预训练网络
基本介绍
from torchvision import models # 查看对象的属性和方法列表 print(dir(models)) # ['AlexNet','DenseNet','ResNet',...,'alexnet','densenet',....,'resnet','resnet101']上述代码是查看pytorch中提供的预训练模型,其中首字母大写的名称是指实现了许多流行模型的Python类;首字母小写的名称是指的一些便捷函数,它们返回对应函数实例化的模型,而像resnet101表示返回一个有101层网络的ResNet实例
模型系列 主要特点与优势 典型应用场景 代表性模型 经典CNN系列 结构经典,理解深入,可靠性高。 教学、研究、通用图像分类基准。 AlexNet, VGG系列 深度残差网络 解决了深度网络退化问题,性能强大均衡。 最通用的骨干网络,适用于绝大多数视觉任务。 ResNet-18/34/50/101/152 轻量级网络 参数少、计算量小、速度快。 移动端、嵌入式设备等资源受限的实时应用。 MobileNetV2/V3, SqueezeNet 高效复合网络 通过复合缩放在精度和效率间取得更好平衡。 追求更高精度且对模型大小有一定要求的场景。 EfficientNet, ResNeXt Transformer系列 基于自注意力机制,擅长捕捉全局信息。 数据量充足、追求前沿性能的研究或应用。 Vision Transformer (ViT) 当对于某些网络并不熟悉时,可以使用help()查看官方的文档
from torchvision import models print(help(models.resnet101)) # Help on function resnet101 in module torchvision.models.resnet: resnet101(*, weights: Optional[torchvision.models.resnet.ResNet101_Weights] = None, progress: bool = True, **kwargs: Any) -> torchvision.models.resnet.ResNet ResNet-101 from `Deep Residual Learning for Image Recognition <https://arxiv.org/abs/1512.03385>`__. .. note:: The bottleneck of TorchVision places the stride for downsampling to the second 3x3 convolution while the original paper places it to the first 1x1 convolution. This variant improves the accuracy and is known as `ResNet V1.5 <https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch>`_. Args: weights (:class:`~torchvision.models.ResNet101_Weights`, optional): The pretrained weights to use. See :class:`~torchvision.models.ResNet101_Weights` below for more details, and possible values. By default, no pre-trained weights are used. progress (bool, optional): If True, displays a progress bar of the download to stderr. Default is True. **kwargs: parameters passed to the ``torchvision.models.resnet.ResNet`` base class. Please refer to the `source code <https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py>`_ for more details about this class. .. autoclass:: torchvision.models.ResNet101_Weights :members: None
AlexNet
与其他网络相比,AlexNet是出现最早的几个神经网络之一,其规模相当小,适合作为学习的第一个神经网络
ResNet
残差网络,目前最为通用的网络之一
from torchvision import models resnet = models.resnet101(pretrained = True) print(resnet) #ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) .... (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=2048, out_features=1000, bias=True) )这里的结果中我们看到了许多模块,它们与Python模块没有任何关系,是独立的操作系统,一般称之为层。
对于该模型来说,其有101层,故而其Bottleneck有101个,包括在该层的卷积和其他模块,最后一层的(fc)为为1000个输出类中的每个类生成的预测分数
特殊函数
在python中存在一些特殊函数,它是某一个class类的一个实例化函数,当该类实例化后,可以直接通过python的内置函数调用
操作 调用的方法 说明 obj = Class()__init__构造函数 obj()__call__使实例可调用 obj[key]__getitem__索引/切片访问 obj.attr__getattr__属性访问 str(obj)__str__字符串表示 len(obj)__len__长度 obj1 + obj2__add__加法操作 with obj:__enter__/__exit__上下文管理器 其中obj表示实例化后的class类,同时
[]操作符调用__getitem__,如列表等的切片索引
()操作符调用__call__,如定义函数后,在主代码中运行它
+操作符调用__add__
print()调用__str__或__repr__
len()调用__len__
class SpecialMethodsDemo: def __getitem__(self, key): return f"Accessed with []: {key}" def __call__(self, arg): return f"Called with (): {arg}" def __add__(self, other): return f"Added with +: {other}" demo = SpecialMethodsDemo() print(demo["key"]) # 输出: Accessed with []: key print(demo("arg")) # 输出: Called with (): arg print(demo + 10) # 输出: Added with +: 10这个代码会返回两个值,一个是第一个图像的图像信息,另一个是这个数据集的长度
读取数据
Dataset
torch.utils.data.Dataset
自定义数据集
Dataset主要用于表示数据集,因此需要继承和实现两个关键方法
len():返回数据集的大小
getitem():根据索引返回一个样本
提供一种方式去获取数据及其label
from torch.utils.data import Dataset import cv2 import os class MyData(Dataset): def __init__(self, root_dir, label_dir): """初始化变量""" self.root_dir = root_dir self.label_dir = label_dir self.path = os.path.join(self.root_dir, self.label_dir) # 目录拼接 self.img_path = os.listdir(self.path) # 读取图片名字列表 def __getitem__(self, idx): """读取图片和标签""" img_name = self.img_path[idx] img_item_path = os.path.join(self.path, img_name) # 图片的路径 img = cv2.imread(img_item_path) label = self.label_dir # 标签,用于说明标定的图片是什么 return img, label def __len__(self): """整个数据集的长度""" return len(self.img_path) root_dir = './dataset/train' ants_label_dir = 'ants' bees_label_dir = 'bees' ants_dataset = MyData(root_dir, ants_label_dir) bees_dataset = MyData(root_dir, bees_label_dir)如果需要对应的图片的标签放在另一个文件夹中
ants_label = 'ants_label' for name in ants_dataset.img_path: name = name.split('.jpg')[0] + '.txt' # txt文件名字 with open(os.path.join(root_dir, ants_label, name), 'w', encoding = 'utf-8') as file: file.write(ants_label_dir)
内部数据集
Dataset函数拥有一些内部的数据集
一、图像分类数据集:
MNIST: 手写数字识别,10个类别,灰度图像28x28。
Fashion-MNIST: 10类时尚物品,灰度图像28x28。
CIFAR10: 10类物体,彩色图像32x32。
CIFAR100: 100类物体,彩色图像32x32。
ImageNet: 大规模视觉识别数据集(ILSVRC),1000类,需要申请下载。
STL10: 10类物体,彩色图像96x96,包含无标签数据用于无监督学习。
SVHN: 街景门牌号数字识别,彩色图像32x32。
PhotoTour: 图像匹配数据集,用于训练描述符。
PCAM: 病理图像分类数据集,彩色图像96x96。
Country211: 用于图像地理定位,包含211个国家,每个国家至少100张图像。
二、检测和分割数据集:
VOCDetection: PASCAL VOC目标检测数据集(2007、2012)。
VOCSegmentation: PASCAL VOC分割数据集(2007、2012)。
COCO: Microsoft Common Objects in Context,用于目标检测、分割和字幕生成。
Cityscapes: 城市街景场景理解,用于语义分割和实例分割。
SBD: Semantic Boundaries Dataset,用于语义分割。
KITTIVision: 自动驾驶场景中的多种任务(立体、光流、场景流等)。
三、其他任务数据集:
LSUN: 大规模场景理解数据集,有多种场景分类。
ImageFolder: 通用的图像文件夹数据集,要求每个类别的图像放在一个文件夹中。
DatasetFolder: 通用的文件文件夹数据集,可以处理非图像数据。
Kinetics-400/600/700: 人体动作识别数据集(视频分类)。
UCF101: 动作识别数据集,101类动作。
HMDB51: 动作识别数据集,51类动作。
四、生成模型和自监督学习数据集:
CelebA: 名人脸部属性数据集,常用于生成模型。
CelebA-HQ: 高分辨率CelebA。
LSUN Bedroom, Church等: 特定场景的图像生成。
五、音频数据集(torchaudio):
YESNO: 简单的 yes/no 音频分类。
SPEECHCOMMANDS: 语音命令识别。
LIBRISPEECH: 大词汇量英语语音识别。
COMMONVOICE: Mozilla的多语言语音数据集。
GTZAN: 音乐分类数据集。
六、文本数据集(torchtext):
IMDB: 电影评论情感分类。
AG_NEWS: 新闻分类。
SogouNews: 搜狗新闻分类。
DBpedia: 维基百科条目分类。
YelpReviewPolarity, YelpReviewFull: Yelp评论分类。
AmazonReviewPolarity, AmazonReviewFull: 亚马逊评论分类。
WikiText2, WikiText103: 语言建模数据集。
PennTreebank: 语言建模数据集。
CIFAR10
cifar10 = datasets.CIFAR10(root, train, transform, target_transform, download)
root:需要将数据集下载到的目录,在该目录下会创建一个cifar-10-batches-py,这里面便是下载的数据集
train:bool型,是否使用训练集,当为True时,使用训练集;当为False时,使用测试集
transform:可选,用于对输入图像进行预处理和数据增强,一般可以使用下面的Compose来进行多种处理
target_transform:可选,用于对标签进行预处理,除了独热标签一般不需要使用
download:bool型,是否下载数据集,为True时,下载数据集,一般可能需要较长时间;为False时则是从上面的root目录中加载数据集,速度较快
数据处理
transforms.Compose
该函数用于组合多个图像变换的类
调整大小:transforms.Resize((256, 256))
裁剪:transforms.CenterCrop(224)--中心裁剪到224×224
填充:transforms.Pad(padding=(10, 20), fill = 0)--使用黑色元素左右填充10,上下填充20
将PIL图像转化为张量并自动归一化:transforms.ToTensor()
标准化:transforms.Normalize(
mean=0.485, 0.456, 0.406, # ImageNet的均值
std=0.229, 0.224, 0.225 # ImageNet的标准差 ),
其中均值和标准差的值都是通过torch.mean()和torch.std()求出来的
其中大部分功能可以使用opencv来处理,但是需要一定的转化由于opencv使用的图像为BGR型的,而PIL图像以及张量的转化一般都是RGB型的,因此需要先将图像转化为BGR型
import cv2 import numpy as np from PIL import Image import torchvision.transforms as transforms from torchvision.transforms.functional import to_pil_image # 方法1:使用Lambda包装OpenCV函数 def opencv_to_tensor_transform(image): """将OpenCV处理集成到transform管道""" # 如果输入是PIL图像,先转换为numpy数组 if isinstance(image, Image.Image): # PIL转OpenCV格式 (RGB -> BGR) img_np = np.array(image) img_np = cv2.cvtColor(img_np, cv2.COLOR_RGB2BGR) else: img_np = image # 使用OpenCV处理 # 示例:高斯模糊 img_np = cv2.GaussianBlur(img_np, (5, 5), 0) # 转换回PIL格式 (BGR -> RGB) img_np = cv2.cvtColor(img_np, cv2.COLOR_BGR2RGB) return Image.fromarray(img_np) # 创建包含OpenCV函数的transform管道 transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.Lambda(opencv_to_tensor_transform), # ← 这里使用OpenCV transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ])
Dataloader
add_scalar(tag, scalar_value, global_value, walltime, new_style)
图像分类
这个使用的案例是CIFAR10中的飞机和鸟之间的识别分类
数据预处理
使用上面的Compose函数来对数据集进行预处理
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ])
加载数据集
# 加载数据集 data_path = '../data-unversioned/p1ch7' cifar10 = datasets.CIFAR10(data_path, train = True, download = False, transform = transform) cifar10_val = datasets.CIFAR10(data_path, train = False, download = False, transform = transform)
定义标签和数据
cifar10数据集中的类别对应如下:
0: airplane(飞机)
1: automobile(汽车)
2: bird(鸟)
3: cat(猫)
4: deer(鹿)
5: dog(狗)
6: frog(青蛙)
7: horse(马)
8: ship(船)
9: truck(卡车)
可以看出0是飞机,2是鸟,因此需要重新创建一个标签映射
# 定义标签和数据 label_map = {0:0, 2:1} class_name = {'airplane', 'bird'} # for img, label in cifar10 # if label in [0, 2] # (img, label_map[label]) cifar2 = [(img, label_map[label]) for img, label in cifar10 if label in [0, 2]] cifar2_val = [(img, label_map[label]) for img, label in cifar10_val if label in [0, 2]]
创建模型
激活函数
由于问题是分类的问题,对于神经网络来说,无法直接认定一个图像是什么,我们一般使用一个概率激活函数
因此输出的每个元素必须在0.0\~1.0之间,同时输出元素总和必须为1,由此可以使用softmax函数
该函数pytorch有提供
# 创建模型 n_out = 2 model = nn.Sequential(nn.Linear(3072, 512), nn.Tanh(), nn.Linear(512, n_out), nn.Softmax(dim = 1))
损失函数和优化器
这里使用负似然对数作为损失函数
# 损失函数 loss_fn = nn.NLLLoss() # 优化器 learning_rate = 1e-2 optimtize = optim.SGD(model.parameters(), lr = learning_rate) for epoch in range(100): for img, label in cifar2: img = img.view(-1).unsqueeze(0).to(device) label = torch.tensor([label]).to(device) out = model(img) loss = loss_fn(out, label) optimtize.zero_grad() loss.backward() optimtize.step() print('Epoch:%d, Loss:%f ' % (epoch, float(loss)))
完整代码如下:
import torch from torchvision import datasets from torchvision import transforms import torch.nn as nn import torch.optim as optim # 激活函数 def softmax(x): return torch.exp(x) / torch.exp(x).sum() # 数据预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 加载数据集 data_path = '../data-unversioned/p1ch7' cifar10 = datasets.CIFAR10(data_path, train = True, download = False, transform = transform) cifar10_val = datasets.CIFAR10(data_path, train = False, download = False, transform = transform) # 定义标签和数据 label_map = {0:0, 2:1} class_name = {'airplane', 'bird'} # for img, label in cifar10 # if label in [0, 2] # (img, label_map[label]) cifar2 = [(img, label_map[label]) for img, label in cifar10 if label in [0, 2]] cifar2_val = [(img, label_map[label]) for img, label in cifar10_val if label in [0, 2]] # 创建模型 n_out = 2 model = nn.Sequential(nn.Linear(3072, 512), nn.Tanh(), nn.Linear(512, n_out), nn.LogSoftmax(dim = 1)).to(device) # 损失函数 loss_fn = nn.NLLLoss() # 优化器 learning_rate = 1e-2 optimtize = optim.SGD(model.parameters(), lr = learning_rate) for epoch in range(100): for img, label in cifar2: img = img.view(-1).unsqueeze(0).to(device) label = torch.tensor([label]).to(device) out = model(img) loss = loss_fn(out, label) optimtize.zero_grad() loss.backward() optimtize.step() print('Epoch:%d, Loss:%f ' % (epoch, float(loss)))
批量处理
DataLoader
通过运行上面的代码,即便已经将数据集转化到GPU上运行,但是可以发现其速度仍然非常非常慢,因此GPU可以并行处理,但是上述的代码相当与一次只给一张图片,导致GPU大部分的时间都在空转,同时还有两个原因导致,一是to(device)本身便会花费时间,二是for循环也十分的浪费时间
由此我们也可以想到的处理便是使GPU的空间充分运行,即批量处理一组数据
在训练代码中,我们选择大小为1的小批量(一个固定的大小,需要我们在训练之前设置,就像学习率一样,这些数据被称之为超参数),即每次从数据集中选择一项pytorch提供了这样一个函数,它和上述所讲的Dataset有着密不可分的关系,就是DataLoader(torch.utils.data.DataLoader),该类有助于打乱数据和组织数据
Dataset和DataLoader的区别
总的来说Dataset负责"存储和索引",DataLoader负责"运输和打包"。简单点来说,Dataset就是一个数据集(无论是你定义的还是pytorch内部的数据集),它可以储存数据集或者使用索引找到一些你想要的特定的数据;而DataLoader则将Dataset这个数据集包装起来,提供一些高级功能。
DataLoader的功能
上面我们说了DataLoader会提供一些高级功能,接下来我们来详细说一下
自动批处理--最基础也最重要的功能
这个功能是显而易见的,也是我们之所以提出DataLoader这个类的根本原因
自动打乱数据
在模型训练时,如果数据顺序永远固定(比如先全是猫,再全是狗),模型会"死记硬背"顺序,而不是学习特征,导致训练效果极差。因此需要生成一个索引列表 0, 1, 2...N,每次 Epoch开始前调用 `random.shuffle()` 打乱它,然后根据乱序的索引去取数据。而DataLoader直接调取参数即可(DataLoader(..., shuffle=True))
多进程并发加载--性能提升的关键
读取硬盘上的图片和进行预处理是非常慢的CPU操作。如果是单进程:GPU算完一批,停下来等CPU读下一批;CPU读的时候,GPU在等待。这是巨大的资源浪费。但是DataLoader可以在后台启动多个"工人"(Worker)进程,CPU提前帮GPU把下一批、下下批数据准备好放在内存里(DataLoader(..., num_workers=4))
锁页内存
数据通常在CPU内存里,模型在GPU显存里。数据传输需要通过 PCI-e 总线。如果内存是"分页"的,传输速度会受限。而DataLoader会把数据放在CPU的"锁页内存区",这种内存直接拷贝到 GPU 的速度非常快(DataLoader(..., pin_memory=True))
torch.utils.data.DataLoader
class DataLoader(
dataset: Dataset_T_co,
batch_size: Optionalint = 1,
shuffle: Optionalbool = None,
sampler: UnionSampler, Iterable, None = None,
batch_sampler: UnionSampler\[list, Iterablelist, None] = None,
num_workers: int = 0,
collate_fn: Optional_collate_fn_t = None,
pin_memory: bool = False,
drop_last: bool = False,
timeout: float = 0,
prefetch_factor: Optionalint = None,
persistent_workers: bool = False,
in_order: bool = True)
dataset:用于加载数据的数据集
batch_size:可选,每批加载的样本数量
shuffle:可选,每个周期是否重新洗牌数据,当为True时,每个周期都会重新洗牌数据
sampler:可选,每个周期从数据集中抽取数据的方法
batch_sampler:可选,与sampler类似,但是每次会返回一批索引
num_workers:可选,用于数据加载的子进程数量
collate_fn:可选,将样本列表合并为一个张量小批量
pin_memory:可选,数据加载器是否在返回张量之前将其复制到设备/CUDA 锁定内存中
drop_last:可选,设为True时,如果数据集大小不能被批次大小整除,则丢弃最后一个不完整的批次。如果为False且数据集大小不能被批次大小整除,则最后一个批次会更小。
timeout:可选,如果为正数,则为从工作进程收集批次的超时值。其值应始终为非负数
prefetch_factor:可选,每个工作进程提前获取的数量。'2' 表示所有工作进程总共会提前获取 2 * num_workers 个批次。(默认值取决于num_workers的设置值。如果num_workers = 0,默认值为 ``None``。否则,如果num_workers > 0,默认值为'2')
persistent_workers:可选,数据加载器是否在数据集被处理一次后关闭工作进程,当为True时则会关闭工作进程
in_order:可选,数据加载器是否按照批次先进先出的顺序返回,仅在'num_workers > 0'时适用
对于dataset来说,只要其能被索引(实现 getitem)同时有长度(实现 len)则可以作为传入DataLoader的数据集shuffle,sampler,batch_sampler和drop_last这四个参数相互冲突,有定义了其中一个参数,则不能再定义另外三个参数
使用
针对于上面的例子,使用DataLoader来批量处理数据,实现代码如下
cifar2 = [(img, label_map[label]) for img, label in cifar10 if label in [0, 2]] cifar2_val = [(img, label_map[label]) for img, label in cifar10_val if label in [0, 2]] train_loader = torch.utils.data.DataLoader(cifar2, batch_size = 64, shuffle = True, num_workers = 2, pin_memory = True) val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size = 64, shuffle = True, num_workers = 2, pin_memory = True)train_loader每次加载64张图像,同时打乱标签顺序避免模型的死记硬背,同时使用两个进程同时运行,并将返回的张量放入CUDA中
整体代码如下
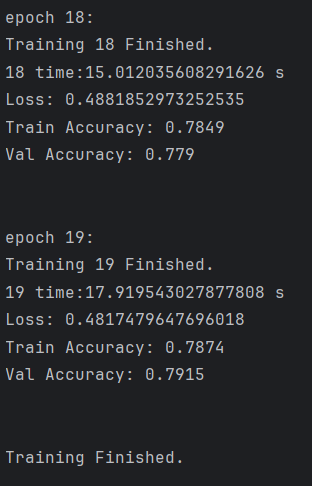
import torch from torchvision import datasets from torchvision import transforms import torch.nn as nn import torch.optim as optim import time if __name__ == '__main__': # 数据预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 加载数据集 data_path = '../data-unversioned/p1ch7' cifar10 = datasets.CIFAR10(data_path, train = True, download = False, transform = transform) cifar10_val = datasets.CIFAR10(data_path, train = False, download = False, transform = transform) print(f'数据集加载成功') # 定义标签和数据 label_map = {0:0, 2:1} class_name = {'airplane', 'bird'} # for img, label in cifar10 # if label in [0, 2] # (img, label_map[label]) cifar2 = [(img, label_map[label]) for img, label in cifar10 if label in [0, 2]] cifar2_val = [(img, label_map[label]) for img, label in cifar10_val if label in [0, 2]] train_loader = torch.utils.data.DataLoader(cifar2, batch_size = 256, shuffle = True, num_workers = 2, pin_memory = True) val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size = 256, shuffle = True, num_workers = 2, pin_memory = True) print(f'数据集预处理完毕') # 创建模型 n_out = 2 model = nn.Sequential(nn.Flatten(),nn.Linear(3072, 1024), nn.Tanh(), nn.Linear(1024, 512), nn.Tanh(), nn.Linear(512, 128), nn.Tanh(), nn.Linear(128, n_out)).to(device) print(f'模型创建完毕') # 损失函数 loss_fn = nn.CrossEntropyLoss() print(f'损失函数创建完毕') # 优化器 learning_rate = 1e-2 optimtize = optim.Adam(model.parameters(), lr = learning_rate) print(f'优化器创建完毕') print(f'开始训练') for epoch in range(20): print(f'epoch {epoch}:') start_time = time.time() # ----训练阶段---- model.train() running_loss = 0.0 train_correct = 0 train_total = 0 for img, label in train_loader: img = img.to(device) label = label.to(device) out = model(img) loss = loss_fn(out, label) optimtize.zero_grad() loss.backward() optimtize.step() running_loss += loss.item() _, predicted = torch.max(out, dim=1) train_total += label.shape[0] train_correct += int((predicted == label).sum()) # ----验证阶段---- model.eval() val_correct = 0 val_total = 0 with torch.no_grad(): for img, label in val_loader: img = img.to(device) label = label.to(device) out_put = model(img) _, predicted = torch.max(out_put, dim = 1) val_total += label.shape[0] val_correct += int((predicted == label).sum()) end_time = time.time() avg_loss = running_loss / len(train_loader) print(f'Training {epoch} Finished.') print(f'{epoch} time:{end_time - start_time} s') print(f'Loss: {avg_loss}') print(f'Train Accuracy: {train_correct / train_total}') print(f'Val Accuracy: {val_correct / val_total}') print('\n') print('Training Finished.')得出结果来
能够看出这对于一个简单的二分类来说,瞎猜都有0.5的正确率,因此训练集和验证集都是0.8的正确率是远远不够的,但是无论我们怎么改变损失函数或优化器,或者将模型更加的细分,也无法使模型变得完美,最多是训练集的准确率有所提高,这是因为模型也就是我们所用的全连接神经网络是由局限性的,无论怎么处理都无法使模型准确率提升的更大
因此我们需要更换一个更好的模型,也就是CNN神经网络,也是目前最为流行的图像处理的神经网络,特别是其中的改进版残差神经网络更是目前来说最为前沿的,工业界最常用的神经网络架构。当前最近还有一个较火的技术ViT也可以很好的应用于图像处理。
同时在提出残差神经网络后也就不得不提出专门用于图像处理的库--YOLO,YOLO的骨干网络本质是卷积神经网络结构,其核心操作(卷积层、池化层、激活函数等)完全继承自基础 CNN。