背景
Chromium 采用多进程架构,主要组件包括:浏览器进程 (Browser Process)、GPU 进程、渲染进程 (Renderer Process)、网络进程 (Network Process) 等。本方案主要关注渲染进程,因为页面js解析默认在渲染进程的主线程中。
目前每一个 Tab 标签打开同一网站都对应一个独立的 Render 进程。这种机制导致了应用后台经常驻留几十个进程,占用了大量系统资源,给人带来了不好的体验。
Chromium 自身包含多种渲染进程策略,会根据特定规则进行进程合并。因此,页面与进程的对应关系往往并不直观:哪些页面被合并在同一个进程,哪些页面是独立的进程,取决于具体的策略配置。
核心概念
在了解核心概念之前,我们先来看看chrome中创建渲染进程的默认策略,下面打开的网页都是相同地址的(同一个site):
- 现象一:
通过 "+" 打开一个新网页不会创建新的渲染进程,这个主要是因为两个网页之间有opener关系(通过js可以实现两个页面之间相互操作),并且属于同一BrowserInstance。

- 现象二:
通过超链接打开网页,此时不设置rel属性,默认是"noopener",会创建新的渲染进程。这是由于两个页面不属于同一个BrowserInstance了。
xml
<!doctype html><meta charset="utf-8">
<a href="https://cursor.com/cn/download" target="_blank">open cursor download</a>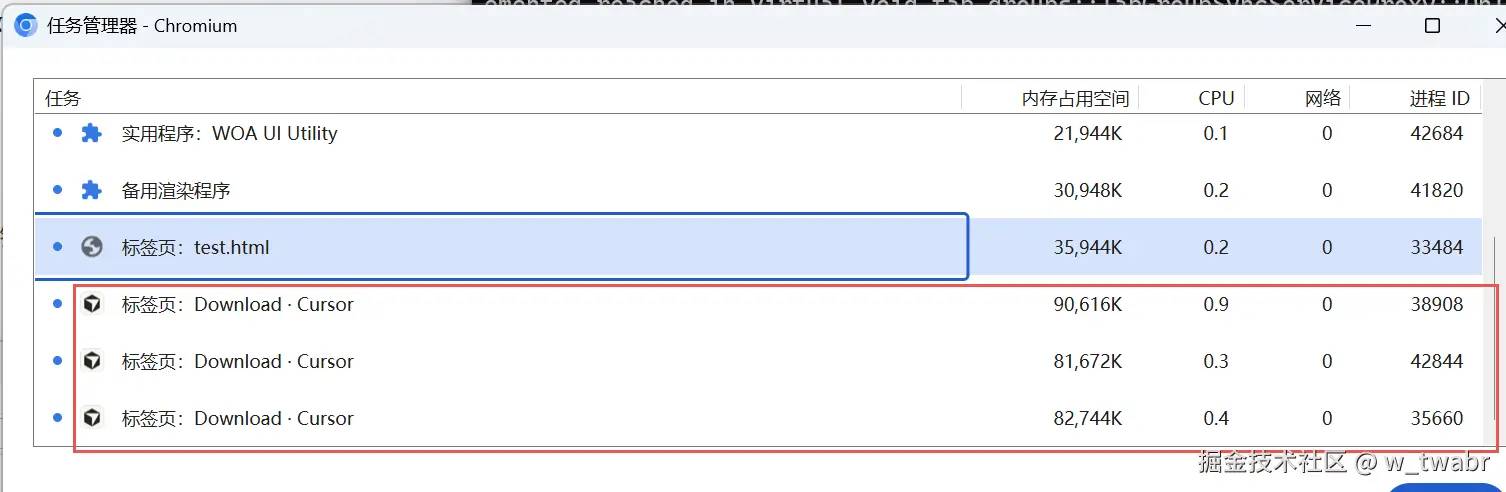
- 现象三:
通过超链接打开网页,设置rel属性为"opener",此时页面都在同一个BrowserInstance,新的网页会复用之前渲染进程,
xml
<!doctype html><meta charset="utf-8">
<a href="https://cursor.om/cn/download" target="_blank" rel="opener">open cursor download</a>
站点 (Site)
- 定义: 站点(Site)是指具有相同注册域名 (eTLD+1)和 协议(scheme) 的 URL 集合。
- 示例:
bash
https://mail.google.com 和 https://docs.google.com 属于同一个站点 (https://google.com)
http://example.com 和 https://example.com 属于不同站点(协议不同)
https://a.example.com 和 https://b.example.com 属于同一个站点 (https://example.com)
/* 注:与同源的区别
同源:要求协议、域名(包括子域名)、端口完全相同
同站:只要求协议和 eTLD+1 相同,子域名和端口可以不同
*/
https://a.example.com:443/x 和 https://a.example.com:443/y 属于同源- 计算方法:
php
// content/browser/site_info.cc
// static
GURL SiteInfo::GetSiteForOrigin(const url::Origin& origin) {
// 取 eTLD+1
std::string domain = net::registry_controlled_domains::GetDomainAndRegistry(
origin, net::registry_controlled_domains::INCLUDE_PRIVATE_REGISTRIES);
// 返回 scheme + eTLD+1
// 例如: https://mail.google.com -> https://google.com
return SchemeAndHostToSite(origin.scheme(),
domain.empty() ? origin.host() : domain);
}浏览实例 (BrowsingInstance)
- 定义: 代表一组可以通过脚本相互访问的标签页和框架的集合(比如
window.open打开的新窗口、同一页面里的 iframe)。 - 关键特性:
-
- 同一个 BrowsingInstance 内的页面可以通过 JavaScript 相互访问(前提是符合同源策略)
- 每个 BrowsingInstance 拥有独立的 ID (
BrowsingInstanceId) - BrowsingInstance 包含多个 SiteInstance
- 创建时机:
-
- 使用
window.open()打开新窗口时(带noopener则创建新 BrowsingInstance) - 导航到需要 COOP (Cross-Origin-Opener-Policy) 隔离的页面时
- 使用
<a target="_blank">链接打开新页面时(取决于是否有rel="noopener",默认为noopener")
- 使用
站点实例 (SiteInstance)
- 定义: 同一 BrowsingInstance 内、同一站点通常只对应一个 SiteInstance。同一 SiteInstance 内的文档共享同一个渲染进程。
- 关键特性:
-
- 每个 SiteInstance 关联一个
SiteInfo(包含站点 URL、进程锁定信息等) - 每个 SiteInstance 属于一个 BrowsingInstance
- 同一 SiteInstance 的所有文档必须在同一个进程中运行
- 一个 BrowsingInstance 中,每个站点最多只有一个 SiteInstance(正常情况下)
- 每个 SiteInstance 关联一个
关系展示
📌默认情况下,同一BrowsingInstance下,同一site通常复用同一个同一SiteInstance,运行在同一渲染进程,不同BrowsingInstance下,同一site会被保存到不同SiteInstance,大多运行在不同渲染进程
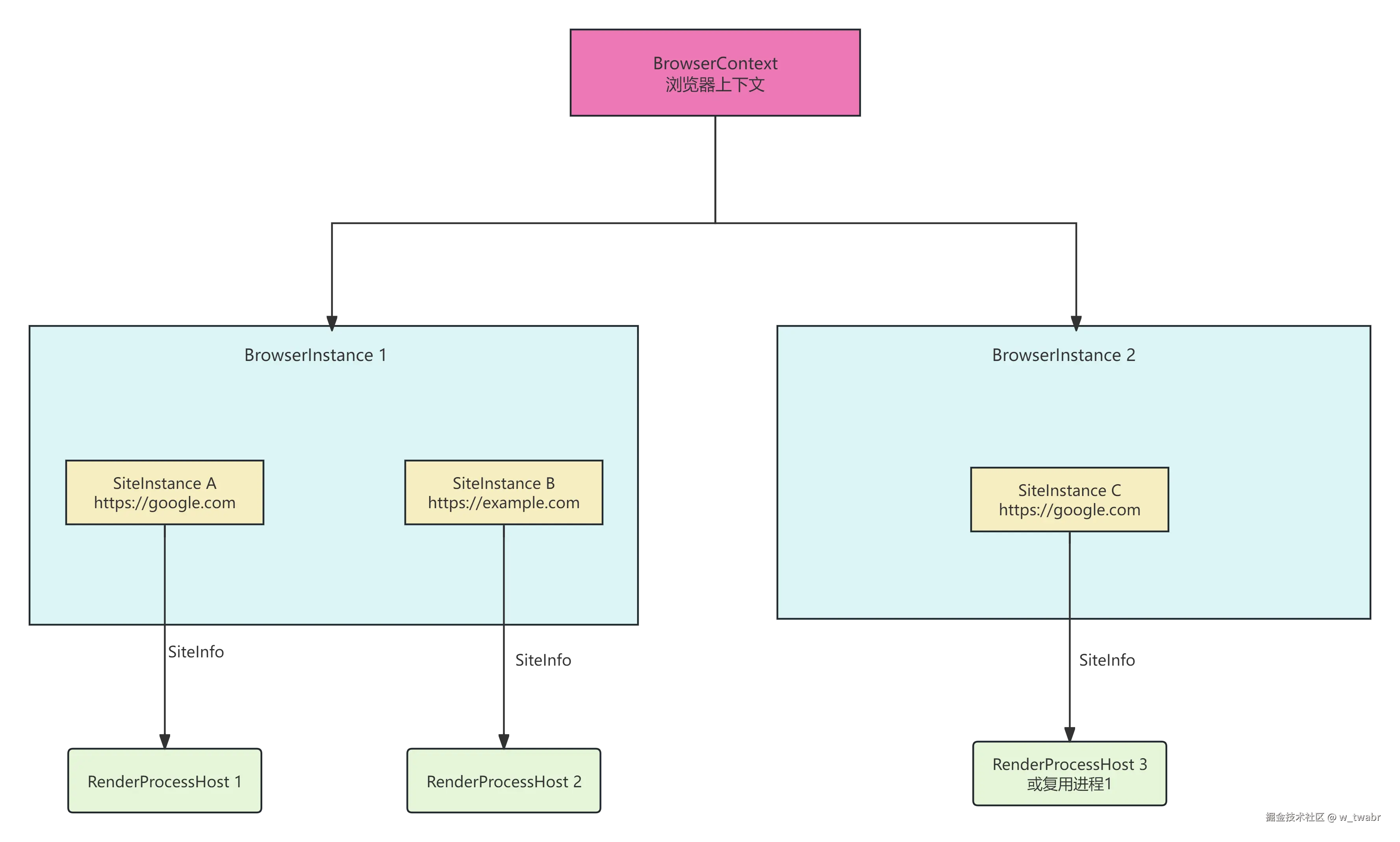
进程模型
Chromium 支持四种进程模式,通过命令行参数 --process-per-site-instance、--process-per-site、--process-per-tab、--single-process 可以切换。
Process-per-site-instance (默认模式)
- 策略: 同一个 SiteInstance 使用一个进程。
- 特点:
-
- Chrome 默认使用的模式
- 兼顾性能与安全性的中庸方案
- 同一 BrowsingInstance 内的同一站点共享进程
- 不同 BrowsingInstance 的同一站点可能使用不同进程(也可能复用)
- 源码体现:
scss
// content/browser/browsing_instance.cc
scoped_refptr<SiteInstanceImpl> BrowsingInstance::GetSiteInstanceForURL(
const UrlInfo& url_info,
bool allow_default_instance) {
SiteInfo site_info = ComputeSiteInfoForURL(url_info);
// 检查是否已存在该站点的 SiteInstance
auto it = site_instance_map_.find(site_info);
if (it != site_instance_map_.end()) {
return it->second; // 复用现有 SiteInstance(进程)
}
// 创建新的 SiteInstance
// ...
}Process-per-site
- 策略: 同一个 site 使用一个进程,跨越所有 BrowsingInstance。
- 特点:
-
- 整个浏览器进程中,同一站点只有一个渲染进程
- 更激进的进程共享,内存占用更低
- 安全隔离性降低(渲染进程卡死,所有窗口白屏)
源码体现:
rust
// content/browser/site_info.cc
bool SiteInfo::ShouldUseProcessPerSite(BrowserContext* browser_context) const {
// 检查是否为需要 process-per-site 的站点
return GetContentClient()->browser()->ShouldUseProcessPerSite(
browser_context, site_url_);
}
// 进程复用策略枚举:
// content/browser/process_reuse_policy.h
enum class ProcessReusePolicy {
PROCESS_PER_SITE, // 整个浏览器共享进程
// ...
};Process-per-tab
- 策略: 每个标签页使用一个独立进程。
- 特点:
-
- 每个标签页独立进程,即使是同一站点
- 隔离性最强,但内存和进程数开销最大
- 不考虑站点的概念
- 使用场景:
-
- 测试和调试
- 需要极强隔离性的场景
3.4 Single Process
- 策略: 所有标签页共用一个渲染进程。
- 特点:
-
- 主要用于调试
- 性能开销最小,但没有安全隔离
- 生产环境不推荐使用
补充说明:
-
--renderer-process-limit=N:限制渲染器进程的最大数量为 N
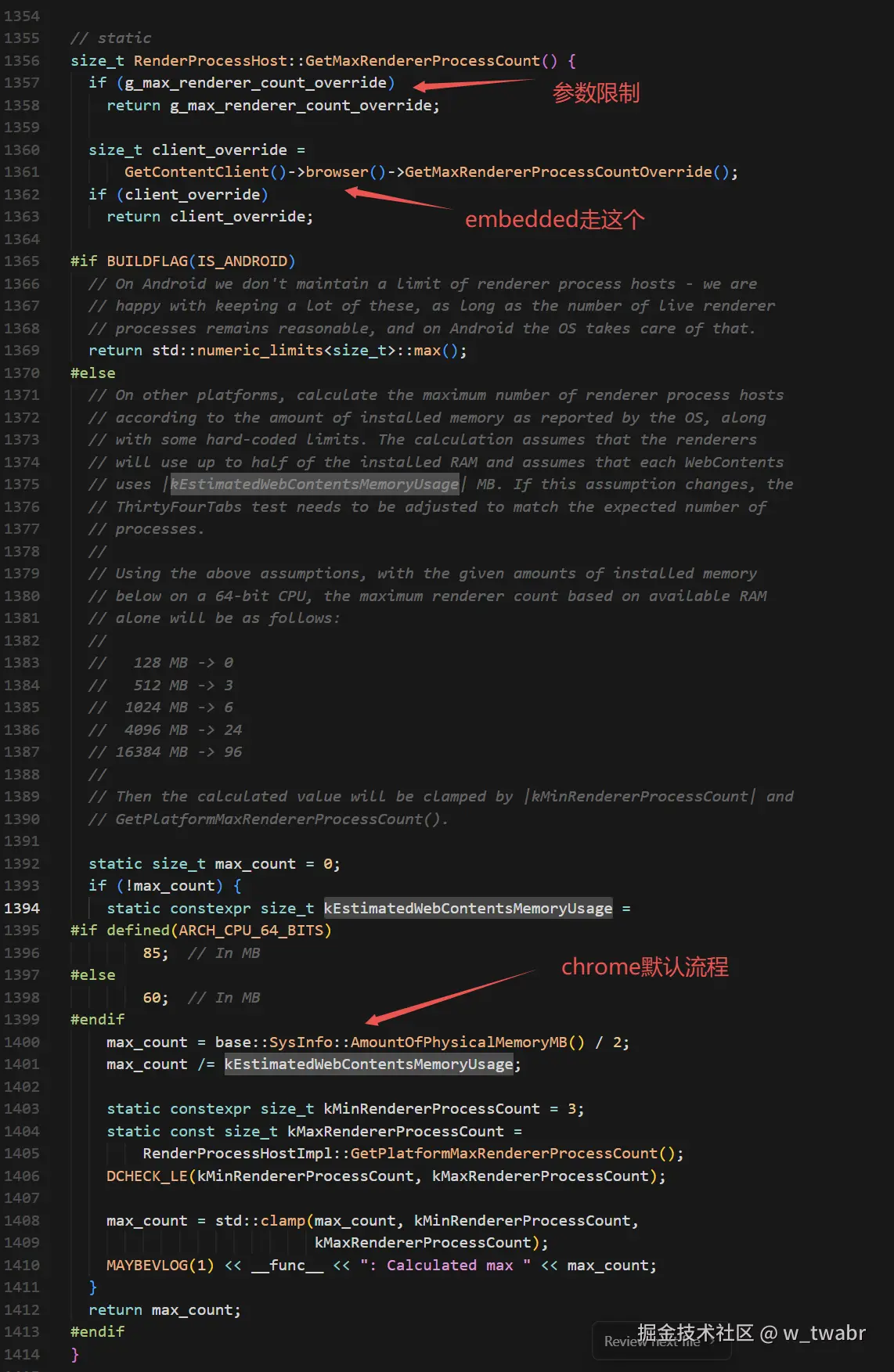
默认情况下,64位机器:max_count≈物理内存➗(2✖85)