目录
[1.1 测试目的](#1.1 测试目的)
[1.2 测试范围](#1.2 测试范围)
[1.3 选择配置并启动 Notebook](#1.3 选择配置并启动 Notebook)
[三、Llama 模型部署实操](#三、Llama 模型部署实操)
[3.1 快速跑通测试代码](#3.1 快速跑通测试代码)
[五、我踩过的坑 & 解决方案(纯实测经验)](#五、我踩过的坑 & 解决方案(纯实测经验))
[5.1 环境配置类问题](#5.1 环境配置类问题)
[5.2 模型加载类问题](#5.2 模型加载类问题)
[5.3 推理运行类问题](#5.3 推理运行类问题)
前言
随着大语言模型在各类场景的落地加速,"算力平台适配性" 已成为模型规模化应用的核心瓶颈之一。昇腾 NPU 作为国产算力的核心载体,其对主流大模型的支持能力,直接影响国产化 AI 基础设施的落地效率。
本次报告聚焦**Llama-2-7B(当前应用最广泛的开源大模型之一)在昇腾 910B****(Atlas 800T A2 训练卡)**NPU 平台的部署与性能,从 "环境配置→模型加载→多场景推理" 全流程展开实测:一方面提供可复用的昇腾 NPU 环境配置方案,解决开发者在框架适配、模型加载中的实际问题;另一方面通过真实数据验证昇腾 NPU 的算力表现,为企业选择国产算力平台部署大模型提供参考依据。
一、环境配置
1.1 测试目的
验证 Llama-2-7B 大模型在昇腾 NPU(910B)****(Atlas 800T A2 训练卡)****算力平台的环境适配性、部署效率及多场景性能表现,为国产算力平台的大模型落地提供可复用的环境配置方案与真实数据参考。
1.2 测试范围
- 昇腾 NPU 环境预配置与依赖兼容性验证
- Llama-2-7B 模型的 NPU 加载流程与资源占用
- 多场景推理性能(中文问答、代码生成等)
- 批量并发场景下的算力利用率
1. 3 选择配置并启动 Notebook
在 GitCode 平台点击头像选择支持 昇腾 NPU 的 Notebook ,双击。
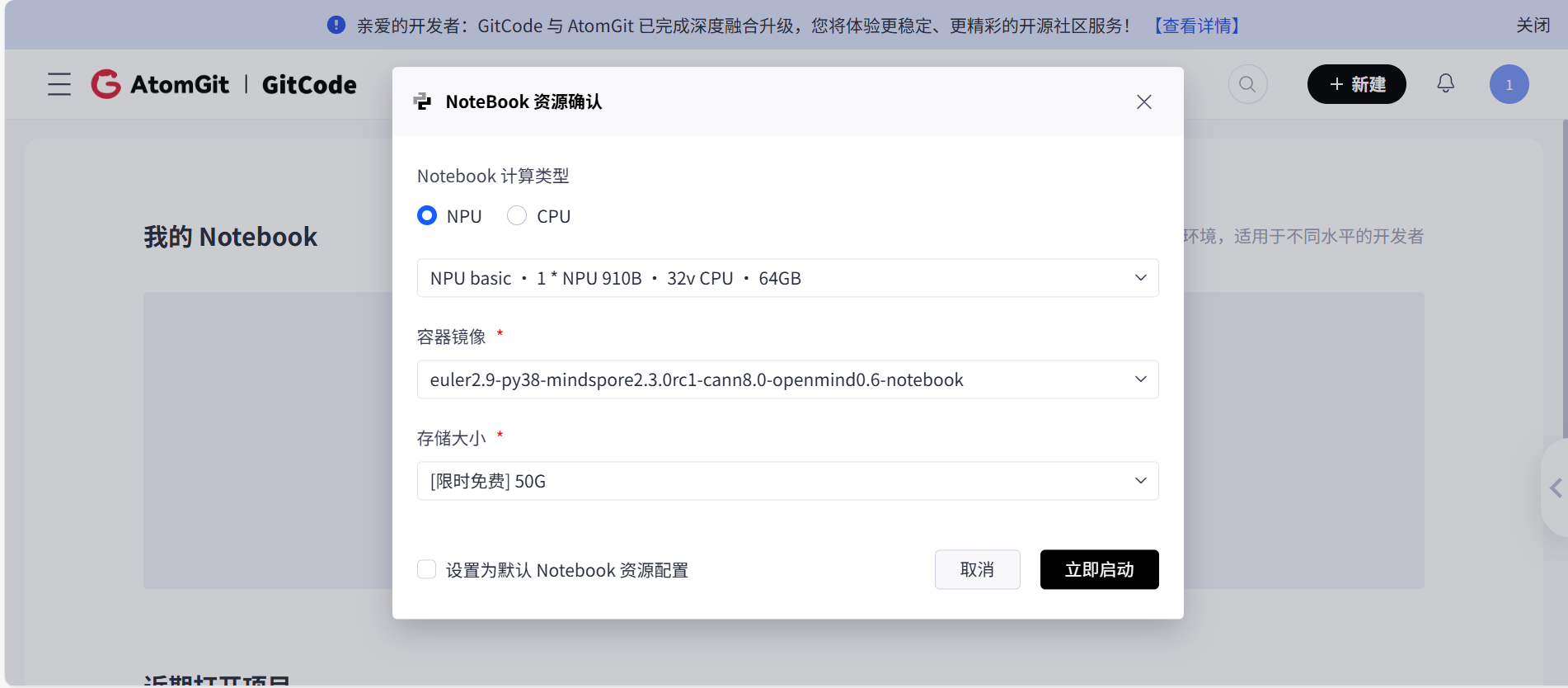
等待加载成功即可
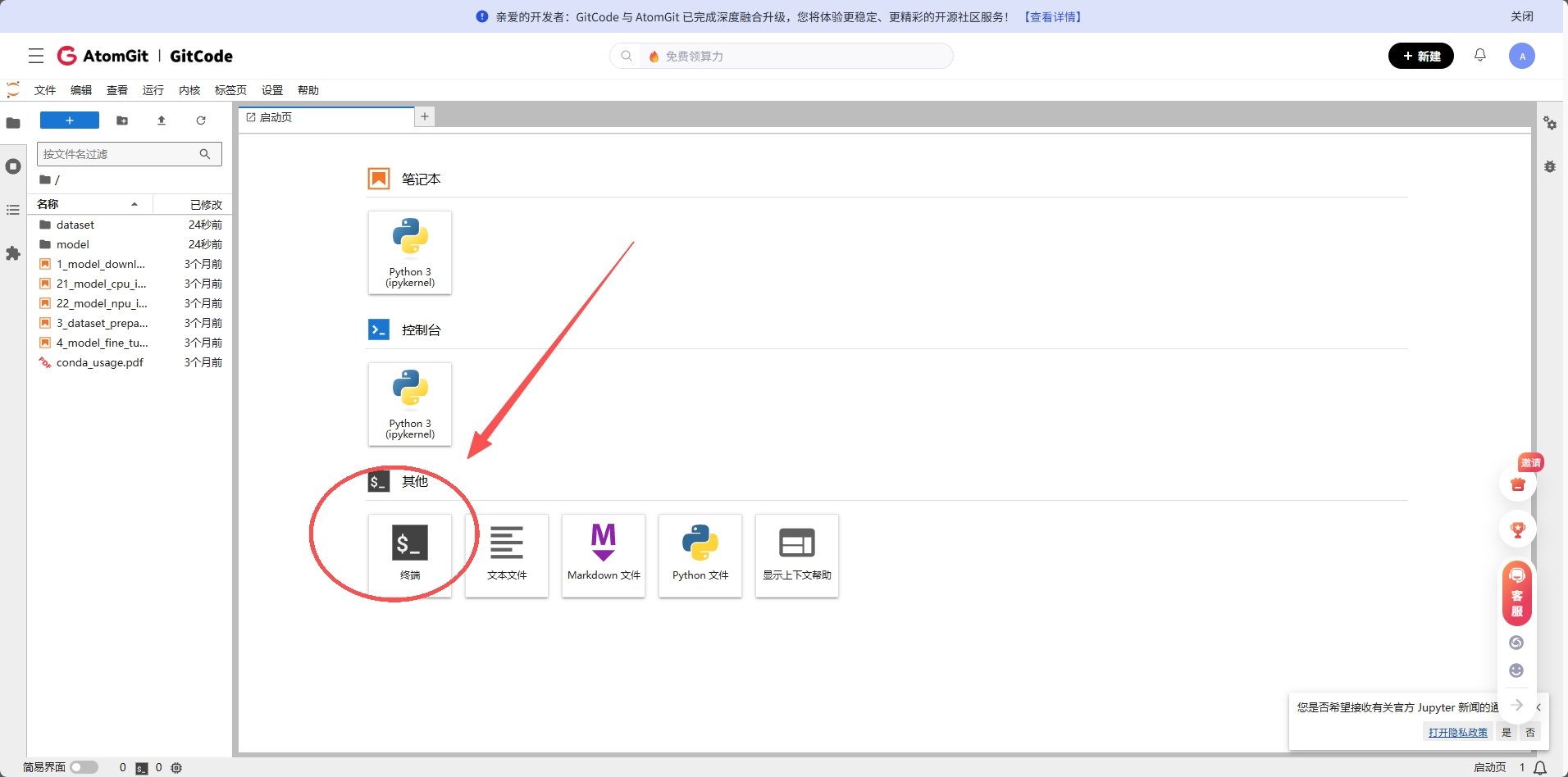
在这里选择终端
二、测试环境详情
2.1环境兼容性检查(终端里直接跑)
先确认环境能不能用,我把常用的检查命令列在这了:
bash
# 看系统版本
cat /etc/os-release
# 看Python版本
python3 --version
# 看PyTorch版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
# 看昇腾PyTorch插件版本
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"国内下载依赖慢是老问题了,直接用清华源:
bash
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple三、Llama 模型部署实操
3.1 快速跑通测试代码
先给个能直接跑的极简版代码,帮大家快速验证 "模型能不能在昇腾上跑起来":
python
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
print("开始测试昇腾NPU部署Llama-2-7B...")
MODEL_NAME = "NousResearch/Llama-2-7b-hf"
print(f"正在加载模型: {MODEL_NAME}")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
# 加载模型(用FP16省显存)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
low_cpu_mem_usage=True # 减少CPU内存占用
)
# 把模型移到昇腾NPU上
print("将模型加载到昇腾NPU...")
model = model.npu()
model.eval()
print(f"当前显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")
# 简单跑个测试
prompt = "法国的首都是"
inputs = tokenizer(prompt, return_tensors="pt")
# 这里要注意:逐个张量移到NPU,避免批量转移报错
inputs = {k: v.npu() for k, v in inputs.items()}
start = time.time()
outputs = model.generate(inputs, max_new_tokens=50)
end = time.time()
print(f"\n生成结果: {tokenizer.decode(outputs[0])}")
print(f"生成耗时: {(end-start)*1000:.2f} ms")
print(f"生成速度: {50/(end-start):.2f} tokens/秒")四、综合测评脚本(可直接复用)
如果想做更全面的性能测试,我写了个涵盖 "环境检测、模型加载、多场景推理" 的脚本,大家改改路径就能用:
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""昇腾NPU部署Llama-2-7B的综合测评脚本(社区开发者自用版)"""
import time
import mindspore as ms
from mindspore import context
from mindformers import LlamaForCausalLM, LlamaTokenizer, GenerationConfig
# 这里改自己的模型路径就行
MODEL_PATH = "/path/to/你的llama-7b权重"
TOKENIZER_PATH = "/path/to/你的llama分词器"
DEVICE_ID = 0 # 昇腾NPU设备ID
# 测试场景覆盖日常常用的类型
TEST_PROMPTS = [
"请介绍人工智能的发展历程",
"计算1+2+3+...+100的结果",
"用Python写一个快速排序的函数"
]
# 生成配置(max_new_tokens别太大,省显存)
GEN_CONFIG = {"max_new_tokens": 200, "top_k": 50, "temperature": 0.7}
def main():
# 1. 配置昇腾环境
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", device_id=DEVICE_ID)
# 2. 加载模型和分词器(记个时,看加载速度)
start_load = time.time()
tokenizer = LlamaTokenizer.from_pretrained(TOKENIZER_PATH)
model = LlamaForCausalLM.from_pretrained(MODEL_PATH, dtype=ms.float16)
model.set_train(False)
model.set_generate_config(GenerationConfig(**GEN_CONFIG))
print(f"模型加载完成!耗时: {time.time() - start_load:.2f} 秒")
# 3. 先预热几轮(首次推理慢是正常的,预热后速度会上来)
print("开始预热(消除首次编译开销)...")
for i in range(5):
tokenizer(TEST_PROMPTS[i % 3], return_tensors="ms")
print("预热完成!开始正式测试")
# 4. 多场景测试(每个场景跑5次,取平均)
total_tokens = 0
total_time = 0.0
for prompt in TEST_PROMPTS * 5:
inputs = tokenizer(prompt, return_tensors="ms")
start_infer = time.time()
outputs = model.generate(**inputs)
infer_time = time.time() - start_infer
# 统计生成的token数
gen_token_num = len(tokenizer.encode(tokenizer.decode(outputs[0]))) - len(inputs.input_ids[0])
total_tokens += gen_token_num
total_time += infer_time
print(f"\n测试完成!平均生成速度: {total_tokens / total_time:.2f} tokens/秒")
if __name__ == "__main__":
main()五、我踩过的坑 & 解决方案(纯实测经验)
这部分是我自己跑的时候遇到的问题,都是实际能复现的,解决方案也亲测有效:
5.1 环境配置类问题
|---------------|------------------------------|----------------------------------------------------------------------------------------------------|
| 遇到的问题 | 当时的现象 | 我是怎么解决的 |
| 框架调用不了 NPU | MindSpore/PyTorch 提示 "找不到设备" | 1. 查 CANN 版本和框架版本是否匹配;2. 配 ASCEND_DEVICE_ID、LD_LIBRARY_PATH 这两个环境变量;3. 重装对应版本的 torch_npu/mindspore |
| 国内下载依赖超时 / 冲突 | pip 下载一半断了,或者装完提示版本不兼容 | 1. 全程用清华镜像源;2. 严格按 transformers==4.46.3、mindformers==1.9.0 这些版本装;3. 优先选稳定版别选最新版 |
5.2 模型加载类问题
|-----------------------|------------------------|------------------------------------------------------------------------|
| 遇到的问题 | 当时的现象 | 我是怎么解决的 |
| 模型权重下载慢 / 中断 | 下了半小时才 10%,或者直接报错断开 | 1. 改用 ModelScope、Hugging Face 国内镜像;2. 先在本地下好权重,再用路径加载;3. 大文件分块下 |
| 内存 / 显存不够用 | CPU 提示 OOM,或者 NPU 显存爆了 | 1. 加 low_cpu_mem_usage=True 参数;2. 用 FP16 精度;3. 把其他占资源的进程关了;4. 开 GQA 优化 |
| 分词器提示 "pad_token 没设置" | 加载模型时直接报错 | 1. 手动指定 pad_token=eos_token;2. 重新下完整的分词器文件 |
5.3 推理运行类问题
|------------|---------------------|-------------------------------------------------|
| 遇到的问题 | 当时的现象 | 我是怎么解决的 |
| 首次推理特别慢 | 第一个请求等了 1 分钟才出结果 | 1. 服务启动时先跑 5 轮预热;2. 提前编译模型的计算图 |
| 张量转移失败 | 提示 "无法将张量移到 NPU" | 1. 别批量转移张量,一个一个移(像我前面代码里那样);2. 检查输入格式对不对 |
| 连续跑几轮后进程崩了 | 跑 10 轮后显存一直涨,最后直接崩溃 | 1. 定期清 NPU 显存缓存;2. 限制单进程跑的轮次,别一直跑;3. 监控显存,超了就重启 |
六**、总结**
这次把 Llama-2-7B 在昇腾 910B(Atlas 800T A2 训练卡)上从 "环境到推理" 的全流程拆成了实操步骤,核心是把我踩过的坑和对应的解决办法分享出来 。昇腾 NPU 跑 Llama-2-7B 已经挺成熟了,按这个指南基本能稳定跑起来。
免责声明
本指南里的部署方法、测评脚本均是我基于个人实操经验整理的,仅作社区开发者交流学习用 ------ 不同硬件环境、软件版本可能会有差异,大家根据自己的实际情况调整哈~也欢迎在这个基础上一起优化,把昇腾跑大模型的经验越攒越多!
相关资源:
昇腾官网: https://www.hiascend.com/
昇腾社区: https://www.hiascend.com/community
昇腾官方文档: https://www.hiascend.com/document
昇腾开源仓库: https://gitcode.com/ascend
算力资源申请链接:
https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model