通过前面对D1芯片的启动流程、SPL以及OpenSBI代码分析,我们对此芯片有了一个初步的认识。
因此现在尝试对其移植一个类Unix系统xv6,通过移植此操作系统,将对整个芯片如何运行操作系统有一个清晰的认识。同时将进一步分析芯片体系结构相关的中断处理、内存管理等。
一、链接地址修改
由于xv6-riscv版本的源代码是针对qemu虚拟机设计的,所以其运行地址为0x8000_0000。因此需要修改链接脚本,将链接地址修改为D1芯片的DDR起始地址处0x4000_0000。同时还需修改Makefile文件,在编译时同时生成二进制bin文件,用于直接运行验证。
cpp
OUTPUT_ARCH( "riscv" )
ENTRY( _entry )
SECTIONS
{
/*
* ensure that entry.S / _entry is at 0x80000000,
* where qemu's -kernel jumps.
*/
/* 修改链接地址为D1芯片的DDR内存起始地址 */
. = 0x40000000;
.text : {
kernel/entry.o(_entry)
*(.text .text.*)
. = ALIGN(0x1000);
_trampoline = .;
*(trampsec)
. = ALIGN(0x1000);
/* 当trampsec空间大于1个物理页(也就是4KB)时,代码在链接的时候将报错 */
ASSERT(. - _trampoline == 0x1000, "error: trampoline larger than one page");
PROVIDE(etext = .);
}
.rodata : {
. = ALIGN(16);
*(.srodata .srodata.*) /* do not need to distinguish this from .rodata */
. = ALIGN(16);
*(.rodata .rodata.*)
}
.data : {
. = ALIGN(16);
*(.sdata .sdata.*) /* do not need to distinguish this from .data */
. = ALIGN(16);
*(.data .data.*)
}
.bss : {
. = ALIGN(16);
*(.sbss .sbss.*) /* do not need to distinguish this from .bss */
. = ALIGN(16);
*(.bss .bss.*)
}
PROVIDE(end = .);
}在链接脚本中修改链接地址为0x4000_0000。

在Makefile中将编译生成的elf文件转换为二进制bin文件。
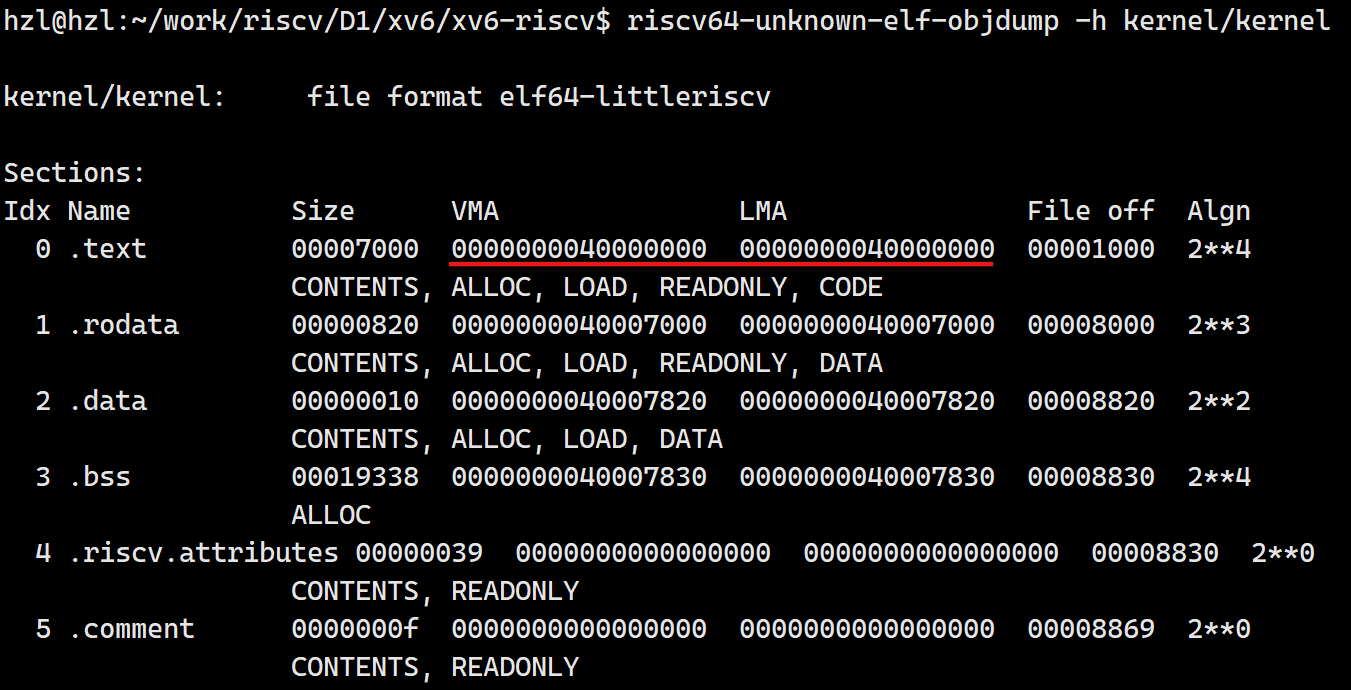
重新进行编译后,生成的xv6镜像的各个主要段信息如下图所示:
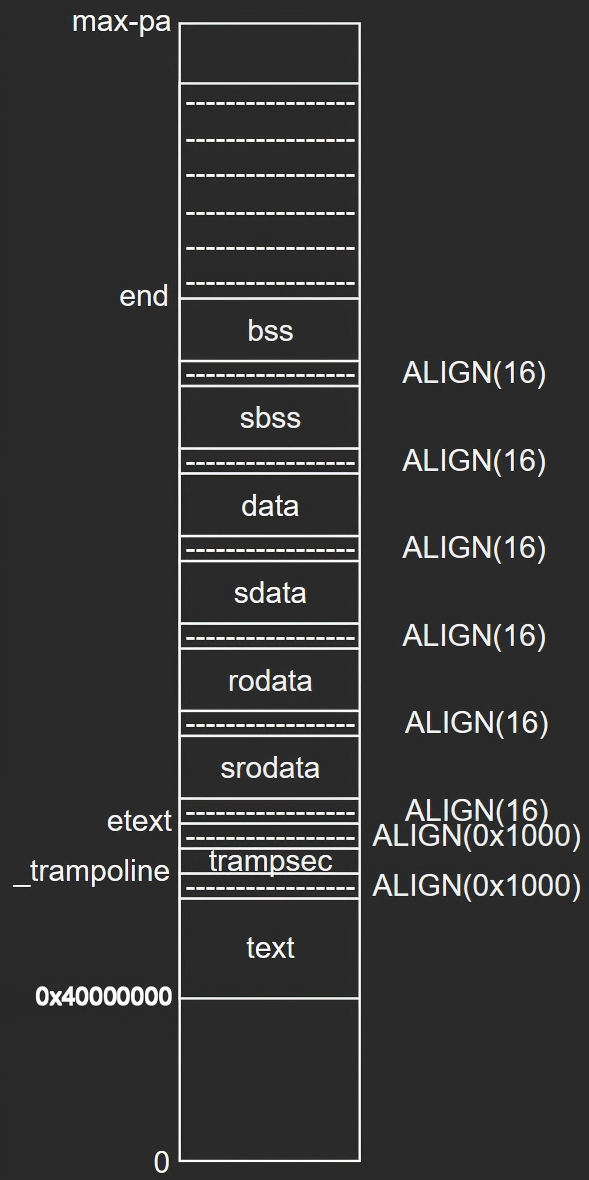
同时通过对链接脚本的分析,其入口代码位于entry.S汇编文件中的_entry符号处,并且xv6系统空间分布如下图所示:
二、汇编入口分析
cpp
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + ((hartid + 1) * 4096)
la sp, stack0 // 加载栈底到sp
li a0, 1024*4 // 设置栈大小为4KB空间
csrr a1, mhartid // 读取hart的id号
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0 // 加上hart编号对应的偏移量,将sp设置为对应hart的栈地址上去
/* CLINT 发起的超级用户软件中断和定时器中断可以被响应 */
li t1, 0x20000
csrs mxstatus, t1
# jump to start() in start.c
call start // 跳转到c代码中,开始执行程序
spin: // 当在start中执行出错,则返回到此处陷入循环
j spin设置每一个hart的sp,为每一个hart准备好c代码运行环境;其栈空间分配情况如下所示:(假设n个hart):
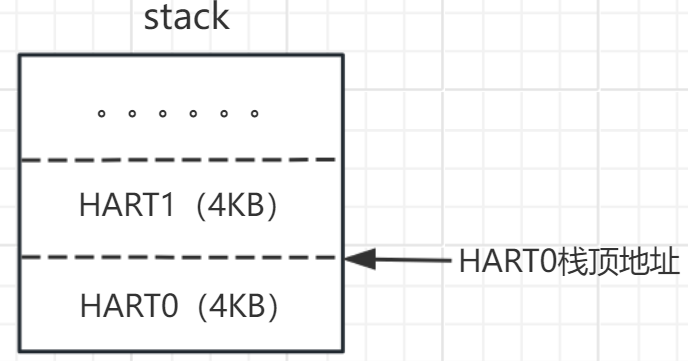
栈区空间是一个全局数组变量,即栈区空间位于bss段中。最后跳入start函数中执行。
三、c代码入口分析
start()函数代码分析如下:
cpp
void start()
{
// set M Previous Privilege mode to Supervisor, for mret.
unsigned long x = r_mstatus();
x &= ~MSTATUS_MPP_MASK;
x |= MSTATUS_MPP_S;
w_mstatus(x); // 读取mstatus(机器模式状态寄存器),并将mpp位设置为S(监管模式)模式,
// 在中断或异常返回后,将进入S模式
// set M Exception Program Counter to main, for mret.
// requires gcc -mcmodel=medany
w_mepc((uint64)main); // 写入mepc寄存器需要在退出机器模式时执行的指令
// disable paging for now.
w_satp(0); // 失能页表基地址寄存器
// delegate all interrupts and exceptions to supervisor mode.
w_medeleg(0xffff);
w_mideleg(0xffff); // 委托所有机器模式下的中断与异常到监管者模式
w_sie(r_sie() | SIE_SEIE | SIE_STIE); // 打开定时器中断、外部中断
// configure Physical Memory Protection to give supervisor mode
// access to all of physical memory.
w_pmpaddr0(0x3fffffffffull); // 根据D1芯片实际情况设置能够访问的物理地址范围
w_pmpcfg0(0xf); // 配置物理内存保护,使监管者模式能访问所有物理内存
// ask for clock interrupts.
timerinit(); // 完成定时器的初始化
// keep each CPU's hartid in its tp register, for cpuid().
int id = r_mhartid();
w_tp(id);
// switch to supervisor mode and jump to main().
asm volatile("mret"); // 从机器模式进行返回,由上面的代码可知:切换到监管者模式,并跳转到
// main函数中运行,同时将等待定时器中断的触发。
}接下来对代码中3处功能点进行说明:中断代理与使能、物理内存保护以及定时器初始化。
3.1、中断代理与使能
进行机器模式下中断代理配置时,需要配置medeleg和mideleg寄存器,其解释如下:
- medeleg和mideleg寄存器:
- medeleg:异常委托寄存器;
- mideleg:中断委托寄存器;
- 这是riscv提供的一种异常委托机制,一般来说,在默认情况下,发生异常或中断时,控制权都会被移交到机器模式;而通过这两个寄存器,可以将对应的中断或异常委托给监管模式来执行。
- 这样的好处是什么?
- 委托过后,cpu的模式不用切换到机器模式,并且也不用使用mret来退出机器模式,能够优化很多模式转换上的操作;并使得操作系统能更有效率的执行中断与异常。
- 同时,使用sie寄存器,能够屏蔽被委托过后的中断;如果中断并未被委托,那么sie相应的中断屏蔽位则是无效的。
当中断代理设置完成后,进行中断使能时,就需要用到sie寄存器:
- sie与sip寄存器:
- 它就是一个监管者模式下的中断使能寄存器和中断挂起寄存器,其低16bit是riscv统一的标准;
- 如下图所示:
- 三个位,分别代表:软件中断、定时器中断以及外部中断;

并且需要注意的是,当中断代理全部都委托给监管者模式时,机器模式的中断将不会被触发,因此mie就算没有开启也没关系(但是需要使能mie寄存器中关于S模式的软件、定时器以及外部中断)。
同时还需要注意,对于D1芯片,想要将定时器与软件中断委托给监管者模式,需要操作csr的mxstatus寄存器,对监管者模式响应定时器与软件中断进行使能(此属于芯片扩展功能):
cpp
/* CLINT 发起的超级用户软件中断和定时器中断可以被响应 */
li t1, 0x20000
csrs mxstatus, t13.2、物理内存保护
在进入监管者模式前,需要在机器模式下设置PMP物理内存保护配置,将对部分内存的读写执行权限赋予监管者模式,否则在监管者模式下,可能发生内存访问无权限导致异常的情况。
对物理内存进行保护配置的寄存器为:pmpaddr和pmpcfg寄存器组。
3.2.1、pmpcfg寄存器说明
pmpcfg寄存器中每个表项的bit排布如下图所示:

pmpcfg寄存器中每个表项的bit含义如下图所示:

其中A域为表项地址的匹配模式设置,此域决定了pmpaddr寄存器的配置方式。比如A域设置为了01,即TOR模式,其含义为使用上一个pmpaddr寄存器表项的地址作为起始地址,自身的pmpaddr寄存器表项作为结束地址,在此内存范围区域进行权限设置。(比如pmpcfg1中进行配置,则pmpaddr0作为起始地址,pmpaddr1作为结束地址)
(pmpcfg0作为配置项时,则默认起始地址为0,结束地址为pmpaddr0)
3.2.1、pmpaddr寄存器说明
pmpaddr寄存器的配置方式是需要根据pmpcfg寄存器的A域来进行的,现在我们以D1芯片的TOR模式来进行举例说明。pmpaddr寄存器bit排布如下图所示:

由于D1芯片内部总线地址寻址支持到0~39bit位,并且由于设置pmpaddr地址时需要4字节对齐。因此设置此地址时,需要先将地址右移2位然后再写入pmpaddr寄存器中。所以在xv6代码中会对pmpaddr0寄存器设置时进行修改,将其改为w_pmpaddr0(0x3fffffffffull),仅设置0~39地址范围即可。
3.3、定时器初始化
cpp
#define STIMECMPL 0x1400D000
#define STIMECMPH 0x1400D004
static inline void w_stimecmp(uint64 x)
{
// asm volatile("csrw stimecmp, %0" : : "r" (x));
// asm volatile("csrw 0x14d, %0" : : "r" (x));
// 修改stimecmp设置操作,由于D1芯片未实现csr中的0x14d寄存器
*(volatile uint32 *)STIMECMPL = x & 0xFFFFFFFF;
*(volatile uint32 *)STIMECMPH = (x >> 32) & 0xFFFFFFFF;
}
// ask each hart to generate timer interrupts.
void timerinit()
{
// enable supervisor-mode timer interrupts.
w_mie(r_mie() | MIE_STIE); // 使能监管者模式下的定时器中断
// enable the sstc extension (i.e. stimecmp).
//w_menvcfg(r_menvcfg() | (1L << 63)); // D1芯片中无此寄存器,因此需要屏蔽
// allow supervisor to use stimecmp and time.
w_mcounteren(r_mcounteren() | 2); // 设置监管者模式能正常读取time寄存器
// ask for the very first timer interrupt.
w_stimecmp(r_time() + 1000000); // 设置第一次定时间中断时间
}由于D1芯片内部实现的csr寄存器与qemu虚拟机中略有差异,因此需要根据实际情况进行修改。比如在初始化定时器时,D1芯片在csr中未实现timecmp比较寄存器,因此需要通过CLINT寄存器来进行设置等。
当所有初始化完成后,最后调用mret指令,退出机器模式并跳转到监管者模式,同时进入main函数中执行。
四、console初始化分析
进入main函数后,首先进行的就是串口初始化,进行启动信息的输出打印。通过调用consoleinit函数,完成串口的初始化(即波特率、数据位、停止位与奇偶校验位的设置等),然后再注册console设备的读写接口。
uart框架如下所示:
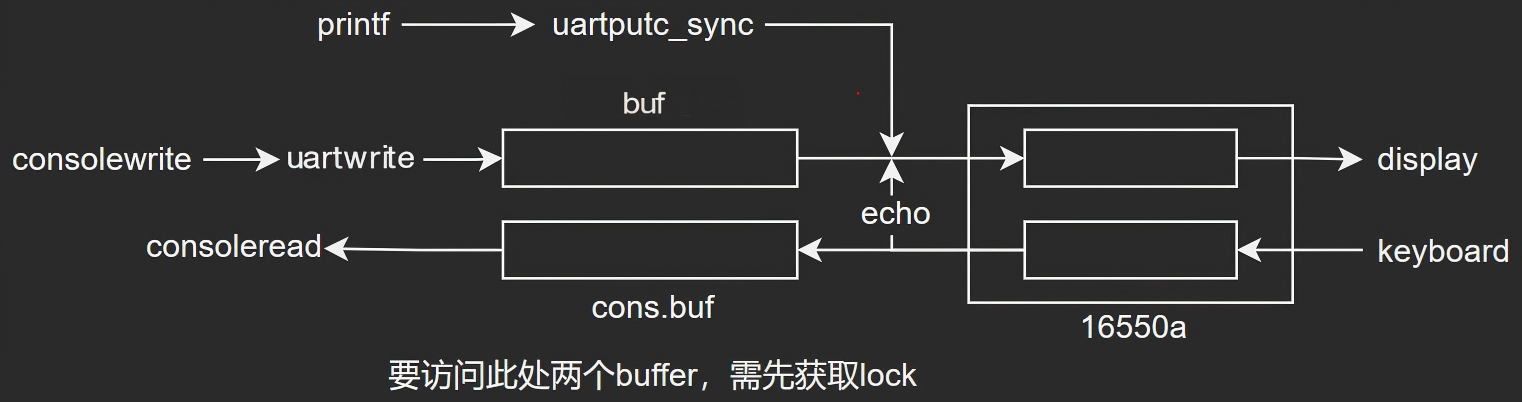
在进行printf输出打印debug信息时,直接调用uartputc_sync接口操作uart发送寄存器进行数据发送,不使用中断(在发送过程中会关闭中断使能);而在进行consolewrite发送数据时,发送完成一个字符后将进入休眠,并等待发送完成中断将其唤醒继续发送。
对于uart接收,将使用中断的方式进行。接收中断触发后,串口输入数据将被读取存储到cons.buf缓冲区中(目前缓冲区大小128字节),其buffer缓冲区结构如下所示(右图为缓冲区为空的情况):
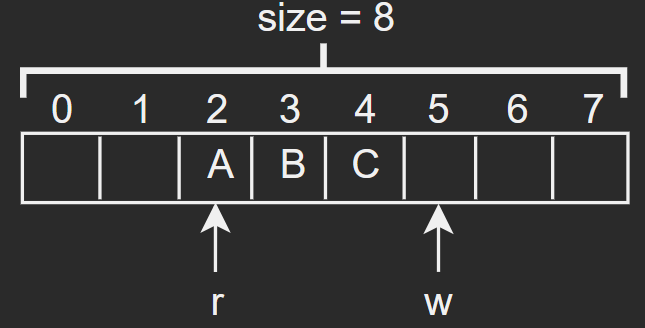
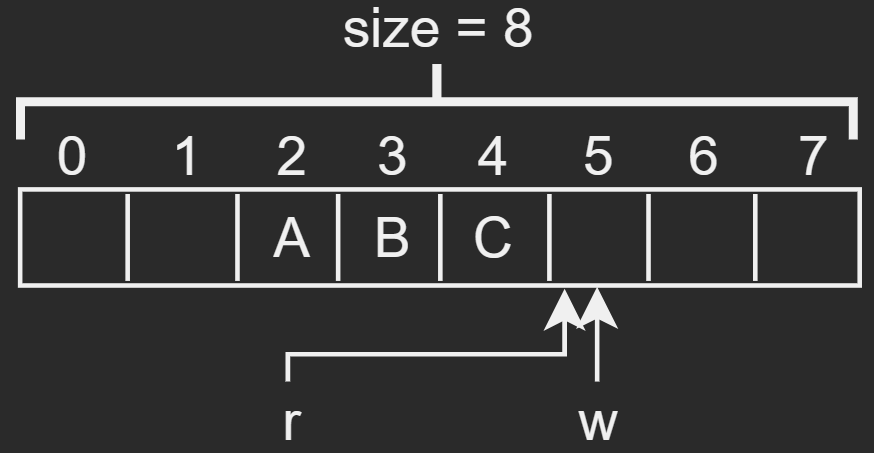
- 其中r和w为读数据和写数据的索引值,且其一直为递增的;
- buffw++ % size = char,通过w++ % size取余结果来得到写的索引值;
- char = buffr++ % size,通过r++ % size取余结果来得到读的索引值;
- 这样做的好处在于:
- 使得此buff成为一个环形结构,索引值一直在递增,但能一直填充此buff;
- 可以通过r == w,来判断缓冲区为空;
- 可以通过r + size > w,来判断要读取的数据量已经超限;
- 同时需注意此缓冲区可能会被多个进程访问,所以需要对此buff进行加锁操作。
4.1、D1串口驱动适配
由于D1串口兼容16550,因此xv6源码中的串口驱动即可。但是需要注意的是,需要修改串口控制器的寄存器基地址以及寄存器偏移量,最后将波特率修改为115200即可。
cpp
// 修改为D1 uart0寄存器基地址
#define UART0 0x02500000L
// D1芯片串口兼容16550,但是需修改寄存器偏移为4字节
#define Reg(reg) ((volatile unsigned char *)(UART0 + (reg * 4)))
void uartinit(void)
{
。。。。。。
// special mode to set baud rate.
WriteReg(LCR, LCR_BAUD_LATCH);
// LSB for baud rate of 38.4K.
WriteReg(0, 0x0d); // 设置波特率为115200,修改分频值(时钟源为24MHz)
// MSB for baud rate of 38.4K.
WriteReg(1, 0x00);
。。。。。。
}4.2、清bss段
完成上述修改后,进行编译启动时发现,系统没有正常运行下去。通过直接操作串口寄存器进行输出打印,又发现串口输出是正常的。因此说明串口初始化正常,只是在调用某个接口的时候卡住了。
通过排查发现,在调用uartputc_sync接口时,陷入了一个死循环当中。原因在于此函数中使用了两个全局变量,当检测到其中一个变量非0时,则会陷入死循环。因此通过check之前代码,发现两个全局变量代码中并没有显式的在代码中赋初值,并且整个启动过程中并没有清除bss段,因此两个全局变量初始值可能本来就不为0。
所以在启动汇编代码中进行添加bss段清零操作:
cpp
_entry:
、、、、、、
add sp, sp, a0
jal clear_bss # bss段清零
# jump to start() in start.c
call start
clear_bss:
la t0, __bss_start
la t1, __bss_end
clbss_1:
sw zero, 0(t0)
addi t0, t0, 4
blt t0, t1, clbss_1
ret
spin:
j spin进行重新编译并运行后,串口出现如下打印:

至此说明串口初始化成功,可以进入下一阶段初始化了。(需要特别注意的是,此处进行bss段清零的操作并不规范,由于D1芯片是单核,所以这样清除不会发生异常;如果是一个多核CPU,则仅能使一个hart来进行bss清零,否则可能会产生异常。并且在自处清除bss段的目的在于,前面讲过,栈区位于bss段中,如果后面在c环境中进行清除bss段,则可能破坏栈区。)
五、内存管理分析
内存管理最小的单位是4KB,称其为1个页面;然后系统将维护一个链表,此链表就是由所有空闲页面组成,而内存管理的功能,就是管理这个链表,通过添加和删除这个链表来进行内存的分配。
在对D1移植xv6系统时,需要修改内存管理的基地址为0x4000_0000,同时管理内存的结束地址目前为0x4000_0000 + 128MB。
5.1、物理页分配器分析
调用kinit()函数进行物理页分配器的初始化。从代码中分析可以得出,其管理的物理内存空间范围为下图中,end向上对齐到4KB的地址为起始地址,0x4000_0000 + 128MB的地址为结束地址。在起始地址与结束地址之间的范围即为物理内存分配器管理的地址范围:
其代码内容如下:
cpp
void kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}
void kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
void *kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}- freerange函数:
- 完成对end~PHYSTOP之间物理地址的kfree;
- 首先对end地址进行4KB的地址对齐;
- 然后再将end~PHYSTOP之间的物理空间进行kfree,加入到空闲内存管理链表中;
- kfree函数:
- 首先对传入的物理地址进行错误判断,看其是否4KB对齐、是否存在内存越界情况;
- 然后再将其物理页中每个字节都置1;
- 然后将传入的物理地址的前8个字节物理空间填充为kmem.freelist的值;
- 最后再将kmem.freelist的值修改为传入的物理地址;
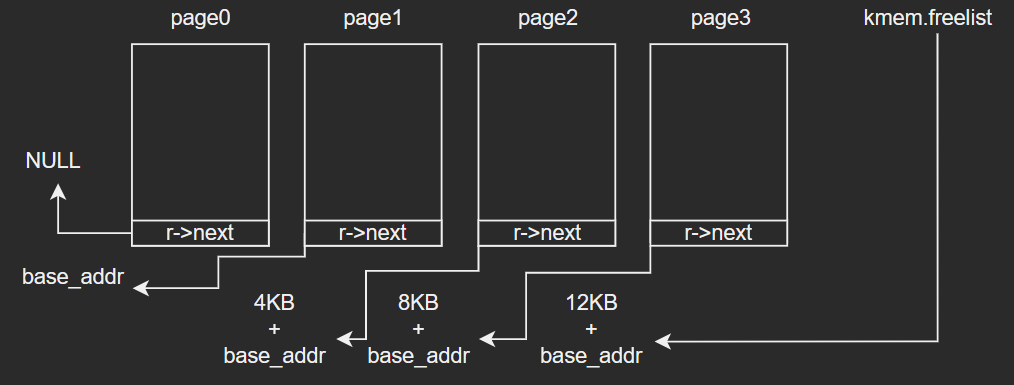
- kfree的过程就是得到一个需要释放的物理页基地址后,将此物理页的前8个字节填充为kmem.freelist指向的空闲物理页地址的值;然后再将kmem.freelist的值更新为释放后的物理页的基地址;
- kalloc函数:
- kalloc函数就和kfree函数是逆过程,原理基本一致,就不在赘述。
- 不过kalloc和kfree有一个很巧妙的设计思想在于:
- 在进行kfree时,整个需要释放的物理页,在理论上来说,在它的空间中存储的数据已经没有作用了,所以可以用它本身的物理空间来存储下一个空闲物理页的基地址;
- 而在进行kalloc时,需要将空闲物理页从链表中取出,而在取出时,r-next已经被赋值给了kmem.freelist,所以取出的物理页可以随意使用,而不用担心其中存储的下一个空闲物理页的基地址数据被覆盖掉。
其基本原理下图所示:
5.2、内核页表初始化分析
在开始分析内核页表初始化之前,先说明一下riscv的页表映射原理,我们以D1芯片为例来进行说明。
5.2.1、页表映射原理
D1芯片使用玄铁C906只支持Sv39虚拟内存系统(Sv39,3级分页,可访问到的内存空间达到512GB),也就是对于虚拟地址的寻址,其支持访问0x0000_0000_0000_0000~0x0000_003F_FFFF_FFFF与0xFFFF_FFC0_0000_0000~0xFFFF_FFFF_FFFF_FFFF两个虚拟地址区域(在mmu打开时)。
- Sv39模式下的页表转换原理:
- Sv39模式下的虚拟地址格式为:

- bit39~bit63为保留位,无效,将忽略;
- 低12bits为4KB内存页中的偏移量;
- 然后vpn2~vpn0,分别为2~0级别的索引值;
- 页表项格式如下所示:

- 此页表项一共有512个,每个页表项大小为8Byte,刚好占用一页4KB空间大小;
- 其转换原理如下图所示:
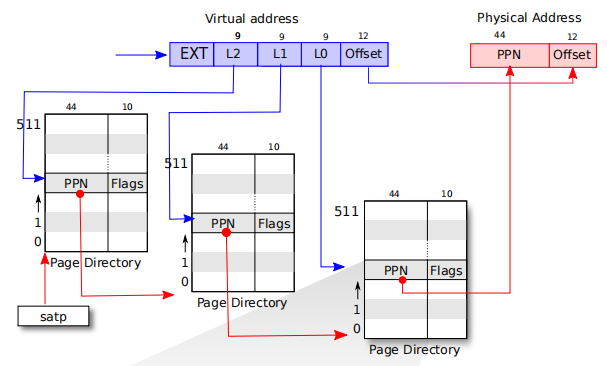
- satp寄存器存储了2级页表的基地址,当要对一个虚拟地址进行转换时,需要使用虚拟地址中的L2在2级页表中找到对应的1级页表的基地址;
- 然后再使用L1,在找到的1级页表中,寻找到对应的0级页表的基地址;
- 最后再使用L0,在找到的0级页表中,寻找到对应的物理页地址,再使用offset在此物理页中寻找到对应的数据。
- Sv39模式下的虚拟地址格式为:
- 子页表类型的页表项flag标志位意义:

- V:页表有效标志位,0是无效页表项;
- RWX:可读、可写、可执行属性,当它们全为0时,表示这是一个指向下一级页表的页表项;如果它们不全为0,则表示这是一个最终的页类型或块类型子页表项;
- A:为 1 时,表明该页被访问过;为 0 时表示没被访问过,对该页表的访问会触发 Page Fault (对应访问类型) 异常且将该域置为 1;(对于玄铁C906架构而言)
- D:为 1 时,当前页已经被写/可写;为 0 时当前页未被写/不可写;此位在 C906 的硬件实现与 W 属性类似。当 D 位为 0 时,对此页面进行写操作会触发 Page Fault(store) 异常,通过在异常服务程序中配置 D 位来维护该页面是否已经被改写/可写的定义;(对于玄铁C906架构而言)
- 在进行xv6系统移植时,特别注意A、D属性位,在进行页表映射时,需将其置位,否在设置完页表后,会立即产生缺页异常;这就是系统中缺页异常的原理,即先分配虚拟地址,产生缺页异常分配物理地址后,在设置A、D属性位;(对于玄铁C906架构而言)
- satp寄存器:

- MODE:用于控制cpu使用那种模式,Sv39、Sv48或者关闭mmu使用物理地址;
- ASID:进程地址空间标识符;
- PPN:物理页编号,存储最高级页表的基地址(物理地址总宽度为56 = 44 + 12);
需要注意的是,当cpu处于m模式(即机器模式)时,是不会使用虚拟地址的(即使设置了satp页表基地址寄存器),cpu直接进行物理地址寻址,页表转换此时无效。
5.2.2、xv6页表初始化
对于页表的初始化,分析如下一个函数就知道页表是如何进行赋值的:
cpp
pte_t *walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
// pagetable是L2页表的物理基地址,通过如下循环将找到L0页表中va对应的PTE内存地址
for(int level = 2; level > 0; level--) {
// 首先利用虚拟地址va检查当前等级页表中对应的PTE是否有效
pte_t *pte = &pagetable[PX(level, va)];
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
// 如果PTE无效,则kalloc分配一个page的物理内存做次级页表
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
memset(pagetable, 0, PGSIZE);
// 对次级页表中的PTE进行初始化,并设置其有效属性
*pte = PA2PTE(pagetable) | PTE_V;
}
}
// 得到最后一级L0页表后,找出va对应的PTE,并返回其地址
return &pagetable[PX(0, va)];
}通过如上函数,可以找到3级页表中,L0页表中对应虚拟地址的页表项PTE地址,并且将此地址返回后,上级函数可以对其进行物理页帧和访问属性的设置。如:
cpp
*pte = PA2PTE(pa) | perm | PTE_V | PTE_A | PTE_D;PA2PTE宏的作用是将pa物理地址转换为PTE中对应位域的物理页帧号,perm是页表项中的flag设置(也就是访问属性),PTE_V宏是1(代表设置此PTE有效),PTE_A与PTE_D一定要设置,否则使能mmu后,将立即产生缺页异常。(对于玄铁C906架构而言)
需要注意的是,xv6对页表进行初始化时,都是使用3级页表来进行映射的(4KB大小为单位进行映射),并没有使用巨页或最大页,当进行大空间映射时,其实是比较消耗内存资源的。
5.2.3、xv6页表使能
首先修改映射表,将CLINT寄存器进行恒等映射,因为之后会操作其中的定时器比较寄存器;同时修改之前进行映射的串口、PLIC等空间的实际物理地址,使其与D1芯片一致:
cpp
pagetable_t
kvmmake(void)
{
pagetable_t kpgtbl;
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
// UART0寄存器基地址与范围修改为D1芯片的实际地址与大小
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
// D1芯片实际应该没有使用
//kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// 新增CLINT寄存器映射,需使用其中的定时器比较寄存器,映射大小64KB
kvmmap(kpgtbl, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
// PLIC寄存器基地址与范围修改为D1芯片的实际地址与大小
kvmmap(kpgtbl, PLIC, PLIC, 0x300000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
// allocate and map a kernel stack for each process.
// 映射64个内核进程栈(每个4KB大小)到虚拟地址
proc_mapstacks(kpgtbl);
return kpgtbl;
}最后调用kvminithart()函数,将L2页表的基地址设置到satp寄存器中:
cpp
// use riscv's sv39 page table scheme.
#define SATP_SV39 (8L << 60)
// 组合生成stap寄存器的值,设置为Sv39模式以及转换页表的物理地址为物理页帧号
#define MAKE_SATP(pagetable) (SATP_SV39 | (((uint64)pagetable) >> 12))
void kvminithart()
{
// wait for any previous writes to the page table memory to finish.
sfence_vma();
w_satp(MAKE_SATP(kernel_pagetable));
// flush stale entries from the TLB.
sfence_vma();
}通过如上一系列初始化与配置之后,页表便生效了。虽然使用的寄存器地址仍然与物理地址一致,但实际上已经开始使用虚拟地址来对寄存器进行访问了。
六、进程初始化
cpp
void procinit(void)
{
struct proc *p;
initlock(&pid_lock, "nextpid");
initlock(&wait_lock, "wait_lock");
for(p = proc; p < &proc[NPROC]; p++) {
initlock(&p->lock, "proc");
p->state = UNUSED;
p->kstack = KSTACK((int) (p - proc));
}
}主要完成自旋锁的初始化、进程状态设置以及进程内核栈的初始化。(目前静态创建了64个空闲进程,最大也仅支持64个进程)
对进程的内核栈分配了2个page大小的虚拟地址空间。
七、中断异常分析
首先设置监管模式下临时的trap入口:(stvec寄存器设置的应该是hart能够正常寻址的地址。即mmu开启后,设置虚拟地址;mmu开启前,设置物理地址)
cpp
void trapinithart(void)
{
w_stvec((uint64)kernelvec);
}将汇编xv6-riscv\kernel\kernelvec.S文件中的kernelvec函数设置为S模式下的trap入口,当用户模式下发生中断或异常时,将进入kernelvec进行异常中断处理。
接着调用plicinit()与plicinithart()函数完成PLIC外设中断控制器的初始化,其主要作用是设置uart0串口中断的优先级与使能等。
7.1、kernelvec入口函数分析
进入kernelvec后,首先做的事情是入栈,将调用者保存类型的通用寄存器压入sp栈中,然后再调用kerneltrap函数,进行中断处理。
cpp
void kerneltrap()
{
int which_dev = 0;
uint64 sepc = r_sepc();
uint64 sstatus = r_sstatus();
uint64 scause = r_scause();
// 获取cpu状态与中断使能情况,判断是否为panic情况
if((sstatus & SSTATUS_SPP) == 0)
panic("kerneltrap: not from supervisor mode");
if(intr_get() != 0)
panic("kerneltrap: interrupts enabled");
// 调用devintr函数,获取中断类型,目前仅能处理S模式下的外部中断与定时器中断类型
if((which_dev = devintr()) == 0){
// interrupt or trap from an unknown source
// 如果产生的是异常或软件中断,则陷入panic
printf("scause=0x%lx sepc=0x%lx stval=0x%lx\n", scause, r_sepc(), r_stval());
panic("kerneltrap");
}
// give up the CPU if this is a timer interrupt.
if(which_dev == 2 && myproc() != 0)
yield();
// the yield() may have caused some traps to occur,
// so restore trap registers for use by kernelvec.S's sepc instruction.
w_sepc(sepc);
w_sstatus(sstatus);
}上述代码中需要注意devintr函数,它的功能就是一个中断分发器,识别外部中断和定时器中断;如果发生外部中断,则读取PLIC控制器中的中断类型,进行对应外部中断的处理;如果发生定时器中断,则重新设置定时器比较值;如果两则都不是,则什么都不做,并返回0。
当devintr返回0时,则系统进入panic。
当devintr返回2时,则进行进程调度等操作。关于进程调度的相关内容,后续还会进行详细说明。
7.2、CLINT与PLIC
D1芯片的中断框图如下所示:

外部中断通过PLIC触发给CPU,而软件中断和定时器中断可以由CLINT直接触发CPU。
- 通过medeleg 和mideleg寄存器可以将异常和中断委托给S模式来执行(因为默认异常和中断都会先进入M模式,如果未设置中断代理的话),前面已经做过详细的说明。
- 通过mcause/scause寄存器可以获取到中断异常类型。其中最高位为1时,代表产生的是中断;最高位为0时,代表产生的是异常;其中外部中断(比如中断号9、11)来源由PLIC中断控制器提供,同时其子中断号(如挂接在PLIC上的spi、i2c等外设)则通过PLIC寄存器提供:
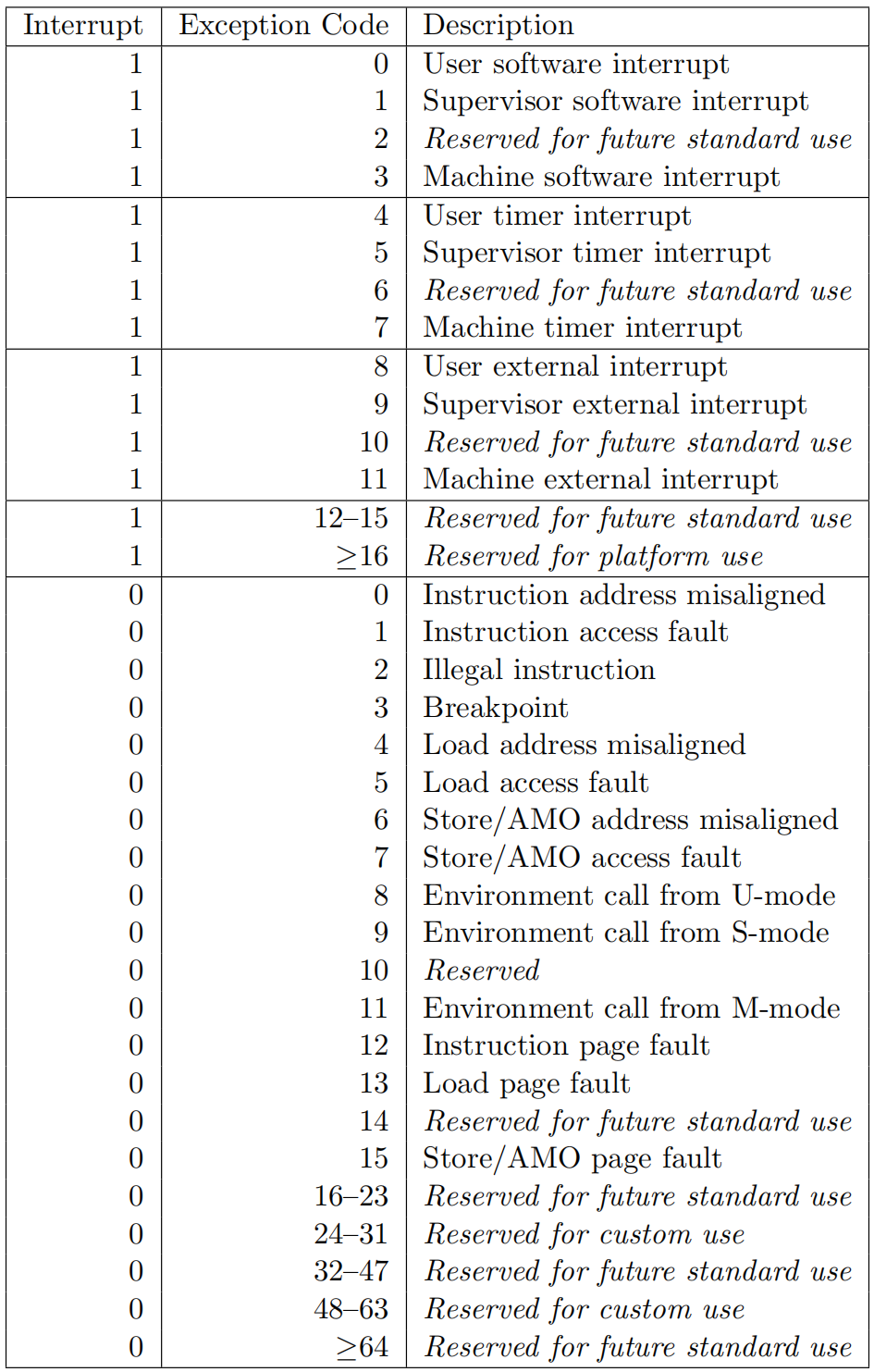
- 当发生trap时(假设已经设置了中断代理给S模式):
- riscv硬件完成如下工作:
- u-mode ---》 s-mode
- disable interrupts
- PC寄存器 ---》 sepc寄存器(这里需注意一下,如果是中断,则写入sepc的地址为PC+4;如果是异常,则写入sepc的地址就为PC)
- stvec寄存器 ---》 PC寄存器
- riscv硬件完成如下工作:
- 当发生sret时(假设已经设置了中断代理给S模式):
- riscv硬件完成如下工作:
- s-mode ---》 u-mode
- sepc寄存器 --- 》 PC寄存器
- enable interrupts
- riscv硬件完成如下工作:

八、进程调度分析
调用userinit(void)函数,进行init进程初始化。我们首先来看看此函数完成了那些工作:
cpp
void userinit(void)
{
struct proc *p;
p = allocproc();
initproc = p;
p->cwd = namei("/");
p->state = RUNNABLE;
release(&p->lock);
}- 从初始64个定义好未使用的进程中分配1个出来做init初始进程;
- 将进程状态设置为RUNNABLE;
- 上述看似初始化很简单,但是在allocproc中已经将进程初始化完成,并且在initproc进程第一次被调度时,将在文件系统中寻找init程序,执行控制台shell功能。
上述代码仅将initproc进程进行了初始化,后续将手动调用scheduler()函数完成当前hart对xv6进程调度系统的启动。scheduler函数如下所示:
cpp
void scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
intr_on();
intr_off();
int found = 0;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
c->proc = 0;
found = 1;
}
release(&p->lock);
}
if(found == 0) {
asm volatile("wfi");
}
}
}- 进入一个调度系统的无限循环中;
- 从64个进程中,寻找已经准备就绪态的进程,即RUNNABLE状态的进程;如果所有进程都处于未就绪态,则执行wfi指令进行短暂休息,然后再投入到下一次循环中;
- 如果找到RUNNABLE状态进行,如上面刚刚就绪的initproc进程,则将其设置为RUNNING态,排除其他hart执行它;同时将此进程绑定到当前hart上(c->proc = p;),并将hart的上下文切换到进程的上下文中去(swtch(&c->context, &p->context););
- 等待定时器完成一次时间片调度或进程自己执行调度,则将当前进程执行的上下文保存到进程结构体中,并还原hart在步骤3时的上下文,使hart继续寻找就绪态进程;
同时这里需要注意一下使用自旋锁的小技巧:

- 在得到进程后,要访问它的资源时,需要先获取到它的自旋锁;
- 当判断到此进程处于就绪态,那么将hart正在运行的进程设置为此进程,并将此进程设置为运行态;
- 最后再进行swtch切换;
- 切换到进程后,会对hart正在执行的进程进行自旋锁的释放,使其他hart能正常进行进程调度;
通过上述分析,基本了解进程调度原理了,当两个进程发生调度时,切换流程大致如下图所示:
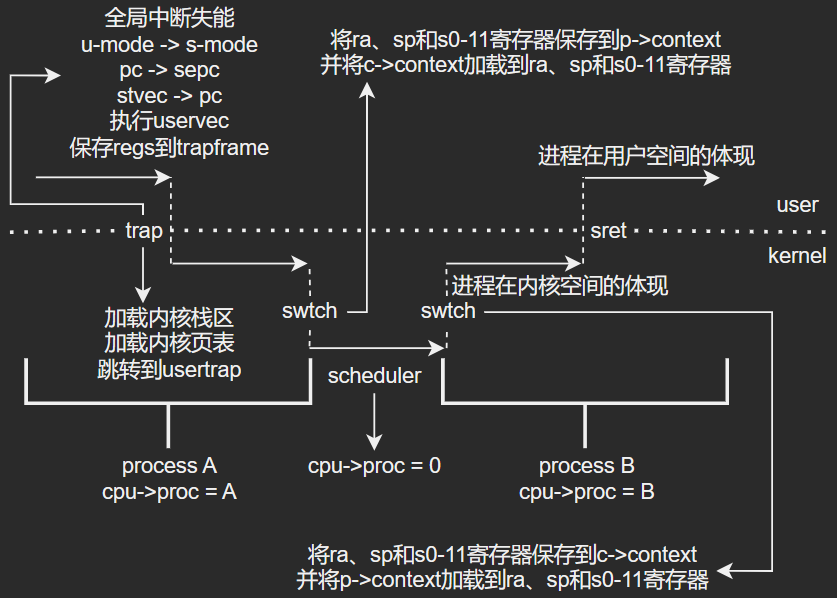
8.1、进程分配原理分析
进程分配接口函数是allocproc(),其作用为:
- 在进程池中寻找到一个UNUSED状态的进程;
- 为其分配pid、设置USED状态,并为其分配trapframe与用户进程页表内存空间;
- 初始化页表和进程上下文(即设置进程的内核态栈区和返回用户态入口forkret函数);
8.1.1、内核、进程虚拟地址空间布局
分配出来的进程虚拟地址布局基本如下图所示:(对于上面所说的initproc进程来说有点特殊,其代码段加栈区加起来一共就4KB,并放在进程空间的虚拟地址0处)
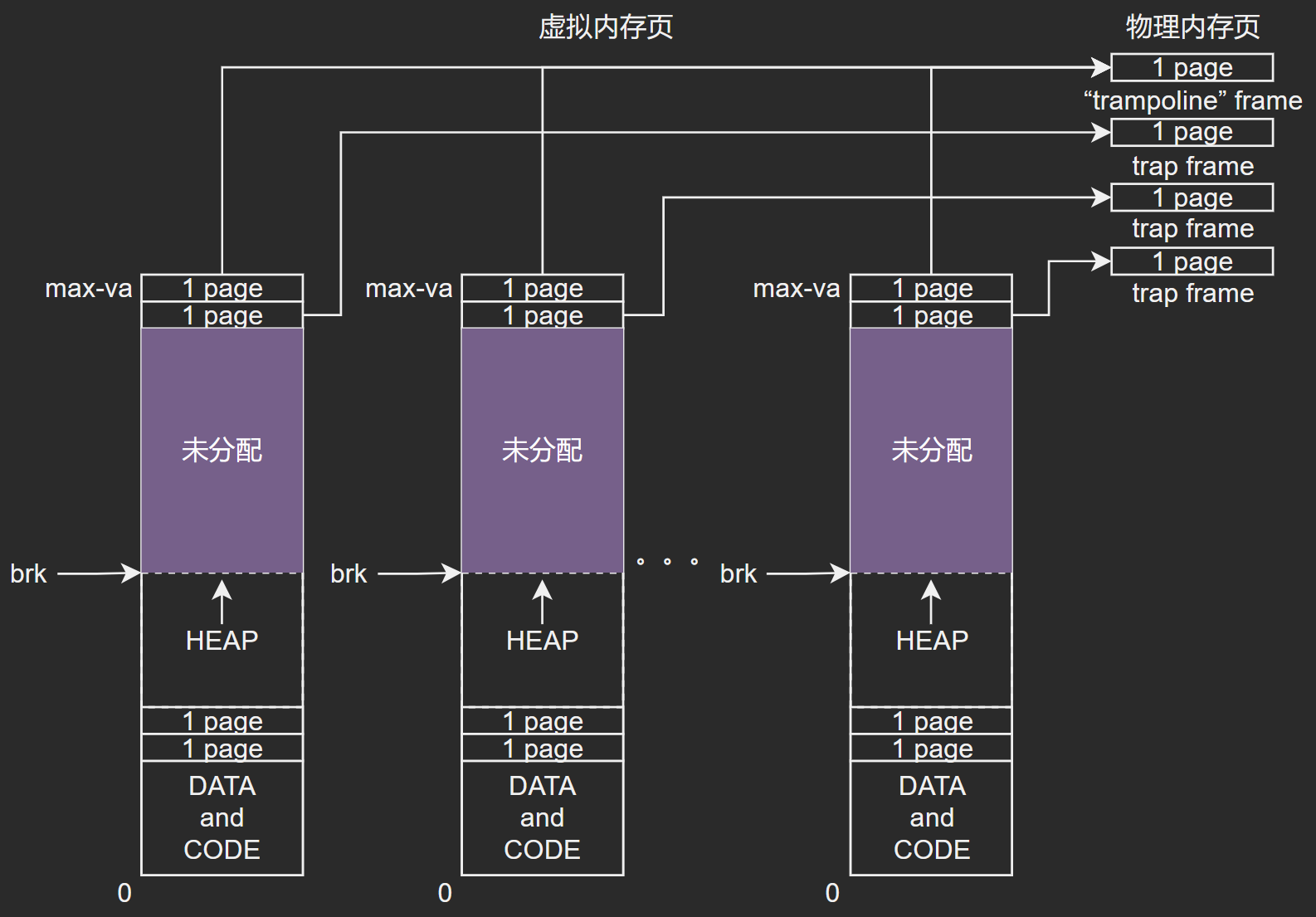
- 每个用户进程都有一个专属的虚拟地址空间;
- 并且每个用户进程的虚拟地址空间的布局都是相同的,只不过堆、栈等的地址可能不一致;
- 而对于内核来说,它只有一个虚拟地址空间,内核中所有代码都共用同一套虚拟地址空间;
其中进程分配时,初始就会创建两个page页映射,并且地址在最高的两个page处:
- trampoline page:
- 此页位于进程虚拟空间的高地址首页;
- 所有进程都拥有此虚拟地址的映射关系,并且映射到同一个物理页,此处是一段内核代码段,所以拥有执行权限,且用户模式不可访问;
- 其中包含了一些代码,如:uservec和userret;
- uservec和userret代码被映射到了每一个进程的虚拟地址空间的高位首页,以及内核虚拟地址空间的高位首页;
- 其为监管者模式下的trap入口;
- trapframe page:
- 此页面对应的物理页对于每个进程来说是独有的,每个进程都有自己的一个独有物理页来映射到虚拟地址上;
- 此页中的内容包含了数据以及通用寄存器保存区域,因为要保存自己的数据,所以需要自己的一个独立物理页来进行保存;
- 其属性为可读可写以及用户模式不可访问。
通过上述的分析,我们大致可以得出进程虚拟地址空间、内核虚拟地址空间以及物理地址空间的对应关系如下图所示:(下图为qemu时所画的地址关系对应图,因此物理地址实际可能与D1不相符)
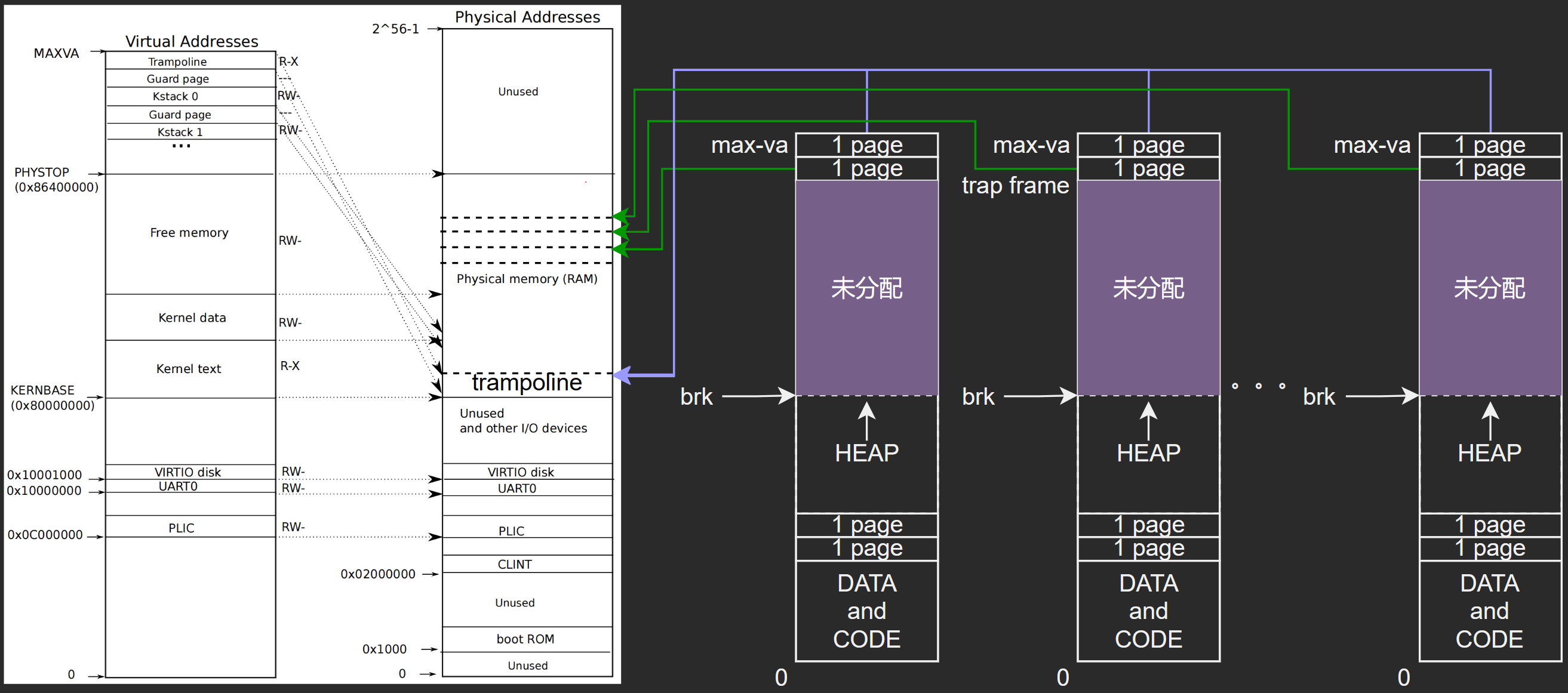
通过上图也可以看出,内核虚拟地址与物理地址之间大部分直接做了恒等映射,只有 trampoline代码段 与 为每个进程分配的内核栈 采用了非恒等的线性映射。而进程虚拟地址的低位地址处分配出来的内存则在用户模式下可以进行访问。
8.1.2、init进程上下文初始化
通过以下代码,完成init进程上下文的初始化。
cpp
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;- 当hart切换到进程的context上下文并进行ret返回时,将执行ra寄存器中保存的地址;
- 此时执行的环境仍然是内核的监管者模式,同时使用了进程的kstack内核栈区。
还记得《八、进程调度分析》章节中的分析吗?
cpp
# Context switch
#
# void swtch(struct context *old, struct context *new);
#
# Save current registers in old. Load from new.
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret- scheduler()函数中将调用上述代码,如果是initproc进程,在完成ret后,则将跳入forkret函数中运行;
- forkret函数在第一次执行时,会读取文件系统中的init程序,并最终创建执行sh进程完成shell的初始化。
8.1.3、用户程序加载运行分析
以init进程为例进行分析,一步一步拆解在S模式下的hart是如何返回到U模式进行应用程序的运行的。
cpp
void forkret(void)
{
extern char userret[];
static int first = 1;
struct proc *p = myproc();
release(&p->lock);
if (first) {
fsinit(ROOTDEV);
first = 0;
__sync_synchronize();
p->trapframe->a0 = kexec("/init", (char *[]){ "/init", 0 });
if (p->trapframe->a0 == -1) {
panic("exec");
}
}
prepare_return();
uint64 satp = MAKE_SATP(p->pagetable);
uint64 trampoline_userret = TRAMPOLINE + (userret - trampoline);
((void (*)(uint64))trampoline_userret)(satp);
}- 首先调用kexec接口,从文件系统中读取init可执行elf文件;
- 同时解析elf头,分配用户空间内存,并将init程序拷贝到用户空间内存中;
- 最后再将用户空间程序入口地址等信息赋值给进程结构体中。
如下部分代码所示:
cpp
oldpagetable = p->pagetable;
p->pagetable = pagetable; // 赋值新创建的页表
p->sz = sz; // 进程代码段+栈空间大小
p->trapframe->epc = elf.entry; // 进程应用代码入口地址传入p->trapframe->epc
p->trapframe->sp = sp; // 用户空间栈顶赋值
proc_freepagetable(oldpagetable, oldsz); // 释放进程之前的页表- 然后调用prepare_return()函数,进行S模式下异常向量入口(即为uservec)设置,同时将内核页表地址、进程内核栈地址、usertrap函数地址等保存到进程trampframe帧结构体中;
- 设置SPP域为user模式,以及SPIE置1(代表S模式降级到U模式后,S模式下中断将开启);
- 最后将进程应用程序的入口地址设置到sepc中,调用sret后,将跳转到sepc中的地址处;
代码如下所示:
cpp
void prepare_return(void)
{
struct proc *p = myproc();
intr_off();
uint64 trampoline_uservec = TRAMPOLINE + (uservec - trampoline);
w_stvec(trampoline_uservec);
p->trapframe->kernel_satp = r_satp(); // kernel page table
p->trapframe->kernel_sp = p->kstack + PGSIZE; // process's kernel stack
p->trapframe->kernel_trap = (uint64)usertrap;
p->trapframe->kernel_hartid = r_tp(); // hartid for cpuid()
unsigned long x = r_sstatus();
x &= ~SSTATUS_SPP; // clear SPP to 0 for user mode
x |= SSTATUS_SPIE; // enable interrupts in user mode
w_sstatus(x);
w_sepc(p->trapframe->epc);
}- 最后再调用userret汇编入口,进行S模式返回到U模式下,并跳转到sepc中的地址处执行。
代码如下:
cpp
userret:
sfence.vma zero, zero
csrw satp, a0
sfence.vma zero, zero
li a0, TRAPFRAME
# restore all but a0 from TRAPFRAME
ld ra, 40(a0)
ld sp, 48(a0)
ld gp, 56(a0)
ld tp, 64(a0)
ld t0, 72(a0)
ld t1, 80(a0)
ld t2, 88(a0)
ld s0, 96(a0)
ld s1, 104(a0)
ld a1, 120(a0)
ld a2, 128(a0)
ld a3, 136(a0)
ld a4, 144(a0)
ld a5, 152(a0)
ld a6, 160(a0)
ld a7, 168(a0)
ld s2, 176(a0)
ld s3, 184(a0)
ld s4, 192(a0)
ld s5, 200(a0)
ld s6, 208(a0)
ld s7, 216(a0)
ld s8, 224(a0)
ld s9, 232(a0)
ld s10, 240(a0)
ld s11, 248(a0)
ld t3, 256(a0)
ld t4, 264(a0)
ld t5, 272(a0)
ld t6, 280(a0)
ld a0, 112(a0)
sret主要完成了3步操作:
- 将页表切换到了进程的用户空间页表;
- 恢复用户空间的上下文到hart;
- 调用sret返回到用户模式下执行应用程序。
其中切换页表时能正常运行程序,完全归功于此部分代码都映射到了内核页表与进程页表中的同一虚拟地址上;所以在切换页表时,能无感切换,正常执行指令。
8.2、进程调度流程总结
所以一个进程从用户模式下发生定时器中断调度时,其流程如下所示:
- 用户模式下,发生定时器调度trap时的逻辑如下:
- 1、hart发生trap,全局中断失能,u-mode--》s-mode,pc--》sepc,stvec--》pc;
- 2、进入stvec,而stvec的值是汇编代码中uservec标签的地址:
- a、将31个通用寄存器的值存储到 MAXVA - 2*PGSIZE 地址空间处;
- b、设置sp为内核栈地址,tp为对应hart号,t0为usertrap()函数地址,satp为内核页表;
- c、跳转到t0地址处,也就是跳转到usertrap()函数开始执行;
- 3、将stvec更新为kernelvec函数;(为了在内核空间中执行系统调用时,能够响应中断与异常)
- 4、得到当前hart正在执行的proc进程;
- 5、sepc--》p->trapframe->epc,将sepc保存到trapframe中;
- 6、接着判断是trap是ecall异常还是中断?
- a、ecall异常:
- p->trapframe->epc += 4,因为是异常,所以sepc的值,需要加一个指令长度(4字节);
- 为了能够在进行系统调用时响应中断,此时使能全局中断 intr_on();
- 最后再调用syscall(),完成系统调用功能函数的执行;
- b、中断:
- 执行devintr()函数,完成中断处理;
- a、ecall异常:
- 7、give up the CPU if this is a timer interrupt,完成进程调度;
- ==========================调入调出分界线==========================
- 8、执行prepare_return()函数,进行从内核空间退回到用户空间的准备工作:
- a、获取到当前hart正在执行的proc进程;
- b、关闭中断,并将完成uservec--》stvec的更新;
- c、更新trapframe区域中的内核页表、内核栈、内核trap以及hartid等内容;
- d、设置sstatus寄存器的SPP域为user模式,以及SPIE置1(代表S模式降级到U模式后,S模式下中断将开启);
- e、p->trapframe->epc--》sepc,将sepc的值进行恢复;
- f、完成userret函数的调用;
- 9、进入到userret函数:
- a、完成用户空间页表的恢复;
- b、从 MAXVA - 2*PGSIZE 空间中,完成对通用寄存器值的恢复;
- c、sret,完成从监管模式到用户模式的返回;
- 全局中断使能,s-mode--》u-mode;
- 10、回到用户空间,继续进行代码的执行;
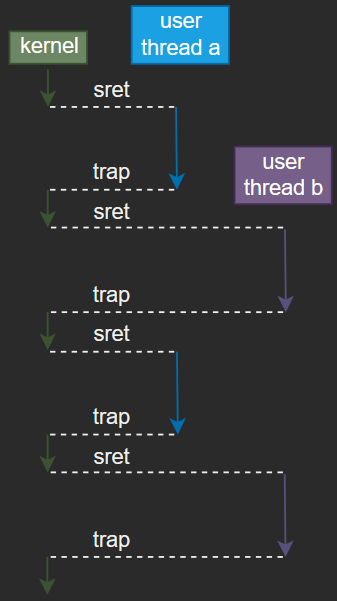
一个hart上运行多进程的情况就如上图所示。
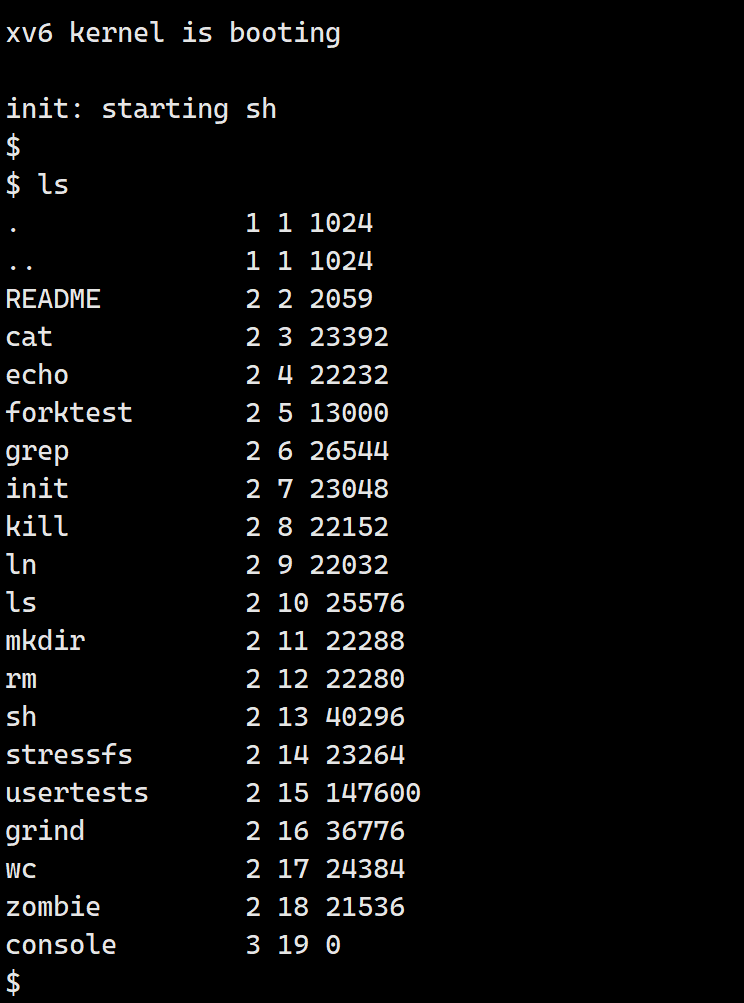
至此,整个xv6系统的移植与分析就已经完成了,在D1芯片上运行的结果如下所示:
后续还有一些关于自旋锁、系统调用、sleep以及wakeup等的实现,将在后面进行分析。