一、css选择器
css基础语法
学习网站:CSS 选择器 | 菜鸟教程
|------------------|---------------------|
| 语法 | 功能 |
| p | 选择p标签 |
| .class1 | 选择class="class1"的标签 |
| #id1 | 选择id="id1"的标签 |
| body p | 选择body标签下的所有p标签 |
| body>p | 选择body标签下子级p标签 |
| div,p | 选择p和div标签 |
| div+p | 选择和div挨着的p标签 |
| class | 选择有class属性的标签 |
| class=class1 | 选择class="class1"的标签 |
实现代码(python)
python
pass二、Xpath
基础语法
学习网站:XPath 教程 | 菜鸟教程
xpath中将标签称为节点
|----------------|-----------------------------|
| 语法 | 功能 |
| p | 选择当前节点的所有名为p的子节点 |
| / | 选择根节点,html的根节点为html标签 |
| /p | 选择根节点下子节点中的p节点 |
| //p | 选择根节点下后辈节点中的p节点,后辈包含子节点的子节点 |
| title@lang | 选择有lang属性的title节点 |
实现代码(python)
python
from lxml import etree
import requests
def xpath_spider(url="https://www.test.com/fw/?k=%E7%BD%91%E7%BB%9C%E5%AE%89%E5%85%A8"):
resp = requests.get(url)
resp.encoding = resp.apparent_encoding
sour = resp.text
et = etree.HTML(sour)
divs = et.xpath("//div[@class='search-result-list-service']/div")
for div in divs:
price = div.xpath("./div/div[3]/div/span/text()")[0]
name = div.xpath("./div/div[3]/div[2]/div/span//text()")
name = "-".join(name)
company = div.xpath("./div/div[5]/div/div/div/text()")[0].split("丨")[0]
print(f"名称:{name}\n价格:{price}\n公司:{company}\n")
if "__main__" == __name__:
xpath_spider()
"""结果
名称:企业-网络-,服务器,存储,系统调试
价格:¥500
公司:t_9020_HBtnz8
名称:*测试,-安全-测试,app测试,-安全-检查
价格:¥1000
公司:网络安全爱好者
名称:技术服务|网站运维|数据库维护
价格:¥600
公司:宇视星AI启航
名称:提供远程技术支持服务,涵盖家庭-网络-调试、打印机配
价格:¥49
公司:t_9396_LD3bnh
名称:Web*测试基础版
价格:¥800
公司:祥安安服
.....三、正则
基础语法
学习网站:正则表达式 -- 语法 | 菜鸟教程
语法测试网站:https://www.jyshare.com/front-end/854/
|------------------|--------------------------------------------------------|
| 语法 | 功能 |
| ABC | 匹配A,B,C中任意一个字符 |
| \^ABC | 匹配除了A,B,C的任意字符 |
| A-Z | 匹配A-Z中一个字符 |
| . | 匹配除了空白字符的一个任意字符 |
| \s \S | \s匹配任意一个空白字符,\S匹配任意一个非空白字符 |
| \w \W | \w匹配字母、数字、下划线(变量命名字符),大写取反 |
| \d | \d匹配任意一个数字字符,大写取反 |
| ^a | 匹配作为字符串开头的a字符 |
| a$ | 匹配作为字符串结尾的a字符 |
| a* | 匹配任意个数量的a字符 |
| a+ | 匹配最少一个a字符 |
| a? | 匹配最多一个a字符 |
| a{x} | 匹配x个a字符 |
| a{x,y} | 匹配最少x个,最多y个a字符 |
| a{x,} | 匹配最少x个a字符 |
| a{,y} | 匹配最多x个a字符 |
| () | 分组符,可以理解为把括号中表达式匹配到的字符存入一个变量中可以后续调用 |
| \bcat\b | \b表示匹配一个非字母、数字下划线的字符,保证\b中间是一个独立的单词 |
| \Bcat\B | \B与\b相反,表示我要匹配一个单词中的cat字符串 |
| def(?=abc) | 表示匹配后面跟着abc字符串的def字符串 例:(defabc) |
| def(?!abc) | 表示匹配后面没有跟着abc字符串的def字符串 例:(defxxx) |
| (?<=abc)def | 匹配前面连接着一个abc字符串的def字符串 例:(abcdef) |
| (?<!abc)def | 匹配前面没有连接着一个abc字符串的def字符串 例:(xxxdef) |
| \1 | \1的作用就是调用前面分组中匹配到的字符串 例:(\w+) \1 匹配 "hello hello" |
| (?P<word>\w+) | 给分组取到的数据取名为word。可以理解为给word变量赋值。注:此为python语法,不同编程语言有所偏差 |
隐藏匹配规则贪婪:
* + {x,y} 这三个数量匹配语法都会尽可能多的匹配字符
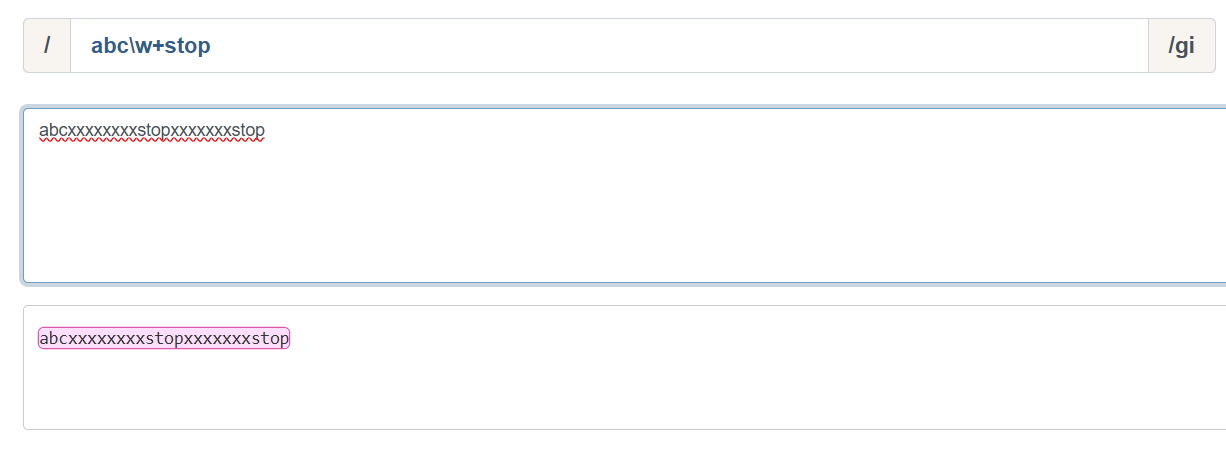
原始字符:adcxxxxxxxxstopxxxxxxxstop
例:abc\w+stop 此表达式会匹配整条字符串
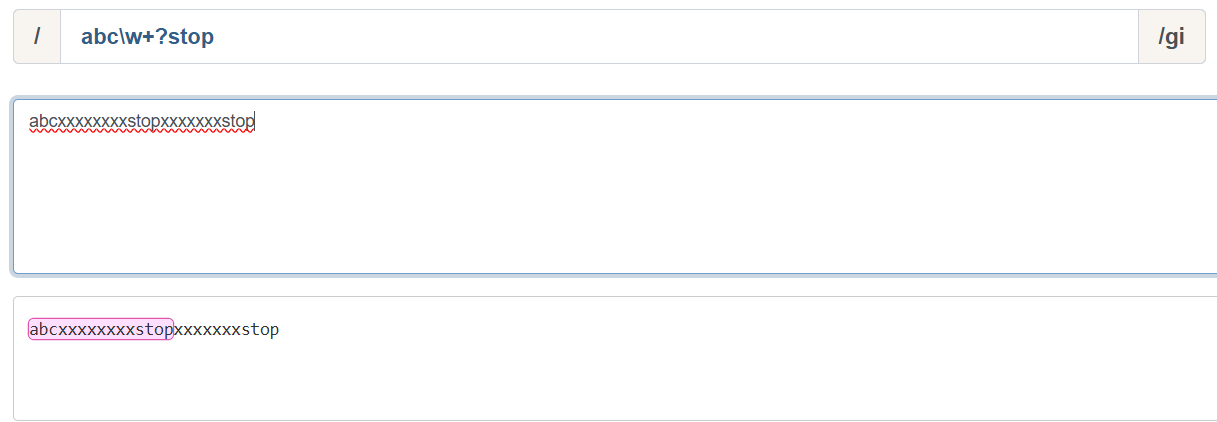
避免贪婪(懒惰匹配)
例:abc\w+?stop 匹配尽量少的字符串
实现代码(python)
python
def request_data(movie_url):
try:
movie_info_pattern = re.compile(
r"<br />◎片 名 (?P<movie_name>.*?)"
r"<br />◎年 代 (?P<release_year>\d{4})"
r"<br />◎产 地 (?P<production_region>.*?)"
)
movie_response = requests.get(url=movie_url, headers=headers, timeout=10)
movie_response.encoding = movie_response.apparent_encoding
movie_html = movie_response.text
movie_info = movie_info_pattern.search(movie_html)
return movie_info
except Exception as e:
print(f"处理电影页面 {movie_url} 时出错: {e}")