基于Scrapy框架全站抓取菜鸟教程(Python3)
文章目录
- 基于Scrapy框架全站抓取菜鸟教程(Python3)
-
- 摘要
- [一、 原理与架构设计](#一、 原理与架构设计)
-
- [1.1 Scrapy 核心机制](#1.1 Scrapy 核心机制)
- [1.2 本次实验策略](#1.2 本次实验策略)
- [二、 实施过程](#二、 实施过程)
-
- [2.1 项目初始化](#2.1 项目初始化)
- [2.2 目标网址分析与 XPath 设计](#2.2 目标网址分析与 XPath 设计)
- [2.3 核心代码实现](#2.3 核心代码实现)
-
- [(1) 定义数据模型 (`items.py`)](#(1) 定义数据模型 (
items.py)) - [(2) 编写爬虫逻辑 (`runoob_spider.py`)](#(2) 编写爬虫逻辑 (
runoob_spider.py)) - [(3) 编写数据管道 (`pipelines.py`)](#(3) 编写数据管道 (
pipelines.py)) - [(4) 调整配置 (`settings.py`)](#(4) 调整配置 (
settings.py))
- [(1) 定义数据模型 (`items.py`)](#(1) 定义数据模型 (
- [三、 结果分析](#三、 结果分析)
-
- [3.1 运行结果](#3.1 运行结果)
- [3.2 产出文件结构](#3.2 产出文件结构)
- [3.3 项目结构总结](#3.3 项目结构总结)
- [四、 问题与思考](#四、 问题与思考)
-
- [Q1: 为什么 PyCharm 中部分代码标红,但终端运行正常?](#Q1: 为什么 PyCharm 中部分代码标红,但终端运行正常?)
- [Q2: 在提取链接时,正则表达式与 XPath 有何本质区别?](#Q2: 在提取链接时,正则表达式与 XPath 有何本质区别?)
摘要
本文记录了一次基于 Scrapy 框架的爬虫实战过程。目标是自动化抓取 菜鸟教程 的 Python3 系列教程,实现了全站链接自动追踪、数据结构化提取,并设计了 JSON 与 TXT 双格式的数据持久化管道。文章详细解析了 CrawlSpider 的使用、XPath 策略分析以及反爬配置。
一、 原理与架构设计
1.1 Scrapy 核心机制
Scrapy 是一个基于 Python 的开源、高效网络爬虫框架。它采用异步事件驱动架构(基于 Twisted),通过组件化设计实现高并发数据抓取。其核心工作流程如下:
- 调度器 (Scheduler):管理请求队列,决定下一个抓取哪个网址。
- 下载器 (Downloader):异步获取网页内容。
- 爬虫 (Spider):解析页面结构,提取数据(Items)或新的链接(Requests)。
- 管道 (Pipeline):进行数据清洗、验证和持久化存储。
1.2 本次实验策略
- 链接追踪 :基于
CrawlSpider类,利用LinkExtractor组件配合正则表达式/XPath,自动匹配左侧导航栏的教程链接,实现全站遍历。 - 数据提取 :使用
XPath选择器定位 HTML DOM 树,精准提取标题、正文等信息。 - 反爬处理 :
- 禁用
ROBOTSTXT_OBEY规避协议限制。 - 关闭
COOKIES_ENABLED避免会话追踪。 - (可选) 设置下载延迟模拟人工频率。
- 禁用
- 存储方案:设计双重管道,同时输出机器可读的 JSON 文件和人类可读的 TXT 文本。
二、 实施过程
2.1 项目初始化
首先创建 Scrapy 项目及爬虫文件:
bash
# 1. 创建项目
scrapy startproject elaine_RunoobScrapy
# 2. 进入目录并生成 CrawlSpider 模板
cd elaine_RunoobScrapy
scrapy genspider -t crawl runoob_spider runoob.com2.2 目标网址分析与 XPath 设计
目标地址:https://www.runoob.com/python3/python3-tutorial.html
通过开发者工具 (F12) 分析页面结构,我们需要精准定位左侧导航栏中的 Python3 相关链接,避免抓取到广告或测试题(Quiz)。

- 左侧导航栏容器 :
div[@id="leftcolumn"] - 目标链接特征:href 属性包含 "python3",且不包含 "quiz"。
最终的链接提取 XPath:
xpath
//div[@id="leftcolumn"]//a[contains(@href, "python3") and not(contains(@href, "quiz"))]2.3 核心代码实现
(1) 定义数据模型 (items.py)
明确我们需要抓取的字段:
python
import scrapy
class RunoobItem(scrapy.Item):
title = scrapy.Field() # 教程标题
url = scrapy.Field() # 教程链接
content = scrapy.Field() # 教程正文
crawl_time = scrapy.Field() # 爬取时间(2) 编写爬虫逻辑 (runoob_spider.py)
继承 CrawlSpider,配置 rules 实现自动翻页:
python
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from elaine_RunoobScrapy.items import RunoobItem
from datetime import datetime
class RunoobSpiderSpider(CrawlSpider):
name = "runoob_spider"
allowed_domains = ["runoob.com"]
start_urls = ["https://www.runoob.com/python3/python3-tutorial.html"]
# 定义链接提取规则
rules = (
Rule(
LinkExtractor(
# 仅在左侧导航栏提取 Python3 相关链接
restrict_xpaths=[
'//div[@id="leftcolumn"]//a[contains(@href, "python3") and not(contains(@href, "quiz"))]'
]
),
callback='parse_item', # 回调函数处理详情页
follow=True # 允许跟进链接
),
)
def parse_item(self, response):
item = RunoobItem()
# 提取标题(兼容多种页面结构)
title = response.xpath('//div[contains(@class, "article-header")]//h1/text()').get()
if not title:
title = response.xpath('//h1/text()').get()
item['title'] = title.replace(' | 菜鸟教程', '').strip() if title else "未知标题"
item['url'] = response.url
# 提取正文并简单清洗
content_sections = response.xpath('//div[contains(@class, "article-body")]//text()').getall()
item['content'] = '\n'.join([s.strip() for s in content_sections if s.strip()])[:200] # 截取前200字预览
item['crawl_time'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
return item(3) 编写数据管道 (pipelines.py)
实现 JSON 和 TXT 的双重存储:
python
import json
import codecs
import os
from itemadapter import ItemAdapter
class ElaineRunoobscrapyPipeline:
def __init__(self):
self.data_dir = 'tutorial_data'
if not os.path.exists(self.data_dir):
os.makedirs(self.data_dir)
# 初始化文件流
self.json_file = codecs.open(f'{self.data_dir}/python3_tutorials.json', 'w', encoding='utf-8')
self.txt_file = codecs.open(f'{self.data_dir}/python3_tutorials.txt', 'w', encoding='utf-8')
self.json_file.write('[\n')
self.first_item = True
def process_item(self, item, spider):
adapter = ItemAdapter(item)
# 写入 JSON
if not self.first_item:
self.json_file.write(',\n')
self.first_item = False
json.dump(dict(adapter), self.json_file, ensure_ascii=False, indent=2)
# 写入 TXT
self.txt_file.write(f"标题: {adapter.get('title')}\n链接: {adapter.get('url')}\n")
self.txt_file.write("-" * 50 + "\n\n")
return item
def close_spider(self, spider):
self.json_file.write('\n]')
self.json_file.close()
self.txt_file.close()(4) 调整配置 (settings.py)
python
# 忽略 robots.txt
ROBOTSTXT_OBEY = False
# 禁用 Cookies
COOKIES_ENABLED = False
# 启用我们编写的 Pipeline
ITEM_PIPELINES = {
"elaine_RunoobScrapy.pipelines.ElaineRunoobscrapyPipeline": 300,
}三、 结果分析
3.1 运行结果
执行命令 scrapy crawl runoob_spider 后,控制台输出如下:
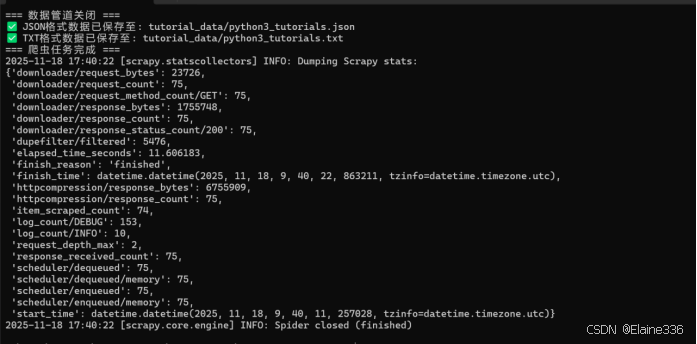
- 爬取页面:约 75 个
- 成功提取:74 个教程项目
- 总耗时:约 11.6 秒
3.2 产出文件结构
项目根目录下自动生成了 tutorial_data 文件夹:

- python3_tutorials.json :
- 格式规范的 JSON 数组,包含所有元数据,适合后期导入数据库或进行 Pandas 分析。
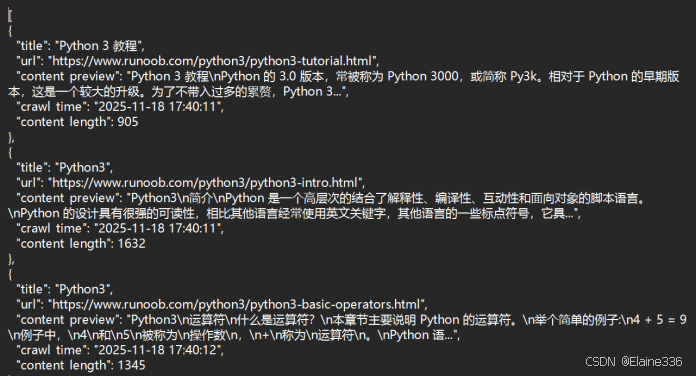
- python3_tutorials.txt :
- 人类可读的文本报告,包含标题、链接和部分内容预览。

3.3 项目结构总结
scrapy.cfg: 项目部署配置。items.py: 定义了数据的"模具"。runoob_spider.py: 核心逻辑,定义了"怎么爬"和"怎么解析"。pipelines.py: 后处理逻辑,定义了"数据存哪去"。settings.py: 全局控制中心。
四、 问题与思考
Q1: 为什么 PyCharm 中部分代码标红,但终端运行正常?
A: 这是 PyCharm 静态代码分析与 Python 动态运行时环境的差异导致的。Scrapy 框架大量使用了动态属性注入和元编程技术(例如 Item 的字段访问),IDE 在静态扫描时无法推断出这些属性在运行时是存在的。只要代码逻辑正确,遵循 Scrapy 规范,直接运行即可。
Q2: 在提取链接时,正则表达式与 XPath 有何本质区别?
- 正则表达式 (Regex) :基于文本模式匹配。它将 HTML 视为纯字符串,适合提取特定格式的字符(如提取 URL 中的 ID、日期),不关心 HTML 的层级结构。
- XPath :基于 DOM 树 导航。它解析 HTML 的层级结构(父子、兄弟节点、属性),定位更精准。例如"提取左侧导航栏(
div#leftcolumn)下的所有链接",用 XPath 描述非常自然,而用正则则很难处理嵌套结构。
结语
- 通过本次进阶实战,我不仅掌握了 Scrapy 的核心架构,更深刻体会到了"组件化"编程的魅力。从 CrawlSpider 的自动追踪到Pipeline 的灵活存储,每一个环节都展现了 Scrapy 作为工业级爬虫框架的强大。
⚖️ 爬虫合法性与伦理建议 (Ethics & Legality)
在进行数据采集实验时,开发者应始终遵循"技术向善"的原则,确保行为的合法性与合理性:
尊重 Robots 协议:在本项目设置中,为了实验目的将 ROBOTSTXT_OBEY 设为了 False 。但在实际生产环境和商业爬虫中,应优先遵守网站的 robots.txt 声明 。
控制抓取频率:实验报告中提到,应通过设置下载延迟等手段模拟人工操作频率。过度高频的请求会对目标服务器造成负担,甚至被视为攻击行为。
保护隐私与会话隔离:通过关闭 Cookies (COOKIES_ENABLED = False),可以避免会话追踪,降低对用户私密数据的触碰风险 。
数据用途明确:本实验项目聚焦于 Scrapy 进阶功能的学术落地与教学研究。爬取的数据应仅用于学习、科研或个人非营利性目的,严禁用于非法牟利或侵犯版权。
合规声明:爬虫开发应遵守《网络安全法》及相关法律法规。在采集涉及个人隐私或受版权保护的内容前,应征得相关权利人的许可。