文章目录
开始
相信很多朋友有出来word的需求,比如Word转PDF,Word转Markdown等。虽然现在AI已经非常强了,但是使用AI转了之后我们很多时候还是需要去校验一下文字对不对。
怎么出来这类需求呢?总不能肉眼一个一个去看吧,有时候几十、几百甚至几千上万个文件,大脑都能整得宕机。
这个时候,我们就可以使用poi工具来处理。
但实际上Word格式非常复杂,这也让poi的接口非常复杂,很难全部记忆。
有什么好的方法能处理这个问题呢?
有,就是理解Word格式。
问题引入
我们先来看一个实际问题,我们有一批pdf,是通过Word转换来,因为是合同性质的资料,我们必须确保它一个字都不能变。
这其中一个很重要的问题就是编号,Word编号是单独处理的,不能简单处理。

java
public static String readDocxText(String filePath) throws IOException {
StringBuilder textBuilder = new StringBuilder();
try (XWPFDocument document = new XWPFDocument(new FileInputStream(filePath))) {
for (XWPFParagraph paragraph : document.getParagraphs()) {
String paragraphText = paragraph.getText();
if (!paragraphText.trim().isEmpty()) {
textBuilder.append(paragraphText).append("\n");
}
}
}
return textBuilder.toString();
}
@Test
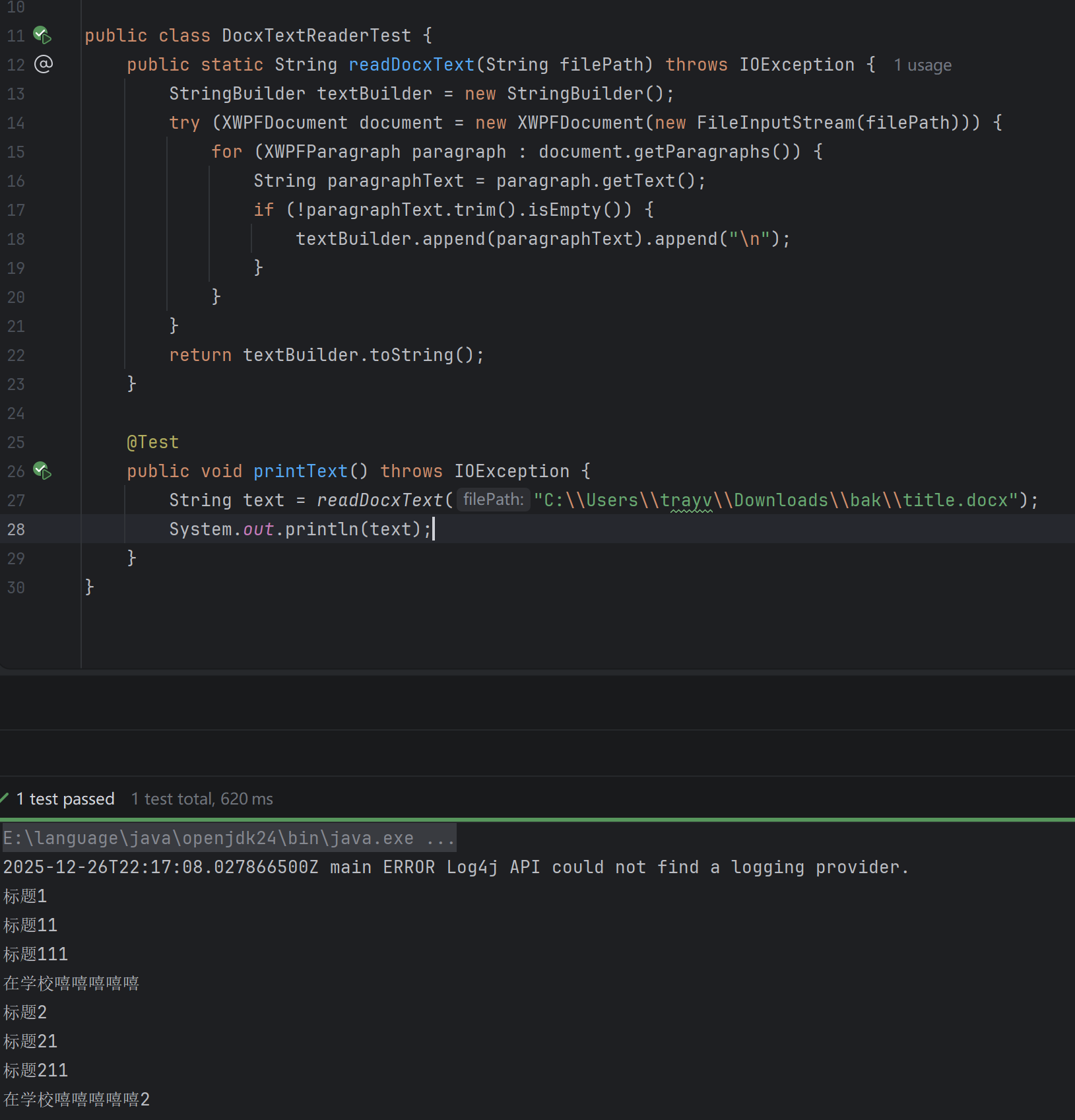
public void printText() throws IOException {
String text = readDocxText("C:\\Users\\trayv\\Downloads\\bak\\title.docx");
System.out.println(text);
}
怎么办呢?
docx文件格式
我们首先来了解一下docx的文件格式,否则看到下面这类代码,指定蒙圈。
java
XWPFNum xwpfNum = numbering.getNum(numID);
numStart = xwpfNum.getCTNum().getLvlOverrideArray()[0].getStartOverride().getVal();
CTDecimalNumber abstractNumId = xwpfNum.getCTNum().getAbstractNumId();
XWPFAbstractNum abstractNum = numbering.getAbstractNum(abstractNumId.getVal());
CTAbstractNum ctAbstractNum = abstractNum.getCTAbstractNum();
CTLvl ctLvl = ctAbstractNum.getLvlArray(0);
format = ctLvl.getNumFmt().getVal().toString();
lvlText = ctLvl.getLvlText().getVal();不清楚docx格式的朋友,现在可能想问,这都是什么啊?
没关系,我们来看一下docx的格式就就会清晰很多。
docx其实和jar、epub这类文件一样本质上是一个zip文件。
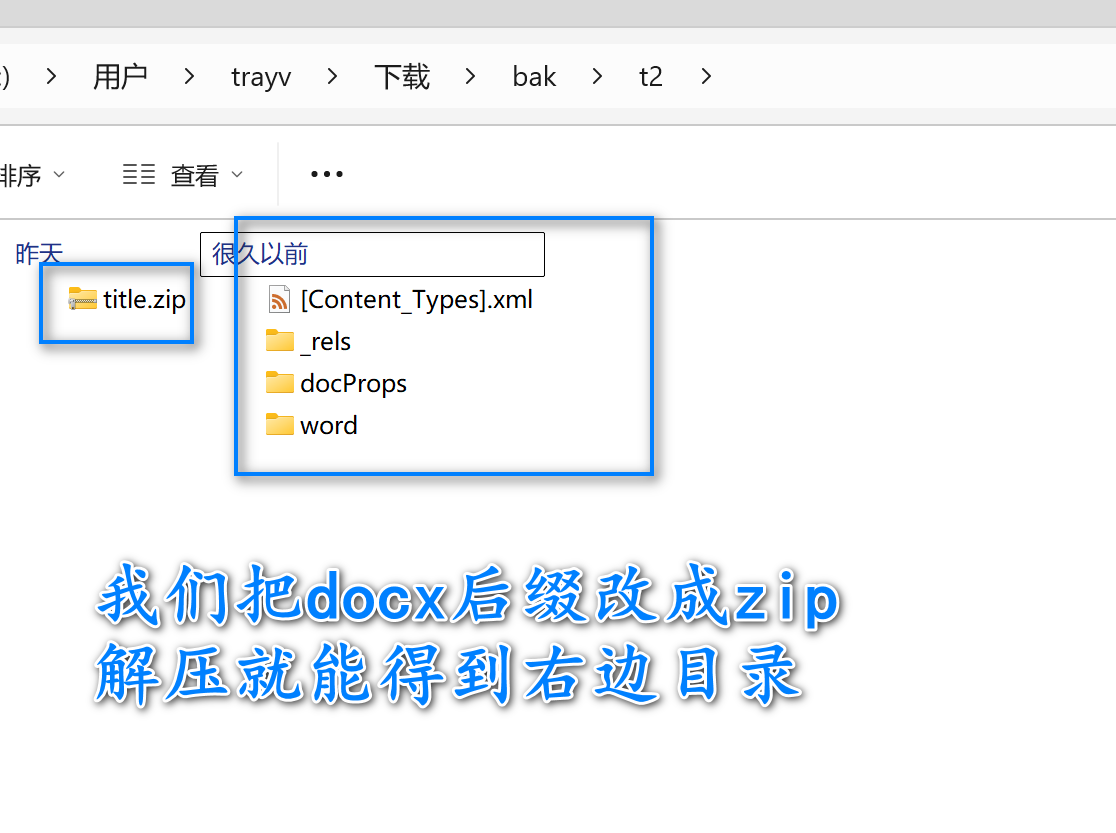
其中核心在word文件夹下:
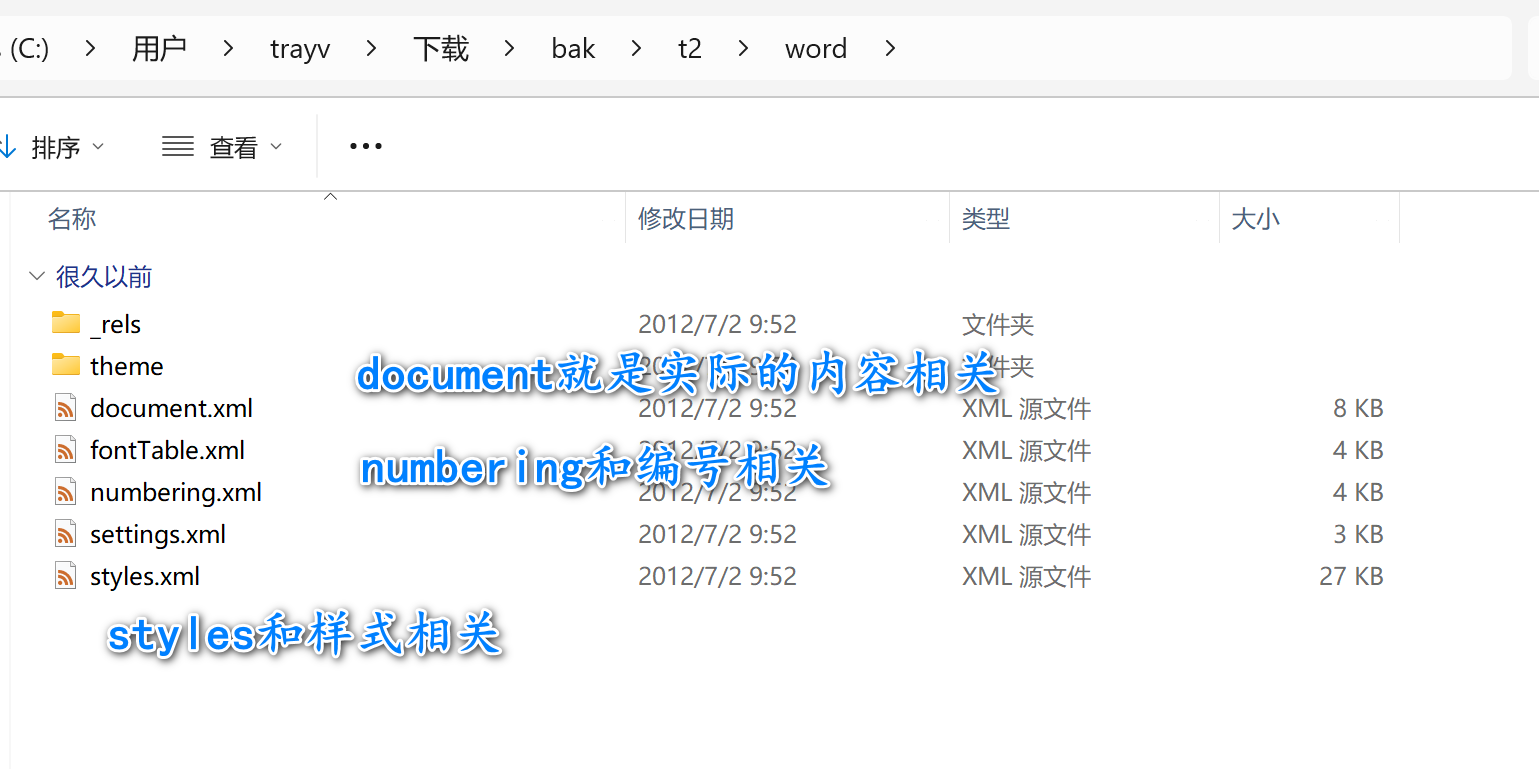
我们来看一下document的内容:
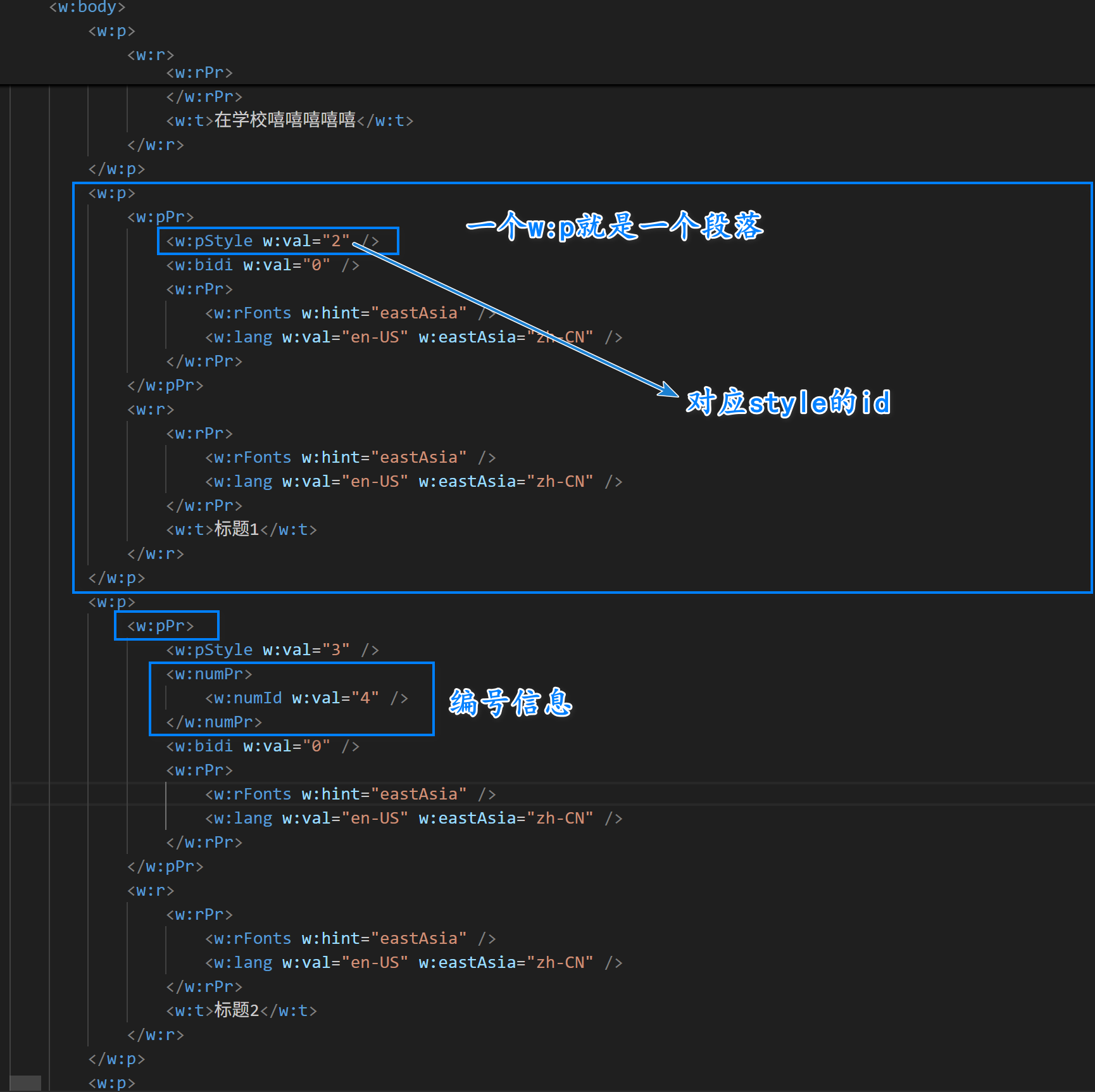
现在,知道.getPPr().getNumPr()是啥了吧,其实就是获取标签对应的对象。
以后,我们使用poi的时候,就可以对着xml文件去看有没有对应api就可以了。
就这么简单吗?
肯定不是,其实非常复杂,有些虽然它自己没有编号,但是它的style可能会有对应的编号。

然后我们需要在numbering.xml文件中找对应的信息:

看着头大吧,头大就对了,其实实际远比这复杂,还有很多关联关系。
还好poi已经为我们处理了大部分问题,接下来我们来看实际应用。
应用实例
这里只是一个简化版,没有处理多个ilvl、重编号、全部的编号类型等情况,不过基本够用了,如果实际情况有出入,相信有前面的知识,也能知道怎么去处理。
java
import org.apache.pdfbox.Loader;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.poi.xwpf.usermodel.*;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.*;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.math.BigInteger;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.function.Function;
import java.util.function.Predicate;
/**
* 编号枚举:
* org.openxmlformats.schemas.wordprocessingml.x2006.main.STNumberFormat.Enum
* chineseCountingThousand: 一
* japaneseCounting: 一
*/
public class WordPdfCompareHelper {
public static void generateCompareText(String pdfPathStr, String docxPathStr, String outDirStr) throws IOException {
String pdfText = readPdfText(pdfPathStr);
String docxText = readDocxText(docxPathStr);
Path pdfTxtPath = Paths.get(outDirStr, "pdf", getFileName(pdfPathStr) + ".txt");
File parent = pdfTxtPath.getParent().toFile();
if (!parent.exists()) {
if (!parent.mkdirs()) {
return;
}
}
Path docxTxtPath = Paths.get(outDirStr, "docx", getFileName(docxPathStr) + ".txt");
parent = docxTxtPath.getParent().toFile();
if (!parent.exists()) {
if (!parent.mkdirs()) {
return;
}
}
Files.writeString(pdfTxtPath, pdfText);
Files.writeString(docxTxtPath, docxText);
}
private static String getFileName(String pathStr) {
File file = new File(pathStr);
String fileName = file.getName();
int index = fileName.lastIndexOf(".");
if (index == -1) {
return fileName;
} else {
return fileName.substring(0, index);
}
}
public static String readDocxText(String filePathStr) throws IOException {
// return getWordNumText(filePathStr, getDefaultPredicate(), getDefaultContentFunction());
return getWordNumText(filePathStr, null, null);
}
/**
*
* @param filePathStr 文件路径
* @param contentFilter 内容过滤器,例如跳过空行
* @param contentConverter 内容转换器,例如需要把全角替换为半角等
* @return 实际文件内容
* @throws IOException IO 异常信息
*/
public static String getWordNumText(
String filePathStr,
Predicate<String> contentFilter,
Function<String, String> contentConverter) throws IOException {
try (FileInputStream fis = new FileInputStream(filePathStr);
XWPFDocument doc = new XWPFDocument(fis)
) {
XWPFNumbering numbering = doc.getNumbering();
XWPFStyles styles = doc.getStyles();
StringBuilder sb = new StringBuilder();
Map<String, Integer> numMap = new HashMap<>();
for (XWPFParagraph paragraph : doc.getParagraphs()) {
String paragraphText = paragraph.getText();
if (contentFilter != null) {
if (!contentFilter.test(paragraphText)) {
continue;
}
}
String numText = "";
BigInteger numID = paragraph.getNumID();
BigInteger numStart;
String format;
String lvlText;
if (numID != null) {
BigInteger level = paragraph.getNumIlvl();
if (level != null) {
format = paragraph.getNumFmt();
lvlText = paragraph.getNumLevelText();
numStart = paragraph.getNumStartOverride();
} else {
// w:num
XWPFNum xwpfNum = numbering.getNum(numID);
numStart = xwpfNum.getCTNum().getLvlOverrideArray()[0].getStartOverride().getVal();
CTDecimalNumber abstractNumId = xwpfNum.getCTNum().getAbstractNumId();
XWPFAbstractNum abstractNum = numbering.getAbstractNum(abstractNumId.getVal());
CTAbstractNum ctAbstractNum = abstractNum.getCTAbstractNum();
CTLvl ctLvl = ctAbstractNum.getLvlArray(0);
format = ctLvl.getNumFmt().getVal().toString();
lvlText = ctLvl.getLvlText().getVal();
}
System.out.println("numId:" + numID + " level:" + level + " format:" + format + " getNumLevelText:"
+ lvlText + " numStart:" + numStart + " text:" + paragraphText);
String key = numID.toString();
Integer num = numMap.get(key);
if (num == null) {
num = 1;
} else {
num = num + 1;
}
numMap.put(key, num);
numText = formatNumText(format, num);
numText = lvlText.replaceFirst("%1", numText);
} else {
String styleID = paragraph.getStyleID();
XWPFStyle style = styles.getStyle(styleID);
if (style != null) {
// styles.xml w:style w:pPr w:numPr
CTNumPr numPr = style.getCTStyle().getPPr().getNumPr();
if (numPr != null) {
CTDecimalNumber numId = numPr.getNumId();
BigInteger ilvl = numPr.getIlvl().getVal();
XWPFNum xwpfNum = numbering.getNum(numId.getVal());
CTNum ctNum = xwpfNum.getCTNum();
CTDecimalNumber abstractNumId = ctNum.getAbstractNumId();
XWPFAbstractNum abstractNum = numbering.getAbstractNum(abstractNumId.getVal());
CTLvl ctLvl = abstractNum.getCTAbstractNum().getLvlArray(0);
String formatName = ctLvl.getNumFmt().getVal().toString();
String numFormat = ctLvl.getLvlText().getVal();
System.out.println("style--->" + styleID +
" numId:" + numId.getVal() +
" numPr.getIlvl().getVal():" + ilvl +
" getNumFmt:" + formatName +
" ctLvl.getLvlText().getVal():" + numFormat +
" numStart:" + ctLvl.getStart().getVal() +
" text:" + paragraphText);
String key = numId.toString();
Integer num = numMap.get(key);
if (num == null) {
num = 1;
} else {
num = num + 1;
}
numMap.put(key, num);
numText = formatNumText(formatName, num);
numText = numFormat.replaceFirst("%1", numText);
}
}
if (contentConverter != null) {
paragraphText = contentConverter.apply(paragraphText);
}
}
sb.append(numText).append(paragraphText).append("\n");
}
return reLine(sb.toString());
}
}
public static String formatNumText(String textFormat, int num) {
if (textFormat.equals("chineseCountingThousand")
|| textFormat.equals("japaneseCounting")
|| textFormat.equals("chineseCounting")
) {
return convertToChinese(num);
}
return String.valueOf(num);
}
public static String simpleNumText(XWPFParagraph paragraph, Map<String, Integer> numMap) {
BigInteger numID = paragraph.getNumID();
String text = paragraph.getText();
if (numID == null) {
return text;
}
String getNumLevelText = paragraph.getNumLevelText();
String key = numID.toString();
Integer num = numMap.get(key);
if (num == null) {
num = 1;
} else {
num = num + 1;
}
numMap.put(key, num);
String numText = convertToChinese(num);
numText = getNumLevelText.replaceFirst("%1", numText);
return numText + text;
}
private static Function<String, String> getDefaultContentFunction() {
return (in) -> {
in = in.replaceAll("\\s+", "");
// \R 会匹配 \n, \r, \r\n 等所有换行符
// in = in.replaceAll("\\R", "");
in = in.replaceAll(".", ".");
return in;
};
}
private static Predicate<String> getDefaultPredicate() {
return (in) -> !in.isEmpty();
}
private static String reLine(String content) {
// 因为转 pdf 之后行段落会变,所以使用新规则重新分行
// String[] lines = content.split("[。!]");
String[] lines = content.split("[。!\n]");
List<String> list = Arrays.stream(lines).filter(getDefaultPredicate())
.map(getDefaultContentFunction()).toList();
return String.join("\n", list);
}
/**
* 读取 PDF全部文本
*
* @param filePath PDF 文件路径
* @return 提取的文本内容
* @throws IOException 读取异常
*/
public static String readPdfText(String filePath) throws IOException {
try (PDDocument document = Loader.loadPDF(new File(filePath))) {
if (document.isEncrypted()) {
document.setAllSecurityToBeRemoved(true);
}
PDFTextStripper textStripper = new PDFTextStripper();
textStripper.setLineSeparator("\n");
textStripper.setSortByPosition(true);
return reLine(textStripper.getText(document));
}
}
private static final String[] NUMBERS = {"零", "一", "二", "三", "四", "五", "六", "七", "八", "九"};
private static final String[] UNITS = {"", "十", "百", "千"};
/**
* 阿拉伯数字转中文数字(仅支持0-9999)
*
* @param number 待转换数字(0-9999)
* @return 符合中文习惯的中文数字字符串
*/
public static String convertToChinese(int number) {
if (number < 0 || number > 9999) {
throw new IllegalArgumentException("仅支持转换0-9999之间的数字");
}
if (number == 0) {
return NUMBERS[0];
}
char[] numChars = String.valueOf(number).toCharArray();
int len = numChars.length;
StringBuilder sb = new StringBuilder();
boolean needZero = false;
for (int i = 0; i < len; i++) {
int digit = numChars[i] - '0';
int pos = len - 1 - i;
if (digit == 0) {
if (pos != 0 && !needZero) {
needZero = true;
}
} else {
if (needZero) {
sb.append(NUMBERS[0]);
needZero = false;
}
sb.append(NUMBERS[digit]).append(UNITS[pos]);
}
}
String result = sb.toString();
if (result.startsWith("一十")) {
result = result.substring(1);
}
return result;
}
}
java
@Test
void generateCompareText() throws IOException {
String pdfPathStr = "C:\\Users\\trayv\\Downloads\\bak\\title.pdf";
String docxPathStr = "C:\\Users\\trayv\\Downloads\\bak\\title.docx";
String outDir = "D:\\tmp\\compare";
WordPdfCompareHelper.generateCompareText(pdfPathStr,docxPathStr,outDir);
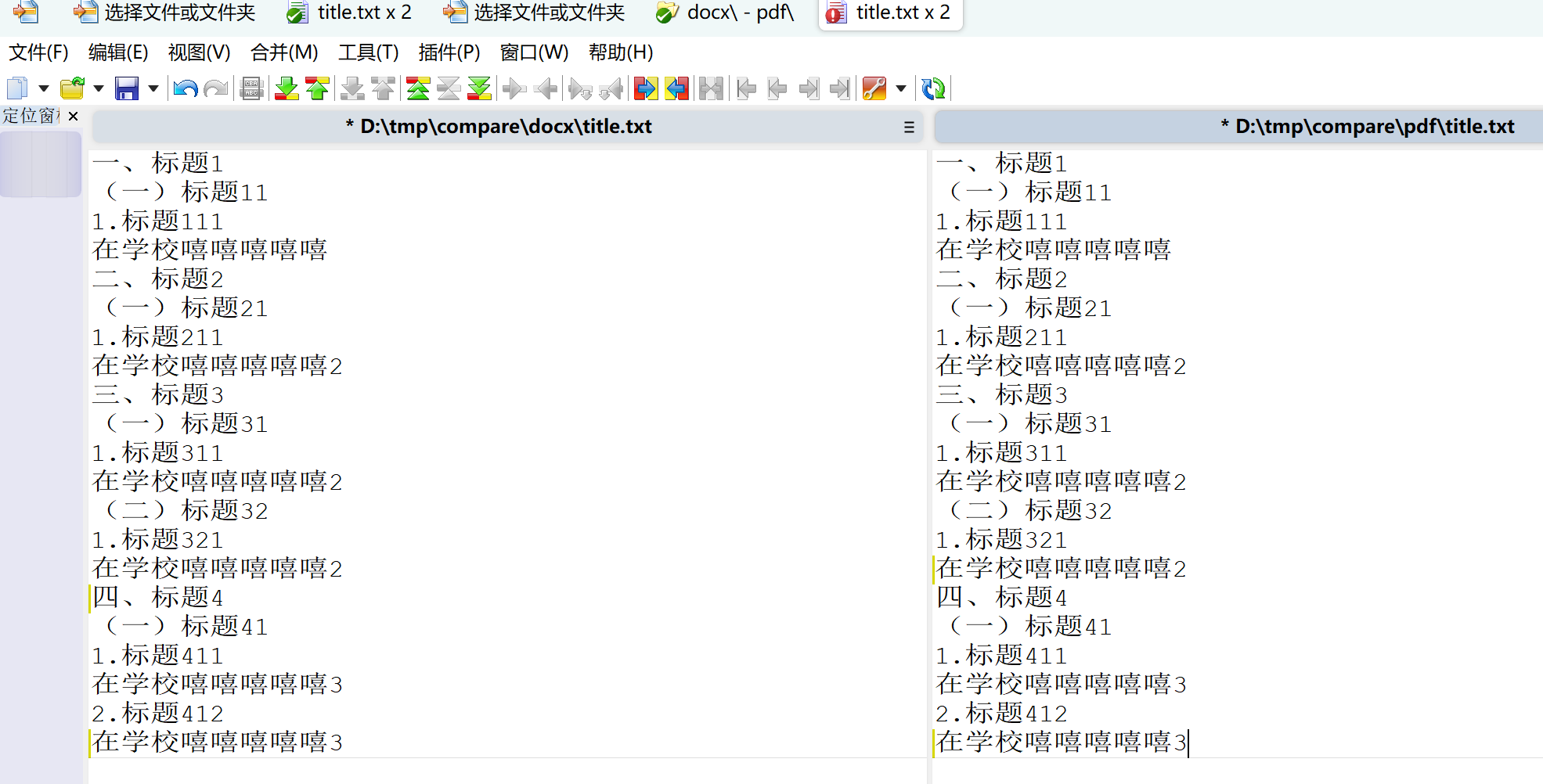
}处理之后,我们可以通过:WinMerge比较
pom.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>vip.meet</groupId>
<artifactId>poi-learn</artifactId>
<version>1.0.0</version>
<properties>
<java.version>17</java.version>
<poi.version>5.5.1</poi.version>
<pdfbox.version>3.0.6</pdfbox.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>${pdfbox.version}</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>${pdfbox.version}</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>${pdfbox.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.5.0-jre</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.5.0</version>
</dependency>
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.20.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.60</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.21.2</version>
</dependency>
<dependency>
<groupId>com.belerweb</groupId>
<artifactId>pinyin4j</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.4.8</version>
</dependency>
<!-- 对应版本:https://projectlombok.org/changelog-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.38</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.9.2</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.12.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>