一、引言:分布式系统的"铁三角"与"柔性智慧"
想象这样一个场景:一个全球性的在线支付系统,在"双十一"零点时刻,每秒要处理数百万笔交易请求。用户在中国下单,商家在美国收款,交易数据需要在北京、硅谷、法兰克福的多个数据中心同时更新。这时,系统面临三个基本要求:
-
一致性:用户支付后,账户余额应该立即在所有数据中心同步更新
-
可用性:无论哪个数据中心出现问题,用户都应该能正常支付
-
分区容错性:即使中美之间的海底光缆中断,系统仍应部分可用
这就是分布式系统设计的核心困境。2000年,Eric Brewer教授提出了著名的CAP定理,指出这三个属性不可能同时满足。而后来提出的BASE理论,则为我们提供了在这种"不可能三角"中寻找平衡的实用指南。
本文将深入探讨这两个理论,通过大量图表和实际案例,展示它们在现代系统设计中的应用。无论你是准备面试,还是正在设计高可用的分布式系统,这些理论都将是你不可或缺的思考框架。
二、CAP理论深度解析:分布式系统的"铁律"
2.1 CAP定理的精确含义
让我们首先明确CAP三个属性的准确定义:
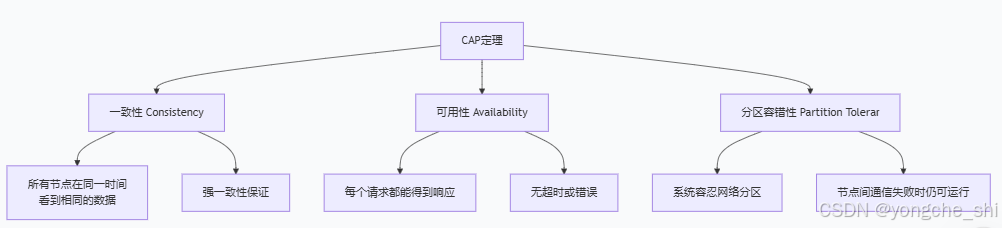
一致性 (Consistency)
这里指的是强一致性或线性一致性。对于任何客户端,无论连接到哪个节点,读取到的数据都是最新的。系统表现得像单机系统,所有操作都有全局顺序。
数学表达:对于任意两个操作O1和O2,如果O1在真实时间上先于O2完成,那么在所有节点看来,O1都应该在O2之前生效。
可用性 (Availability)
系统在有限时间内对每个请求都做出响应(不保证是最新数据)。注意两个关键点:
-
必须是非错误响应(不能返回超时或系统错误)
-
必须在合理时间内响应(通常指毫秒到秒级)
分区容错性 (Partition Tolerance)
系统能够容忍网络分区(节点之间无法通信)的发生,并在分区发生时继续运行。
2.2 为什么只能三选二?
CAP定理的核心洞察是:当网络分区发生时,你必须在一致性和可用性之间做出选择。
让我们通过一个具体例子来理解:
python
# 简化示例:分布式键值存储系统
class DistributedKVStore:
def __init__(self):
self.nodes = {
'US-East': {'data': {}, 'version': 0},
'US-West': {'data': {}, 'version': 0},
'EU-Central': {'data': {}, 'version': 0}
}
self.network_partition = False
def set(self, key, value):
# 理想情况:同步写入所有节点
if not self.network_partition:
for node in self.nodes.values():
node['data'][key] = value
node['version'] += 1
return True
else:
# 网络分区发生!
# 选择CP:写入失败,返回错误
# 选择AP:只写入可达节点,允许不一致
pass
def get(self, key):
# 理想情况:从任意节点读取最新值
if not self.network_partition:
return self.nodes['US-East']['data'].get(key)
else:
# 网络分区发生!
# 选择CP:如果无法保证一致性,可能返回错误
# 选择AP:返回本地数据,可能是旧值
pass当网络分区发生时:
-
如果要保证一致性,就必须拒绝部分请求(牺牲可用性)
-
如果要保证可用性,就必须返回可能不一致的数据(牺牲一致性)
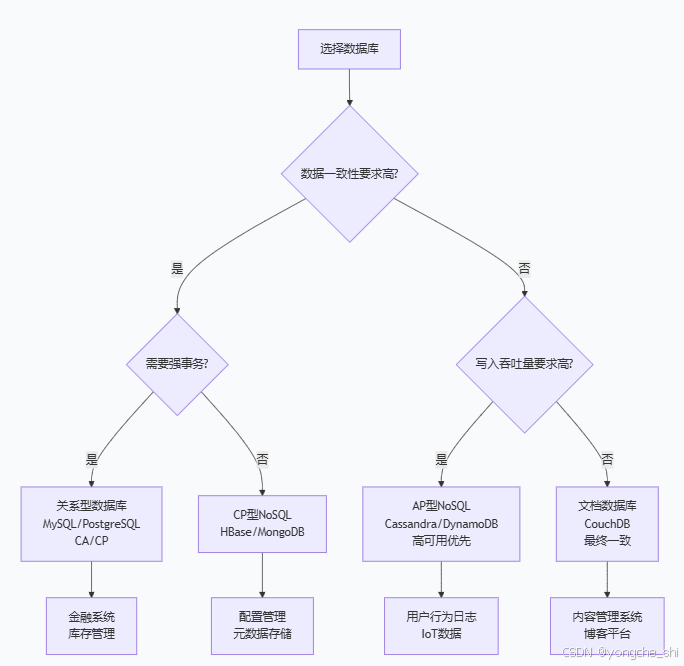
2.3 CAP组合的典型系统
| 组合 | 特点 | 典型系统 | 适用场景 |
|---|---|---|---|
| CA | 保证一致性和可用性,放弃分区容错 | 传统单机数据库主从同步数据库(无自动故障转移) | 小型系统金融核心系统(容忍停机) |
| CP | 保证一致性和分区容错,放弃可用性 | ZooKeeper etcd HBase Google Spanner | 配置管理 分布式锁 金融交易 |
| AP | 保证可用性和分区容错,放弃强一致性 | Cassandra DynamoDB CouchDB Riak | 社交网络 内容推荐 物联网数据 |
2.4 CAP理论的现实理解
需要澄清几个常见误解:
-
CAP不是永远的三选二:只是在网络分区发生时必须选择。大部分时间系统可以同时满足CA。
-
P是必须的:在真实的分布式系统中,网络分区是必然发生的("网络是可靠的"是分布式系统八大谬误之首)。因此实际选择是CP或AP。
-
一致性有不同级别:CAP中的C是强一致性,但实际中有多种一致性模型:
-
强一致性(线性一致性)
-
顺序一致性
-
因果一致性
-
最终一致性
-
三、BASE理论:从"铁三角"到"柔性平衡"
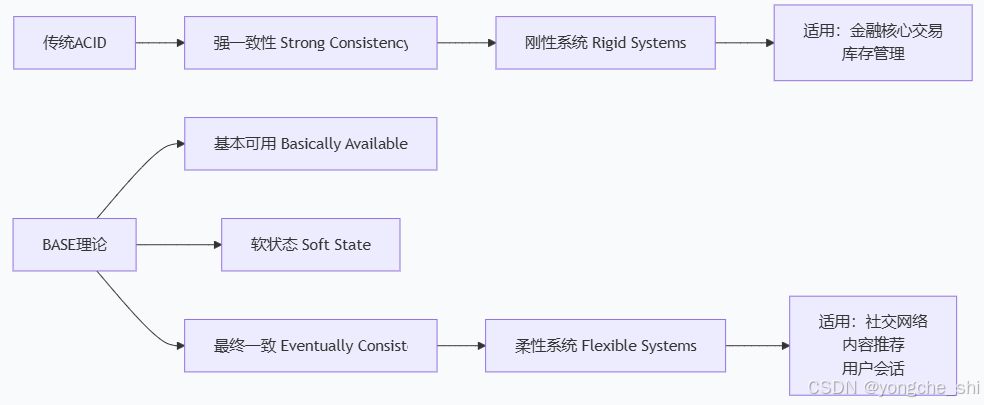
3.1 BASE理论的核心思想
BASE(Basically Available, Soft state, Eventually consistent)是CAP中AP方向的延伸,为构建高可用系统提供了实用指导。
3.2 BASE三要素详解
基本可用 (Basically Available)
系统在出现故障时,保证核心功能可用,允许非核心功能降级。
实现模式:
python
class BasicallyAvailableSystem:
def __init__(self):
self.primary_service = PrimaryService()
self.secondary_service = SecondaryService()
def handle_request(self, request):
try:
# 1. 首先尝试主服务
return self.primary_service.process(request)
except ServiceUnavailableError:
# 2. 主服务失败,尝试降级方案
if self.is_core_function(request):
# 核心功能:使用简化但可用的备选方案
return self.degraded_processing(request)
else:
# 非核心功能:直接返回降级结果
return self.get_cached_response(request)
def degraded_processing(self, request):
"""降级处理:保证基本功能"""
# 示例:支付系统降级
# 正常流程:实时风控 + 实时记账 + 实时通知
# 降级流程:简化风控 + 异步记账 + 延迟通知
pass软状态 (Soft State)
系统允许数据存在中间状态,且该状态不会影响系统整体可用性。
实际案例:电商订单状态流转
text
待支付 → 支付中 → 已支付 → 发货中 → 已发货 → 已收货
↘ 支付失败 ↘ 发货失败最终一致性 (Eventually Consistent)
经过一段时间后,所有数据副本最终会达到一致状态。
最终一致性的变体:
python
class ConsistencyModels:
def causal_consistency(self):
"""因果一致性:有因果关系的操作保持顺序"""
# A评论了B的帖子 → B回复A的评论
# 保证B一定能看到A的评论后才回复
def read_your_writes(self):
"""读己之所写:用户总能读到自己的写入"""
# 用户发布朋友圈后,立即能看到
def session_consistency(self):
"""会话一致性:同一会话内保持一致性"""
# 用户登录期间,看到的数据是一致的
def monotonic_read(self):
"""单调读:不会读到比之前更旧的数据"""
pass
def monotonic_write(self):
"""单调写:同一用户的写入按顺序执行"""
pass3.3 BASE vs ACID
| 特性 | ACID (传统数据库) | BASE (现代分布式系统) |
|---|---|---|
| 一致性 | 强一致性,事务隔离 | 最终一致性 |
| 可用性 | 可能牺牲可用性保证一致性 | 高可用,允许降级 |
| 事务 | 原子性,持久化 | 柔性事务,补偿事务 |
| 响应 | 同步,立即确认 | 异步,可能延迟 |
| 适用场景 | 银行转账,库存扣减 | 社交点赞,消息推送 |
四、CAP/BASE在典型系统中的应用
4.1 数据库系统选择策略
4.2 微服务架构中的数据一致性
在微服务架构中,每个服务有自己的数据库,如何保证数据一致性?
方案1:Saga模式(最终一致性)
python
class OrderSaga:
"""订单处理的Saga模式实现"""
def create_order(self, order_data):
# 1. 创建订单(本地事务)
order = self.order_service.create(order_data)
# 2. 扣减库存(补偿事务:恢复库存)
try:
self.inventory_service.reserve(order.items)
except:
self.order_service.cancel(order.id) # 补偿
raise
# 3. 扣减余额(补偿事务:恢复余额)
try:
self.payment_service.deduct(order.user_id, order.amount)
except:
self.inventory_service.restore(order.items) # 补偿
self.order_service.cancel(order.id)
raise
# 4. 所有步骤成功
return order方案2:事件驱动架构
python
class EventDrivenOrder:
"""事件驱动的订单处理"""
def __init__(self):
self.event_bus = EventBus()
def place_order(self, order_data):
# 1. 发布"OrderCreated"事件
event = OrderCreatedEvent(order_data)
self.event_bus.publish(event)
# 立即返回订单ID,不等待后续处理
# 各个服务订阅事件
class InventoryService:
@subscribe(OrderCreatedEvent)
def on_order_created(self, event):
# 异步处理库存扣减
self.reserve_stock(event.order_id)
class PaymentService:
@subscribe(StockReservedEvent)
def on_stock_reserved(self, event):
# 库存扣减成功后处理支付
self.process_payment(event.order_id)4.3 实际案例分析:Twitter的时间线系统
Twitter面临的设计挑战:
-
读写比例极高(读:写 ≈ 3000:1)
-
关注关系复杂(名人可能有数千万粉丝)
-
实时性要求高(推文需要立即出现在粉丝时间线)
解决方案演进:
python
class TwitterTimelineSystem:
"""Twitter时间线系统设计"""
def __init__(self):
# 写扩散(Fan-out on write)
# 用户发推时,推送给所有粉丝
self.write_fanout = WriteFanoutStrategy()
# 读扩散(Fan-out on read)
# 用户读时间线时,实时聚合关注用户的推文
self.read_fanout = ReadFanoutStrategy()
# 混合策略
self.hybrid = HybridStrategy()
class HybridStrategy:
"""混合策略:名人用读扩散,普通用户用写扩散"""
def post_tweet(self, user_id, tweet):
if self.is_celebrity(user_id):
# 名人:只写入自己的时间线,粉丝读取时聚合
self.store_to_author_timeline(user_id, tweet)
else:
# 普通用户:写入所有粉丝的时间线
self.push_to_followers_timeline(user_id, tweet)
def get_timeline(self, user_id):
# 1. 从自己的时间线读取(已预计算的推文)
timeline = self.get_precomputed_timeline(user_id)
# 2. 合并关注的名人最新推文(实时计算)
celebs_tweets = self.get_recent_celebrity_tweets(user_id)
return merge_and_rank(timeline, celebs_tweets)CAP选择分析:
-
可用性优先:时间线读取必须高可用,允许看到稍旧的推文
-
最终一致性:推文出现的时间可能有几秒延迟
-
分区容错:跨数据中心的数据同步采用异步复制
五、实战:设计一个基于CAP/BASE的社交点赞系统
5.1 需求分析
设计一个支持千万级用户的社交点赞系统:
-
用户可以对帖子点赞/取消点赞
-
显示点赞数和最近点赞用户
-
高并发(热点帖子可能每秒数万点赞)
-
高可用(点赞功能不能成为单点故障)
-
数据一致性要求:最终一致即可
5.2 架构设计
python
class SocialLikeSystem:
"""
基于CAP/BASE理论的社交点赞系统
设计选择:AP + 最终一致性
"""
def __init__(self):
# 缓存层:Redis集群,负责高并发读写
self.cache = RedisCluster(
nodes=10, # 10个节点
replication_factor=3 # 每个数据3个副本
)
# 持久层:Cassandra,负责数据持久化
self.db = CassandraCluster(
consistency_level='LOCAL_QUORUM', # 本地法定数
replication_strategy='NetworkTopologyStrategy'
)
# 消息队列:Kafka,负责异步处理
self.message_queue = KafkaCluster(
topics=['likes', 'unlikes', 'counters']
)
# 计数器服务:负责点赞数聚合
self.counter_service = CounterService()
def like_post(self, user_id, post_id):
"""
点赞操作:AP设计,高可用优先
"""
# 1. 先写缓存,保证快速响应
cache_key = f"like:{post_id}:{user_id}"
self.cache.setex(cache_key, 3600, 1) # 1小时过期
# 2. 发消息到队列,异步持久化
message = {
'action': 'like',
'user_id': user_id,
'post_id': post_id,
'timestamp': time.time()
}
self.message_queue.produce('likes', message)
# 3. 立即更新计数器缓存(非强一致)
count_key = f"count:{post_id}"
self.cache.incr(count_key)
return {'success': True, 'liked': True}
def get_like_count(self, post_id):
"""
获取点赞数:可能返回近似值
"""
# 1. 先读缓存
count = self.cache.get(f"count:{post_id}")
if count is None:
# 2. 缓存未命中,从计数器服务获取
count = self.counter_service.get_count(post_id)
# 3. 回填缓存
self.cache.setex(f"count:{post_id}", 60, count) # 60秒过期
return int(count)
class CounterService:
"""
计数器服务:最终一致性聚合
"""
def __init__(self):
self.db = CassandraCluster()
def get_count(self, post_id):
# 从多个副本读取,取最新值
counts = []
for replica in self.get_replicas(post_id):
count = replica.query_count(post_id)
counts.append((count, replica.timestamp))
# 返回最新的计数(可能不是所有副本都一致)
latest_count = max(counts, key=lambda x: x[1])[0]
return latest_count
def async_update(self):
"""后台异步聚合任务"""
while True:
# 从消息队列消费点赞事件
messages = self.message_queue.consume_batch('counters', 1000)
# 批量更新计数器
batch_updates = self.aggregate_counts(messages)
# 写入数据库
self.db.batch_update(batch_updates)
# 更新缓存
self.update_cache(batch_updates)
class ConsistencyVerification:
"""
一致性验证和修复
"""
def background_repair(self):
"""后台修复不一致数据"""
while True:
# 1. 扫描可能不一致的数据
inconsistencies = self.find_inconsistencies()
for inc in inconsistencies:
# 2. 使用CRDT(无冲突复制数据类型)解决冲突
resolved = self.resolve_with_crdt(inc)
# 3. 修复数据
self.repair_data(resolved)
time.sleep(300) # 每5分钟运行一次
def resolve_with_crdt(self, inconsistency):
"""使用CRDT解决冲突"""
# LWW-Register(最后写入胜出)
# 对于点赞时间戳,取最新的操作
latest_action = max(
inconsistency.actions,
key=lambda x: x.timestamp
)
# G-Counter(增长计数器)
# 对于点赞数,合并所有副本的计数
total_count = sum(inconsistency.counts.values())
return {
'post_id': inconsistency.post_id,
'action': latest_action,
'count': total_count
}5.3 数据模型设计
sql
-- Cassandra数据模型
CREATE TABLE likes (
post_id uuid,
user_id uuid,
action_type text, -- 'like' or 'unlike'
timestamp timestamp,
PRIMARY KEY (post_id, user_id)
) WITH compaction = {'class': 'TimeWindowCompactionStrategy'};
-- 计数器表
CREATE TABLE like_counts (
post_id uuid PRIMARY KEY,
count counter -- Cassandra的特殊计数器类型
);
-- 最终一致性视图
CREATE MATERIALIZED VIEW recent_likes AS
SELECT post_id, user_id, timestamp
FROM likes
WHERE timestamp IS NOT NULL AND user_id IS NOT NULL
PRIMARY KEY (post_id, timestamp, user_id)
WITH CLUSTERING ORDER BY (timestamp DESC);5.4 监控和告警
python
class MonitoringSystem:
"""监控系统一致性延迟和可用性"""
def __init__(self):
self.metrics = MetricsCollector()
def track_consistency_lag(self):
"""追踪最终一致性延迟"""
while True:
# 测量从写入到所有副本可见的时间
lag = self.measure_replication_lag()
self.metrics.gauge('consistency.lag.seconds', lag)
if lag > 5.0: # 延迟超过5秒告警
self.alert('HIGH_CONSISTENCY_LAG', {
'lag': lag,
'threshold': 5.0
})
time.sleep(1)
def measure_availability(self):
"""测量系统可用性"""
success_rate = self.calculate_success_rate()
self.metrics.gauge('availability.rate', success_rate)
if success_rate < 0.999: # 可用性低于99.9%
self.alert('LOW_AVAILABILITY', {
'rate': success_rate,
'threshold': 0.999
})六、总结与面试准备
6.1 核心要点总结
-
CAP定理是分布式系统的基石
-
网络分区发生时,必须在C和A之间选择
-
真实系统中P必须保证,实际选择是CP或AP
-
不同的数据、不同的业务可以选择不同的CAP策略
-
-
BASE理论是AP系统的实践指南
-
基本可用:核心功能优先,允许降级
-
软状态:接受中间状态,提高系统弹性
-
最终一致:通过异步机制达到一致性
-
-
现代系统的混合策略
-
关键数据用CP(如用户账户、交易记录)
-
非关键数据用AP(如社交点赞、内容推荐)
-
同一系统内可以混合使用不同策略
-
6.2 面试常见问题与回答思路
Q1:CAP定理中,为什么说P是必须的?
回答思路:
-
分布式系统运行在网络上,网络分区是必然发生的故障模式
-
所有实际的分布式系统都必须考虑网络故障的容错
-
如果放弃P,系统在分区时完全不可用,这对大多数业务不可接受
-
举例说明:即使在同一数据中心,网络交换机故障也会导致分区
Q2:如何在实际项目中应用BASE理论?
回答思路:
-
首先识别业务的核心功能和非核心功能
-
为不同功能设计不同的可用性级别
-
设计补偿机制处理中间状态
-
选择合适的最终一致性模型
-
举例:电商系统,支付功能必须强一致,商品评价可以最终一致
Q3:ZooKeeper和Cassandra的CAP选择有什么不同?
回答思路:
-
ZooKeeper选择CP:保证强一致性,用于配置管理、分布式锁等场景
-
Cassandra选择AP:保证高可用性,用于日志、监控、社交数据等场景
-
技术实现差异:ZooKeeper使用ZAB协议,Cassandra使用Gossip协议
-
适用场景对比:ZooKeeper适合小数据量强一致,Cassandra适合大数据量高可用
Q4:如何设计一个最终一致性的评论系统?
回答思路:
-
写入路径:评论先写入本地缓存和消息队列,立即返回成功
-
异步处理:后台服务从队列消费,持久化到数据库
-
读取路径:优先从缓存读取,缓存未命中查询数据库
-
冲突解决:使用时间戳或向量时钟解决并发冲突
-
监控修复:定期比对缓存和数据库,修复不一致
6.3 系统设计模版
当面试中遇到系统设计问题时,可以使用以下CAP/BASE分析框架:
text
1. 需求分析
- 数据一致性要求(强一致/最终一致)
- 可用性要求(SLA目标)
- 分区容错需求(跨地域部署)
2. CAP选择
- 如果要求强一致 → CP方向
- 如果要求高可用 → AP方向
- 如果两者都需要 → 分层设计,不同组件不同选择
3. BASE设计
- 基本可用:设计降级方案
- 软状态:定义中间状态和状态机
- 最终一致:选择同步机制和冲突解决
4. 技术选型
- CP系统:ZooKeeper、etcd、HBase
- AP系统:Cassandra、DynamoDB、Riak
- 混合方案:Redis + Kafka + 数据库
5. 监控保障
- 一致性延迟监控
- 可用性SLA监控
- 自动修复机制6.4 进阶思考
在分布式系统设计中,CAP和BASE只是起点。现代系统还需要考虑:
-
PACELC理论:CAP的扩展,考虑延迟(Latency)和一致性(Consistency)的权衡
-
CRDTs:无冲突复制数据类型,解决最终一致性的冲突问题
-
CALM定理:一致性作为逻辑单调性,从逻辑角度理解一致性
-
分布式事务的演进:从2PC到Saga,从TCC到本地消息表
掌握CAP和BASE理论,不仅能帮助你在面试中脱颖而出,更重要的是,它能让你在真实的系统设计中做出明智的权衡。记住,没有完美的架构,只有适合业务场景的架构。在一致性和可用性之间找到平衡点,是每个架构师的必修课。