文章目录
- 1.核心概念
- 2.与LangChain区别
- 3.如何搭建
- 4.案列
-
- 1.as_query_engine
- 2.as_chat_engine
- 3.rag检索增强
- [Settings.embed_model 和 Settings.llm 的调用机制](#Settings.embed_model 和 Settings.llm 的调用机制)
-
- [1. **全局配置作用**](#1. 全局配置作用)
- [2. **调用时机**](#2. 调用时机)
- [3. **隐式使用机制**](#3. 隐式使用机制)
- [4. **框架集成**](#4. 框架集成)
LlamaIndex(之前叫 GPT Index)是一个专门为 LLM 应用程序 设计的数据框架,主要解决 数据摄取、索引和查询 的问题。它让你能够轻松地将私有数据或领域特定数据与大语言模型(如 GPT-4、Llama 等)结合使用。
1.核心概念
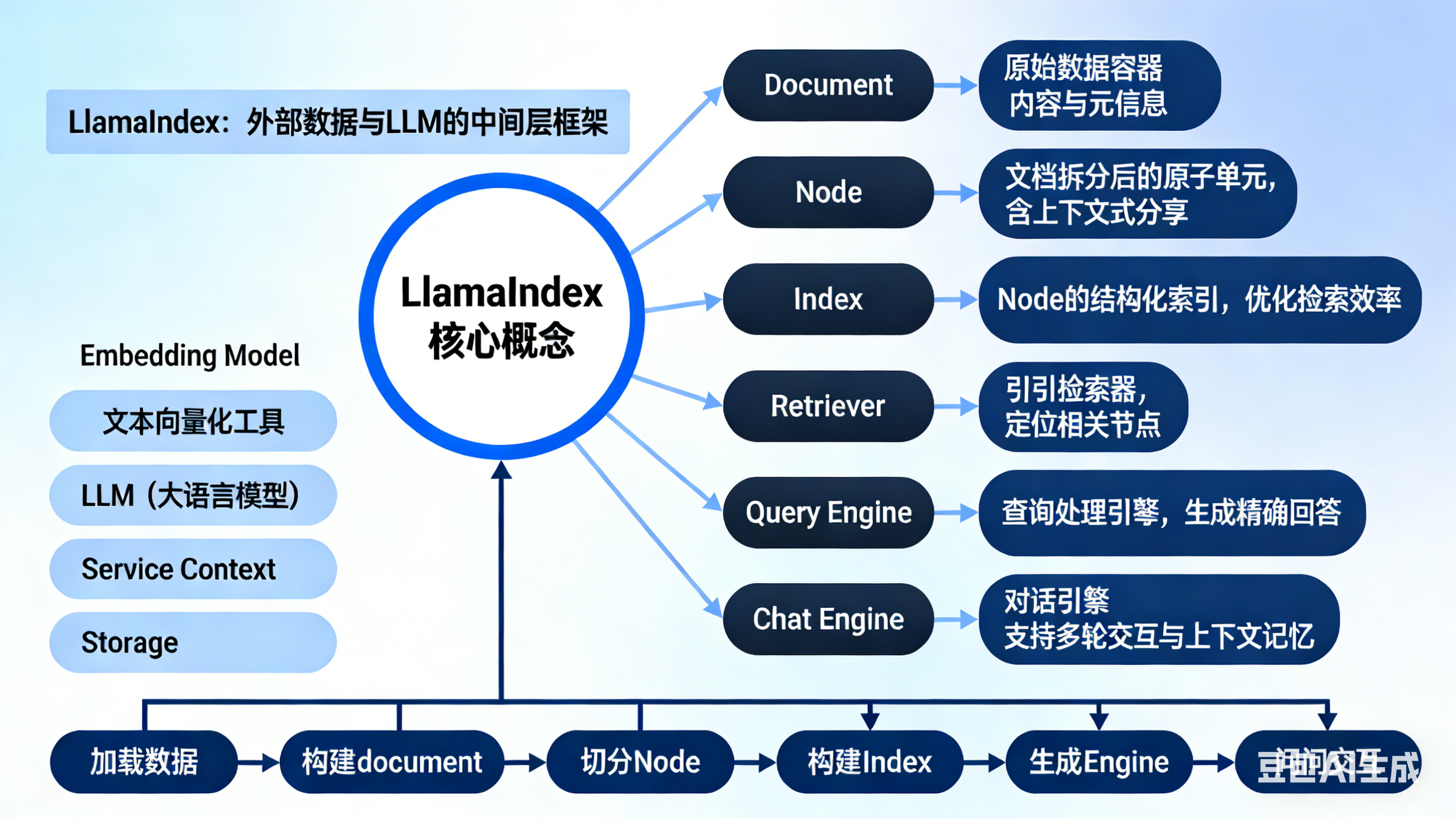
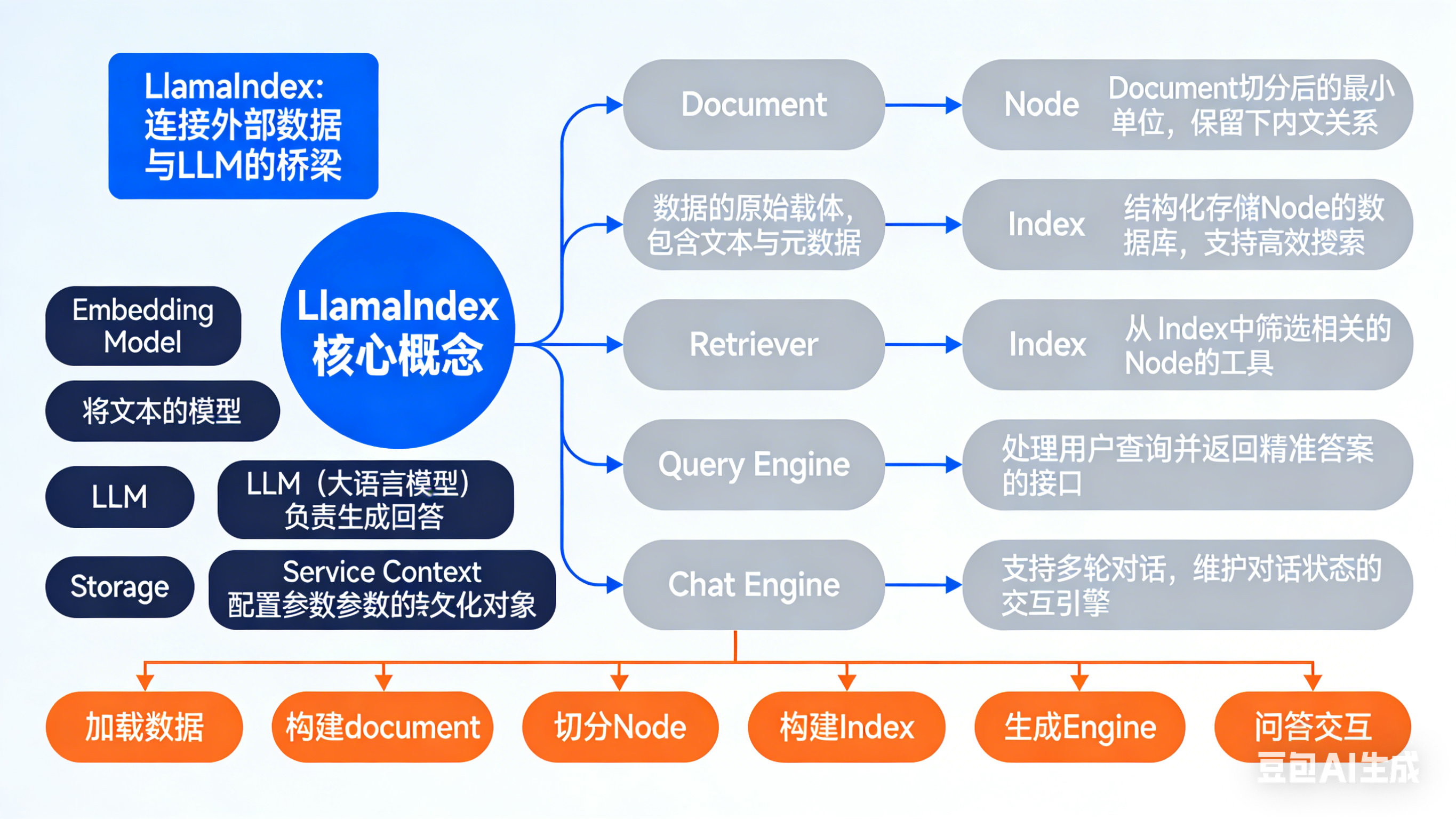
LlamaIndex 核心概念
├─ 基础定位 :LLM 数据增强框架(衔接私有数据与大模型)
├─ 六大核心基础概念(数据流转顺序)
│ ├─ Document:原始数据载体(数据入口)
│ ├─ Node:最小处理单元(文档切分产物)
│ ├─ Index:结构化检索库(核心数据组织形式)
│ ├─ Retriever:检索器(索引与引擎的桥梁)
│ ├─ Query Engine:单轮问答接口(核心交互入口)
│ └─ Chat Engine:多轮对话接口(上下文记忆)
├─ 四大进阶核心概念(能力扩展)
│ ├─ Embedding Model:文本转向量(相似度检索基础)
│ ├─ LLM:大模型(答案生成核心)
│ ├─ Service Context:全局配置中心
│ └─ Storage:数据持久化存储
└─ 核心流程 :加载数据→构建Document→切分Node→构建Index→生成Engine→问答交互
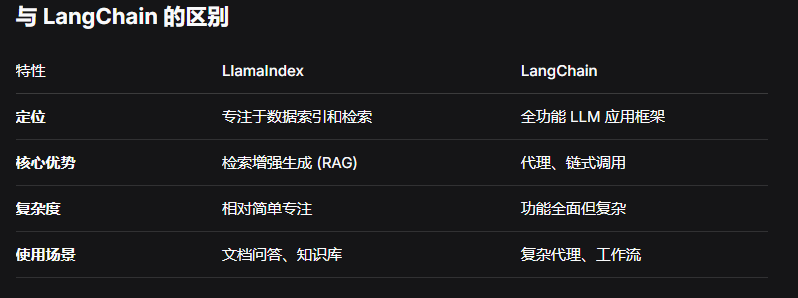
2.与LangChain区别
3.如何搭建
python
# 安装环境
conda create -n llama-index python=3.10
conda activate llama-index
pip install chromadb
#如果官网下载速度比较慢,可以使用阿里云镜像源
pip install chromadb -i https://mirrors.aliyun.com/pypi/simple
pip install llama-index
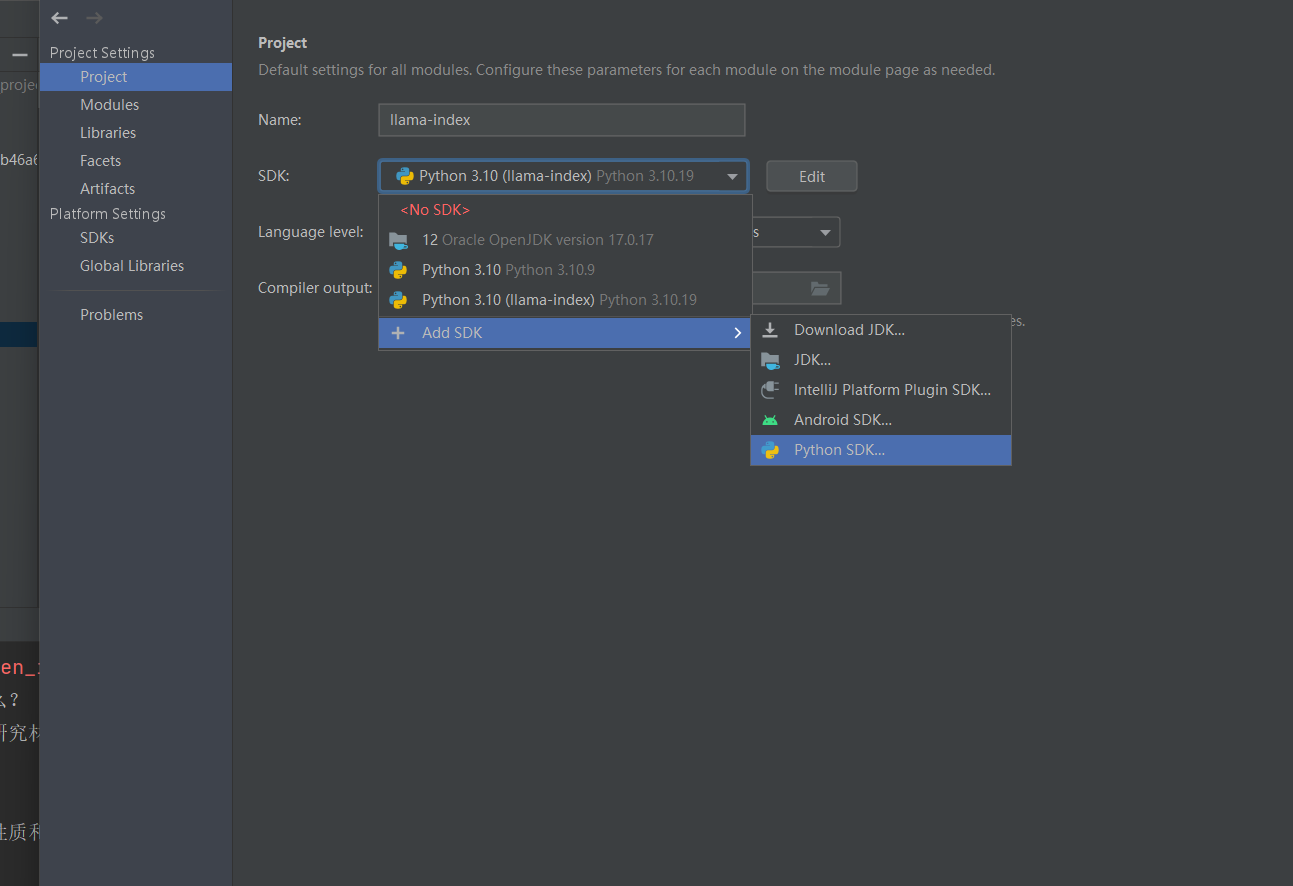
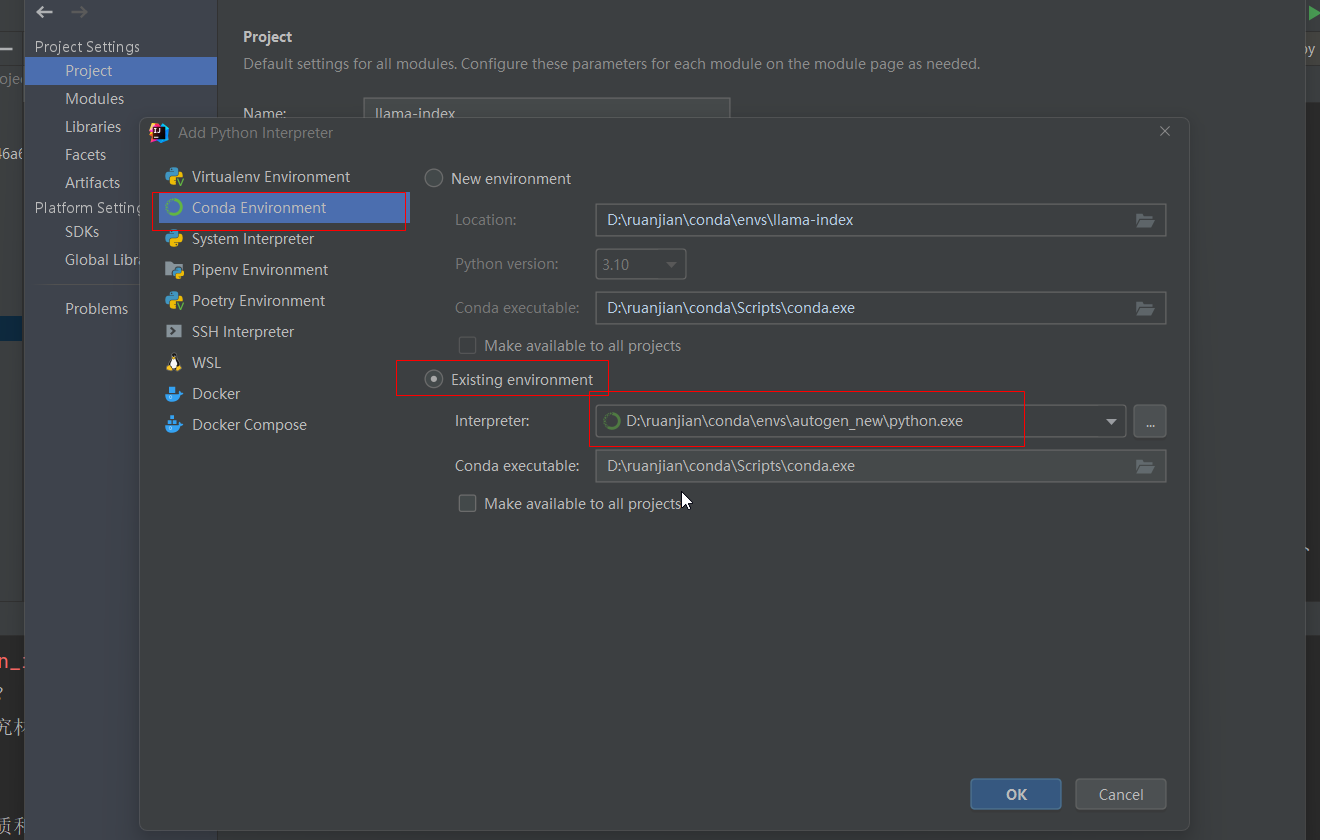
在idea中切换python环境
4.案列
LlamaIndex框架适用于openAI较多,所以当时这个代码改了很多次
本地建Chroma向量数据库
1.as_query_engine
python
import chromadb
# 替换为你的阿里云DashScope API-KEY
DASHSCOPE_API_KEY = "sk-秘钥"
# -------------------------- ✅ 核心库导入 --------------------------
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, StorageContext, Settings
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.llms.dashscope import DashScope
# ✅ 关键1:导入Chroma专属异常类(必须加)
from chromadb.errors import NotFoundError
# -------------------------- ✅ 1. 配置通义嵌入模型 --------------------------
Settings.embed_model = DashScopeEmbedding(
model_name="text-embedding-v1",
api_key=DASHSCOPE_API_KEY,
show_progress=True
)
# -------------------------- ✅ 2. 配置通义大模型LLM --------------------------
Settings.llm = DashScope(
model_name="qwen-turbo",
api_key=DASHSCOPE_API_KEY,
temperature=0.1,
max_tokens=2048
)
# -------------------------- ✅ 3. Chroma向量库初始化(核心修复) --------------------------
# 初始化Chroma持久化客户端,指定本地存储路径
chroma_client = chromadb.PersistentClient(path="./chroma_robot_db")
# ✅ 关键2:精准捕获 Chroma 专属的 NotFoundError
try:
chroma_collection = chroma_client.get_collection("quickstart")
print("✅ 成功加载已存在的集合:quickstart")
except NotFoundError: # 替换原有的 ValueError,精准拦截「集合不存在」
chroma_collection = chroma_client.create_collection("quickstart")
print("✅ 集合不存在,已自动新建:quickstart")
# 绑定向量存储
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# -------------------------- ✅ 4. 文档加载 + 索引构建 + 查询 --------------------------
documents = SimpleDirectoryReader("./data").load_data()
print(f"📄 成功加载 {len(documents)} 个文档片段")
# 智能构建/加载索引
if documents:
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
else:
index = VectorStoreIndex.from_vector_store(vector_store)
# 执行查询
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("人形机器人包含了那些行业,请用中文答复")
# 格式化输出
print("\n" + "="*80)
print("🎯 查询问题:人形机器人,请用中文答复")
print("💡 答复结果:\n", response)
print("="*80)结果就是RAG后,会读取data里面的内容
2.as_chat_engine
python
# `as_query_engine` 和 `as_chat_engine` 的区别
## 1. **功能定位**
- `as_query_engine`: 用于构建**问答引擎**,专门处理基于检索的问答任务
- `as_chat_engine`: 用于构建**对话引擎**,支持连续的多轮对话交互
## 2. **使用场景**
- `as_query_engine`: 适用于单次查询场景,如文档检索、知识库问答
- `as_chat_engine`: 适用于需要上下文记忆的对话场景,如聊天机器人
## 3. **返回内容**
- `as_query_engine`: 返回与查询最相关的文档片段和答案
- `as_chat_engine`: 维护对话历史,支持上下文连贯的多轮交互
## 4. **参数配置**
- `as_query_engine`: 主要配置 `similarity_top_k` 等检索参数
- `as_chat_engine`: 支持 `chat_mode` 等对话模式参数,如 `ChatMode.CONTEXT`、`ChatMode.CONDENSE_QUESTION` 等
## 5. **调用方式**
- `as_query_engine`: 通常用于一次性查询,每次调用独立处理
- `as_chat_engine`: 保持会话状态,支持连续的对话交互
python
import chromadb
# 替换为你的阿里云DashScope API-KEY
DASHSCOPE_API_KEY = "sk-秘钥"
# -------------------------- ✅ 核心库导入 --------------------------
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, StorageContext, Settings
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.llms.dashscope import DashScope
# ✅ 关键1:导入Chroma专属异常类(必须加)
from chromadb.errors import NotFoundError
# -------------------------- ✅ 1. 配置通义嵌入模型 --------------------------
Settings.embed_model = DashScopeEmbedding(
model_name="text-embedding-v1",
api_key=DASHSCOPE_API_KEY,
show_progress=True
)
# -------------------------- ✅ 2. 配置通义大模型LLM --------------------------
Settings.llm = DashScope(
model_name="qwen-turbo",
api_key=DASHSCOPE_API_KEY,
temperature=0.1,
max_tokens=2048
)
# -------------------------- ✅ 3. Chroma向量库初始化(核心修复) --------------------------
# 初始化Chroma持久化客户端,指定本地存储路径
chroma_client = chromadb.PersistentClient(path="./chroma_robot_db")
# ✅ 关键2:精准捕获 Chroma 专属的 NotFoundError
try:
chroma_collection = chroma_client.get_collection("quickstart")
print("✅ 成功加载已存在的集合:quickstart")
except NotFoundError: # 替换原有的 ValueError,精准拦截「集合不存在」
chroma_collection = chroma_client.create_collection("quickstart")
print("✅ 集合不存在,已自动新建:quickstart")
# 绑定向量存储
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# -------------------------- ✅ 4. 文档加载 + 索引构建 + 查询 --------------------------
documents = SimpleDirectoryReader("./data").load_data()
print(f"📄 成功加载 {len(documents)} 个文档片段")
# 智能构建/加载索引
if documents:
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
else:
index = VectorStoreIndex.from_vector_store(vector_store)
# 执行查询
chat = index.as_chat_engine(similarity_top_k=5)
response = chat.chat("人形机器人包含了那些行业,请用中文答复")
# 格式化输出
print("\n" + "="*80)
print("🎯 查询问题:人形机器人,请用中文答复")
print("💡 答复结果:\n", response)
print("="*80)3.rag检索增强
从魔搭社区下载本地deepseek模型,魔搭如何使用看之前文章魔搭
下载最小的1.5b模型,3.2G
python
# 模型下载
from llama_index.core.base.llms.types import ChatMessage
#pip install modelscope -i https://mirrors.aliyun.com/pypi/simple
from modelscope import snapshot_download
##首次会下载,后面就会读取本地
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B')
from llama_index.llms.huggingface import HuggingFaceLLM
# 使用HuggingFaceLLM加载本地大模型
llm = HuggingFaceLLM(model_name='D:\langChain\modelscope\models\models\deepseek-ai\DeepSeek-R1-Distill-Qwen-1___5B',
tokenizer_name='D:\langChain\modelscope\models\models\deepseek-ai\DeepSeek-R1-Distill-Qwen-1___5B',
model_kwargs={"trust_remote_code": True},
tokenizer_kwargs={"trust_remote_code": True})
# trust_remote_code=True:允许模型和分词器加载来自远程仓库的自定义代码。具体来说:
# 对于 model_kwargs,它使得模型可以信任并执行远程代码,例如自定义的前向传播逻辑或特殊的初始化方法。
# 对于 tokenizer_kwargs,它使得分词器可以信任并执行远程代码,例如自定义的分词规则或预处理逻辑。
# 这两个参数通常用于加载那些不仅仅是权重文件,还包含自定义实现的模型和分词器。确保设置为 True 可以使这些自定义实现生效,但出错。
# 调用模型chat引擎得到回复
rsp = llm.chat(messages=[ChatMessage(content="你叫什么名字?")])
print(rsp)
python
# 模型下载
from llama_index.core.base.llms.types import ChatMessage
#pip install modelscope -i https://mirrors.aliyun.com/pypi/simple
from modelscope import snapshot_download
#model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B')
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, StorageContext, Settings
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.embeddings.dashscope import DashScopeEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
DASHSCOPE_API_KEY = "sk-秘钥"
# -------------------------- ✅ 1. 配置通义嵌入模型 --------------------------
Settings.embed_model = DashScopeEmbedding(
model_name="text-embedding-v1",
api_key=DASHSCOPE_API_KEY,
show_progress=True
)
# 使用HuggingFaceLLM加载本地大模型
Settings.llm = HuggingFaceLLM(model_name='D:\langChain\modelscope\models\models\deepseek-ai\DeepSeek-R1-Distill-Qwen-1___5B',
tokenizer_name='D:\langChain\modelscope\models\models\deepseek-ai\DeepSeek-R1-Distill-Qwen-1___5B',
model_kwargs={"trust_remote_code": True},
tokenizer_kwargs={"trust_remote_code": True})
# trust_remote_code=True:允许模型和分词器加载来自远程仓库的自定义代码。具体来说:
# 对于 model_kwargs,它使得模型可以信任并执行远程代码,例如自定义的前向传播逻辑或特殊的初始化方法。
# 对于 tokenizer_kwargs,它使得分词器可以信任并执行远程代码,例如自定义的分词规则或预处理逻辑。
# 这两个参数通常用于加载那些不仅仅是权重文件,还包含自定义实现的模型和分词器。确保设置为 True 可以使这些自定义实现生效,但出错。
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
rsp = query_engine.query("材料科学是什么")
print(rsp)Settings.embed_model 和 Settings.llm 的调用机制
1. 全局配置作用
Settings.embed_model和Settings.llm是全局配置对象- 在框架内部被自动引用,无需显式传递
2. 调用时机
Settings.embed_model: 在VectorStoreIndex.from_documents()时自动使用- 用于将文档转换为向量表示
Settings.llm: 在as_query_engine()创建查询引擎时自动使用- 用于处理查询和生成回答
3. 隐式使用机制
VectorStoreIndex.from_documents()内部会检查Settings.embed_modelas_query_engine()方法内部会使用Settings.llm创建查询处理逻辑- 通过全局状态管理,避免了在每个方法调用时重复传递模型实例
4. 框架集成
- llama-index 框架设计为使用全局
Settings对象 - 所有相关组件都会自动从全局配置中获取模型实例
- 这种设计简化了 API 使用,避免了冗余的参数传递