摘要 :2026 年,CRUD 工程师的生存空间被无限压缩,大厂面试全是 AI Agent、RAG、向量数据库。作为 Go/Java 开发者,真的要重头学 Python 吗?本文将通过一个已上线的企业级 AI 面试平台(基于字节跳动 Eino + Hertz + Milvus),带你从 0 到 1 拆解如何用 Go 语言构建高性能 AI 应用。
一、 后端人的"中年危机"与 AI 破局
兄弟们,见字如面,我是阳哥。
最近翻看 Boss 直聘和拉勾,大家有没有发现一个扎心的现象:纯后端开发的岗位越来越少了,要求越来越高了。 以前会写 CRUD、懂点 Redis/MySQL 就能拿高薪,现在 JD 里满屏都是:
- "熟悉 LLM 应用开发"
- "有 LangChain/Agent 落地经验优先"
- "熟悉 RAG 检索增强生成技术"
很多兄弟私信我:"阳哥,我想转 AI,是不是得先把 Python 学一遍?我看网上教程都是 Python 的。"
错!大错特错!
在 模型训练(Training) 阶段,Python 确实是王者。但在 **应用落地 Serving **阶段,特别是企业级的高并发场景下,Go 语言的并发能力、类型安全和工程化优势,是 Python 无法比拟的。
字节跳动最近开源的 Eino 框架,更是给 Go 开发者送来了一把"神兵利器"。它让我们可以像写微服务一样,用强类型、组件化的方式编排复杂的 AI Agent。
今天,我就通过我最近带队开发并上线的 【面试吧】(Interview Agent) 项目,手把手带你看看:一个真正的企业级 AI Agent 平台,到底是怎么长出来的。
二、 为什么是 Go + Eino?
在做这个项目之前,我也调研过 Python 的 LangChain。说实话,写 Demo 很爽,但一上生产环境就头大:
- 调试困难:动态类型一时爽,重构火葬场。
- 并发拉胯:Python 的 GIL 锁懂的都懂,高并发下延迟感人。
- 黑盒严重:很多逻辑被封装在库里,想改改不动。
而 Eino(CloudWeGo 团队开源)完美解决了这些痛点:
- 强类型约束:编译期就能发现 80% 的错误,代码写起来心里有底。
- Graph 编排 :用图(Graph)的结构来定义 Agent 的思考路径,逻辑清晰,比满屏的
if-else优雅太多。 - 完美融入 Go 生态 :可以无缝结合 Hertz (高性能 Web 框架)和 Kitex(RPC 框架)。
三、 硬核拆解:从架构到代码
【面试吧】 是一个模拟真实面试的 AI 平台。用户上传简历,AI 面试官(Go/Java/Redis 专项专家)会根据简历内容进行多轮提问,并生成评估报告。
在线体验 :mianshiba.dayu.club/
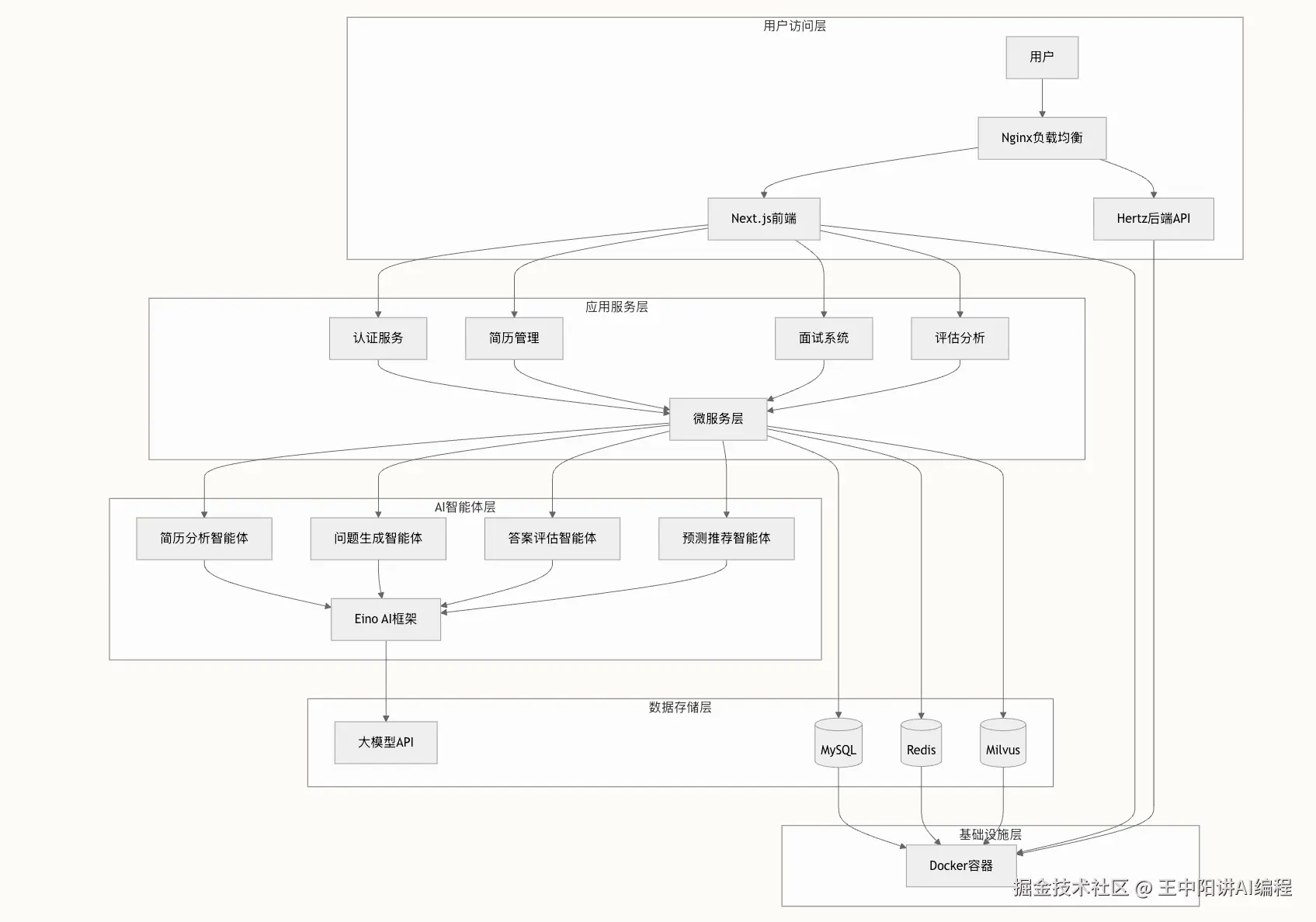
3.1 总体架构设计
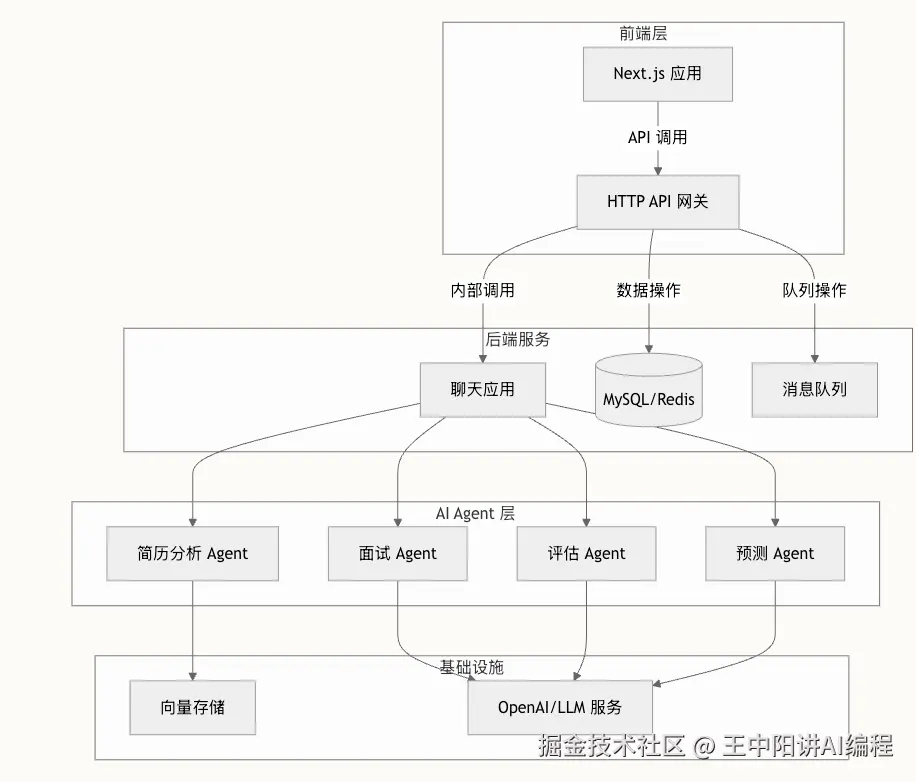
我们没有搞简单的 API 套壳,而是按照大厂微服务标准设计的:
- 网关层:Hertz (HTTP)
- 编排层:Eino (Agent Graph)
- 模型层:接入 DeepSeek/OpenAI
- 数据层:MySQL (业务数据) + Milvus (向量数据)
- 中间件:Redis Queue (异步削峰)
3.2 核心代码 Show Case
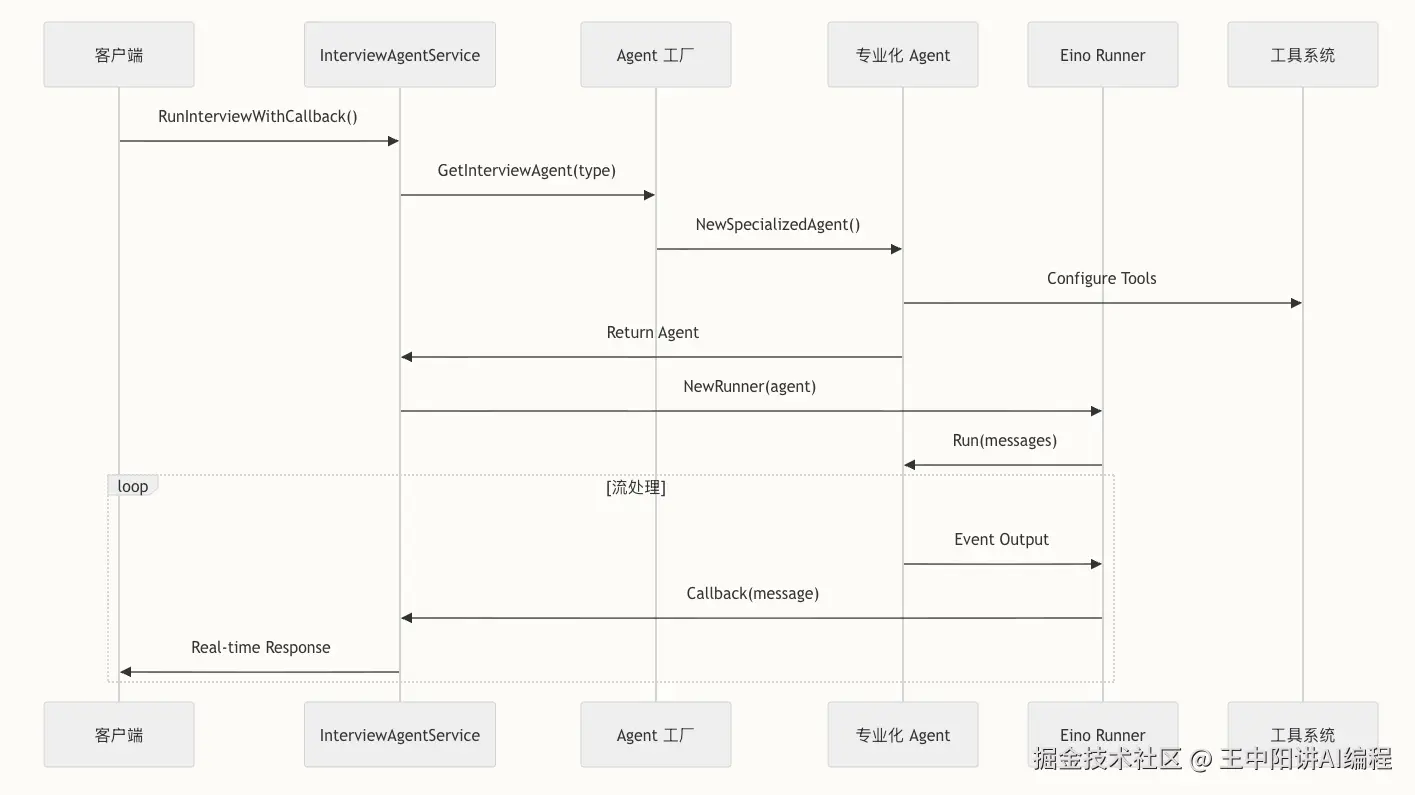
场景一:定义一个"会思考"的 Agent
在 Eino 中,我们不再写死对话逻辑,而是定义一个 Agent 。看这段代码,我们如何创建一个 Go 语言专项面试官:
go
// backend/chatApp/agent/interview/specialized/go_agent.go
func NewGoSpecializedAgent(userId uint, needResumeTool bool) (adk.Agent, error) {
// 1. 准备工具箱(Tool Use)
// 如果需要分析简历,就挂载简历分析工具
var toolsConfig adk.ToolsConfig
if needResumeTool {
toolsConfig = adk.ToolsConfig{
ToolsNodeConfig: compose.ToolsNodeConfig{
Tools: []componenttool.BaseTool{
tool2.GetResumeInfoTool(), // 自定义工具:从 PDF 解析简历
},
},
}
}
// 2. 创建 Agent
// 使用 ReAct 范式:Reasoning + Acting
baseAgent, err := adk.NewChatModelAgent(ctx, &adk.ChatModelAgentConfig{
Name: "GoSpecializedAgent",
Description: "Go 专项面试官,专注于评估 GMP 模型、GC 机制等深度知识",
Instruction: GoSpecializedAgentInstruction, // 深度调优的 System Prompt
Model: model, // 底层大模型
ToolsConfig: toolsConfig,
MaxIterations: 15, // 最大思考轮数,防止死循环
})
return baseAgent, nil
}亮点 :通过 ToolsConfig,我们让 Agent 拥有了"手"和"眼",它不再只是瞎聊,而是会先去查简历,再针对性提问。
场景二:RAG 混合检索(解决幻觉)
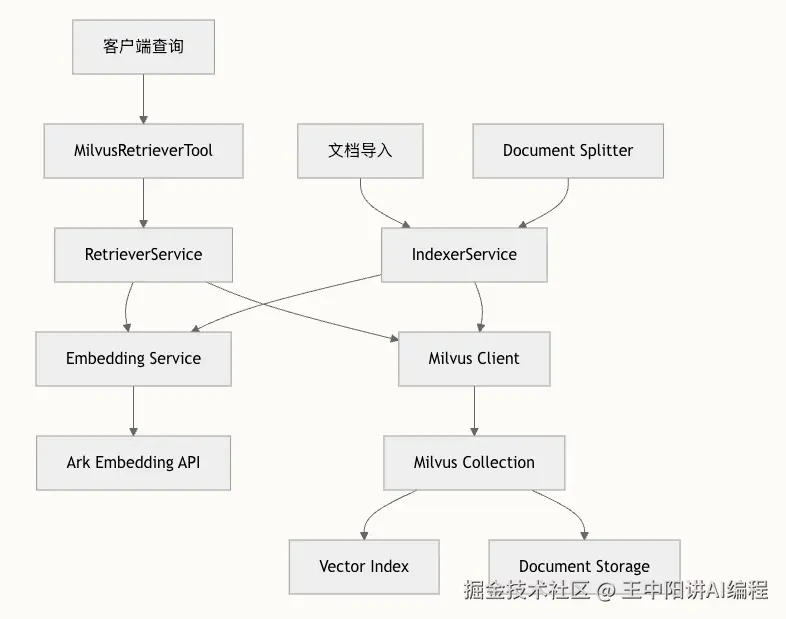
为了让 AI 面试官有"标准答案",我们引入了 Milvus 做知识库。这里我们实现了一个混合检索逻辑:
go
// backend/internal/eino/milvus/retrieval/retriever.go
func (s *RetrieverService) RetrieveWithOptions(ctx context.Context, query string, opts *RetrieveOptions) ([]*schema.Document, error) {
// 1. 构建标量过滤表达式(Filter)
// 比如:只检索"Go语言"分类下,"难度系数 > 3"的题目
expr := BuildFilterExpr(opts)
// 2. 调用 Milvus 进行向量相似度搜索
// Eino 的接口设计非常规范,直接对齐大厂标准
if expr != "" {
return SearchWithExpr(ctx, s.client, s.config, query, expr, opts)
}
// ... 默认检索逻辑
}亮点 :真正的企业级 RAG,绝不是简单的向量搜索。必须结合标量过滤(Scalar Filtering),才能精准命中业务数据。
场景三:异步削峰与流式响应
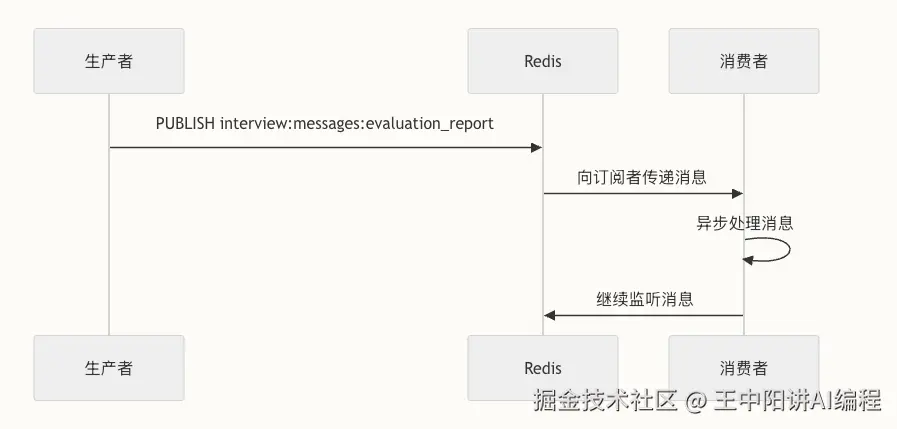
AI 推理是很慢的(可能几秒到几十秒)。如果在主线程同步等待,Hertz 服务早被拖垮了。 我们设计了一套 Redis 队列 + SSE 机制:
- 用户发请求 -> 写入 Redis 队列 -> 立刻返回
task_id。 - 后台 Consumer 轮询队列 -> 调用 Eino Agent 执行推理。
- 前端通过 SSE (Server-Sent Events) 长连接监听
task_id,实现打字机效果。
go
// backend/internal/mq/redis_queue.go
func (q *RedisQueue) Publish(ctx context.Context, topic string, message []byte) error {
// 使用 LPUSH 写入任务
return q.client.LPush(ctx, topic, message).Err()
}
// Consumer 端
func (c *Consumer) Start() {
for {
// 使用 BRPOP 阻塞式读取,避免空轮询浪费 CPU
result, err := c.client.BRPop(ctx, 0, c.topic).Result()
// ... 处理 AI 任务
}
}四、 实战复盘:我踩过的那些坑
做 Demo 容易,上生产难。在这个项目开发过程中,我也踩了不少坑,分享给大家:

- Token 爆炸 :最开始没做上下文截断,聊了十几轮后,Token 消耗指数级上升,接口直接报错。后来引入了滑动窗口机制,只保留最近 N 轮的核心对话。
- Prompt 调优 :一开始 AI 总是"老好人",面试不敢追问。后来我们引入了 CoT(思维链),在 Prompt 里强制要求它"必须针对候选人的回答中的漏洞进行追问",效果瞬间提升。
- PDF 解析乱码:很多简历格式奇葩。最后我们对比了多种 OCR 方案,选定了一套基于规则+模型的混合解析方案,准确率提升到 95% 以上。
五、 写在最后
技术在变,但工程化的本质不变。 AI 时代,Go 开发者依然大有可为。
如果你也想从 CRUD 转型 AI 全栈,如果你也想拥有一套能写进简历、能抗住面试官深挖的商业级 AI 项目代码,欢迎一起交流。
这个项目的完整源代码(Go/Next.js/Docker) 、20+小时的视频讲解 以及详细的开发文档,我已经全部整理好了。
👉 获取方式: 关注公众号【王中阳 】,回复"面试吧 ",即可获取项目演示和源码线索。 或者直接绿泡泡私信我,备注"掘金",拉你进技术交流群。
2026,别焦虑,搞技术,搞落地!