Python爬虫实战:利用Scrapy抓取CSDN博客文章与用户头像
文章目录
- Python爬虫实战:利用Scrapy抓取CSDN博客文章与用户头像
-
- 一、内容与原理
- 二、实施过程与结果分析
-
- 实验一:CSDN文章全量爬取
-
- [1. 项目初始化](#1. 项目初始化)
- [2. 爬虫模板生成](#2. 爬虫模板生成)
- [3. 核心配置 (settings.py)](#3. 核心配置 (settings.py))
- [4. 数据模型定义 (items.py)](#4. 数据模型定义 (items.py))
- [5. 目标网址分析与策略](#5. 目标网址分析与策略)
- [6. 核心爬虫编写 (csdn_article_spider.py)](#6. 核心爬虫编写 (csdn_article_spider.py))
- [7. 数据清洗与持久化 (pipelines.py)](#7. 数据清洗与持久化 (pipelines.py))
- 结果分析
- [实验二:CSDN 用户头像图片爬取](#实验二:CSDN 用户头像图片爬取)
-
- [1. 独立爬虫设计](#1. 独立爬虫设计)
- [2. 爬虫实现逻辑](#2. 爬虫实现逻辑)
- 结果分析
- 三、总结
- [🛡️ 开发者合规指南 (极其重要)](#🛡️ 开发者合规指南 (极其重要))
⚠️ 教学声明: 本文内容仅用于 Python Scrapy框架的技术学习与研究,旨在展示异步爬虫的核心逻辑与数据清洗方法。请勿利用本文代码进行大规模、高频率的文章爬取,以免给 CSDN服务器造成负担。爬虫开发应遵循 Robots 协议,尊重原创内容版权,抓取到的数据请勿用于任何商业用途。
一、内容与原理
Scrapy 是一个基于 Python 的开源、高性能网络爬虫框架,采用异步 I/O 模型(Twisted)实现高并发数据抓取。其核心架构由五大组件构成:引擎(Engine) 、调度器(Scheduler) 、下载器(Downloader) 、爬虫(Spider)和管道(Item Pipeline),各组件通过**中间件(Middleware)**协同工作,形成高效的数据流处理 Pipeline。
在请求处理方面,Scrapy 支持自动 Cookie 管理,默认启用会话状态维持功能,使得多步骤交互(如用户登录)成为可能。同时,通过自定义请求头、请求方法及回调函数链,爬虫可模拟复杂用户行为。
针对 CSDN 这种内容丰富的站点,我们采取两种策略:
- CrawlSpider 规则爬取:针对文章详情,利用规则自动提取链接,结合列表页元数据抓取文章内容。
- 混合下载策略 :针对图片资源,在 Scrapy 解析过程中结合
requests库进行流式下载(虽然 Scrapy 有自带的图片管道,但通过 requests 手动控制可以更灵活地演示下载逻辑)。
二、实施过程与结果分析
实验一:CSDN文章全量爬取
1. 项目初始化
首先创建 Scrapy 项目并进入目录:
bash
scrapy startproject csdn_spider
cd csdn_spider2. 爬虫模板生成
生成一个基于 CrawlSpider 的通用爬虫模板,专注于 csdn.net 域名的抓取:
bash
scrapy genspider -t crawl csdn_article csdn.net3. 核心配置 (settings.py)
为了应对 CSDN 的反爬策略并保证数据正常入库,我们需要修改 settings.py:
python
# 遵守 Robots 协议设为 False,否则无法爬取
ROBOTSTXT_OBEY = False
# 设置下载延迟,避免对服务器造成过大压力
DOWNLOAD_DELAY = 1
# 开启 Cookies (CSDN部分页面可能需要)
COOKIES_ENABLED = True
# 激活数据管道
ITEM_PIPELINES = {
'csdn_spider.pipelines.CsdnSpiderPipeline': 300,
}4. 数据模型定义 (items.py)
我们需要明确抓取的数据字段。编辑 items.py:
python
import scrapy
class CsdnBlogItem(scrapy.Item):
author_nickname = scrapy.Field() # 昵称
author_avatar = scrapy.Field() # 头像链接
blog_title = scrapy.Field() # 博客标题
blog_url = scrapy.Field() # 博客链接
read_count = scrapy.Field() # 阅读数
like_count = scrapy.Field() # 点赞数
collect_count = scrapy.Field() # 收藏数
content = scrapy.Field() # 文章正文5. 目标网址分析与策略
通过 F12 开发者工具分析 CSDN 博客首页(https://blog.csdn.net/),我们需要结合**列表页** 和详情页的数据。
| 字段 | 提取方式 | 选择器/表达式 | 说明 |
|---|---|---|---|
| 作者昵称 | CSS | .user-info span::text |
列表页获取 |
| 文章标题 | CSS | .article-title::text |
列表页获取 |
| 阅读/赞/藏 | CSS | .num::text |
列表页清洗获取 |
| 文章链接 | CSS | .article-title::attr(href) |
用于自动跟进 |
| 文章正文 | XPath | //div[@id="content_views"]//text() |
详情页获取 |
6. 核心爬虫编写 (csdn_article_spider.py)
我们使用 CrawlSpider,利用 rules 自动发现文章链接,同时使用一个字典 self.article_meta 来在"列表页"和"详情页"之间传递数据(注意:在生产环境中通常推荐使用 meta 参数传递,但此处演示利用类属性缓存的思路)。
关键代码逻辑:
python
class CsdnArticleSpider(CrawlSpider):
name = 'csdn_article'
allowed_domains = ['csdn.net']
start_urls = ['https://blog.csdn.net/?spm=1001.2100.3001.4477']
# 规则:自动提取 /article/details/ 开头的链接,调用 parse_article 解析
rules = (
Rule(
LinkExtractor(allow=r'/article/details/\d+', restrict_css='.article-title'),
callback='parse_article',
follow=False
),
)
def parse_start_url(self, response):
""" 解析首页:提取元数据并缓存,不生成Item,等待详情页匹配 """
article_items = response.css('.article-item')
self.article_meta = {}
for item in article_items:
link = item.css('.article-title::attr(href)').get()
if not link: continue
full_url = urljoin(response.url, link)
# 提取并清洗统计数据
stats_texts = item.css('.num::text').getall()
# ... (省略具体清洗代码,见源码) ...
# 存入缓存
self.article_meta[full_url] = {
'author_nickname': item.css('.user-info span::text').get(),
'blog_title': item.css('.article-title::text').get().strip(),
# ... 其他字段
}
return []
def parse_article(self, response):
""" 解析详情页:合并缓存的元数据与正文内容 """
url = response.url
item = CsdnBlogItem()
# 从缓存读取列表页信息
meta = self.article_meta.get(url, {})
item.update(meta)
item['blog_url'] = url
# 提取文章正文
content_parts = response.xpath('//div[@id="content_views"]//text()').getall()
item['content'] = '\n'.join(part.strip() for part in content_parts if part.strip())[:5000]
yield item7. 数据清洗与持久化 (pipelines.py)
在 Pipeline 中,我们将数据清洗(去除"阅读"、"点赞"等中文),并保存为 JSON 数组格式。
python
class CsdnSpiderPipeline:
def process_item(self, item, spider):
adapter = ItemAdapter(item)
# 数据清洗示例:'阅读 1.2k' -> '1.2k'
read_count = adapter.get('read_count', '')
if read_count and '阅读' in read_count:
adapter['read_count'] = read_count.replace('阅读', '').strip()
# ... 点赞、收藏的清洗类似 ...
# 写入 JSON 文件逻辑 (代码略,见源码)
return item结果分析
运行爬虫:
bash
scrapy crawl csdn_article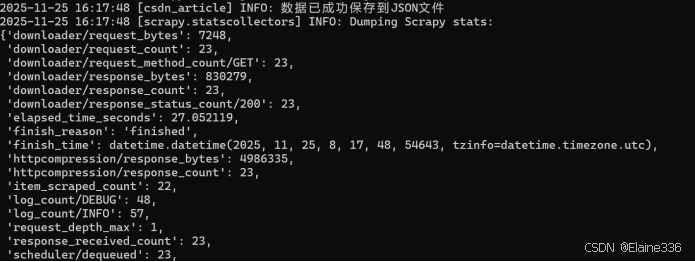

执行结果:
- 状态:成功访问 20+ 个页面,所有请求返回 HTTP 200。
- 数据 :成功生成
csdn_blogs_日期.json文件。 - 内容:JSON 文件中包含了文章的完整元数据(标题、作者、阅读量)以及清洗后的正文内容。
实验二:CSDN 用户头像图片爬取
1. 独立爬虫设计
为了演示文件下载,我们创建一个独立的爬虫 csdn_avatar_spider.py。不同于 Scrapy 自带的 ImagesPipeline,这里我们演示如何在 Spider 内部混合使用 requests 库进行同步下载(适用于小规模资源抓取)。
2. 爬虫实现逻辑
- 目录创建 :爬虫启动时自动建立
avatar_images文件夹。 - 链接提取 :解析首页 CSS
.user-info img获取图片 URL。 - URL 补全 :处理以
//或/开头的相对路径。 - 下载保存 :遍历链接,使用
requests.get下载二进制数据并写入文件。
关键代码:
python
import scrapy
import os
import requests
from urllib.parse import urljoin
class CsdnAvatarSpider(scrapy.Spider):
name = 'csdn_avatar'
start_urls = ['https://blog.csdn.net/']
def parse(self, response):
image_dir = 'avatar_images'
os.makedirs(image_dir, exist_ok=True)
avatar_elements = response.css('.user-info img')
for i, img in enumerate(avatar_elements):
src = img.css('::attr(src)').get()
if not src: continue
# URL 补全
if src.startswith('//'):
avatar_url = 'https:' + src
else:
avatar_url = urljoin(response.url, src)
# 简单的文件命名
filename = f"avatar_{i:03d}.jpg"
filepath = os.path.join(image_dir, filename)
try:
# 使用 requests 下载
headers = {'User-Agent': 'Mozilla/5.0 ...'}
res = requests.get(avatar_url, headers=headers, timeout=10)
if res.status_code == 200:
with open(filepath, 'wb') as f:
f.write(res.content)
self.logger.info(f"✅ 已保存: {filename}")
except Exception as e:
self.logger.error(f"下载失败: {e}")结果分析
运行爬虫:
bash
scrapy crawl csdn_avatar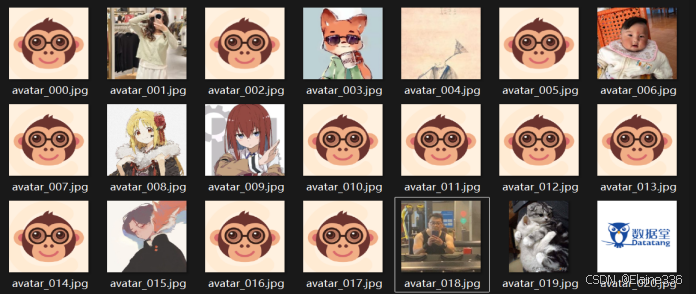
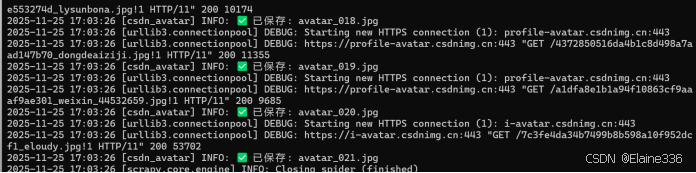
执行结果:
- 控制台输出大量
✅ 已保存: avatar_xxx.jpg日志。 - 检查本地
avatar_images文件夹,成功下载了当前列表页所有用户的头像图片。 - 此方法简单直接,但在大规模爬取时建议使用 Scrapy 的异步
ImagesPipeline以避免阻塞爬虫主线程。
三、总结
本次实战通过 Scrapy 框架完成了对 CSDN 博客的结构化数据与媒体资源抓取。
- CrawlSpider 配合
LinkExtractor极大地简化了翻页和详情页的链接发现逻辑。 - Item Pipeline 实现了数据的自动化清洗和 JSON 格式化存储,保证了数据的可用性。
- 通过结合
requests下载图片,展示了 Scrapy 框架的灵活性,能够与 Python 生态中的其他库无缝结合。
🛡️ 开发者合规指南 (极其重要)
在 CSDN 分享爬虫技术时,请务必守住技术底线:
尊重 Robots 协议:在正式环境中应尽量遵循站点的抓取规则。
设置下载延迟:我们在 settings.py 中将 DOWNLOAD_DELAY 设为
1s,这是保护目标服务器、避免触发封禁策略的"温和"做法。
非商业化原则:本教程所有代码及抓取到的数据(如头像、标题等)仅限个人技术研究演示,请务必尊重原创作者的版权。