一、研究背景(Context)
CNN 的统治时代:自 2012 年 AlexNet 以来,CNN(卷积神经网络)通过局部感受野、平移不变性、参数共享等设计,成为了计算机视觉(CV)任务的标准骨干网络。其层级化结构(如 ResNet)天然支持多尺度特征提取(从边缘→纹理→部件→物体),非常适合检测、分割等dense prediction(密集预测)任务。
Transformer 的崛起:在 NLP 领域,Transformer 凭借 self-attention 机制建模长距离依赖,彻底取代 RNN。2020 年 ViT(Vision Transformer)首次将纯 Transformer 应用于图像分类,效果惊艳------但仅限分类。
问题浮出水面:ViT 将整张图切成固定大小 patch,全局计算 attention,不具层级结构,输出只有一层低分辨率 feature map,且 attention 的 O(N²) 复杂度(N = patch 数)让高分辨率图像(如 1024×1024)的 dense prediction 几乎不可行。------它像一个"只看整体、不看细节"的学者,能认对类别,却画不准边界。
✅ 一句话背景:CNN 擅长细节与结构,Transformer 擅长全局建模;但直接把后者照搬进视觉,会水土不服。
二、问题(Challenge)
因为视觉信号的两大本质特性------尺度多变性(scale variation)与高分辨率需求(high-res demand)------使得全局自注意力(global self-attention)无法作为通用视觉骨干网络(general-purpose backbone)。
具体拆解如下:
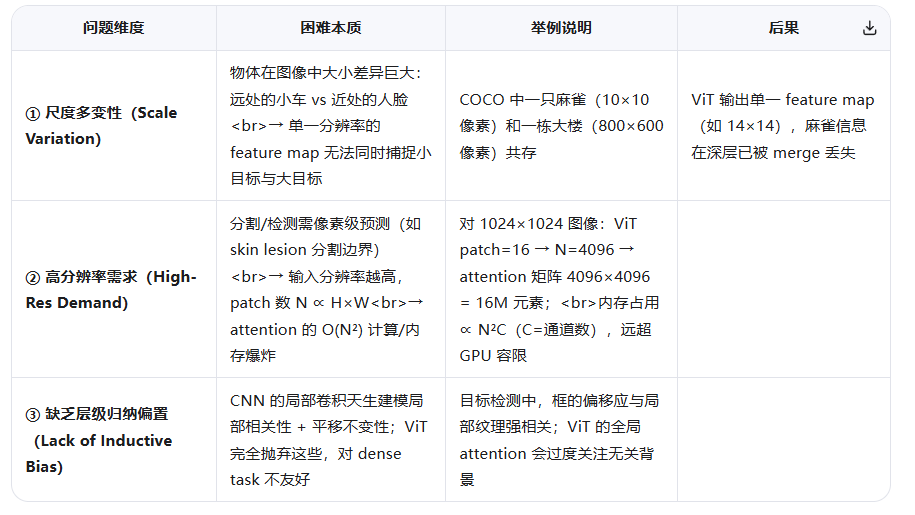
❗核心矛盾:既要保留 Transformer 的长程建模能力,又要像 CNN 一样高效、分层、适配 dense 任务------但"全局 attention + 层级结构"在计算上互斥。
三、Finding(洞见)← 这是全文最核心的"闪光点"
🔥 作者的颠覆性发现是: "局部窗口内的自注意力" + "窗口划分的周期性偏移" = 既保留局部高效性,又隐式建模长距离依赖的
层次化建模新范式。 换句话说:不必全局算 attention,只要让每个 patch
在"两步之内"就能触达图像任意位置,即可近似全局建模能力------而这可通过 Shifted Window 实现。
这个 finding 为何厉害?------它重构了对"感受野扩展"的认知:
- 传统 CNN:靠 stack 卷积层逐层扩大感受野(如 ResNet-50 最后一层感受野≈1000+ 像素)
- ViT:一步到位全局attention(感受野=整图,但代价高昂)
- Swin 的新视角: "感受野不必物理上覆盖全图,只要信息能在浅层快速流动到全局即可。"
→ 用 两层交替的窗口划分(regular + shifted)构成一个"信息高速公路网":- Layer l:patch A 与同窗口内邻居通信
- Layer l+1:窗口偏移后,A 的新窗口包含 上一层其他窗口 的 patch → A 间接连接到远方 patch → 仅 2 层即可实现跨窗口通信,O(1) 步实现全局连接(类似跳表 Skip List 思想)
四、方法(Method)------如何把 finding 落地?
Swin Transformer 的设计是 finding 的自然展开,可分解为三步:
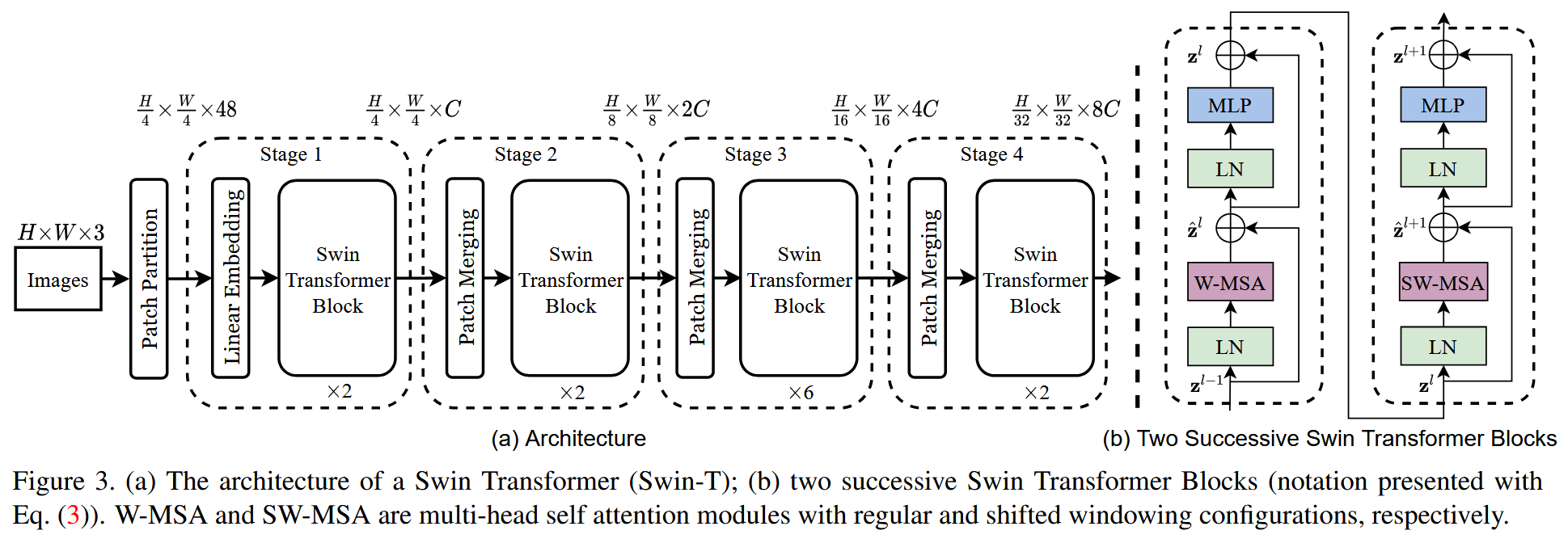
📌 Step 1:分层特征构建(Hierarchical Feature Maps)
输入:H×W×3 RGB 图像
Stage 1:4×4 patch → 48-dim token → linear embedding (C=96)
后续 Stage:每阶段用 Patch Merging:将 2×2 邻域 patch concat → linear proj → 分辨率降 2×,通道数×2
→ 输出 4 级 feature map:H/4, H/8, H/16, H/32
→ ✅ 兼容 FPN / U-Net 等 dense head
📌 Step 2:Swin Transformer Block = W-MSA + SW-MSA 交替
每个 block = LN → (W-MSA / SW-MSA) → LN → MLP(GELU)
W-MSA(Window-based MSA):将 feature map 划分为 不重叠 M×M 窗口(M=7),每个窗口内独立算 self-attention
→ 复杂度从 O((HW)²) 降至 O(HW·M²) = 线性于图像尺寸!
SW-MSA(Shifted W-MSA):将窗口划分 向右下偏移 (⌊M/2⌋, ⌊M/2⌋) = (3,3)
→ 新窗口跨越原窗口边界(见 Figure 2)
→ 用 cyclic shift + mask attention 实现高效 batch 计算(避免 padding 浪费)
💡 关键技巧:mask 掉非同一子窗口的 patch 对(如 Figure 4 中 A-B 间无连接),保持注意力纯净
📌 Step 3:相对位置偏置(Relative Position Bias)
不像 ViT 用绝对位置编码(absolute pos embed),Swin 在 attention score 中加 可学习的相对位置偏置 B:
Attention(Q,K,V) = Softmax(QKᵀ/√d + B)V
B ∈ R^{(2M−1)×(2M−1)},参数量小,泛化好
实验表明:对 dense task 至关重要(+2.3 mIoU on ADE20K)
🧩 整体流程图(Figure 3):
Patch Partition → Stage1(W-MSA→SW-MSA×2)→ Patch Merging → Stage2(同上)→ ... → 输出 4 级 feature