在看 Transformer 的 self-attention 结构时,很多人第一次见到 ( Q, K, V ) 三个矩阵都会有点疑惑:
明明输入就是一个向量序列,为什么还要多此一举做三次线性变换 ?
而且最后还要套上一个 Softmax,这又是在干什么?
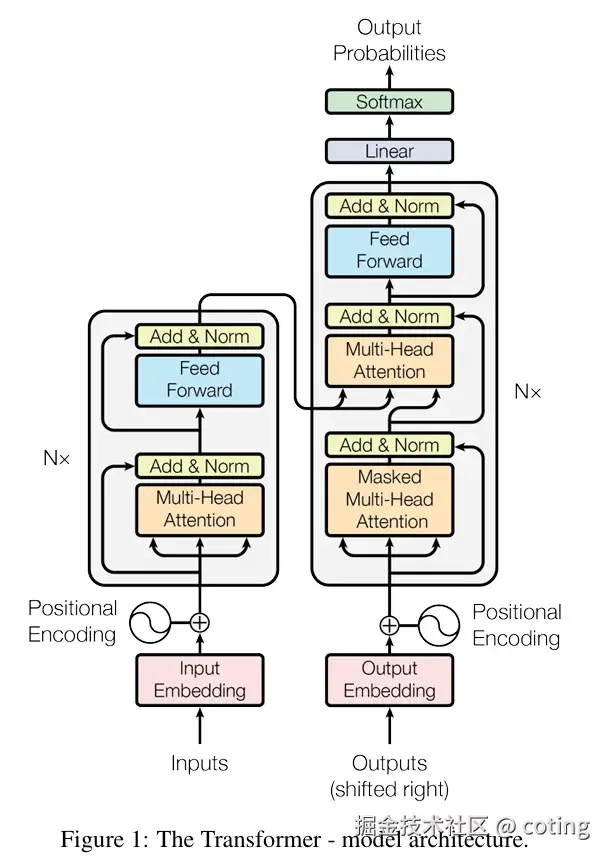
这两个问题,其实是理解注意力机制的核心关键。
我们从最直观的角度来拆开看。
所有相关源码示例、流程图、面试八股、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!
一、为什么要 Q、K、V?
假设我们有一个输入序列: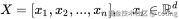
每个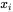 就是一个 token 的 embedding,比如一个词、一个字、或者一个图像 patch。
就是一个 token 的 embedding,比如一个词、一个字、或者一个图像 patch。
如果我们直接用这些 之间做点积:
它确实能反映出两个 token 的相关性(越大越相关),但存在两个致命问题:
- 每个 token 的表示是静态的 :输入 embedding 没有区分谁在关注别人 还是被别人关注。
- 无法表达不同的关注模式:所有 token 的关系都被一个固定空间描述,模型无法灵活学习不同角度的相似性。
于是就引出了 Q、K、V 的设计。
二、Q、K、V 的线性变换在干什么?
1.投影到不同子空间
输入的特征维度是 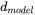 ,每个 token 的 embedding 包含所有语义信息。
,每个 token 的 embedding 包含所有语义信息。
直接用原始 embedding 做 Q/K/V,相当于在同一个空间计算相似度,模型无法学习不同语义关系的权重。
我们把输入 ( X ) 分别线性变换成三种表示:
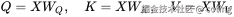
- Query(查询):表示我想关注什么信息
- Key(键):表示我是什么样的信息
- Value(值):表示我携带的信息内容
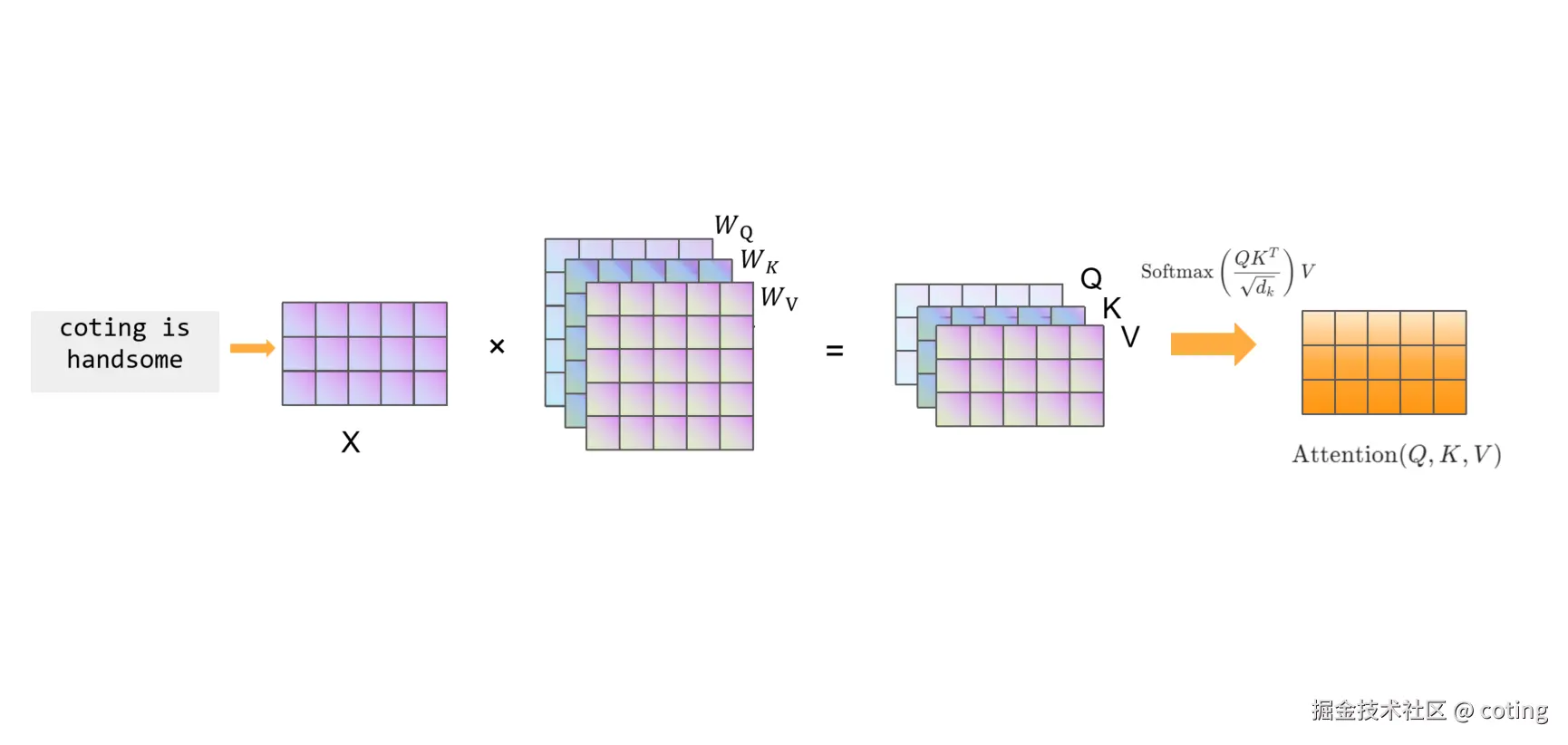
这三个矩阵其实是从同一个输入 (X) 投影出来的三种视角 。
这一步的作用,就是让模型在不同子空间中理解 token 之间的关系。
举个简单的例子:
在一句话中,"他吃了一个苹果",
"他"这个词(Query)可能更关注"吃"这个动词,而"吃"这个词(Key)可能更多地被名词吸引。
通过三组独立的线性变换,模型可以学习到这种不同角色的匹配关系。
所以你可以这样理解,Q 是注意力的提问方式 ,K 是信息的身份描述 ,V 是最终被提取的信息内容。
2.支持多头注意力
多头注意力把 Q/K/V 切分成多个头,每个头关注不同子空间的特征。
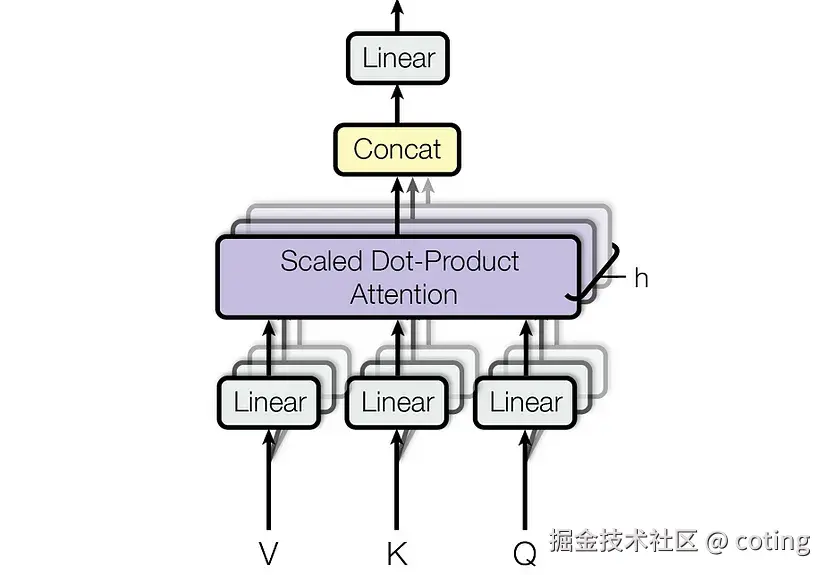
如果没有线性变换,每个头得到的还是原始 embedding,无法学习多角度关系。
线性投影允许每个 head 独立学习一套查询/键/值表示,提升模型表达能力。
公式:
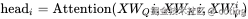
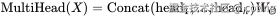
3.增加可学习参数
每个线性变换 W_Q, W_K, W_V都是 可训练权重,模型可以自动学习如何对不同 token 的 embedding 做不同的查询、匹配和加权。
这使得 self-attention 不只是一个固定的相似度计算,而是一个 可调节、可优化的语义匹配函数。
4.便于下游操作
QK^T 计算的是注意力权重,如果不做线性变换,模型只能依赖原始 embedding 的内积,这种相似度空间不一定适合 softmax 加权。
线性变换可以把 embedding 投影到更适合做注意力匹配的空间,提高学习能力。
三、Q 与 K 的点积
拿到 Q 和 K 后,self-attention 计算的是每个 Query 与所有 Key 的相似度:

这里的点积代表匹配程度,即:
- Q_i 表示第 i 个 token 想关注的信息;
- K_j 表示第 j 个 token 所包含的信息;
- 它们的点积越大,说明第 i 个 token 越应该关注第 j 个 token。
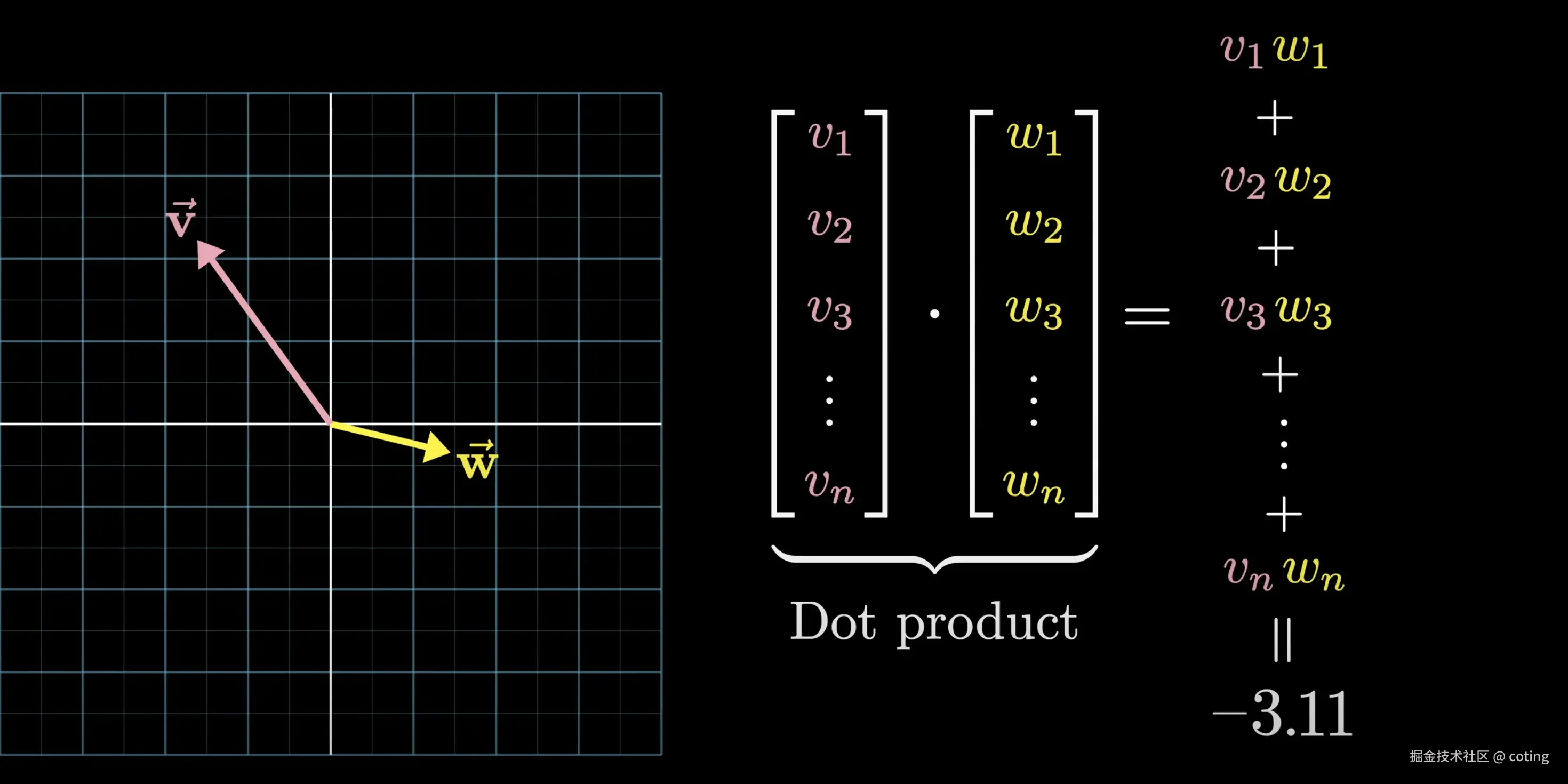
从计算上看,点积是将所有的对齐分量相乘并累加;从几何上看,当向量指向相似方向时,点积为正,如果向量垂直,点积为0,当向量方向相反时则为负数。
这样,我们就得到了一个注意力分数矩阵,表示每个 token 对其他 token 的注意力权重。
四、为什么要用 Softmax?
问题来了:我们已经有了相似度分数,为什么还要再过一遍 Softmax?
其实原因很简单:
- 把"相似度"变成"权重分布"
点积结果可以是任意实数,而 Softmax 会把它们压缩到 ( 0, 1 ) 区间,并且所有权重之和为 1。
这让注意力分数能被解释为概率分布,即模型在关注谁、关注多少。

- 放大强关注、削弱弱关注
Softmax 有指数特性,会让大的分数更大、小的分数更小,从而突出主导注意力。
这在语义建模中非常关键------模型不会平均地看所有 token,而是能聚焦重点。 - 梯度稳定性
如果直接用点积做加权,分数可能过大或过小,导致梯度不稳定。
Softmax 保证了数值范围可控,梯度传播更平滑。
最后一步,把注意力权重乘上 Value:

就得到了每个 token 根据上下文动态加权后的新表示。
总结一下,Q、K、V 的线性变换是为了让模型从同一输入中生成不同功能的向量表示,分别负责提问、匹配和传递信息,增强模型的表达灵活性。
Softmax 的作用则是把相似度分数转成稳定的注意力分布,突出重点并保证梯度可训练。
📚 推荐阅读
● Transformer------Attention怎么实现集中注意力
● Transformer------FeedForward模块在干什么?
● Transformer注意力机制------MHA&MQA&GQA
● 面试官:BatchNorm、LayerNorm、GroupNorm、InstanceNorm 有什么本质区别?
● FlashAttention2:更快的注意力机制,更好的并行效率
● FlashAttention3 全解析:速度、精度、显存的再平衡
● Transformer 中为什么用LayerNorm而不用BatchNorm?
关于深度学习和AI大模型相关的知识和前沿技术更新,请关注公众号 aicoting!