在上一章中完成对xv6操作系统的移植,本章补全其中的部分接口机制分析。
一、xv6自旋锁
1.1、自旋锁初始化
cpp
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};
// Per-CPU state.
struct cpu {
struct proc *proc; // The process running on this cpu, or null.
struct context context; // swtch() here to enter scheduler().
int noff; // Depth of push_off() nesting.
int intena; // Were interrupts enabled before push_off()?
};
void initlock(struct spinlock *lk, char *name)
{
lk->name = name;
lk->locked = 0;
lk->cpu = 0;
}- 自旋锁的初始化:
- initlock(struct spinlock *lk, char *name)
- 将lk自旋锁中的name命名为传入的字符串;
- 然后将lk中的locked和cpu成员都初始化为0;
1.2、自旋锁获取
-
自旋锁的获取:
- acquire(struct spinlock *lk)
cpp// Acquire the lock. // Loops (spins) until the lock is acquired. void acquire(struct spinlock *lk) { push_off(); // disable interrupts to avoid deadlock. if(holding(lk)) panic("acquire"); // On RISC-V, sync_lock_test_and_set turns into an atomic swap: // a5 = 1 // s1 = &lk->locked // amoswap.w.aq a5, a5, (s1) while(__sync_lock_test_and_set(&lk->locked, 1) != 0) ; // Tell the C compiler and the processor to not move loads or stores // past this point, to ensure that the critical section's memory // references happen strictly after the lock is acquired. // On RISC-V, this emits a fence instruction. __sync_synchronize(); // Record info about lock acquisition for holding() and debugging. lk->cpu = mycpu(); }-
首先调用push_off函数,此函数的作用为:
- 关闭监管者模式的全局中断;
- 然后再判断此hart是否第一次进入push_off,如果是,则保存sstatus寄存器中监管者中断使能状态,如果不是,则说明已经被保存过了;
- 最后再将noff嵌套深度值+1;
-
再进行判断holding(lk)的返回值:
*cppint holding(struct spinlock *lk) { int r; r = (lk->locked && lk->cpu == mycpu()); return r; }- 如果自旋锁之前从未被获取,则返回0;
- 如果自旋锁之前已经被获取,并且获取此自旋锁的hart,也是现在正想获取此自旋锁的hart,则返回1;
- 这里的意思是,如果同一个hart,在获取此自旋锁后,在并未释放此自旋锁的情况下,再一次去获取此自旋锁,则返回1;之后便将发生panic,因为发生这种情况后,此hart将无法解锁;(即死锁情况发生)
-
接着再调用硬件原子指令集while(__sync_lock_test_and_set(&lk->locked, 1) != 0);
-
__sync_lock_test_and_set指令为硬件指令,其为原子操作,将一系列指令集打包为原子执行;
-
其功能为,先将lk->locked的值存入一个临时寄存器,再将1写入lk->locked中,最后再将临时寄存器中的值进行返回,其汇编如下:
*cpp// On RISC-V, sync_lock_test_and_set turns into an atomic swap: a5 = 1 s1 = &lk->locked amoswap.w.aq a5, a5, (s1) -
由此可知,当lk->locked一直为1时,while条件将一直成立,所以hart将一直陷入循环当中;直到此锁被释放,使得while条件不成立,退出循环,获取到此锁;
-
-
最后向此自旋锁登记绑定的hart,lk->cpu = mycpu();
1.3、自旋锁释放
-
自旋锁的释放:
*cpp// Release the lock. void release(struct spinlock *lk) { if(!holding(lk)) panic("release"); lk->cpu = 0; // Tell the C compiler and the CPU to not move loads or stores // past this point, to ensure that all the stores in the critical // section are visible to other CPUs before the lock is released, // and that loads in the critical section occur strictly before // the lock is released. // On RISC-V, this emits a fence instruction. __sync_synchronize(); // Release the lock, equivalent to lk->locked = 0. // This code doesn't use a C assignment, since the C standard // implies that an assignment might be implemented with // multiple store instructions. // On RISC-V, sync_lock_release turns into an atomic swap: // s1 = &lk->locked // amoswap.w zero, zero, (s1) __sync_lock_release(&lk->locked); pop_off(); }-
同样首先判断此自旋锁是否已经被获取,如果没有,则panic;如果有被获取,但要释放此锁的hart不是获取到此锁的hart,则也panic;
-
然后lk->cpu = 0; 再将此锁与hart解绑定;
-
再__sync_lock_release(&lk->locked);将锁清零,汇编代码如下:
*cpp// On RISC-V, sync_lock_release turns into an atomic swap: s1 = &lk->locked amoswap.w zero, zero, (s1)- __sync_lock_release指令也是原子的指令集合,指令如上所示;
-
最后再调用pop_off();进行解嵌套,如果解嵌套到最后一层,则恢复sstatus寄存器在push_off之前的值。
-
1.4、xv6自旋锁设计原理
- 关于自旋锁的疑问:
- 为何在获取自旋锁时,需要关闭本地cpu的全局中断,在释放自选锁后,再恢复全局中断使能?
- 从下图分析可得结论:
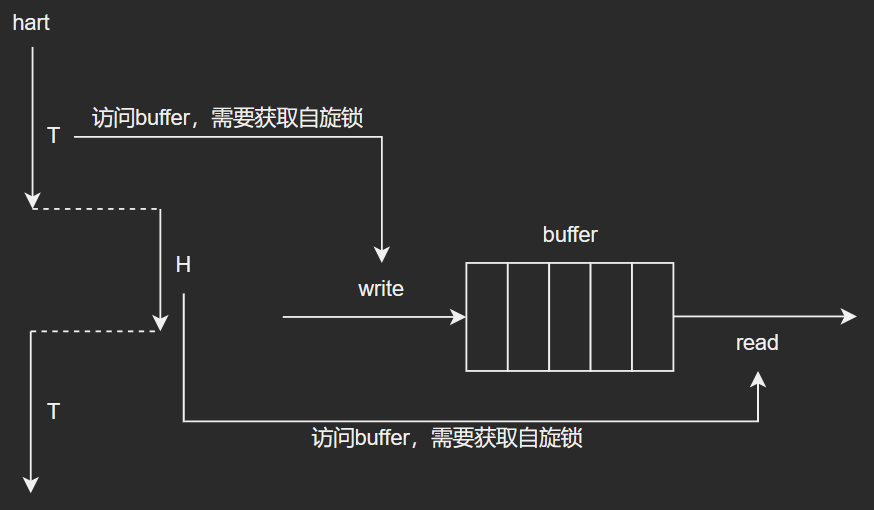
- 当在同一hart中时,其中有一个正在运行的线程T,并且即将访问buffer时,将获取访问此buffer的"钥匙",即自旋锁;
- 并且在线程T还未完全处理完buffer时,此时发生中断,并且在中断上下文H中如果也要访问相同buffer,则中断上线文H也将会去获取相同的自旋锁,那么此时将发生死锁;(xv6串口驱动就会发生此情景)
- 所以为了防止这种情况的出现,在获取自旋锁时,就需要进行全局中断的关闭,以此来规避中断的产生;(在现代Linux系统当中,自旋锁的实现提供了两种接口,一种仅保证多CPU间的互斥;另一种实现了关闭本地中断,可以在中断中使用的自旋锁接口)
- 所以在自旋锁中间的代码,被称为关键代码,需要尽快执行完毕。
- 为何在获取自旋锁时,需要先进行push_off,且在push_off时,会进行中断使能的嵌套判定?
-
push_off与pop_off的代码如下:
*cppvoid push_off(void) { int old = intr_get(); // disable interrupts to prevent an involuntary context // switch while using mycpu(). intr_off(); if(mycpu()->noff == 0) mycpu()->intena = old; mycpu()->noff += 1; } void pop_off(void) { struct cpu *c = mycpu(); if(intr_get()) panic("pop_off - interruptible"); if(c->noff < 1) panic("pop_off"); c->noff -= 1; if(c->noff == 0 && c->intena) intr_on(); } -
从代码中可知,mycpu()->noff代表了嵌套数,在嵌套数为0时,将保存关闭全局中断前的sstatus寄存器的值;
-
然后每次陷入嵌套后,noff都将+1,而保存的sstatus寄存器值都将不变;
-
最后在跳出所有嵌套后,将noff降至0,然后再恢复sstatus寄存器的值,此时将打开全局中断;
-
所以为什么要这样做呢?是因为在获取了某一个自旋锁A后,在执行第一段关键代码时,可能还会获取到另外一个自旋锁B,所以在执行完第二段关键代码后,释放自旋锁B时,因为第一个问题,还不能恢复全局中断,所以需要判断嵌套层级;等到释放自旋锁A后,确认完全退出嵌套后,才能恢复sstatus寄存器,打开全局中断。
-
- 为何在获取自旋锁时,需要关闭本地cpu的全局中断,在释放自选锁后,再恢复全局中断使能?
二、系统调用
系统调用是操作系统提供给用户层应用程序访问内核某些特定功能的接口。
在xv6系统中,系统调用初始有如下几种:
cpp
// An array mapping syscall numbers from syscall.h
// to the function that handles the system call.
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_pause] sys_pause,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
};系统调用用户层实现代码为(以前两个系统调用代码举例):
cpp
#define SYS_fork 1
#define SYS_exit 2
.global fork
fork:
li a7, SYS_fork
ecall
ret
.global exit
exit:
li a7, SYS_exit
ecall
ret- 首先在操作系统中,对于每一个系统调用都有一个唯一的系统调用编号;
- 当发生系统调用时,将系统调用对应的唯一编号填入a7寄存器当中,然后再调用ecall汇编指令,陷入异常;
- 此时cpu将陷入异常状态,进入监管者模式,并通过a7寄存器中的编号找到内核中实现的系统调用功能函数,完成执行对应系统调用功能。
三、sleep与wakeup的实现
首先要理解ticks的含义,ticks是嘀嗒计时器,也就是说cpu内部有一个定时器,会进行嘀嗒计时,当每一次"嘀嗒"后,ticks都将会+1;并且ticks的计时增加,只由hart0来完成。
首先查看定时器ticks处理函数:
cpp
void clockintr()
{
if(cpuid() == 0){
acquire(&tickslock);
ticks++;
wakeup(&ticks);
release(&tickslock);
}
// ask for the next timer interrupt. this also clears
// the interrupt request. 1000000 is about a tenth
// of a second.
w_stimecmp(r_time() + 1000000);
}- 此函数为处理hart定时器中断的入口函数;
- 首先获取ticks的自旋锁,然后再将ticks加1,再执行唤醒操作:
cpp
void wakeup(void *chan)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
if(p != myproc()){
acquire(&p->lock);
if(p->state == SLEEPING && p->chan == chan) {
p->state = RUNNABLE;
}
release(&p->lock);
}
}
}-
遍历每个进程,然后再判断该进程是否处于睡眠态,并与ticks指针绑定;
-
如果满足唤醒条件,则将该进程设置为准备运行态;
然后再查看sleep系统调用的实现:
cpp
void sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
acquire(&p->lock); //DOC: sleeplock1
release(lk);
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
release(&p->lock);
acquire(lk);
}- 在此函数中首先释放传入的自旋锁;
- 然后再将进程设置为睡眠态,并将chan设为传入的通道;
- 最后执行sched()函数,完成进程的调度切换,使当前进程进入休眠;
所以当调用sleep,并且传入的参数是ticks通道时,当每次ticks中断发生时,将唤醒全部在ticks通道上进行休眠的进程,将其设置位可运行态,等待下一次cpu的调度。
- 所以sleep系统调用的实际实现原理:
- 1、设置需要休眠的ticks数;
- 2、然后将此进程设置为休眠态,并进行进程调度;
- 3、在进行ticks计数+1时,唤醒所有处于休眠态的进程,将休眠态改为可运行态;
- 4、调度到以前休眠的进程时,判断ticks计数值是否已经大于等于设置需要休眠的ticks值:
- 如果已经大于等于,则退出sleep系统调用,继续进程的运行;
- 如果依然小于,则继续从第2步开始循环执行。