引言
如果我们需要判断一封电子邮件是否为垃圾邮件。如果只依赖单个人(或单一算法)进行判断,可能会因为固有的偏见或知识局限而出错,但如果让一群人(多个算法)分别独立判断,再通过投票共同决定,结果的准确性就会大幅提升。这正是"随机森林"算法的核心理念------集思广益,通过群体的智慧弥补个体的不足,本文将一起学习这一强大而实用的算法。
一、从一棵树到一片森林
我们再上一篇文章中学习了决策树算法,决策树的判断过程类似于玩"20个问题"游戏,通过一系列问题(如"邮件是否包含'免费'一词?"、"发件人是陌生人吗?")逐步推导出结论,但单个决策树容易像死记硬背的学生一样"过拟合",意思就是过分适应训练数据而在面对新情况时表现不佳。为了解决这个问题,可以采用"集成学习"方法------团结多个较弱的"基学习器"共同构建一个强大的模型,主要有三种实现路径:其中一个是"装袋法",通过并行训练多个模型并让它们投票决策(这正是我们当前学习的随机森林所采用的),其二是"提升法",让后续模型重点学习前序模型判断错误的样本,以此串联改进,其三是"堆叠法",将多个模型的输出结果作为新特征,再训练一个高阶模型进行最终决策。
二、随机森林深度解析
1、什么是随机森林?
随机森林是一种集成学习算法,其核心是结合"决策树"、"Bagging"和"随机特征选择"三项技术。它通过自助采样法构建多棵决策树,每棵树不仅基于数据的随机样本进行训练,而且在每个节点分裂时只考虑特征的一个随机子集。这种双重随机性确保每棵树具有差异性。最终,对于分类任务通过投票、对于回归任务通过取平均值的方式,汇总所有树的预测结果,从而获得比单棵决策树更准确、更稳定的模型,并且可以有效防止过拟合。
2、随机森林的三大特点
1.数据采样随机(行随机)与特征选取随机(列随机)
随机森林通过双重随机性来构建多棵差异化的决策树:首先在数据层面进行"行随机",采用有放回的自助采样方式,为每棵树生成略有差异的训练数据集,同时在特征层面进行"列随机",即在树的每个节点分裂时,只考虑特征的一个随机子集。这种结合了Bagging与随机特征选择的方法,有效降低了模型复杂度与方差,最终通过集体投票或取均值的方式汇聚各树的预测,从而得到一个能有效防止过拟合的稳健模型。
2.森林
这片森林由数十棵乃至数百棵相对简单、深度较浅的决策树集合而成,通常,森林中包含的树的数量越多,模型的整体表现就越稳定,但这种提升效果并非无限,其存在一个合理的极限。
3.基分类器为决策树
每一棵决策树本身的结构都相对简单,且深度较浅,能力有限;然而,通过将大量这种"能力较弱但个体差异显著"的树组合在一起,却能形成一个整体性能强大且稳健的森林。
3、随机森林如何工作?
原始数据
↓
创建多个自助样本集
↓
对每个样本集: 并行训练!
├─ 随机选择特征子集
├─ 构建决策树
└─ 不剪枝(或轻度剪枝)
↓
新数据到来时:
├─ 每棵树独立投票
└─ 取多数票为最终结果随机森林的生成步骤:首先,从原始数据中通过自助采样创建多个略有差异的数据子集,接着,针对每一个子集并行地训练一棵决策树,在训练每棵树时,不仅数据是随机采样的,而且在每个节点分裂时都只考虑一个随机选择的特征子集,树通常生长到最大深度而不进行剪枝,当需要预测新数据时,森林中的所有树会各自独立地给出预测,最终的预测结果由所有树的投票或输出的平均来决定。我们使用随机森林,主要因为它可以在各类问题上都能获得很高的预测准确率,可以通过双重随机性(数据与特征)有效降低了模型的过拟合风险,能够高效地处理高维数据,并在训练过程中隐含了特征选择,同时,由于每棵树的训练相互独立,该算法能利用现代计算硬件来大幅提升训练效率。
三、亲手实践------垃圾邮件分类实战
现在让我们用一个简单的项目来演示随机森林:
1、数据处理
首先,使用pandas库读取名为spambase.csv的数据文件并加载为DataFrame,接着,将数据分为特征矩阵X和标签向量y,最后,借助sklearn的train_test_split函数,将数据集按80%训练、20%测试的比例进行随机划分,并固定随机种子以确保结果可复现,从而得到训练集与测试集。
# 1. 数据准备
import pandas as pd
df = pd.read_csv('spambase.csv') # 读取数据
# 划分特征和标签
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
# 分割训练集和测试集(80%训练,20%测试)
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(
X, y, test_size=0.2, random_state=100
)2、创建随机森林模型
首先从sklearn.ensemble中导入RandomForestClassifier类,然后实例化一个随机森林模型,关键参数设置为生成100棵决策树,每棵树在分裂节点时随机使用80%的特征,并固定随机种子,最后,调用fit方法,使用此前准备好的训练特征xtrain和训练标签ytrain对模型进行训练,让算法自动完成创建多棵决策树并集成为森林。
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rf = RandomForestClassifier(
n_estimators=100, # 100棵树
max_features=0.8, # 每棵树使用80%的特征
random_state=0
)
# 训练模型
rf.fit(xtrain, ytrain)关键参数解读:
1.n_estimators=100(随机森林独有参数)
是决策树的数量,开始时用100,可增加到300-500观察效果。
2.max_features=0.8(随机森林独有参数)
每棵树使用的最大特征比例,这里是80%的特征,即每棵树随机选择45个特征,增加可能提高单棵树性能,但会降低多样性。
3.random_state=0
随机种子,确保每次运行结果一致。
4.max_depth=None
树不限制深度,可能过拟合。
5.min_samples_split=2
节点最少2个样本才继续分裂。
6.min_samples_leaf=1
叶节点最少1个样本。
7.bootstrap=True
使用有放回抽样(Bagging的核心)。
3、模型评估
在完成模型的训练后,通常会先在训练集上进行预测,观察模型对已学习数据的"记忆"程度或拟合效果, 之后,在模型从未见过的测试集上进行预测,最后,借助 sklearn.metrics 中的评估工具,如通过打印针对测试集的分类报告可以清晰地得到精确度、召回率、F1分数等关键指标,从而客观判断模型的实际表现。
# 在训练集上测试(看看"记住"了多少)
train_predicted = rf.predict(xtrain)
# 在测试集上测试(真正的"考试")
test_predicted = rf.predict(xtest)
# 使用混淆矩阵和分类报告评估
from sklearn import metrics
print("测试集表现:")
print(metrics.classification_report(ytest, test_predicted))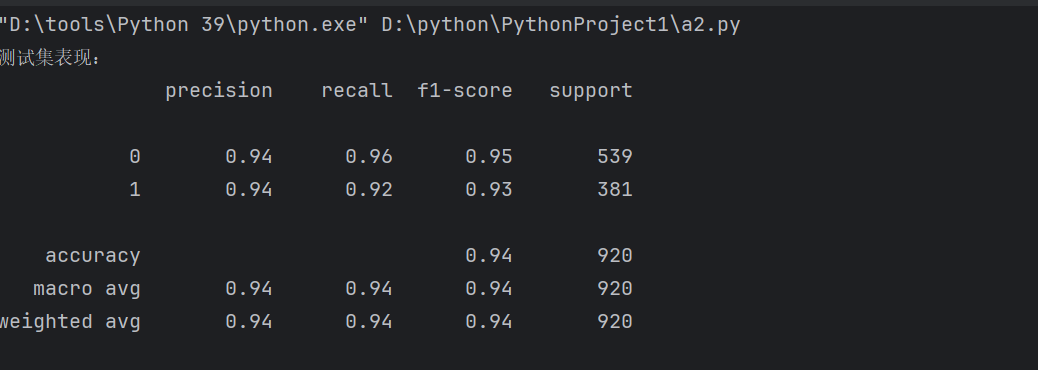
四、洞察模型------特征重要性分析
随机森林还能告诉我们哪些特征最重要。
1、特征重要性排序
首先,通过调用已训练好的随机森林分类器 rf 的 feature_importances_ 属性,获取所有特征对于预测结果的重要性得分,随后,将这些重要性数值与对应的特征名称组合成一个结构清晰的 DataFrame,最后,利用 sort_values 方法按重要性得分进行降序排序,并选取排名前10的最重要特征,直观地展现出哪些特征在模型的决策过程中起到了关键作用。
# 获取特征重要性
importances = rf.feature_importances_
# 创建DataFrame保存结果
im = pd.DataFrame(importances, columns=["importances"])
im['feature_name'] = df.columns[:-1] # 获取特征名
# 排序
im = im.sort_values(by=['importances'], ascending=False)[:10]2、可视化展示
用matplotlib库绘制特征重要性的可视化水平条形图:首先,根据前10个重要特征的数量生成对应的索引范围,然后,通过plt.yticks将特征名称设置为y轴标签,并使用plt.barh绘制出各特征重要性得分的水平条形图,最后通过plt.show()展示出直观的图形。
import matplotlib.pyplot as plt
index = range(len(im))
plt.yticks(index, im.feature_name) # 设置y轴标签
plt.barh(index, im['importances']) # 水平条形图
plt.title("Top 10 Important Features")
plt.show()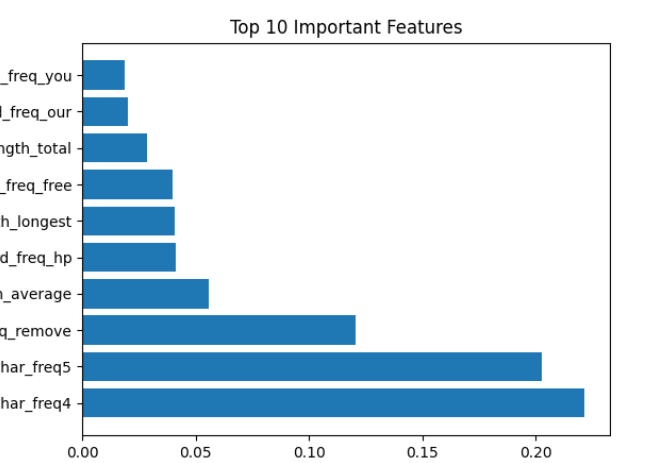
五、调整与优化------让模型更出色
如果我们的模型训练后的效果不理想的话,我们可以试着:
1、增加树的数量(会减慢速度)
通过集成更多的决策树进行投票或平均,能够更有效地降低单棵树的方差与偶然误差,使模型能在一定范围内提升预测的准确率。然而,训练时间和计算成本会相应增加,并且当树的数量超过一定限度后,性能的提升会逐渐减小,甚至可能因计算资源消耗过大而得不偿失。
rf = RandomForestClassifier(n_estimators=300, ...)2、调整特征比例
在构建随机森林分类器时,系统性地遍历多个特征比例,每次循环都将 max_features 参数设置为对应的 feature_ratio 值。这一比例控制了每棵决策树在节点分裂时可以随机考虑的最大特征数量,通过改变特征子集的随机性,来平衡模型的预测能力:较低的比例能增强树之间的差异性,有助于降低过拟合风险并提升计算效率,但可能牺牲单棵树的表达能力,较高的比例则让每棵树能看到更完整的特征信息,可能提升个体性能但可能减少多样性。
# 尝试不同的特征比例
for feature_ratio in [0.3, 0.5, 0.7, 0.9]:
rf = RandomForestClassifier(max_features=feature_ratio, ...)3、控制树深度防止过拟合
通过限制每棵决策树的最大深度,可以有效控制随机森林中每棵树的复杂度和生长程度,从而防止模型因学习得过于具体和复杂而陷入过拟合。
rf = RandomForestClassifier(max_depth=10, ...)4、使用交叉验证找最佳参数
首先从 sklearn.model_selection 中导入 GridSearchCV 工具,然后定义一个参数网格 param_grid,其中指定了待评估的候选值------树的数量为 100, 200,每次分裂考虑的特征比例为 0.7, 0.8, 0.9,接着,创建一个 GridSearchCV 对象,传入基础的随机森林估计器、参数网格,并设置交叉验证折数为 5。该对象会自动化地遍历所有参数组合,对每一种组合进行 5 折交叉验证训练与评估,最终通过比较平均得分来确定能带来最佳性能的参数配置,从而完成模型的调优。
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200],
'max_features': [0.7, 0.8, 0.9]
}
grid_search = GridSearchCV(rf, param_grid, cv=5)到这里我们就完成了随机森林算法的学习,在下一章里,我们将学习更多机器学习中的常用算法。