摘要
本周深入研读了基于U-Net的像素级解码器(DiP)相关研究,该工作旨在提升扩散Transformer(DiT)在图像生成中的像素级细节重建能力。研究系统探究了像素级网络的两个关键设计空间:网络引入位置(后置、内部回注、混合注入)与网络架构选择(标准MLP、坐标MLP、块内Transformer、U-Net)。实验表明,在DiT后端接入一个轻量级U-Net解码器,能够在最小化架构改动的前提下,最有效地改善生成图像的视觉保真度(FID指标),并实现较好的训练效率平衡。
Abstract
This week focused on an in-depth study of Diffusion with Pixel-aware Decoders (DiP), which aims to enhance the pixel-level detail reconstruction capability of Diffusion Transformers (DiT) in image generation. The research systematically investigated two key design spaces for the pixel-level network: the insertion point (post-hoc, internal feedback, hybrid) and the network architecture (standard MLP, coordinate-based MLP, intra-patch Transformer, U-Net). Experiments demonstrate that appending a lightweight U-Net decoder to the DiT backend most effectively improves the visual fidelity (FID metric) of generated images with minimal architectural modifications, achieving a favorable balance with training efficiency.
1、DiP - 基于 U-Net 的像素级解码器
1.1 总览
DiP 探究了网络设计的两个设计空间:
应该在哪个地方引入像素级网络?是在 DiT 后面接一个新网络,还是将像素级网络的输出传给 DiT?
像素级网络应该用哪个架构?
从引入网络的位置来看,论文测试了三类方式:
DiT 完成后再接 head
将高频信息回注到 DiT 内部
混合注入
三类方式的示意图及实验结果如下图所示。实验结果包括 FID 指标及网络中间特征在不同类别图像下的 t-SNE 可视化结果。
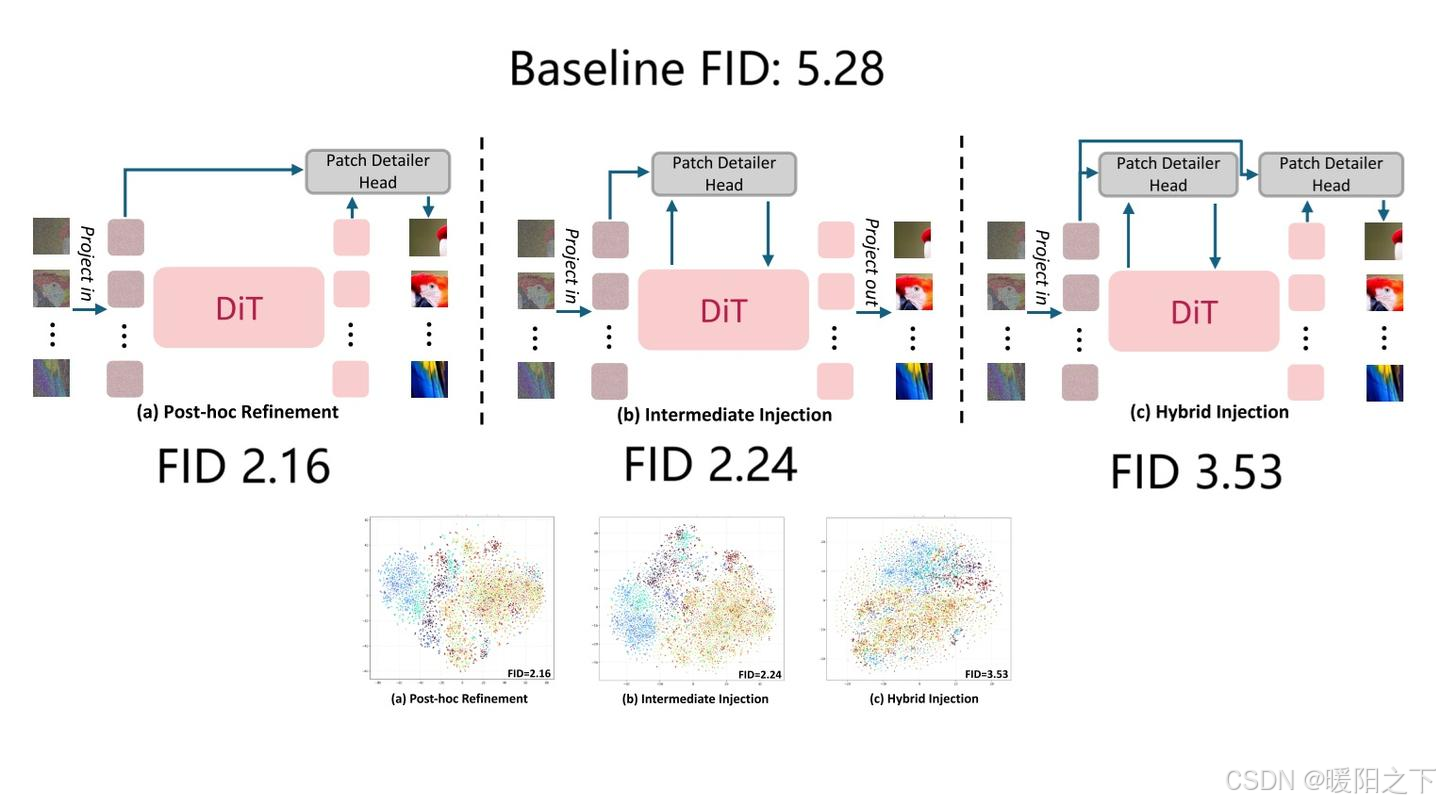
从实验结果来看,三种方法都能提升 FID。不过,接在 DiT 后面的效果最好,且实现最简单,因为加入它时完全不用修改 DiT 的架构。这也证明我们的直觉是正确的:用一个小型解码器取代 unpatchify 比较好,不需要修改 DiT 的其他部分。论文最终采用的就是这个配置。
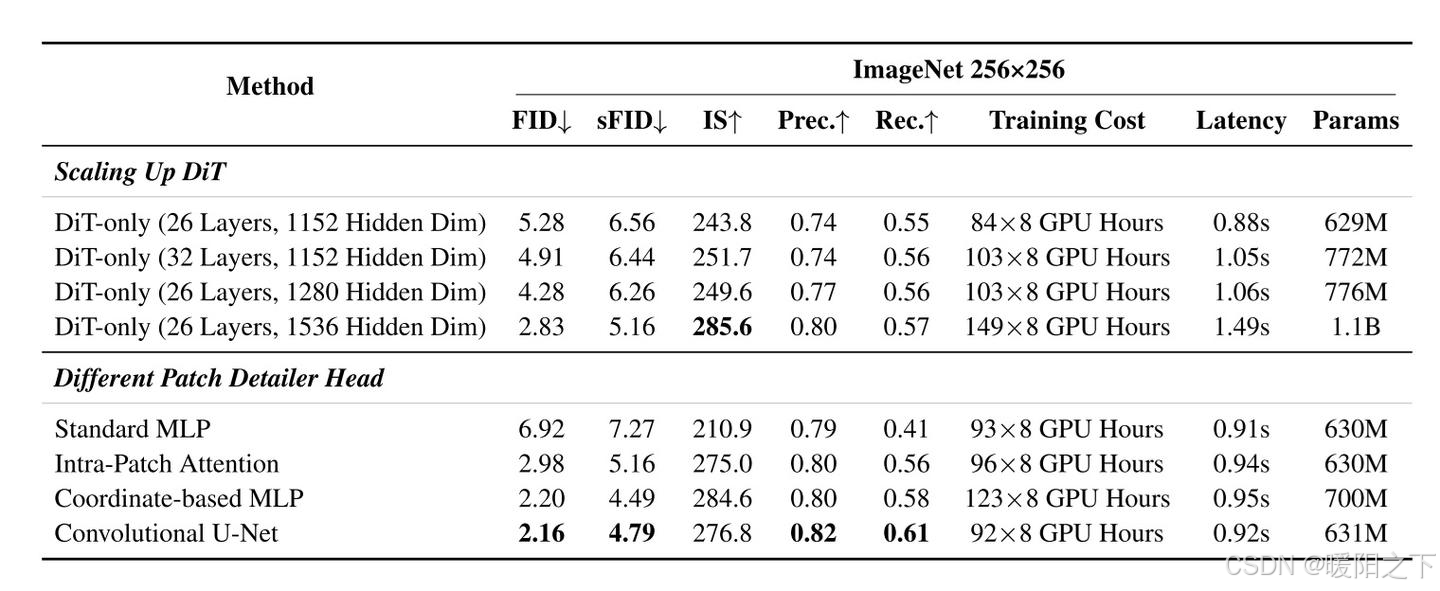
此外,论文尝试了多种解码器架构。所有解码器的输入输出都是形状为 pxpx3 的像素级 token,条件信息为 DiT 的在该 patch 处的输出特征。该网络不直接包含 patch 与 patch 之间的信息交流,全局信息仅靠 DiT 输出特征提供。
标准 MLP:即一个把所有输入 flatten 的全连接网络,而不是 Transformer 里那种逐元素 MLP。这个做法仅仅是 patchify 的一个升级,网络的输入和输出还是高维的,并没有利用 patch 内部的空间信息。
坐标 MLP:类似 NeRF 的结构,目的是用神经网络表示一张连续的 2D 图像。我们用 DiT 的输出来生成 MLP 的权重,通过输入二维坐标来读取此处的输出像素值。这和之前的工作 PixNerd 完全一致。
块内 Transformer: 用一个小型 Transformer,对一个 patch 内所有像素级特征做 attention。缺点是效率低。
U-Net(最终选择):标准去噪 U-Net。DiT 条件信息会拼接到 U-Net 的最深层。
表格下半部分的实验结果显示,U-Net 是生成质量最高且训练效率最高的。由于加入 U-Net 实际上增加了总网络参数,我们或许会怀疑继续增大 DiT 参数能否达到同样效果。但表格上半部分的实验结果显示,增加 DiT 参数的作用没有加一个像素级 U-Net 明显。
1.2 分析
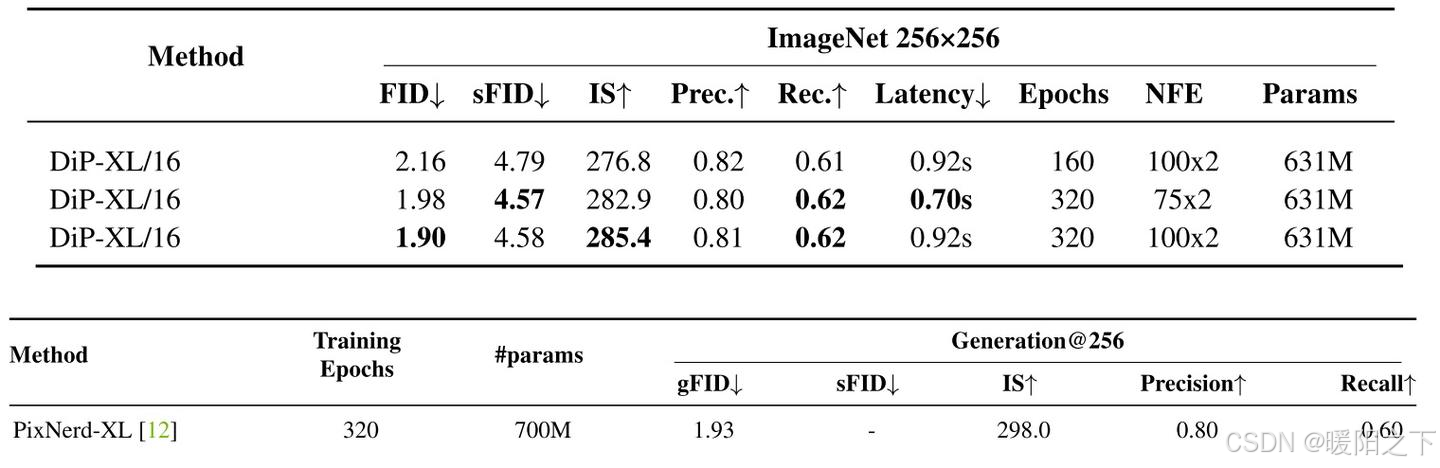
DiP 确实出色解决了像素 DiT 生成任务。FID 超越了之前所有方法。
论文的实验表格有取巧之嫌:ImageNet-256 实验表格没有放最先进,比自己效果更好的 LDM 方法。我这里展示了 DiP 和此前最好方法 PixNerd 的对比。从效果上看,DiP 没有明显好于 PixNerd。但从上一个表格看,DiP 比 PixNerd 快很多。
经作者指正,上表的 Coordinate-based MLP 就是 PixNerd。论文表格会很快更新。
总结
本周通过对DiP论文的详细解析,深入理解了提升DiT模型像素级生成质量的核心思路与技术路径。