目录
[1. 概述](#1. 概述)
[3. 实例演示](#3. 实例演示)
[3.1 书写proto文件](#3.1 书写proto文件)
[3.2 编译 .proto 文件](#3.2 编译 .proto 文件)
[3.3 Writer.cpp代码](#3.3 Writer.cpp代码)
[3.4 Reader.cpp代码](#3.4 Reader.cpp代码)
[3.5 执行Writer和Reader](#3.5 执行Writer和Reader)
[4. ProtoBuf的Encoding](#4. ProtoBuf的Encoding)
[4.1 Message Buffer](#4.1 Message Buffer)
[4.2 Varint](#4.2 Varint)
[4.3 Key](#4.3 Key)
[4.4 Zigzag 编码](#4.4 Zigzag 编码)
[5. API介绍](#5. API介绍)
[6. Protobuf的优点](#6. Protobuf的优点)
[6.1 优点](#6.1 优点)
[6.2 不足之处](#6.2 不足之处)
1. 概述
在移动互联网时代,手机流量、电量是最为有限的资源,而移动端的即时通讯应用无疑必须得直面这两点。
解决流量过大的基本方法就是使用高度压缩的通信协议,而数据压缩后流量减小带来的自然结果也就是省电:因为大数据量的传输必然需要更久的网络操作、数据序列化及反序列化操作,这些都是电量消耗过快的根源。
当前即时通讯应用中最热门的通信协议无疑就是Google的Protobuf了,基于它的优秀表现,微信和手机QQ这样的主流IM应用也早已在使用它。本文将详细介绍Protobuf的使用、原理等。
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。xml、json也可以用来存储此类结构化数据,但是使用protobuf表示的数据能更加高效,并且将数据压缩得更小,大约是json格式的1/10,xml格式的1/20。
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。
2.环境安装
2.1编译源码包
从github:https://github.com/protocolbuffers/protobuf 下载源代码;此处 我下载的是匹配我们项目的版本protobuf-3.21.7。
2.2下载源码并解压
以ubuntu安装为例,安装步骤如下:
bash
tar --xzf protobuf-cpp-3.21.7.tar.gz
cd protobuf-cpp-3.21.7/
./configure --prefix=$INSTALL_DIR //设置install路径
make
make check
make install3. 实例演示
使用 Protobuf 和 C++ 开发一个十分简单的读写程序。这个程序由Writer和Reader组成。 Writer 负责将一些结构化的数据写入一个磁盘文件,Reader 则负责从该磁盘文件中读取结构化数据并打印到屏幕上。

图1
3.1 书写proto 文件
首先我们需要编写一个 proto 文件,定义我们程序中需要处理的结构化数据,在 protobuf 的术语中,结构化数据被称为 Message。proto 文件非常类似 java 或者 C 语言的数据结构体定义。
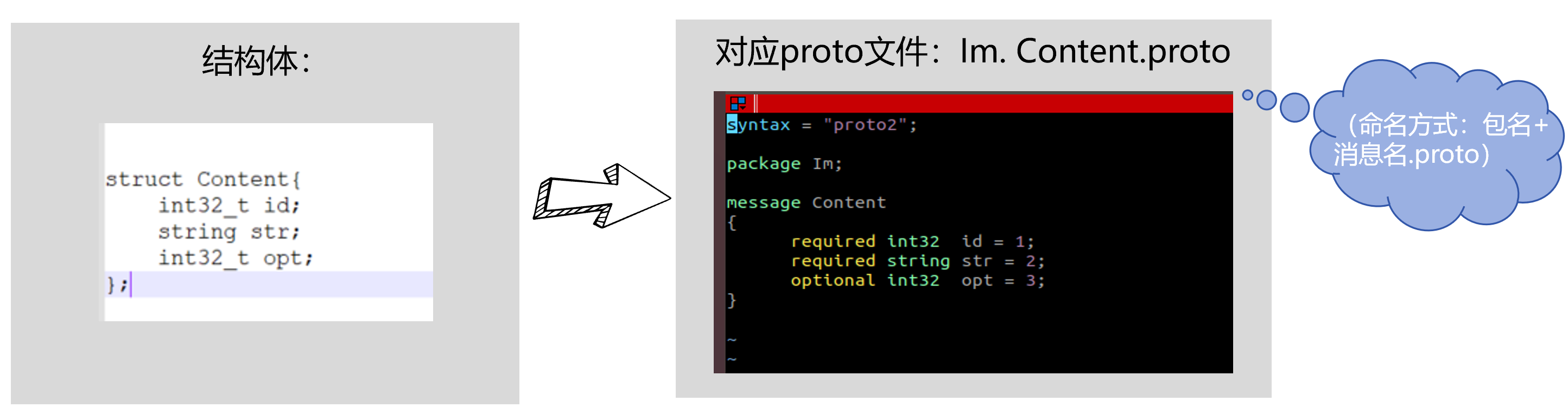
图2
在上例中,package 名字叫做 lm,定义了一个消息 Content,该消息有三个成员,类型为 int32 的 id,另一个为类型为 string 的成员 str。opt 是一个可选的成员,即消息中可以不包含该成员。
3.2 编译 .proto 文件
写好 proto 文件之后就可以用 Protobuf 编译器将该文件编译成目标语言了。本例中我们将使用 C++。
我们可以新建一个测试目录:/app ; 把include目录下的文件都按照该目录结构和lib/libprotobuf.a复制到所测试的目录中去;

图3
执行安装目录下bin目录中的protoc程序,将写好的proto 文件用Protobuf 编译器将该文件编译成目标语言。命令生成Im.Content.pb.h和Im.Content.pb.cc文件,如下图所示:

图4
3.3 Writer.cpp 代码
现在要将数据存入磁盘,该结构化数据由Im::Content类的对象表示,它提供一系列的get/set函数用来修改和读取结构化数据中的数据成员。当需要将该结构化数据保存到磁盘上时,类Im::Content已经提供相应的方法来把一个复杂的数据变成一个字节序列,可以将这个字节写入磁盘。
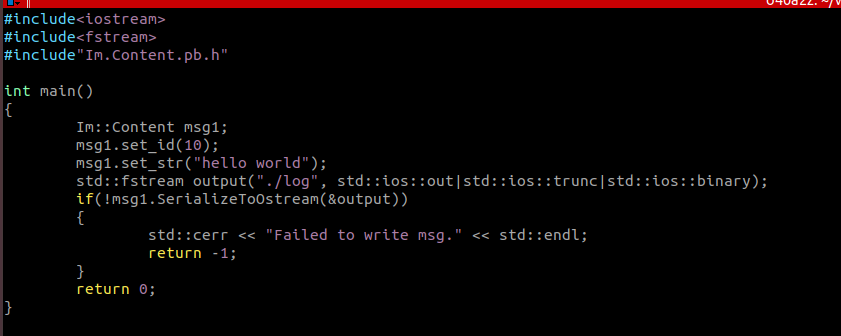
图5
编译Writer.cpp文件

图6
3.4 Reader.cpp 代码
对于Reader,只需从log文件中读取,反序列化后就能获得结构化的数据。利用Im::Cotent对象的ParseFromIstream方法从一个fstream流中读取信息并反序列化,此后,ListMsg 中采用 get 方法读取消息的内部信息,并进行打印输出操作。参考Writer,对齐进行编译;
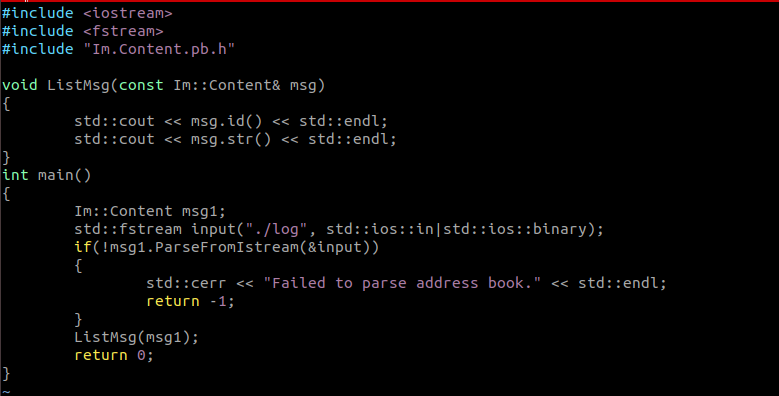
图7
3.5 执行Writer 和Reader
通过Writer把数据序列化写到文件中;然后通过Reader读取出来;
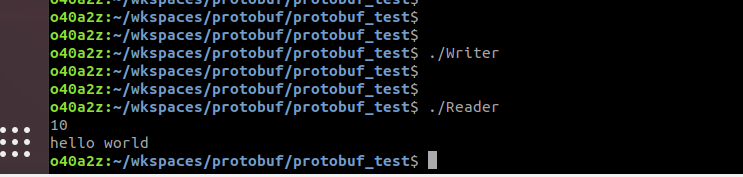
图8
4. ProtoBuf的Encoding
4.1 Message Buffer
++Protobuf++ ++序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf++ ++采用的非常巧妙的 Encoding++ ++方法++
首先介绍一下Message Buffer的组成
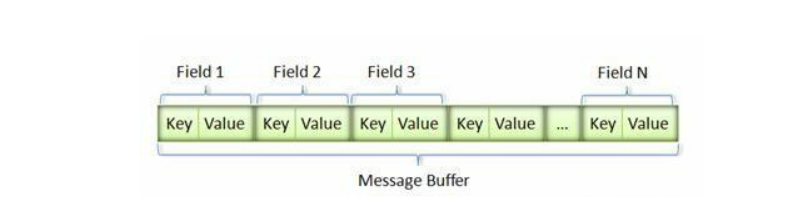
图9
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
4.2 Varint
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。下面就详细介绍一下 Varint。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。
Google Protocol Buffer 字节序采用 little-endian 的方式。
cpp
message Test {
optional int32 a = 1;
}对于这个例子来说,如果给a赋值150,那么最终得到的编码是什么呢?
150的2进制编码是:1001 0110 。 由于数据只有低七位有效,所以数据可以写成 000 0001 001 0110. 然后因为小端模式,所以交换字节位置:001 0110 000 0001 。 因为最高位表示后面byte是否是数据的一部分,所以高字节,最高位填写1,低字节最高位填写0;最终得到编码为:1001 0110 0000 0001;
解码的话,就是把这个过程反过来;
1001 0110 0000 0001 根据两个字节的最高位可以推断出来,这里的有效数据是两个字节。 去除高字节的最高位,跟低字节的最高位,可以得到编码: 001 0110 000 0001. 因为小端模式,反一下字节序: 000 0001 001 0110.
4.3 Key
++Key++ ++用来标识具体的 field++ ++,在解包的时候,Protocol Buffer++ ++根据 Key++ ++就可以知道相应的 Value++ ++应该对应于消息中的哪一个 field++ ++。++
Key 的定义如下:
cpp
(field_number << 3) | wire_type可以看到 Key 由两部分组成。第一部分是 field_number,比如消息 lm.helloworld 中 field id 的 field_number 为 1。第二部分为 wire_type。表示 Value 的传输类型。
Wire Type 可能的类型如下表所示:
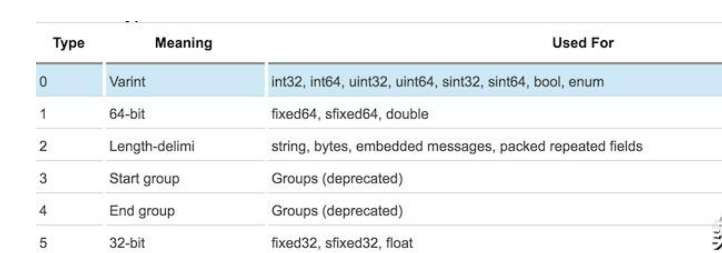
图10
4.4 Zigzag 编码
在我们的例子当中,field id 所采用的数据类型为 int32,因此对应的 wire type 为 0。或许会看到在 Type 0 所能表示的数据类型中有 int32 和 sint32 这两个非常类似的数据类型。Google Protocol Buffer 区别它们的主要意图也是为了减少 encoding 后的字节数。
在计算机内,一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 5 个 byte。为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。
Zigzag 编码用无符号数来表示有符号数字,正数和负数交错,这就是 zigzag 这个词的含义了。
使用 zigzag 编码,绝对值小的数字,无论正负都可以采用较少的 byte 来表示,充分利用了 Varint 这种技术。
其他的数据类型,比如字符串等则采用类似数据库中的 varchar 的表示方法,即用一个 varint 表示长度,然后将其余部分紧跟在这个长度部分之后即可。
通过以上对 protobuf Encoding 方法的介绍,想必您也已经发现 protobuf 消息的内容小,适于网络传输。假如您对那些有关技术细节的描述缺乏耐心和兴趣,那么下面这个简单而直观的比较应该能给您更加深刻的印象。
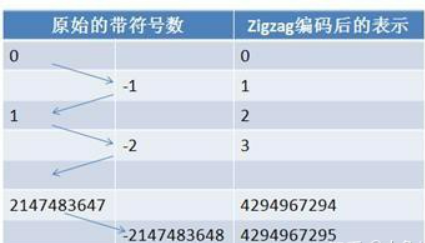
图11
使用 zigzag 编码,绝对值小的数字,无论正负都可以采用较少的 byte 来表示,充分利用了 Varint 这种技术。
其他的数据类型,比如字符串等则采用类似数据库中的 varchar 的表示方法,即用一个 varint 表示长度,然后将其余部分紧跟在这个长度部分之后即可。
5. API 介绍
常用API, 可以直接查看生成的代码中的 .h 文件
1)protoc 为message 的每个required 字段和optional 字段都定义了以下几个函数(不限于这几个):
- TypeName xxx() const; //获取字段的值
- bool has_xxx(); //判断是否设值
- void set_xxx(const TypeName&); //设值
- void clear_xxx(); //使其变为默认值
2)为每个repeated 字段定义了以下几个:
- TypeName* add_xxx(); //增加结点, 然后需要拿到结构体指针后对成员进行赋值操作;
- TypeName xxx(int) const; //获取指定序号的结点,类似于C++的"\[\]"运算符
- TypeName* mutable_xxx(int); //类似于上一个,但是获取的是指针
- int xxx_size(); //获取结点的数量
3)下面几个是常用的序列化函数:
- bool SerializeToOstream(std::ostream * output) const; //输出到输出流中
- bool SerializeToString(string * output) const; //输出到string
- bool SerializeToArray(void * data, int size) const; //输出到字节流,可以通过ByteSize方法计算存储空间后使用new申请一块内存给data;
4)与之对应的反序列化函数:
- bool ParseFromIstream(std::istream * input); //从输入流解析
- bool ParseFromString(const string & data); //从string解析
- bool ParseFromArray(const void * data, int size); //从字节流解析,size为buffer的size
5)其他常用的函数:
- bool IsInitialized(); //检查是否所有required字段都被设值
- size_t ByteSize() const; //获取二进制字节序列的大小
6)对嵌套message 成员提供的函数:
- bool has_xxx()
- void set_has_xxx()
- void clear_has_xxx()
- void clear_xxx()
- const TypeName& xxx() const //前面几个和上面介绍的一致
- TypeName* mutable_xxx() //会自动new一块内存并返回,然后拿到结构体指针后对成员进行赋值操作;
- TypeName* release_xxx()
- void set_allocated_xxx(TypeName* xxx) //传入的参数需要自己手动new一块内存,和mutable_xxx()有所区别;
6. Protobuf 的优点
6.1 优点
1)Protobuf有如XML,不过它更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。只需使用Protobuf对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。
2)它有一个非常棒的特性,即"向后"兼容性好,人们不必破坏已部署的、依靠"老"数据格式的程序就可以对数据结构进行升级。这样您的程序就可以不必担心因为消息结构的改变而造成的大规模的代码重构或者迁移的问题。因为添加新的消息中的 field 并不会引起已经发布的程序的任何改变。
3)Protobuf 语义更清晰,无需类似 XML 解析器的东西(因为 Protobuf 编译器会将 .proto 文件编译生成对应的数据访问类以对 Protobuf 数据进行序列化、反序列化操作)。
4)使用 Protobuf 无需学习复杂的文档对象模型,Protobuf 的编程模式比较友好,简单易学,同时它拥有良好的文档和示例,对于喜欢简单事物的人们而言,Protobuf 比其他的技术更加有吸引力。
6.2 不足之处
Protbuf 与 XML 相比也有不足之处。它功能简单,无法用来表示复杂的概念。XML 已经成为多种行业标准的编写工具,Protobuf 只是 Google 公司内部使用的工具,在通用性上还差很多。由于文本并不适合用来描述数据结构,所以 Protobuf 也不适合用来对基于文本的标记文档(如 HTML)建模。另外,由于 XML 具有某种程度上的自解释性,它可以被人直接读取编辑,在这一点上 Protobuf 不行,它以二进制的方式存储,除非你有 .proto 定义,否则你没法直接读出 Protobuf 的任何内容