【大模型LLM学习】通义Agent学习笔记
- 场景
- [1. WebWalker](#1. WebWalker)
- [2. WebDancer](#2. WebDancer)
-
- [2.1 CRAWLQA数据构造](#2.1 CRAWLQA数据构造)
- [2.2 E2HQA数据构造](#2.2 E2HQA数据构造)
- [2.3 正确的轨迹数据构造](#2.3 正确的轨迹数据构造)
- [3. WebSailor](#3. WebSailor)
-
- [Level 3 数据集构造](#Level 3 数据集构造)
- [4. WebShaper](#4. WebShaper)
- [5. WebWatcher](#5. WebWatcher)
- [6. WebResearcher](#6. WebResearcher)
-
- IterResearch
- WebFrontier数据构造方法
- [Test Time Scaling](#Test Time Scaling)
- [7. ReSum](#7. ReSum)
- [8. WebWeaver](#8. WebWeaver)
- [9. WebSailor-V2](#9. WebSailor-V2)
- [10. AgentFounder](#10. AgentFounder)
-
- [First-order Action Synthesis with Zero Supervisory Signal](#First-order Action Synthesis with Zero Supervisory Signal)
- [High-order Action Synthesis](#High-order Action Synthesis)
- [11. AgentScaler](#11. AgentScaler)
- [12. AgentFold](#12. AgentFold)
- [13. WebLeaper](#13. WebLeaper)
-
- QA构造pipeline
-
- [Version 1: Basic](#Version 1: Basic)
- [Version 2: Union](#Version 2: Union)
- [version 3: Reverse-Union](#version 3: Reverse-Union)
- 轨迹构造
- [14. BrowseConf](#14. BrowseConf)
- [15. E-GRPO](#15. E-GRPO)
- [16. ParallelMuse](#16. ParallelMuse)
- [17. AgentFrontier](#17. AgentFrontier)
- [18. DeepResearch](#18. DeepResearch)
场景
通义的一系列Agent,一开始的目标是构建自主借助网络搜索答案的WebAgent系列,后续基于这些WebAgent,通义开发了Deep Researcher系列。涉及的论文很多,记录一下学习笔记方便日后查阅~
WebAgent的场景,是给定问题,Agent思考,并使用搜索、浏览、点击链接等工具,生成正确答案。
要做好WebAgent,需要解决的问题主要有:
- 【数据缺失】如何构建web场景训练的Q-A数据集,针对性提升模型思考、调用工具和回答的能力
- 【复杂问题解决能力】如何构建难样本,提升模型回答需要复杂检索、调用工具的问题的能力
- 【模型训练】如何高效训练模型、设计奖励信号
- 【上下文管理】对于复杂问题,思考-调用工具-思考...-回答,轮次很多,上下文窗口装不下怎么办
- 【TTS】如何提升回答速度和准确率(Test Time Scaling何时如何进行)
1. WebWalker
- 论文名《WebWalker: Benchmarking LLMs in Web Traversal》,arXiv ID为2501.07572
- 文中提出了一种两Agent协作的框架,一个Agent负责探索网页,另一个Agent负责回答。
- 运行时,首先指定网站链接,浏览网页内容以及里面的所有链接内容,看能否回答,还是要点击链接寻找答案。Agent拥有的工具为【click】,能够决定是否以及点击哪一个链接。
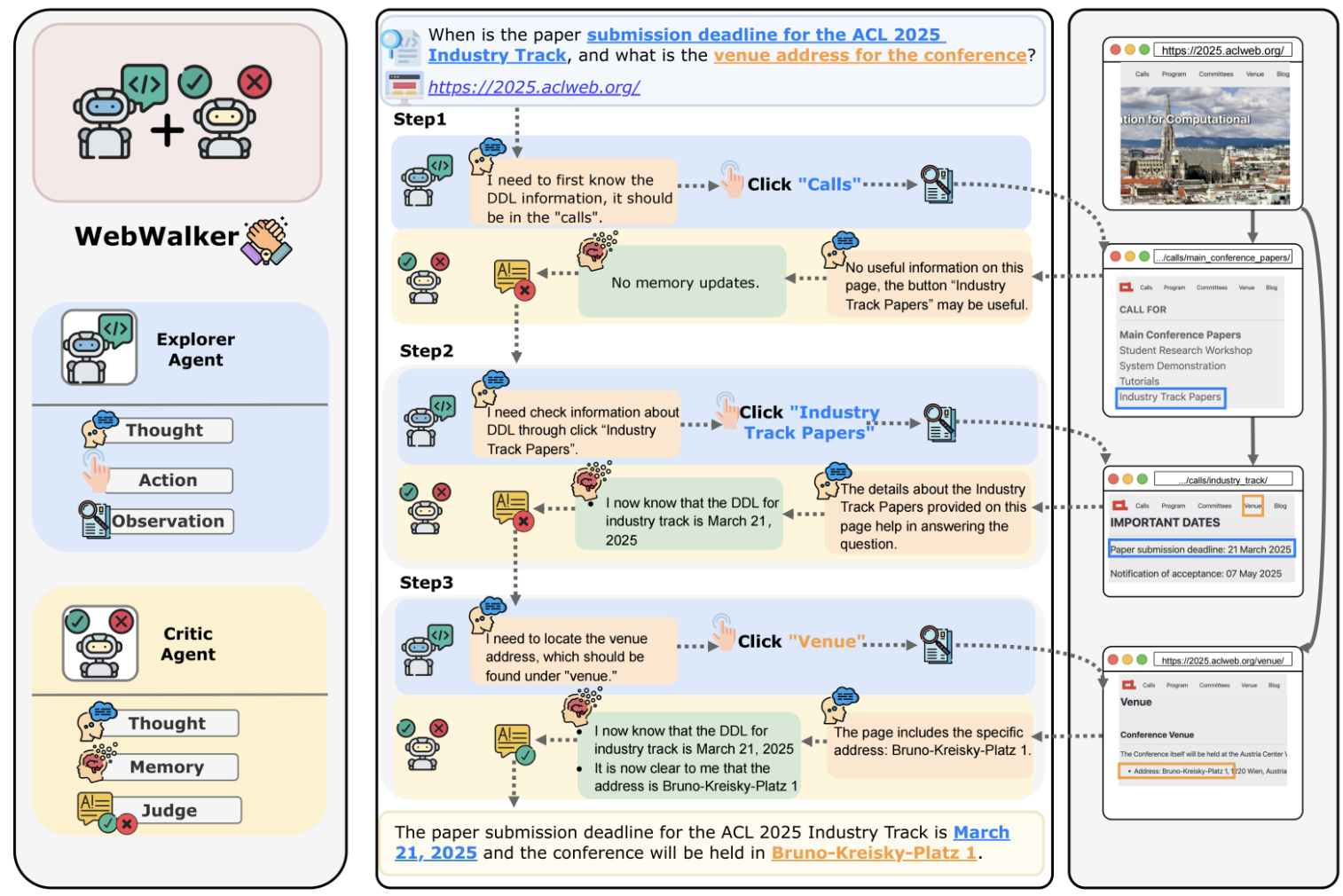
- 这种方法能比较适合Web-Navigation的问题(从一个网页出发,以链接跳转的形式能找到答案的情形,拓扑结构是相对线性的)

2. WebDancer
- 论文题目为《WebDancer: Towards Autonomous Information Seeking Agency》,arXiv ID为2505.22648
- 该论文中,Agent拥有的工具为search网页+visit网页链接
- 本文主要是面向WebAgent场景,提出了高质量训练数据的自动化合成方法(包括QA数据集和Agent的轨迹数据)
2.1 CRAWLQA数据构造
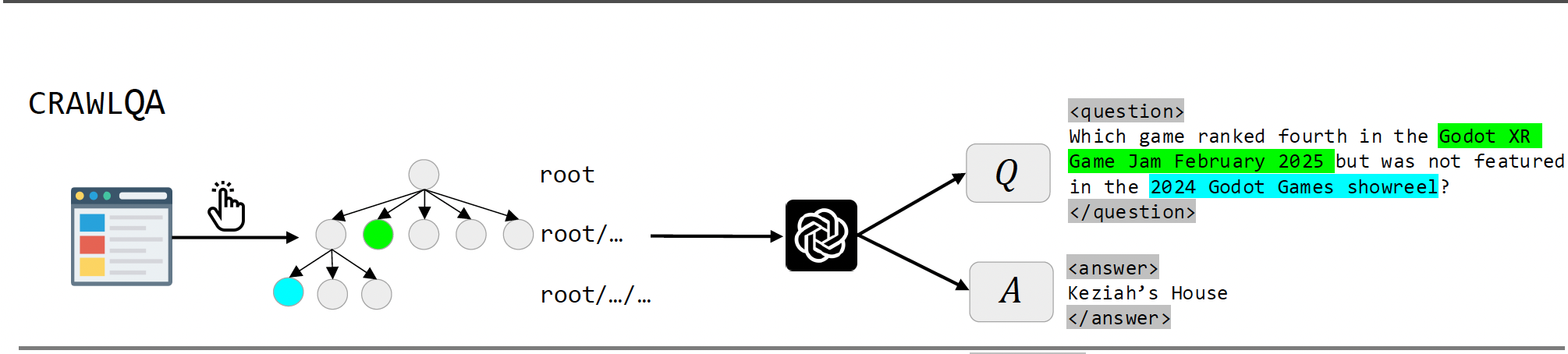
第一种方法是CRAWLQA,通过从种子URL出发,模拟像人一样浏览链接打开子页面,再使用GPT给予这些浏览过的网页生成问题和答案。
2.2 E2HQA数据构造
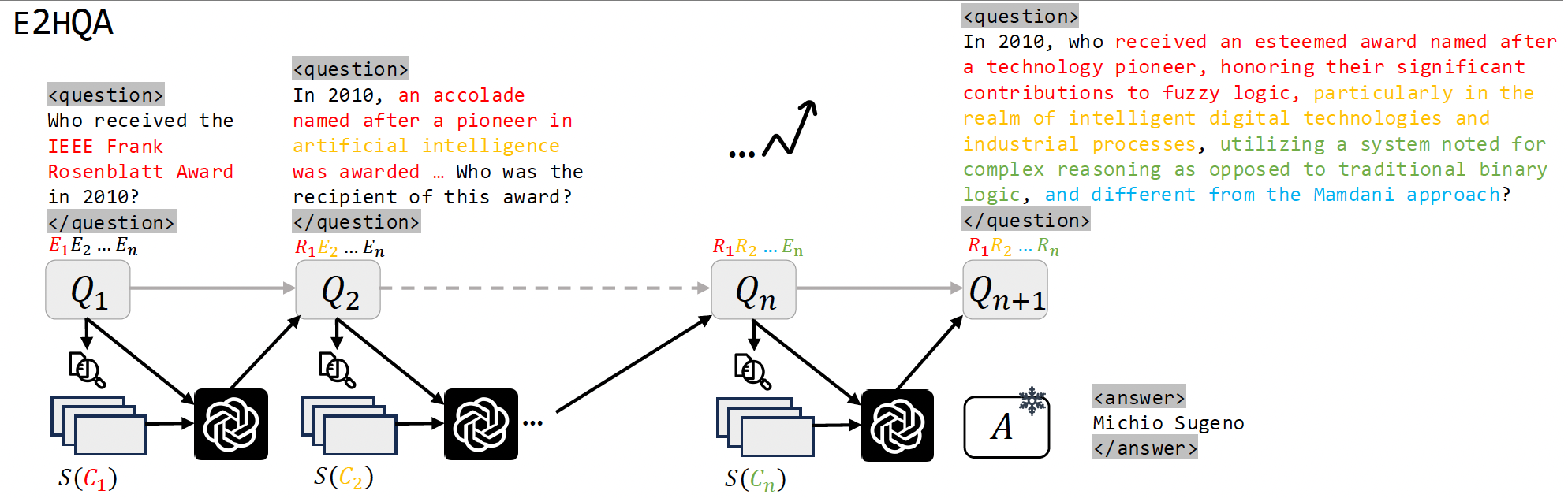
第二中方法为E2HQA,首先有Q-A对,作为种子。然后通过借助搜索工具,把问题Q复杂化。这个把问题 Q 1 Q_1 Q1复杂化的过程为,把Q里面涉及到的实体列出来,为 E 1 , E 2 , . . . , E n E_1,E_2,...,E_n E1,E2,...,En,借助搜索引擎搜索关于 E 1 E_1 E1的信息 S ( C 1 ) S(C_1) S(C1),把信息交给LLM,让LLM改变 E 1 E_1 E1的说法,把 E 1 E_1 E1描述为 R 1 R_1 R1,替换原始问题Q里面的 E 1 E_1 E1。以此类推,得到最后的 Q n Q_n Qn,无论多复杂的问题,最后答案还是 A 1 A_1 A1。甚至可以做一些拒绝采样,构造好的问题,如果LLM能直接回答出来,这样的问题移出训练集,这样构造出来的问题比CRAWLQA复杂很多,Agent要学会规划好如何解、如何搜索整理得到最终的答案。
以图中为例, Q 1 Q_1 Q1为谁获得了Frank Rosenblatt Award,把这个实体替换成为了"an accolade named after a pioneer in artificial intelligence was awarded"。第二轮迭代对着"artificial intelligence"这个实体展开。最终原始简单直白的问题变成了一个比较绕的复杂的问题。
2.3 正确的轨迹数据构造
有了QA数据之后,要训练Agent模型学会寻找答案,还需要一份正确的Agent的思考-工具调用-回答的轨迹数据,ReAct的格式需要Thought-Action-Observation这三部分。
- 调用大模型按照ReAct方式例如GPT-4o来回答问题,Action是【search+visit+answer】之一
- 只保留LLM-as-judge判断答案准确的路径作为轨迹训练集
- Thought数据构建:(1)短的CoT直接取GPT-4o的ReAct方式的Thought;(2)长的CoT使用推理模型QwQ-Plus来生成,并且是每个step单独来生成。在每个step,给QwQ-Plus看到之前的所有的Action和Observation,让它输出决定本次Action的思考,作为该step的Thought
收集到QA+轨迹数据后,可以使用SFT/RL训练Agent模型。WebDancer使用SFT+DAPO,DAPO里面提到会滤掉roll-out时completion全对/全错的样本。
3. WebSailor
- 论文题目为《WebSailor: Navigating Super-human Reasoning for Web Agent》,arXiv ID为2507.02592
- 这篇论文的目标是要提升模型面对不确定性复杂问题、大量信息的搜索浏览能力。之前的QA合成方法造的QA对太简单,模型不足以学习到更强大的能力,该文中提出了更复杂问题的QA对和轨迹合成方法。
在WebWalker和WebDancer中合成的数据,属于level1-level2,这些任务是从一个seed出发,通过线性的方式生成的,模型只需要沿着线性的搜索链就能够找到答案,解决方法是明确的。WebSailor里面考虑了level3这样的更复杂的问题场景,这样的问题没有明确的能够预定义好的推理链条。
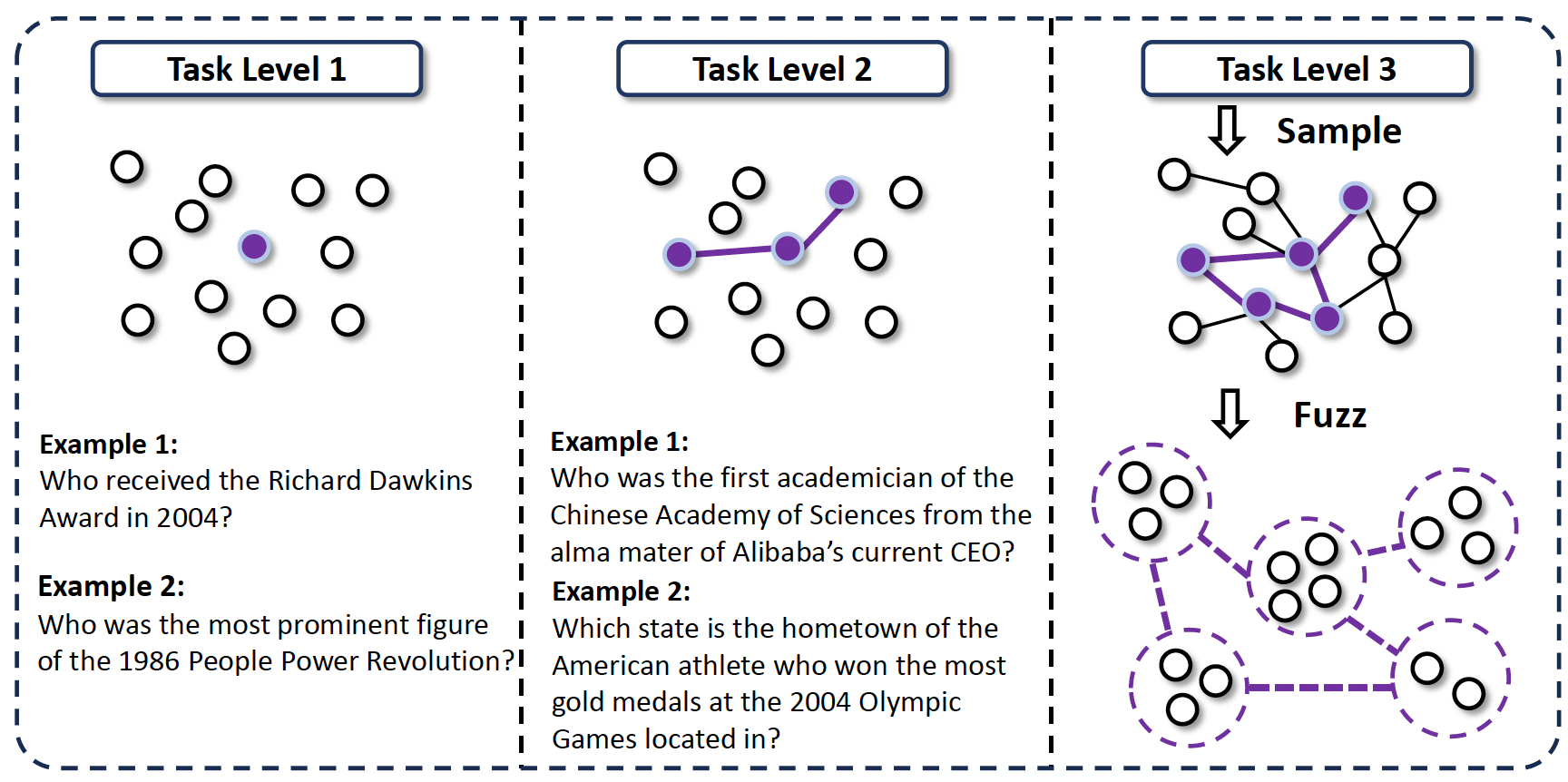
Level 3 数据集构造
先使用Wikidata's SPARQL构造一个图。接着,从图中一个实体节点出发,随机游走,搜索和这个实体相关的信息,获得到和这个实体有关联的新的实体,在图里面建立起节点和节点的连接。这样获得到的就是level2的multi-hop的线性结构,这个过程和WebDancer类似。
为了继续增大难度获得level3的数据,对这些实体做模糊性处理。例如修改为"在大约2010年"、"占比小于1%"等。这样信息会指向一个集合,而不是单一的一个节点,模型需要学会推理和比较才能找到答案。
4. WebShaper
- 论文题目为《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》,arXiv ID为2507.15061
- 之前的几篇数据合成方法,存在2个问题:(1)信息冗余-例如下图a中,迭代3次把问题复杂化了之后,可能复杂化的这3个实体,和原始问题答案的实体是直接相连的,模型只需要找到其中1个的答案,就能够回答原始问题,这3个复杂化是冗余的;(2)存在捷径-例如下图b中,假如也是把实体复杂化了很多次,但是里面存在一个和原始问题答案直接相连的实体,如果模型搜到了这个实体的信息,可以直接找到答案,不需要从预设的最远的那个实体开始搜索
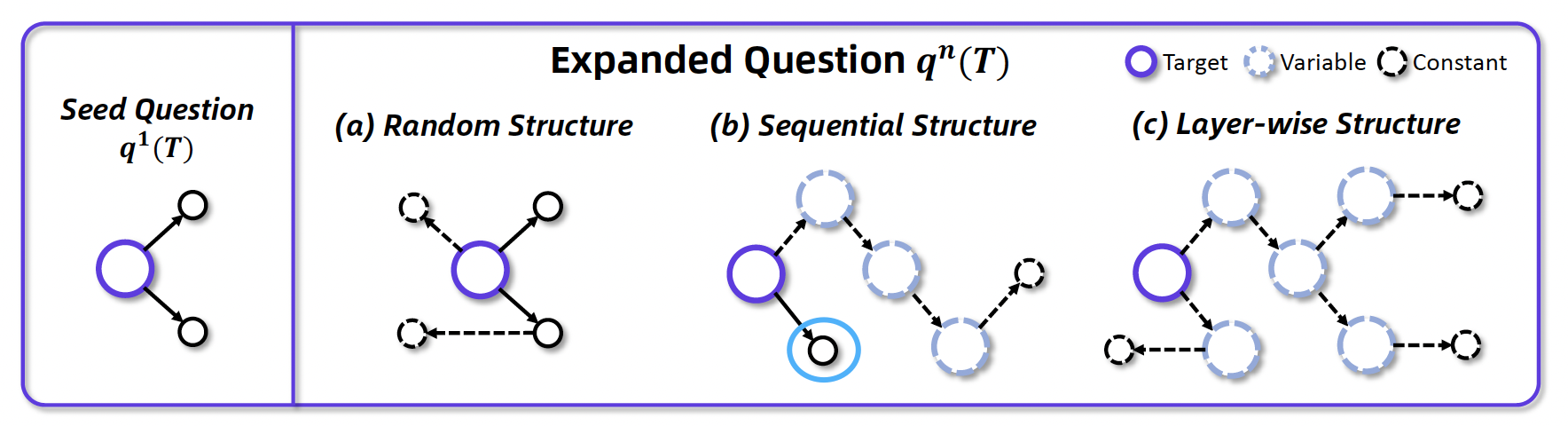
为此,webshaper做了形式化的分析,认为合成数据集应该遵循layer-wise的方法。也就是先遍历图节点,找到"叶节点常量"(如具体年份、球队名),对于每个叶子节点,调用工具:- Search:用 Google/Jina 搜索关于叶子节点的相关信息;
- Summarize:聚合多网页内容,替换对叶子节点实体的描述,变成一个子问题
- Validate:验证新子问题是否答案就是叶子节点;是否这个子问题太简单离线LLM能直接回答(过滤简单问题)
5. WebWatcher
- 论文题目为《WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent》,arXiv ID为2508.05748
- 之前的Agent都是纯文本的理解,WebWatcher有原生的处理图片的能力。数据合成的主体方法和前面系列相同,区别在于对图片数据的处理,提出了WebAgent领域VQA数据构造方法。

- 模型拥有的工具除了文本search+visit,还拥有OCR、图片搜索和python代码工具。在合成VQA数据时,先用前面系列的文本方法合成出原始的QA,然后做一个QA-to-VQA的转换。
QA-to-VQA
- 图片搜索: 从谷歌图片搜索中搜每个实体,去掉图片上模棱两可的实体,使用搜到的真实的图片作为上下文
- 实体模糊和问题改写: 使用GPT-4o改写原始的文本QA,原始的q里面是直接描述了实体B的信息,现在把它替换为图片 < i m a g e > <image> <image>,同时文本里面的描述模糊为"这张图片"
- 去掉改写失败的样本(例如改写后,文本描述里面还是直接泄漏了图片内容的信息),以及改写前后内容不对齐的样本;对于实体B的图片产生一个caption,过滤掉caption和图片不匹配的样本;
6. WebResearcher
- 论文题目为《WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents》,arXiv ID为2509.13309
- 当下deep-research的智能体面临2个问题:(1)上下文超长:模型的上下文窗口是固定长度,ReAct中每一步结果都进入上下文,step增加,留给当前主动推理的空间会越来越少;(2)噪声污染不可逆:当前方法,上下文只增不减,一旦中间出现了错误噪声,错误会随着step增加而累积放大
- 文中提出IterResearch范式来解决这两种问题,同时还给出了新的数据合成方法WebFrontier
IterResearch
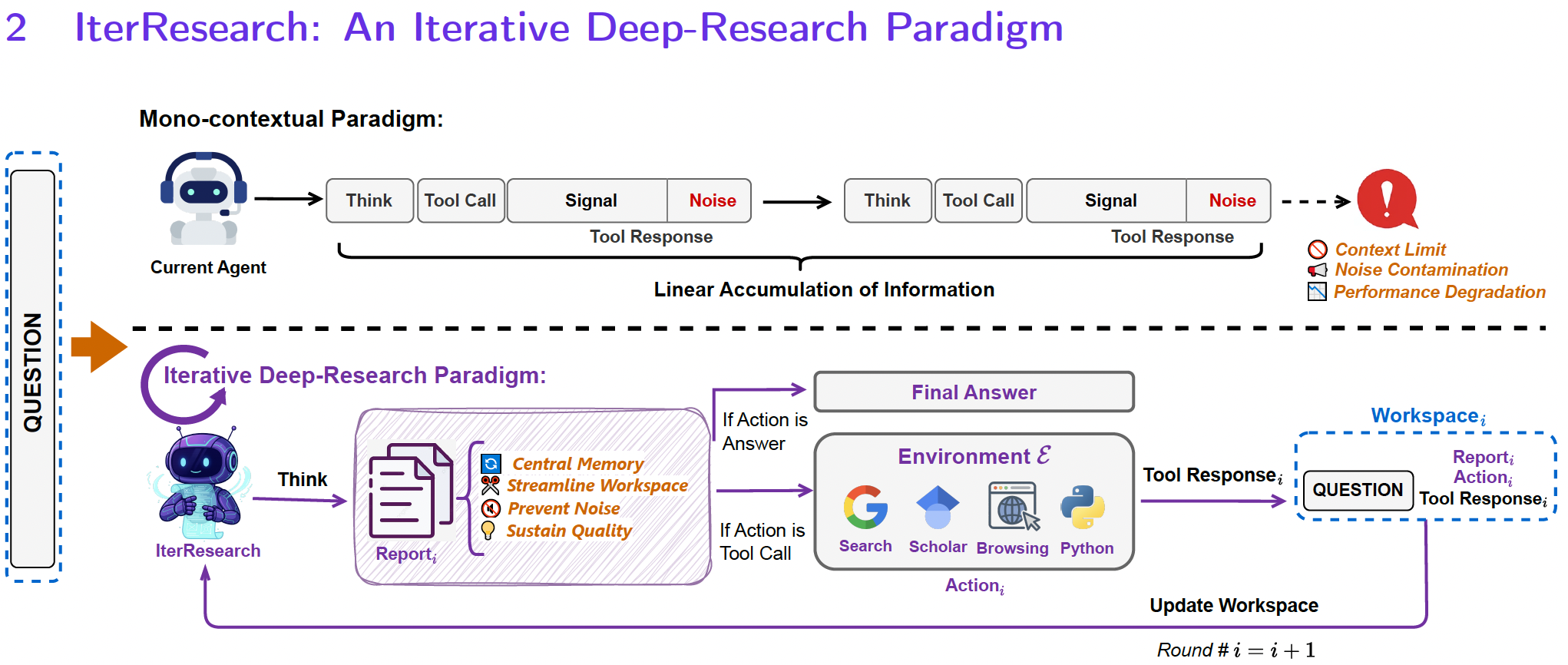
- 相比于ReAct把所有的thought-observation存入上下文,IterResearch使用report的方式管理上下文,每次think阶段,把历史report、当前思考和准备执行的plan和最近一次的action-observation作为上下文,整理成一个summary report中,然后再去执行action,避免超长上下文,缓解错误累积传播的问题
WebFrontier数据构造方法
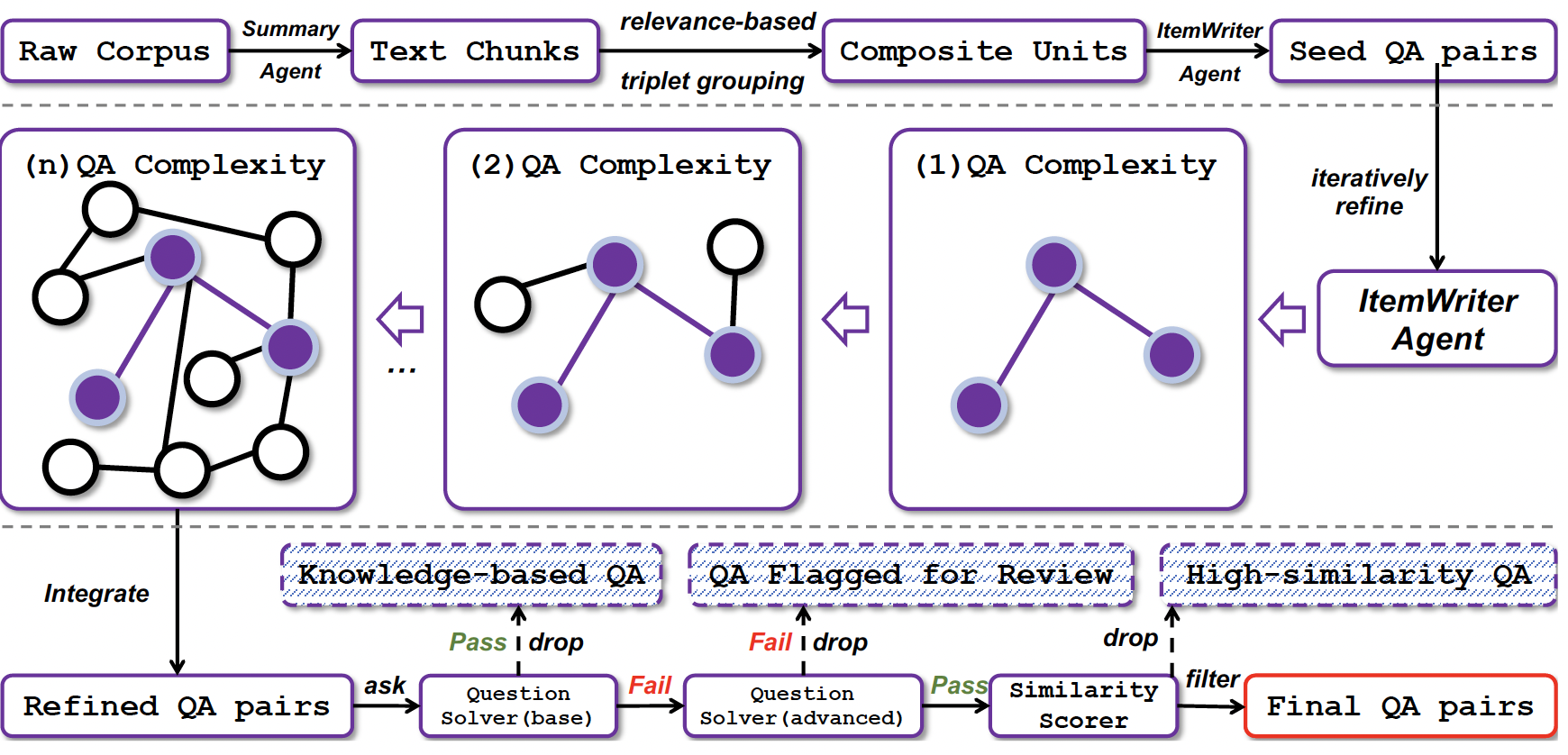
- 和前面系列的方法类似,区别在于对实体进行模糊化操作时,拥有更多工具选项:(1)网页搜索;(2)学术搜索(3)网页浏览(4)python解释器。可以进行搜索、浏览和代码执行做一些数据分析的模糊操作,把原始的问题Q变得复杂化。
- 在获得QA对后,进行了严格的过滤:(1)如果问题直接被离线大模型回答出来了, 这是简单问题,可以放到领域预训练里面;(2)如果一个问题LLM+tool也回答不出来,人工review;(3)一个问题LLM+tool答上来,且和训练集里面已有问题相似度足够低的,才纳入训练集
Test Time Scaling
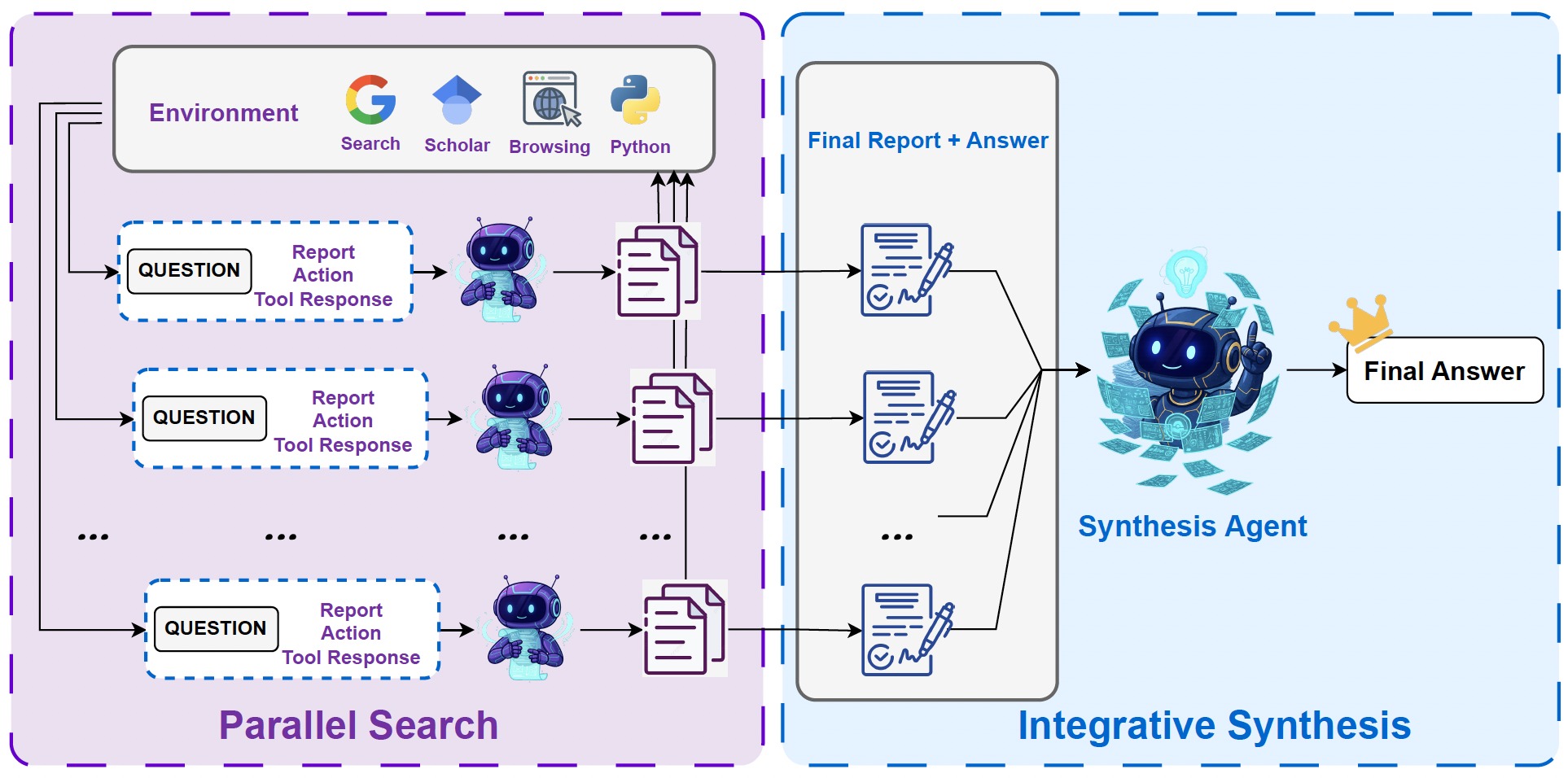
- 因为上下文短都是summary的形式,对于复杂问题,可以并行调度多个Agent同时去解决,再汇总得到最终答案
7. ReSum
- 论文题目为《ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization》,arXiv ID为2509.13313
- 为了解决超长上下文的问题,每完成几个step,对上下文进行summary,从历史信息中提取verifiable evidence
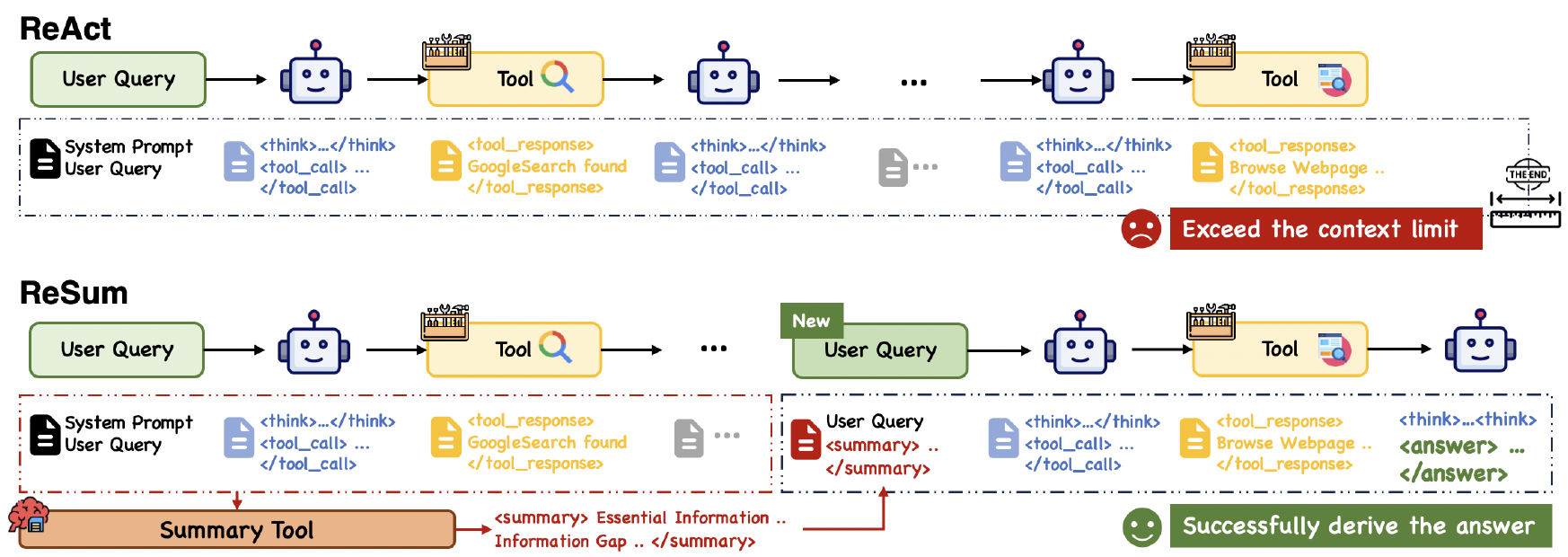
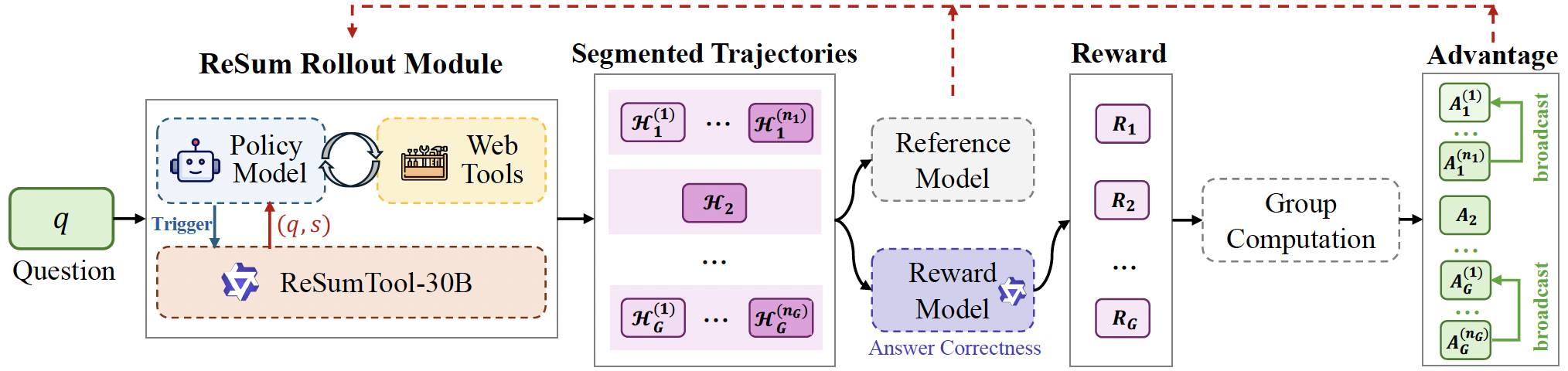
训练一个ReSum模型来完成总结任务,对于何时进行summary,可以是固定token预算/固定step间隔,或者是训练一个policy model来决定何时触发上下文的summary
8. WebWeaver
- 论文题目为《WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research》,arXiv ID为2509.13312
- 这篇论文聚焦写报告,提出了更灵活的Agent编排方式WebWeaver。
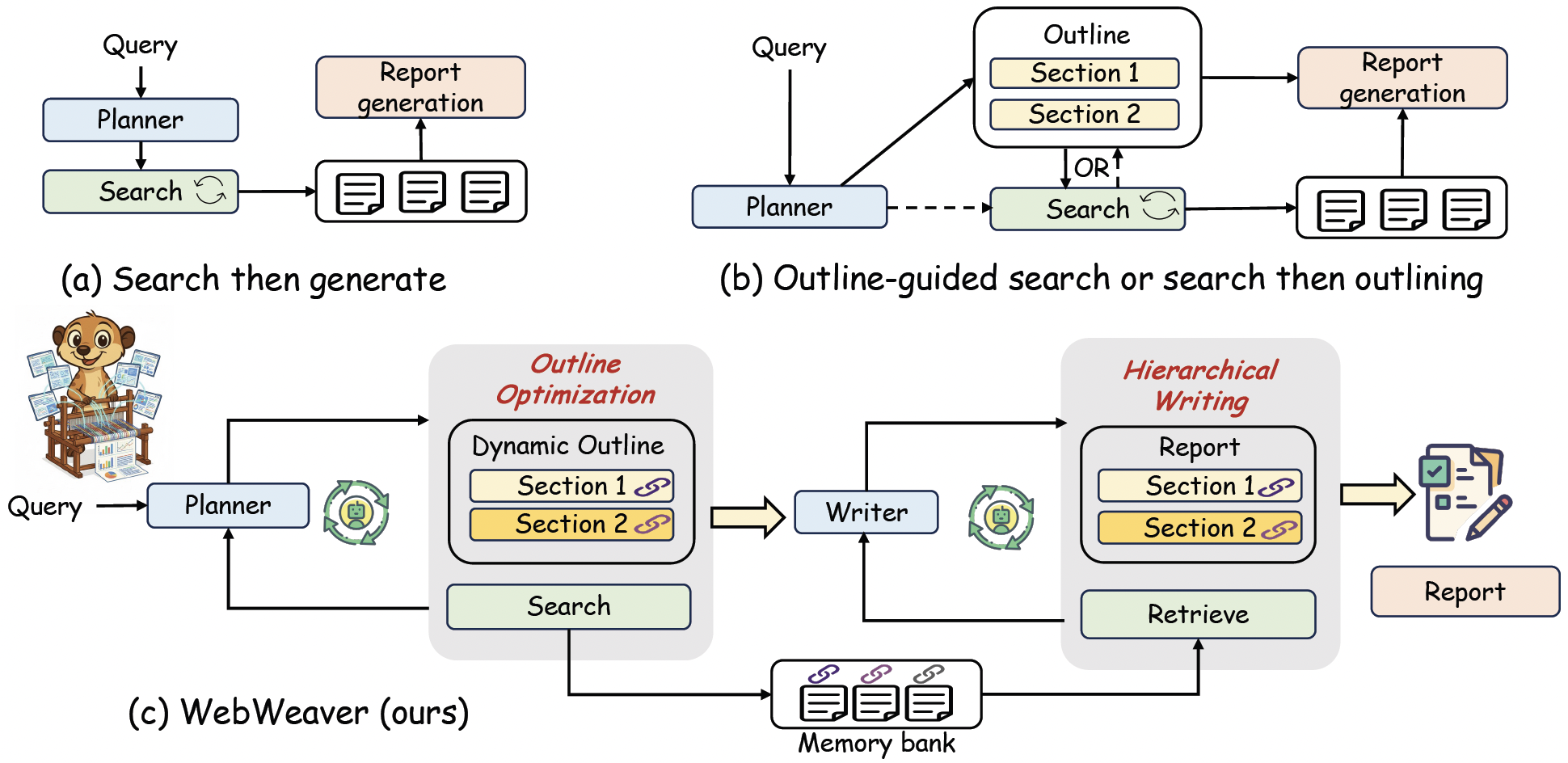
- 之前的方式:(a)原始的search then generate先规划->搜索然后总结输出report;(b)outline-guided的先规划好outline,然后搜索获取信息产生draft,最后根据outline的结构润色章节产生最后的报告
- 之前的方式一开始就规划好了,如果没有搜集到某些信息,这个章节的内容会有问题;即使在搜索的过程中获得了更有用的信息,因为一开始离线确定好的大纲,这些更有用的信息也不太好以更有逻辑的方式体现在最终的报告里面
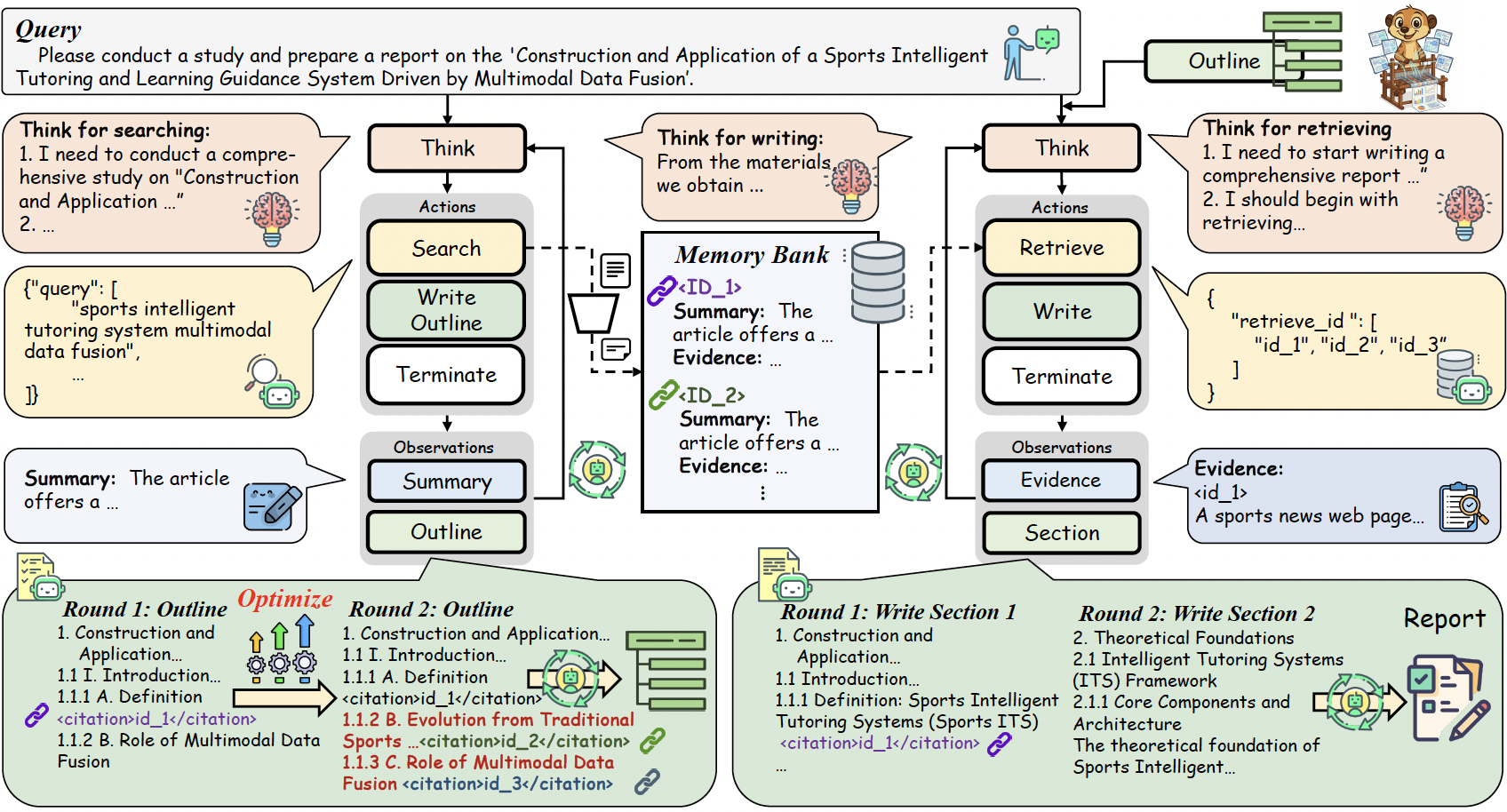
动态的outline
WebWeaver是边搜索边迭代优化outline,并且在outline中把参考资料的链接也附带上,这样获得的outline相比于LLM离线只使用自身知识会更合理。在行动和生成阶段,writer一章一章地生成,每次取outline里这个章节附带的参考链接信息。
9. WebSailor-V2
- 论文题目为《WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning》,arXiv ID为2509.13305
- 相比于之前的改变在于数据构造方法上,引入了更复杂的拓扑结构的考虑
SailorFog-QA-V2
之前WebShaper里面通过形式化的方法去除图里面的冗余(BFS的形式),websailor1里面构造的图大部分都是线性的或者树型结构的,WebSailor-V2里面认为,这些结构忽略了真实世界里面复杂逻辑关系的那一部分。所以在WebSailor-V2里面,专门构造出一些带环的数据,让节点之间的链接更dense。
在迭代替换实体把问题变复杂的过程中,引入了图论里的分析方法,找不同构的子图,替换的时候从orbit node里面采样,提升采样效率,让迭代时选取到的实体组成的路径尽可能多样,让模型学到各种reasoning的方式。
仿真环境
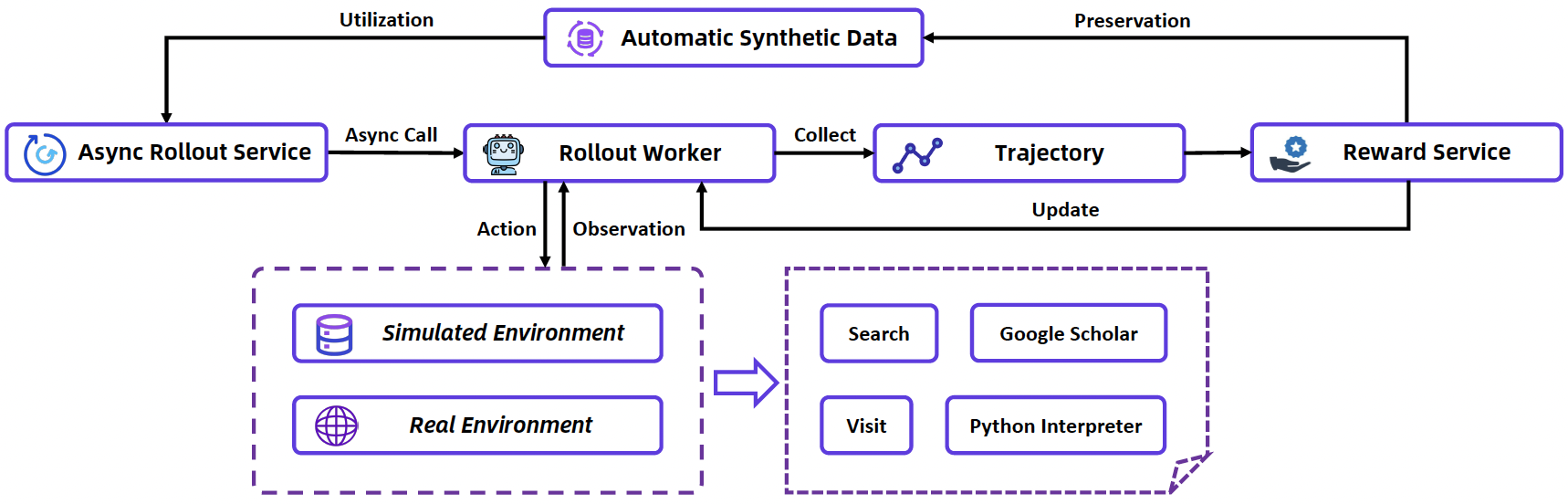
WebSailor-V2里面还根据训练集,构造了一个离线的仿真环境用于RL训练。不同的训练算法...PO等对结果影响不大,数据和交互环境对结果更有决定性。
10. AgentFounder
- 论文题目为《Scaling Agents via Continual Pre-training》,arXiv ID为2509.13310
- 认为当前主流做法,在通用基础模型上直接进行后训练,在智能体任务上表现不佳,是因为缺乏专为智能体行为设计的基础模型,文中提出了预训练Agent模型的方法。
First-order Action Synthesis with Zero Supervisory Signal
在构造预训练数据上,和之前的WebAgent系列方法不一样,AgentFounder使用更容易scaling的方式。搜索数据本身是带有轨迹的和Agent的动作一样,但是其他文档里面收集来的数据都是静态的,要用于训练Agent需要做一个转换。
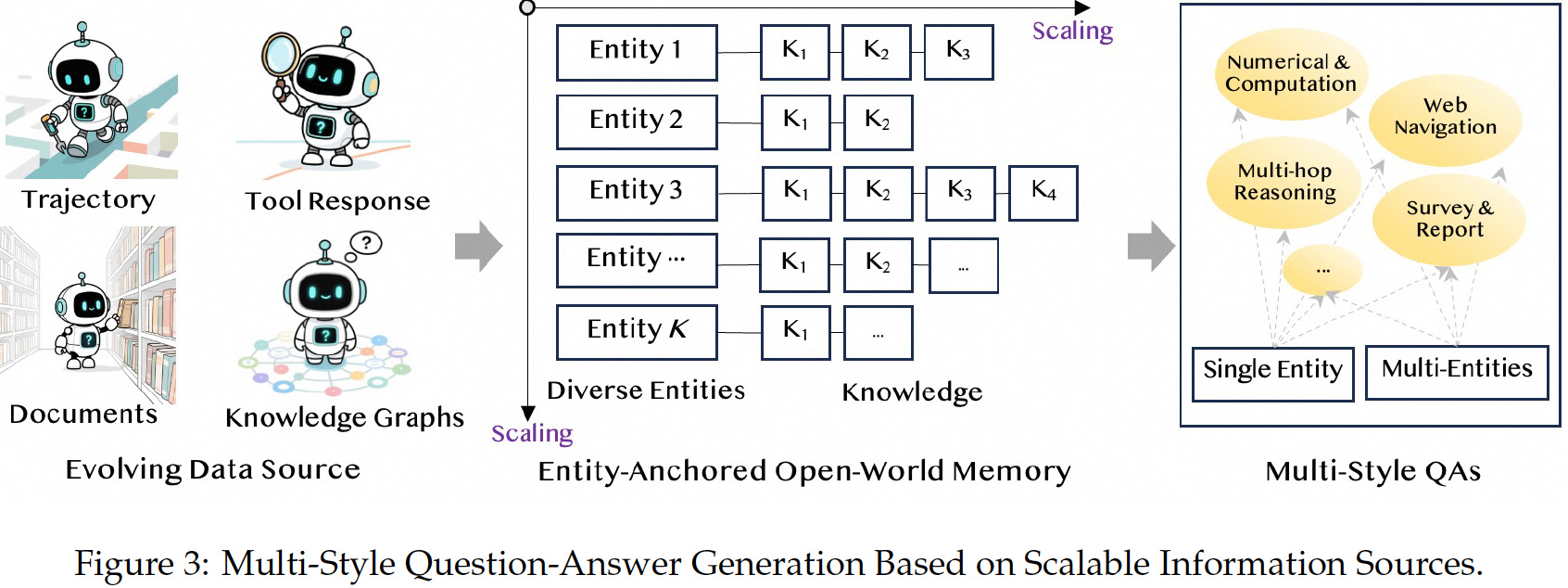
- Phase 1:把数据变成key-value格式,value是一个链表形式,key是entity,不用关心entity之间的节点联系。entity是例如"法国"这样的实体,后面的knowledge是从知识库里面取到的对于这个实体的知识性片段,例如K1是"巴黎是法国首都",K2是"2025年6月抵达法国旅游人数超过了400万人"
- Phase 2:从每条知识链里面随机的抽取知识来合成问题。

- Phase 3:Plan数据构造。AgentFounder提出,Agent的第一步进行任务分析和规划的推理,对于本次任务能否成功完成至关重要。后续真实的调用工具获取response的数据相对没有那么重要,并且调用工具成本高。所以,AgentFounder侧重于合成第一步的plan数据。对于原始问题以及关联的知识,构造K个不同表述的问题,然后调用LLM生成K个plan,并且用LLM-as-judge的方式,给定judge问题和知识和plan,判断使用这个plan能否回答问题,过滤掉低质量的plan。
- Phase 4:Chain-of-Thought数据构造:(1)先让模型把原始问题Q分解为多个子问题,然后用模型内部知识猜测和回答子问题,生成最后答案A1;(2)给模型提供问题Q关联的知识链以及第一次的答案A1,让模型修改A1里面的逻辑错误得到答案A2;(3)使用llm-as-judge的方式过滤掉A2错误的这部分数据
High-order Action Synthesis
以上的数据还没有用Action部分训练模型。使用之前的方法合成出一条条带有action的轨迹数据后,训练时直接模仿路径,容易导致过拟合特定策略、无法学习"为何不选其他选项"、样本效率低(一条轨迹只提供一个正/负样本)。但是如果使用细粒度step-level的,reward不好定义训练也不稳定。AgentFounder提出了一个折中的数据合成方式HAS。对于问题 Q Q Q和轨迹 T = { ( S 1 , R 1 ) , . . . , ( S k , R k ) } T=\{(S_1, R_1), ...,(S_k, R_k)\} T={(S1,R1),...,(Sk,Rk)}, S k S_k Sk表示第 k k k步的思考和工具调用, R k R_k Rk表示对应的observation,完整的轨迹 T T T还有一个结果标签 J ∈ { 0 , 1 } J \in \{0,1\} J∈{0,1}表示这个轨迹最后是成功还是失败了。之前的训练方法对一条轨迹的利用率低,只作为一个样本。AgentFounder提出:
(1)step-level scaling: 在第 k k k步,上下文为 C k = { Q , S 1 , R 1 , . . . , S k − 1 , R k − 1 } C_k=\{Q,S_1, R_1,...,S_{k-1},R_{k-1}\} Ck={Q,S1,R1,...,Sk−1,Rk−1}。在不真实调用工具的情况下,让LLM在给定上下文 C k C_k Ck的情况下,在随机生成 N N N个思考和工具调用 A k = S k ( 1 ) , . . . , S k ( N ) A_k={S^{(1)}_k,...,S^{(N)}_k} Ak=Sk(1),...,Sk(N),然后把这条轨迹真实的原始的 S k S_k Sk并入得到 A k ~ \tilde{A_k} Ak~,这样子在第 k k k步,就有 N + 1 N+1 N+1种可能的think-action。记住真实的原始的 S k S_k Sk的下标 n k n_k nk,对 A k ~ \tilde{A_k} Ak~里面的顺序随机置换,原始的一条轨迹样本,变成了含有(N + 1) × K个think-action。
(2)Contrastive Decision-Action Synthesis: 现在从回答原始问题 Q Q Q开始,在每一步,模仿做选择题,think里面插入 A k ~ \tilde{A_k} Ak~,以及""I will choose option n k n_k nk",后面拼接真实的observaiton R k R_k Rk。最后的最后,把结果标签拼入,"My decision
is {Correct/Incorrect}",得到一条完整的训练样本。

11. AgentScaler
- 论文题目为《Towards General Agentic Intelligence via Environment Scaling》,arXiv ID为2509.13311
- 这篇论文主要介绍了如何构建一个仿真的环境用于agent训练,把api的网络调用等模拟成对本地数据库的读写操作。
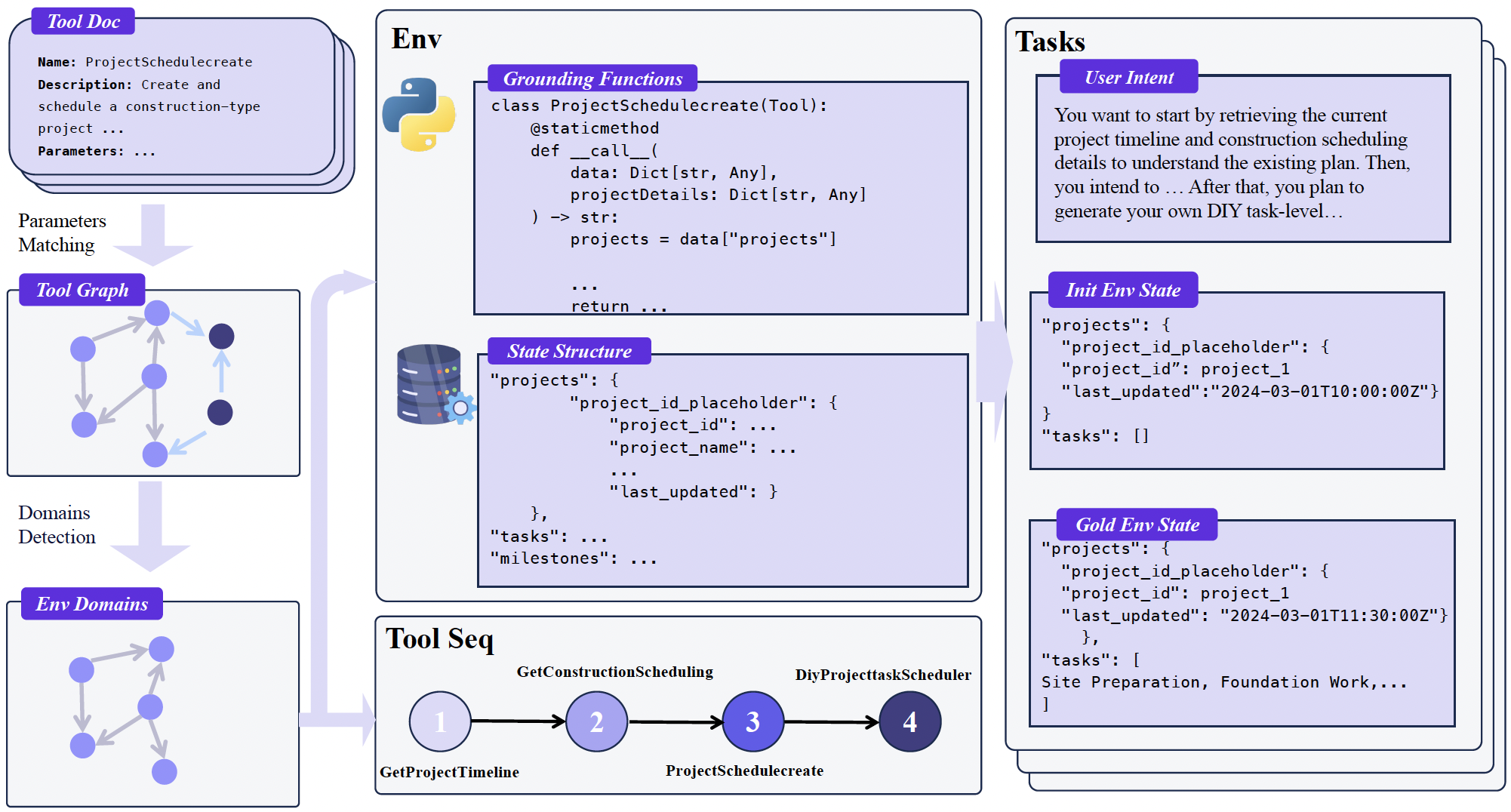
环境构建
- 场景收集:从 ToolBench、API-Gen 和内部仓库中汇集了超过 30,000 个真实 API,并对它们进行了严格筛选和优化,剔除低质量接口,重写模糊描述,明确标注输入输出格式。
- 工具依赖图建模(工具聚类):将每个工具视为图中的节点,并通过将参数列表编码为向量、计算余弦相似度的方式,自动建立工具之间的依赖边------当相似度超过阈值时,即认为两个工具可组合。基于此图,采用 Louvain 社区检测算法将其划分为超过 1,000 个功能连贯的"工具社区",每个社区对应一个domain(如天气、金融、电商等)。后续会基于每个domain的工具社区,构造连贯的工具调用。
- 工具和domain数据库:最后,针对每个domain,系统根据其工具的参数自动生成对应的domain的数据库 Schema,并将每个工具实现为能对该数据库执行读/写操作的 Python 函数,不需要访问外部网络。这样一来,原本黑盒式的外部 API 被转化为在可控、可观测、可重置的内部状态环境中运行的具体程序,对数据库进行读或者写。
Agent任务构建
本文会基于Agent-human的interplay来合成轨迹数据,充分模拟用户、agent和环境。为此,基于前文构建的领域专属数据库 Schema(如航班表、用户表、订单表等);
- 随机填充初始数据(如插入若干航班记录、用户信息),但确保逻辑合理(如日期格式正确、外键一致),鼓励多样性
- 使用这个domain的工具依赖图,随机游走产生工具调用序列。每一步产生工具调用的参数,真实地调用工具读写数据库,记录结果和数据库的状态(这些就是ground truth),这个序列能完成某个意图任务
Agent Experience Learning
根据前面的序列,生成一个模拟的user query,进行真实的interplay,得到trajectory。
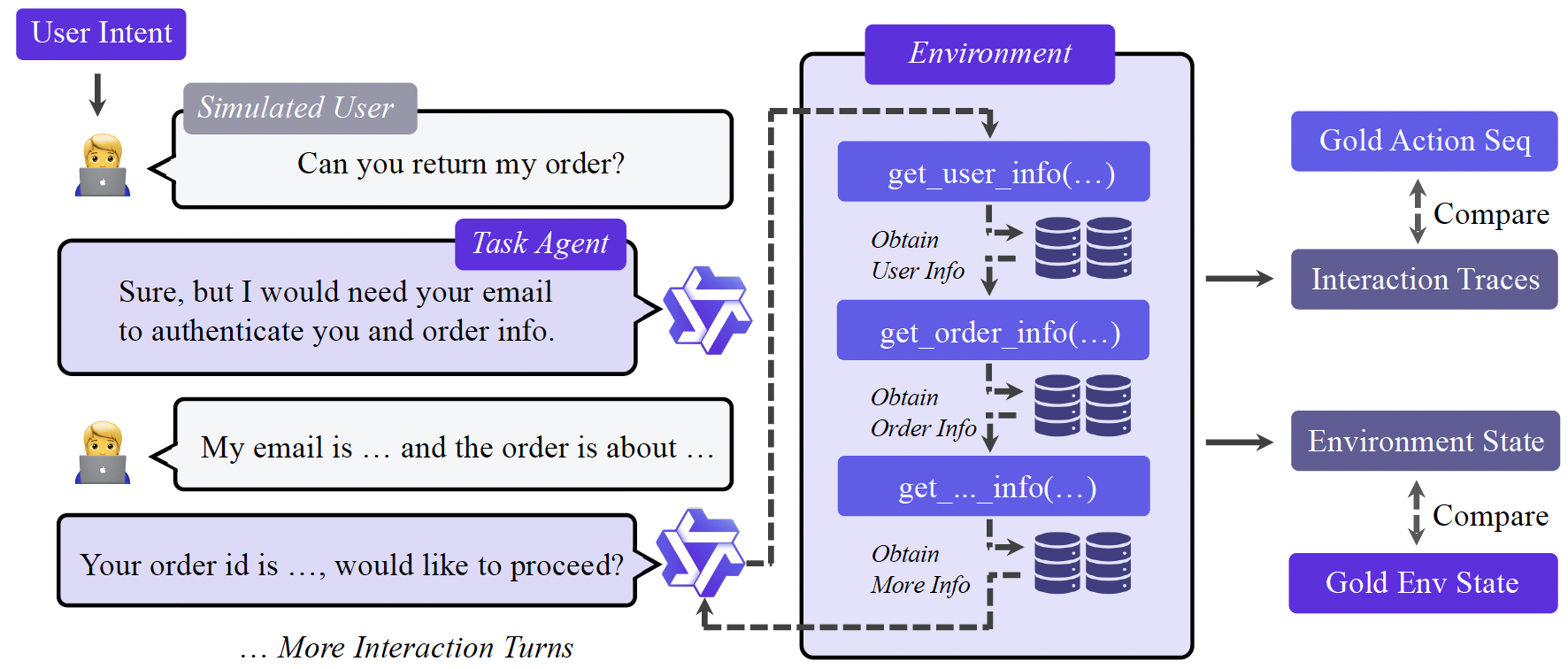
对产生的轨迹数据集进行筛选过滤:
- 有效性:过滤掉含有严重重复工具调用序列的轨迹
- 环境校验-数据库级别:拿之前的ground truth和现在的数据库环境进行对比,只保留和ground truth一致的轨迹(这能保证工具序列正确的进行了写操作)
- 调用校验-工具级别:如果一个任务只包含读操作),数据库状态不会改变,数据库级别环境校验无法判断轨迹准确性。因此做工具级别校验,只有当所调用的工具序列及其参数与整体意图完全匹配时,该轨迹才会被保留
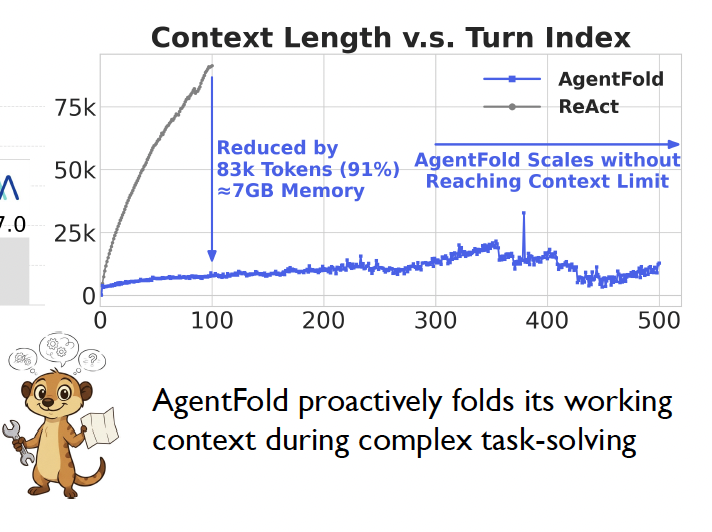
12. AgentFold
- 论文题目为《AgentFold: Long-Horizon Web Agents with Proactive Context Management》,arXiv ID为2510.24699
- 这篇论文提出了一种上下文管理的方法AgentFold,能让Agent运行更多step执行复杂任务。ReAct的上下文增长是线性的,AgentFold通过压缩来减少上下文长度。
- AgentFold做了两阶段的压缩,以当前在第9步为例,Agent在step9,能看到前面的上下文Fold,进行think-action后,得到response
- 在上下文中,对step9的信息进行压缩,结果为A,上下文有1-3、4-7、8、9这4个块
- 进一步压缩,发现step4-9可以压缩合并在一起,因此上下文压缩成为1-3、4-9这2个块
- step10时,Agent看到的是Folding后的这2个块,以及step9的call-response信息
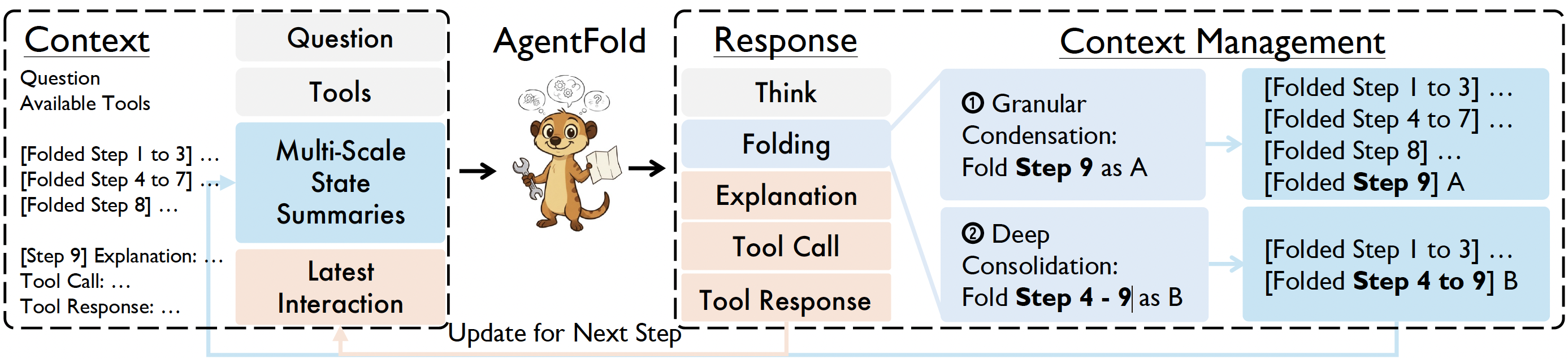
为了让模型学会folding,使用LLM结合拒绝采样构建folding数据集,使用SFT训练了一个模型用于压缩上下文。
13. WebLeaper
- 论文题目为《WebLeaper: Empowering Efficient, Info-Rich Seeking for Web Agents》,arXiv ID为2510.24697
- WebLeaper指出已有的信息获取智能体,因为训练集里面目标实体的稀疏(从一系列已知实体出发,搜集信息推测目标实体),导致学到的agent模型搜索效率低下。例如用GPT模型在一个数据获取数据集上测试,发现模型获取到的实体是回答问题真正需要的占比很低。
为了衡量搜索效率,文中提出了Information-Seeking Rate (ISR)和Information-Seeking Efficiency (ISE)这2个指标。
ISR衡量信息覆盖率,R是完成这个任务需要的目标实体集合,O是智能体完成任务过程中获取到的实体集合,ISR定义为:
I S R = ∣ R ∩ O ∣ ∣ R ∣ ISR=\frac{|R \cap O|}{|R|} ISR=∣R∣∣R∩O∣
ISE衡量信息获取效率,T是智能体完成任务的步数,ISE定义为:
I S E = ∣ R ∣ ∣ T ∣ ISE=\frac{|R|}{|T|} ISE=∣T∣∣R∣
QA构造pipeline
- WebLeaper中有3种不同难度的QA数据构造方式
Version 1: Basic
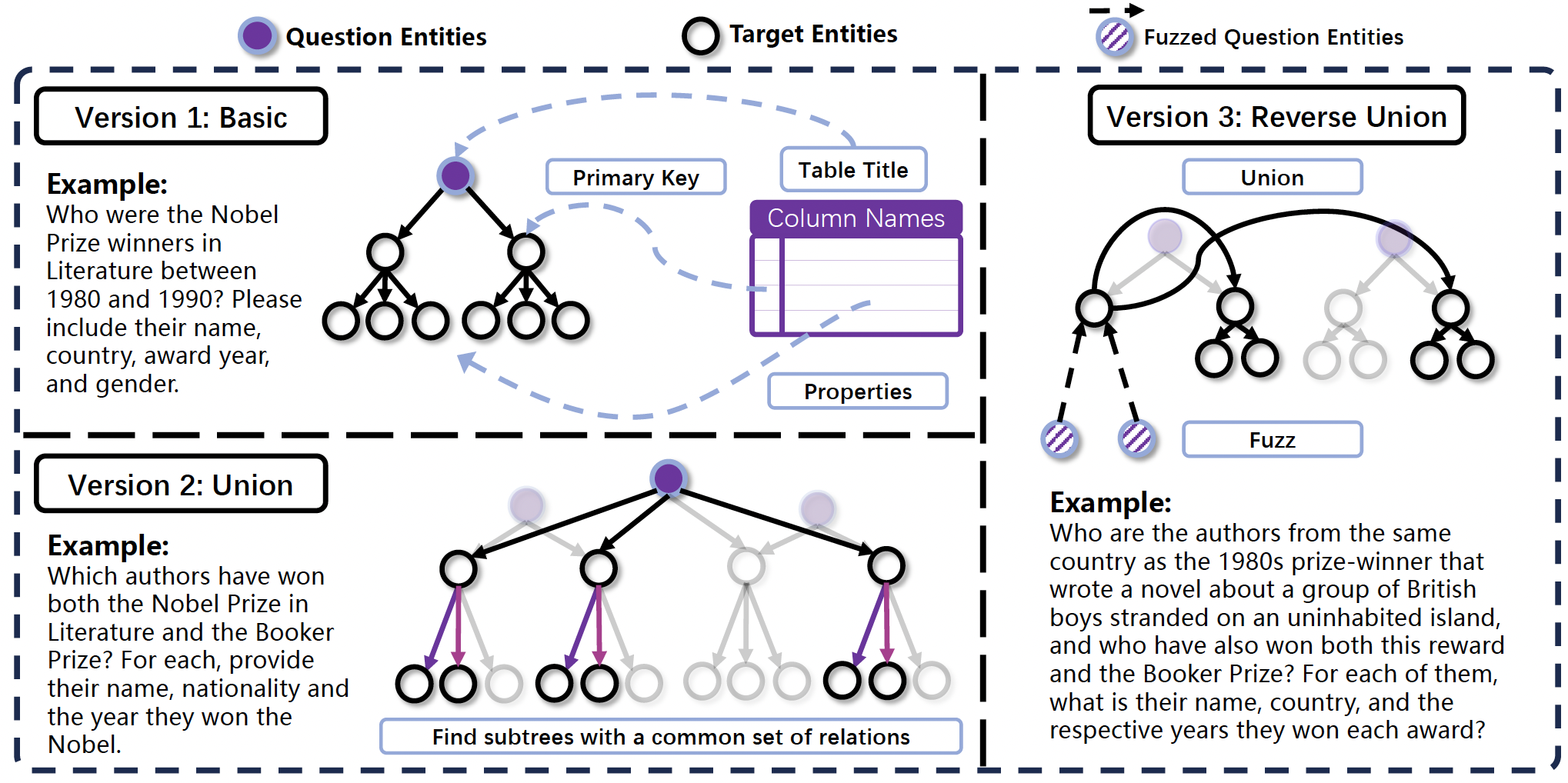
为了便于构造QA数据对,之前的方法从一个root url或者实体搜索跳转的效率比较低,这篇论文使用的方法是,从Wikipedia上爬取表格,表格的标题作为root节点(也就是问题Q),使用LLM从表格里面提取primary key实体作为第二层节点(例如人名列),root和节点的边表示这个表含有这些实体。第三层节点是用LLM从表格中提取出描述第二层实体的属性的信息,例如国籍、出生年月等,连接第二层和第三层节点的边表示第二层节点含有对应的第三层节点对应的属性。问题是根节点,它的所有子树组成答案。
Version 2: Union
为了获得更复杂的问题,一种思路是直接随机合并version 1里面有相同主题、结构的子树,这种方式得到的问题可能语义上不连贯。为了找到适合合并的关系,WebLeaper提出了一种算法来寻找maximal unions。这个算法会系统性地识别多个推理树中具有共同关系结构的子树,这些子树必须在语义结构上对齐(如都包含"作者 → 国籍"、"作者 → 姓名"等关系),非共有的关系(如某棵子树独有"性别"属性)在合并时被丢弃,以保证融合后的结构一致性。
一旦找到maximal unions,就用LLM根据所选择的子树的共同的feature来合成问题Q。例如合并了的子树拥有共享的关系(如 has_name, has_nationality),每个子树的结构为
bash
[奖项]
→ [获奖者(作者)]
→ has_name: "Alice Munro"
→ has_nationality: "Canadian"
...尽管奖项不同,但它们的第二层实体都是"作者",这些共享的关系(如 has_name, has_nationality)可以确认"这两棵树讲的是同类事物",从而可以把它们联合起来提问,例如LLM合成的问题Q为"哪些作者同时获得过诺贝尔文学奖和布克奖"。要回答这个问题,需要先将两个奖项的获奖者分别识别为中间的"目标实体",然后求这两个集合的交集,才能得到最终的"目标实体",回答问题的难度相比于version1上升了。
version 3: Reverse-Union
尽管Union方法能够生成复杂的多源任务,但仍存在一个漏洞:agent可能分别对各个组成部分直接进行关键词搜索。(例如,union后的问题"找出同时获得诺贝尔奖和布克奖的得主",agent可能先搜索"诺贝尔奖得主",再搜索"布克奖得主"),从而绕过所需的信息整合过程,无法有效激发真正的推理能力。为此,WebLeaper提出了Reverse-Union操作,Reverse-Union 并不等同于集合论中的"补集"操作,它的核心思想是 "反转推理流程" + "模糊化起点",目的是强制agent进行多步演绎推理,而非直接关键词搜索。首先进行Union操作,接着是2个操作:
- Deductive Fuzz:先把Union得到的问题实体模糊化,把第二层的实体(anchor),用一系列的第三层的属性来进行描述,这样模型解决问题时必须先从线索里面推理出这个第二层实体。
- Union-based Search Construction:让anchor只是链接到最后答案的桥梁而不是答案本身。先从anchor实体的子树中选取一个特定的第三层实体(例如,国籍"英国")作为枢纽(pivot)。随后,设计问题的后半部分,迫使agent必须利用这一枢纽属性,发起新一轮搜索。最终的"目标实体"被定义为所有满足以下两个条件的第二层实体:(1)与锚点共享该枢纽属性(即同样是英国人);(2)满足原始的交集条件(即同时获得诺贝尔奖和布克奖)
描述可能有些抽象,举一个详细的列子:
bash
假设我们已经使用 Union 方法联合了2个子树:
* 诺贝尔文学奖得主
* 布克奖得主
Union后的Q是找出:同时获得这两个奖的作者。
** 第一步:Deductive Fuzz------隐藏锚点 **
给出的线索是:
"the 1980s prize-winner that wrote a novel about a group of British boys stranded on an uninhabited island"
这是一个模糊描述,没有直接说出名字。
智能体需要推理出:作者是 William Golding;
锚点实体(anchor) = William Golding(第二层实体:作者),这个锚点是通过第三层实体(小说情节、获奖年代等)间接描述的。
** 第二步:Union-based Search Construction **
现在,William Golding 只是一个"跳板",不是最终答案!
系统从他的属性中选一个枢纽(pivot),比如:
国籍:British(英国人)
然后,问题被继续构造为:
"在所有同时获得诺贝尔文学奖和布克奖的作者中,有哪些人和这位写《蝇王》的1980年代获奖者一样,也是英国人?"
最终目标实体(Target Entities) 是:
所有满足以下两个条件的作者(第二层实体):
国籍是英国(与锚点共享 pivot 属性);
同时获得过诺贝尔文学奖和布克奖(原始交集条件)。轨迹构造
有了QA数据后,使用和之前一样的方式构造轨迹数据,使用拒绝采样丢弃错误的轨迹,同时限制要求ISE和ISR高于阈值,只保留这些高效的轨迹数据用于训练。此外,为了训练时让模型学会高效搜索,reward function里面引入了和ISR相关的设计。 O O O是ground truth, R R R是轨迹中召回的,其中 s ( ) s() s()是衡量相似度的函数,召回率可以定义为 R c \mathcal{R}c Rc,精确度可以定义为 P \mathcal{P} P,和F1类似的定义的reward function为 R WebLeaper \mathcal{R}{\text{WebLeaper}} RWebLeaper。
R c = 1 ∣ R ∣ ∑ e r ∈ R max e o ∈ O s ( e o , e r ) P = 1 ∣ O ∣ ∑ e o ∈ O max e r ∈ R s ( e o , e r ) R WebLeaper = ( 1 + ω 2 ) P ⋅ R c ω 2 P + R c \begin{align*} &\mathcal{R}c = \frac{1}{|R|} \sum{e_r \in R} \max_{e_o \in O} s(e_o, e_r) \\ &\mathcal{P}= \frac{1}{|O|} \sum_{e_o \in O} \max_{e_r \in R} s(e_o, e_r) \\ &\mathcal{R}_{\text{WebLeaper}} = (1 + \omega^2) \frac{P \cdot \mathcal{R}_c}{\omega^2 P + \mathcal{R}_c} \end{align*} Rc=∣R∣1er∈R∑eo∈Omaxs(eo,er)P=∣O∣1eo∈O∑er∈Rmaxs(eo,er)RWebLeaper=(1+ω2)ω2P+RcP⋅Rc
14. BrowseConf
- 论文题目为《BrowseConf: Confidence-Guided Test-Time Scaling for Web Agents》,arXiv ID为2510.23458
- 这篇论文关注Test-Time Scaling,讨论什么情况下需要多并发重复调用多次来获得更可靠的结果,什么情况下结果已经很可靠了。
- 测试显示,及时是multi-turn的agent,最后输出的confidence和最后结果的准确率也有明显的相关关系,confidence越高,结果准确率越高 -> 相比于self-consistence,只需要在置信度低的情况下并发重复调用获取更置信的结果,节约token
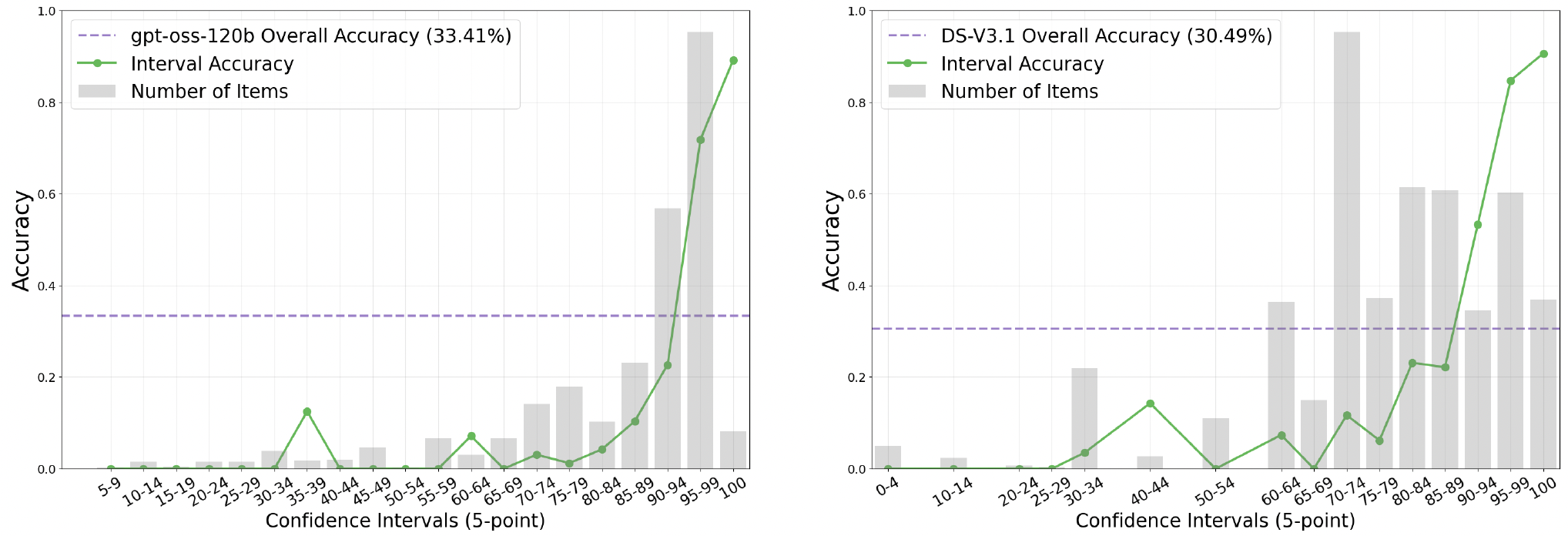
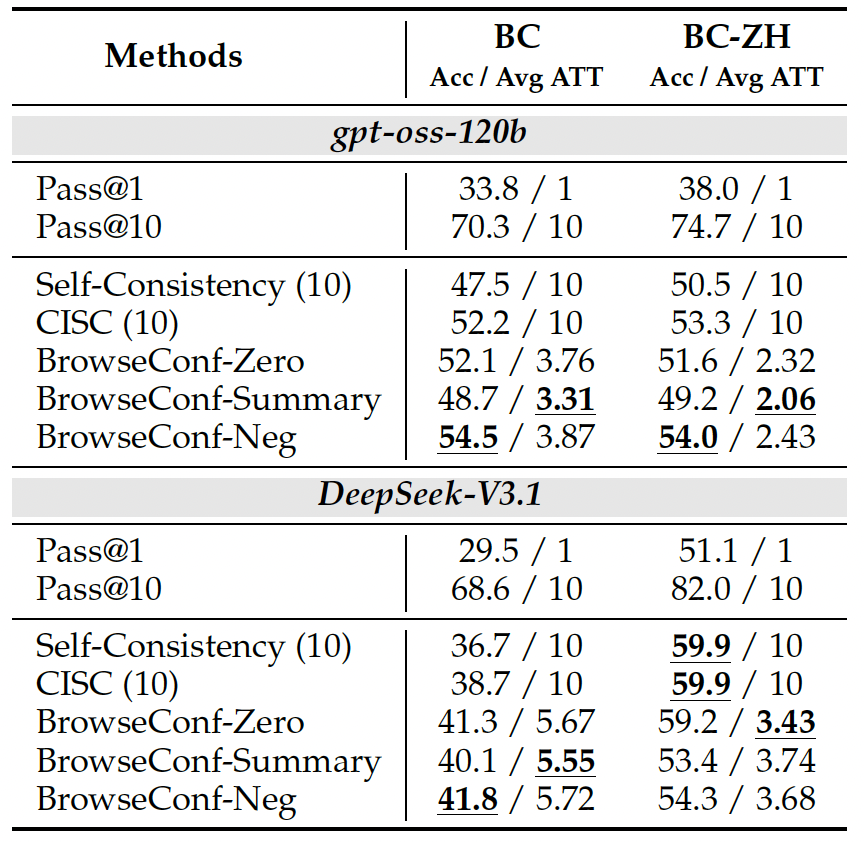
文中提出了3种TTS模式: - BrowseConf-Zero:置信度低,从头开始回答
- BrowseConf-Summary:在第t+1次重试时,把第t次尝试的总结作为输入信息
- BrowseConf-Neg:在第t+1次重试时,把第1-t次低置信度尝试的答案也作为输入信息
对比结果
15. E-GRPO
- 论文题目为《Repurposing Synthetic Data for Fine-grained Search Agent Supervision》,arXiv ID为2510.24694
- 已有的Agent数据合成方法大部份是一步步的entity-based的,但是训练方法GRPO只关注轨迹的最终结果,奖励是稀疏的,没有充分利用实体的信息。这篇论文提出了一种entity-aware的 reward function。
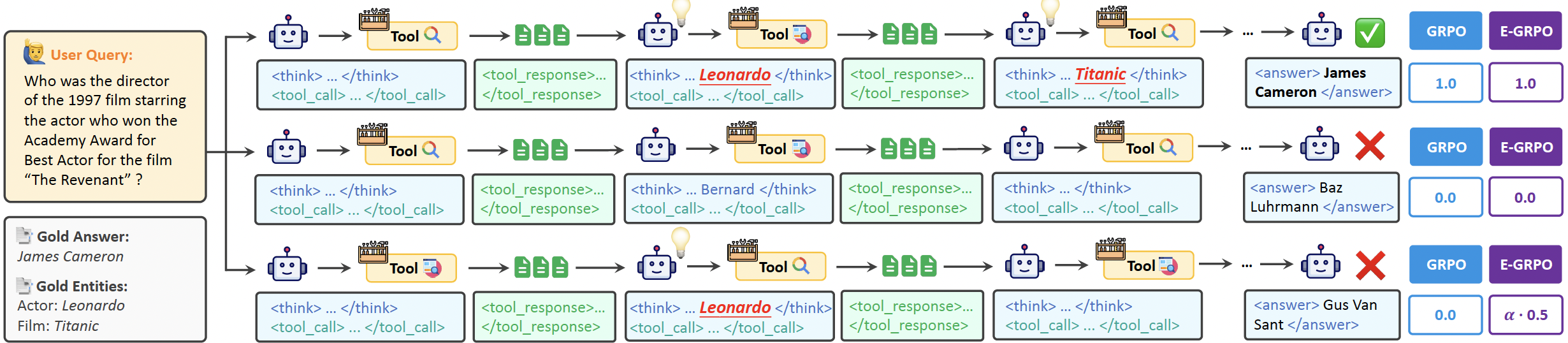
对于一个QA对,如果它里面有 m m m个实体,在 r o l l o u t i rollout_i rollouti,如果提到了其中的 E i E_i Ei个,提及率为 γ i = E i m \gamma_i=\frac{E_i}{m} γi=mEi,在GRPO中使用归一化的 γ i ~ \tilde{\gamma_i} γi~:
γ ^ i = { γ i γ max if γ max > 0 0 otherwise where γ max = max j ∈ { 1 , ... , G } γ j . \hat{\gamma}i = \begin{cases} \dfrac{\gamma_i}{\gamma{\max}} & \text{if } \gamma_{\max} > 0 \\ 0 & \text{otherwise} \end{cases} \quad \text{where} \quad \gamma_{\max} = \max_{j \in \{1, \ldots, G\}} \gamma_j. γ^i=⎩ ⎨ ⎧γmaxγi0if γmax>0otherwisewhereγmax=j∈{1,...,G}maxγj.
完整的reward function定义如下,相比于通常的GRPO,对于回答错误的 R i R_i Ri并不是直接定义为0,而是 α ⋅ γ i ~ \alpha \cdot \tilde{\gamma_i} α⋅γi~,只有格式错误的才是打出reward=0
R i = { 1 if H ( i ) is correct α ⋅ γ ^ i if H ( i ) is wrong 0 if error 1 occurs in H ( i ) R_i = \begin{cases} 1 & \text{if } \mathcal{H}^{(i)} \text{ is correct} \\ \alpha \cdot \hat{\gamma}_i & \text{if } \mathcal{H}^{(i)} \text{ is wrong} \\ 0 & \text{if error\^1 occurs in } \mathcal{H}^{(i)} \end{cases} Ri=⎩ ⎨ ⎧1α⋅γ^i0if H(i) is correctif H(i) is wrongif error1 occurs in H(i)
16. ParallelMuse
- 论文题目为《ParallelMuse: Agentic Parallel Thinking for Deep Information Seeking》,arXiv ID为2510.24698
- 这篇论文考虑的是,什么时候需要如何进行Parallel Thinking。BrowseConf是从最终输出的置信度来进行考虑的,如果置信度低,就从头(或者加入前面低置信度结果)开始尝试。从头开始尝试效率低,并且最终需要聚合这么长的信息,对上下文长度也是一个挑战。ParallelMuse提出,在工具调用的粒度进行Parallel Thinking。
置信度衡量
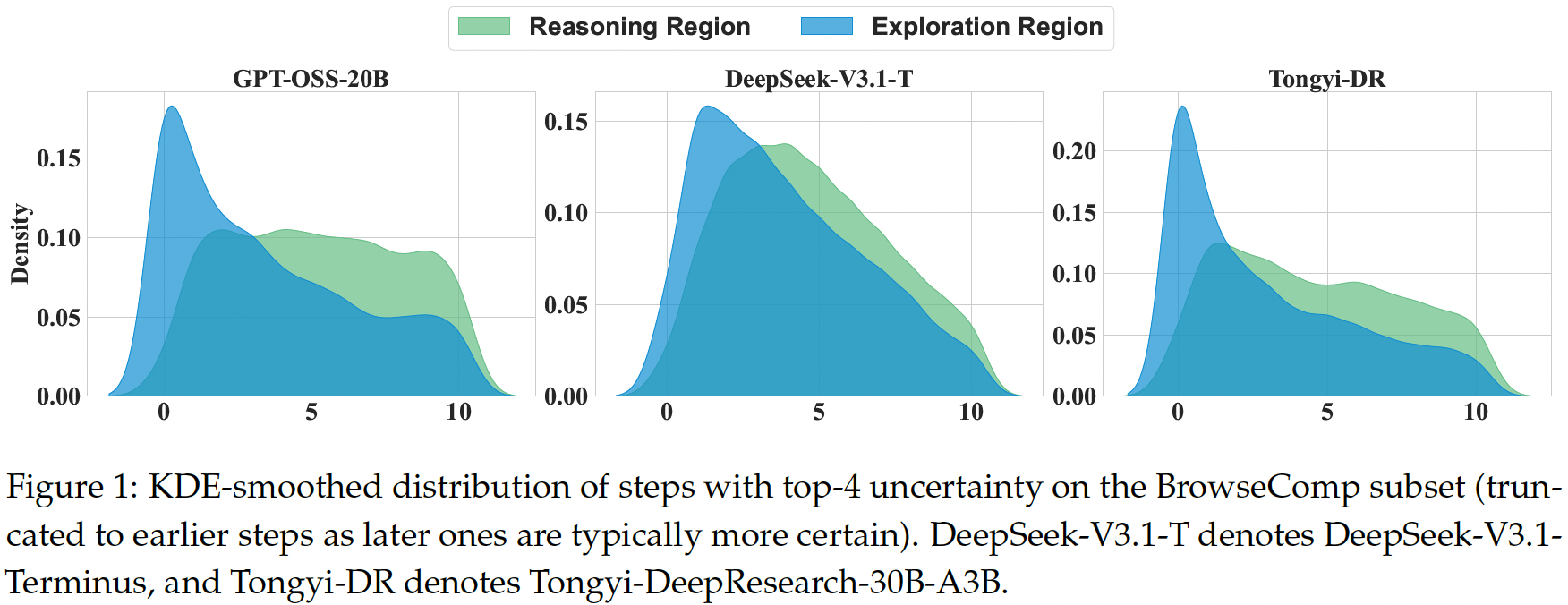
把Agent的输出token分成reasoning tokens和exploration tokens,在数据集上测试发现这两种token的perplexity的分布不一样(perplexity越高,置信度越低)。上面的图是任务执行过程中观测到的不确定性最高的前 4 个step的分布情况,横轴是step。exploration的不确定性在最早阶段达到最高水平,此时智能体还未获取到更多外部信息;而reasoning不确定性则稍晚达到峰值,此时智能体开始将检索到的信息整合进其内部推理过程。随着任务的推进,这两种不确定性均逐渐降低。
 ParallelMuse先推理 M M M个独立的轨迹(例如图中M=2),然后计算每个function call的token的perplexity:
ParallelMuse先推理 M M M个独立的轨迹(例如图中M=2),然后计算每个function call的token的perplexity:
P P L ( f , t ) = exp ( − 1 ∣ T t f ∣ ∑ i = 0 ∣ T t ∣ log p ( x t , i ∣ x < t , i ) ) , x t , i ∈ ∣ T t f ∣ , f ∈ { r , e } \mathrm{PPL}(f, t) = \exp\left( -\frac{1}{|\mathcal{T}t^f|} \sum{i=0}^{|\mathcal{T}t|} \log p(x{t,i} \mid x_{<t,i}) \right), \quad x_{t,i} \in |\mathcal{T}_t^f|, \quad f \in \{r, e\} PPL(f,t)=exp −∣Ttf∣1i=0∑∣Tt∣logp(xt,i∣x<t,i) ,xt,i∈∣Ttf∣,f∈{r,e}
找到perplexity最高的 k k k个step,只需要对这 k k k个step进行Parallel Thinking。使用不同token区域计算perplexity方式找argmax的效果如下:

在Parallel Thinking后,结果合并是在多路信息压缩后做的,每一路信息被单独压缩为report,report包含:
- 解决方案规划:描述主问题如何被分解为若干子问题,包括这些子问题之间的依赖关系及其执行顺序。
- 解决方法:为解决每个子问题所调用的工具、使用的具体参数,以及直接或间接贡献于最终答案的中间子答案
- 最终推理:阐明如何将已识别的子问题及其对应的子答案进行整合,从而推导出最终答案
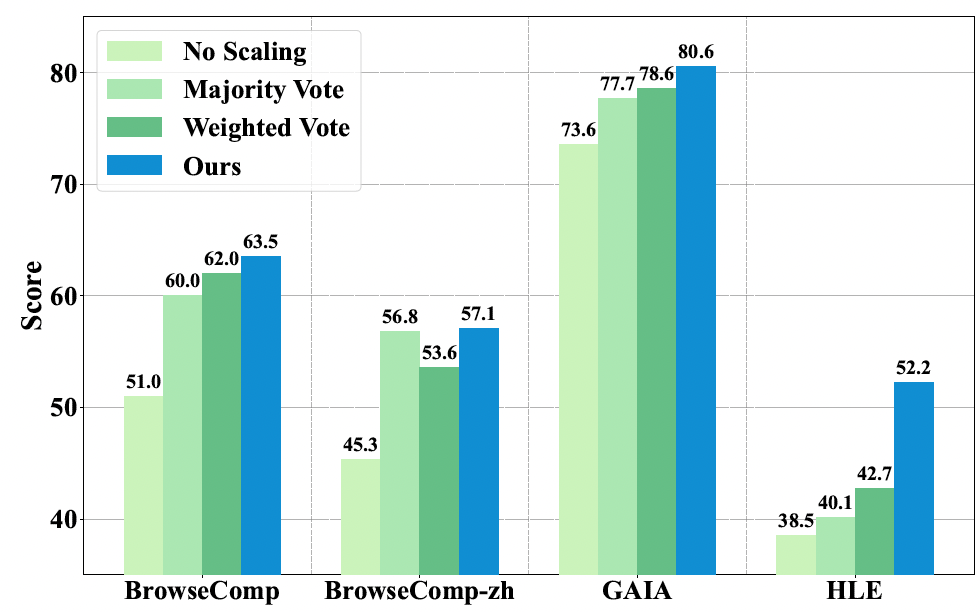
17. AgentFrontier
- 论文题目为《AgentFrontier: Expanding the Capability Frontier of LLM Agents with ZPD-Guided Data Synthesis》,arXiv ID为2510.24695
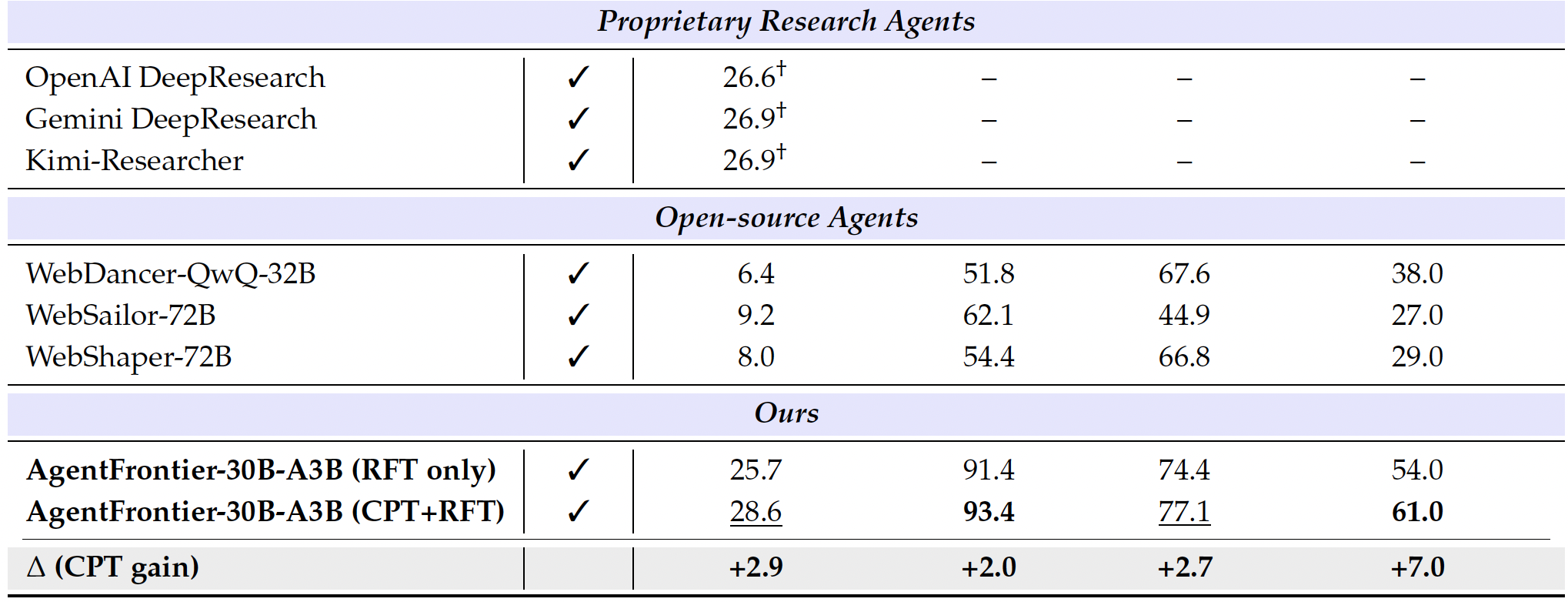
- 通过合成更合适的难的问题(LLM没法独自解决,可以被LLM+tool解决),提升Agent的复杂问题推理能力。整体方法和WebResearcher几乎一致,只是WebResearcher里面被base LLM回答对的问题直接丢弃了,这里放到pretrain数据集里面。
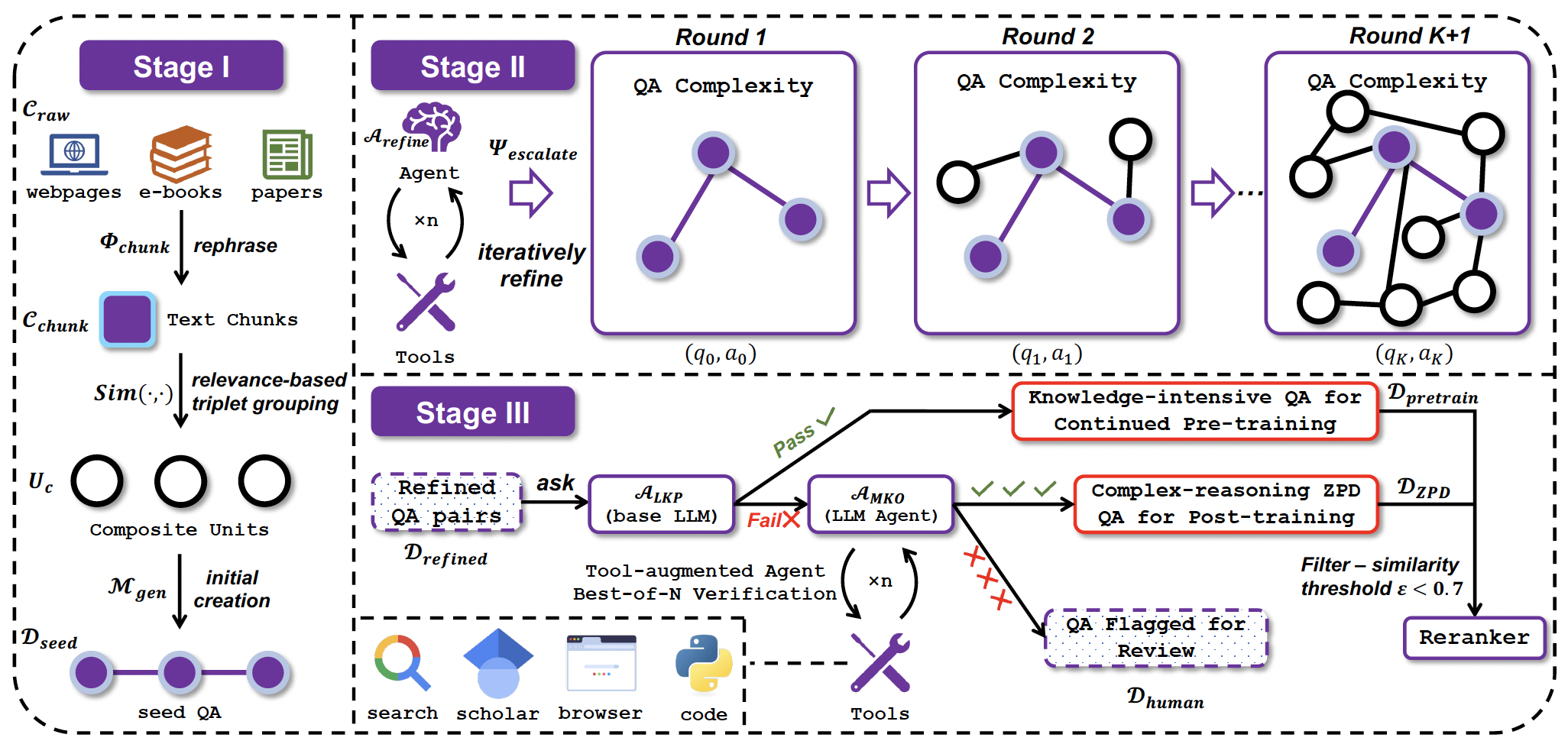
QA数据合成过程为: - 使用LLM把语料信息压缩为一个个chunk,对于一个chunk,寻找和它向量相似度高的chunk组成语义单元,使用LLM生成问题,得到原始QA对。
- 通过工具调用迭代改写问题,提升问题复杂度
- 数据筛选:base LLM能回答上的属于简单问题,可以放入预训练集合;LLM Agent回答得上的属于ZPD,这部分过滤掉和已有数据相似的,剩下的纳入ZPD训练集合;LLM Agent回答不上的人工review
结果上,继续预训练的收益不高,SFT已经足够
18. DeepResearch
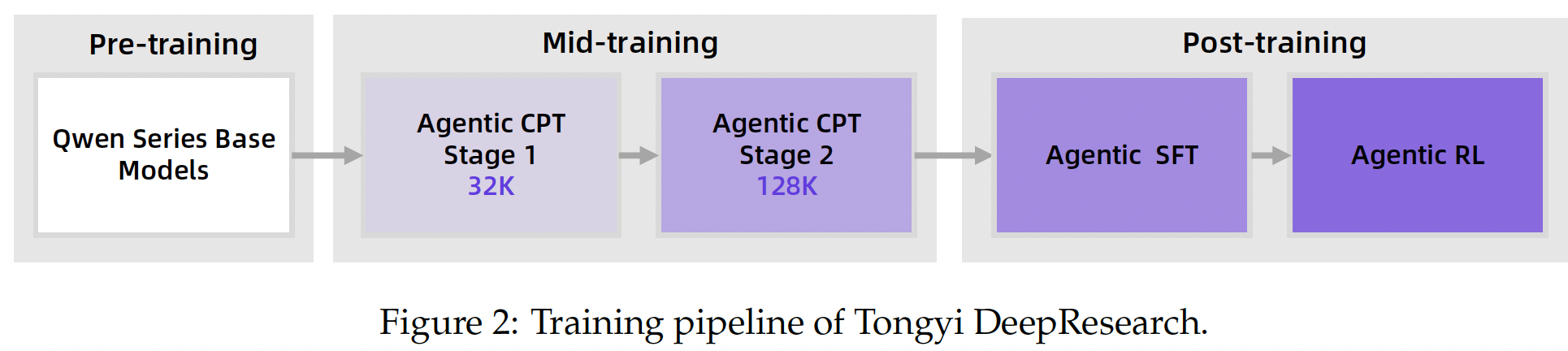
- 论文题目《Tongyi DeepResearch Technical Report》,arXiv ID为2510.24701
构建过程
- 上下文管理使用的是《WebResearcher: Unleashing unbounded reasoning
capability in Long-Horizon Agents》中的IterResearch方法,每次只看到重建的workspace,包括问题q、report和上一步的call+response
训练过程包括Agent继续预训练和使用Agent的QA数据的SFT
- CPT阶段:使用《Scaling Agents via Continual Pre-training》的方法,特别的对于function call的数据,使用《Towards general agentic intelligence via environment scaling》的方法进行增强
- Post-training阶段:使用包括Websailor、Websailor-v2、Webshaper和WebFrontier的方法,合成Agent的QA数据和轨迹数据,最后在RL阶段使用GRPO
- 最后对模型做了参数上的融合
θ merged = ∑ k α k ⋅ θ ( k ) , s.t. ∑ k α k = 1 , α k ≥ 0. \theta_{\text{merged}} = \sum_k \alpha_k \cdot \theta^{(k)}, \quad \text{s.t.} \quad \sum_k \alpha_k = 1, \; \alpha_k \geq 0. θmerged=k∑αk⋅θ(k),s.t.k∑αk=1,αk≥0.