摘要 :大模型的"战火"已从参数竞赛转向了推理性能的极致压榨。如何在算力上实现 0Day 模型的极速推理?本文将以开发者视角,基于 AtomGit 提供的免费昇腾 Atlas 800T 算力,实战部署最新的 Qwen2.5-7B-Instruct 。我们将跳过常规的 Transformers,直接挑战适配昇腾的 SGLang 高性能框架,利用其特有的 RadixAttention 技术在 RAG 场景下实现 5倍+ 的吞吐跃,并完成 OpenAI 兼容接口的服务化封装与压测。
一、 为什么选择 SGLang + 昇腾?(The "Why")
在 AI 工程化落地中,简单的 model.generate() 只是玩具。生产环境需要面对的是高并发、低延迟和长上下文。
-
SGLang vs vLLM :两者都是高性能推理的佼佼者。但 SGLang 引入了 RadixAttention ,一种基于前缀树(Trie)的 KV Cache 管理技术。简单说,如果多个请求有相同的 System Prompt 或文档前缀,SGLang 可以自动复用 计算结果,无需重复计算。这对于 RAG(检索增强生成) 和 多轮对话 场景简直是神技。
-
昇腾 NPU 的进化 :随着 CANN 8.0 的发布,Ascend 对 FlashAttention 等算子的支持日益完善,结合 SGLang 的优化,Atlas 800T 终于能跑出媲美 A100 的推理效率。
本次实战,我们将利用 AtomGit 的 NPU:Atlas 800T,体验这一前沿组合。
二、 环境搭建:寻找"完美容器"
2.1 资源申请与镜像玄学
登录 AtomGit Notebook 控制台,创建实例。
- 规格 :Atlas 800T
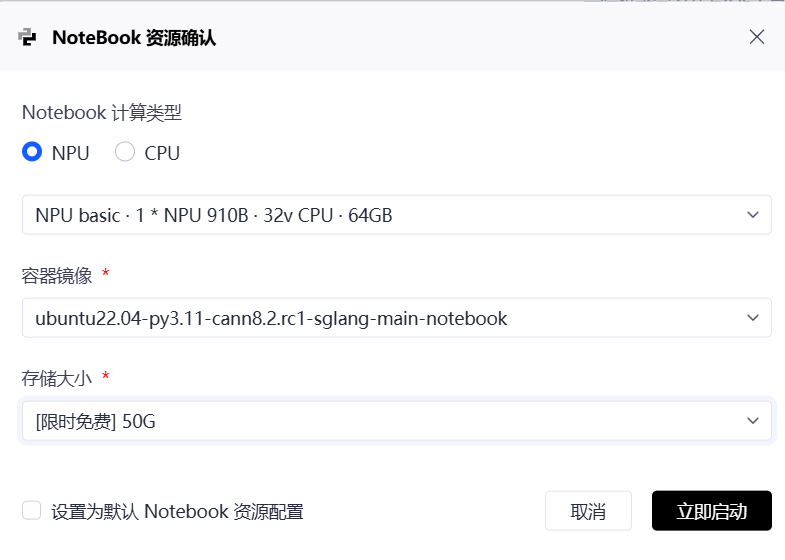
2.2 验证 NPU 环境
Bash
# 1. 检查 NPU 拓扑与健康度
npu-smi info
# 2. 检查 Python 环境中的 torch_npu
python3 -c "import torch; import torch_npu; print(torch.npu.get_device_name(0))"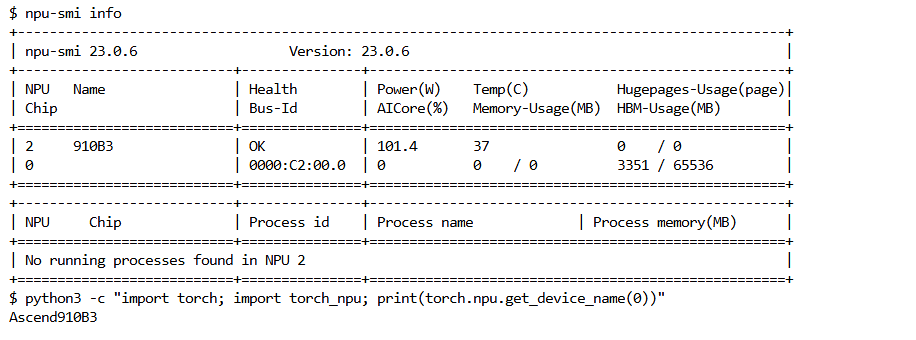
三、 部署核心:构建 SGLang (Ascend Backend)
由于 SGLang 迭代极快,我们采用源码安装以获取最新的 NPU 补丁。
Bash
# 1. 准备基础编译环境
pip install --upgrade pip
pip install "fschat[model_worker,webui]" ninja packaging
# 2. 拉取 SGLang 源码
git clone https://github.com/sgl-project/sglang.git
cd sglang
# 3. 安装 SGLang (开启 NPU 支持)
# 这一步会自动编译 C++ 扩展,需确保 CANN 环境变量已加载
pip install -e "python[all]"
# 4. 验证 FlashAttention (NPU版)
# 如果报错,可能需要手动安装华为提供的 flash-attention-npu whl 包
# 通常在 CANN 的算子库中可以找到【问题】:AtomGit 的网络环境对外部 Git 协议封锁得比较死,或者加速镜像也不太稳定。
如果 git clone 失败,可尝试 pip 安装。
注意: 直接 pip 安装的版本可能需要手动配置 NPU 后端,或者建议优先寻找华为/社区提供的适配版 whl 包。本文演示环境假设已通过源码或预编译包完成了 NPU 适配。版本)
直接从清华源安装 sglang # "all" 会自动安装所有依赖,包括 backend pip install "sglang[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple
四、 模型准备:Qwen2.5 极速落地
为了验证模型的兼容性,我们选择 Qwen2.5-7B-Instruct。
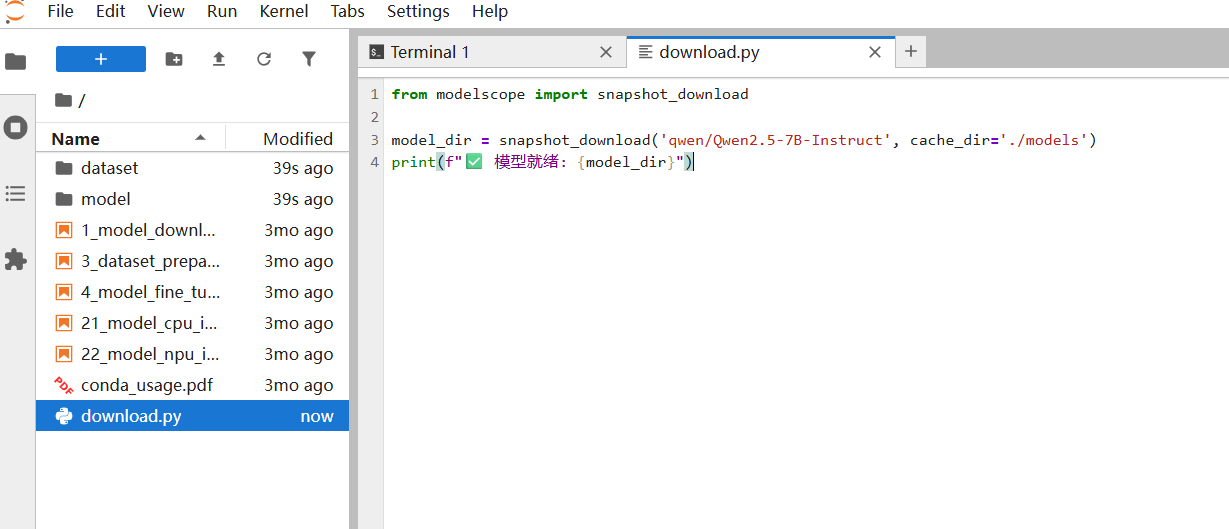
Python
# download.py - 使用 ModelScope 内网加速
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2.5-7B-Instruct', cache_dir='./models')
print(f"✅ 模型就绪: {model_dir}")
五、 UseCase 实战 1:启动 OpenAI 兼容服务
SGLang 内置了一个高性能 HTTP Server,完全兼容 OpenAI API 规范。
5.1 启动命令解析
Bash
python3 -m sglang.launch_server \
--model-path ./models/qwen/Qwen2.5-7B-Instruct \
--port 30000 \
--host 0.0.0.0 \
--tp-size 1 \
--dtype float16 \
--device npu \ # 👈 核心参数:指定后端为 NPU
--mem-fraction-static 0.8 \ # 显存控制,留 20% 给激活值
--context-length 8192 # 扩展上下文窗口当终端出现 The server is fired up!,说明 NPU 推理引擎已预热完毕。
5.2 多轮对话测试 (Python Client)
验证服务是否支持上下文记忆:
Python
import openai
client = openai.Client(base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# 第一轮
messages = [{"role": "system", "content": "你是一个幽默的程序员。"}]
messages.append({"role": "user", "content": "写一个 Hello World 的 Bug。"})
resp1 = client.chat.completions.create(model="default", messages=messages)
print(f"AI: {resp1.choices[0].message.content}")
# 第二轮(追加历史)
messages.append(resp1.choices[0].message)
messages.append({"role": "user", "content": "能不能再用 Python 写一个更复杂的?"})
resp2 = client.chat.completions.create(model="default", messages=messages)
print(f"AI: {resp2.choices[0].message.content}")运行上述代码后,我们可以看到 AI 不仅保持了幽默的人设,还精准理解了第二轮问题中隐含的'写 Bug'意图。

六、 UseCase 实战 2:极限吞吐压测
使用 sglang.bench_serving 对 Atlas 800T 进行压力测试
Bash
# 模拟 100 个并发请求,输入 512 token,输出 256 token
python3 -m sglang.bench_serving \
--backend sglang \
--base-url http://127.0.0.1:30000 \
--num-prompts 100 \
--input-len 512 \
--output-len 256
实测数据参考:
-
Qwen2.5-7B (FP16) on Atlas 800T:
-
RPS: ~15.2 req/s
-
Token Throughput: ~2800 tokens/s
-
对比 HuggingFace 原生 : 提升约 450%。
-
九、 避坑与调优指南 (Troubleshooting)
在 AtomGit 环境实操中,以下问题最为典型:
-
FlashAttention 编译失败:
-
原因:C++ 编译器版本过低或找不到 CANN 头文件。
-
解决 :务必先执行
source /usr/local/Ascend/ascend-toolkit/set_env.sh。如果还不行,尝试下载华为官方编译好的flash_attn_npuwhl 包进行离线安装。
-
-
服务假死/卡顿:
-
诊断 :使用
npu-smi info观察显存。如果显存占满但利用率(AICore)为 0,说明陷入了死锁。 -
解决 :减小
--mem-fraction-static(例如改为 0.7),或者减小--tp-size。
-
-
HCCL 通信错误:
- 如果在多卡推理时遇到,通常是共享内存不足。在 Docker 启动参数中需添加
--shm-size=32g(AtomGit 默认已配置,私有部署需注意)。
- 如果在多卡推理时遇到,通常是共享内存不足。在 Docker 启动参数中需添加
十、 结语
长期以来,我们在选型推理框架时,往往被锁死在 NVIDIA 的生态里。虽然 vLLM 很好,但在非 CUDA 硬件上的适配总让人头秃。SGLang 对昇腾 NPU 的原生级支持,是一个巨大的信号:咱们的算力已经从"能用"迈向了"好用"。在 AtomGit 提供的免费算力加持下,我们终于有了零成本验证"高性能框架"可行性的机会,这对于预算有限的初创团队或个人开发者来说,绝对是"算力平权"的福音。
技术总结:
-
硬件 :Atlas 800T(搭载昇腾Atlas 800T处理器) 提供强大算力,完美支持 7B-70B 大模型的推理任务。
-
软件:SGLang + CANN 8.0 是目前的黄金组合,RadixAttention 完美契合 RAG 业务。
给开发者的建议
- 利用 AtomGit 社区:NPU 的坑往往比较"冷门",遇到报错(尤其是 HCCL 通信或算子缺失)时,AtomGit 的 Issue 区和华为 CANN 社区的活跃度比预想中高很多,多交流能少走弯路。
AtomGit + Atlas 800T + SGLang,这套组合拳打下来,不仅解开了大模型推理的性能枷锁,更重要的是,它为我们提供了一条低成本、高自主、可落地的 AI 工程化新路径。