文章目录
- 一、Thor介绍
-
-
- [1.1 核心规格:跨越式的性能提升](#1.1 核心规格:跨越式的性能提升)
- [1.2 核心技术亮点](#1.2 核心技术亮点)
- [1.3 主要产品形态](#1.3 主要产品形态)
- [1.4 开发者套件接口(I/O)](#1.4 开发者套件接口(I/O))
- [1.5 应用场景](#1.5 应用场景)
- [1.6 注意事项:DRIVE Thor vs. Jetson Thor](#1.6 注意事项:DRIVE Thor vs. Jetson Thor)
-
- 二、系统安装
-
-
- [2.1 启动盘安装](#2.1 启动盘安装)
- [2.2 SDK Manager安装](#2.2 SDK Manager安装)
-
- 三、Docker镜像拉取和启动
-
-
- [3.1 Docker安装](#3.1 Docker安装)
- [3.2 GROOT-N1.5镜像拉取](#3.2 GROOT-N1.5镜像拉取)
- [3.3 Docker容器启动](#3.3 Docker容器启动)
-
- 四、模型微调与部署
-
-
- [4.1 拉取官方代码](#4.1 拉取官方代码)
- [4.2 环境安装](#4.2 环境安装)
- [4.3 数据采集](#4.3 数据采集)
- [4.4 模型微调](#4.4 模型微调)
- [4.5 模型部署](#4.5 模型部署)
- [4.6 真机测试](#4.6 真机测试)
-
一、Thor介绍

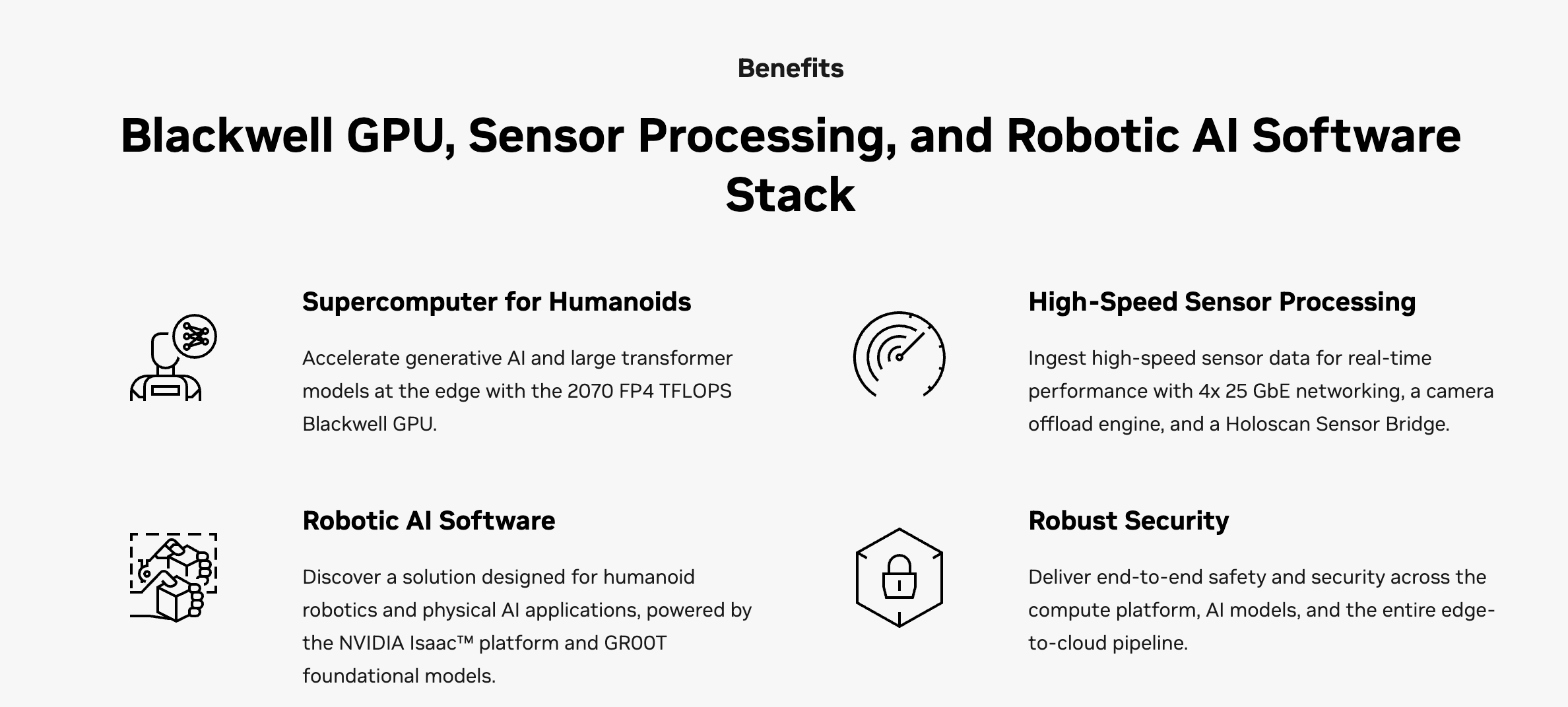
NVIDIA Jetson AGX Thor 是英伟达于 2024 年 GTC 大会首次发布、并在 2025 年正式上市的顶尖边缘计算平台。它是 Jetson 家族中首款采用 Blackwell 架构 的产品,被官方定位为"为具身智能(Physical AI)和人形机器人而生的超级计算机"。
以下是关于 Jetson AGX Thor 开发板的核心介绍:
1.1 核心规格:跨越式的性能提升
相比上一代的 Jetson AGX Orin,Thor 在算力和能效比上实现了巨大的跨越:
- GPU 架构:采用最新的 Blackwell 架构(配备 2560 个 CUDA 核心和 96 个第五代 Tensor Cores)。
- AI 算力:提供高达 2070 TFLOPS (FP4) 的稀疏算力。这比 Orin 提升了约 7.5 倍。
- CPU:搭载 14 核 Arm Neoverse-V3AE 64 位处理器,这是 Arm 专门为高性能边缘计算和自动驾驶设计的服务器级 CPU。
- 内存:配备 128 GB LPDDR5X,带宽达 273 GB/s,足以运行大规模的 Transformer 模型(如 LLMs 和 VLMs)。
- 功耗:功耗在 40W 至 130W 之间可调,保持了极佳的能效比。
1.2 核心技术亮点
- 第二代 Transformer 引擎:专门优化了针对 Transformer 架构的计算,支持 FP4 精度。这意味着它能在边缘端以极低延迟运行万亿参数级别的生成式 AI 模型。
- 具身智能支持:Thor 是 NVIDIA Project GR00T(人形机器人通用基础模型)的官方推荐硬件平台,旨在让机器人能够理解多模态输入(语言、感知)并执行复杂的动作。
- 高速互联(Networking):支持高达 4 个 25 GbE(25000 兆以太网)接口,这在处理来自激光雷达、高清摄像头等大量传感器的数据融合时至关重要。
1.3 主要产品形态
英伟达提供了两种主要的 Thor 模块规格:
- Jetson T5000:旗舰型号,2070 TFLOPS AI 算力,128 GB 内存。
- Jetson T4000:主流型号,1200 TFLOPS AI 算力,64 GB 内存。
1.4 开发者套件接口(I/O)
Jetson AGX Thor 开发板(DevKit)提供了极其丰富的物理接口,方便原型开发:
- 存储:内置 1 TB NVMe SSD(通过 M.2 Key M 插槽)。
- 网络:1个 5GBe RJ45 电口,以及 1个 QSFP28 接口(可转 4 个 25 GbE)。
- 传感器接入:支持 Holoscan Sensor Bridge (HSB),通过 QSFP 槽位可接入多达 20 个摄像头;另外支持 MIPI CSI-2 接口。
- 视频输出:支持 HDMI 2.1 和 DisplayPort 1.4a,最多支持 4 路同步显示
1.5 应用场景
- 人形机器人:处理实时感知、自然语言交互和全身协调控制。
- 自动驾驶与自主机器:用于配送机器人、无人农机、医疗手术机器人等需要极高性能边缘 AI 的场景。
- 工业边缘计算:在工厂端进行高精度的实时视觉检测和数字孪生同步。
1.6 注意事项:DRIVE Thor vs. Jetson Thor
在英伟达的产品线中,"Thor" 有两个分支:
- DRIVE AGX Thor:面向汽车 OEM 厂商,侧重于车载自动驾驶、智驾域控,符合 ISO 26262 ASIL-D 功能安全标准。
- Jetson AGX Thor:面向机器人开发者、学术界和工业界,侧重于边缘端通用 AI 和复杂机器人开发。
二、系统安装
Thor系统安装的方法有两种,一种是自己用U盘制作启动盘,安装系统环境,个人感觉比较复杂,另一种是找一台有ubuntu系统的电脑,然后安装官方的SDK Manager软件来进行系统安装。
2.1 启动盘安装
网上比较多的教程都是制作启动盘安装的,我这里就不再重复教学,大家可以参考https://blog.csdn.net/nenchoumi3119/article/details/151148194?spm=1001.2014.3001.5506和https://wiki.seeedstudio.com/cn/fine_tune_gr00t_n1.5_for_lerobot_so_arm_and_deploy_on_jetson_thor/#%E5%AE%89%E8%A3%85%E5%9F%BA%E6%9C%AC%E5%BC%80%E5%8F%91%E4%BE%9D%E8%B5%96%E9%A1%B9。
2.2 SDK Manager安装
如果我们刚好有一台ubuntu系统的电脑,那么就可以到https://developer.nvidia.com/sdk-manager官方网站下载ubuntu的专属软件。由于这里我是用ubuntu系统安装的软件进行系统安装,但是我看其它系统也可以该软件进行jetson系列开发版的系统安装,由于我没有试过ubuntu以外的安装方式,所以这里也不好确认其它系统是否可以,大家如果没有ubuntu的电脑可以尝试下windows或其他安装方式,不过我看官方是说window10和11是支持jetpack6.x和 7.x版本的烧录。
软件打开以后如下所示,第一次需要登陆下账号:
但是在装机之前,我们需要将Thor切换到烧录模式,具体操作如下图所示: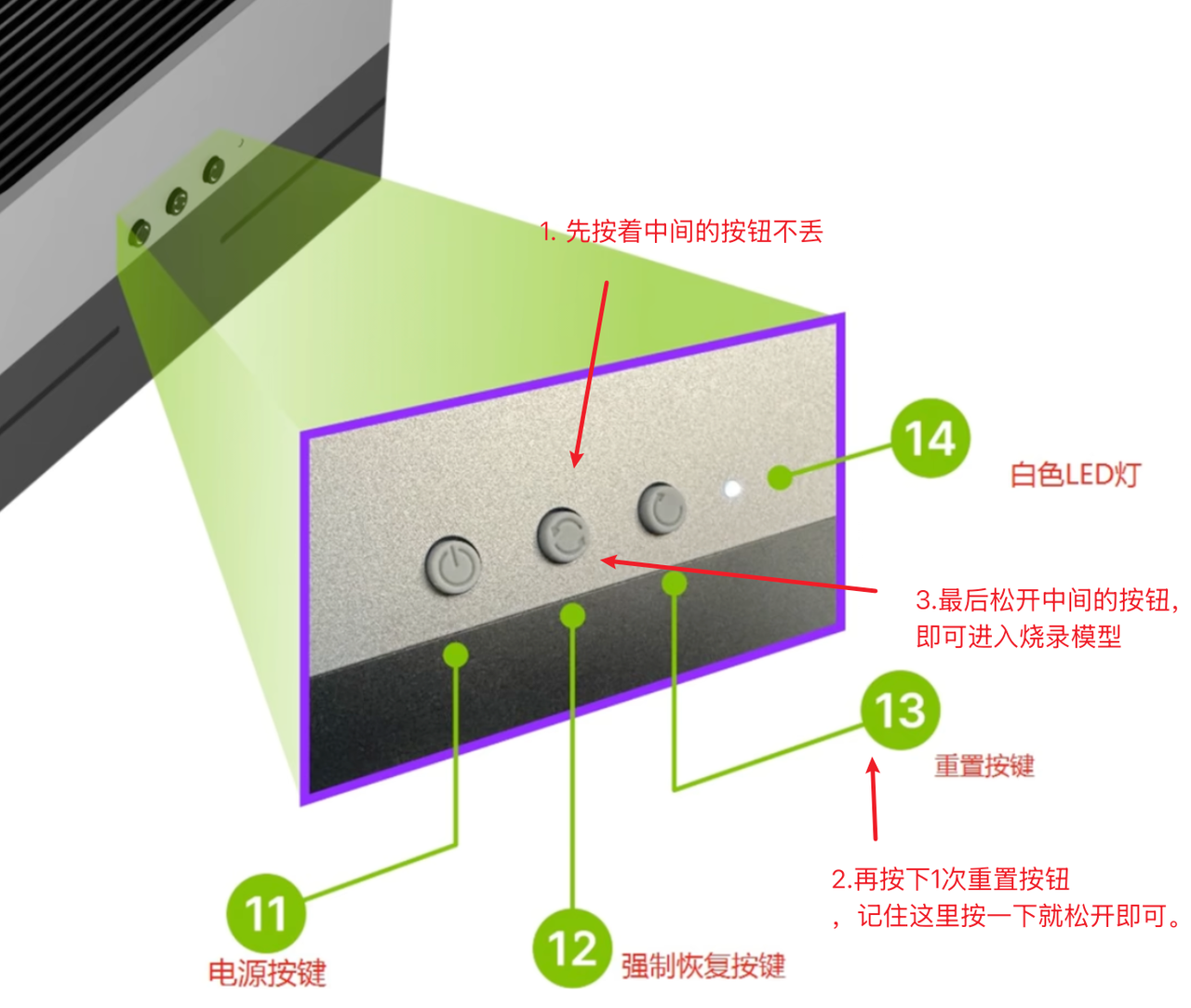
这时候将Thor开发板连通电源,并将用一根usb转type c的连接线连接我们的ubuntu系统电脑,然后按照下图选好后点击CONTINUE进入下一步。
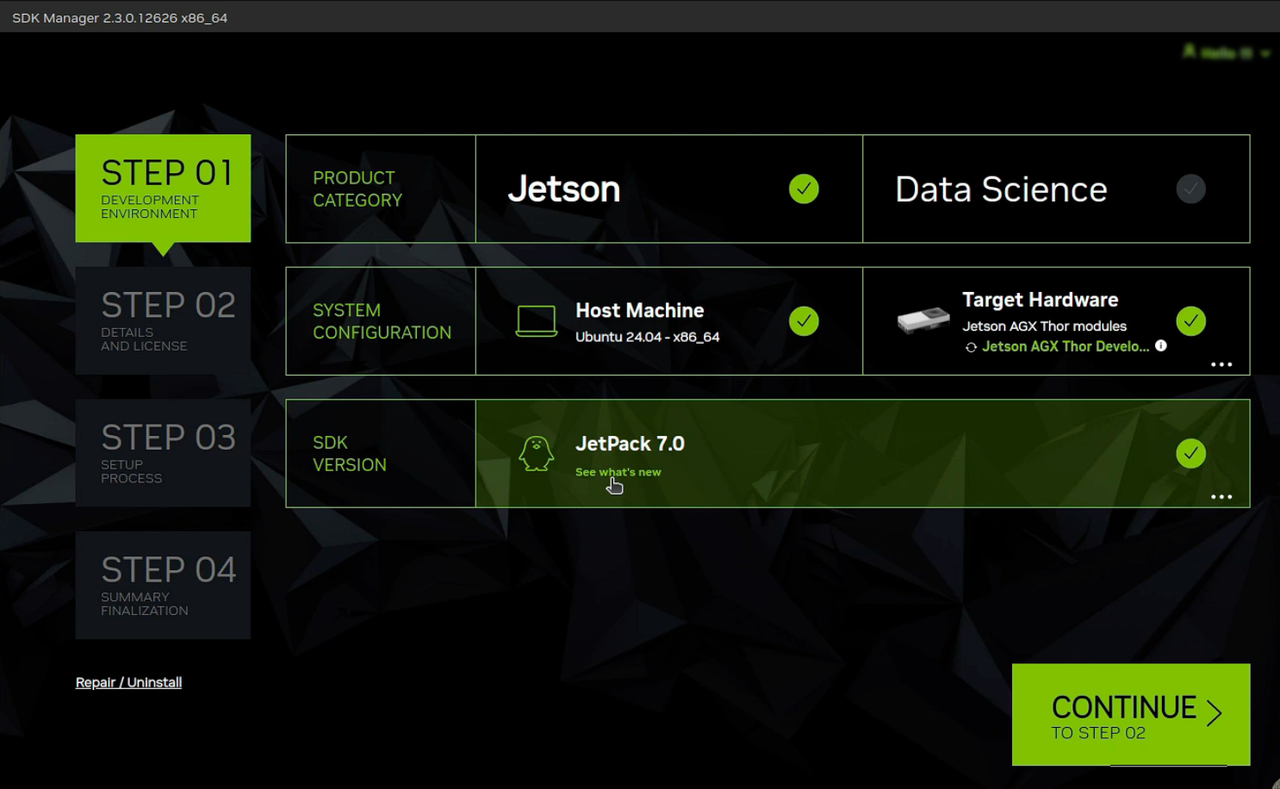
接下来就是选择我们需要的一些基础环境了,这里我建议电脑有内存的话,就按照默认的进行安装即可,这里我们可以直接按照默认的进行下一步。
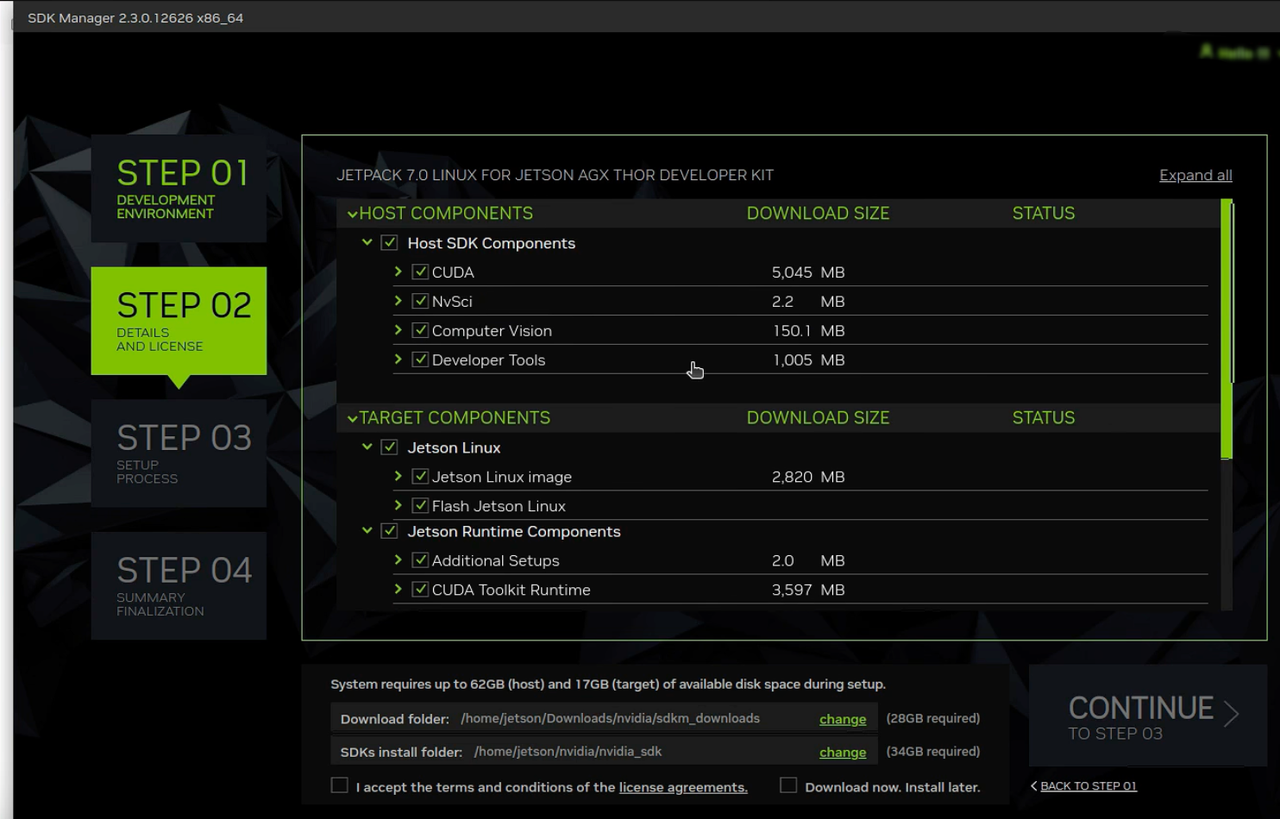
这里选择下一步的时候需要输入我们开发板设定的密码,然后进入下一步即可进行安装:
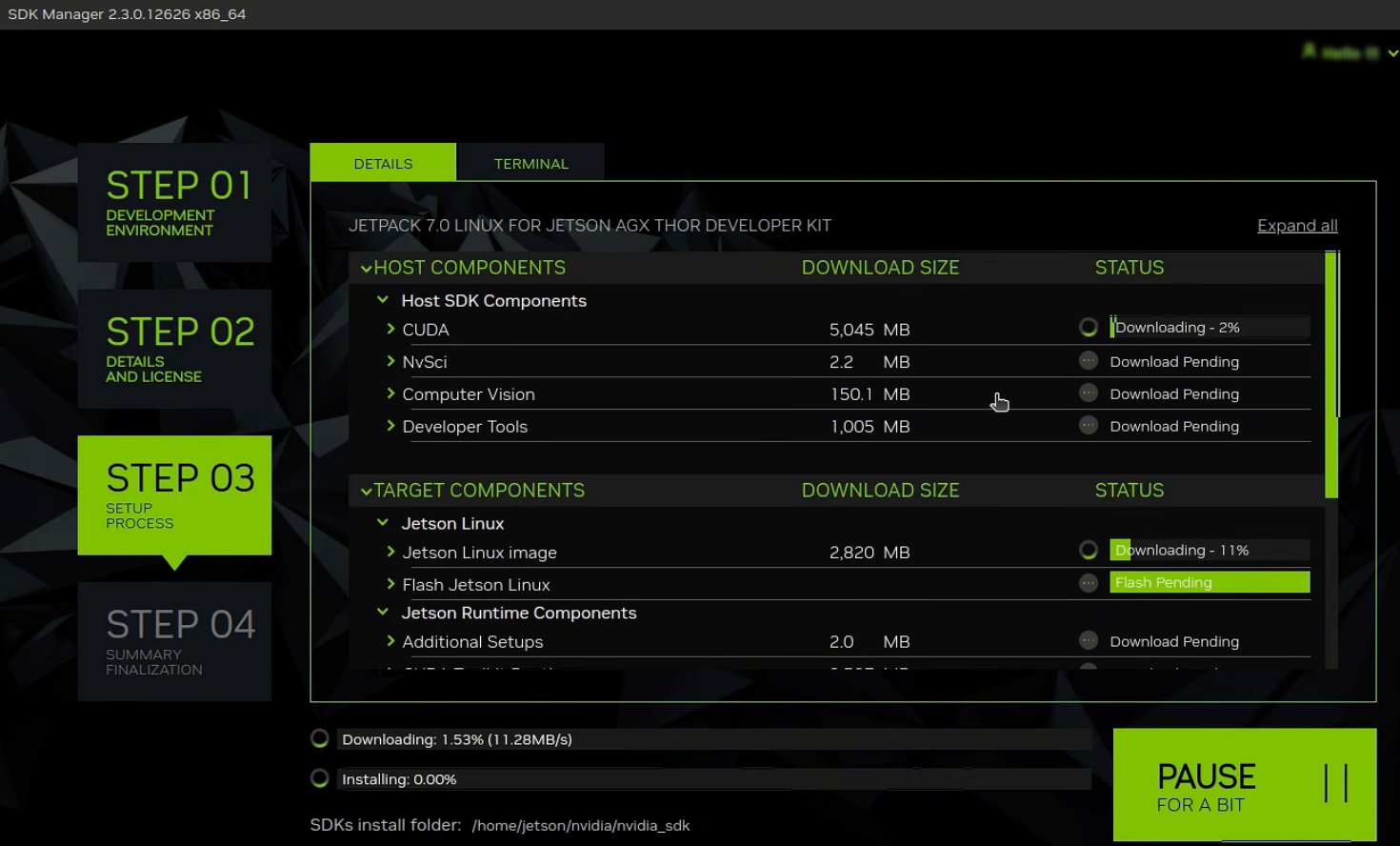
安装到一半的时候会跳出烧录前的配置准备工作:
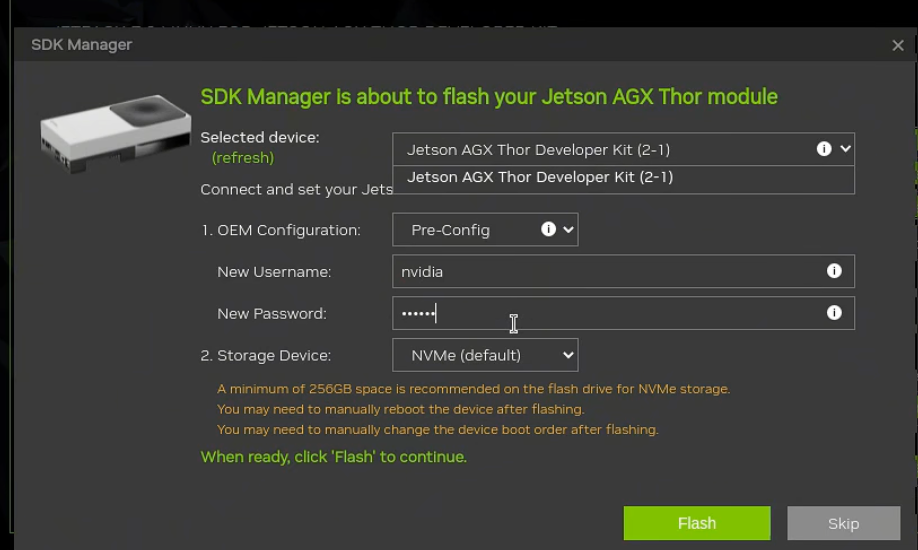
这时候我们直接设置好我们开发板的账号密码点击flash即可进行烧录。烧录快结束的时候会再跳出一个窗口,我们检查一下是否有误后点击install即可,这里一般直接install就行。
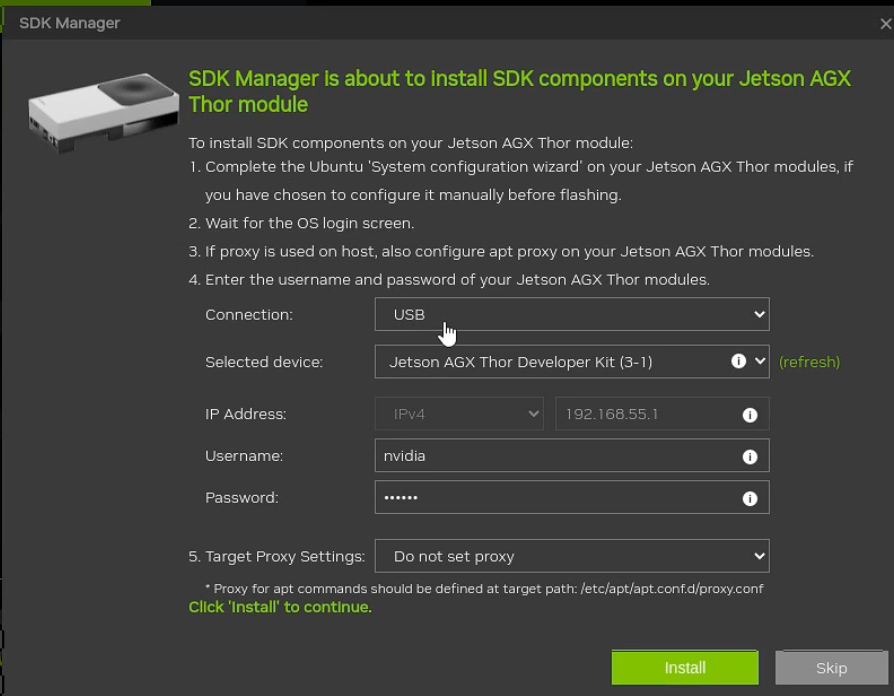
等到最后安装完毕以后,我们就可以准备hdmi或者dp线连接屏幕进行开发板的使用了。
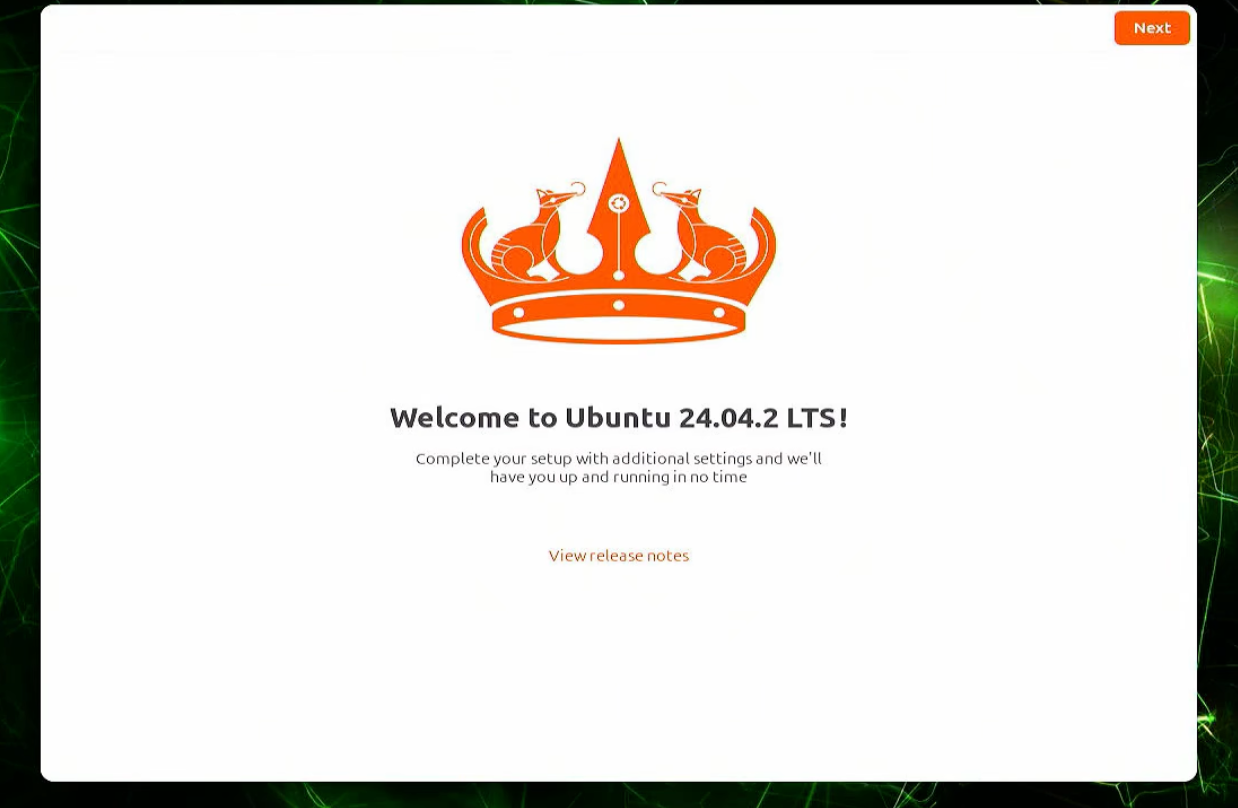
三、Docker镜像拉取和启动
一开始尝试在Thor上直接安装GROOT-N1.5的环境,发现该开发版的版本和架构都比较新,很难适配官方代码仓库现有的环境。
所以,后来直接参考网上的一些成功案例,直接拉取GROOT-N1.5的docker镜像来进行模型的训练和部署。
3.1 Docker安装
一般NVIDIA 官方提供的 JetPack 系统(基于 Ubuntu)在安装时已经预装了 Docker。我们可以通过以下命令检查是否已经安装好了Docker:
python
docker --version如果像下面一样返回了版本号,就说明已经预安装成功了。

3.2 GROOT-N1.5镜像拉取
python
docker pull johnnync/isaac-gr00t:r38.2.arm64-sbsa-cu130-24.04 拉取完成后可以看到johnnync/isaac-gr00t:r38.2.arm64-sbsa-cu130-24.04镜像。

3.3 Docker容器启动
拉取镜像成功后,我们就可以通过以下命令启动该Docker容器。
python
sudo docker run -it \
--network=host \
-e NVIDIA_DRIVER_CAPABILITIES=compute,utility,video,graphics \
--runtime nvidia \
--privileged \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v /etc/X11:/etc/X11 \
--device /dev/nvhost-vic \
-v /dev:/dev \
johnnync/isaac-gr00t:r38.2.arm64-sbsa-cu130-24.04只要看到前面变成了root@localhost,就说明我们已经成功进入到了容器内部。
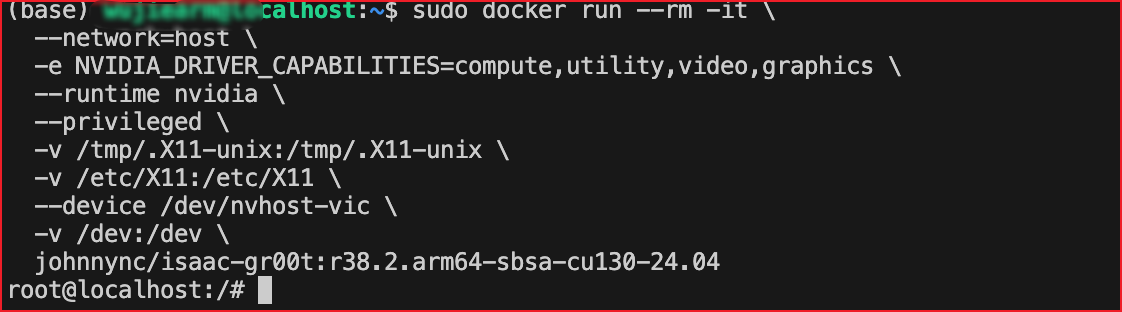
四、模型微调与部署
4.1 拉取官方代码
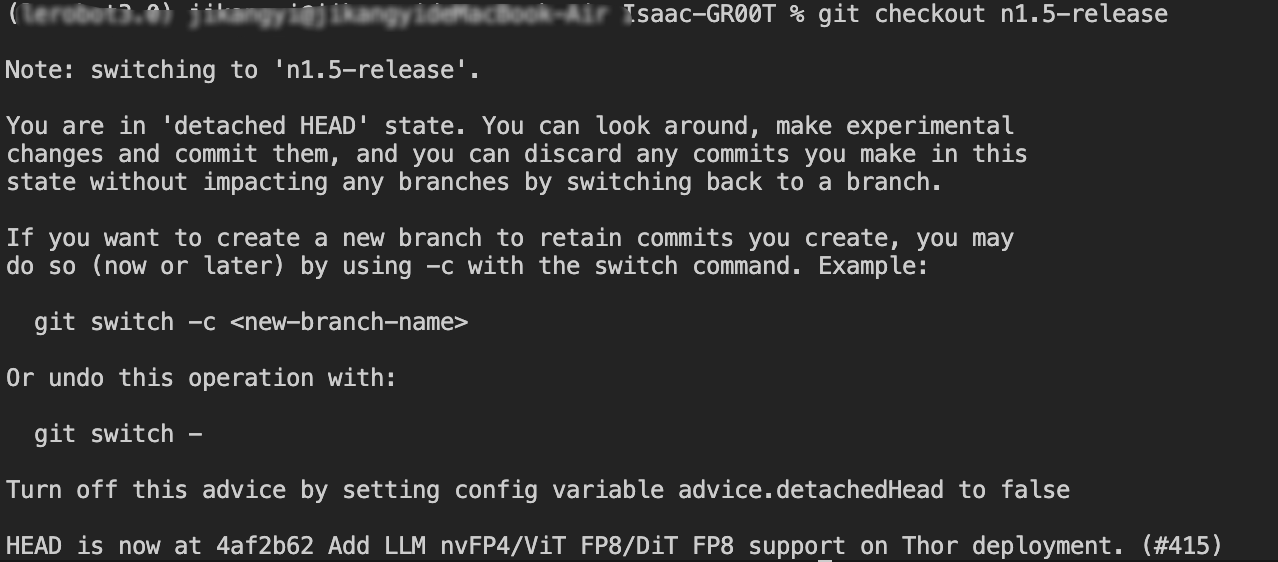
由于目前GROOT最新版本更新为了GROOT-N1.6,所以我们要切换到GROOT-N1.5版本,切换命令如下:
python
cd Isaac-GR00T
git checkout n1.5-release切换成功如下图所示:
4.2 环境安装
接下来就是安装该模型所需的依赖库,在代码主目录下执行以下命令即可:
python
pip install --upgrade setuptools
pip install -e .[base]
pip install --no-build-isolation flash-attn==2.7.1.post4 4.3 数据采集
这里微调所需的数据可以自己采集,也可以直接用demo_data提供的示例数据,或者用Lerobot官方给的示例数据:https://huggingface.co/datasets/lerobot/svla_so101_pickplace/tree/main
这里我用SO101机械臂采集了20条将方块抓取并放置到盘子里的数据集进行微调。
这里需要说明一点,就是GROOT模型与Lerobot V2兼容,但是需要一个额外的modality.json文件,同时切记必须使用Lerobot v2版本的数据集格式,如果我们采集数据的格式是Lerobot v3版本,需要用脚本转化为v2版本的数据集,具体数据格式说明可以参考官方文档:https://github.com/NVIDIA/Isaac-GR00T/blob/main/getting_started/data_preparation.md
这里再提一个小bug,直接从v3转为v2的lerobot数据集,训练的时候会报错:
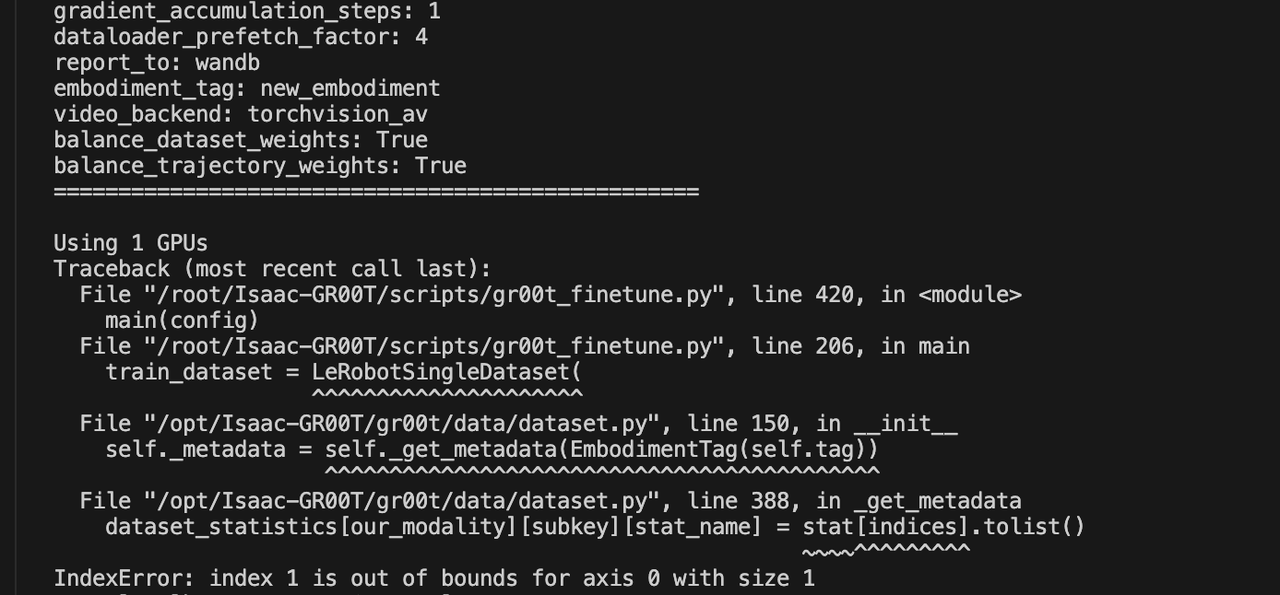
这里是因为新转换的数据集里的states.json文件里有大量的count统计信息,官方示例的 stats.json 中没有 count 字段。count 是长度为 1 的标量数组,代码用 modality.json 的索引(如 gripper: start=5, end=6,即 indices=5)访问 stat5,stat 只有索引 0,访问索引 5 会越界。
这里我们可以从数据层面解决,从 stats.json 中删除所有 count 字段(训练不需要,官方示例也没有)。运行下面代码即可移除这些count字段。
python
#!/usr/bin/env python3
"""
从 stats.json 中删除 count 字段
因为 count 是标量统计,不应该按维度切片,会导致 IndexError
"""
import json
from pathlib import Path
def remove_count_from_stats(stats_path: Path):
"""从 stats.json 中删除所有 count 字段"""
print(f"处理文件: {stats_path}")
with open(stats_path, 'r') as f:
stats = json.load(f)
# 删除所有 count 字段
removed_count = 0
for key in list(stats.keys()):
if isinstance(stats[key], dict) and "count" in stats[key]:
del stats[key]["count"]
removed_count += 1
print(f" 从 '{key}' 中删除了 'count' 字段")
if removed_count > 0:
# 备份原文件
backup_path = stats_path.with_suffix('.json.backup')
print(f"备份原文件到: {backup_path}")
with open(backup_path, 'w') as f:
json.dump(stats, f, indent=4)
# 保存修改后的文件
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=4)
print(f"✅ 已删除 {removed_count} 个 'count' 字段")
else:
print("ℹ️ 未找到 'count' 字段,无需修改")
if __name__ == "__main__":
import sys
if len(sys.argv) > 1:
stats_path = Path(sys.argv[1])
else:
stats_path = Path("cube_20/meta/stats.json")
if not stats_path.exists():
print(f"错误: 文件不存在: {stats_path}")
sys.exit(1)
remove_count_from_stats(stats_path)由于我的是S0101采集的数据集,所以modality.json内容如下,如果是其它款机械臂需要根据自己的机械臂进行修改:
python
{
"state": {
"single_arm": {
"start": 0,
"end": 5
},
"gripper": {
"start": 5,
"end": 6
}
},
"action": {
"single_arm": {
"start": 0,
"end": 5
},
"gripper": {
"start": 5,
"end": 6
}
},
"video": {
"front": {
"original_key": "observation.images.front"
},
"wrist": {
"original_key": "observation.images.wrist"
}
},
"annotation": {
"human.task_description": {
"original_key": "task_index"
}
}
}4.4 模型微调
如果数据集和环境都已经按照上面教程准备就绪,就可以用以下命令启动模型训练:
python
export HF_ENDPOINT=https://hf-mirror.com
python -W ignore scripts/gr00t_finetune.py \
--dataset-path ./demo_data/SO101-cube/ \
--num-gpus 1 \
--output-dir ./cleanup-checkpoints \
--max-steps 10000 \
--data-config so100_dualcam \
--video-backend torchvision_av \
--batch-size 16训练过程如下:
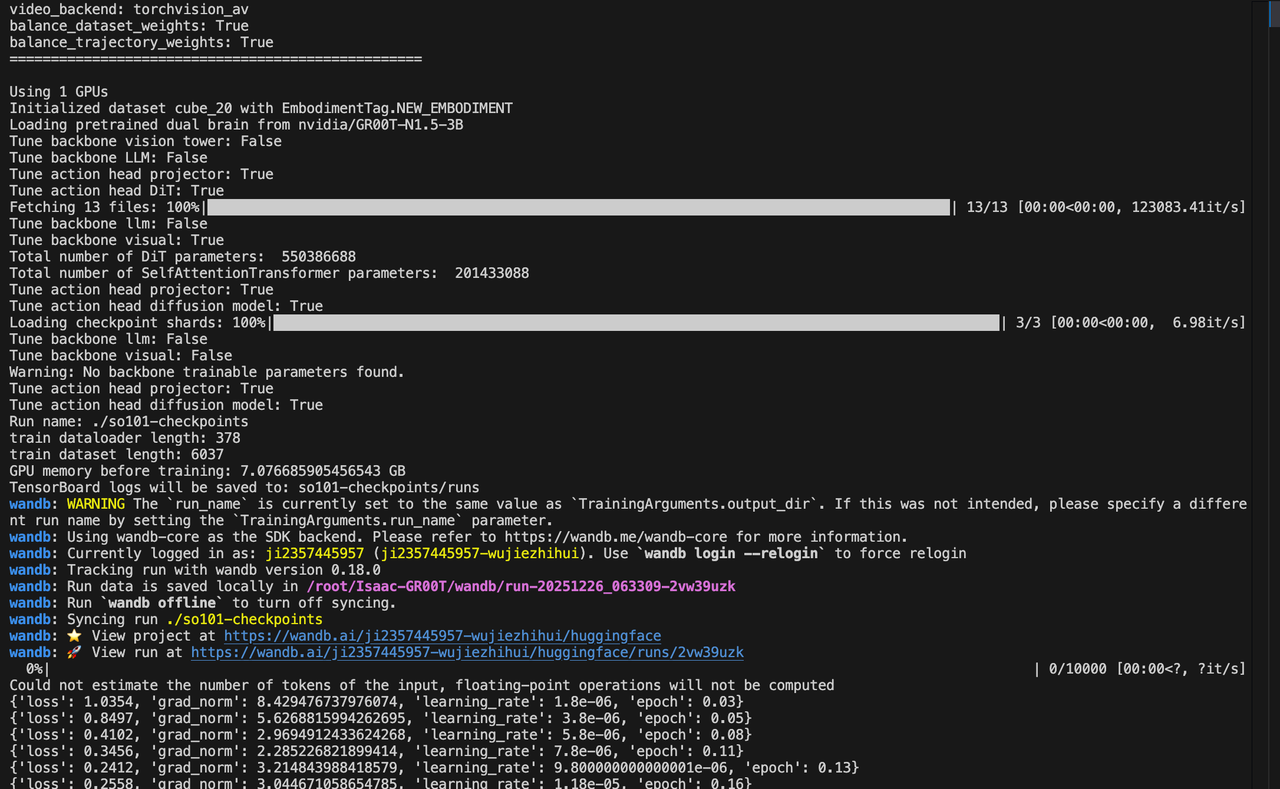
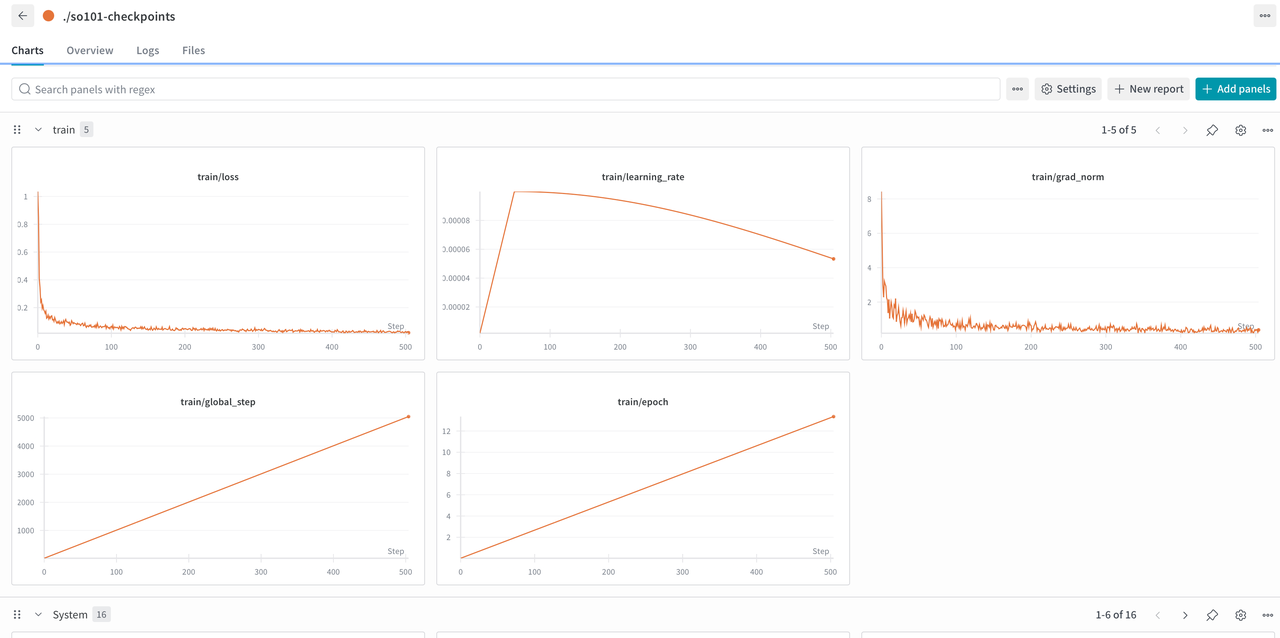
我们在第一次训练的时候需要将wandb的apikey输入下,以便于训练可视化。
4.5 模型部署
打开新的终端进入到同一个容器内部,我们可以通过docker ps命令查看当前容器的id:

然后通过以下命令进入该容器内部:
python
docker exec -it <container id> /bin/bash接着进入到GROOT代码主目录下运行下面的命令:
python
python scripts/inference_service.py --server \
--model_path ./so101-checkpoints/checkpoint-6500 \
--embodiment-tag new_embodiment \
--data-config so100_dualcam \
--denoising-steps 4推理服务端开启后如下图所示:
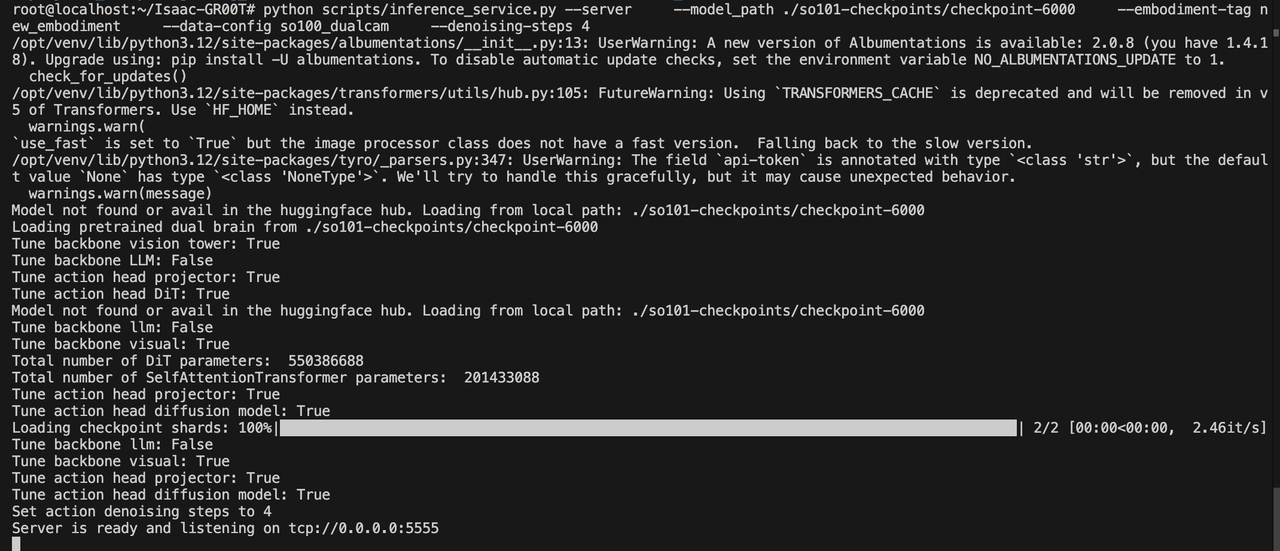
4.6 真机测试
首先赋予/dev/ttyACM* 权限:
python
sudo chmod 666 /dev/ttyACM*接着运行client端代码:
python
python examples/SO-100/eval_lerobot.py \
--robot.type=so100_follower \
--robot.port=/dev/ttyACM0 \
--robot.id=my_awesome_follower_arm \
--robot.cameras="{ wrist: {type: opencv, index_or_path: 4, width: 640, height: 480, fps: 30}, front: {type: opencv, index_or_path: 6, width: 640, height: 480, fps: 30}}" \
--policy_host=192.168.112.254 \
--lang_instruction="pick up the blue cube and place it on the plate"成功推理如下图所示:
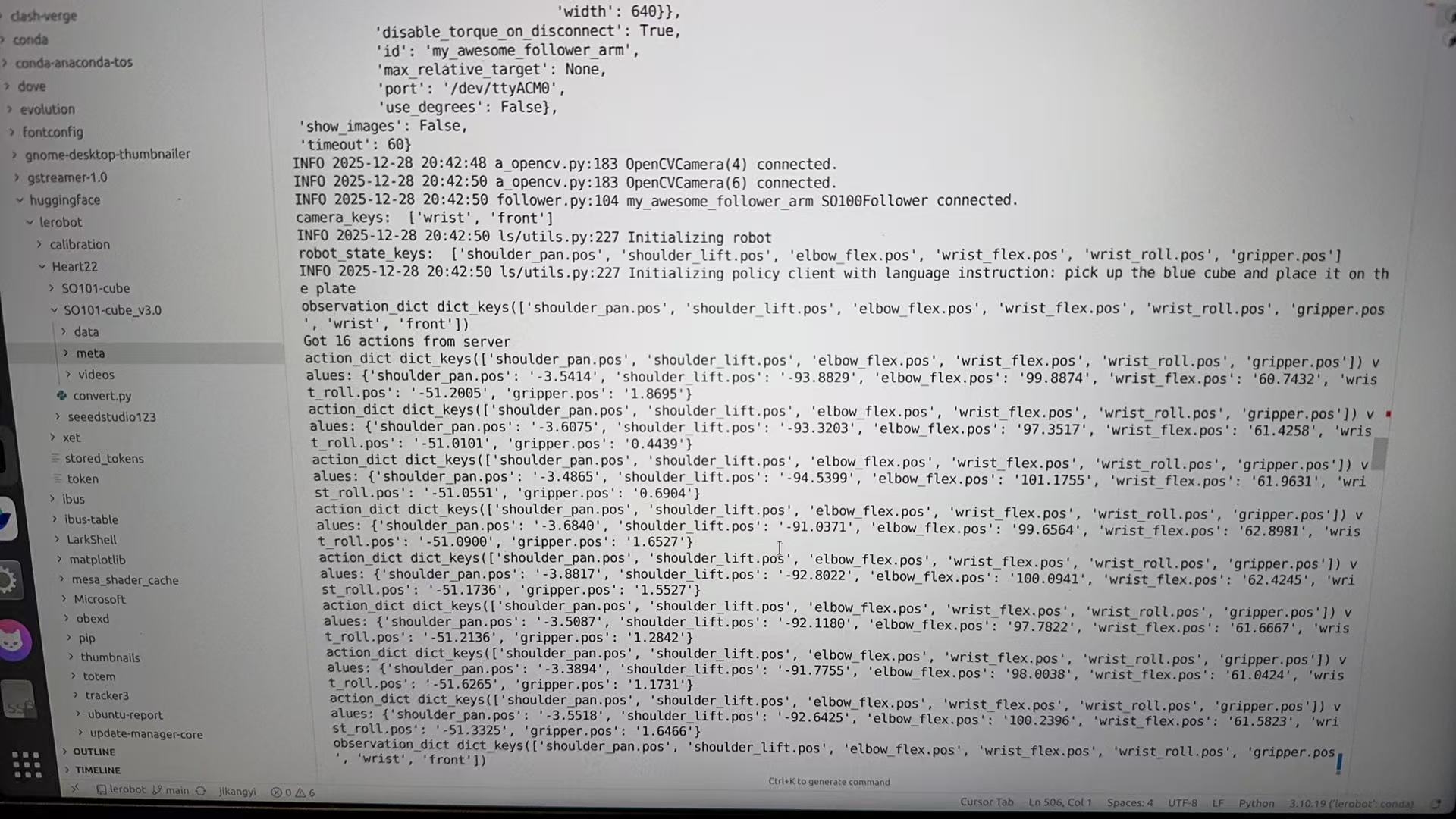
如果不确定自己的摄像头的index,可以通过以下命令查找:
python
lerobot-find-cameras opencv终端会打印相关摄像头信息。
python
(gr00t) jikangyi@jikangyi-ThinkBook-16-G7-IAH:~/Isaac-GR00T$ lerobot-find-cameras opencv
--- Detected Cameras ---
Camera #0:
Name: OpenCV Camera @ /dev/video0
Type: OpenCV
Id: /dev/video0
Backend api: V4L2
Default stream profile:
Format: 16.0
Fourcc: YUYV
Width: 640
Height: 480
Fps: 30.0
--------------------
Camera #1:
Name: OpenCV Camera @ /dev/video2
Type: OpenCV
Id: /dev/video2
Backend api: V4L2
Default stream profile:
Format: 16.0
Fourcc: GREY
Width: 640
Height: 360
Fps: 30.0
--------------------
Camera #2:
Name: OpenCV Camera @ /dev/video4
Type: OpenCV
Id: /dev/video4
Backend api: V4L2
Default stream profile:
Format: 16.0
Fourcc: YUYV
Width: 640
Height: 480
Fps: 30.0
--------------------
Camera #3:
Name: OpenCV Camera @ /dev/video6
Type: OpenCV
Id: /dev/video6
Backend api: V4L2
Default stream profile:
Format: 16.0
Fourcc: YUYV
Width: 640
Height: 480
Fps: 30.0
--------------------
Finalizing image saving...
Image capture finished. Images saved to outputs/captured_images类似于上面的输出,index索引对应/dev/video*对应的数字id。
Document