如果想获取1000+整理好的面试题,请查看我总结的1000+大模型面试题
回答:主要有的几个做法为ALiBi、内插法、NTK-Aware方法、Yarn方法。
展开说一下:
长度外推或者说是Length Generalization研究的是如何预训练的时候使用较小的长度,但在外推的时候能够泛化到更大的长度上去。长度外推问题依然是目前Transformer亟待解决但还没解决的一个问题。好的外推性能表现就是在泛化到超长序列的时候,者相关指标不会出现较大的下降,模型表现依然很稳健。
目前或者说着2年内研究长度泛化的一些经典的思路如下:
-
ALiBi直接外推,ALiBi主要是在计算attention score后添加上一个不可学习的bias, 公式即
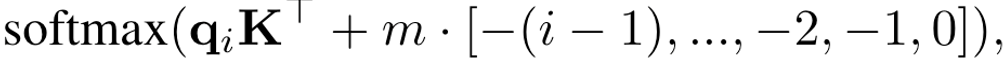
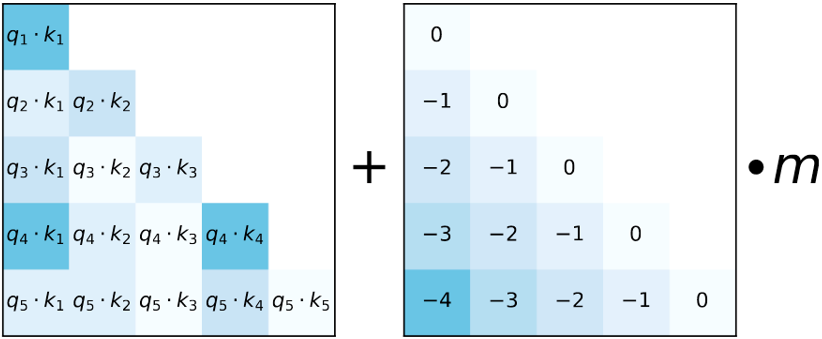
其中m的一个预先定义好的值,举例说明下对于8个heads的时候,m的取值为:1/2, 1/4, 1/8, 1/16, 1/32, 1/64, 1/128, 1/256,ALiBi由于线性偏差,无法在单层注意力中捕捉远距离信息。ALIBI之所以能外推,是因为它类似局部滑动注意力,通过多层attention捕捉超过单层长度的信息,但这种信息感知能力与网络层数成正比,理论上是有限的。
-
PI内插法,将预测的长文本的位置编码乘上因子Ltrain / Ltest,缩放到训练长度范围内,流程如下:
训练阶段:(1,2,3,4,...,n) 测试阶段:(1,2,3,4,...,n,...,2n) -> (0.5,1,...,n) 通过内插的方式来实现
尽管位置内插避免了远处的位置越界问题,但这同时压缩了邻近Token的距离,严重扰乱了模型的局部分辨率, 会导致PPL爆炸,但研究显示,PI经过常文本微调后,效果也是可以的。整体上我们可以理解为这种做法是将位置编码中的sin(m/base^{-2i/d})中的m进行缩放【这里只是拿sin举个例子 base为100000】,比如之前是1的,现在经过压缩后变成了0.5。代码如下
def _compute_linear_scaling_rope_parameters(
config: Optional[PretrainedConfig] = None,
device: Optional["torch.device"] = None,
seq_len: Optional[int] = None,
**rope_kwargs,
) -> Tuple["torch.Tensor", float]:
"""
Computes the inverse frequencies with linear scaling. Credits to the Reddit user /u/kaiokendev
Args:
config ([`~transformers.PretrainedConfig`]):
The model configuration.
device (`torch.device`):
The device to use for initialization of the inverse frequencies.
seq_len (`int`, *optional*):
The current sequence length. Unused for this type of RoPE.
rope_kwargs (`Dict`, *optional*):
BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
Returns:
Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
post-processing scaling factor applied to the computed cos/sin (unused in this type of RoPE).
"""
if config is not None and len(rope_kwargs) > 0:
raise ValueError(
"Unexpected arguments: `**rope_kwargs` and `config` are mutually exclusive in "
f"`_compute_linear_scaling_rope_parameters`, got `rope_kwargs`={rope_kwargs} and `config`={config}"
)
if len(rope_kwargs) > 0:
factor = rope_kwargs["factor"]
elif config is not None:
factor = config.rope_scaling["factor"]
# Gets the default RoPE parameters
inv_freq, attention_factor = _compute_default_rope_parameters(config, device, seq_len, **rope_kwargs)
# Then applies linear scaling to the frequencies.
# NOTE: originally, scaling was applied to the position_ids. However, we get `embs = inv_freq @ position_ids`, so
# applying scaling to the inverse frequencies is equivalent.
inv_freq /= factor
return inv_freq, attention_factor-
NTK-aware系列: NTK-aware Scaled RoPE,目前基于RoPE的大模型太多了,基于该位置编码研究外推的算法很多,NTK-aware Scaled RoPE是一个网友提出来的,思路也是很简单,就是该上面sin(m/base^{-2i/d})中的base,变成了sin(m/(base*alph)^{-2i/d}),从苏剑林等人的分析来看,这种方式类似于进制转换,将b进制转换为lambda b进制,其中lambda=k^(2/d)。且理论上分析,这种方法可以实现高频外推、低频内插的目的,高频指的是如下具体参考文献2。苏剑林提出:NTK-aware Scaled RoPE"平摊"就不是最优的,应该是低位(比如第35维到64维)要分摊更多,高位(第10-35维)分摊更少,这就导致了混合进制的产生(这里不细说).代码如下:
import transformers
old_init = transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.init
def ntk_scaled_init(self, dim, max_position_embeddings=2048, base=10000, device=None):
#The method is just these three lines
max_position_embeddings = 16384
a = 8 #Alpha value
base = base * a ** (dim / (dim-2)) #Base change formula
old_init(self, dim, max_position_embeddings, base, device)
transformrs.models.llama.modeling_llama.LlamaRotaryEmbedding.init = ntk_scaled_init
Dynamically Scaled RoPE:这里找了一个transformers中的代码,位于https://github.com/huggingface/transformers/blob/10feacd88aef9569e240b7e3833ab32b297e4460/src/transformers/modeling_rope_utils.py#L112,对于动态 NTK,设置了一个α,其中α 的缩放设置为 (α * 当前序列长度 / 原始模型上下文长度) - (α - 1)。随着序列长度的增加动态缩放超参数。从如下代码中 可以看到其base缩放的过程:
def _compute_dynamic_ntk_parameters(
config: Optional[PretrainedConfig] = None,
device: Optional["torch.device"] = None,
seq_len: Optional[int] = None,
**rope_kwargs,
) -> Tuple["torch.Tensor", float]:
"""
Computes the inverse frequencies with NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla
Args:
config ([`~transformers.PretrainedConfig`]):
The model configuration.
device (`torch.device`):
The device to use for initialization of the inverse frequencies.
seq_len (`int`, *optional*):
The current sequence length, used to update the dynamic RoPE at inference time.
rope_kwargs (`Dict`, *optional*):
BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
Returns:
Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
post-processing scaling factor applied to the computed cos/sin (unused in this type of RoPE).
"""
# TODO (joao): use the new `original_max_position_embeddings` from rope_scaling
if config is not None and len(rope_kwargs) > 0:
raise ValueError(
"Unexpected arguments: `**rope_kwargs` and `config` are mutually exclusive in "
f"`_compute_dynamic_ntk_parameters`, got `rope_kwargs`={rope_kwargs} and `config`={config}"
)
if len(rope_kwargs) > 0:
base = rope_kwargs["base"]
dim = rope_kwargs["dim"]
max_position_embeddings = rope_kwargs["max_position_embeddings"]
factor = rope_kwargs["factor"]
elif config is not None:
base = config.rope_theta
partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
dim = int(head_dim * partial_rotary_factor)
max_position_embeddings = config.max_position_embeddings
factor = config.rope_scaling["factor"]
attention_factor = 1.0 # Unused in this type of RoPE
# seq_len: default to max_position_embeddings, e.g. at init time
seq_len = seq_len if seq_len is not None and seq_len > max_position_embeddings else max_position_embeddings
# Compute the inverse frequencies 核心代码
base = base * ((factor * seq_len / max_position_embeddings) - (factor - 1)) ** (dim / (dim - 2))
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.int64).float().to(device) / dim))
return inv_freq, attention_factor-
苏剑林提出的几种方式,包括ReRoPE和Leaky ReRoPE,其主要的思路是:结合外推和内插的方法呢,先自己设定一个窗口大小w,在窗口内我们使用大小为1的位置间隔,在窗口外我们使用大小为1/k的位置间隔。在这个case下,不管输入长度是多少,它的位置编码范围都不超过w,这种方式可以支持任意长度的content. 但这种思路会增加计算量,因为窗口内核窗口外都算一遍后再归到一起,增加了计算开销(这些都是后话)。除此外,苏建林还提出了log n 的缩放因子,在测试阶段每个q都呈上log n 以稳定注意力分数的分布,该点虽说是trick但有理论证明且效果很好。具体可以通过文献2去找其发布的一些博客。
-
Yarn,有两份部分工作,第一部分是对灵活进制的设计,说白了就是不同的位置用不同的进制。对于低维度,表示数字高位(数字=token的位置信息),外推,就是角度不变;对于中间维度(旋转位置编码向量的维度),表示数字的中间的位,需要逐步内插,也即逐步减小角度,相当于逐步增大"进制",对于高维度,表示数字的低位,彻底内插,就是把进制变成原来的进制的40倍。看参考文献7;计算公式如下:

第二份工作是在相关研究观察到,在对logits进行softmax操作之前引入温度t可以统一地影响困惑度,无论数据样本和扩展上下文窗口上的token位置如何,更准确地说,我们将注意力权重的计算修改为
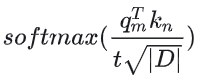
YaRN方法在微调和非微调场景中均超过以前所有方法,由于其占用空间较小,YaRN与修改注意力机制库(如Flash Attention 213)直接兼容,且在对不到0.1%的原始预训练数据进行微调后,YaRN在上下文窗口扩展中达到了最先进的性能, 同时,如果YaRN与动态缩放的推理技术相结合而得到的Dynamic-yarn,其允许在超过2倍的上下文窗口扩展,而无需任何微调。代码和上面的连接一样,这里也列一下
def _compute_yarn_parameters(
config: PretrainedConfig, device: "torch.device", seq_len: Optional[int] = None, **rope_kwargs
) -> Tuple["torch.Tensor", float]:
"""
Computes the inverse frequencies with NTK scaling. Please refer to the
[original paper](https://arxiv.org/abs/2309.00071)
Args:
config ([`~transformers.PretrainedConfig`]):
The model configuration.
device (`torch.device`):
The device to use for initialization of the inverse frequencies.
seq_len (`int`, *optional*):
The current sequence length. Unused for this type of RoPE.
rope_kwargs (`Dict`, *optional*):
BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
Returns:
Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
post-processing scaling factor applied to the computed cos/sin.
"""
# No need to keep BC with yarn, unreleased when this new pattern was created.
if len(rope_kwargs) > 0:
raise ValueError(
f"Unexpected arguments: `**rope_kwargs` should be unset in `_compute_yarn_parameters`, got {rope_kwargs}"
)
base = config.rope_theta
partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
dim = int(head_dim * partial_rotary_factor)
max_position_embeddings = config.max_position_embeddings
factor = config.rope_scaling["factor"]
# Sets the attention factor as suggested in the paper
attention_factor = config.rope_scaling.get("attention_factor")
if attention_factor is None:
attention_factor = 0.1 * math.log(factor) + 1.0
# Optional config options
# beta_fast/beta_slow: as suggested in the paper, default to 32/1 (correspondingly)
beta_fast = config.rope_scaling.get("beta_fast") or 32
beta_slow = config.rope_scaling.get("beta_slow") or 1
# Compute the inverse frequencies
def find_correction_dim(num_rotations, dim, base, max_position_embeddings):
"""Inverse dimension formula to find the dimension based on the number of rotations"""
return (dim * math.log(max_position_embeddings / (num_rotations * 2 * math.pi))) / (2 * math.log(base))
def find_correction_range(low_rot, high_rot, dim, base, max_position_embeddings):
"""Find dimension range bounds based on rotations"""
low = math.floor(find_correction_dim(low_rot, dim, base, max_position_embeddings))
high = math.ceil(find_correction_dim(high_rot, dim, base, max_position_embeddings))
return max(low, 0), min(high, dim - 1)
def linear_ramp_factor(min, max, dim):
if min == max:
max += 0.001 # Prevent singularity
linear_func = (torch.arange(dim, dtype=torch.float32) - min) / (max - min)
ramp_func = torch.clamp(linear_func, 0, 1)
return ramp_func
# Note on variable naming: "interpolation" comes from the original technique, where we interpolate the position IDs
# to expand the possible context length. In other words, interpolation = apply scaling factor.
pos_freqs = base ** (torch.arange(0, dim, 2).float().to(device) / dim)
inv_freq_extrapolation = 1.0 / pos_freqs
inv_freq_interpolation = 1.0 / (factor * pos_freqs)
low, high = find_correction_range(beta_fast, beta_slow, dim, base, max_position_embeddings)
# Get n-dimensional rotational scaling corrected for extrapolation
inv_freq_extrapolation_factor = 1 - linear_ramp_factor(low, high, dim // 2).float().to(device)
inv_freq = (
inv_freq_interpolation * (1 - inv_freq_extrapolation_factor)
+ inv_freq_extrapolation * inv_freq_extrapolation_factor
)
return inv_freq, attention_factor参考:
1.https://zhuanlan.zhihu.com/p/656684326
2.https://kexue.fm/archives/9675
3.https://kexue.fm/content.html
4.https://blog.csdn.net/v_JULY_v/article/details/135072211
5.https://blog.csdn.net/zpp13hao1/article/details/142999954 代码解读
6.https://blog.csdn.net/luxurie/article/details/135119538 研究ROPE的远程衰减性