📝 前言
随着 NVIDIA Blackwell (GB10/B200) 硬件的陆续落地,如何在这一全新架构上部署超大参数模型成为了业界的焦点。GPT-OSS 120B 作为 OpenAI 发布的开源底座模型,结合 Blackwell 的 MXFP4 (Micro-scaling FP4) 精度优势,能实现单卡(128GB 统一内存)的高效推理。
但在实际部署过程中,我们遭遇了 NumPy 版本 ABI 冲突 、Python 多进程 CUDA 初始化死锁 、OpenAI Harmony 词表内网下载失败 等一系列"深坑"。
本文将还原全流程,提供一套经过实战验证的黄金部署路径。
🛠️ 硬件与环境清单
- GPU: NVIDIA Blackwell GB10 (128GB Unified Memory)
- Driver: CUDA 13.0 Compatible (Driver 580+)
- OS: Ubuntu 24.04.3 LTS
- Python: 3.11 (Conda)
- vLLM: V1 Engine (Source Build)
- Model: GPT-OSS 120B (MXFP4 Quantized)
🚧 第一关:环境构建与依赖排雷
由于 Blackwell 架构较新,标准的 pip 安装往往无法启用 V1 引擎特性。
1.1 创建纯净环境
bash
conda create -n vllm-spark python=3.11 -y
conda activate vllm-spark1.2 源码编译 vLLM
为了支持 mxfp4 量化,建议使用源码编译安装:
bash
# 下载源码
git clone https://github.com/vllm-project/vllm.git
cd vllm
# 安装编译依赖
pip install -r requirements-build.txt
# 开始编译 (根据 CPU 核心数调整 MAX_JOBS)
export MAX_JOBS=32
pip install -e .💥 踩坑 1:NumPy ABI 兼容性冲突
【问题现象】
启动时报错 ImportError: numpy.core.multiarray failed to import。
【原因分析】
最新的 Numba 库与 NumPy 2.x 版本存在 ABI 冲突,而 vLLM 的某些依赖默认安装了新版 NumPy。
【解决方案】
强制降级 NumPy 到 2.3 以下版本:
bash
pip install "numpy<2.3" --force-reinstall
# 验证版本
python -c "import torch; import numpy; print(f'Torch: {torch.__version__}, NumPy: {numpy.__version__}')"🔑 第二关:离线词表构建 (解决 HarmonyError)
这是最容易卡住的一步,也是内网部署的痛点。
💥 踩坑 2:Harmony 词表下载失败
【问题现象】
启动 API Server 时,报错 openai_harmony.HarmonyError: error downloading or loading vocab file。即使设置了 TIKTOKEN_CACHE_DIR 也不生效。
【原因分析】
gpt-oss 依赖 openai_harmony 库(底层基于 Rust 的 tiktoken-rs)。该库在启动时会强制校验词表,且它查找缓存的逻辑是基于文件 URL 的 SHA1 哈希值,而不是文件名,且优先读取 Rust 侧的环境变量。
【解决方案】
我们需要手动构建"哈希缓存"来欺骗库文件。
步骤 1:准备缓存目录
bash
# 创建 tiktoken-rs 专用缓存目录
mkdir -p /root/.cache/tiktoken步骤 2:下载并重命名词表
openai_harmony 实际上需要的是 OpenAI 的 o200k_base 词表。
- 下载地址 :
https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken - 目标哈希文件名 :
fb374d419588a4632f3f557e76b4b70aebbca790
执行脚本:
bash
cd /home/david/workspaces/models/gpt-oss-120b
# 下载词表 (如无法联网,请本地下载后上传)
wget https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken -O harmony_gpt_oss.tiktoken
# 复制并重命名为哈希文件 (关键步骤!)
cp harmony_gpt_oss.tiktoken /root/.cache/tiktoken/fb374d419588a4632f3f557e76b4b70aebbca790
# 验证文件大小 (应为 ~3.5MB)
ls -lh /root/.cache/tiktoken/fb374d419588a4632f3f557e76b4b70aebbca790
⚙️ 第三关:多进程与 CUDA 初始化
💥 踩坑 3:Python 多进程死锁
【问题现象】
启动服务时报错:RuntimeError: An attempt has been made to start a new process before the current process has finished its bootstrapping phase...
【原因分析】
CUDA 12+ 在 Python 的默认 fork 模式下,如果主进程已经初始化了 CUDA 上下文,子进程再次初始化极易发生死锁或崩溃。
【解决方案】
强制指定 Python 多进程启动方式为 spawn。
✅ 最终环境变量配置
建议保存为 env_setup.sh,一次性解决所有问题:
bash
#!/bin/bash
# 1. 显式指定后端
export VLLM_TARGET_DEVICE="cuda"
# 2. [核心] 强制使用 spawn 模式 (解决多进程死锁)
export VLLM_WORKER_MULTIPROC_METHOD="spawn"
# 3. [核心] 指定 Rust 侧词表缓存路径 (解决 HarmonyError)
export TIKTOKEN_RS_CACHE_DIR="/root/.cache/tiktoken"
# 4. 清理旧设置,让 vLLM 自动识别 Blackwell 算子
unset VLLM_ATTENTION_BACKEND
echo "Blackwell Environment Configured!"🚀 第四步:满血启动脚本
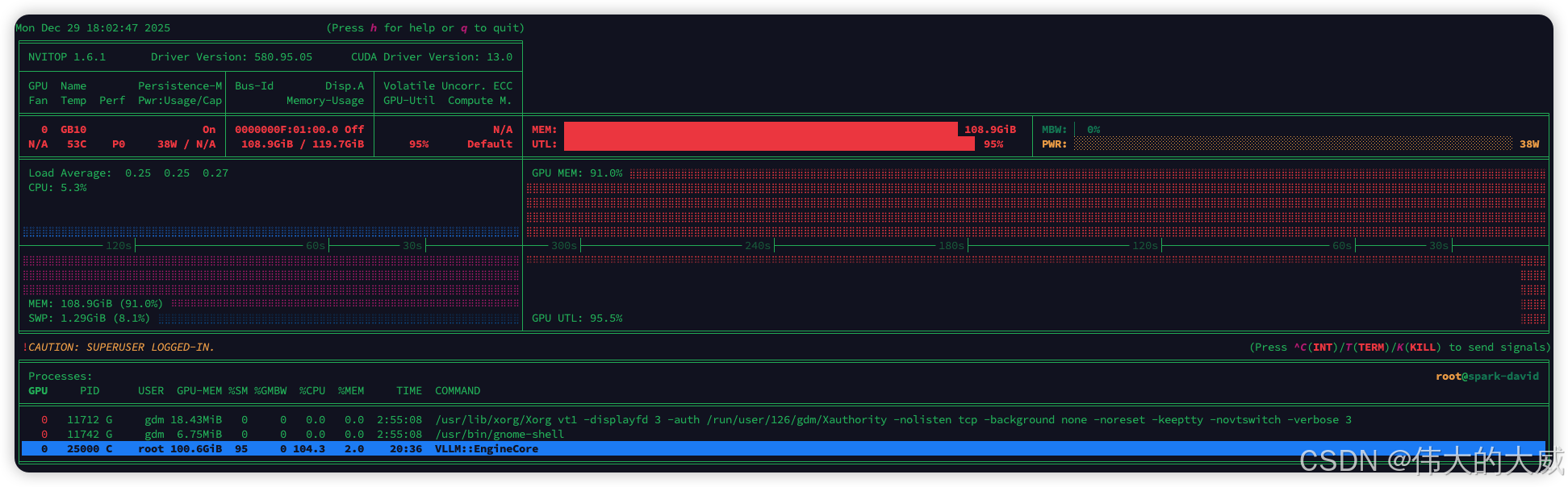
一切准备就绪,使用以下脚本启动 API Server。针对 Blackwell GB10 的 128GB 显存,我们启用了 MXFP4 量化和 FP8 KV Cache。
启动脚本 run_blackwell.sh:
bash
#!/bin/bash
source ./env_setup.sh
# 确保进入工作目录
cd /home/david/workspaces/vllm-spark/vllm
echo "Starting GPT-OSS 120B on Blackwell..."
python -m vllm.entrypoints.openai.api_server \
--model /home/david/workspaces/models/gpt-oss-120b \
--served-model-name gpt-oss-120b \
--quantization mxfp4 \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.85 \
--max-model-len 4096 \
--trust-remote-code \
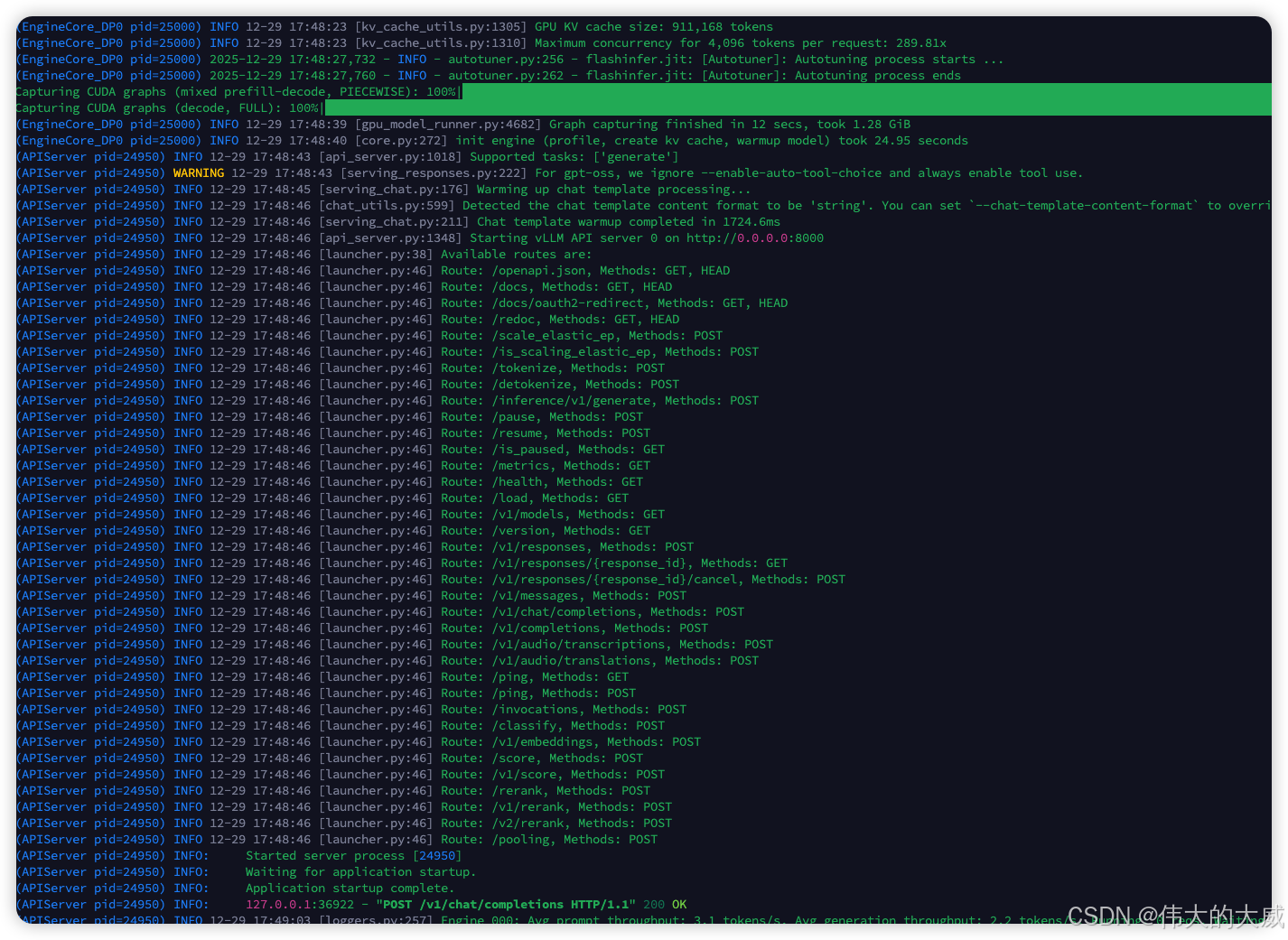
--host 0.0.0.0 --port 8000启动过程实录
- 加载权重:约 3-5 分钟,显存占用攀升至 ~66GB。
- KV Cache 预分配:显存进一步占用至 85% 水位。
- 成功标志 :终端显示
Uvicorn running on http://0.0.0.0:8000。
🧪 第五步:推理测试
GPT-OSS 是 Base 模型,支持思维链推理(Reasoning),返回结果中会包含 reasoning 字段。
测试脚本 test_curl.sh:
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant running on NVIDIA Blackwell hardware."},
{"role": "user", "content": "你好,Blackwell!请详细介绍一下你自己。"}
],
"max_tokens": 500,
"temperature": 0.7
}'


📝 避坑总结表
| 报错关键词 | 核心原因 | 必杀技 |
|---|---|---|
ImportError: numpy.core.multiarray |
NumPy 2.x ABI 不兼容 | pip install "numpy<2.3" |
HarmonyError: error downloading |
内网无法下载词表,且库只认 Hash | 设置 TIKTOKEN_RS_CACHE_DIR 并放入 SHA1 命名的文件 |
RuntimeError: bootstrapping phase |
CUDA 初始化与 Fork 冲突 | export VLLM_WORKER_MULTIPROC_METHOD="spawn" |
OOM (Out of Memory) |
加载了 BF16 权重而非 FP4 | 确保启动参数包含 --quantization mxfp4 |
希望这篇实战指南能帮助大家在 NVIDIA Blackwell 平台上顺利落地大模型!