在 Superset 里给运营同学搭看板,想展示一下用户的对话日志。数据从 PostgreSQL 视图里一查,DBeaver 里看着一切正常。
结果一放到 Superset 图表上,傻眼了:
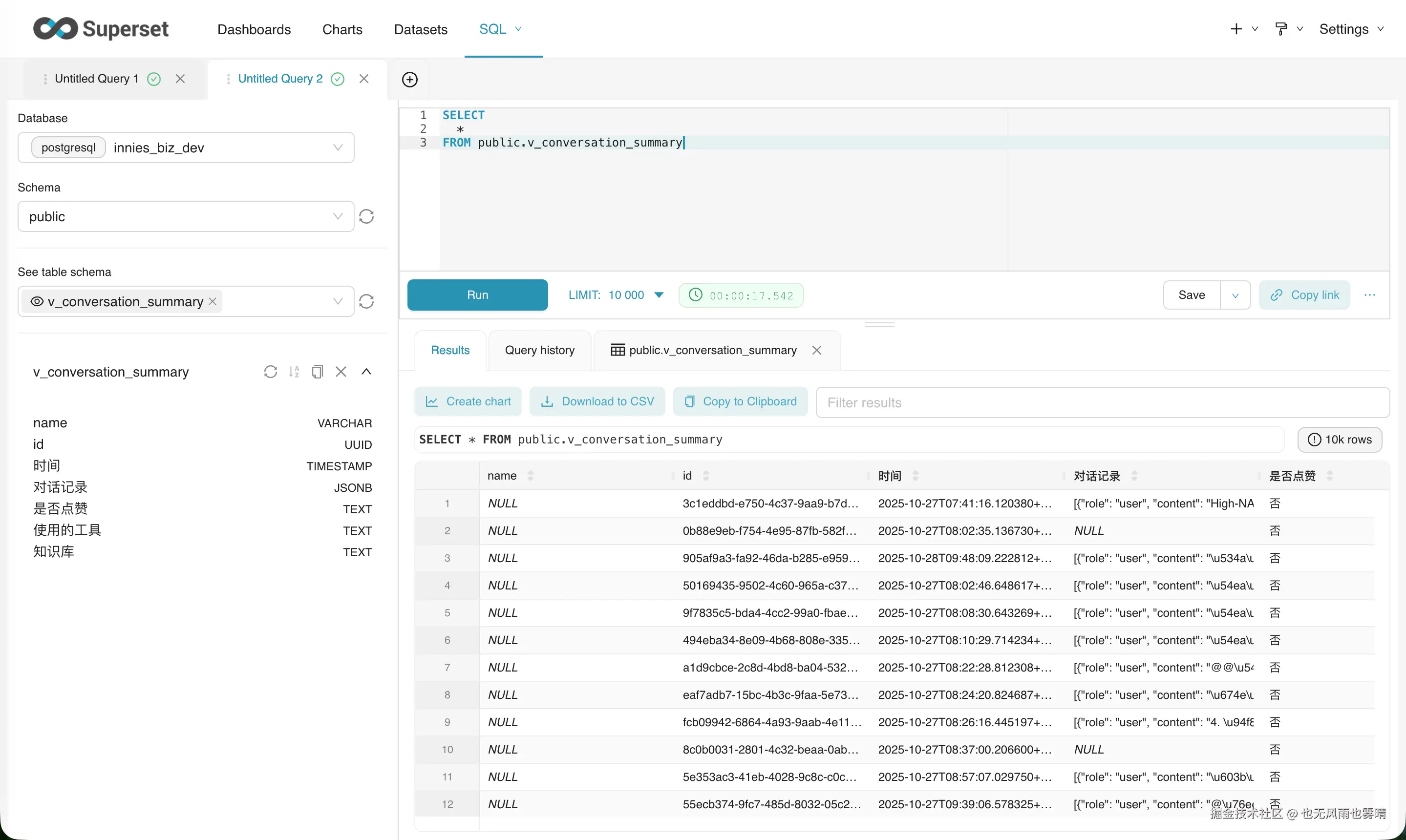
json
[{"role": "user", "content": "\u4eca\u5929\u5929\u6c14"}]好好的中文全变成了 \uXXXX 这种天书。
案发现场
背景是这样的:我用 PostgreSQL 的 FDW 做跨库查询,专门写了个视图 v_conversation_summary 投喂给 Superset。为了把多轮对话聚合在一行显示,我用了 jsonb_agg:
sql
-- 原始 SQL 片段
SELECT jsonb_agg(
jsonb_build_object('role', tm.role, 'content', tm.content)
ORDER BY tm.message_order
) AS 对话记录
...逻辑没毛病,数据库里查出来的结果也是标准的 JSON 数组。怎么到了 Superset 前端就"乱码"了呢?
插播:为什么一开始要用 JSONB?
这里稍微解释下,为什么我习惯性地选了 JSONB 而不是普通的文本拼接。
PostgreSQL 的 JSONB (Binary JSON) 是个非常强大的特性。不同于普通的 JSON 类型(纯文本存储),JSONB 在存储时会把数据解析并转换成二进制格式。
- 存的时候:它会把键值对排序、去重、压缩。
- 取的时候:不需要再次解析文本,直接就能拿来用,性能极高。
- 最重要的是 :它支持 GIN 索引 。如果你想在几百万条数据里搜
{"role": "user"},用 JSONB 是毫秒级的,用文本存就是全表扫描。
因为习惯了它的高性能和规范性,我下意识地就用了 jsonb_agg。没想到,正是这个"二进制"的特性,配合上 Python 的严谨,搞出了这次的乱码乌龙。
破案过程
第一反应通常是:"是不是数据库编码不对?" 或者 "Superset 的编码设置有问题?"
但仔细一对比发现:
- DBeaver 查询:显示完美中文。
- Superset 展示:显示 Unicode 转义符。
这说明数据库里存的数据本身没问题。问题出在从数据库取出来,到发给浏览器的这段路上。
真凶:Python 的 json.dumps
Superset 后端是 Python 写的。当它从 PostgreSQL (通过 psycopg2 驱动) 拿到 JSONB 类型的数据时,Python 会把它转换成字典(Dict)。
关键一步来了:Superset 要把这个字典传给前端,需要把它序列化成字符串。这时候它(或者底层的库)大概率调用了 Python 标准库的 json.dumps。
在 Python 里,json.dumps 有个默认行为:
python
import json
data = {"msg": "你好"}
# 默认 ensure_ascii=True
print(json.dumps(data))
# 输出: {"msg": "\u4f60\u597d"} <-- 也就是我们看到的"乱码"这个 ensure_ascii=True 默认开启,原本是为了兼容性------确保不管对方系统多老旧,只要能认 ASCII 码就不会崩。但在我们这个场景下,它就成了"好心办坏事",把原本能正常显示的 UTF-8 中文强行转义了。
为什么 DBeaver 没事? 因为 DBeaver 是个成熟的客户端,它拿到数据后在本地做了解析和渲染,它"认识"这些 Unicode 字符,所以贴心地帮你转回了中文。而 Superset 把它当成了普通字符串直接吐了出来。
怎么解?
既然知道了是序列化的问题,改 Superset 源码去关掉 ensure_ascii 显然动静太大,容易"此时一时爽,升级火葬场"。
最优雅的办法,其实是在数据库层就把格式修好。
既然我们的目标是"给人看"(运营看板),而不是给程序读,那为什么要执着于传 JSON 格式呢?直接拼成易读的文本不更香吗?
于是我把 jsonb_agg 换成了 STRING_AGG,顺手还加了点 Emoji 做美化:
sql
(
SELECT STRING_AGG(
CASE
WHEN tm.role = 'user' THEN '👤 ' || tm.content -- 用户说话加个小人
WHEN tm.role = 'assistant' THEN '🤖 ' || tm.content -- AI 回复加个机器人
ELSE tm.role || ': ' || tm.content
END,
E'\n\n' -- 用换行符隔开,清晰明了
ORDER BY tm.message_order
)
FROM task_messages tm
WHERE tm.task_id = t.id
) AS 对话记录这样改的两个红利:
- 彻底绕过序列化坑:输出变成了纯文本(Text),Superset 拿到什么就显示什么,Python 再也不会自作多情去转义它。
- 运营体验拉满 :去掉了冷冰冰的
{"role":...}花括号和引号,直接显示对话流,运营同学看数据眼睛也不累了。
附:深度科普 PostgreSQL 的 JSONB
既然提到了 JSONB,顺便多聊两句。很多同学从 MySQL 转过来,可能觉得"不就是存 JSON 嘛,有啥区别?"
其实 PG 里的 json 和 jsonb 完全是两个物种。
1. 它是"熟"的,不是"生"的
- JSON 类型就像把肉冻在冰箱里,你存进去是什么样(包括空格、键的顺序、重复键),取出来就是什么样。它本质上就是个带校验的文本。
- JSONB 则是把肉做成了熟食。存进去的时候,数据库会把它解析、去重、排序 ,转换成一种高效的二进制格式 。
- 优点:读的时候不需要重新解析,速度飞快;支持索引。
- 缺点:写入时多了一步解析,稍微慢一丢丢;原本的空格和格式会丢失。
2. 杀手锏:GIN 索引
JSONB 最大的威力在于它支持 GIN (Generalized Inverted Index) 索引。
假设你有一亿行日志,存了个 payload 字段:
sql
-- 查所有"用户ID为10086"的操作记录
SELECT * FROM logs WHERE payload @> '{"user_id": 10086}';- 如果是普通 JSON:数据库得一行行把文本读出来,解析,再比对------这就是灾难。
- 如果是 JSONB + 索引:它可以直接定位到包含这个键值对的行,速度和查主键差不多。
3. 避坑指南:到底选谁?
| 场景 | 推荐类型 | 理由 |
|---|---|---|
| 只是做日志归档 | JSON | 写入快,原样保留原始请求体(哪怕格式很丑) |
| Web端透传参数 | JSON | 既然后端不处理,就别费劲转二进制了 |
| 经常要根据字段查询 | JSONB | 必选,为了用索引 |
| 频繁更新局部字段 | JSONB | jsonb_set 修改性能更好 |
| 给 BI 工具做展示 | Text | 就像本文遇到的坑,直接用 SQL 拼成字符串最安全! |
小结
遇到这种"数据库查着对,前端显示乱"的问题,尤其是涉及 JSON 的时候,多半是中间层的序列化配置在作妖。
虽然技术上我们可以通过配置解决编码问题,但转换思维往往能找到更好的路:既然是做展示,不如直接在 SQL 里把数据加工成最适合阅读的样子。既解决了乱码,又优化了排版,一举两得。
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills (按需加载,意图自动识别,不浪费 token,介绍文章):
- code-review-skill - 代码审查技能,覆盖 React 19、Vue 3、TypeScript、Rust 等约 9000 行规则(详细介绍)
- 5-whys-skill - 5 Whys 根因分析,说"找根因"自动激活
- first-principles-skill - 第一性原理思考,适合架构设计和技术选型
vibe coding 原理学习:
- coding-cli-guide(学习网站)- 学习 qwen-cli 时整理的笔记,40+ 交互式动画演示 AI CLI 内部机制
全栈项目(适合学习现代技术栈):
- prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
- chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB