1. epoll初识
核心定位:epoll 是一种基于多个 fd 的就绪事件通知机制,通过监控这些 fd 上的事件(如可读、可写),在事件就绪时通知应用程序,从而避免阻塞等待。这与 select 和 poll 的目标一致,但设计更高效。
历史背景:epoll 是在 Linux 内核 2.5.44 版本中引入的,按照 man 手册的说法,它是为处理大批量句柄(fd)而改进的 poll,旨在解决传统方法在高并发场景下的局限性。
性能优势:epoll 几乎具备了之前多路 I/O 方法的所有优点,被公认为 Linux 2.6 下性能最好的多路 I/O 就绪通知方法。相比之下,poll 随着 fd 数量的增多,效率会逐渐降低,而 epoll 通过内部优化(如使用事件驱动和回调机制)避免了这一问题,能够高效处理成千上万的并发连接。
实现与使用:epoll 的实现原理、接口使用与 select 和 poll 差别非常大。它通过 epoll_create、epoll_ctl 和 epoll_wait 等系统调用,实现了更灵活的事件注册和触发机制,减少了遍历所有 fd 的开销,从而提升了性能。
2. epoll的相关系统调用
2.1 epoll_create
epoll_create 函数用于创建一个 epoll 模型,其原型为:
cpp
int epoll_create(int size);epoll_create 是创建 epoll 实例的核心函数。它返回一个 epoll 文件描述符,后续所有对 epoll 的操作都通过这个描述符进行。虽然参数 size 在早期版本中用于提示内核分配内存大小,但在现代 Linux 内核中,该参数已被忽略,内核会动态调整内部数据结构的大小。因此,通常传入 1 或任意正整数即可。
2.2 epoll_ctl
epoll_ctl 函数用于控制 epoll 文件描述符,其原型为:
cpp
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);其中:
- epfd 是由
epoll_create返回的 epoll 文件描述符; - op 操作类型包括:
EPOLL_CTL_ADD:首次注册一个文件描述符到 epoll 实例中,同时指定关心的事件(如 EPOLLIN)。EPOLL_CTL_MOD:修改已注册文件描述符的监听事件,例如从只读改为可读可写。EPOLL_CTL_DEL:从 epoll 实例中移除某个文件描述符,不再监听其事件,此时 event参数可忽略。
- fd 是要操作的文件描述符;
- `event 是指向 struct epoll_event 结构体的指针,用于指定关注的事件。
结构体定义如下:
cpp
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};事件标志位包括:
- EPOLLIN:表示对应的文件描述符可以读 (包括对端SOCKET正常关闭);
- EPOLLOUT:表示对应的文件描述符可以写;
- EPOLLPRI:表示对应的文件描述符有紧急的数据可读 (这里应该表示有带外数据到来);
- EPOLLERR:表示对应的文件描述符发生错误;
- EPOLLHUP:表示对应的文件描述符被挂断;
- EPOLLET:将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered) 来说的.
- EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话, 需要再次把这个socket加入到EPOLL红黑树里.
struct epoll_event 中:
events字段是一个位掩码,表示关心的事件集合(如EPOLLIN | EPOLLET);data字段是用户自定义数据,可用于存储与文件描述符关联的上下文信息(如 socket 对应的客户端地址等),内核不会修改该字段。
`epoll_ctl 是管理 epoll 监听事件的核心接口。通过它,用户可以向 epoll 实例添加、修改或删除需要监听的文件描述符及其事件。
交互逻辑 :用户通过此调用告诉内核 :"请帮我关心 fd上发生的 events事件"。
2.3 epoll_wait
epoll_wait 函数用于等待 I/O 事件,其原型为:
cpp
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);其中:
epfd必须是由 epoll_create 创建的有效描述符;events数组长度由 maxevents 限制,实际返回值不会超过该值;maxevents是 events 数组的最大长度,必须大于0;timeout控制等待时间,单位为毫秒,支持非阻塞(0)和无限阻塞(-1);- 返回值:
- 正数:就绪事件数量,并将对应的事件信息填充到 events 数组中。;
- >0:超时无事件;
- 负数:出错(如 errno 设置)。
`epoll_wait 是阻塞等待事件发生的函数,当有文件描述符就绪时,内核会将就绪事件填充到用户提供的 events 数组中,并返回就绪事件的数量。
交互逻辑 :内核通过此调用通知用户:"你让我关心的那些 fd 中,events数组里这些已经就绪了"。
3. epoll的原理
epoll 的核心原理是通过在内核中维护一个高效的数据结构(红黑树+就绪队列),实现事件从"用户注册"到"内核通知"的 O(1) 时间复杂度管理,从而解决了 select/poll 线性扫描的性能瓶颈。
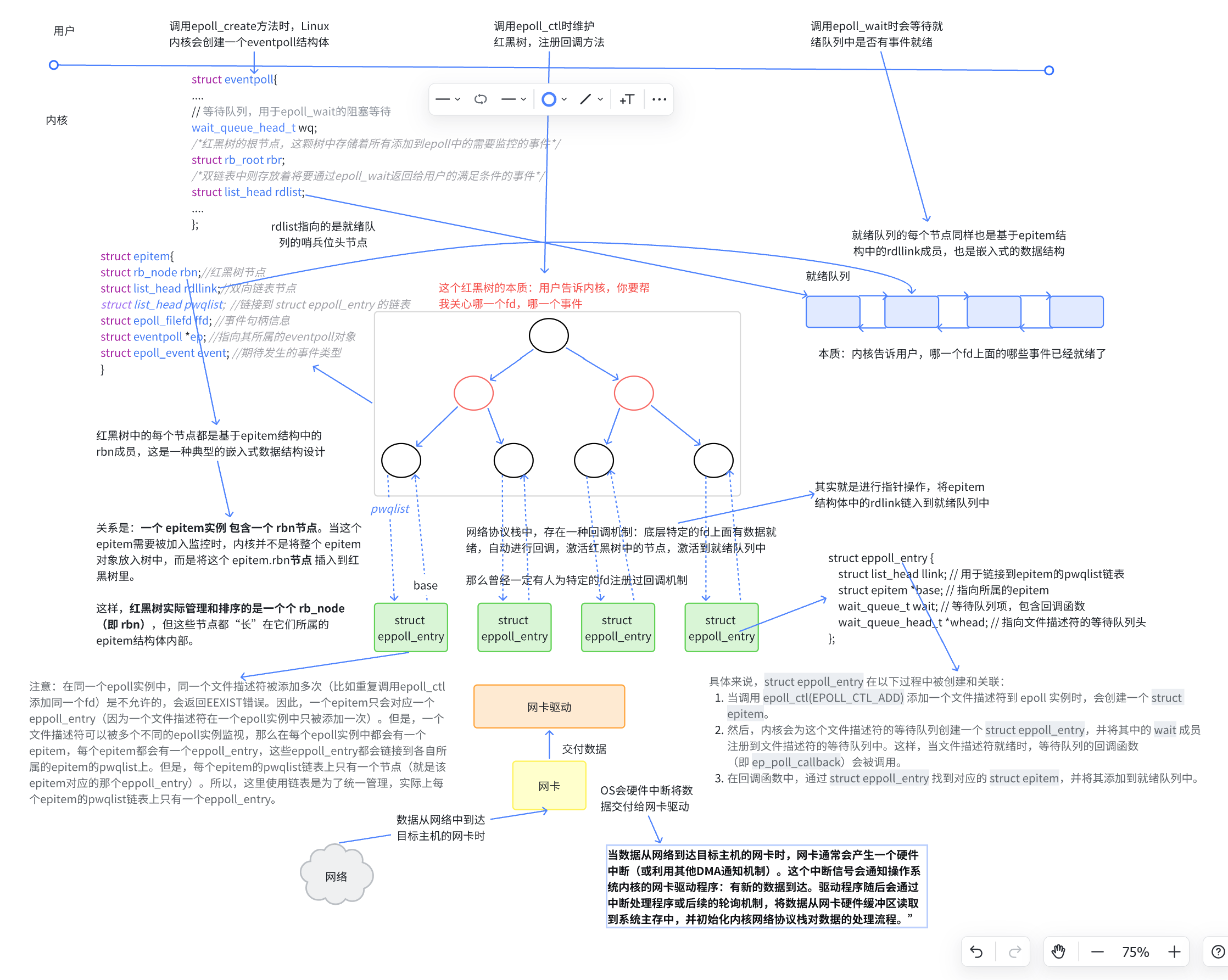
用户告诉内核关心什么 :通过 epoll_ctl将需要监控的 文件描述符 (fd) 和其对应的事件 注册到内核。内核将此信息存储在一棵红黑树 中,键就是 fd。
内核告诉用户什么就绪了 :当某个 fd上的事件就绪(如数据到达),内核会通过图中的回调机制 ,将该事件对应的节点放入一个就绪队列 。用户调用 epoll_wait时,内核只需直接检查并返回这个队列的内容即可,无需遍历所有监控的fd。这使得"检测是否有fd就绪"的时间复杂度为 O(1)。
我们分别来看这三个系统调用在内核中的主要动作。
1. epoll_create
当用户调用epoll_create (或epoll_create)时,内核会创建一个eventpoll结构体,并返回一个文件描述符,这个文件描述符对应的是eventpoll实例。
主要步骤:
- 分配并初始化 struct eventpoll `:
- 分配一个
struct eventpoll对象,并初始化其中的成员,如等待队列(wq)、就绪链表(rdllist)、红黑树根(rbr)等。 - 初始化自旋锁和互斥锁,用于保护
eventpoll的访问。
- 分配一个
- 创建一个匿名文件 :
- 内核会创建一个新的匿名文件,并分配一个文件描述符。这个文件对应的
file_operations是eventpoll_fops,即该文件的操作集合(如poll、release等)都是由epoll模块提供的。 - 将
eventpoll实例的指针存储在匿名文件的private_data字段中,这样通过文件描述符就可以找到对应的eventpoll实例。
- 内核会创建一个新的匿名文件,并分配一个文件描述符。这个文件对应的
- 返回文件描述符 :
- 将文件描述符返回给用户。这个文件描述符就是epoll实例的句柄,后续的
epoll_ctl和epoll_wait都会使用它。
- 将文件描述符返回给用户。这个文件描述符就是epoll实例的句柄,后续的
注意:epoll_create 的参数 size 在较新的内核中已经被忽略,但必须大于0。
2. epoll_ctl
epoll_ctl用于向epoll实例中添加、修改或删除被监视的文件描述符。这里以添加(EPOLL_CTL_ADD)为例:
主要步骤:
- 根据文件描述符找到对应的
struct file:- 通过用户传递的epoll文件描述符,找到对应的
eventpoll实例(即struct eventpoll)。 - 通过用户传递的目标文件描述符,找到对应的
struct file。
- 通过用户传递的epoll文件描述符,找到对应的
- 检查是否已经添加 :
- 在
eventpoll的红黑树中查找是否已经存在该文件描述符对应的epitem。如果已经存在,则返回错误(EEXIST)。
- 在
- 创建并初始化
struct epitem:- 分配一个
struct epitem,并初始化其成员,包括设置要监视的文件描述符、事件掩码(用户传递的struct epoll_event)等。 - 将
epitem的ep指针指向eventpoll实例。
- 分配一个
- 设置回调函数 :
- 调用目标文件描述符的
poll操作(即调用file->f_op->poll),并将一个回调函数(ep_ptable_queue_proc)传递给poll操作。这个回调函数会在文件描述符有事件发生时被调用。 - 在回调函数中,内核会创建一个
eppoll_entry,将其添加到文件描述符的等待队列中,并设置回调函数为ep_poll_callback。
- 调用目标文件描述符的
- 将
epitem插入红黑树 :- 将新创建的
epitem插入到eventpoll的红黑树中,以便后续快速查找。
- 将新创建的
- 如果当前文件描述符已经有事件就绪,将其添加到就绪链表 :
- 在调用
poll操作后,如果文件描述符已经有事件就绪,那么回调函数ep_poll_callback会被调用,将epitem添加到就绪链表(rdllist)中,并唤醒等待在epoll_wait上的进程。
- 在调用
注意:修改(EPOLL_CTL_MOD)和删除(EPOLL_CTL_DEL)操作类似,但修改会更新事件掩码,删除则会从红黑树中移除epitem,并清理相关的等待队列项。
3. epoll_wait
epoll_wait用于等待在epoll实例上注册的文件描述符有事件发生。
主要步骤:
- 根据文件描述符找到
eventpoll实例 :- 通过用户传递的epoll文件描述符,找到对应的
struct eventpoll。
- 通过用户传递的epoll文件描述符,找到对应的
- 检查就绪链表 :
- 如果就绪链表(
rdllist)不为空,则说明已经有文件描述符就绪,直接处理就绪事件。 - 如果就绪链表为空,且用户设置的超时时间不为0,则当前进程需要等待。
- 如果就绪链表(
- 等待事件发生 :
- 将当前进程加入到
eventpoll的等待队列(wq)中,然后让出CPU进入睡眠状态。 - 当有事件发生时(例如,某个被监视的文件描述符可读或可写),回调函数
ep_poll_callback会被调用,它会将对应的epitem添加到就绪链表,并唤醒等待队列(wq)中的进程。
- 将当前进程加入到
- 收集就绪事件 :
- 进程被唤醒后,将就绪链表中的
epitem取出,遍历这些epitem,将发生的事件复制到用户空间。 - 在复制过程中,会根据用户传递的
maxevents参数来控制最多返回多少个事件。
- 进程被唤醒后,将就绪链表中的
- 返回就绪事件的数量 :
- 返回给用户就绪事件的数量,并更新用户传递的
events数组。
- 返回给用户就绪事件的数量,并更新用户传递的
注意:epoll_wait可以设置超时时间,如果超时时间设置为0,则立即返回,即使没有事件就绪;如果设置为-1,则无限等待直到有事件发生。
总结
epoll_create:创建eventpoll实例和对应的文件描述符。epoll_ctl:向eventpoll实例中添加、修改或删除被监视的文件描述符,并设置回调函数。epoll_wait:等待被监视的文件描述符有事件发生,并返回就绪的事件。
高效的管理结构:红黑树与就绪队列
内核为每个epoll实例维护一个eventpoll结构体。其中的红黑树(rbr) 负责管理所有被监控的文件描述符(fd),这使得对fd的增、删、改操作的时间复杂度都是O(log n),非常适合管理大量连接。就绪链表(rdllist) 则是一个双向链表,专门存放有事件发生的fd。当epoll_wait调用时,内核无需遍历所有监控的fd,只需检查这个链表是否为空即可,这使检测就绪事件的时间复杂度是O(1)。
事件就绪的回调(Callback)机制
这是epoll高效的关键。通过epoll_ctl注册监听事件时,内核会通过ep_ptable_queue_proc函数在目标文件(如socket)的等待队列上添加一个表项eppoll_entry,并设置其回调函数为ep_poll_callback。当网络数据到达,导致socket状态变化时,内核协议栈就会调用这个回调函数。该回调函数的核心工作就是将对应的epitem快速添加到就绪队列rdllist中,并唤醒等待在epoll_wait上的进程。这是一种"中断"式通知,避免了像select/poll那样需要主动轮询所有fd。
怎么看待就绪队列??
就绪队列是 epoll 机制中的核心数据结构之一,用于存储当前已经就绪(可读、可写或有异常)的文件描述符(fd)事件。从图中可以看出,epoll 的本质是一个基于事件就绪的"生产者-消费者"模型:
- 生产者 :内核在检测到某个 fd 上有数据到达、连接建立、写缓冲区空闲等事件时,会将该 fd 对应的 struct epitem 节点插入到就绪队列(
wait_queue_head_t wq)中。 - 消费者 :用户态调用
epoll_wait时,会从就绪队列中取出所有已就绪的事件,返回给应用程序处理。
就绪队列的本质是一个链表结构,由 struct epitem 组成,每个节点包含:
int fd------ 对应的文件描述符uint32_t events------ 注册的事件类型(如 EPOLLIN)list head link------ 链入就绪队列的指针rb_node left; rb_node right------ 红黑树节点,用于在 epoll 的红黑树中定位该 fd
注意:以上这些节点包含的成员是为了便于理解简化的,实际要复杂一点
epoll 的本质不是基于轮询的,而是生产者-消费者模型! 这意味着:
- 内核主动将就绪事件推送到就绪队列(生产)
- 用户程序通过 epoll_wait 主动拉取事件(消费)
此外,就绪队列是线程安全的,因为其访问受到 rwlock_t lock 保护,避免多线程竞争。
获取就绪事件,如果缓冲区大小不够了怎么办??
当调用 epoll_wait 时,如果用户提供的 events 缓冲区大小不足以容纳所有就绪事件,会发生以下情况:
- 不会阻塞或失败 ,而是只返回能容纳的事件数量
- 剩余未返回的事件会 保留在就绪队列中,不会丢失。
- 下一次调用 epoll_wait 时,这些事件仍会被返回(即默认给你保留着,下次拿
这体现了 epoll 的非丢弃式事件通知机制 ,确保了事件的完整性。应用层,处理就绪事件的时候,处理的全都是就绪的,根本不需要非法检测!
从实现角度看,epoll_wait 函数内部会遍历就绪队列,逐个填充 events 数组,直到填满或队列为空。如果缓冲区不足,函数返回实际填充的数量,并保留剩余事件供下次使用。
因此,解决方案是:增大 maxevents 参数,或者分批调用 epoll_wait`,以确保所有事件都能被处理。
4. epoll demo代码
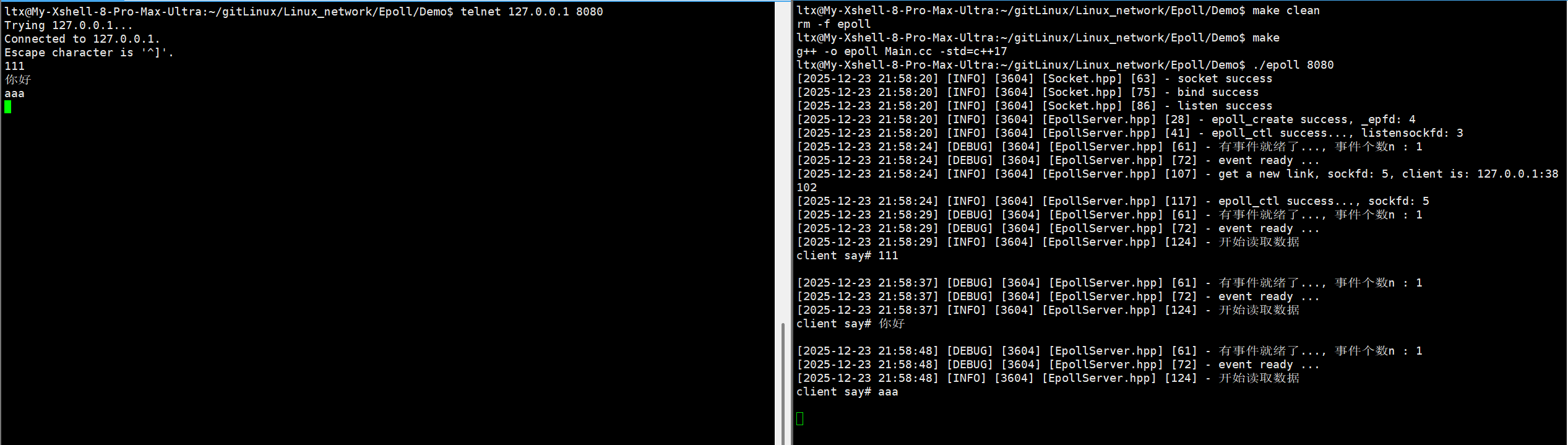
为了先了解一下怎么使用epoll和相关函数的用法以及代码怎么写,我们这里demo代码和之前的select和poll一样,实现一个EchoServer,而且只处理读事件
cpp
#pragma once
#include <iostream>
#include <memory>
#include <sys/epoll.h>
#include <unistd.h>
#include "Socket.hpp"
using namespace SocketModule;
using namespace LogModule;
class EpollServer
{
const static int size = 64;
const static int defaultfd = -1;
public:
EpollServer(int port) : _listensock(std::make_unique<TcpSocket>()), _isrunning(false), _epfd(defaultfd)
{
_listensock->BuildTcpSocketMethod(port);
// 创建epoll模型
_epfd = epoll_create(256);
if (_epfd < 0)
{
LOG(LogLevel::FATAL) << "epoll_create error...";
exit(EPOLL_CREATE_ERR);
}
LOG(LogLevel::INFO) << "epoll_create success, _epfd: " << _epfd;
// 将listensocket设置到内核中!
struct epoll_event ev; // 此时还没有设置到内核中,也没有在rb_tree中新增节点
ev.events = EPOLLIN;
ev.data.fd = _listensock->Fd(); // 这里未来是维护的是用户的数据,常见的是fd
int n = epoll_ctl(_epfd, EPOLL_CTL_ADD, _listensock->Fd(), &ev);
if (n < 0)
{
LOG(LogLevel::FATAL) << "epoll_ctl error...";
exit(EPOLL_CTL_ERR);
}
LOG(LogLevel::INFO) << "epoll_ctl success..., listensockfd: " << _listensock->Fd();
}
void Start()
{
int timeout = -1;
_isrunning = true;
while (_isrunning)
{
int n = epoll_wait(_epfd, _revs, size, timeout);
switch (n)
{
case -1:
LOG(LogLevel::ERROR) << "epoll_wait error ...";
break;
case 0:
LOG(LogLevel::INFO) << "time out ...";
break;
default:
// 有事件就绪, 就不仅仅是新连接到来, 还有可能是读事件就绪
LOG(LogLevel::DEBUG) << "有事件就绪了..., 事件个数n : " << n;
Dispatcher(n); // 处理就绪的事件
break;
}
}
_isrunning = false;
}
// 事件派发器
void Dispatcher(int rnum)
{
LOG(LogLevel::DEBUG) << "event ready ..."; // LT: 水平触发模式--epoll默认
// 有事件就绪, 不仅仅是新连接到来, 还有可能是读事件就绪
for (int i = 0; i < rnum; i++)
{
int sockfd = _revs[i].data.fd;
uint32_t revent = _revs[i].events;
if (revent & EPOLLIN)
{
// 此时事件就绪,是新连接到来,还是读事件就绪?
if (sockfd == _listensock->Fd())
{
// 如果是监听套接字就绪,那就是新连接到来
Accepter();
}
else
{
// 读事件就绪
Recver(sockfd);
}
}
}
}
// 连接管理器
void Accepter()
{
// 新连接到来,我们需要accept接受新连接
InetAddr client;
int sockfd = _listensock->Accept(&client);
if (sockfd >= 0)
{
// 获取新链接到来成功, 然后呢??能不能直接read/recv()
// 当然不行,sockfd是否读就绪,我们不清楚
// 只有谁最清楚,未来sockfd上是否有事件就绪?肯定是epoll!
// 所以我们需要将新的sockfd,托管给epoll!
LOG(LogLevel::INFO) << "get a new link, sockfd: " << sockfd << ", client is: " << client.StringAddr();
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = sockfd;
int n = epoll_ctl(_epfd, EPOLL_CTL_ADD, sockfd, &ev);
if (n < 0)
{
LOG(LogLevel::FATAL) << "epoll_ctl error...";
}
else
LOG(LogLevel::INFO) << "epoll_ctl success..., sockfd: " << sockfd;
}
}
// IO处理器
void Recver(int sockfd)
{
LOG(LogLevel::INFO) << "开始读取数据";
// 处理 sockfd 读事件
// 我们在这里读取的时候,就不会阻塞了 --- 因为 epoll 已经完成等操作了!
char buffer[1024];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
// recv 读的时候会有bug!因为无法保证能够读取到一个完整的请求!--- TCP 是流式协议!
// 我们目前先不做处理,等到后面的时候,再做处理!
if (n > 0)
{
buffer[n] = 0;
std::cout << "client say# " << buffer << std::endl;
}
else if (n == 0)
{
LOG(LogLevel::INFO) << "client quit ...";
// 此时不再需要让epoll帮我们再关心fd
// 从epoll中移除fd的关心 && 关闭fd -- 细节:epoll_ctl: 只能移除合法fd -- 先移除,在关闭!!
int m = epoll_ctl(_epfd, EPOLL_CTL_DEL, sockfd, nullptr);//删除不需要再关心任何事件直接填空指针
if(m > 0)
{
LOG(LogLevel::INFO) << "epoll_ctl remove sockfd success: " << sockfd;
}
close(sockfd);
}
else
{
LOG(LogLevel::ERROR) << "recv error ...";
// 此时不再需要让epoll帮我们再关心fd
// 从epoll中移除fd的关心 && 关闭fd -- 细节:epoll_ctl: 只能移除合法fd -- 先移除,在关闭!!
int m = epoll_ctl(_epfd, EPOLL_CTL_DEL, sockfd, nullptr);//删除不需要再关心任何事件直接填空指针
if(m > 0)
{
LOG(LogLevel::INFO) << "epoll_ctl remove sockfd success: " << sockfd;
}
close(sockfd);
}
}
~EpollServer() {}
private:
std::unique_ptr<Socket> _listensock;
bool _isrunning;
int _epfd;
struct epoll_event _revs[size];
};运行结果:
5. epoll的优点(和 select 的缺点对应)
1. 接口设计更高效
接口使用方便,这体现在 epoll将功能拆分为三个独立的系统调用:
epoll_create: 创建 epoll 实例,初始化内核数据结构。epoll_ctl: 负责注册、修改或删除需要监控的文件描述符(fd)及其事件。这是一个增量操作,只需在连接建立或关闭时调用。epoll_wait: 专责等待事件发生,并将就绪事件返回给用户。
这种设计将"管理监控列表"和"等待事件"解耦 。相比之下,select/poll每次调用时,都需要从用户态向内核态传递一个完整的 fd 集合,告诉内核"这次要监控这些",参数既作为输入也作为输出,每次调用前都必须重新初始化,非常繁琐且低效。
2. 数据拷贝开销小
select/poll的瓶颈 : 每次调用 select或 poll,都需要将整个需要监控的 fd 集合从用户空间全量拷贝到内核空间。当监控数千个 fd 时,这种频繁的内存拷贝会成为巨大的性能开销。
epoll的优化 : 在通过 epoll_ctl添加一个 fd 时,会将其信息永久地 拷贝到内核中一次。之后,在事件循环中调用 epoll_wait时,不再需要传递整个 fd 集合 ,内核已经保存了这份列表。这使得 epoll_wait的参数非常轻便,极大地减少了用户态和内核态之间不必要的数据拷贝。
3. 事件检测:O(1) 复杂度 vs. O(n) 复杂度
**select**/ **poll**的轮询 : 无论 fd 是否就绪,select/poll在内核中都需要线性扫描(遍历) 整个传入的 fd 集合,检查每个 fd 的状态。算法时间复杂度是 O(n),其中 n 是监控的 fd 总数。当 n 很大但活跃连接很少时,效率极低。
epoll的回调机制
- 注册回调 : 在通过
epoll_ctl添加 fd 时,内核会为其注册一个回调函数。 - 事件就绪 : 当某个 fd 上的数据就绪时(例如,网络数据到达),设备驱动会触发中断,内核网络栈处理数据后,会调用该 fd 对应的回调函数。
- 加入就绪队列 : 这个回调函数的工作很简单:将对应的 fd 添加到一个内核维护的就绪链表中。
- 高效返回 :
epoll_wait被调用时,内核只需检查这个就绪链表是否为空。如果不为空,就将链表中的项目复制到用户空间。这个过程的复杂度是 O(1),因为它只与就绪的 fd 数量相关,而与监控的 fd 总数无关。
简单来说,epoll是"事件驱动"的,只有活跃的 fd 才会主动通知内核;而 select/poll是"主动轮询"的,需要一次次地问所有 fd:"你们准备好了吗?"
4. 支持的文件描述符数量无硬性限制
select的硬伤 : 受限于 FD_SETSIZE的默认值(通常为 1024),一个进程能监控的 fd 数量有严格上限。虽然可以修改并重新编译内核,但会带来其他问题。
poll的改进: 使用链表存储,理论上无数量限制。
epoll的优势 : 和 poll一样,没有数量上的硬性限制。其能监控的 fd 上限取决于系统所能打开的最大文件描述符数量(可通过 /proc/sys/fs/file-max查看),通常远高于 1024,足以应对高并发场景
关于"内存映射(mmap)"的澄清
网上流传的"epoll通过 mmap在用户态和内核态共享就绪队列,实现零拷贝"的说法是不准确甚至是错误的。
实际情况是:
- 存在数据拷贝 : 当
epoll_wait返回时,内核确实需要将就绪事件的数据 (即struct epoll_event数组)从内核空间拷贝到你在用户空间预先分配好的数组中。 - 优势所在 :
epoll的优势并不在于"零拷贝",而在于我们前面阐述的:1)只在epoll_ctl(ADD)时的一次 fd 信息拷贝;2)epoll_wait返回时只拷贝就绪事件,而非全量 fd 集合。
各方案优缺点详解
select:经典但受限
select 的最大优势在于其出色的跨平台支持 ,几乎在所有主流操作系统上都能使用。此外,它提供的超时精度可以达到微秒级 。然而,它的缺点也非常突出:单个进程能监控的文件描述符数量有严格限制(通常为1024) ;每次调用都需要在用户态和内核态之间完整拷贝fd集合 ,并且内核和应用程序都需要线性扫描所有fd,这在连接数增多时性能损耗很大。其接口设计也较为繁琐,需要多次设置fd集合。
poll:改进的select
poll 对 select 的主要改进在于取消了监控fd数量的上限 ,改用了链表结构。同时,它将文件描述符和事件绑定在一起 ,通过 events和 revents分离输入输出参数,接口设计更合理,无需每次调用前重置监控集合。但是,poll 依然没有解决select的根本性能问题 :每次调用仍需整体拷贝fd结构,并且内核仍然需要轮询所有fd来判断就绪状态,性能随fd数量增加线性下降的问题依旧存在。
epoll:Linux下的高性能之选
epoll 是 Linux 为处理大规模并发连接而设计的高性能方案。其核心优势在于事件驱动(回调)机制 ,内核只在fd就绪时通过回调函数通知应用程序,使得检测就绪fd的时间复杂度为 O(1)。它通过 epoll_ctl进行fd的一次性注册 ,避免了每次调用的巨大拷贝开销。此外,它支持更高效的边缘触发(ET)模式 ,可以减少相同事件被重复触发的次数。当然,epoll 的主要缺点是缺乏跨平台性,通常只能在 Linux 系统上使用。它的编程模型,尤其是ET模式,需要设置非阻塞I/O并循环读写直到结束,比select/poll更复杂一些。
如何选择
了解了它们的特性后,你可以根据具体场景做出选择:
选择 select :通常仅在对跨平台性有严格要求 ,或需要微秒级超时控制 ,且监控的连接数非常少的场景下考虑。
选择 poll :当需要监控的连接数超过1024,但又不具备使用epoll的条件(如非Linux平台),且连接数尚未达到需要事件驱动模型的程度时,可作为select的替代方案。
选择 epoll :这是构建高性能Linux网络服务器 的首选 。尤其适用于处理大量并发连接 ,但其中只有小部分是活跃连接的场景(例如Web服务器、即时通讯网关等)。在连接非常活跃的情况下,epoll的回调开销可能使其优势不明显,甚至性能略低于poll。
6. epoll的工作方式
问题:如果事件就绪但未处理,epoll 会一直通知吗?为什么?
答案:取决于工作模式。
- 在 LT(水平触发)模式下:会一直通知。
- 原因:只要文件描述符处于就绪状态(如可读、可写),epoll_wait 就会持续返回该事件,直到你处理它(例如读取数据)。
- 适用于初学者或对可靠性要求高的场景。
- 在 ET(边缘触发)模式下:不会重复通知。
- 原因:只在状态变化时通知一次(从非就绪 → 就绪)。如果未处理完数据,下次状态不变时不会再次通知。
- 要求用户必须一次性读取或写完所有数据,否则可能遗漏事件。
- 适用于高性能场景,减少系统调用次数。
📌因此,"epoll 会一直通知我们"的说法,仅适用于 LT 模式。
问题:如何理解水平和边缘触发?
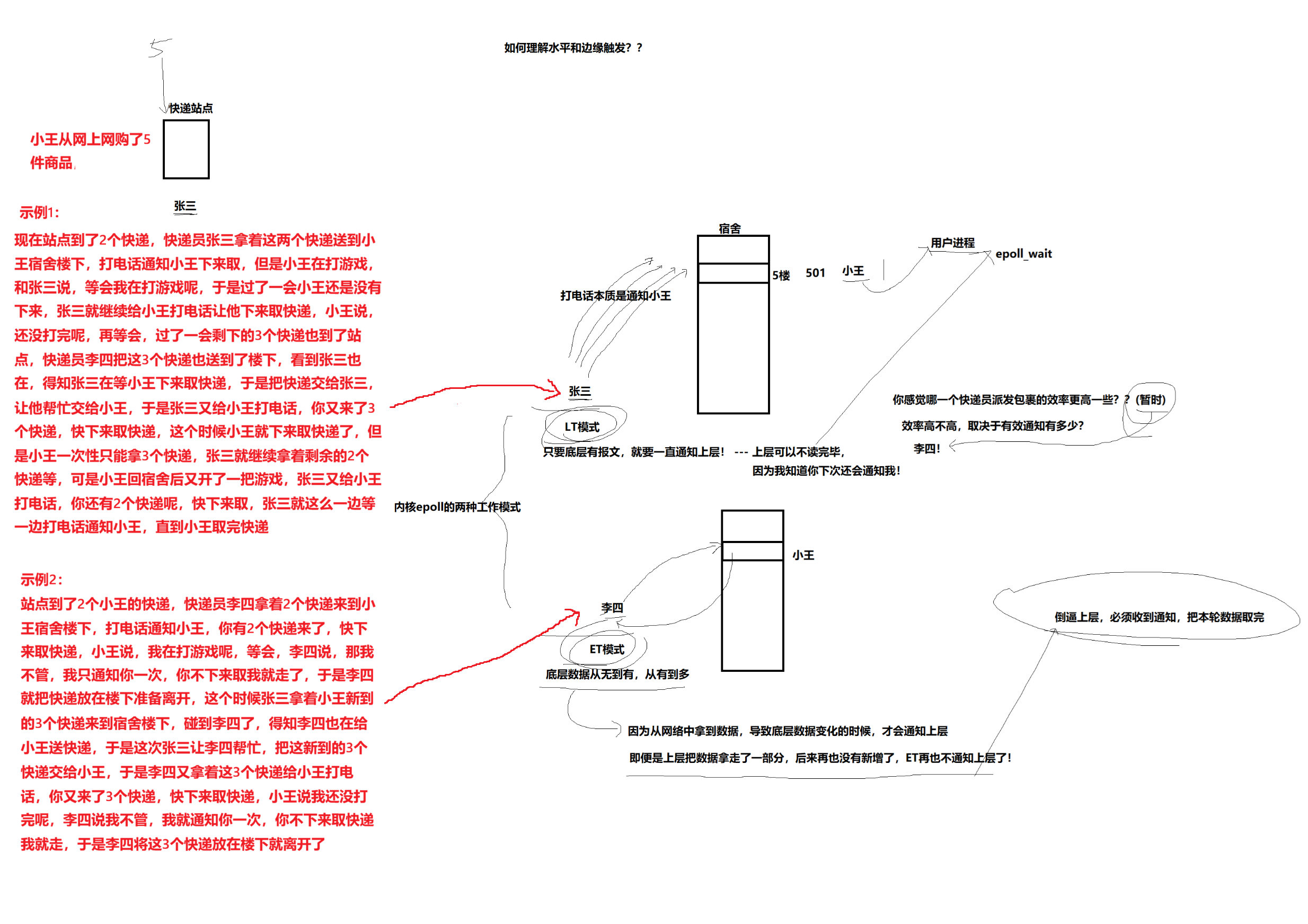
核心比喻解读
- 小王 :代表应用程序。
- 快递(商品) :代表Socket接收缓冲区中的数据。
- 快递员(张三/李四)打电话通知 :代表内核通过
epoll_wait返回事件,通知应用程序。 - 小王下楼取快递 :代表应用程序调用
read等函数读取数据。 - 快递放在楼下 :代表数据仍留在内核缓冲区中。
两种触发模式详解
1. 水平触发(LT)- 示例1:耐心的张三
模式特点 :只要缓冲区中还有数据,就会持续通知。
- 过程:无论小王一次取走几个快递,只要楼下(缓冲区)还有剩余的快递(数据),快递员张三就会不停地打电话通知他,直到全部取完。
- 内核行为 :只要某个socket的读缓冲区中还有数据可读,每次调用
epoll_wait时,都会报告这个socket的EPOLLIN(可读)事件。 - 对程序的影响 :
- 编程友好 :如果一次
read没有读完所有数据,下次调用epoll_wait时依然会得到通知,程序有机会继续读取。容错性高。 - 可能效率较低:如果数据就绪后,应用程序因为某些原因没有立刻处理完,会导致内核反复通知,产生一些不必要的开销。
- 编程友好 :如果一次
2. 边缘触发(ET)- 示例2:只通知一次的李四
模式特点 :仅在缓冲区数据状态发生变化时(从无到有/从有到更多)通知一次。
- 过程 :李四只在快递到达楼下的那一刻 打电话通知小王一次。之后无论小王下来取走几个,只要他没一次性取完,李四都不会再主动通知。直到有新的快递送达(数据从无到有或增加),他才会再次通知。
- 内核行为 :仅当socket的读缓冲区从空变为不空 (即有新数据到达)时,才会报告
EPOLLIN事件。如果缓冲区中一直有旧数据未被读走,epoll_wait不会再通知。 - 对程序的影响(非常关键!) :
- 高性能:避免了同一事件在数据未处理完时的重复通知,减少了系统调用和上下文切换,效率更高。
- 编程要求严格 :如图中所述,"倒逼上层,必须收到通知,把本轮数据取完" 。这意味着:
- 必须一次性读完/写完 :当
epoll_wait返回一个socket的可读事件后,应用程序必须循环调用read,直到其返回错误EAGAIN或EWOULDBLOCK(表示本轮数据已读完),否则会永远丢失这部分数据的通知。 - 必须使用非阻塞IO :为了支持上面的循环读取,socket必须设置为非阻塞模式(
O_NONBLOCK)。否则,在最后一次read时,如果缓冲区已空,线程会阻塞在那里,导致程序卡死。
- 必须一次性读完/写完 :当
select和poll其实也是工作在LT模式下,epoll既可以支持LT,也可以支持ET。不过LT是 epoll 的默认行为.
问题:为什么 ET 必须与非阻塞 I/O 配合?
假设使用阻塞 I/O,在 ET 模式下:
recv(fd, 100)读取了部分数据(如 100 字节),但缓冲区还有 2000 字节未读。- 若此时再次调用 recv ,由于缓冲区仍有数据,系统调用不会返回 EAGAIN,而是阻塞等待更多数据。
- 但 ET 模式下,epoll 不会再次通知你,因为状态没有变化(仍然是"有数据"),导致你的程序卡死在recv上,无法处理其他事件。
因此,必须设置 fd 为非阻塞模式:
cpp
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);这样,当 recv 无法立即读取到数据时,会立即返回 EAGAIN 或 EWOULDBLOCK,程序可以继续处理其他任务。
问题:LT可以设置非阻塞吗?
可以,LT也可以设置非阻塞,通过循环来一次性读取完数据,只要你想就可以这么做,但是这么做就会增加编程复杂性
那么你ET倒逼上层要一次性读完数据,我 LT 也可以这样啊!!!(指一次性读完数据),那为什么不这样呢?
- LT 模式 :允许"惰性"处理。程序在收到通知后,可以只读取部分数据,下次调用 epoll_wait时,内核会因为数据未读完而再次通知。这种行为是合法的。
- ET 模式 :操作系统(OS)通过其机制"约束程序员" 。如果程序不一次性读完,剩余的数据将不会再触发通知,可能导致数据滞留。这种"约束"创造了一种确定性的 I/O 行为。
所以,ET模式是通过OS来约束程序员要这么写代码,但是LT模式取决于程序员想怎么写就怎么写,那程序员肯定是怎么省心怎么写
LT 对比 ET效率
我们知道ET模式可以减少 epoll_wait 的唤醒次数,从而降低系统调用开销。
但是还有一方面可以看出ET模式效率更高
TCP 流量控制与接收窗口 :TCP 通信中,接收方通过 接收窗口(Window Size) 告诉发送方"我还能收多少数据"。这个窗口大小取决于接收缓冲区的剩余空间。
ET 如何提升效率:
- 及时清空缓冲区:ET 模式强制程序尽快、尽可能多地读取数据。
- 更快、更大程度地更新窗口 :接收缓冲区被迅速清空后,接收方能更快、更频繁 地向发送方回送一个更大的新窗口(更大的 win)。
- 提高发送并发度 :发送方一旦获知接收方有更大的可用窗口,就可以连续发送更多数据包,而无需等待之前的包被确认。这显著提高了网络管道的利用率和整体吞吐量,减少了发送方的等待时间。
LT 模式的问题:在 LT 模式下,如果程序不"自律"地一次性读完数据,接收缓冲区可能长期处于较满的状态。这会导致回送给发送方的接收窗口很小,发送方因此"畏手畏脚",只能发送少量数据,然后等待,严重限制了网络传输的并发度和整体速度。
所以,在 ET 模式下,程序被强制"一次性读完",从而:
快速清空接收缓冲区 → 向对端通告更大的接收窗口(win)→ 对端可以发送更多数据 → 提高 TCP 传输吞吐量。
ET 模式倒逼程序员的本质是:通过强制用户快速消费数据,最大化 TCP 窗口利用率,提升传输效率。
7. epoll中的惊群问题(选学)
惊群问题有些面试官可能会问到,参考:epoll惊群效应解析-CSDN博客
下一篇文章我们将会基于Reactor反应堆模式实现ET模式的epoll服务器