '小猫'}) print('初始笑话:') print(state['joke']) if 'improved_joke' in state: print('改进后笑话:') print(state['improved_joke']) print('最终笑话:') print(state['final_joke'])
三、路由模式
3.1 路由模式概念
路由模式旨在通过对输入请求进行智能分类,并将其定向到专门的下游处理节点,从而高效应对多样化的任务需求。在 LangGraph 的实现中,这通常涉及定义一个路由器节点(负责分类决策)和一组下游节点(每个节点专精于处理某一特定类型的任务)。工作流会使用条件边,根据路由器节点的分类结果,将任务流转导向最合适的处理分支。
路由模式的核心思想是引入一个分流步骤。该步骤可以由大模型驱动,也可以由更传统的分类模型支持。整个工作流的成功在很大程度上取决于这个分类步骤的准确性:如果输入被错误分类,就会被引导至不恰当的处理路径,从而导致输出结果不正确或不满足预期。
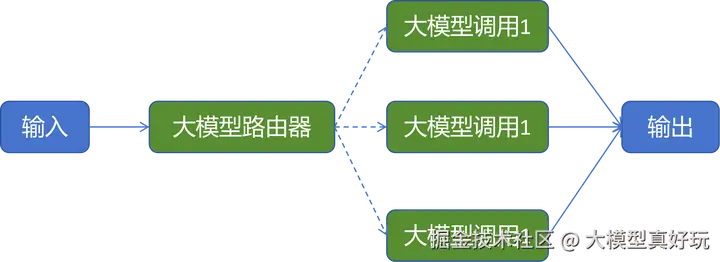
路由模式非常适合处理同一大类任务下包含多种不同处理逻辑的场景。以下是两个典型适用例子:
- 客户服务分流:在客户服务应用中,路由可用于区分不同类型的客户查询。例如,一般咨询、退款请求和技术支持工单可以被路由到不同的专用下游流程。一般咨询可能触发简单的FAQ检索;退款请求则可能启动一个需要查询订单历史并调用支付接口的工作流;而技术支持则会被导向包含详细故障排查步骤的专业流程。
- 资源与成本优化:路由还可用于优化系统的响应速度与计算成本。例如,可以根据请求的复杂度或紧急性进行分类:将简单、常见的查询路由到更轻量、快速且成本低廉的模型(如 Qwen3-8B),而将复杂、特殊的请求定向给能力更强但资源消耗也更大的模型(如 DeepSeek-671B)。
3.2 路由模式代码示例
单纯概念描述不直观,笔者通过一个具体的代码实例来理解。本例是一个内容生成器,根据用户输入决定是输出笑话、故事还是诗歌。
-
引入依赖 (同样需要配置好.env文件中的DEEPSEEK_API_KEY):
pythonfrom typing import TypedDict, Literal from langchain_deepseek import ChatDeepSeek from langgraph.graph import StateGraph, START, END from langchain.messages import HumanMessage, SystemMessage from dotenv import load_dotenv load_dotenv() llm = ChatDeepSeek( model="deepseek-chat", ) -
定义状态: 状态需要记录用户输入、路由决策以及最终输出。
pythonclass State(TypedDict): input: str decision: str output: str -
定义节点函数: 包括三个专精于不同创作类型的下游节点,以及一个负责分类的路由器节点。
python# 1. 定义节点 def generate_story(state: State): ''' 写故事节点 ''' print('进入写故事处理逻辑') result = llm.invoke(state['input']) return { 'output': result.content } def generate_joke(state: State): ''' 写笑话节点 ''' print('进入写笑话处理逻辑') result = llm.invoke(state['input']) return { 'output': result.content } def generate_poetry(state: State): ''' 写诗歌节点 ''' print('进入写诗歌处理逻辑') result = llm.invoke(state['input']) return { 'output': result.content } class Classification(TypedDict): response_format: Literal['story', 'joke', 'poetry'] def llm_call_router(state: State): ''' 使用结构化输出将输入路由到适当的节点 ''' structed_llm = llm.with_structured_output(Classification) input_content = state['input'] response = structed_llm.invoke([ SystemMessage(content=''' 你是一个分类路由,根据用户的输入进行分类,分类结果是story, joke, poetry三者中的一种 '''), HumanMessage(content=input_content) ]) return { 'decision': response['response_format'] } -
定义边并构建图: 利用条件边实现基于决策的分支路由。
python# 定义条件边函数 def route_decision(state: State): if state['decision'] == 'story': return 'llm_story' elif state['decision'] == 'joke': return 'llm_joke' elif state['decision'] == 'poetry': return 'llm_poetry' # 2. 定义边和图 router_builder = StateGraph(State) router_builder.add_node('llm_story', generate_story) router_builder.add_node('llm_joke', generate_joke) router_builder.add_node('llm_poetry', generate_poetry) router_builder.add_node('llm_call_router', llm_call_router) router_builder.add_edge(START, 'llm_call_router') router_builder.add_conditional_edges( 'llm_call_router', route_decision, { 'llm_story': 'llm_story', 'llm_joke': 'llm_joke', 'llm_poetry': 'llm_poetry' } ) router_builder.add_edge('llm_story', END) router_builder.add_edge('llm_joke', END) router_builder.add_edge('llm_poetry', END) workflow = router_builder.compile()- 运行测试: 输入"给我写一个关于苍井空的笑话"。如图所示,路由器成功将请求分类为joke,并将其引导至生成笑话的节点进行处理与输出(不得不说,当前大模型在内容生成上仍趋于保守)。
pythonresult = workflow.invoke({ 'input': '给我写一个关于苍井空的笑话' }) print(result['output'])
四、并行模式
4.1 并行模式概念
并行模式旨在充分利用大模型的能力,同时处理一个任务中不同方面或同一任务的不同变体。与顺序执行的提示链模式不同,并行模式允许多个大模型调用同时进行,最后将各自的输出进行聚合,从而显著提升处理效率。
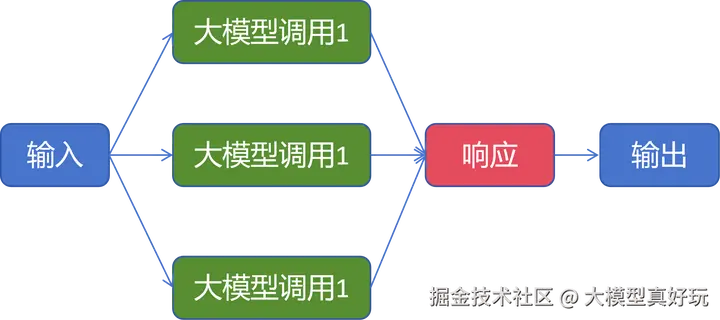
根据任务目标的不同,并行模式的主要聚合方式可分为两类:分段 与 投票 。
- 分段:适用于将一个复杂任务拆分为多个独立的子任务。这些子任务可以并行执行,每个由一个独立的大模型调用处理,最终将结果组合成完整输出。例如,要全面评估一段内容,可以并行调用多个模型,分别评估其事实准确性、逻辑连贯性和文风匹配度,最后聚合这些维度的评分,得到一个综合评估报告。
- 投票:适用于通过共识机制提升结果的准确性。即对同一任务并行执行多次,每次使用略有不同的提示词或配置,然后根据多数输出或某种共识来决定最终结果。例如,在审查一段代码是否存在安全漏洞时,可以用三个并行的模型,分别从"内存安全"、"注入攻击"和"逻辑缺陷"三个角度进行审查。如果其中两个模型都认为存在漏洞,则可以相对可靠地判定该代码有风险。
4.2 并行模式
单纯概念描述不直观,笔者通过一个具体的代码实例来理解。该任务是通过用户输入的主题,生成一个包含故事、笑话和诗歌的合集。
-
引入依赖(同样需要配置好.env文件中的DEEPSEEK_API_KEY):
pythonfrom langchain_deepseek import ChatDeepSeek from langgraph.graph import StateGraph, START, END from dotenv import load_dotenv load_dotenv() llm = ChatDeepSeek( model="deepseek-chat", ) -
定义工作流的状态: 围绕一个主题,并行生成笑话、故事和诗歌,最后聚合为合集。
pythonclass State(TypedDict): topic: str joke: str story: str poetry: str combined_output: str -
定义节点函数: 除了生成笑话、故事、诗歌三个并行执行的节点外,还需要一个聚合节点将三者的输出整合。
pythondef generate_joke(state: State): ''' 生成笑话的节点 ''' topic = state['topic'] msg = llm.invoke(f'写一个关于{topic}的笑话') return { 'joke': msg.content } def generate_story(state: State): ''' 生成故事的节点 ''' topic = state['topic'] msg = llm.invoke(f'写一个关于{topic}的故事') return { 'story': msg.content } def generate_poetry(state: State): ''' 生成诗歌的节点 ''' topic = state['topic'] msg = llm.invoke(f'写一个关于{topic}的诗歌') return { 'poetry': msg.content } def aggregator(state: State): ''' 聚合笑话、故事、诗歌的节点 ''' topic = state['topic'] joke = state['joke'] story = state['story'] poetry = state['poetry'] combined = f'这是一个关于 {topic} 的故事、笑话和诗歌的合集\n\n' combined += f'故事\n {story}\n\n' combined += f'笑话\n {joke}\n\n' combined += f'诗歌\n {poetry}\n\n' return { 'combined_output': combined } -
定义边和图: 注意,这里三个生成节点都从START同时开始,体现了并行性。
pythonparallel_builder = StateGraph(State) parallel_builder.add_node('generate_joke', generate_joke) parallel_builder.add_node('generate_story', generate_story) parallel_builder.add_node('generate_poetry', generate_poetry) parallel_builder.add_node('aggregator', aggregator) parallel_builder.add_edge(START, 'generate_joke') parallel_builder.add_edge(START, 'generate_story') parallel_builder.add_edge(START, 'generate_poetry') parallel_builder.add_edge('generate_joke', 'aggregator') parallel_builder.add_edge('generate_story', 'aggregator') parallel_builder.add_edge('generate_poetry', 'aggregator') parallel_builder.add_edge('aggregator', END) workflow = parallel_builder.compile() -
运行测试: 使用"pgone 与 李小璐"作为主题进行测试,结果如下(deepseek 连这个故事也不能讲嘛)
pythonstate = workflow.invoke({ 'topic': 'pgone 与 李小璐' }) print(state['combined_output'])
以上就是今天的全部内容,完整代码大家可以关注笔者的同名微信公众号 大模型真好玩 ,并私信: LangChain智能体开发免费获取。
五、总结
本文分享了LangGraph智能体开发的设计模式:工作流模式和多智能体模式,同时详细讲解了三种核心工作流模式。提示链模式通过顺序分解任务与门控检查提升准确性;路由模式借助智能分类实现专业化任务分流;并行模式同时处理多个子任务以提升效率。这些模式为构建复杂、可靠的智能体系统提供了可复用的基础架构。当然今天的内容仅仅是开胃小菜,下一期内容笔者将分享更加灵活的设计模式:协调器-工作者模式和评估器-优化器模式,大家敬请期待。
《深入浅出LangChain&LangGraph AI Agent 智能体开发》专栏内容源自笔者在实际学习和工作中对 LangChain 与 LangGraph 的深度使用经验,旨在帮助大家系统性地、高效地掌握 AI Agent 的开发方法,在各大技术平台获得了不少关注与支持。目前已更新34讲,正在更新LangGraph1.0速通指南,并随时补充笔者在实际工作中总结的拓展知识点。如果大家感兴趣,欢迎关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号 大模型真好玩,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。