1. 核心命题
个人学习/工作的本质不是"获取信息",而是持续完成四件事:
-
把目标变成可执行的任务结构(从"想做"到"能做")
-
在复杂上下文中保持一致的理解(从"碎片"到"体系")
-
在行动中缩短反馈周期并积累可复用经验(从"做完"到"做对且越来越快")
-
在长期中对抗遗忘、漂移和自我欺骗(从"当下聪明"到"持续进步")
"人机协同认知引擎"要解决的不是一次对话的聪明,而是长期、稳定、可复利的认知生产力。
2. 方法论总原则:把协同从"对话"升级为"闭环系统"
单纯的 LLM 交互是"即时生成";认知引擎要做的是"持续运营"。因此方法论上必须满足三条总原则:
-
结构化优先于表述:先建结构(目标/约束/状态/证据/行动),再生成语言。
-
证据优先于观点:输出结论必须能回指到来源、上下文与推理路径(至少可审计)。
-
闭环优先于答案:每次协同的产物必须能进入下一次协同(可复用、可更新、可迭代)。
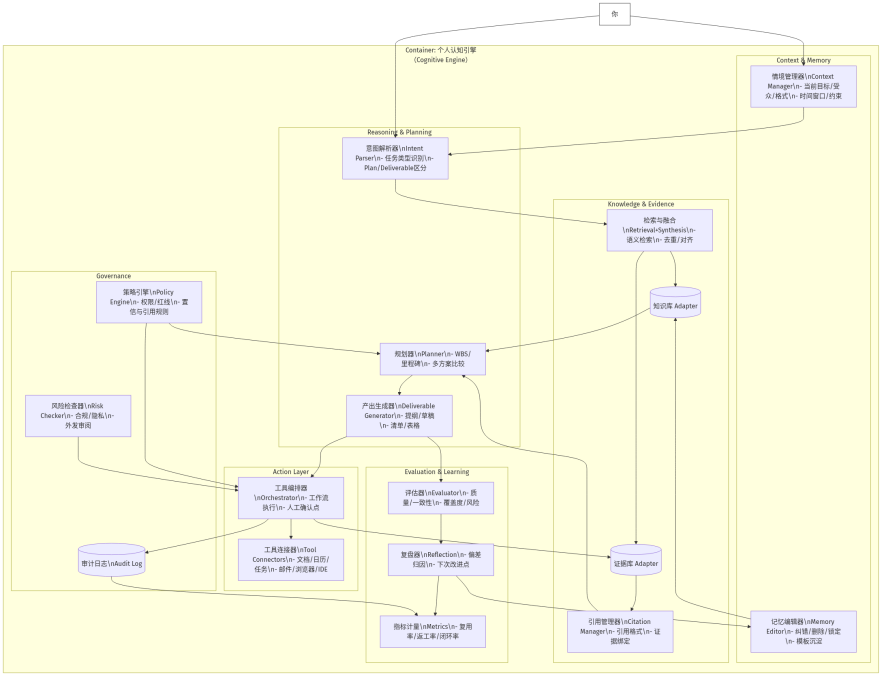
3. 架构原理:一个"认知引擎"应有的六层
个人场景下的认知引擎可以抽象为 6 层(不是产品形态,而是认知功能分工)。你可以把它理解为:人负责价值与最终裁决,机器负责结构、检索、推演、执行编排与复盘记账。
L1 情境层 Context
目的:让系统"知道你现在是谁、在做什么、为什么做、有什么限制"。
-
关键对象:当前任务、角色(学习者/写作者/管理者)、时间窗口、风险偏好、输出格式、受众
-
架构含义:把"提示词"从临时输入升级为可维护的"情境对象"
-
方法论:先对齐情境,再谈解决方案(否则方案会漂)
L2 世界模型层 World Model(个人版)
目的:让系统拥有"可运行的个人知识与工作对象模型",避免每次从零理解。
-
关键对象:主题知识图谱、项目/文档/决策记录、能力模型、概念定义、常用框架
-
关键机制:概念---关系---状态---约束(至少要有"状态"与"约束",否则只是笔记堆)
-
方法论:把你在乎的对象变成"可查询、可更新、可引用"的结构化实体
L3 证据与记忆层 Evidence & Memory
目的:让协同具备可追溯性与抗幻觉能力,并形成长期复利。
-
三类记忆:
-
事实记忆:结论、数据、定义、最终稿
-
过程记忆:推理过程、比较方案、踩坑与取舍
-
偏好记忆:写作风格、决策偏好、工作习惯(可控、可删改)
-
-
方法论:任何"重要结论"都必须绑定证据(引用、来源、上下文、时间)
L4 推理与规划层 Reasoning & Planning(LLM 在这里)
目的:把 L1-L3 的结构当底座,生成"可执行计划"和"可验证中间产物"。
-
典型输出不是"答案",而是:
-
任务分解(WBS/里程碑/检查点)
-
多方案比较(假设---证据---风险---成本)
-
质量标准(验收清单、评审维度)
-
-
方法论:强制区分 Plan(计划)/Do(行动)/Check(验证)/Learn(更新)
L5 行动与外部化层 Action & Externalization
目的:让系统不止"建议",还能把建议变成你能直接用的外部化成果。
-
连接对象:日程、任务管理、笔记/知识库、文档、代码仓库、邮件、会议纪要
-
关键机制:工具调用/流程编排/模板化输出
-
方法论:每次协同必须留下"可复用工件":
- 文档模板、可复制的清单、可执行的步骤、可复盘的记录
L6 评估与学习层 Evaluation & Meta-cognition
目的:让系统自我校准,持续提升"可靠性与效率",并避免把错误固化进记忆。
-
评估对象:
-
产出质量:是否满足目标与受众
-
过程质量:是否走了弯路、是否遗漏关键风险
-
协同效率:你是否更省力、是否更少返工
-
-
方法论:用"复盘-更新"替代"用完即弃的对话"
4. 运行机理:个人认知引擎的"闭环工作流"
可以把协同过程简化成一个稳定的闭环(每次都走一遍,但可以很快):
-
对齐情境:确认目标、约束、交付物形态
-
调用世界模型:相关概念/项目背景/历史决策自动带入
-
检索证据:优先引用你的资料与可信来源(个人场景尤其重要)
-
生成计划与中间件:先产出结构化骨架(提纲/清单/里程碑)
-
行动外部化:产出可直接投入工作的工件(文档、任务列表、邮件草稿等)
-
评估与沉淀:记录关键取舍、失败模式、下一次复用的提示/模板
这套闭环的关键,是把"每次聊天的临时智能"变成"可积累的认知资产"。
5. 治理原则:个人场景也必须"可控"
个人使用同样会出现:误导、偏见固化、过度自动化、隐私泄露、目标漂移。认知引擎要内建治理:
-
权限与边界:什么能自动做、什么必须你确认(尤其是对外输出)
-
来源分级:个人资料 > 权威资料 > 互联网泛资料;不同等级使用不同置信策略
-
记忆可编辑:允许你一键纠错/删除偏好/覆盖旧结论
-
反幻觉策略:不确定就标注不确定;关键事实必须引用来源或提示需要核验
-
反漂移机制:每个项目有"北极星指标"和"禁区清单"(避免越做越偏)
6. 个人场景的落地形态:最小可行"认知引擎"
不谈具体产品,只谈最小结构,你至少需要四个"库"和两个"板":
-
四个库:
-
项目库(目标、里程碑、决策、产出物)
-
知识库(概念体系、框架、引用资料)
-
证据库(来源、摘录、时间戳、上下文)
-
模板库(提纲、清单、提示词/流程脚本)
-
-
两个板:
-
任务面板(在做什么、下一步是什么、卡点是什么)
-
复盘面板(哪里浪费、哪里高质量、下次怎么更快)
-
LLM 的价值被"架构化"以后,会从"聪明聊天"变成"稳定生产"。
7. 判断是否真正变成"引擎"的指标
个人最有用的指标不是模型分数,而是这三类:
-
复用率:模板/清单/提纲/流程被复用的次数
-
返工率:对外输出/重要文档被大改的次数是否下降
-
闭环率:每次协同是否形成可沉淀资产(而不是聊完就没了)