| 编号 | 底层结构 | 全称 | 主要用途 |
|---|---|---|---|
| 1 | SDS | Simple Dynamic String | 字符串、列表、集合等的基础 |
| 2 | 双向链表 | LinkedList | 列表的实现之一 |
| 3 | 压缩列表 | ZipList | 列表、哈希、有序集合的紧凑存储 |
| 4 | 哈希表 | HashTable | 哈希、集合、全局哈希表 |
| 5 | 跳表 | SkipList | 有序集合的实现 |
| 6 | 整数集合 | IntSet | 小整数集合的紧凑存储 |
| 7 | 快速列表 | QuickList | 列表的现代实现(双向链表+压缩列表) |
| 8 | Stream | Radix Tree | 流数据结构的基数树 |
| 9 | 紧凑链表 | listpack | redis7引入用于替代ziplist |
SDS(简单动态字符串)
cpp
// SDS结构定义(Redis 7.0)
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 已用长度
uint8_t alloc; // 分配的总容量
unsigned char flags;// 类型标记
char buf[]; // 柔性数组,存储字符串
};特性:
O(1)获取字符串长度:因为结构中有len字段,不需要通过遍历去获得长度,空间换时间的办法。
二进制安全(可存\0):SDS是以字节数组的形式存储,支持存储任何的二进制数据。
自动扩容,避免缓冲区溢出:下面这个是扩容的规则,也是空间换时间的办法,不需要频繁的阔缩容,但是扩容有几种情况,一种是当前分配的内存块后续还有可以分配的空间,那么就直接分配了,只需要移动变量的结尾指针,就实现了扩容,如果不够了为了内存的连续,会找一个满足条件的内存块进行重新分配,然后把旧内存的内容复制到新内存,然后再释放旧内存,这个其实是最常见的,java的list就是这么干的。最后一种就是扩容失败了,因为没内存可以分配了。
cpp
// 扩容规则:
1. 如果新长度 < 1MB: 新容量 = 新长度 * 2
2. 如果新长度 ≥ 1MB: 新容量 = 新长度 + 1MB
3. 最大预分配空间 = 1MB
// 示例:
原始: len=5, alloc=8
追加3字节: len=8 ≤ alloc=8,不扩容
追加5字节: 新len=13,需要扩容
新alloc = 13 * 2 = 26空间预分配和惰性释放:空间预分配其实就是上面的扩容规则,新的变量分配内存的时候会多分配一些,惰性释放是指就是变量的内容减速了,也不会立刻重新分配内存,比如开始A的内存大小是10,存了ABC,后面通过修改命令,A值存了AB,那么这个时候的大小还是10,是不会重新分配的,只有等到这个变量所属的key过期,或者执行了del命令才会被释放。
使用场景:
| 数据类型 | 是否使用SDS | SDS用途 | 重要性 | 备注 |
|---|---|---|---|---|
| String | ✅直接使用 | 值存储 | ⭐⭐⭐⭐⭐ | SDS就是String的实现 |
| List | ✅间接使用 | 元素存储 | ⭐⭐⭐⭐ | 元素用SDS存储 |
| Hash | ✅间接使用 | 字段名和值存储 | ⭐⭐⭐⭐ | field和value都用SDS |
| Set | ✅间接使用 | 元素存储 | ⭐⭐⭐⭐ | 集合元素用SDS存储 |
| ZSet | ✅间接使用 | 成员和分值存储 | ⭐⭐⭐⭐ | member用SDS,score用double |
| BitMap | ✅基于String | 底层存储 | ⭐⭐⭐⭐ | 复用String的SDS |
| HyperLogLog | ✅基于String | 底层存储 | ⭐⭐⭐ | 复用String的SDS |
| Geospatial | ✅基于ZSet | 成员存储 | ⭐⭐⭐ | 通过ZSet间接使用 |
| Bitfield | ✅基于String | 底层存储 | ⭐⭐⭐ | 复用String的SDS |
| Stream | ✅间接使用 | 消息内容存储 | ⭐⭐⭐⭐ | 字段名和值用SDS |
sds是用处最广泛的,所以的类型的key其实都是sds进行存储的,因为sds成就了String类型,string类型成就了其他类型。
LinkedList(双向链表)
cpp
// 链表节点
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
// 链表结构
typedef struct list {
listNode *head;
listNode *tail;
unsigned long len;
// ... 其他函数指针
} list;这个结构就不啰嗦了,学过数据结构的都知道,就是一个链表,每个节点都有前一个和后一个节点都指针,范围查找、二分查找等都更加友好,相对于普通的单向列表来说,如果是循环链表那么链表的头尾节点都是一个指针地址。
Redis双向链表(LinkedList)现在已不被任何数据类型作为主要底层结构,但被QuickList内部使用,并且仍在Redis内部机制中广泛使用,在redis3.3之后就没有了哦。在之前是list的底层结构。
ZipList(压缩链表)
这个结构的产生其实是和LinkedList有关的,我们刚刚看到双向链表的没个节点都会存前后节点的指针,这样其实太浪费内存了,把大部分的内存全浪费在存节点上面了,所以就有了Ziplist,那他是怎么压缩的呢?
cpp
// ZipList内存布局
[zlbytes][zltail][zllen][entry1][entry2]...[entryN][zlend]
// 总长度: 4 + 4 + 2 + entries + 1 = 11 + entries 字节
// 字段说明:
// zlbytes: uint32_t, 整个ZipList占用的字节数
// zltail: uint32_t, 到尾节点的偏移量(便于尾部操作)
// zllen: uint16_t, 节点数量(当<65535时准确)
// zlend: uint8_t, 结束标记(0xFF)这个是Zipliste的内部布局,他相对于linkedlistt最大的区别就是整个内存是连续的,而linkedlist内存是分散的,没插入一个节点都会重新分配一个不连续的空间,这样会导致空间碎片话,当然自动扩容的机制是和SDS是一样的。
cpp
// 每个entry的结构
[prevlen][encoding][content]
// 1. prevlen: 前一个节点的长度
// - 如果前节点长度 < 254字节: 用1字节存储
// - 如果前节点长度 >= 254字节: 用5字节存储
// 第1字节固定0xFE(254),后4字节存储实际长度
// 2. encoding: 编码,标识content的类型和长度
// - 分字符串和整数两种编码
// 3. content: 实际数据这个是每个节点的结构,通过prevlen就可以算出上一个节点的指针偏移量,实现了双向链表的功能而且节约了内存(在一个节点因为内存的连续所以也容易找到)。
但是他也被quicklist给替代了,现在的版本之作为quicklist的底层被使用,在redis3.2之前他曾作为List类型的小列表实现、Hash类型的小哈希实现 、ZSet类型的小有序集合实现。
QuickList(快速链表)
我们先来说说为什么会取代双向链表和压缩链表,首先是双向链表,就是大部分空间都去记录前后指针了,导致内存利用率低而成造成内存碎片化,再来说压缩链表,其实就是成也萧何,败也萧何,就是连续内存导致的,中间插入、删除修改,都会产生连锁反应,就说插入、删除需要节点挪位置,不然就不能实现双向链表的功能,再说修改,减少和增大一个节点的大小都会对后续的节点产生影响也需要挪位置。所以他们才会被替代。
cpp
// QuickList = 双向链表 + 压缩块(ListPack)
// 每个节点是一个压缩块,存储多个元素
typedef struct quicklist {
quicklistNode *head; // 头节点指针
quicklistNode *tail; // 尾节点指针
unsigned long count; // 所有元素总数
unsigned long len; // quicklist节点数
int fill : 16; // 每个节点的填充因子
unsigned int compress : 16; // 压缩深度,0表示不压缩
} quicklist;
#节点结构
typedef struct quicklistNode {
struct quicklistNode *prev; // 前驱节点
struct quicklistNode *next; // 后继节点
unsigned char *zl; // 指向ziplist
unsigned int sz; // ziplist大小(字节)
unsigned int count : 16; // ziplist中元素个数
unsigned int encoding : 2; // 编码:RAW=1, LZF=2
unsigned int container : 2; // 容器:NONE=1, ziplist=2
unsigned int recompress : 1; // 是否被压缩
unsigned int attempted_compress : 1; // 测试用
unsigned int extra : 10; // 预留
} quicklistNode;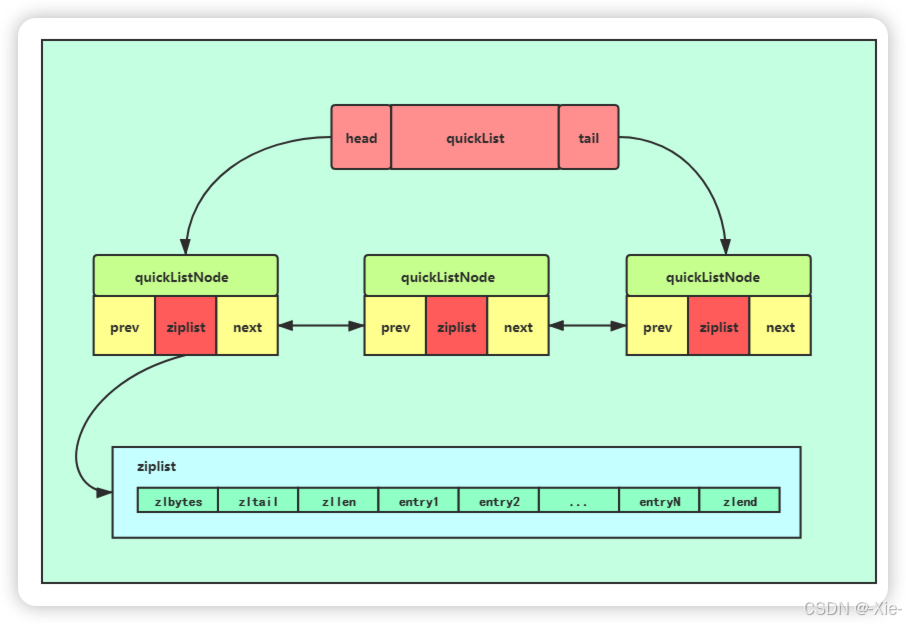
其实从这个图我们就能知道这个快速链表到底是个什么玩意了,他的本质其实是双向链表,节点结合了压缩链表,不在向之前一个节点只存一个元素,而是存多个元素通过节点因子来控制,这样既不会产生过多太小的内存碎片,也减少了压缩链表联级更新的问题,因为连续的内存块小了,联级更新的范围就小了就不会产生太大的性能压力,完美的结合了两个链表的优点,规避了各种的缺点。这个文章写的很不错哦,图片就是从这里拷贝的。https://www.cnblogs.com/hunternet/p/12624691.html
那说了这么多到底谁使用它作为底层结构呢?答案是list,没错就是list,没有sds那么开枝散叶,再说了别人都带了一个list,你说是谁的底层呢?
总结
本篇主要介绍了sds、linkedlist、ziplist、quicklist,其他的下回分解吧。