清晨准备早餐时,我们总会下意识地完成一串"思考-行动"的联动:想做煎蛋便先开火预热,发现油壶空了就去厨房储物柜取用,煎至金黄后关火装盘。这个看似寻常的认知过程,恰恰暗藏着AI领域追逐多年的智能密码,真正的解决问题能力,从来不是单一的"思考"或孤立的"行动",而是两者的动态协同。2022年,姚顺雨团队提出的ReAct范式,正是首次将这种人类认知逻辑系统性植入大语言模型,打破了LLM仅作为"知识库"或"聊天机器人"的局限,开启了其向主动感知、规划决策的Agent形态演进的大门。如今重读这篇被奉为"LLM Agent开山之作"的论文,不仅能明晰其核心创新,更能在当下Agent爆发的浪潮中,找到技术落地的底层逻辑与破局思路。
在ReAct出现之前,大语言模型的应用始终深陷两大割裂的赛道,难以突破复杂任务的瓶颈。一边是聚焦"推理"的阵营,以思维链(CoT)为代表,让模型依托内部知识库进行多步逻辑推演。这种模式在数学计算、简单问答等任务中表现亮眼,但本质上是一种静态的黑盒过程,最大的弊端的是极易产生"幻觉",比如询问"2025年美国总统是谁",训练数据截止到某一时间点的模型可能会给出过时答案,因为它无法获取外部实时信息,只能依赖参数记忆进行臆测。更严重的是,即便推理过程漏洞百出,模型也会自圆其说,导致错误答案极具迷惑性。
另一边则是侧重"行动"的阵营,常见于强化学习(RL)或WebGPT等场景,模型根据环境观察直接输出动作指令,通过API与外部工具交互。这种模式解决了实时信息获取的问题,但缺乏高层语义规划,如同没有导航的旅人,容易在复杂任务中迷失方向。比如在模拟购物网站WebShop中,若用户需求是"买一款适合户外的手机保护套",纯行动模式的模型可能会直接罗列所有保护套商品,却无法提炼"户外所需的耐用、防水材质"这一核心需求,最终陷入无效浏览的死循环。
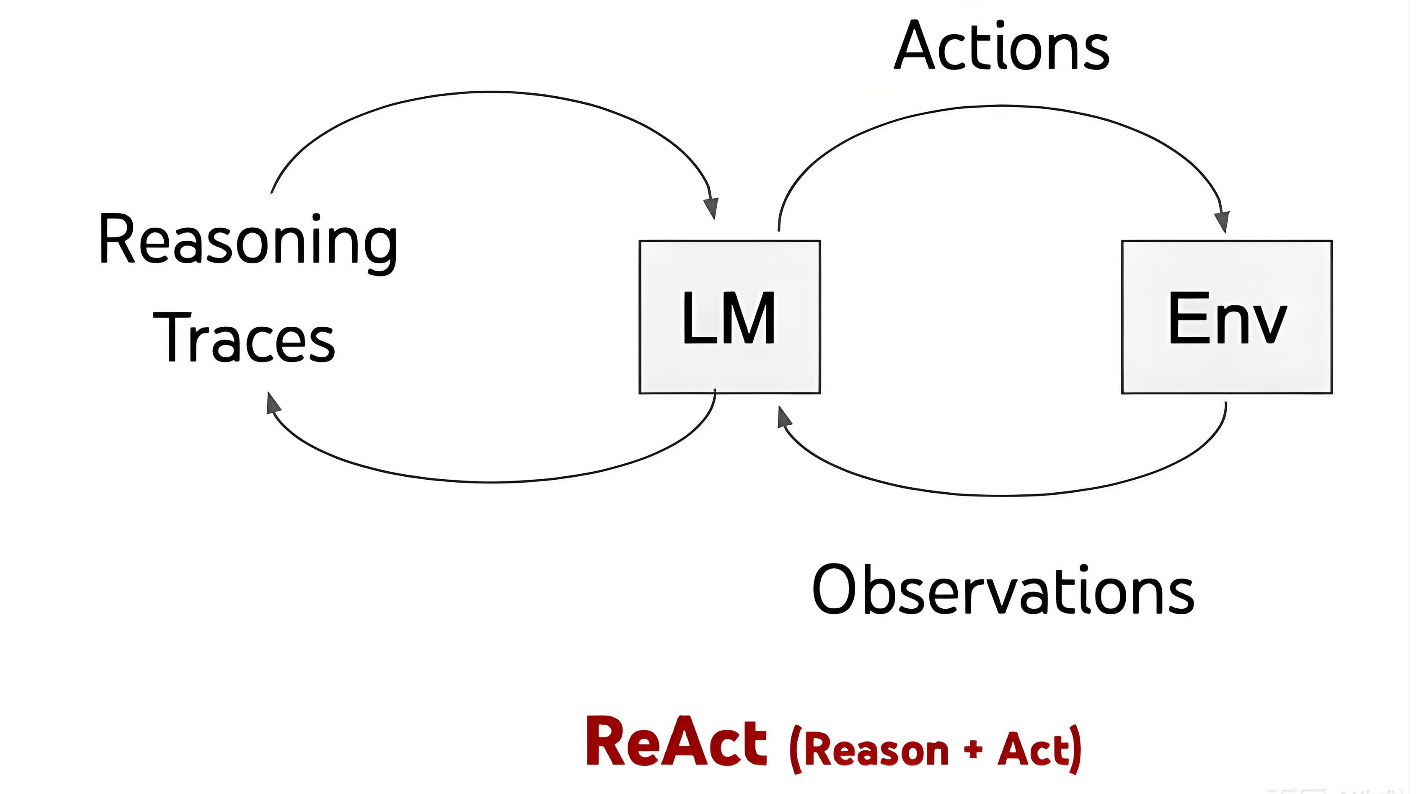
ReAct的核心突破,正是看到了这两大赛道的短板,提出了"推理与行动协同"的全新范式。它借鉴人类"思考-行动-观察-再思考"的认知闭环,将模型的动作空间扩充为两部分:一部分是"Thought(思考)",作为内部动作不影响外部环境,却能更新上下文,帮助模型整理思路、分解目标、提取关键信息;另一部分是"Action(行动)",作为外部动作与环境交互,执行后会获取新的观察结果(Observation),反哺后续思考。这种"Thought-Action-Observation"的交替循环,让LLM不再是孤立的"空想家"或盲目的"执行者",而是具备规划能力与环境适配性的智能Agent。
从形式化定义来看,ReAct将Agent与环境的交互过程进行了清晰拆解。在每个时间步,Agent接收环境观察,结合当前上下文采取行动。传统策略仅学习"观察到行动"的映射,而ReAct则通过引入Thought,构建了"观察-思考-行动-新观察"的闭环映射。其中Thought的作用至关重要,它既是行动的"导航仪",也是异常的"处理器",比如在家庭模拟游戏ALFWorld中,当模型拿到钥匙时,Thought会明确"下一步需要寻找锁的位置";若尝试开门失败,Thought又会调整为"检查钥匙是否匹配,或是否找对了房门",这种动态调整能力,正是纯行动模式所缺失的。
在具体实现上,ReAct采用了少样本提示(Few-shot Prompting)的方式,基于冻结参数的大模型(论文中主要使用PaLM-540B,对比实验采用GPT-3)完成任务。Prompt的构建逻辑十分直观,即嵌入若干人类编写的完整"Thought-Action-Observation"轨迹示例,让模型通过模仿学会协同范式。值得注意的是,ReAct并非僵化要求"每一步都必须包含Thought",而是根据任务类型灵活调整:对于知识密集型任务如多跳问答,采用"Thought-Action-Observation"的严格交替结构,确保推理的严谨性;对于决策密集型任务如游戏闯关,则允许模型自主决定Thought的生成时机,实现稀疏推理,避免冗余思考消耗上下文窗口。
论文中的一系列实验,充分验证了ReAct范式的优越性,也揭示了其与传统模式的核心差异。在知识密集型任务中,研究团队选取HotpotQA(多跳问答)和FEVER(事实验证)两大数据集,允许模型调用Wikipedia API(支持搜索、查询、结束三个动作),对比标准提示(Standard)、思维链(CoT)、纯行动(Act-only)与ReAct四种模式的表现。结果显示,CoT的主要失败模式是事实幻觉,由于无法访问外部数据,其回答的准确率高度依赖内部记忆;Act-only则因缺乏推理指导,频繁出现无效搜索;而ReAct虽能有效规避幻觉,但偶尔会因结构约束打断推理流畅性,出现推理错误。
为了弥补这一短板,论文提出了ReAct与CoT-SC(自我一致性)结合的混合策略,充分发挥两者优势:要么先尝试ReAct,若未找到答案则退回到自我一致性验证;要么先通过CoT-SC生成多个答案,若答案分歧较大则启用ReAct进行事实查证。这种组合策略最终在两大数据集上均取得最佳性能,证明了"推理指导行动,行动验证推理"的协同价值,ReAct负责确保事实准确性,CoT负责保障逻辑连贯性,两者互补形成闭环。
在决策制定任务中,ReAct的表现更是远超传统模式。在ALFWorld文本模拟家庭环境中,任务要求模型完成"关闭客厅所有灯"等指令,ReAct的成功率达到71%,而Act-only仅为45%。深入分析发现,Act-only模型在长时间跨度任务中极易忘记子目标,比如打开衣柜后就忘记要找衣服,或操作失败后陷入重复尝试的死循环;而ReAct通过Thought显式记录状态,始终锚定核心目标,即便出现小失误也能快速修正。在WebShop模拟购物任务中,ReAct更是展现出强大的需求拆解能力,面对"适合户外的保护套"这类模糊指令,能通过Thought提炼出"耐用、防水"等关键属性,再通过搜索动作筛选商品,精准匹配用户需求。
除了零样本提示的表现,论文还探索了ReAct在微调场景下的潜力。研究发现,ReAct范式在大模型(540B参数)上效果显著,但在小模型(8B/62B参数)上难以通过提示实现有效迁移;而若使用ReAct生成的成功轨迹(包含完整Thought-Action-Observation)微调小模型,其效果会显著优于微调后的CoT或Standard模式。这一结论极具实操价值:微调CoT本质上是让模型"背诵"知识,不仅容易过时,还会加剧幻觉问题;而微调ReAct是在教模型"如何寻找信息、如何推理决策"的通用能力,这种能力具备更强的泛化性,即便面对未见过的任务,也能通过协同范式逐步拆解解决。
如今重读ReAct,我们不仅能看到其技术创新,更能深刻理解其有效的底层逻辑。首先是"协同效应(Synergy)",推理与行动的动态联动形成了双向赋能:Thought为Action指明方向,减少无效搜索和盲目操作;Action为Thought提供实时反馈,将推理锚定在客观事实之上,避免陷入空想。这种联动让LLM摆脱了"纸上谈兵"的困境,真正具备了落地解决问题的能力。其次是"可解释性(Interpretability)",Thought的显式生成让模型的决策过程不再是黑盒,我们能通过Thought清晰知晓模型为何执行某个动作、为何调整策略,这种可解释性不仅便于问题排查,更能提升用户信任度。
更具突破性的是ReAct带来的"可控性(Controllability)",论文中的Human-in-the-loop实验充分证明了这一点:当Agent在任务中走偏时,人类无需调整模型参数或重写大量Prompt,只需修改其中一句关键Thought,Agent就能根据修正后的思路调整后续Action,快速回归正确轨道。这种轻量化的控制方式,极大降低了Agent的落地成本,让非技术人员也能参与到Agent的优化过程中,为后续人机协同Agent的发展奠定了基础。
当然,ReAct并非完美无缺,其局限性也为后续研究指明了方向。首先是上下文长度限制,ReAct生成的Thought和Observation会持续占用上下文窗口,在长时间跨度任务中,容易因窗口溢出导致历史信息丢失,影响推理连贯性。这一问题在当下虽有大上下文模型(如GPT-4 Turbo的128k上下文)缓解,但如何轻量化Thought、优化上下文管理,仍是Agent落地的关键挑战。其次是推理错误问题,相比于纯CoT,ReAct的结构约束会在一定程度上限制推理灵活性,偶尔会陷入"搜索-无果-重复搜索"的死循环,如何让模型在协同范式中保持推理的流畅性与创新性,仍需进一步探索。
最后是对Prompt质量的高度依赖,ReAct的少样本提示需要高质量的轨迹示例,若示例存在逻辑漏洞或动作偏差,模型会直接模仿错误模式,导致任务失败。这一局限性也推动了后续研究的发展,比如自动生成高质量轨迹、Prompt自适应优化等方向,都是为了降低ReAct范式的落地门槛。
作为LLM Agent的开山之作,ReAct的价值不仅在于提出了一种全新范式,更在于为后续Agent的发展提供了核心思路。它让我们意识到,AGI的演进并非单一技术的突破,而是对人类认知逻辑的深度借鉴与工程化落地。在当下Agent赛道蓬勃发展的背景下,ReAct的核心思想仍具有极强的指导意义,为我们的技术实践提供了三大关键启示。
第一,构建Agent时,显式的Reasoning Step(Thought)必不可少。很多开发者在设计Agent时,急于让模型调用工具,却忽略了思考环节的重要性,导致模型频繁出现无效操作。事实上,复杂任务的解决离不开清晰的目标拆解与策略规划,让模型先"想清楚"再"动手做",才能减少冗余动作,提升任务成功率。比如在构建企业级Agent时,面对"生成季度销售报告并发送给各部门负责人"的指令,模型应先通过Thought拆解为"获取销售数据、整理数据维度、生成报告文档、确认负责人邮箱、发送邮件"等子目标,再逐步执行对应动作,而非直接调用邮件API。
第二,在私有数据或实时信息场景中,ReAct范式比单纯的RAG(检索增强生成)更具灵活性。RAG的核心是通过预检索将相关信息融入上下文,但其检索策略相对固定,难以应对动态变化的需求;而ReAct允许模型根据任务进展自主决定检索时机、检索关键词,甚至根据检索结果调整后续策略。比如在金融领域的Agent中,当用户询问"某股票今日走势及投资建议"时,ReAct会先通过Thought明确"需要获取实时股价、行业新闻、公司公告等信息",再调用对应API检索,若发现检索结果不足,还会进一步调整关键词补充检索,最终结合信息生成建议,这种动态检索能力是RAG难以企及的。
第三,微调Agent时,应重视中间轨迹的价值。很多开发者在微调时仅将最终答案作为训练数据,却忽略了中间的Thought-Action过程,导致模型虽能输出正确答案,却无法复现合理的决策路径,泛化性极差。而ReAct的微调实验表明,将完整的"Thought-Action-Observation"轨迹纳入训练数据,能让模型学会通用的决策逻辑,即便面对未见过的任务,也能通过协同范式逐步拆解。比如在微调客服Agent时,不仅要包含"用户问题-最终回复",更要加入"理解用户需求的Thought-调用知识库检索的Action-获取检索结果的Observation-生成回复的Thought"等完整轨迹,让模型学会"如何理解需求、如何获取信息、如何组织回复"的全流程逻辑。
ReAct的出现,标志着LLM从"被动响应"向"主动决策"的关键转折,它为AI领域提供了一种全新的智能范式,让大语言模型不再局限于文本生成,而是成为能够感知环境、规划目标、执行动作的智能体。如今,无论是AutoGPT、LangChain等Agent框架,还是各类行业级Agent应用,都能看到ReAct的影子,其"推理与行动协同"的核心思想,已成为Agent技术的底层共识。
当然,ReAct只是LLM Agent发展的起点,随着上下文窗口的扩大、多模态技术的融合、强化学习与Prompting的结合,Agent的能力还将持续迭代。但重读这篇论文我们能深刻意识到,真正的智能从来不是"单向输出",而是"与环境的动态交互、与自身的持续迭代"。ReAct给予我们的不仅是一种技术方法,更是一种认知启发,模仿人类的认知逻辑,让AI在"思考"与"行动"的循环中不断成长,或许正是通往AGI的必经之路。
在当下Agent赛道群雄逐鹿的时代,回望ReAct这盏启蒙之光,能让我们更清晰地把握技术的核心脉络,避开盲目跟风的陷阱。未来,当我们构建更强大的Agent时,不妨始终牢记ReAct的核心逻辑:让思考指导行动,让行动验证思考,在协同与迭代中,让AI真正成为人类解决复杂问题的可靠伙伴。而这,或许正是这篇开山之作留给行业最珍贵的财富。