掌握了集合框架和泛型,在处理集合数据时(如筛选、排序、映射、统计),传统的循环遍历方式代码繁琐且可读性差。今天要学习的Stream 流(Java 8 + 核心特性)正是为解决这个问题而生 ------ 它以 "声明式" 风格操作集合,让代码更简洁、更易读,还能轻松实现并行处理提升性能。本文会从 Stream 的核心概念、常用操作、流式编程思想,到实战场景,帮你彻底掌握 Stream 流的使用!
一、Stream 流的核心价值:为什么不用循环而用 Stream?
1. 传统集合操作的痛点
处理集合数据时,传统的 for / 增强 for 循环存在以下问题:
- 代码繁琐:多步操作(筛选→映射→排序→统计)需要嵌套循环,代码层级深;
- 可读性差:循环逻辑与业务逻辑混杂,难以一眼看出代码意图;
- 难以并行:手动实现并行循环复杂且容易出错;
- 不可复用:循环逻辑耦合度高,难以抽离复用。
示例:传统循环处理集合(问题演示)
java
运行
java
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
// 学生类
class Student {
private String name;
private int age;
private double score;
public Student(String name, int age, double score) {
this.name = name;
this.age = age;
this.score = score;
}
// getter
public String getName() { return name; }
public int getAge() { return age; }
public double getScore() { return score; }
}
public class TraditionalCollectionDemo {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
students.add(new Student("张三", 18, 90.5));
students.add(new Student("李四", 19, 85.0));
students.add(new Student("王五", 18, 95.5));
students.add(new Student("赵六", 20, 80.0));
// 需求:筛选18岁的学生 → 提取姓名 → 按姓名排序 → 输出
// 1. 筛选18岁的学生
List<Student> age18Students = new ArrayList<>();
for (Student s : students) {
if (s.getAge() == 18) {
age18Students.add(s);
}
}
// 2. 提取姓名
List<String> names = new ArrayList<>();
for (Student s : age18Students) {
names.add(s.getName());
}
// 3. 排序
Collections.sort(names);
// 4. 输出
for (String name : names) {
System.out.println(name);
}
}
}2. Stream 流的核心解决思路
Stream 流是对集合数据的 **"流水线式" 操作 **,核心特点:
- 声明式编程:只关注 "做什么",不关注 "怎么做"(无需写循环);
- 链式调用:多个操作串联成一条流水线,代码简洁;
- 惰性求值:中间操作(如 filter、map)不会立即执行,只有终端操作(如 forEach、collect)触发时才执行;
- 可并行 :只需调用
parallelStream()即可实现并行处理,无需手动处理线程; - 无副作用:不修改原集合,操作结果生成新数据。
示例:Stream 流处理集合(解决问题)
java
运行
java
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class StreamBasicDemo {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
students.add(new Student("张三", 18, 90.5));
students.add(new Student("李四", 19, 85.0));
students.add(new Student("王五", 18, 95.5));
students.add(new Student("赵六", 20, 80.0));
// Stream流实现:筛选18岁→提取姓名→排序→输出
List<String> result = students.stream()
.filter(s -> s.getAge() == 18) // 筛选18岁学生
.map(Student::getName) // 提取姓名(方法引用)
.sorted() // 排序
.collect(Collectors.toList()); // 收集结果
// 输出
result.forEach(System.out::println);
}
}二、Stream 流的核心概念与操作流程
1. 核心概念
| 概念 | 说明 |
|---|---|
| 流的来源 | 集合(Collection)、数组、I/O、生成器等(最常用是集合) |
| 中间操作 | 对数据进行处理(筛选、映射、排序等),返回新流,惰性执行 |
| 终端操作 | 触发流的执行,生成结果(如集合、数值、void),流执行后关闭 |
| 并行流 | 基于 Fork/Join 框架的并行处理流,适合大数据量处理 |
2. 流的操作流程
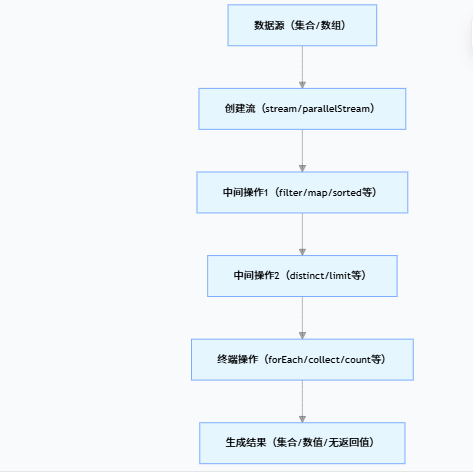
3. 流的创建方式
方式 1:集合创建流(最常用)
java
运行
java
List<String> list = new ArrayList<>();
// 串行流
Stream<String> stream = list.stream();
// 并行流
Stream<String> parallelStream = list.parallelStream();方式 2:数组创建流
java
运行
java
String[] array = {"Java", "Python", "C++"};
Stream<String> stream = Arrays.stream(array);
// 或
Stream<String> stream2 = Stream.of(array);方式 3:创建空流 / 单个元素流 / 无限流
java
运行
java
// 空流
Stream<String> emptyStream = Stream.empty();
// 单个元素流
Stream<String> singleStream = Stream.of("Java");
// 无限流(生成10个随机数)
Stream<Double> randomStream = Stream.generate(Math::random).limit(10);三、Stream 流的常用操作
1. 中间操作(惰性执行)
| 操作 | 作用 | 示例 |
|---|---|---|
filter(Predicate<T>) |
筛选符合条件的元素 | stream.filter(s -> s.length() > 3) |
map(Function<T,R>) |
将元素映射为另一种类型 | stream.map(Student::getScore) |
flatMap(Function<T,Stream<R>>) |
扁平化映射(拆分嵌套流) | stream.flatMap(str -> Stream.of(str.split(","))) |
sorted() |
自然排序(元素实现 Comparable) | stream.sorted() |
sorted(Comparator<T>) |
自定义排序 | stream.sorted(Comparator.comparing(Student::getAge)) |
distinct() |
去重(基于 equals/hashCode) | stream.distinct() |
limit(long n) |
限制返回前 n 个元素 | stream.limit(5) |
skip(long n) |
跳过前 n 个元素 | stream.skip(2) |
peek(Consumer<T>) |
遍历元素(调试用,不修改元素) | stream.peek(System.out::println) |
示例:中间操作组合使用
java
运行
java
List<String> list = Arrays.asList("Java", "Python", "C++", "Java", "Go", "JavaScript");
List<String> result = list.stream()
.filter(s -> s.startsWith("J")) // 筛选以J开头
.distinct() // 去重
.map(String::toUpperCase) // 转大写
.sorted((s1, s2) -> s2.length() - s1.length()) // 按长度降序
.limit(2) // 取前2个
.collect(Collectors.toList());
System.out.println(result); // [JAVASCRIPT, JAVA]2. 终端操作(触发执行)
| 操作 | 作用 | 示例 |
|---|---|---|
forEach(Consumer<T>) |
遍历元素 | stream.forEach(System.out::println) |
collect(Collector<T,A,R>) |
收集结果到集合 / 字符串 | stream.collect(Collectors.toList()) |
count() |
统计元素个数 | stream.count() |
max(Comparator<T>) |
获取最大值 | stream.max(Comparator.comparing(Student::getScore)) |
min(Comparator<T>) |
获取最小值 | stream.min(Comparator.comparing(Student::getScore)) |
findFirst() |
获取第一个元素 | stream.findFirst() |
findAny() |
获取任意元素(并行流高效) | stream.findAny() |
anyMatch(Predicate<T>) |
是否存在符合条件的元素 | stream.anyMatch(s -> s.contains("Java")) |
allMatch(Predicate<T>) |
是否所有元素都符合条件 | stream.allMatch(s -> s.length() > 0) |
noneMatch(Predicate<T>) |
是否没有元素符合条件 | stream.noneMatch(s -> s.isEmpty()) |
reduce(BinaryOperator<T>) |
归约(累加 / 拼接等) | stream.reduce("", (a, b) -> a + b) |
示例 1:终端操作(统计 / 最值)
java
运行
java
List<Student> students = Arrays.asList(
new Student("张三", 18, 90.5),
new Student("李四", 19, 85.0),
new Student("王五", 18, 95.5)
);
// 统计18岁学生数量
long count = students.stream()
.filter(s -> s.getAge() == 18)
.count();
System.out.println("18岁学生数量:" + count); // 2
// 获取最高分学生
Optional<Student> maxScoreStudent = students.stream()
.max(Comparator.comparingDouble(Student::getScore));
maxScoreStudent.ifPresent(s -> System.out.println("最高分学生:" + s.getName())); // 王五示例 2:collect 收集器(常用)
Collectors提供了丰富的收集器,是 Stream 流中最常用的终端操作:
java
运行
java
List<Student> students = Arrays.asList(
new Student("张三", 18, 90.5),
new Student("李四", 19, 85.0),
new Student("王五", 18, 95.5)
);
// 1. 收集到List
List<Student> age18List = students.stream()
.filter(s -> s.getAge() == 18)
.collect(Collectors.toList());
// 2. 收集到Set(去重)
Set<Double> scoreSet = students.stream()
.map(Student::getScore)
.collect(Collectors.toSet());
// 3. 收集到Map(Key=姓名,Value=分数)
Map<String, Double> scoreMap = students.stream()
.collect(Collectors.toMap(
Student::getName,
Student::getScore,
(oldValue, newValue) -> newValue // 重复Key时保留新值
));
// 4. 分组(按年龄分组)
Map<Integer, List<Student>> ageGroup = students.stream()
.collect(Collectors.groupingBy(Student::getAge));
// 5. 拼接字符串
String nameStr = students.stream()
.map(Student::getName)
.collect(Collectors.joining(", ", "学生列表:", "。"));
System.out.println(nameStr); // 学生列表:张三, 李四, 王五。示例 3:reduce 归约操作
java
运行
java
// 字符串拼接
List<String> list = Arrays.asList("J", "a", "v", "a");
String str = list.stream()
.reduce("", (a, b) -> a + b);
System.out.println(str); // Java
// 数值累加
List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5);
int sum = nums.stream()
.reduce(0, Integer::sum);
System.out.println(sum); // 153. 并行流(提升大数据处理性能)
并行流基于 Fork/Join 框架,自动将任务拆分给多个线程执行,适合大数据量处理:
java
运行
java
// 并行流处理1000万条数据(示例)
List<Integer> bigList = new ArrayList<>();
for (int i = 0; i < 10_000_000; i++) {
bigList.add(i);
}
// 串行流求和(耗时)
long start1 = System.currentTimeMillis();
long sum1 = bigList.stream().mapToLong(Integer::longValue).sum();
long end1 = System.currentTimeMillis();
System.out.println("串行流耗时:" + (end1 - start1) + "ms");
// 并行流求和(更快)
long start2 = System.currentTimeMillis();
long sum2 = bigList.parallelStream().mapToLong(Integer::longValue).sum();
long end2 = System.currentTimeMillis();
System.out.println("并行流耗时:" + (end2 - start2) + "ms");四、Stream 流的核心规则与坑点
1. 核心规则
规则 1:流只能消费一次
流执行终端操作后会关闭,再次使用会抛出IllegalStateException:
java
运行
java
Stream<String> stream = Stream.of("Java", "Python");
stream.forEach(System.out::println); // 终端操作,流关闭
// stream.count(); // 报错:流已关闭规则 2:中间操作惰性执行
只有调用终端操作时,中间操作才会执行:
java
运行
java
Stream<String> stream = Stream.of("Java", "Python")
.filter(s -> {
System.out.println("执行filter:" + s); // 终端操作未调用,不会执行
return s.length() > 3;
});
// 调用终端操作,触发filter执行
long count = stream.count();规则 3:不修改原数据源
Stream 流操作是无副作用的,不会修改原集合 / 数组:
java
运行
java
List<String> list = new ArrayList<>();
list.add("Java");
list.add("Python");
list.stream()
.map(String::toUpperCase)
.forEach(System.out::println);
System.out.println(list); // [Java, Python](原集合未变)2. 高频坑点
坑点 1:空指针异常(Optional 处理)
Stream 的findFirst()/max()/min()返回Optional,避免直接调用get()(空值时抛异常):
java
运行
java
// 错误:空值时抛NoSuchElementException
// Student s = students.stream().filter(s -> s.getAge() == 21).findFirst().get();
// 正确:使用Optional的安全方法
Optional<Student> optional = students.stream()
.filter(s -> s.getAge() == 21)
.findFirst();
// 方式1:存在则处理
optional.ifPresent(s -> System.out.println(s.getName()));
// 方式2:不存在则返回默认值
Student defaultStudent = optional.orElse(new Student("默认", 0, 0.0));
// 方式3:不存在则抛自定义异常
Student student = optional.orElseThrow(() -> new IllegalArgumentException("无此学生"));坑点 2:并行流的线程安全问题
并行流处理共享变量时,需保证线程安全(如使用AtomicInteger):
java
运行
java
// 错误:非线程安全的累加
List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5);
int sum = 0;
nums.parallelStream().forEach(n -> sum += n); // 结果不可靠
// 正确:使用reduce或AtomicInteger
AtomicInteger atomicSum = new AtomicInteger(0);
nums.parallelStream().forEach(n -> atomicSum.addAndGet(n));
System.out.println(atomicSum.get()); // 15坑点 3:中间操作顺序影响性能
合理调整中间操作顺序,提升性能(如filter在前,map在后,减少后续操作的数据量):
java
运行
java
// 优化前:先map后filter(处理更多数据)
long count1 = students.stream()
.map(Student::getScore)
.filter(score -> score > 90)
.count();
// 优化后:先filter后map(减少map处理的数据量)
long count2 = students.stream()
.filter(s -> s.getScore() > 90)
.map(Student::getScore)
.count();五、Stream 流的实战场景
场景 1:电商订单数据统计
java
运行
java
// 订单类
class Order {
private String orderId;
private String userId;
private double amount;
private LocalDateTime createTime;
public Order(String orderId, String userId, double amount, LocalDateTime createTime) {
this.orderId = orderId;
this.userId = userId;
this.amount = amount;
this.createTime = createTime;
}
// getter
public String getOrderId() { return orderId; }
public String getUserId() { return userId; }
public double getAmount() { return amount; }
public LocalDateTime getCreateTime() { return createTime; }
}
public class StreamOrderDemo {
public static void main(String[] args) {
// 模拟订单数据
List<Order> orders = Arrays.asList(
new Order("O001", "U001", 100.0, LocalDateTime.of(2025, 1, 1, 10, 0)),
new Order("O002", "U001", 200.0, LocalDateTime.of(2025, 1, 2, 10, 0)),
new Order("O003", "U002", 150.0, LocalDateTime.of(2025, 1, 1, 11, 0)),
new Order("O004", "U003", 300.0, LocalDateTime.of(2025, 2, 1, 10, 0))
);
// 需求1:统计2025年1月的订单总金额
double sumAmount = orders.stream()
.filter(o -> o.getCreateTime().getMonth() == Month.JANUARY)
.filter(o -> o.getCreateTime().getYear() == 2025)
.mapToDouble(Order::getAmount)
.sum();
System.out.println("2025年1月订单总金额:" + sumAmount); // 450.0
// 需求2:按用户分组,统计每个用户的订单总金额
Map<String, Double> userAmountMap = orders.stream()
.collect(Collectors.groupingBy(
Order::getUserId,
Collectors.summingDouble(Order::getAmount)
));
System.out.println("用户订单金额:" + userAmountMap);
// {U001=300.0, U002=150.0, U003=300.0}
// 需求3:获取2025年1月金额最高的订单
Optional<Order> maxOrder = orders.stream()
.filter(o -> o.getCreateTime().getMonth() == Month.JANUARY)
.max(Comparator.comparingDouble(Order::getAmount));
maxOrder.ifPresent(o -> System.out.println("1月最高金额订单:" + o.getOrderId())); // O002
}
}场景 2:数据清洗与转换
java
运行
java
// 模拟原始数据(含空值、重复值)
List<String> rawData = Arrays.asList(
" Java ", "Python", null, "Java", " C++ ", "", "Go"
);
// 数据清洗:去空→去重→去空格→转小写→排序
List<String> cleanData = rawData.stream()
.filter(str -> str != null && !str.trim().isEmpty()) // 去空值和空字符串
.map(String::trim) // 去空格
.map(String::toLowerCase) // 转小写
.distinct() // 去重
.sorted() // 排序
.collect(Collectors.toList());
System.out.println(cleanData); // [c++, go, java, python]六、总结
关键点回顾
- Stream 核心价值:声明式编程,简化集合操作,代码更简洁、易读,支持并行处理;
- 操作流程:创建流→中间操作(惰性)→终端操作(触发执行);
- 核心操作 :
- 中间操作:filter(筛选)、map(映射)、sorted(排序)、distinct(去重);
- 终端操作:forEach(遍历)、collect(收集)、count(统计)、max/min(最值)、reduce(归约);
- 核心规则:流只能消费一次、中间操作惰性执行、不修改原数据源;
- 坑点规避:用 Optional 处理空值、并行流注意线程安全、优化中间操作顺序提升性能。
Stream 流是 Java 8 + 处理集合数据的 "利器",相比传统循环,它能大幅提升代码的可读性和开发效率,尤其在数据统计、清洗、转换等场景中不可或缺。掌握 Stream 流的使用,是从 "基础 Java" 迈向 "高级 Java" 的关键一步。